CLB-BER: An Approach to Electricity Consumption Behavior Analysis Using Time-Series Symmetry Learning and LLMs


Abstract
1. Introduction
- We propose a novel LLM-based framework for the power sector with domain-specific fine-tuning to enhance distributed energy resource management, addressing the challenges of increasingly decentralized and complex energy systems.
- We enhance the CLUBS clustering algorithm with the innovative ECDW method while maintaining Spark compatibility, enabling the more accurate classification of diverse electricity consumption patterns.
- We develop CLB-BER, an advanced LLM-based classification model that employs our Improved-C algorithm, to label datasets and fine-tune a pre-trained DistilBERT model. By incorporating a Softmax layer, it achieves superior user classification accuracy in downstream tasks compared to conventional methods.
2. Methods and Framework
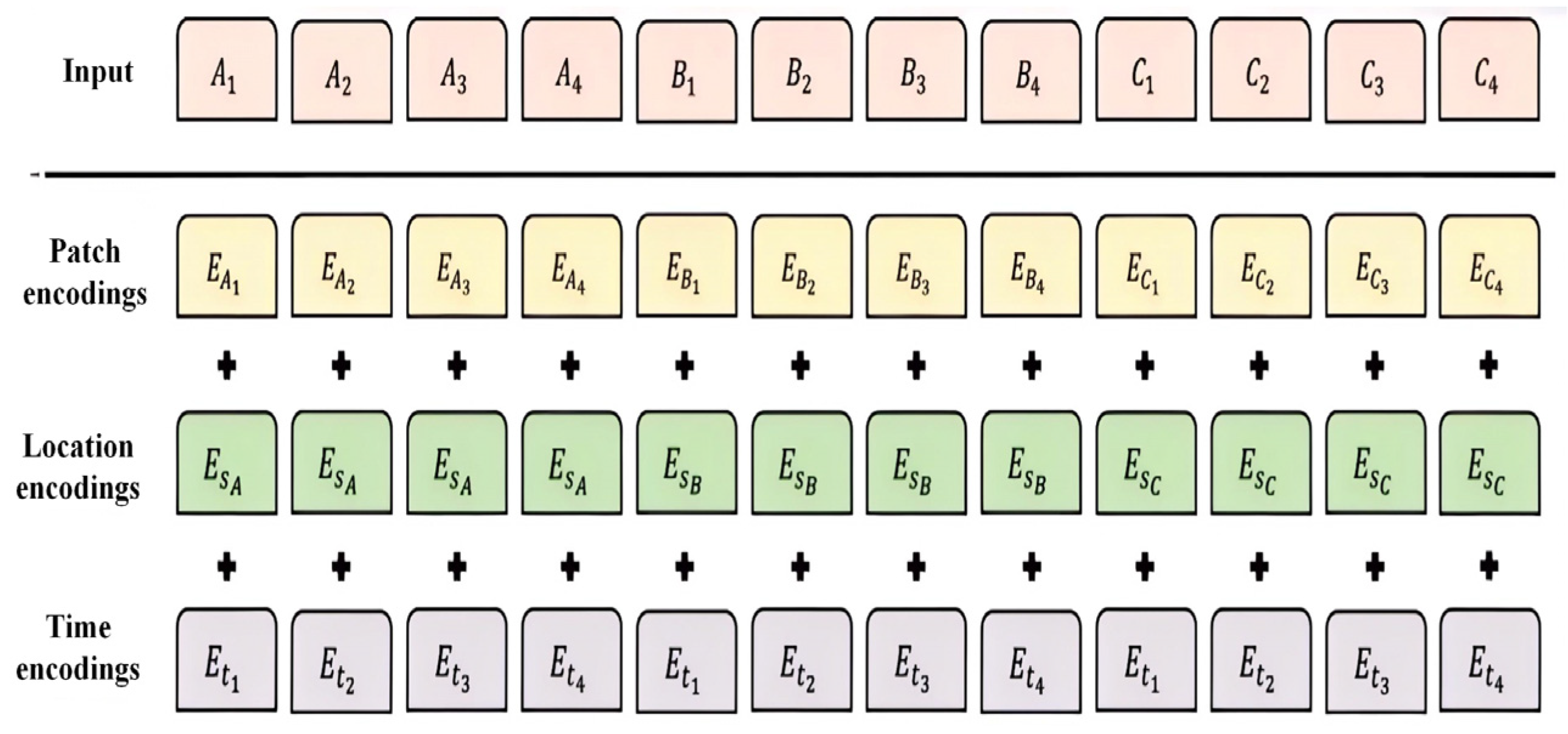
2.1. Overview of LLMs
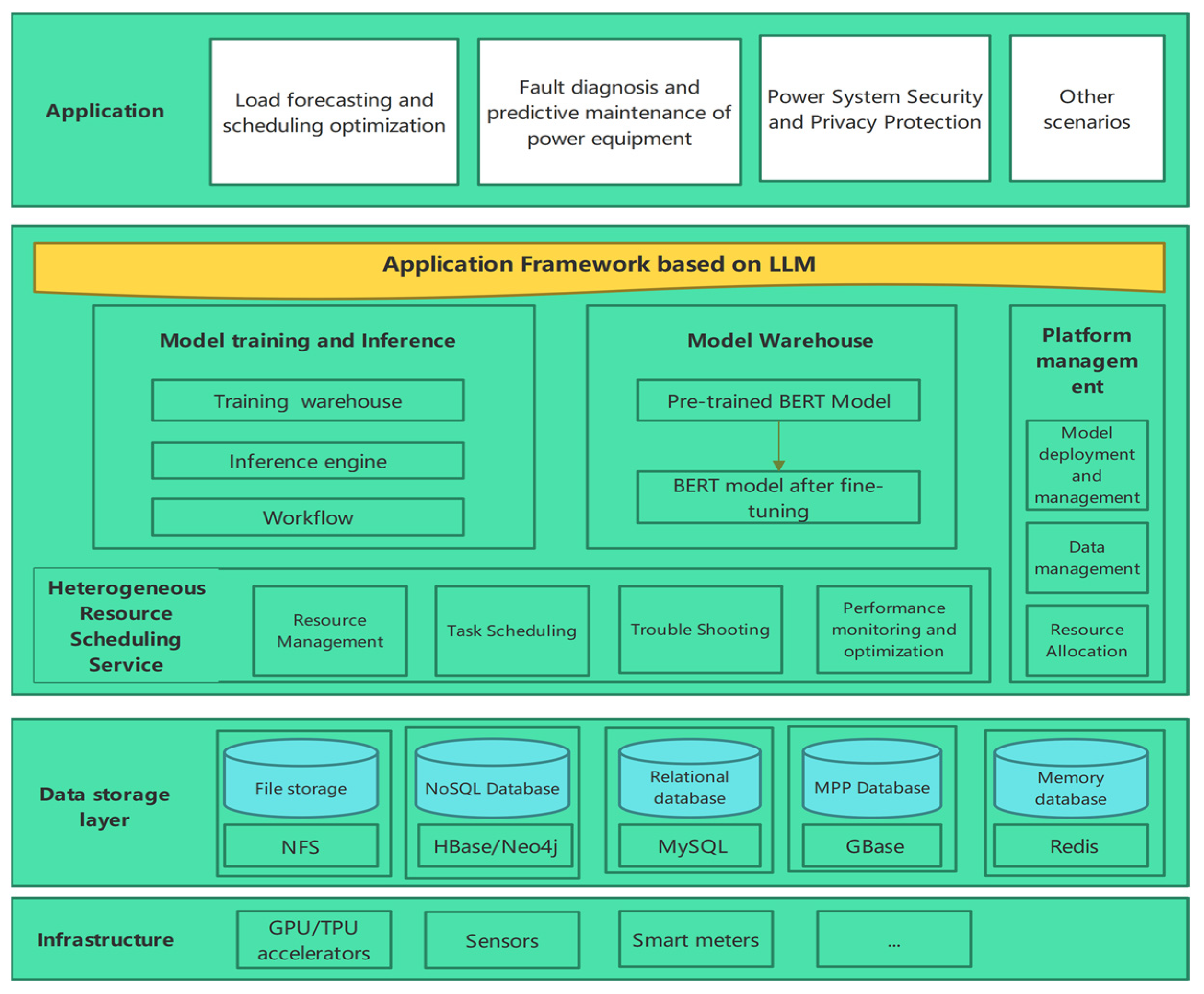
2.2. Application Framework Based on LLMs
- (1)
- The hardware layer integrates GPUs, TPUs, sensors, and smart meters for efficient computational power and data collection from the power system and customers. This layer additionally comprises a data collection interface and a data transmission module.
- (2)
- The data storage layer utilizes the NFS, HBase/Neo4j, MySQL, GBase, and Redis databases to stores massive multi-source heterogeneous data. NFS offers distributed file systems for large-scale data storage and retrieval. HBase and Neo4j store structured and unstructured data, respectively. MySQL and GBase manage structured business data, while Redis stores temporary and cache data.
- (3)
- The heterogeneous resource scheduling service layer manages resource allocation, task scheduling, troubleshooting, and performance monitoring and optimization. It oversees computing assets like CPUs, GPUs, and TPUs, arranges computational tasks, detects and resolves system issues, and optimizes system performance.
- (4)
- The model training and inference layer includes a training warehouse, an inference engine, and a workflow for managing training datasets, deploying trained models for real-time or batch inference, and defining and overseeing model training and inference progress with complex workflows.
- (5)
- The model warehouse stores pre-trained LLMs, such as BERT, along with fine-tuned models tailored to specific application scenarios.
- (6)
- The platform management layer includes model deployment and management, data management, and resource allocation.
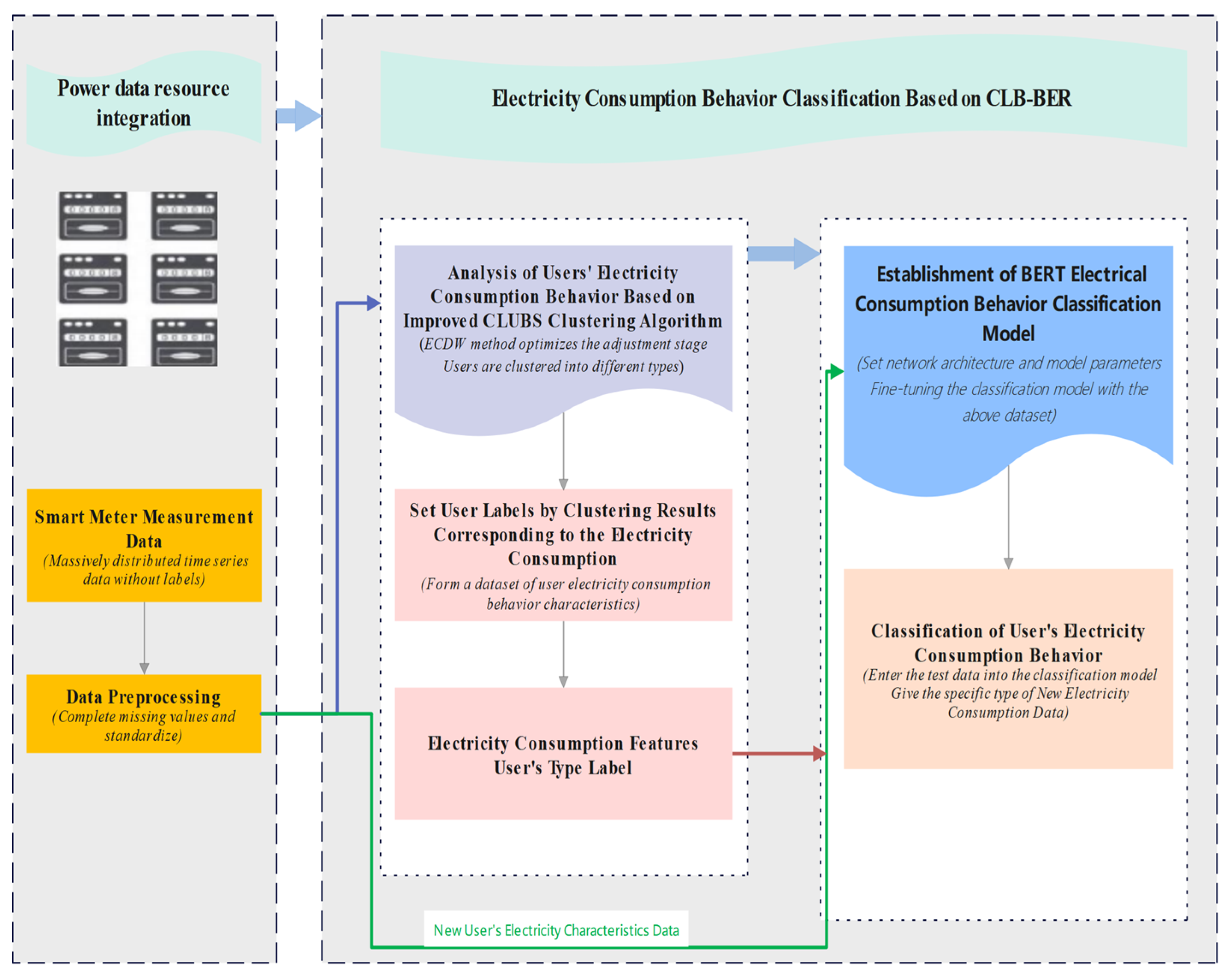
3. Electricity Consumption Behavior Classification Based on CLB-BER
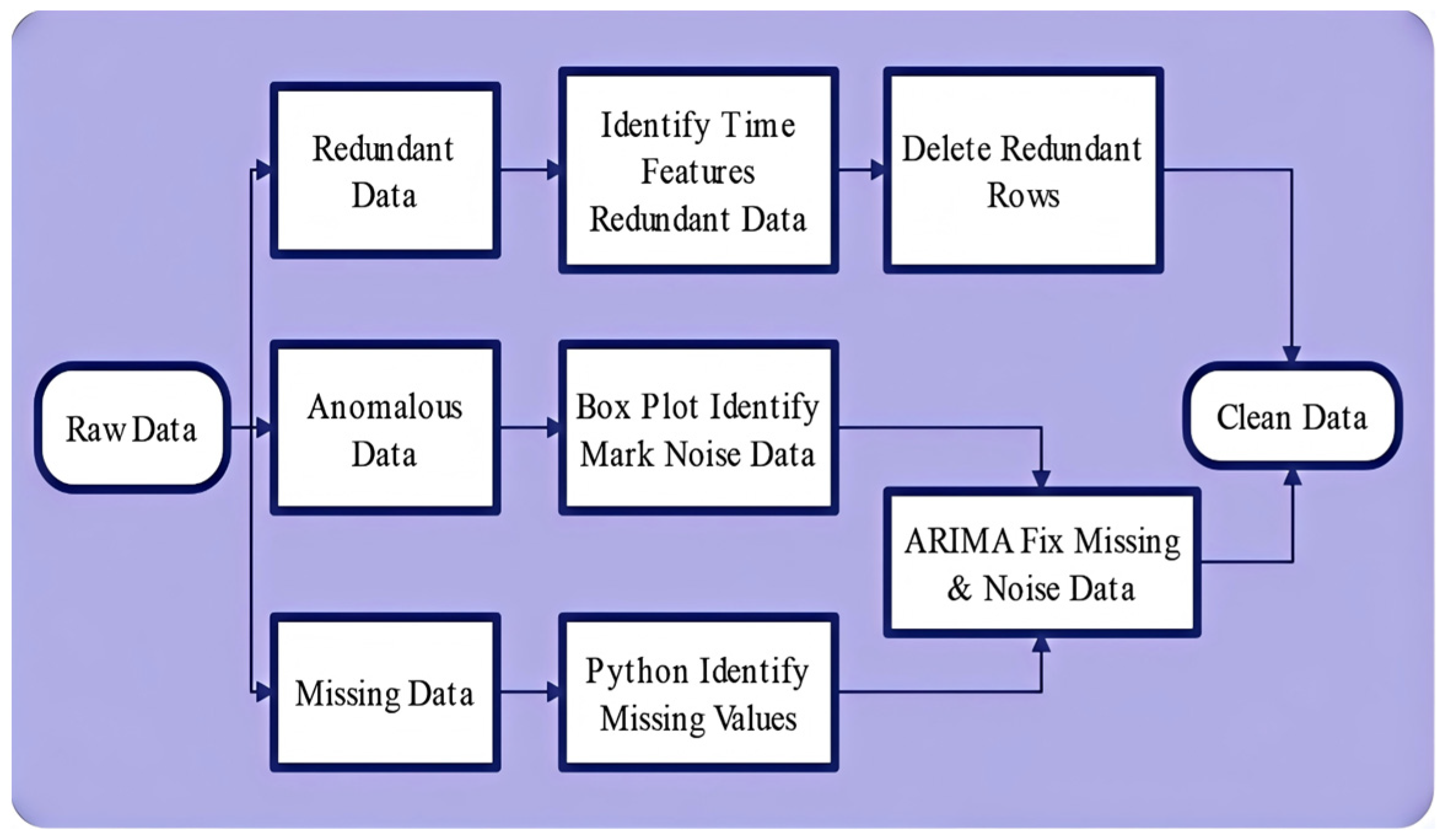
3.1. Data Preprocessing
3.1.1. Noise Recognition
3.1.2. Missing and Noise Value Repair
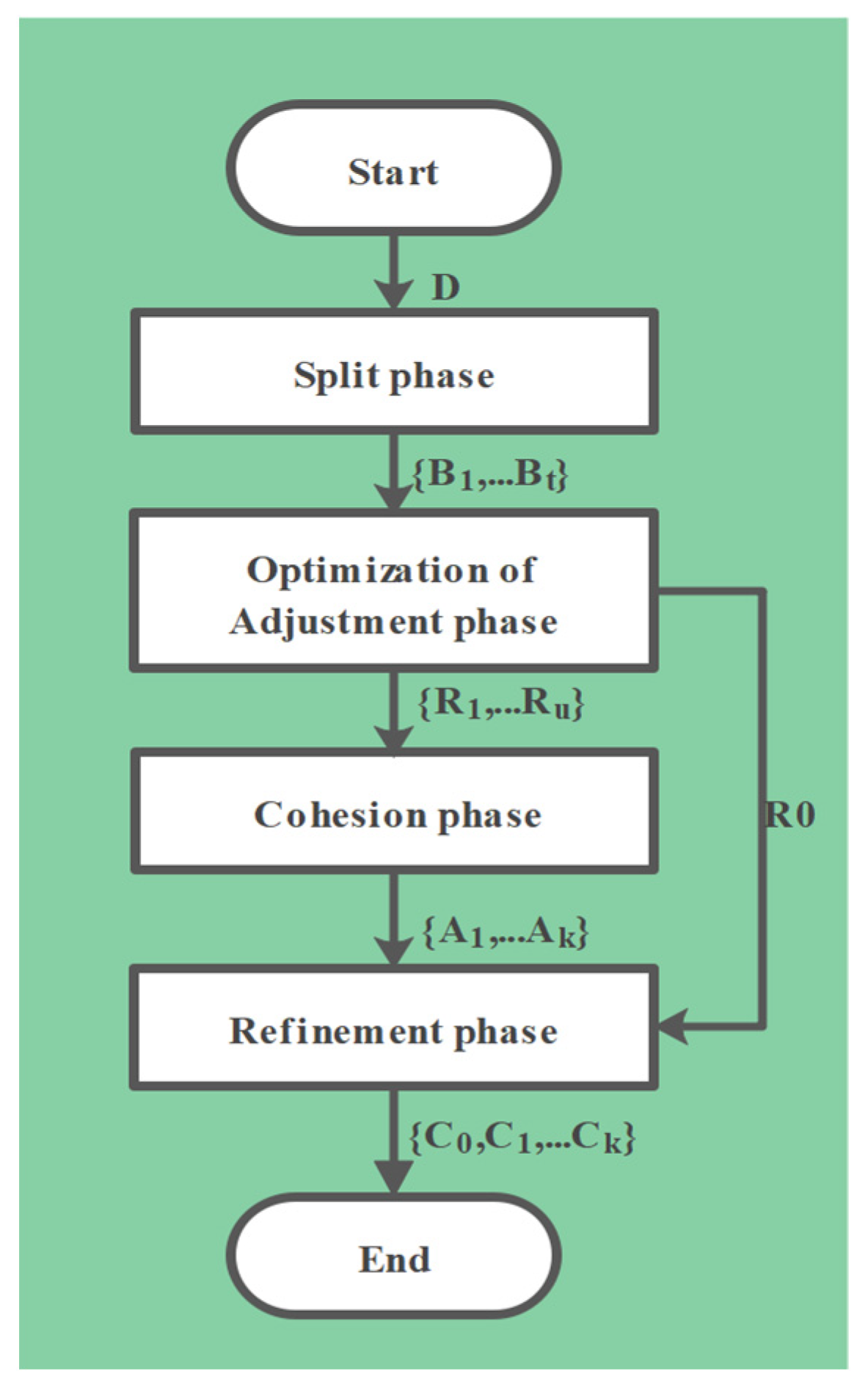
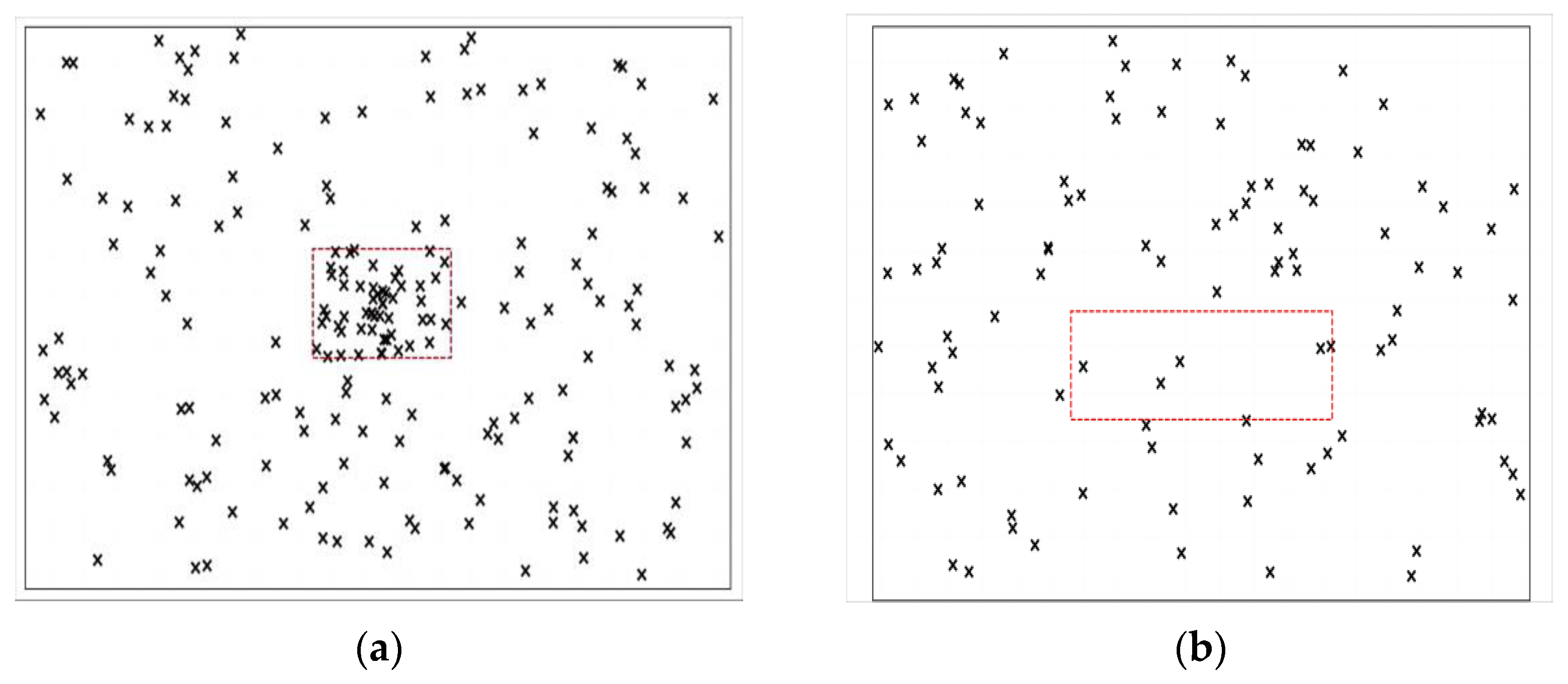
3.2. Improved CLUBS Clustering
3.2.1. Split Phase
3.2.2. Optimization-of-Adjustment Phase
| The Algorithm for Similarity Computation |
|
3.2.3. Cohesion Phase
3.2.4. Refinement Phase
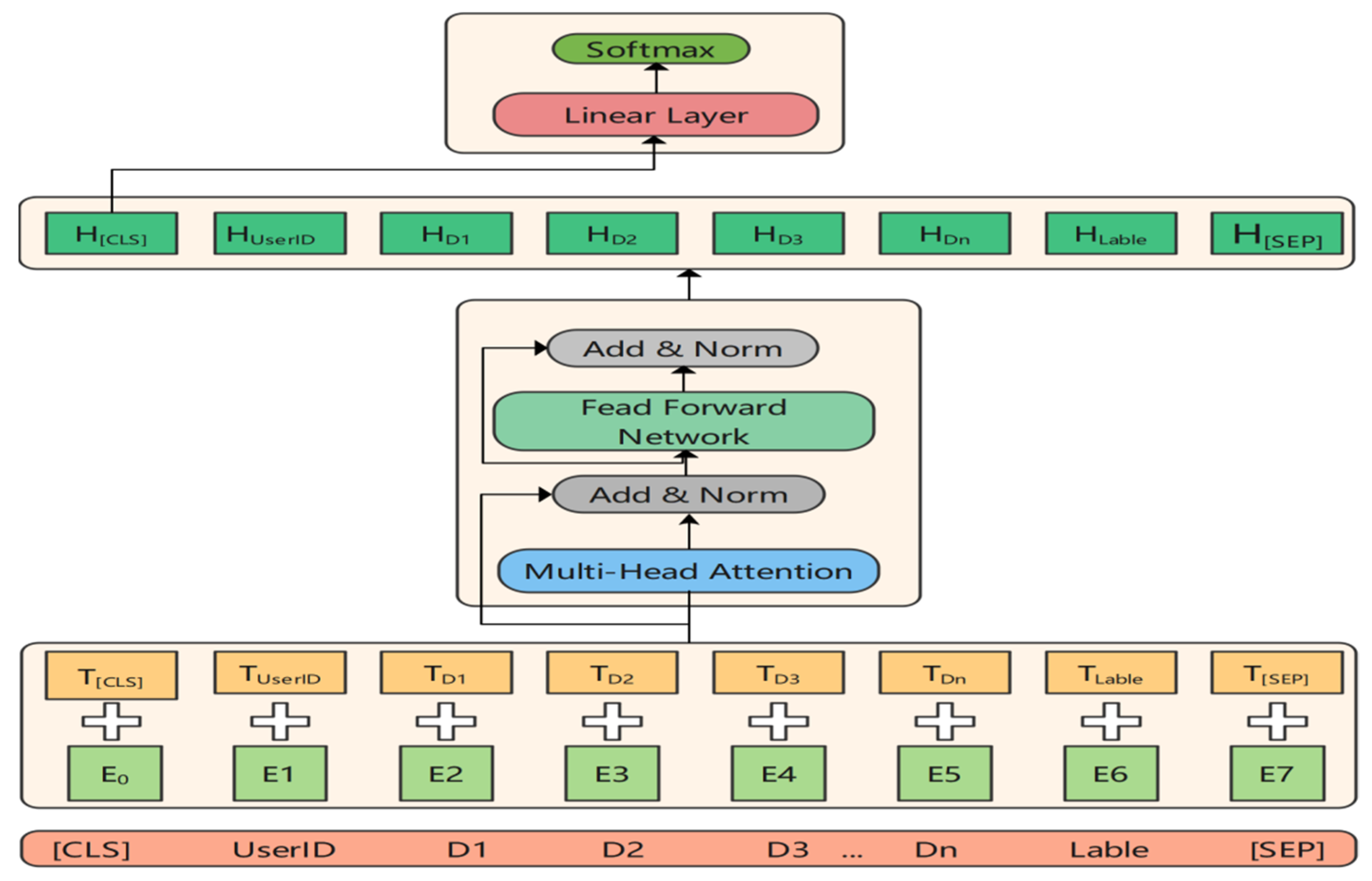
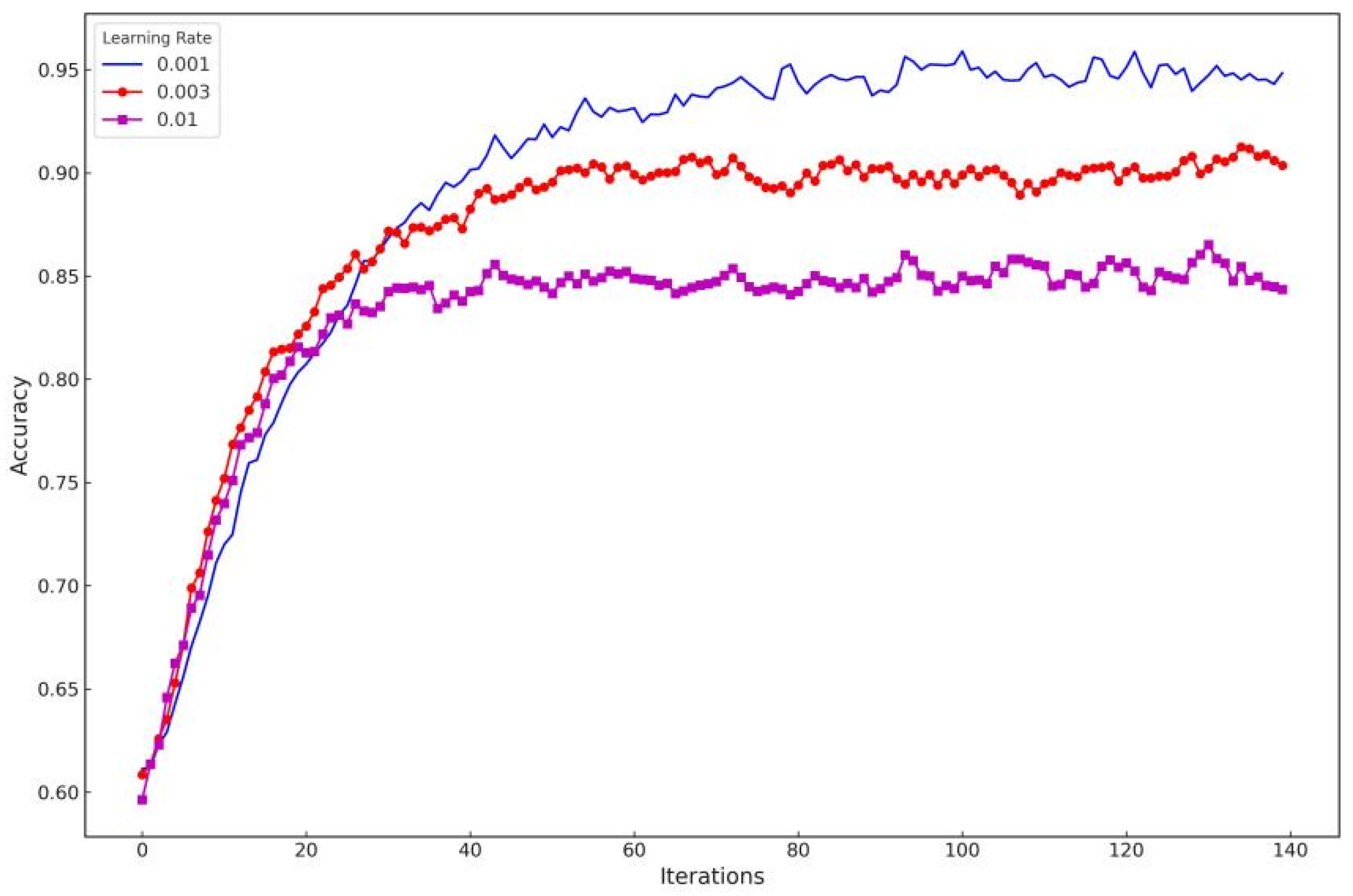
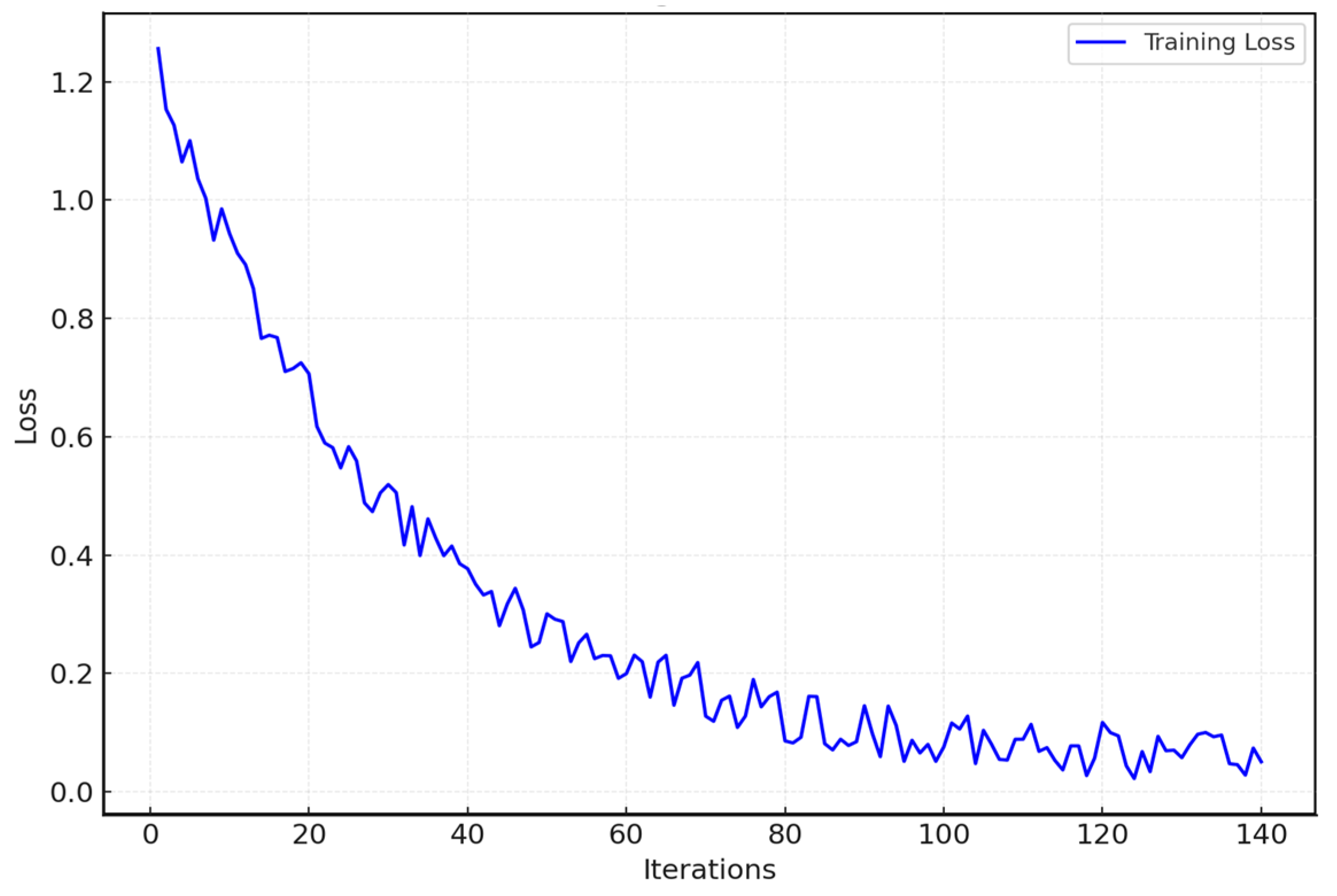
3.3. BERT Classification Model
4. Experiment and Analysis
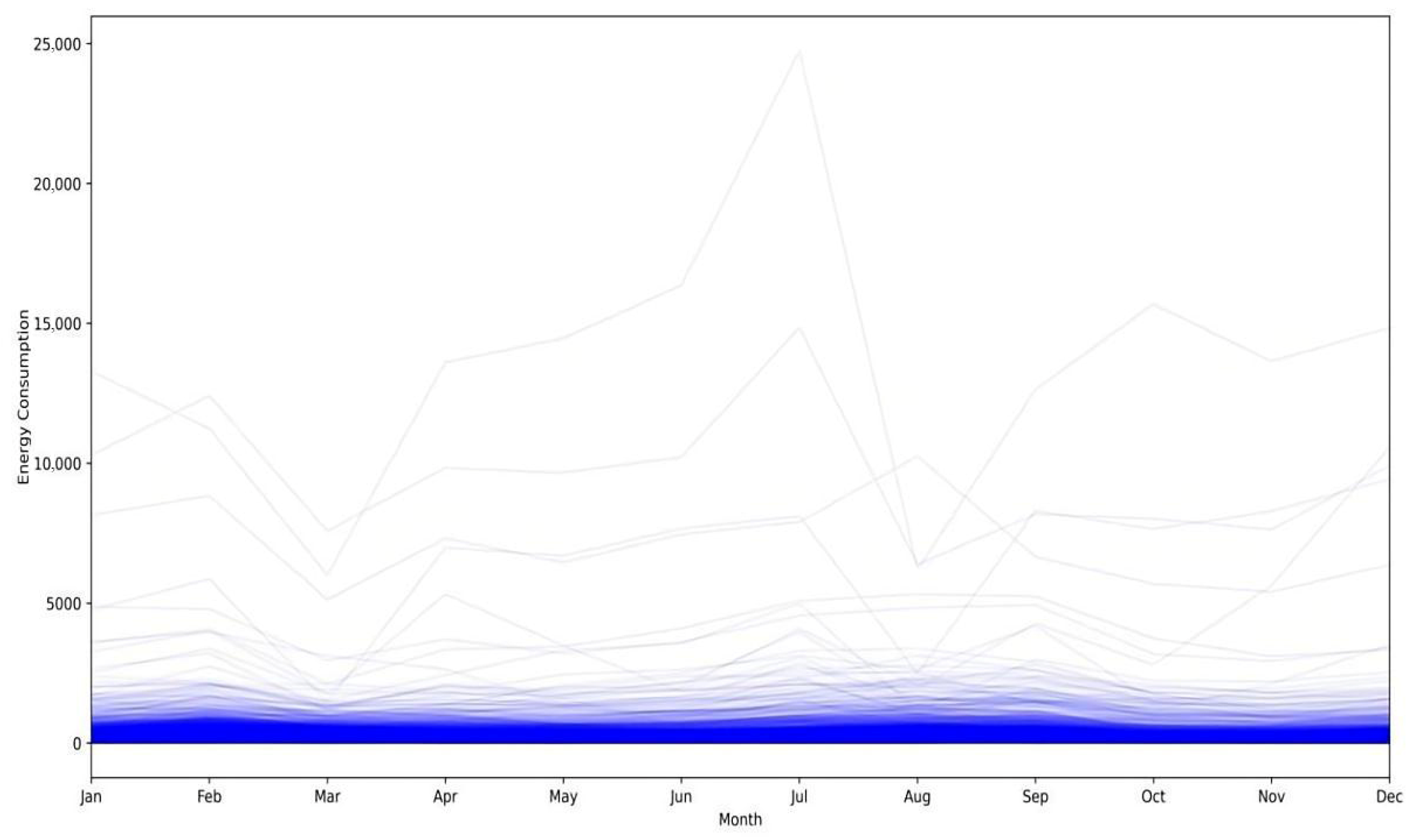
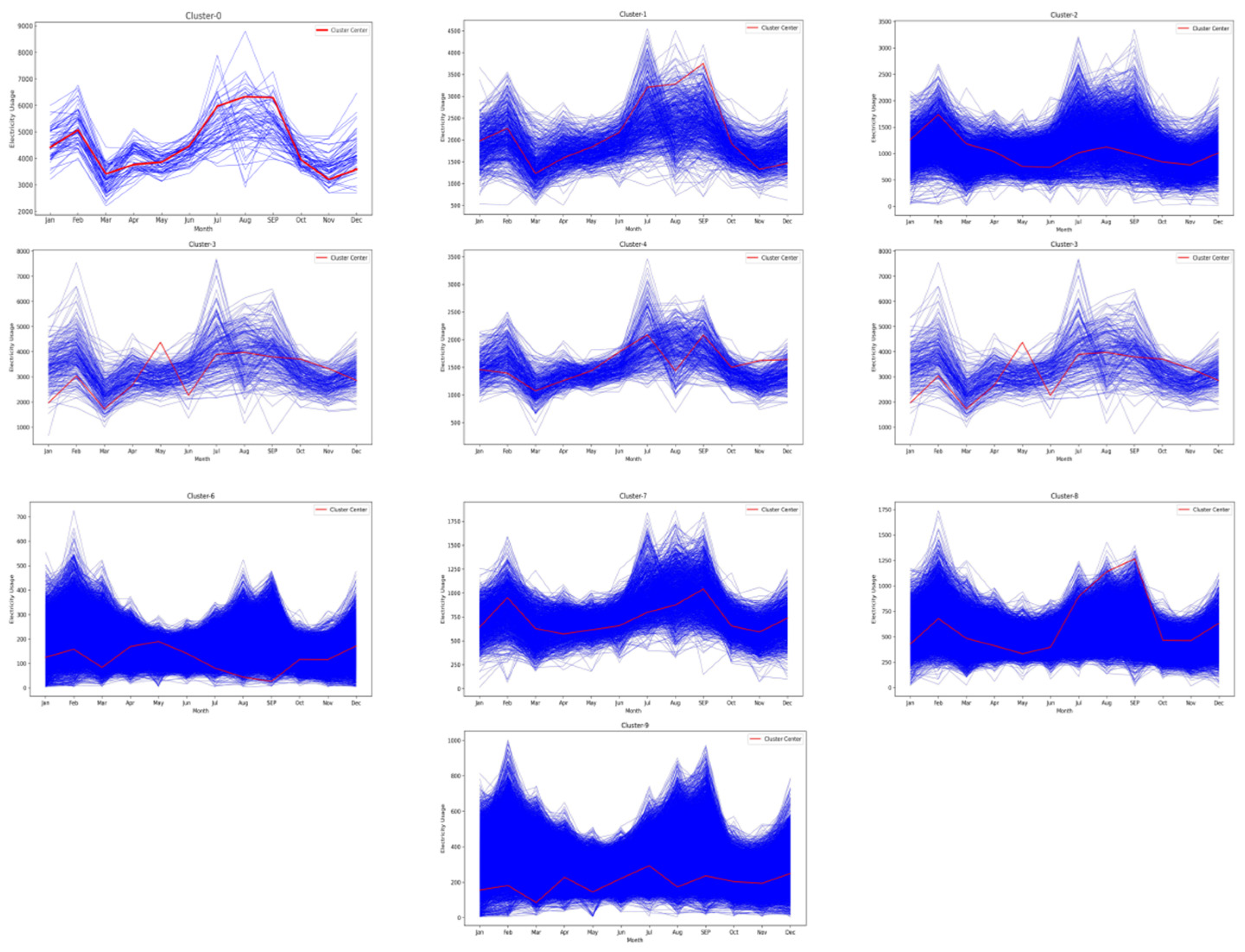
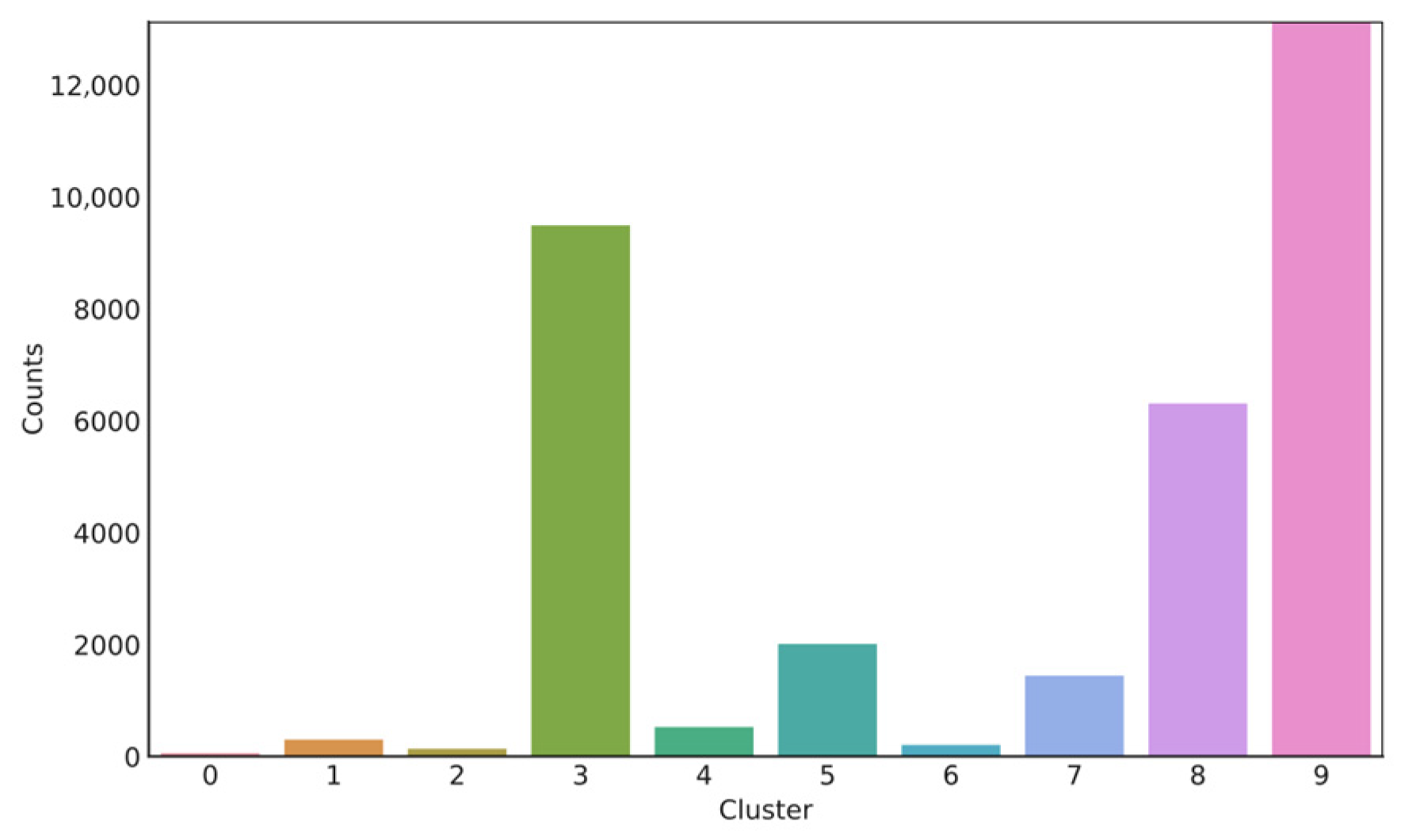
4.1. Clustering for Electricity Consumption Data
4.2. Matching Electricity Consumption Patterns for New Customers
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Glossary
| BCSS | Between-Clusters Sum of Squares: A measure of the variance between different cluster centroids, used to evaluate clustering quality. |
| BERT | Bidirectional Encoder Representations from Transformers: A pre-trained deep learning model designed for natural language processing tasks. |
| CH | Calinski–Harabasz Index: A clustering validation metric that measures the ratio of between-cluster variance to within-cluster variance. |
| CLB-BER | CLUBS-BERT: The proposed model combining improved CLUBS clustering with BERT for electricity consumption behavior classification. |
| CLUBS | CLUstering Big data by Sampling: A non-parametric clustering algorithm designed for large datasets using hierarchical strategies. |
| DistilBERT | Distilled BERT: A smaller, faster variant of BERT that retains most of BERT’s performance while reducing computational requirements. |
| DTW | Dynamic Time Warping: An algorithm for measuring similarity between temporal sequences that may vary in speed or length. |
| ECDW | Euclidean–Cosine Dynamic Windowing: The proposed method combining Euclidean distance and cosine similarity with dynamic windowing for time-series comparison. |
| LLM | Large Language Models: Deep learning models with billions of parameters trained on vast amounts of text data. |
| LSTM | Long Short-Term Memory: A type of recurrent neural network architecture capable of learning long-term dependencies. |
| MHA | Multi-Head Attention: An attention mechanism that allows the model to attend to information from different representation subspaces. |
| MLM | Masked Language Model: A pre-training task where certain tokens in the input are masked and the model learns to predict them. |
| NFS | Network File System: A distributed file system protocol allowing file access over a network. |
| PCA | Principal Component Analysis: A dimensionality reduction technique that transforms data to lower dimensions while preserving variance. |
| PNN | Probabilistic Neural Network: A neural network used for classification and pattern recognition problems. |
| PSO-K | Particle Swarm Optimization K-means: An optimization algorithm that combines particle swarm optimization with K-means clustering. |
| Redis | Remote Dictionary Server: An in-memory data structure store used as a database, cache, and message broker. |
| WCSS | Within-Cluster Sum of Squares: A measure of the variance within each cluster, used to evaluate clustering compactness. |
References
- Wang, H.; Yi, Z.; Xu, Y.; Cai, Q.; Li, Z.; Wang, H.; Bai, X. Data-driven distributionally robust optimization approach for the coordinated dispatching of the power system considering the correlation of wind power. Electr. Power Syst. Res. 2024, 230, 110224. [Google Scholar] [CrossRef]
- Li, G.; Wang, K.; Lin, Y.; Lu, T.; Li, Y.; Han, F. Fault Diagnosis and Prediction Method of Distribution Transformer in Active Distribution Network Based on Data Augmentation. In Proceedings of the 2023 3rd International Conference on Electrical Engineering and Mechatronics Technology (ICEEMT), Nanjing, China, 21–23 July 2023; IEEE: New York, NY, USA, 2023; pp. 137–141. [Google Scholar]
- Huang, J.; Wu, F.; Li, Y.; Qian, J.; Yang, Y.; Yao, W. Safety analysis of new power system based on graph convolutional neural network evaluation. In Proceedings of the 2023 10th International Forum on Electrical Engineering and Automation (IFEEA), Nanjing, China, 3–5 November 2023; IEEE: New York, NY, USA, 2023; pp. 1188–1192. [Google Scholar]
- Liu, Z.; Hu, C.; Xia, H.; Xiang, T.; Wang, B.; Chen, J. SPDTS: A Differential Privacy-Based Blockchain Scheme for Secure Power Data Trading. IEEE Trans. Netw. Serv. Manag. 2022, 19, 5196–5207. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yang, J.; Jin, H.; Tang, R.; Han, X.; Feng, Q.; Jiang, H.; Yin, B.; Hu, X. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. arXiv 2023, arXiv:2304.13712. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar] [PubMed]
- Shakarian, P.; Koyyalamudi, A.; Ngu, N.; Mareedu, L. An Independent Evaluation of ChatGPT on Mathematical Word Problems (MWP). arXiv 2023, arXiv:2302.13814. [Google Scholar] [CrossRef]
- Gruver, N.; Finzi, M.; Stanton, S.; Wilson, A.G. Time Series Forecasting by Reprogramming Large Language Models. In ICLR 2024, Vienna, Austria, 7 May 2024; OpenReview: Alameda, CA, USA; Available online: https://openreview.net/forum?id=Unb5CVPtae (accessed on 16 January 2024).
- Jin, M.; Wen, S.; Song, Y.; Paik, H.Y. Empowering Time Series Analysis with Large Language Models. In Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI), Jeju, Republic of Korea, 3–9 August 2024; IJCAI: Jeju, Republic of Korea, 2024; Available online: https://www.ijcai.org/proceedings/2024/0895.pdf (accessed on 11 April 2024).
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Are Language Models Actually Useful for Time Series Forecasting? In Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 9–15 December 2024; Available online: https://proceedings.neurips.cc/paper_files/paper/2024/file/6ed5bf446f59e2c6646d23058c86424b-Paper-Conference.pdf (accessed on 15 April 2024).
- Xue, H.; Li, Y.; Zhang, J.; Chen, L. A large language model for advanced power dispatch. Sci. Rep. 2025, 15, 91940. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhang, W.; Li, H. Are Large Language Models Useful for Time Series Data Analysis? arXiv 2024, arXiv:2412.12219. [Google Scholar] [CrossRef]
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A survey of data augmentation approaches for NLP. arXiv 2021, arXiv:2105.03075. [Google Scholar] [CrossRef]
- Novelli, C.; Casolari, F.; Rotolo, A.; Taddeo, M.; Floridi, L. Taking AI risks seriously: A new assessment model for the AI act. AI Soc. 2024, 39, 2493–2497. [Google Scholar] [CrossRef]
- Cai, Y.; Mao, S.; Wu, W.; Wang, Z.; Liang, Y.; Ge, T.; Wu, C.; You, W.; Song, T.; Xia, Y. Low-code LLM: Visual programming over LLMs. arXiv 2023, arXiv:2304.08103. [Google Scholar]
- Jain, R.; Gervasoni, N.; Ndhlovu, M.; Rawat, S. A code centric evaluation of C/C++ vulnerability datasets for deep learning based vulnerability detection techniques. In Proceedings of the 16th Innovations in Software Engineering Conference, Allahabad, India, 23–25 February 2023; ACM: New York, NY, USA, 2023; pp. 1–10. [Google Scholar]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef] [PubMed]
- Arcila, B.B. Is it a platform? Is it a search engine? It’s ChatGPT! the European liability regime for large language models. J. Free. Speech Law 2023, 3, 455. [Google Scholar]
- OpenAI. GPT-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Anthropic. (n.d.). Introducing Claude. Available online: https://www.anthropic.com/index/introducing-claude (accessed on 17 June 2025).
- Roziere, B.; Gehring, J.; Gloeckle, F.; Sootla, S.; Gat, I.; Tan, X.E.; Adi, Y.; Liu, J.; Remez, T.; Rapin, J. Code llama: Open foundation models for code. arXiv 2023, arXiv:2308.12950. [Google Scholar]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Alpaca: A Strong, Replicable Instruction-Following Model. Available online: https://crfm.stanford.edu/2023/03/13/alpaca.html (accessed on 20 April 2024).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s transformers: State-of-the-art natural language processing. arXiv 2020, arXiv:1910.03771. [Google Scholar]
- Ianni, M.; Masciari, E.; Mazzeo, G.M.; Mezzanzanica, M.; Zaniolo, C. Fast and effective Big Data exploration by clustering. Future Gener. Comput. Syst. 2020, 102, 84–94. [Google Scholar] [CrossRef]
- Savci, P.; Das, B. Comparison of pre-trained language models in terms of carbon emissions, time and accuracy in multi-label text classification using AutoML. Heliyon 2023, 9, e15670. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Alammary, A.S. BERT models for Arabic text classification: A systematic review. Appl. Sci. 2022, 12, 5720. [Google Scholar] [CrossRef]
- Du, X.; Liu, Z.; Li, C.; Ma, X.; Li, Y.; Wang, X. LLM-BRC: A large language model-based bug report classification framework. Softw. Qual. J. 2024, 32, 985–1005. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
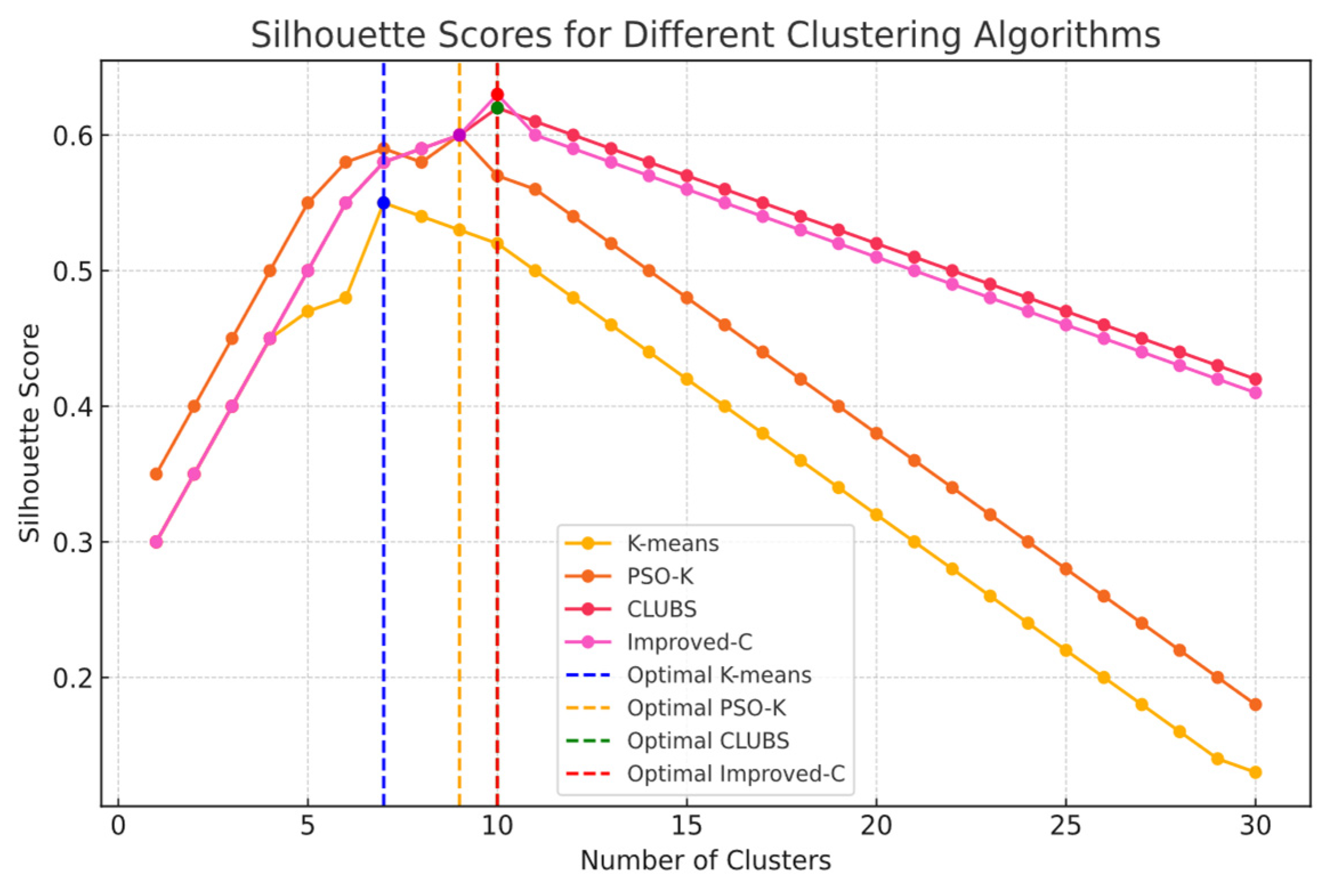
| Model | SI | Time(s) |
|---|---|---|
| K-means | 0.55 | 125 |
| PSO-K | 0.60 | 306 |
| CLUBS | 0.62 | 102 |
| Improved-C | 0.63 | 115 |
| JLDBH | YHBH | Jan | Feb | Mar | … | Nov | Dec | Pat |
|---|---|---|---|---|---|---|---|---|
| 4013XX | 4014XX | 4529.73 | 5195.29 | 3183.92 | … | 3573.03 | 4211.42 | 0 |
| 4013XX | 4014XX | 1468.26 | 1697.26 | 1115.15 | … | 1215.15 | 1390.69 | 1 |
| 4013XX | 4014XX | 2553.65 | 2876.26 | 1794.82 | …. | 2117.70 | 2414.48 | 2 |
| 4013XX | 4014XX | 181.69 | 233.27 | 192.47 | … | 129.21 | 167.91 | 3 |
| 4013XX | 4014XX | 1839.56 | 2149.62 | 1375.06 | … | 1554.40 | 1790.82 | 4 |
| Parameter Name | Default Value |
|---|---|
| vocab_size | 30,522 |
| max_position_embeddings | 512 |
| num_attention_heads | 12 |
| num_hidden_layers | 6 |
| hidden_size | 768 |
| intermediate_size | 3072 |
| hidden_act | sigmoid |
| Batch Size | 32 |
| Initial Learning Rate | 0.001 |
| Epochs | 50 |
| Dropout | 0.1 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| KNN | 81.45 | 82.32 | 80.48 | 81.39 |
| SVM | 86.73 | 87.26 | 85.91 | 86.58 |
| CNN | 88.47 | 88.92 | 87.69 | 88.30 |
| LSTM | 90.28 | 90.84 | 89.87 | 90.35 |
| Transformer | 92.13 | 92.51 | 91.83 | 92.17 |
| Shapelet Transform Transform Pipeline | 89.50 | 90.00 | 88.75 | 89.37 |
| Fuzzy C-Means + SVM | 87.00 | 87.50 | 86.25 | 86.87 |
| DistillBERT | 94.21 | 94.63 | 94.05 | 94.34 |
| Metric | DistilBERT Mean (Std) | Transformer Mean (Std) | p-Value |
|---|---|---|---|
| Accuracy | 94.21 (±0.25) | 92.13 (±0.30) | 0.0017 |
| Precision | 94.63 (±0.22) | 92.51 (±0.28) | 0.0012 |
| Recall | 94.05 (±0.21) | 91.83 (±0.27) | 0.0019 |
| F1-score | 94.34 (±0.20) | 92.17 (±0.25) | 0.0014 |
| Variant | SI | Accuracy (%) | F1 (%) |
|---|---|---|---|
| Full CLB-BER (Improved-C+DistilBERT) | 0.63 | 94.21 | 94.34 |
| Without ECDW (CLUBS + DistilBERT) | 0.62 | 92.50 | 92.75 |
| Improved-C+ SVM | - | 86.73 | 86.58 |
| Improved-C+LSTM | - | 90.28 | 90.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, J.; Zhang, N.; Zhao, Y.; Chen, H. CLB-BER: An Approach to Electricity Consumption Behavior Analysis Using Time-Series Symmetry Learning and LLMs. Symmetry 2025, 17, 1176. https://doi.org/10.3390/sym17081176
Su J, Zhang N, Zhao Y, Chen H. CLB-BER: An Approach to Electricity Consumption Behavior Analysis Using Time-Series Symmetry Learning and LLMs. Symmetry. 2025; 17(8):1176. https://doi.org/10.3390/sym17081176
Chicago/Turabian StyleSu, Jingyi, Nan Zhang, Yang Zhao, and Hua Chen. 2025. "CLB-BER: An Approach to Electricity Consumption Behavior Analysis Using Time-Series Symmetry Learning and LLMs" Symmetry 17, no. 8: 1176. https://doi.org/10.3390/sym17081176
APA StyleSu, J., Zhang, N., Zhao, Y., & Chen, H. (2025). CLB-BER: An Approach to Electricity Consumption Behavior Analysis Using Time-Series Symmetry Learning and LLMs. Symmetry, 17(8), 1176. https://doi.org/10.3390/sym17081176