DFAN: Single Image Super-Resolution Using Stationary Wavelet-Based Dual Frequency Adaptation Network



Abstract
1. Introduction
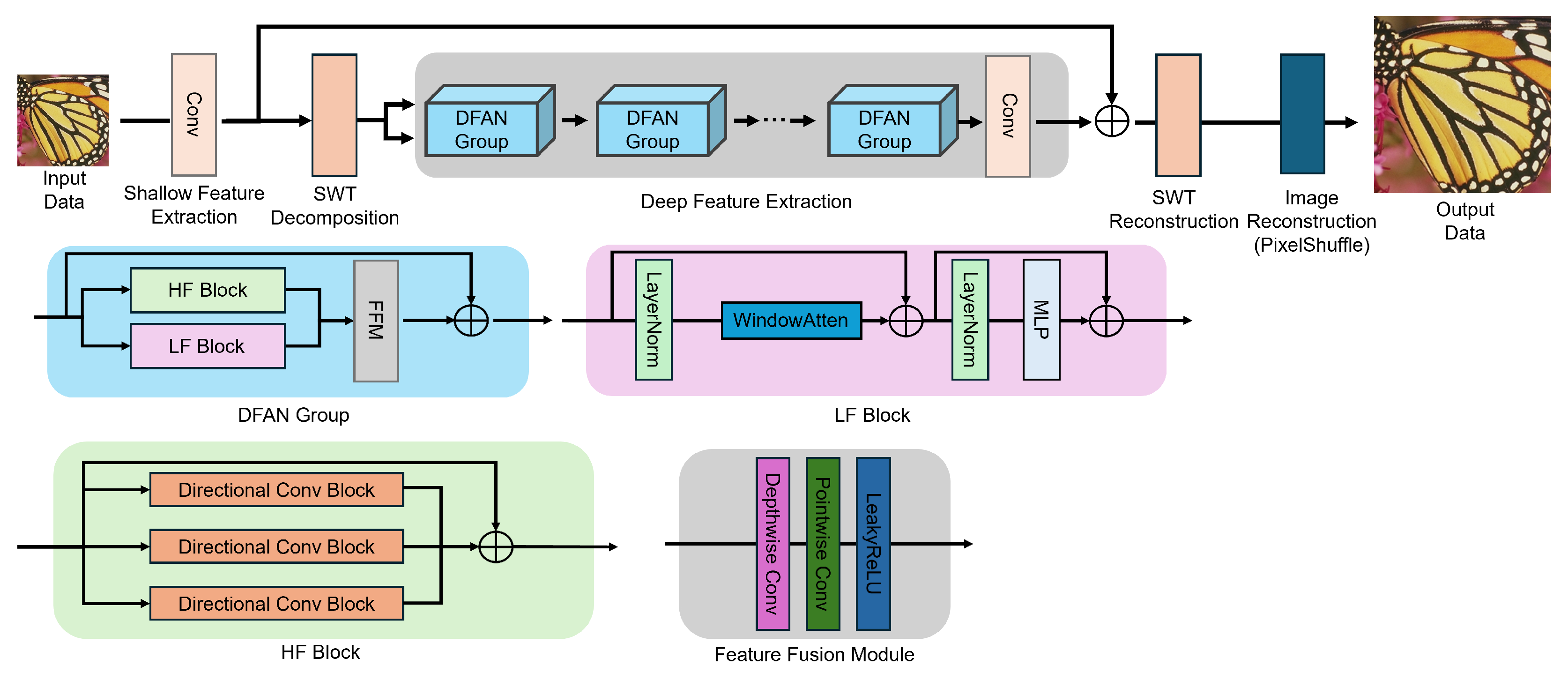
- Frequency-decomposition dual pipeline: The input image is separated into low- and high-frequency bands by SWT and processed in parallel, thereby combining the strengths of both spatial and frequency domains.
- Directional high-frequency module and fusion module: Sub-band-specific Directional Convolution followed by RDB amplifies and refines high-frequency details, which are then adaptively merged with the low-frequency global context in the Fusion Module to recover fine textures.
- Frequency-aware multi-loss function: A high-frequency loss term is added to the conventional reconstruction loss, forcing the network to learn the importance of high-frequency information explicitly.
- Superior super-resolution performance: The proposed design consistently surpasses state-of-the-art frequency-domain SISR methods not only in PSNR and SSIM but also in perceptual quality metrics such as LPIPS.
2. Related Work
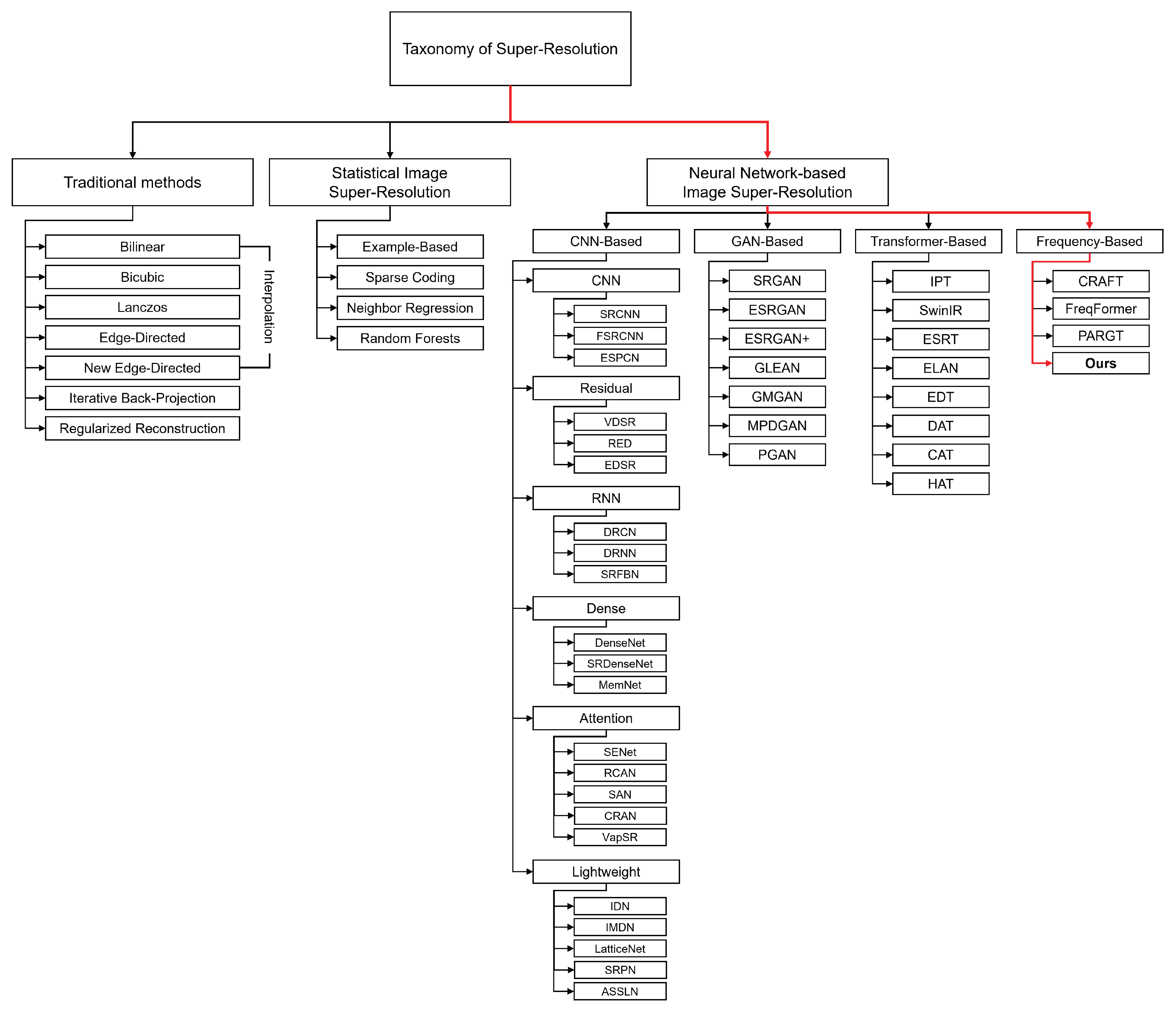
2.1. Traditional Methods
2.2. Statistical Image Super-Resolution Methods
2.3. Neural Network-Based Image Super-Resolution Methods
3. Proposed Method
3.1. Preliminaries
3.2. The Overall Structure
3.3. Low-Frequency Block
3.4. High-Frequency Block
3.5. Loss Function
4. Experimental Results
4.1. Experimental Settings
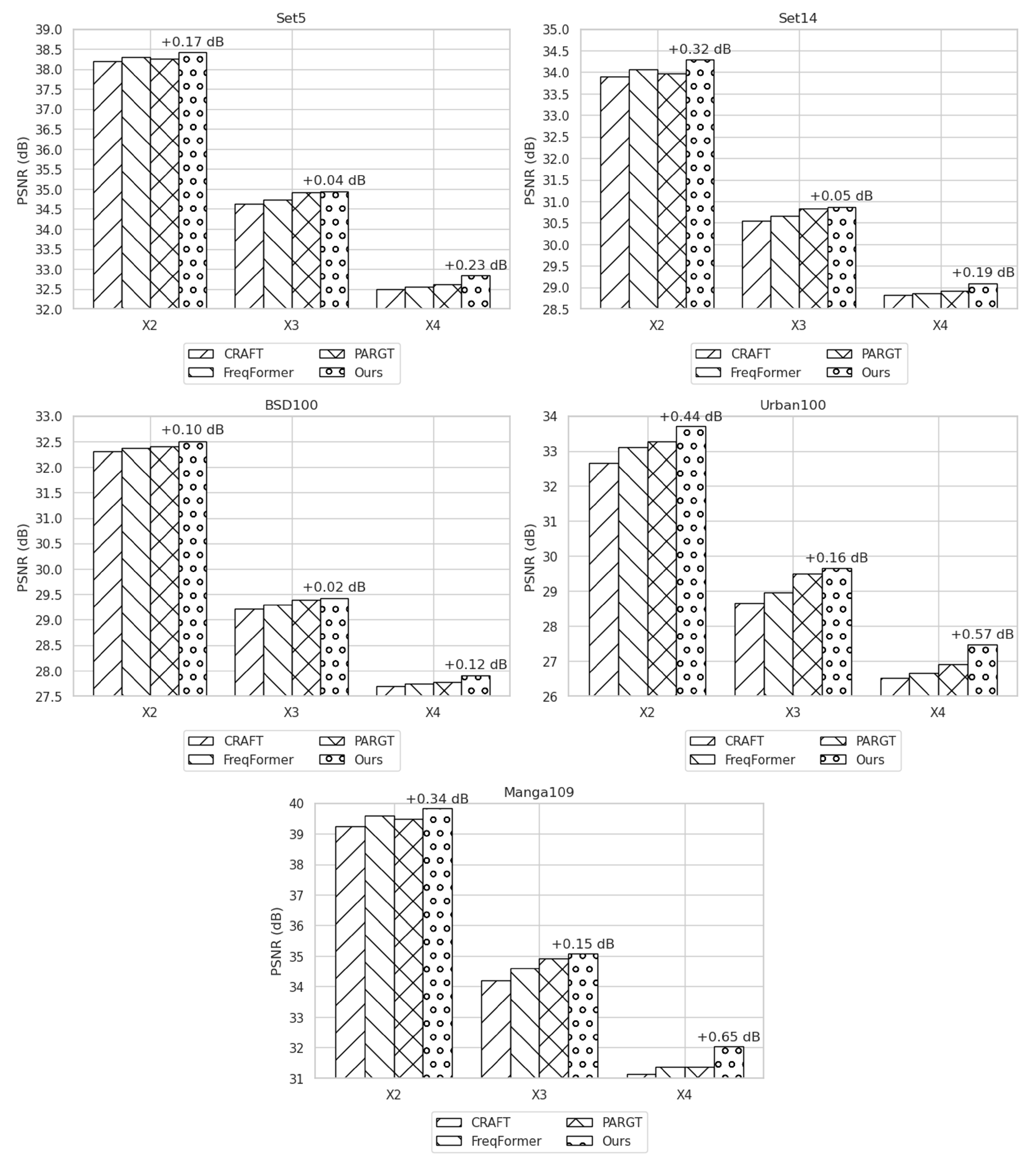
4.2. Comparison Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Hardware Implementation Feasibility

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | #Params | #Multi-Adds. | Inference Time |
|---|---|---|---|
| HFBlock | 17.21 M | 271.86 G | − |
| LFBlock | 9.61 M | 154.08 G | − |
| FFM | 3.16 M | 51.84 G | − |
| Other Layer | 1.76 M | 53.99 G | − |
| Total | 31.74 M | 531.77 G | 78.07 ms |
References
- Neshatavar, R.; Yavartanoo, M.; Son, S.; Lee, K.M. Icf-srsr: Invertible scale-conditional function for self-supervised real-world single image super-resolution. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2024; pp. 1557–1567. [Google Scholar]
- Yao, J.E.; Tsao, L.Y.; Lo, Y.C.; Tseng, R.; Chang, C.C.; Lee, C.Y. Local implicit normalizing flow for arbitrary-scale image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1776–1785. [Google Scholar]
- Al-Mekhlafi, H.; Liu, S. Single image super-resolution: A comprehensive review and recent insight. Front. Comput. Sci. 2024, 18, 181702. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Shi, G.; Chen, X.; Qiao, Y.; Zhang, X.; Wu, X.M.; Dong, C. Real-world image super-resolution as multi-task learning. Adv. Neural Inf. Process. Syst. 2023, 36, 21003–21022. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montréal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22367–22377. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Jiang, L.; Dai, B.; Wu, W.; Loy, C.C. Focal frequency loss for image reconstruction and synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montréal, ON, Canada, 11–17 October 2021; pp. 13919–13929. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Jiang, J.; Yu, Y.; Wang, Z.; Tang, S.; Hu, R.; Ma, J. Ensemble super-resolution with a reference dataset. IEEE Trans. Cybern. 2019, 50, 4694–4708. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, H.; Yuan, Z.; Wang, C. Unsupervised real-world super-resolution: A domain adaptation perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montréal, BC, Canada, 11–17 October 2021; pp. 4318–4327. [Google Scholar]
- Kimura, M. Understanding test-time augmentation. In Proceedings of the International Conference on Neural Information Processing, Bali, Indonesia, 8–12 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 558–569. [Google Scholar]
- Kong, L.; Dong, J.; Ge, J.; Li, M.; Pan, J. Efficient frequency domain-based transformers for high-quality image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18—22 June 2023; pp. 5886–5895. [Google Scholar]
- Xiang, S.; Liang, Q. Remote sensing image compression based on high-frequency and low-frequency components. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Dumitrescu, D.; Boiangiu, C.A. A study of image upsampling and downsampling filters. Computers 2019, 8, 30. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Li, Z.; Zhao, X.; Zhao, C.; Tang, M.; Wang, J. Transfering low-frequency features for domain adaptation. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Oh, Y.; Park, G.Y.; Cho, N.I. Restoration of high-frequency components in under display camera images. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; pp. 1040–1046. [Google Scholar]
- Xie, Z.; Wang, S.; Yu, Q.; Tan, X.; Xie, Y. CSFwinformer: Cross-space-frequency window transformer for mirror detection. IEEE Trans. Image Process. 2024, 33, 1853–1867. [Google Scholar] [CrossRef]
- Deng, X.; Yang, R.; Xu, M.; Dragotti, P.L. Wavelet domain style transfer for an effective perception-distortion tradeoff in single image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3076–3085. [Google Scholar]
- Wang, X. Interpolation and sharpening for image upsampling. In Proceedings of the 2022 2nd International Conference on Computer Graphics, Image and Virtualization (ICCGIV), Chongqing, China, 23–25 September 2022; pp. 73–77. [Google Scholar]
- Jahnavi, M.; Rao, D.R.; Sujatha, A. A comparative study of super-resolution interpolation techniques: Insights for selecting the most appropriate method. Procedia Comput. Sci. 2024, 233, 504–517. [Google Scholar] [CrossRef]
- Panda, J.; Meher, S. A new residual image sharpening scheme for image up-sampling. In Proceedings of the 2022 8th International Conference on Signal Processing and Communication (ICSC), Bangalore, India, 11–15 July 2022; pp. 244–249. [Google Scholar]
- Panda, J.; Meher, S. Recent advances in 2d image upscaling: A comprehensive review. SN Comput. Sci. 2024, 5, 735. [Google Scholar] [CrossRef]
- Witwit, W.; Hallawi, H.; Zhao, Y. Enhancement for Astronomical Low-Resolution Images Using Discrete-Stationary Wavelet Transforms and New Edge-Directed Interpolation. Trait. Signal 2025, 42, 11. [Google Scholar] [CrossRef]
- Liu, Z.S.; Wang, Z.; Jia, Z. Arbitrary point cloud upsampling via dual back-projection network. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 1470–1474. [Google Scholar]
- Liu, Y.; Pang, Y.; Li, J.; Chen, Y.; Yap, P.T. Architecture-Agnostic Untrained Network Priors for Image Reconstruction with Frequency Regularization. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 341–358. [Google Scholar]
- Li, A.; Zhang, L.; Liu, Y.; Zhu, C. Feature modulation transformer: Cross-refinement of global representation via high-frequency prior for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 12514–12524. [Google Scholar]
- Dai, T.; Wang, J.; Guo, H.; Li, J.; Wang, J.; Zhu, Z. FreqFormer: Frequency-aware transformer for lightweight image super-resolution. In Proceedings of the International Joint Conference on Artificial Intelligence, Jeju Island, Republic of Korea, 3–9 August 2024; pp. 731–739. [Google Scholar]
- Wang, J.; Hao, Y.; Bai, H.; Yan, L. Parallel attention recursive generalization transformer for image super-resolution. Sci. Rep. 2025, 15, 8669. [Google Scholar] [CrossRef] [PubMed]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar]
- Schulter, S.; Leistner, C.; Bischof, H. Fast and accurate image upscaling with super-resolution forests. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3791–3799. [Google Scholar]
- Li, H.; Lam, K.M.; Wang, M. Image super-resolution via feature-augmented random forest. Signal Process. Image Commun. 2019, 72, 25–34. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 6–8 December 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3867–3876. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11065–11074. [Google Scholar]
- Zhang, Y.; Wei, D.; Qin, C.; Wang, H.; Pfister, H.; Fu, Y. Context reasoning attention network for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montréal, BC, Canada, 11–17 October 2021; pp. 4278–4287. [Google Scholar]
- Zhou, L.; Cai, H.; Gu, J.; Li, Z.; Liu, Y.; Chen, X.; Qiao, Y.; Dong, C. Efficient image super-resolution using vast-receptive-field attention. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany; pp. 256–272. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 723–731. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Luo, X.; Xie, Y.; Zhang, Y.; Qu, Y.; Li, C.; Fu, Y. Latticenet: Towards lightweight image super-resolution with lattice block. In Proceedings of the Computer Vision—ECCV 2020: 16th European conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXII 16. pp. 272–289. [Google Scholar]
- Zhang, Y.; Wang, H.; Qin, C.; Fu, Y. Learning efficient image super-resolution networks via structure-regularized pruning. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Zhang, Y.; Wang, H.; Qin, C.; Fu, Y. Aligned structured sparsity learning for efficient image super-resolution. Adv. Neural Inf. Process. Syst. 2021, 34, 2695–2706. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Rakotonirina, N.C.; Rasoanaivo, A. ESRGAN+: Further improving enhanced super-resolution generative adversarial network. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–9 May 2020; pp. 3637–3641. [Google Scholar]
- Chan, K.C.; Xu, X.; Wang, X.; Gu, J.; Loy, C.C. GLEAN: Generative latent bank for image super-resolution and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3154–3168. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhao, S. Generative adversarial network-based image super-resolution with a novel quality loss. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar]
- Kuznedelev, D.; Startsev, V.; Shlenskii, D.; Kastryulin, S. Does Diffusion Beat GAN in Image Super Resolution? arXiv 2024, arXiv:2405.17261. [Google Scholar] [CrossRef]
- Mahapatra, D.; Bozorgtabar, B.; Garnavi, R. Image super-resolution using progressive generative adversarial networks for medical image analysis. Comput. Med. Imaging Graph. 2019, 71, 30–39. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12299–12310. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 457–466. [Google Scholar]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 649–667. [Google Scholar]
- Li, W.; Lu, X.; Qian, S.; Lu, J. On efficient transformer-based image pre-training for low-level vision. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, Macao, China, 19–25 August 2023; pp. 1089–1097. [Google Scholar]
- Chen, Z.; Zhang, Y.; Gu, J.; Kong, L.; Yang, X.; Yu, F. Dual aggregation transformer for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 12312–12321. [Google Scholar]
- Chen, Z.; Zhang, Y.; Gu, J.; Kong, L.; Yuan, X. Cross aggregation transformer for image restoration. Adv. Neural Inf. Process. Syst. 2022, 35, 25478–25490. [Google Scholar]
- Ruan, J.; Gao, J.; Xie, M.; Xiang, S. Learning multi-axis representation in frequency domain for medical image segmentation. Mach. Learn. 2025, 114, 10. [Google Scholar] [CrossRef]
- Zhong, Y.; Li, B.; Tang, L.; Kuang, S.; Wu, S.; Ding, S. Detecting camouflaged object in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 4504–4513. [Google Scholar]
- Park, N.; Kim, S. How Do Vision Transformers Work? In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Wang, P.; Zheng, W.; Chen, T.; Wang, Z. Anti-Oversmoothing in Deep Vision Transformers via the Fourier Domain Analysis: From Theory to Practice. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montréal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef]
- Abello, A.A.; Hirata, R.; Wang, Z. Dissecting the high-frequency bias in convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 863–871. [Google Scholar]
- Wang, H.; Wu, X.; Huang, Z.; Xing, E.P. High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 8684–8694. [Google Scholar]
- Zhao, X.; Huang, P.; Shu, X. Wavelet-Attention CNN for image classification. Multimed. Syst. 2022, 28, 915–924. [Google Scholar] [CrossRef]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference, Guildford, UK, 3–7 September 2012; pp. 135.1–135.10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the Curves and Surfaces: 7th International Conference, Avignon, France, 24–30 June 2010; Revised Selected Papers 7. pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]


| Symbol | Name | Description |
|---|---|---|
| Low-Resolution Image | Input Low-Resolution Image | |
| High-Resolution Image | Ground-Truth HR Image | |
| Reconstructed HR Image | Restored High-Resolution Image | |
| SWT Decomposition | Stationary Wavelet Transform Decomposition | |
| SWT Reconstruction | Stationary Wavelet Transform Reconstruction | |
| Convolution | Convolution | |
| concat | Combine Multiple Feature Maps | |
| Network Parameters | DFAN Full Learning Parameters Set | |
| Spatial Loss | Pixel Reconstruction L1 Loss | |
| Frequency Loss | Frequency Reconfiguration Loss | |
| Total Loss | + |
| Dataset | Images | Image Size | Description | Usage |
|---|---|---|---|---|
| DIV2K [83] | 800 | 2K () | high quality natural images | Train |
| Flickr2K [84] | 2650 | 2K () | high-resolution from Flickr | Train |
| Set5 [85] | 5 | five iconic images | Test | |
| Set14 [86] | 14 | natural images of mixed | Test | |
| BSD100 [87] | 100 | varied indoor and outdoor | Test | |
| Urban100 [88] | 100 | urban-scene in building | Test | |
| Manga109 [89] | 109 | high-resolution manga pages | Test |
| Component | Setting | Notes |
|---|---|---|
| DFAN Groups | 6 | - |
| LF Blocks per Group | 6 | Total 36 |
| HF Blocks per Group | 1 | Total 6 |
| FFM per Group | 1 | Total 6 |
| Embedding dimension | 180 | Channels |
| Self-attention heads | 6 | - |
| Window size | - | |
| Input size | Random Rotation and Flip | |
| Batch size | 4 | - |
| Iterations | 500 K | learning-rate decay schedule below |
| Initial learning rate | halved at [250 K, 400 K, 450 K, 475 K] | |
| Optimizer | Adam | , |
| Method | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| CRAFT (2023) | 38.2070 | 33.9034 | 32.2995 | 32.6665 | 39.2395 | |
| FreqFormer (2024) | 38.2925 | 34.0676 | 32.3750 | 33.1099 | 39.5769 | |
| PARGT (2025) | 38.2500 | 33.9664 | 32.3943 | 33.2595 | 39.4927 | |
| Ours | 38.4202 | 34.2870 | 32.4971 | 33.7021 | 39.8351 | |
| CRAFT (2023) | 34.6276 | 30.5380 | 29.2228 | 28.6541 | 34.2061 | |
| FreqFormer (2024) | 34.7365 | 30.6560 | 29.3017 | 28.9503 | 34.5858 | |
| PARGT (2025) | 34.9097 | 30.8217 | 29.3973 | 29.5021 | 34.9208 | |
| Ours | 34.9471 | 30.8670 | 29.4218 | 29.6650 | 35.0757 | |
| CRAFT (2023) | 32.4914 | 28.8153 | 27.6962 | 26.5213 | 31.1378 | |
| FreqFormer (2024) | 32.5532 | 28.8654 | 27.7469 | 26.6441 | 31.3610 | |
| PARGT (2025) | 32.6064 | 28.9114 | 27.7797 | 26.9051 | 31.3785 | |
| Ours | 32.8318 | 29.0985 | 27.8968 | 27.4800 | 32.0279 |
| Method | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| CRAFT (2023) | 0.9613 | 0.9207 | 0.9012 | 0.9330 | 0.9783 | |
| FreqFormer (2024) | 0.9615 | 0.9218 | 0.9022 | 0.9366 | 0.9791 | |
| PARGT (2025) | 0.9615 | 0.9207 | 0.9023 | 0.9384 | 0.9789 | |
| Ours | 0.9621 | 0.9232 | 0.9036 | 0.9414 | 0.9797 | |
| CRAFT (2023) | 0.9290 | 0.8455 | 0.8086 | 0.8617 | 0.9484 | |
| FreqFormer (2024) | 0.9299 | 0.8474 | 0.8103 | 0.8678 | 0.9502 | |
| PARGT (2025) | 0.9311 | 0.8505 | 0.8128 | 0.8774 | 0.9522 | |
| Ours | 0.9317 | 0.8519 | 0.8133 | 0.8803 | 0.9529 | |
| CRAFT (2023) | 0.8987 | 0.7866 | 0.7411 | 0.7984 | 0.9163 | |
| FreqFormer (2024) | 0.8990 | 0.7880 | 0.7428 | 0.8041 | 0.9178 | |
| PARGT (2025) | 0.9002 | 0.7892 | 0.7444 | 0.8110 | 0.9188 | |
| Ours | 0.9025 | 0.7934 | 0.7472 | 0.8242 | 0.9246 |
| Method | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| CRAFT (2023) | 0.1691 | 0.2834 | 0.3630 | 0.2218 | 0.1412 | |
| FreqFormer (2024) | 0.0562 | 0.1369 | 0.1403 | 0.0564 | 0.0227 | |
| PARGT (2025) | 0.0539 | 0.1356 | 0.1383 | 0.0544 | 0.0223 | |
| Ours | 0.0530 | 0.0866 | 0.1354 | 0.0504 | 0.0214 | |
| CRAFT (2023) | 0.1255 | 0.2476 | 0.2765 | 0.1522 | 0.0824 | |
| FreqFormer (2024) | 0.1261 | 0.2528 | 0.2766 | 0.1494 | 0.0821 | |
| PARGT (2025) | 0.1223 | 0.2460 | 0.2705 | 0.1371 | 0.0794 | |
| Ours | 0.1211 | 0.2052 | 0.2697 | 0.1340 | 0.0798 | |
| CRAFT (2023) | 0.1702 | 0.3212 | 0.3643 | 0.2234 | 0.1416 | |
| FreqFormer (2024) | 0.1697 | 0.3206 | 0.3649 | 0.2223 | 0.1408 | |
| PARGT (2025) | 0.1662 | 0.3139 | 0.3572 | 0.2123 | 0.1389 | |
| Ours | 0.1651 | 0.3104 | 0.3566 | 0.1990 | 0.1364 |
| Baseline | |||||
|---|---|---|---|---|---|
| Frequency Loss | ✓ | ✓ | ✓ | X | ✓ |
| HF Block | X | ✓ | X | ✓ | ✓ |
| FFM | X | X | ✓ | ✓ | ✓ |
| PSNR | 33.9047 | 33.7059 | 34.1688 | 34.1484 | 34.2870 |
| Size | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|
| 38.3089 | 34.1270 | 32.4394 | 33.2871 | 39.6650 | |
| 38.4202 | 34.2870 | 32.4971 | 33.7021 | 39.8351 |
| Weight | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|
| 38.3649 | 34.1117 | 32.4640 | 33.3974 | 39.7731 | |
| 38.3748 | 34.2116 | 32.4623 | 33.4187 | 39.8063 | |
| 38.3984 | 34.1451 | 32.4790 | 33.4569 | 39.8424 | |
| 38.4202 | 34.2870 | 32.4971 | 33.7021 | 39.8351 |
| Kernel Size | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|
| 38.2807 | 34.0165 | 32.4096 | 33.0728 | 39.5516 | |
| learnable kernel | 38.1856 | 33.8996 | 32.3276 | 32.5924 | 39.3014 |
| Ours | 38.2955 | 34.1280 | 32.4230 | 33.1009 | 39.5852 |
| Method | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| SwinIR (2021) | 38.3439 | 34.2175 | 32.4669 | 33.5044 | 39.6978 | |
| HAT (2023) | 38.4153 | 34.3592 | 32.4911 | 33.7949 | 39.8079 | |
| Ours | 38.4202 | 34.2870 | 32.4971 | 33.7021 | 39.8351 | |
| SwinIR (2021) | 34.8726 | 30.7984 | 29.3661 | 29.3223 | 34.8562 | |
| HAT (2023) | 34.9408 | 30.8853 | 29.4215 | 29.6555 | 35.0874 | |
| Ours | 34.9471 | 30.8670 | 29.4218 | 29.6650 | 35.0757 | |
| SwinIR (2021) | 32.6939 | 29.0052 | 27.8341 | 27.0502 | 31.7022 | |
| HAT (2023) | 32.7838 | 29.0747 | 27.8862 | 27.4110 | 31.9933 | |
| Ours | 32.8318 | 29.0985 | 27.8968 | 27.4800 | 32.0279 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, G.-I.; Lee, J. DFAN: Single Image Super-Resolution Using Stationary Wavelet-Based Dual Frequency Adaptation Network. Symmetry 2025, 17, 1175. https://doi.org/10.3390/sym17081175
Kim G-I, Lee J. DFAN: Single Image Super-Resolution Using Stationary Wavelet-Based Dual Frequency Adaptation Network. Symmetry. 2025; 17(8):1175. https://doi.org/10.3390/sym17081175
Chicago/Turabian StyleKim, Gyu-Il, and Jaesung Lee. 2025. "DFAN: Single Image Super-Resolution Using Stationary Wavelet-Based Dual Frequency Adaptation Network" Symmetry 17, no. 8: 1175. https://doi.org/10.3390/sym17081175
APA StyleKim, G.-I., & Lee, J. (2025). DFAN: Single Image Super-Resolution Using Stationary Wavelet-Based Dual Frequency Adaptation Network. Symmetry, 17(8), 1175. https://doi.org/10.3390/sym17081175