
A Malicious URL Detection Framework Based on Custom Hybrid Spatial Sequence Attention and Logic Constraint Neural Network

 ,
,
Abstract
1. Introduction
- (1)
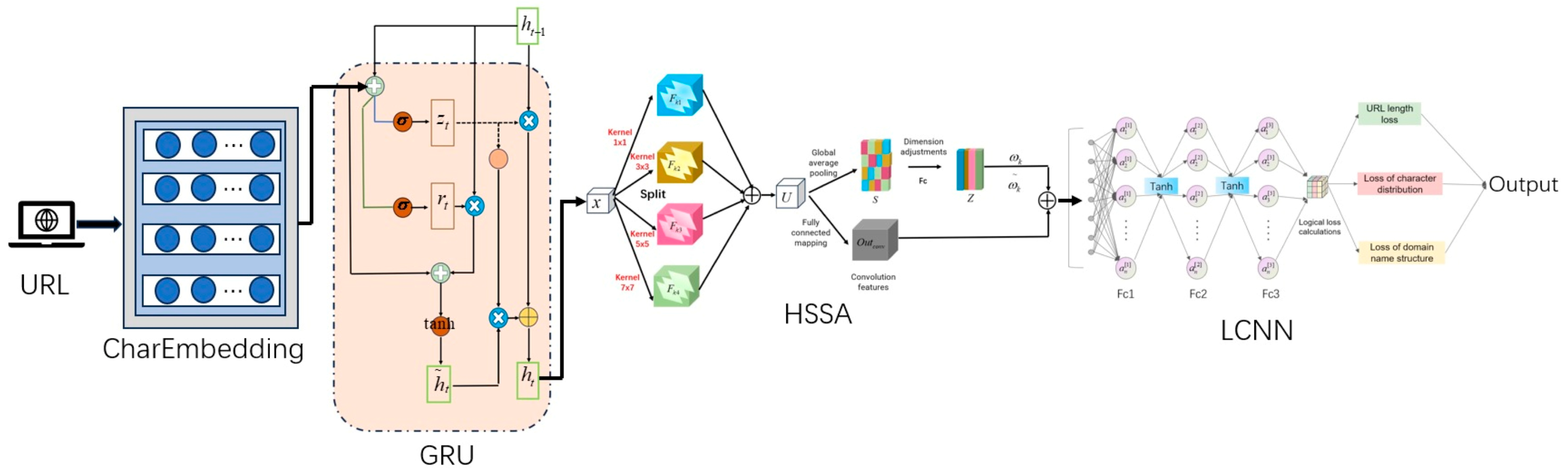
- The HSSA module in HSSLC-CharGRU uses multi-scale convolution to capture local features of different scales and models long-range dependencies in sequences via multi-head self-attention. This combination enables the model to process local and global information simultaneously, enhancing its ability to model complex patterns.
- (2)
- HSSLC-CharGRU includes an LCNN to ensure that its output is consistent with the actual business logic. Logic constraint loss enforces hard constraints on the model’s outputs to ensure that they reflect URL length, character distribution, and domain structure characteristics, improving the model’s detection performance in the face of complex malicious URL data.
- (3)
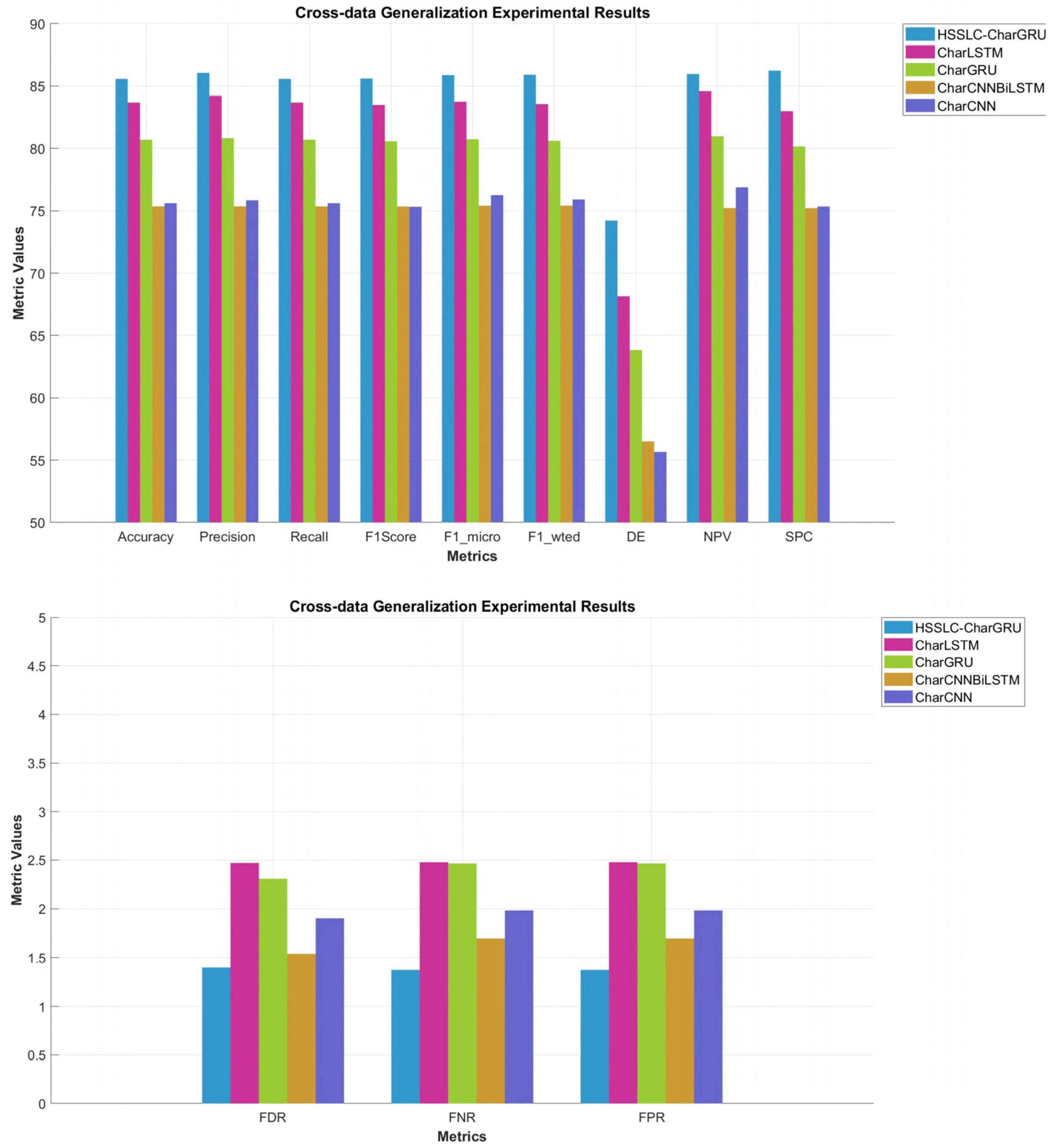
- Cross-dataset generalization tests show that HSSLC-CharGRU has strong generalization and robustness when facing complex malicious URL data across dataset boundaries.
2. Related Work
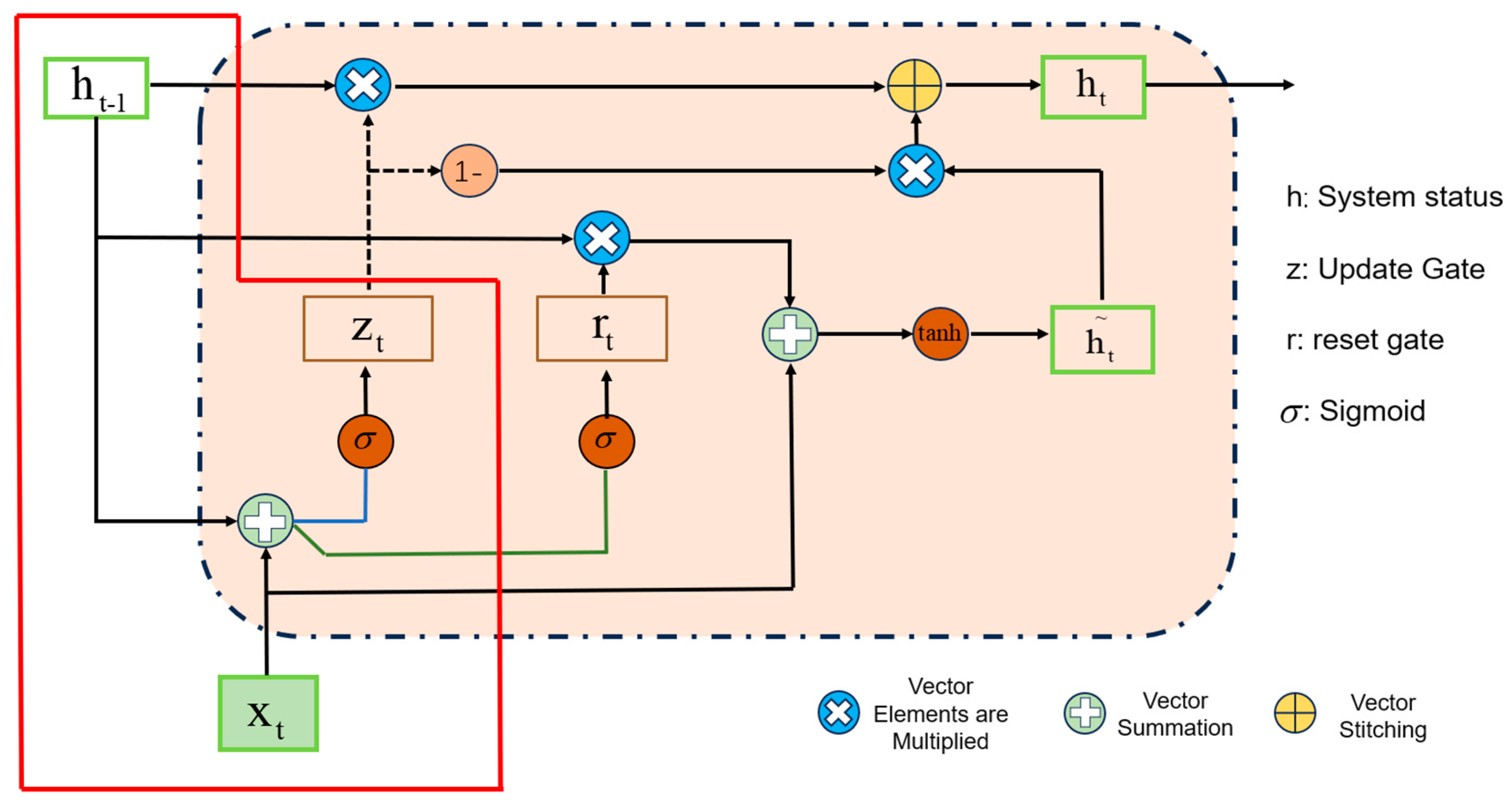
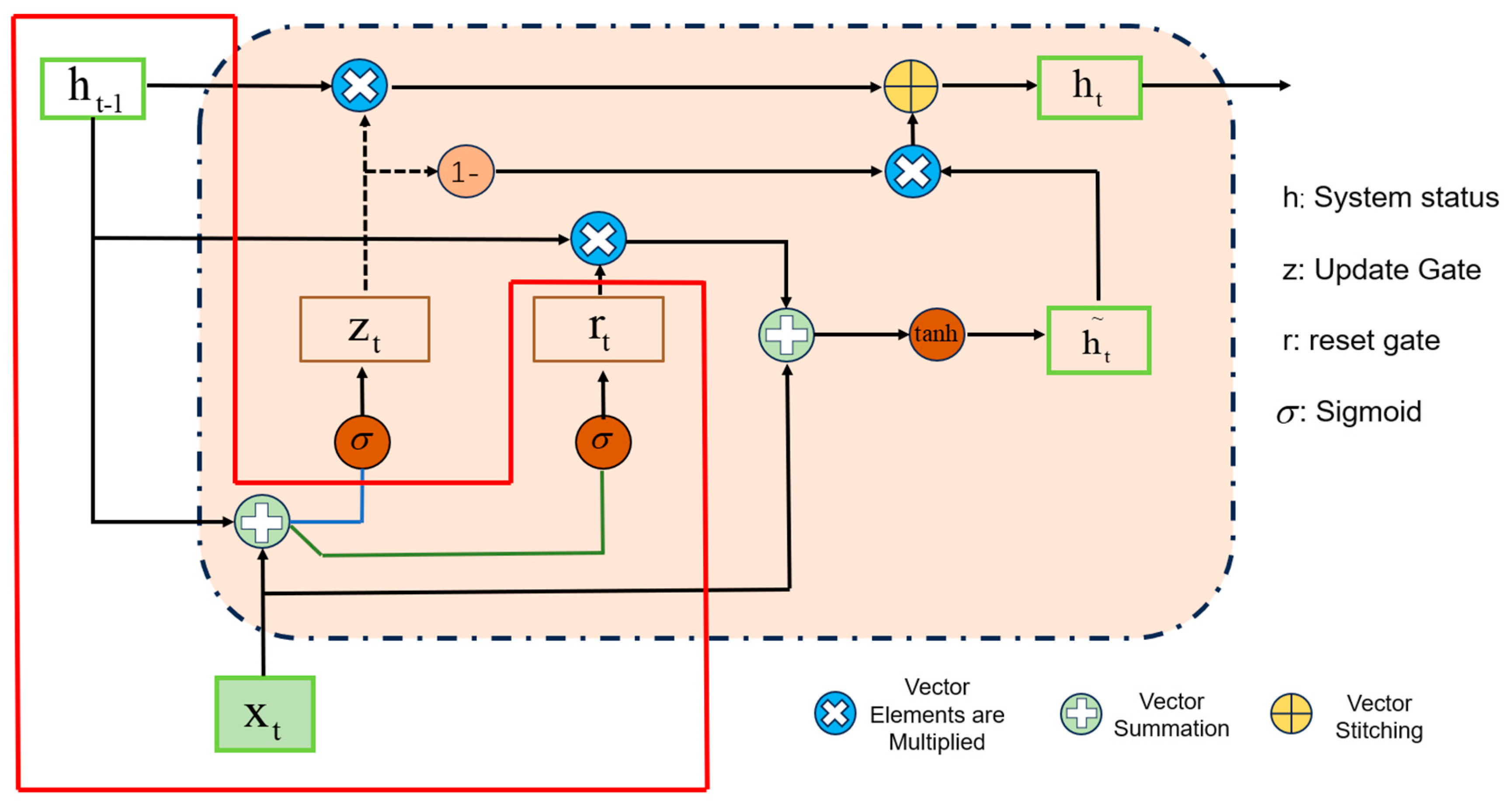
2.1. Gated Recurrent Unit
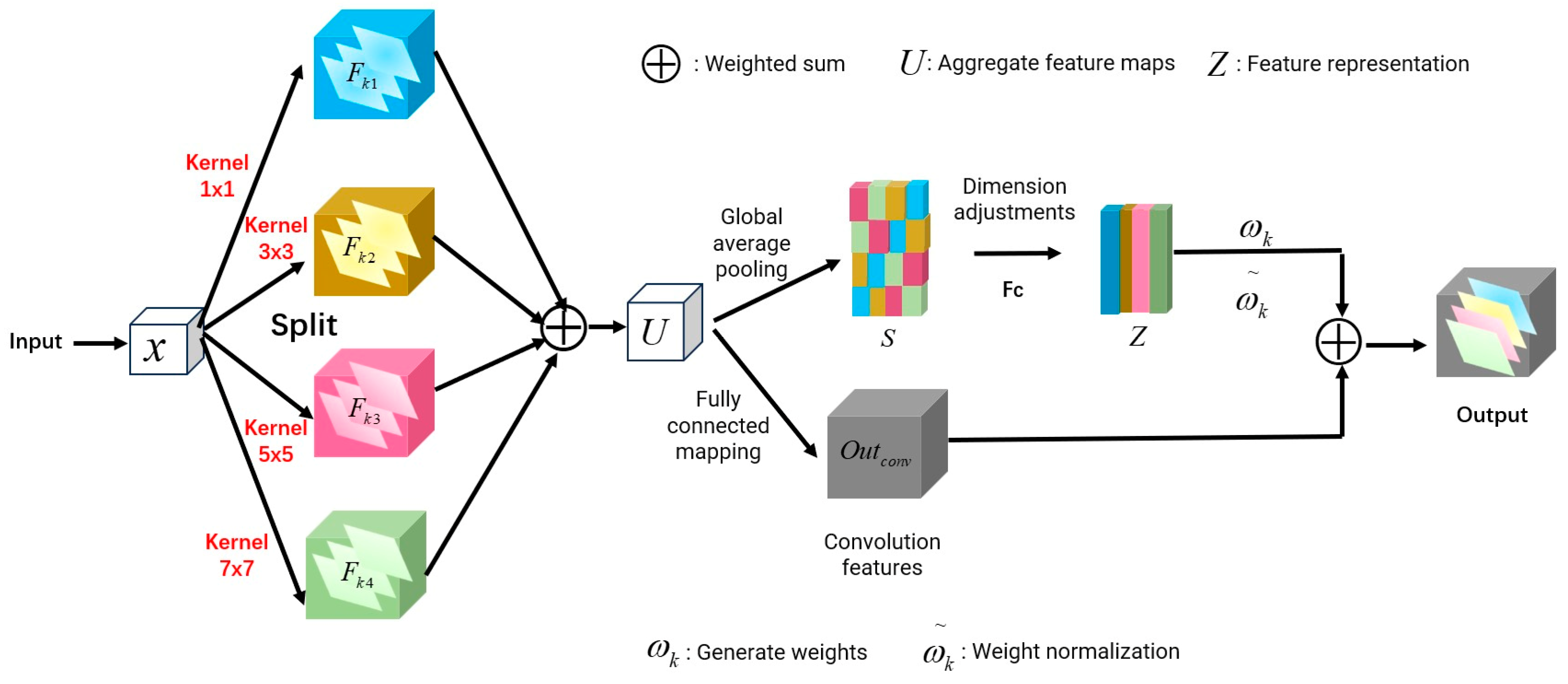
2.2. Hybrid Spatial–Sequential Attention
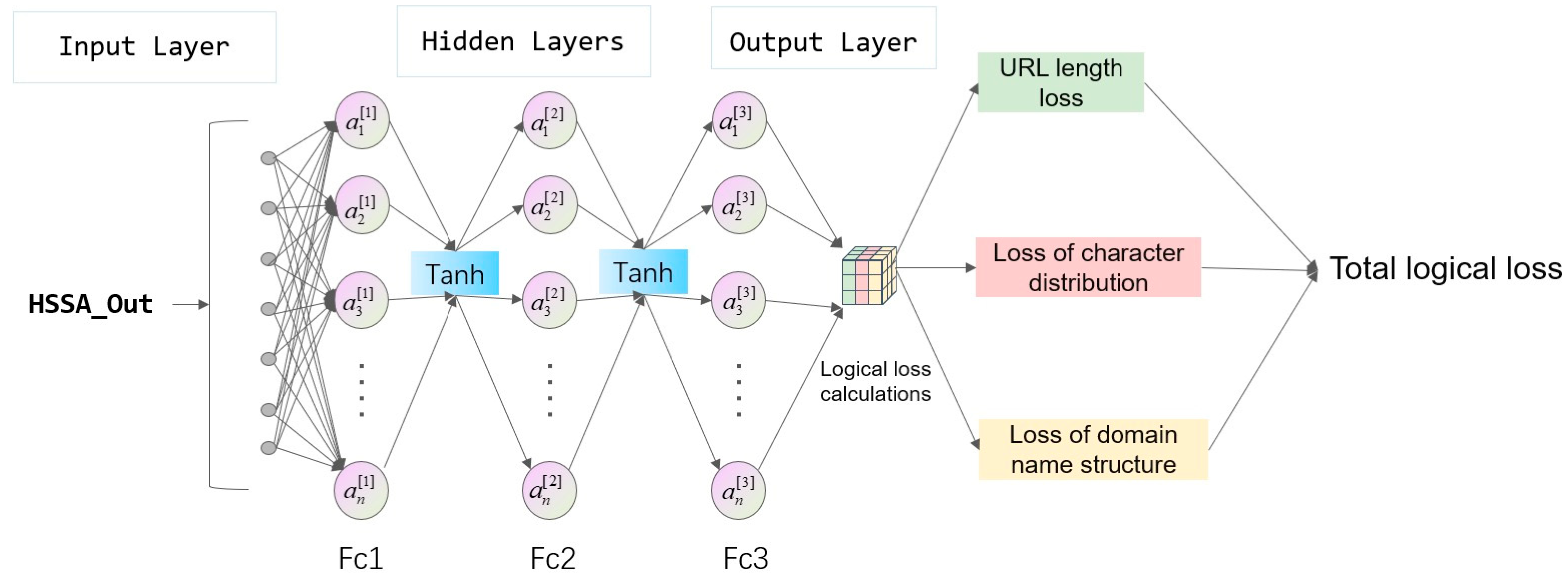
2.3. Logically Constrained Neural Network
3. Methodology
4. Experimental Results and Analysis
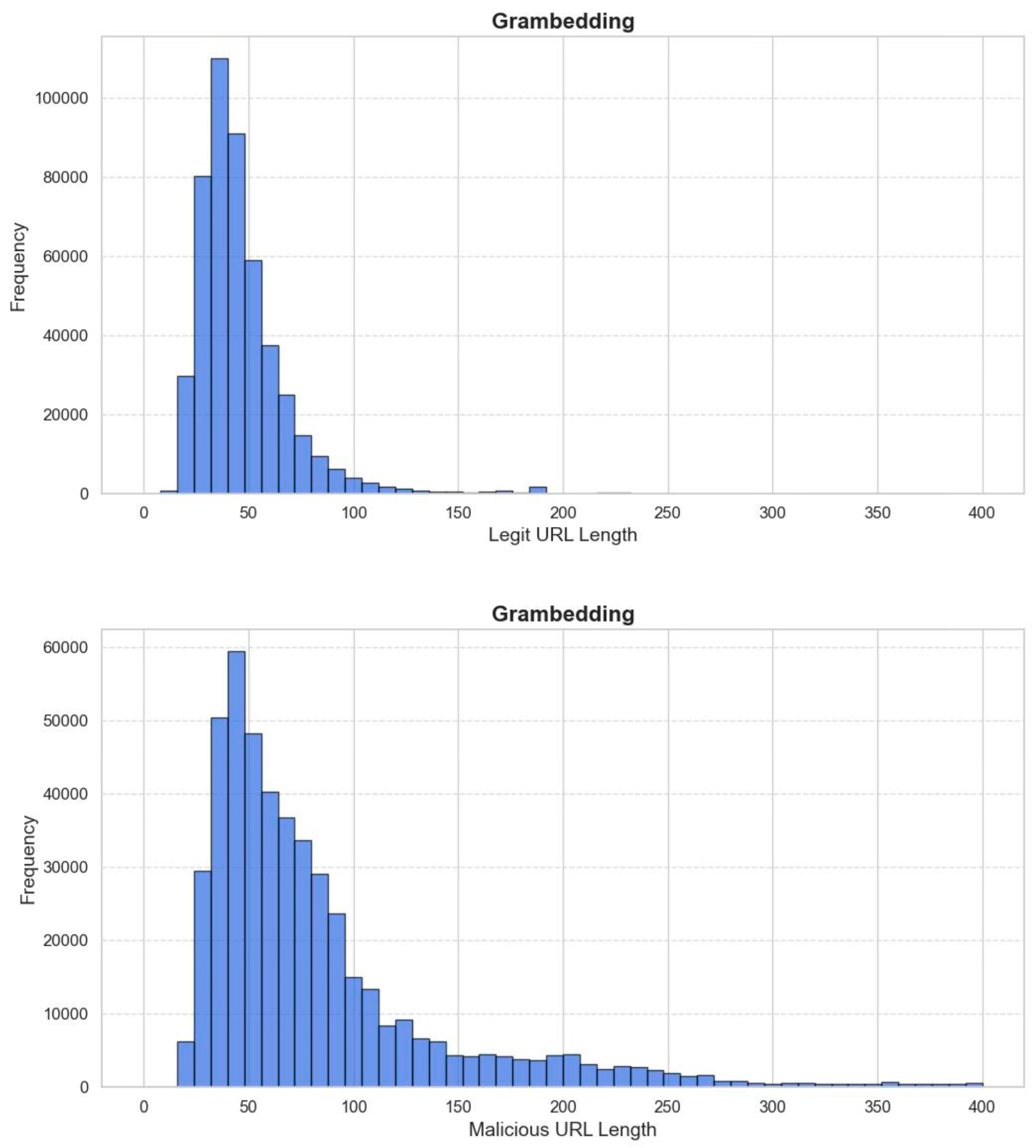
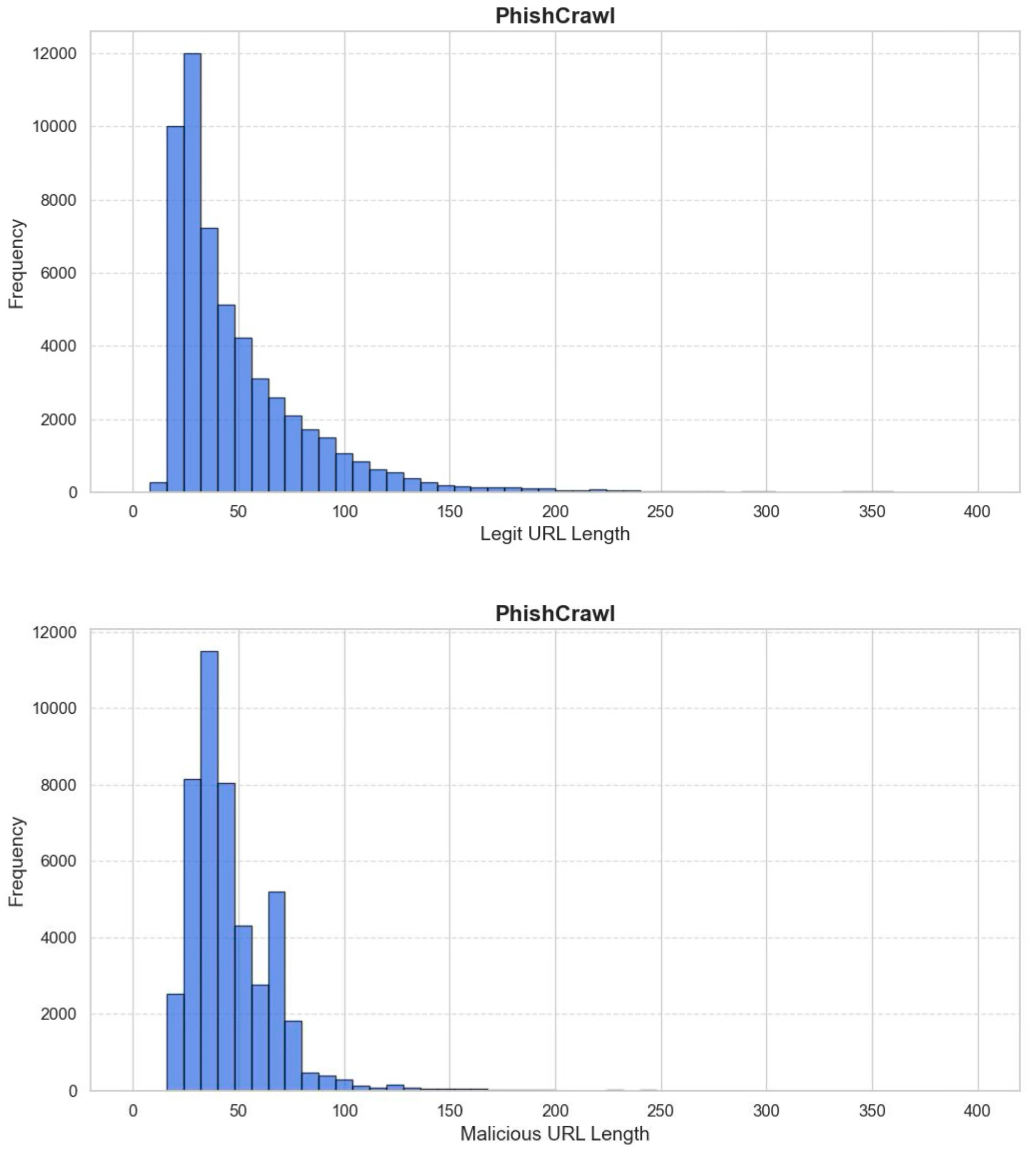
4.1. Datasets
4.2. Compare Models and Evaluation Metrics
- CharGRU: A character-level GRU network.
- CharLSTM: A character-level LSTM (Long Short-Term Memory, LSTM) network.
- CharCNN: A character-level CNN (Convolutional Neural Networks, CNN) that uses convolutional kernels of sizes 3, 4, and 5, followed by a dropout layer and a fully connected layer.
- CharCNNBiLSTM: This model combines a character-level CNN with a BiLSTM network. Features are extracted from the embedding layer using the CNN and then passed to the BiLSTM for further processing.
4.3. Experimental Setup and Results
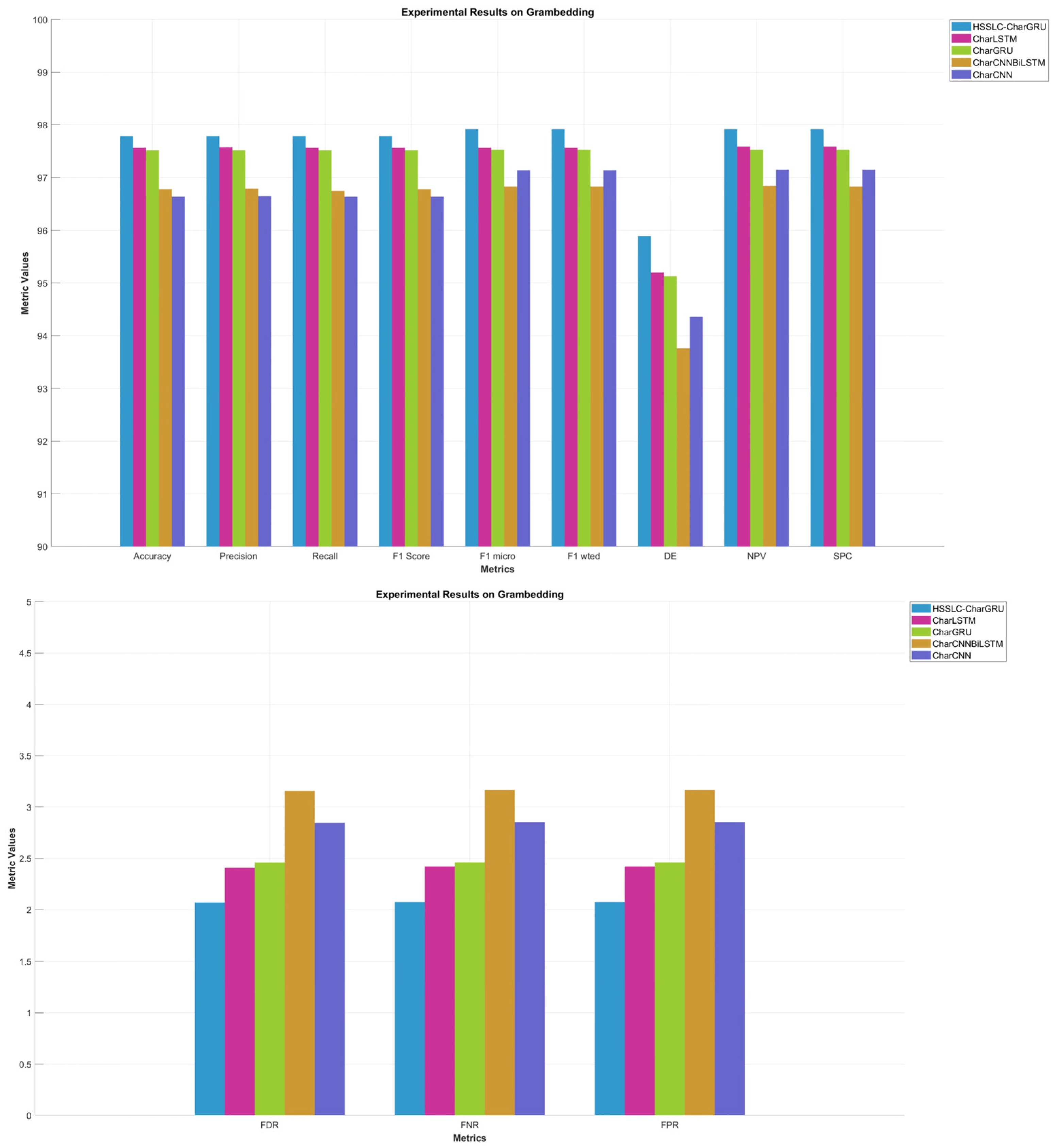
4.3.1. Comparative Experiments and Results
4.3.2. Generalization Experiments Across Datasets
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Proofpoint. State of the Phish 2024: Today’s Cyber Threats and Phishing Protection; Proofpoint Inc.: Sunnyvale, CA, USA, 2024. [Google Scholar]
- Shirazi, H.; Muramudalige, S.R.; Ray, I.; Jayasumana, A.P.; Wang, H. Adversarial autoencoder data synthesis for enhancing machine learning-based phishing detection algorithms. IEEE Trans. Serv. Comput. 2023, 16, 2411–2422. [Google Scholar] [CrossRef]
- Zhu, E.; Yuan, Q.; Chen, Z.; Li, X.; Fang, X. CCBLA: A lightweight phishing detection model based on CNN, BiLSTM, and attention mechanism. Cogn. Comput. 2023, 15, 1320–1333. [Google Scholar] [CrossRef]
- Tsai, Y.D.; Liow, C.; Siang, Y.S.; Lin, S.D. Toward more generalized malicious url detection models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 24 February 2024; Volume 38, pp. 21628–21636. [Google Scholar]
- Jeeva, S.C.; Rajsingh, E.B. Intelligent phishing url detection using association rule mining. Hum.-Centric Comput. Inf. Sci. 2016, 6, 1–19. [Google Scholar] [CrossRef]
- Lee, O.V.; Heryanto, A.; Ab Razak, M.F.; Raffei, A.F.M.; Phon, D.N.E.; Kasim, S.; Sutikno, T. A malicious URLs detection system using optimization and machine learning classifiers. Indones. J. Electr. Eng. Comput. Sci. 2020, 17, 1210–1214. [Google Scholar] [CrossRef]
- AlEroud, A.; Karabatis, G. Bypassing detection of URL-based phishing attacks using generative adversarial deep neural networks. In Proceedings of the Sixth International Workshop on Security and Privacy Analytics, New Orleans, LA, USA, 18 March 2020; pp. 53–60. [Google Scholar]
- Remya, S.; Pillai, M.J.; Nair, K.K.; Subbareddy, S.R.; Cho, Y.Y. An Effective Detection Approach for Phishing URL Using ResMLP. IEEE Access 2024, 12, 79367–79382. [Google Scholar] [CrossRef]
- Islam, M.S.; Rahman, N.; Naeem, J.; Al Mamun, A.; Akter, F.; Jahan, S.; Rahman, S.; Yasar, S.; Omi, M.M.H. WebGuardML: Safeguarding Users with Malicious URL Detection Using Machine Learning. In Proceedings of the 26th International Conference on Computer and Information Technology (ICCIT), Cox’s Bazar, Bangladesh, 13–15 December 2023; IEEE: New York, NY, USA, 2023; pp. 1–6. [Google Scholar]
- Mia, M.; Derakhshan, D.; Pritom, M.M.A. Can Features for Phishing URL Detection Be Trusted Across Diverse Datasets? A Case Study with Explainable AI. In Proceedings of the 11th International Conference on Networking, Systems, and Security, Khulna, Bangladesh, 19–21 December 2024; pp. 137–145. [Google Scholar]
- Kaushik, P.; Rathore, S.P.S. Deep Learning Multi-Agent Model for Phishing Cyber-attack Detection. Int. J. Recent Innov. Trends Comput. Commun. 2023, 11, 680–686. [Google Scholar] [CrossRef]
- Su, M.Y.; Su, K.L. BERT-Based Approaches to Identifying Malicious URLs. Sensors 2023, 23, 8499. [Google Scholar] [CrossRef]
- Geyik, B.; Erensoy, K.; Kocyigit, E. Detection of phishing websites from URLs by using classification techniques on WEKA. In Proceedings of the 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; IEEE: New York, NY, USA, 2021; pp. 120–125. [Google Scholar]
- Taofeek, A.O. Development of a Novel Approach to Phishing Detection Using Machine Learning. ATBU J. Sci. Technol. Educ. 2024, 12, 336–351. [Google Scholar]
- Liang, Y.; Wang, Q.; Xiong, K.; Zheng, X.; Yu, Z.; Zeng, D. Robust detection of malicious URLs with self-paced wide & deep learning. IEEE Trans. Dependable Secur. Comput. 2021, 19, 717–730. [Google Scholar]
- Wu, T.; Wang, M.; Xi, Y.; Zhao, Z. Malicious URL detection model based on bidirectional gated recurrent unit and attention mechanism. Appl. Sci. 2022, 12, 12367. [Google Scholar] [CrossRef]
- Liu, R.; Wang, Y.; Xu, H.; Qin, Z.; Liu, Y.; Cao, Z. Malicious url detection via pretrained language model guided multi-level feature attention network. arXiv 2023, arXiv:2311.12372. [Google Scholar]
- Mahdaouy, A.E.; Lamsiyah, S.; Idrissi, M.J.; Alami, H.; Yartaoui, Z.; Berrada, I. DomURLs_BERT: Pre-trained BERT-based Model for Malicious Domains and URLs Detection and Classification. arXiv 2024, arXiv:2409.09143. [Google Scholar]
- Nowroozi, E.; Mohammadi, M.; Conti, M. An adversarial attack analysis on malicious advertisement URL detection framework. IEEE Trans. Netw. Serv. Manag. 2022, 20, 1332–1344. [Google Scholar] [CrossRef]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv 2018, arXiv:1802.03162. [Google Scholar]
- Wei, W.; Ke, Q.; Nowak, J.; Korytkowski, M.; Scherer, R.; Woźniak, M. Accurate and fast URL phishing detector: A convolutional neural network approach. Comput. Netw. 2020, 178, 107275. [Google Scholar] [CrossRef]
- Afzal, S.; Asim, M.; Javed, A.R.; Beg, M.O.; Baker, T. Urldeepdetect: A deep learning approach for detecting malicious urls using semantic vector models. J. Netw. Syst. Manag. 2021, 29, 1–27. [Google Scholar] [CrossRef]
- Wang, H.H.; Yu, L.; Tian, S.W.; Peng, Y.F.; Pei, X.J. Bidirectional LSTM Malicious webpages detection algorithm based on convolutional neural network and independent recurrent neural network. Appl. Intell. 2019, 49, 3016–3026. [Google Scholar] [CrossRef]
- Atrees, M.; Ahmad, A.; Alghanim, F. Enhancing Detection of Malicious URLs Using Boosting and Lexical Features. Intell. Autom. Soft Comput. 2022, 31, 1405. [Google Scholar] [CrossRef]
- Vanhoenshoven, F.; Nápoles, G.; Falcon, R.; Vanhoof, K.; Köppen, M. Detecting malicious URLs using machine learning techniques. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; IEEE: New York, NY, USA, 2016; pp. 1–8. [Google Scholar]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of online phishing email using dynamic evolving neural network based on reinforcement learning. Decis. Support Syst. 2018, 107, 88–102. [Google Scholar] [CrossRef]
- Khramtsova, E.; Hammerschmidt, C.; Lagraa, S.; State, R. Federated learning for cyber security: SOC collaboration for malicious URL detection. In Proceedings of the 2020 IEEE 40th Internastional Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; IEEE: New York, NY, USA, 2020; pp. 1316–1321. [Google Scholar]
- Tong, X.; Jin, B.; Wang, J.; Yang, Y.; Suo, Q.; Wu, Y. MM-ConvBERT-LMS: Detecting malicious web pages via multi-modal learning and pre-trained model. Appl. Sci. 2023, 13, 3327. [Google Scholar] [CrossRef]
- Sabir, B.; Babar, M.A.; Gaire, R.; Abuadbba, A. Reliability and robustness analysis of machine learning based phishing URL detectors. IEEE Trans. Dependable Secur. Comput. 2022; early access. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhang, K.; Wang, H.; Chen, M.; Chen, X.; Liu, L.; Geng, Q.; Zhou, Y. Leveraging machine learning to proactively identify phishing campaigns before they strike. J. Big Data. 2025, 12, 124. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, K.; Bilal, A.; Zhou, Y.; Fan, Y.; Pan, W.; Peng, Q. An integrated CSPPC and BiLSTM framework for malicious URL detection. Sci. Rep. 2025, 15, 6659. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Bozkir, A.S.; Dalgic, F.C.; Aydos, M. GramBeddings: A new neural network for URL based identification of phishing web pages through n-gram embeddings. Comput. Secur. 2023, 124, 102964. [Google Scholar] [CrossRef]
- Do, N.Q.; Selamat, A.; Fujita, H.; Krejcar, O. An integrated model based on deep learning classifiers and pre-trained transformer for phishing URL detection. Future Gener. Comput. Syst. 2024, 161, 269–285. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step 1 HSSLC-CharGRU uses the model to analyze malicious URL |
|---|
| Input: Input sequence data x, optional additional information (url_lengths, url_char_distributions, domain_structures) |
| Output: Model output O (The result of the prediction of the URL) |
| 1: function HSSLC_CharGRU (vocab_size, output_size, CharEmbedding _dim, hidden_dim, n_layers, drop_prob) |
| 2: CharEmbedding <- nn. CharEmbedding (vocab_size, embedding_dim) |
| 3: GRU <- nn.GRU (CharEmbedding _dim, hidden_dim, n_layers, dropout=drop_prob, batch_first=True, bidirectional = False) |
| 4: dropout <- nn.Dropout(drop_prob) |
| 5: fc_input_size <- hidden_dim * 2 |
| 6: fc <- nn.Linear(fc_input_size, output_size) |
| 7: Hybrid Spatial-Sequential Attention <- HSSA (channel=fc_input_size, embed_dim=fc_input_size) |
| 8: LCNN <- LCNN (input_dim=fc_input_size, hidden_dim=hidden_dim, output_dim=fc_input_size) |
| 9: return Module (CharEmbedding, GRU, dropout, fc, Hybrid Spatial-Sequential Attention, LCNN) |
| 10: function forward (x, url_lengths=None, url_char_distributions=None, domain_structures=None) |
| 11: device <- x.device |
| 12: E <- CharEmbedding (x).to (device) // [batch, seq_len, CharEmbedding _dim] |
| 13: B, _ <- GRU(E) // [batch, seq_len, hidden_dim * 2] |
| 14: B <- B.permute(0, 2, 1).unsqueeze(−1) // [batch, hidden_dim * 2, seq_len, 1] |
| 15: H <- Hybrid Spatial-Sequential Attention (B) // [batch, hidden_dim * 2, seq_len, 1] |
| 16: H <- H.squeeze(−1).permute(0, 2, 1) // [batch, seq_len, hidden_dim * 2] |
| 17: P <- LCNN (H) // [batch, hidden_dim * 2, seq_len] |
| 18: O <- dropout(P) |
| 19: O <- fc O[:, −1, :]) // [batch, output_size] |
| 20: if url_lengths is not None and url_char_distributions is not None and domain_structures is not None |
| 21: logic_loss <- LCNN.compute_logic_loss (O, url_lengths, url_char_distributions, domain_structures) |
| 22: return O, logic_loss |
| 23: return O |
| Dataset | Name | Accuracy | Precision | Recall | F1Score | F1_Micro | F1_Wted | FDR | FNR | FPR | DE | NPV | SPC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grambedding | CharGRU | 97.52 | 97.52 | 97.52 | 97.52 | 97.53 | 97.52 | 2.460 | 2.461 | 2.461 | 95.13 | 97.53 | 97.53 |
| CharLSTM | 97.57 | 97.58 | 97.57 | 97.57 | 97.57 | 97.57 | 2.407 | 2.421 | 2.421 | 95.20 | 97.59 | 97.57 | |
| CharCNN | 96.64 | 96.65 | 96.64 | 96.64 | 97.14 | 97.14 | 2.846 | 2.854 | 2.854 | 94.36 | 97.15 | 97.14 | |
| CharCNNBiLSTM | 96.78 | 96.79 | 96.78 | 96.78 | 96.83 | 96.83 | 3.157 | 3.166 | 3.166 | 93.76 | 96.84 | 96.83 | |
| HSSLC-CharGRU | 97.79 | 97.79 | 97.79 | 97.79 | 97.92 | 97.92 | 2.070 | 2.075 | 2.075 | 95.89 | 97.92 | 97.92 | |
| PhishCrawl | CharGRU | 97.50 | 97.50 | 97.50 | 97.49 | 97.50 | 97.50 | 2.392 | 2.617 | 2.617 | 94.81 | 97.60 | 97.38 |
| CharLSTM | 97.17 | 97.17 | 97.17 | 97.17 | 97.24 | 97.24 | 2.725 | 2.834 | 2.834 | 94.40 | 97.27 | 97.16 | |
| CharCNN | 96.96 | 96.96 | 96.96 | 96.96 | 97.51 | 97.51 | 2.464 | 2.542 | 2.542 | 94.97 | 97.53 | 97.45 | |
| CharCNNBiLSTM | 96.74 | 96.75 | 96.74 | 96.74 | 96.89 | 96.88 | 3.056 | 3.203 | 3.203 | 93.68 | 96.94 | 96.79 | |
| HSSLC-CharGRU | 97.53 | 97.53 | 97.53 | 97.52 | 97.73 | 97.73 | 2.194 | 2.359 | 2.359 | 95.32 | 97.80 | 97.64 |
| Dataset | Name | Accuracy | Precision | Recall | F1Score | F1_Micro | F1_Wted | FDR | FNR | FPR | DE | NPV | SPC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cross-dataset | CharGRU | 80.70 | 80.83 | 80.70 | 80.57 | 80.74 | 80.61 | 1.901 | 1.983 | 1.983 | 63.83 | 80.98 | 80.16 |
| CharLSTM | 83.69 | 84.22 | 83.69 | 83.50 | 83.76 | 83.57 | 1.540 | 1.699 | 1.699 | 68.16 | 84.59 | 83.00 | |
| CharCNN | 75.61 | 75.84 | 75.61 | 75.32 | 76.26 | 75.91 | 2.310 | 2.465 | 2.465 | 55.66 | 76.89 | 75.34 | |
| CharCNNBiLSTM | 75.35 | 75.35 | 75.35 | 75.34 | 75.41 | 75.41 | 2.477 | 2.478 | 2.478 | 56.51 | 75.22 | 75.21 | |
| HSSLC-CharGRU | 85.58 | 86.06 | 85.58 | 85.61 | 85.88 | 85.91 | 1.402 | 1.375 | 1.375 | 74.21 | 85.97 | 86.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Zhang, K.; Zheng, B.; Zhou, Y.; Xie, X.; Jin, M.; Liu, X. A Malicious URL Detection Framework Based on Custom Hybrid Spatial Sequence Attention and Logic Constraint Neural Network. Symmetry 2025, 17, 987. https://doi.org/10.3390/sym17070987
Zhou J, Zhang K, Zheng B, Zhou Y, Xie X, Jin M, Liu X. A Malicious URL Detection Framework Based on Custom Hybrid Spatial Sequence Attention and Logic Constraint Neural Network. Symmetry. 2025; 17(7):987. https://doi.org/10.3390/sym17070987
Chicago/Turabian StyleZhou, Jinyang, Kun Zhang, Bing Zheng, Yu Zhou, Xin Xie, Ming Jin, and Xiling Liu. 2025. "A Malicious URL Detection Framework Based on Custom Hybrid Spatial Sequence Attention and Logic Constraint Neural Network" Symmetry 17, no. 7: 987. https://doi.org/10.3390/sym17070987
APA StyleZhou, J., Zhang, K., Zheng, B., Zhou, Y., Xie, X., Jin, M., & Liu, X. (2025). A Malicious URL Detection Framework Based on Custom Hybrid Spatial Sequence Attention and Logic Constraint Neural Network. Symmetry, 17(7), 987. https://doi.org/10.3390/sym17070987