
A Machine Learning-Based Detection for Parameter Tampering Vulnerabilities in Web Applications Using BERT Embeddings


Abstract
1. Introduction
- (1)
- We propose a novel method for detecting parameter tampering vulnerabilities by analyzing parameter–value contexts and applying manipulated inputs, thereby overcoming the limitations of conventional tools that rely on substituting predefined input patterns.
- (2)
- We construct and train a machine learning model using real-world vulnerability data, enabling the identification of similar attacks without relying on fixed rules, and we present a strategy for prioritizing high-risk parameters.
- (3)
- Our proposed methodology enables automated end-to-end vulnerability detection across entire application environments to address the difficulty of manually inspecting large-scale web applications.
2. Related Work
2.1. Research on Automated Vulnerability Detection
2.2. ML-Based Vulnerability Detection
3. Methodology
3.1. Data Collection and Preprocessing
3.2. Research Framework
| Algorithm 1: Web vulnerable parameter detection based on BERT embedding and XGBoost classifier | |
| 1: | PROCEDURE: VULNERABLE PARAMETER DETECTOR |
| 2: | Train BERT + XGBoost model using labeled parameter-value pairs; |
| 3: | |
| 4: | PROCEDURE: PREDICT VULNERABLE PARAMETERS (URL, threshold) |
| 5: | Extract parameter-value pairs from URL; |
| 6: | Initialize empty list vulnerability_predictions; |
| 7: | |
| 8: | For each parameter-value pair, do |
| 9: | Generate BERT embedding; |
| 10: | Predict vulnerability probability using a trained model; |
| 11: | If probability ≥ threshold, then |
| 12: | Retrieve suggested keywords for attack testing; |
| 13: | Add (parameter name, probability, suggested keywords) to vulnerability_predictions; |
| 14: | end if |
| 15: | end for |
| 16: | |
| 17: | For each entry in vulnerability_predictions, do |
| 18: | Print parameter name, probability, suggested keywords; |
| 19: | end for |
| 20: | |
| 21: | Return vulnerability_predictions; |
| 22: | end |
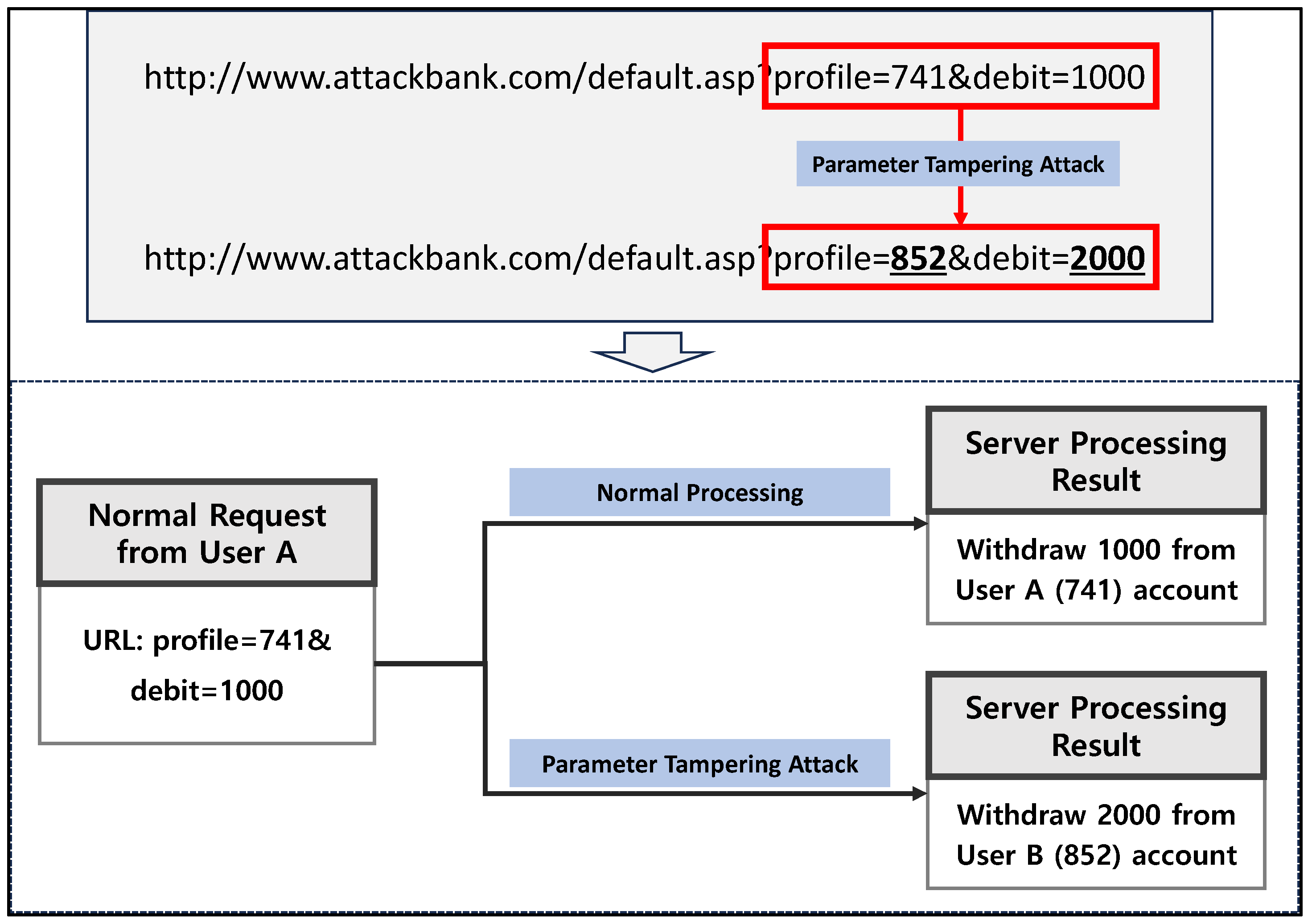
3.3. Parameter Tampering Vulnerabilities
3.4. Machine Learning Model Training and Data Processing Techniques
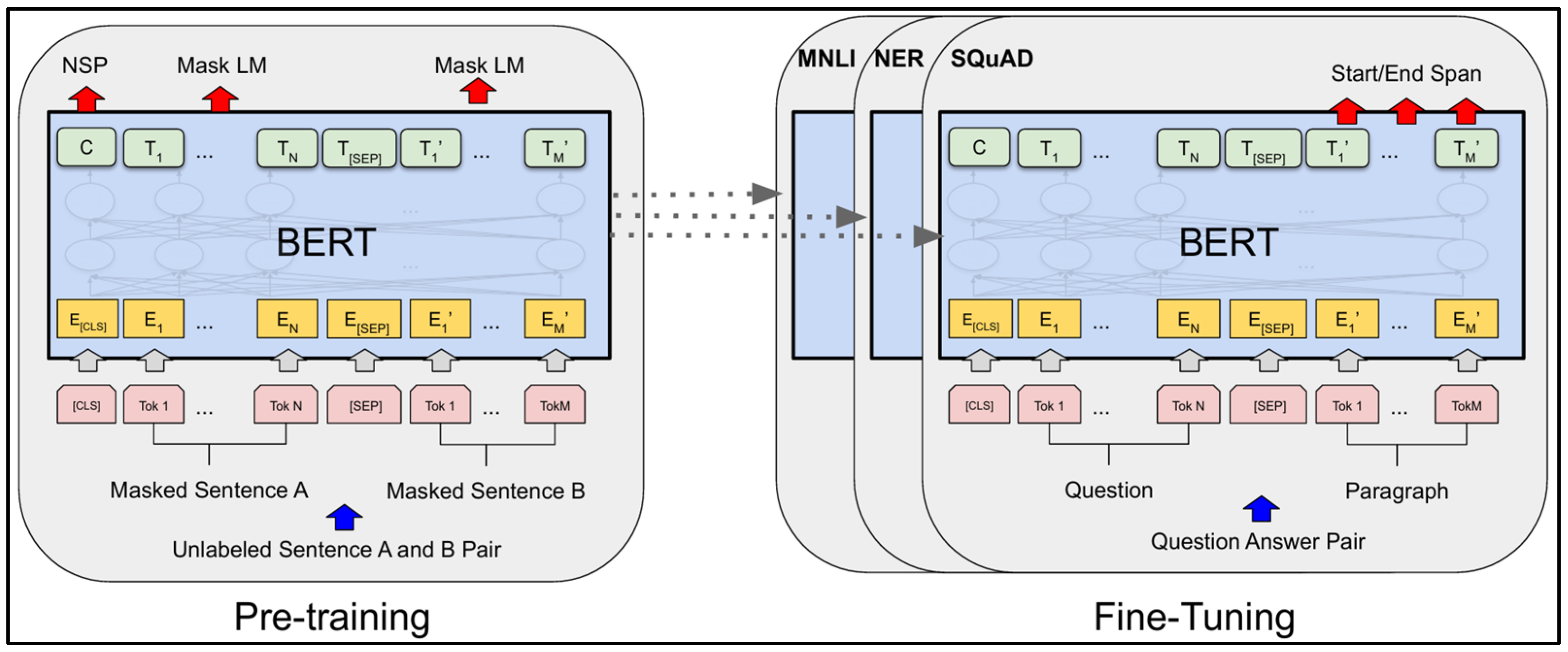
3.4.1. BERT Algorithm
3.4.2. XGBoost Algorithm
3.4.3. SMOTE
4. Results
4.1. Model Selection
4.2. Detection Results of Parameter Tampering Vulnerabilities
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Truong, T.C.; Diep, Q.B.; Zelinka, I. Artificial Intelligence in the Cyber Domain: Offense and Defense. Symmetry 2020, 12, 410. [Google Scholar] [CrossRef]
- Chen, C.; Cui, J.; Qu, G.; Zhang, J. Write+Sync: Software Cache Write Covert Channels Exploiting Memory-Disk Synchronization. IEEE Trans. Inf. Forensics Secur. 2024, 19, 8066–8078. [Google Scholar] [CrossRef]
- Sun, G.; Li, Y.; Liao, D.; Chang, V. Service Function Chain Orchestration Across Multiple Domains: A Full Mesh Aggregation Approach. IEEE Trans. Netw. Serv. Manag. 2018, 15, 1175–1191. [Google Scholar] [CrossRef]
- Sarker, I.H.; Abushark, Y.B.; Alsolami, F.; Khan, A.I. IntruDTree: A Machine Learning Based Cyber Security Intrusion Detection Model. Symmetry 2020, 12, 754. [Google Scholar] [CrossRef]
- Alhogail, A.; Alkahtani, M. Automated Extension-Based Penetration Testing for Web Vulnerabilities. Procedia Comput. Sci. 2024, 238, 15–23. [Google Scholar] [CrossRef]
- Tóth, R.; Bisztray, T.; Erdődi, L. LLMs in Web Development: Evaluating LLM-Generated PHP Code Unveiling Vulnerabilities and Limitations. In Computer Safety, Reliability, and Security. SAFECOMP 2024 Workshops; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2024; Volume 13942, pp. 425–437. [Google Scholar] [CrossRef]
- Bisht, P.; Hinrichs, T.; Skrupsky, N.; Bobrowicz, R.; Venkatakrishnan, V.N. NoTamper: Automatic Blackbox Detection of Parameter Tampering Opportunities in Web Applications. In Proceedings of the 17th ACM Conference on Computer and Communications Security (CCS 2010), Chicago, IL, USA, 4–8 October 2010; pp. 607–618. [Google Scholar] [CrossRef]
- Deepa, G.; Thilagam, P.S.; Praseed, A.; Pais, A.R. DetLogic: A Black-Box Approach for Detecting Logic Vulnerabilities in Web Applications. J. Netw. Comput. Appl. 2018, 109, 89–109. [Google Scholar] [CrossRef]
- Aslam, S.; Aslam, H.; Manzoor, A.; Chen, H.; Rasool, A. AntiPhishStack: LSTM-Based Stacked Generalization Model for Optimized Phishing URL Detection. Symmetry 2024, 16, 248. [Google Scholar] [CrossRef]
- Bao, Q.; Wei, K.; Xu, J.; Jiang, W. Application of Deep Learning in Financial Credit Card Fraud Detection. J. Econ. Theory Bus. Manag. 2024, 1, 51–57. [Google Scholar] [CrossRef]
- Kshetri, N.; Kaur, N.; Kumar, D.; Osama, O.F.; Hutson, J. AlgoXSSF: Detection and Analysis of Cross-Site Request Forgery (XSRF) and Cross-Site Scripting (XSS) Attacks via Machine Learning Algorithms. In Proceedings of the 12th International Symposium on Digital Forensics and Security (ISDFS 2024), Istanbul, Türkiye, 22–23 April 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Castagnaro, A.; Conti, M.; Pajola, L. Offensive AI: Enhancing Directory Brute-Forcing Attack with the Use of Language Models. In Proceedings of the 2024 Workshop on Artificial Intelligence and Security (AISec’24), Salt Lake City, UT, USA, 14–18 October 2024; ACM: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- An, J.H.; Wang, Z.; Joe, I. A CNN-Based Automatic Vulnerability Detection. EURASIP J. Wirel. Commun. Netw. 2023, 2023, 41. [Google Scholar] [CrossRef]
- Fu, C.; Liu, G.; Yuan, K.; Wu, J. Nowhere to H2IDE: Fraud Detection From Multi-Relation Graphs via Disentangled Homophily and Heterophily Identification. IEEE Trans. Knowl. Data Eng. 2024, 36, 1081–1094. [Google Scholar] [CrossRef]
- Xu, Y.; Ding, L.; He, P.; Lu, Z.; Zhang, J. Meta: A Memory-Efficient Tri-Stage Polynomial Multiplication Accelerator Using 2D Coupled-BFUs. IEEE Trans. Circuits Syst. I Regul. Pap. 2024, 71, 541–554. [Google Scholar] [CrossRef]
- OWASP Foundation. Web Parameter Tampering. OWASP. Available online: https://owasp.org/www-community/attacks/Web_Parameter_Tampering (accessed on 6 June 2025).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. # | Title | Methodology | Results | Future Work |
|---|---|---|---|---|
| [2] | Write+Sync: Software Cache Write Covert Channels Exploiting Memory-Disk Synchronization | Software cache writes covert channels exploiting memory-disk synchronization timing (WRITE+SYNC) | Up to 253 Kb/s transmission rate, high success rates across diverse OSes/environments | Investigating dynamic protection techniques and detection feasibility analysis |
| [4] | IntruDTree: A machine learning-based cyber security intrusion detection model | Decision Tree-based IDS with feature ranking | 98% accuracy, outperforming SVM/LogReg/KNN | Advanced feature selection techniques and additional dataset integration |
| [5] | Automated Extension-Based Penetration Testing for Web Vulnerabilities | Automated PenTest model based on browser extension | Effective detection of diverse web vulnerabilities faster than existing tools | Developing ML-based automated analysis/classification models and expanding support for network layer analysis |
| [6] | LLMs in Web Development: Evaluating LLM-Generated PHP Code Unveiling Vulnerabilities and Limitations | LLM (GPT-4)-based PHP code generation with static and dynamic analysis | 11.16% sites with exploitable vulnerabilities; broader analysis than prior studies | Expanding the analysis to other programming languages and broader vulnerability categories |
| [7] | No Tamper: Automatic Blackbox Detection of Parameter Tampering Opportunities in Web Applications | Blackbox-based automated Parameter Tampering detection tool | Nine exploitable vulnerabilities were detected across nine applications | Extending support for AJAX and improving scalability for large-scale web applications |
| [8] | DetLogic: A black-box approach for detecting logic vulnerabilities in web applications | Blackbox FSM-based logic vulnerability detection (DetLogic) | Successful detection of Param Manipulation, access control, and Workflow vulnerabilities | Incorporating multi-user traces and dynamic analysis to enhance the detection of complex logic flaws |
| [9] | AntiPhishStack: LSTM-based Stacked Generalization Model for Optimized Phishing URL Detection | LSTM-based Stacked Generalization model for Phishing URL detection | 96.04% accuracy, better than existing ML/DL models | Incorporating features from web page content/structure and evaluating larger and more diverse datasets |
| [10] | Application of Deep Learning in Financial Credit Card Fraud Detection | Transformer (BERT)-based Credit Card Fraud detection model | 99.95% accuracy, outperforming previous approaches | Applying the model to detect other fraud types and enhancing adaptability to evolving fraud patterns |
| [11] | algoXSSF: Detection and analysis of cross-site request forgery (XSRF) and cross-site scripting (XSS) attacks via Machine learning algorithms | ML-based algoXSSF model for XSRF/XSS detection | 99.92% XSS accuracy using AdaBoost and other ML algorithms | Using larger and more up-to-date datasets and exploring hybrid learning approaches |
| [12] | Offensive AI: Enhancing Directory Brute-forcing Attack with the Use of Language Models | LM-enhanced Directory Brute-forcing attack model | Significant performance improvement over traditional wordlist-based attacks | Evaluating in real-world environments and optimizing initial request efficiency |
| [13] | A CNN-based automatic vulnerability detection | CNN-based V-CNN model for CWE/CVE detection | 98% accuracy, outperforming Random Forest | Improving detection accuracy and utilizing real-world source code datasets |
| [14] | Nowhere_to_H2IDE_Fraud_Detection_From_Multi-Relation_Graphs_via_Disentangled_Homophily_and_Heterophily_Identification | Disentangled representation learning-based H2IDE model for fraud detection in multi-relation graphs | Superior benchmark results; demonstrated scalability | Extending to more complex heterogeneous graphs and diverse relation types |
| [15] | Meta: A Memory-Efficient Tri-Stage Polynomial Multiplication Accelerator Using 2D Coupled-BFUs | META tri-stage polynomial multiplication accelerator using 2D Coupled-BFUs | Up to 10× memory efficiency improvement, up to 13.8× ATP improvement over prior work | Optimizing performance via ASIC implementation and extending to secure application domains |
| Category | Data | Percentage (%) |
|---|---|---|
| Benign Data(0) | 4363 | 63.60% |
| Vulnerable Data(1) | 2497 | 36.40% |
| Total | 6860 | 100% |
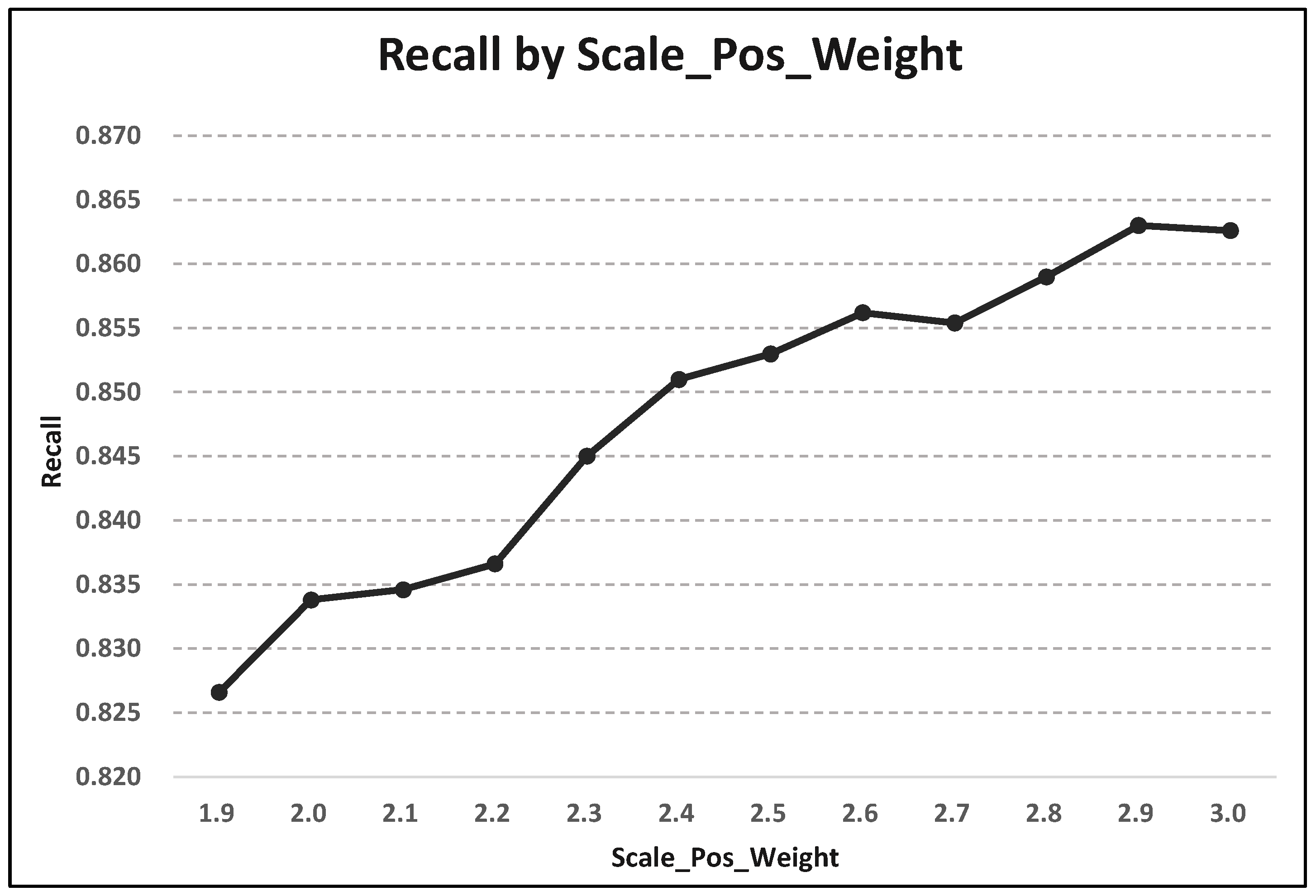
| Scale_Pos_Weight | Accuracy | Precision | Recall | F1-Score | AUC-ROC |
|---|---|---|---|---|---|
| 1.9 | 0.7359 ± 0.0046 | 0.5996 ± 0.0061 | 0.8266 ± 0.0207 | 0.6949 ± 0.0067 | 0.7776 ± 0.0071 |
| 2.0 | 0.7348 ± 0.0074 | 0.5975 ± 0.0097 | 0.8338 ± 0.0142 | 0.6960 ± 0.0050 | 0.7771 ± 0.0071 |
| 2.1 | 0.7337 ± 0.0047 | 0.5960 ± 0.0072 | 0.8346 ± 0.0158 | 0.6952 ± 0.0020 | 0.7770 ± 0.0068 |
| 2.2 | 0.7335 ± 0.0053 | 0.5955 ± 0.0074 | 0.8366 ± 0.0118 | 0.6957 ± 0.0025 | 0.7769 ± 0.0056 |
| 2.3 | 0.7362 ± 0.0051 | 0.5974 ± 0.0074 | 0.8450 ± 0.0166 | 0.6998 ± 0.0041 | 0.7764 ± 0.0060 |
| 2.4 | 0.7354 ± 0.0053 | 0.5957 ± 0.0072 | 0.8510 ± 0.0121 | 0.7008 ± 0.0033 | 0.7778 ± 0.0068 |
| 2.5 | 0.7334 ± 0.0060 | 0.5931 ± 0.0074 | 0.8530 ± 0.0139 | 0.6996 ± 0.0050 | 0.7769 ± 0.0072 |
| 2.6 | 0.7345 ± 0.0076 | 0.5941 ± 0.0093 | 0.8562 ± 0.0092 | 0.7014 ± 0.0049 | 0.7759 ± 0.0066 |
| 2.7 | 0.7331 ± 0.0067 | 0.5925 ± 0.0082 | 0.8554 ± 0.0094 | 0.7000 ± 0.0040 | 0.7769 ± 0.0073 |
| 2.8 | 0.7329 ± 0.0055 | 0.5919 ± 0.0071 | 0.8590 ± 0.0099 | 0.7008 ± 0.0021 | 0.7772 ± 0.0066 |
| 2.9 | 0.7327 ± 0.0076 | 0.5911 ± 0.0088 | 0.8630 ± 0.0092 | 0.7015 ± 0.0056 | 0.7772 ± 0.0062 |
| 3.0 | 0.7321 ± 0.0054 | 0.5905 ± 0.0072 | 0.8626 ± 0.0135 | 0.7010 ± 0.0023 | 0.7763 ± 0.0053 |
| Model | Dataset | Accuracy | Precision | Recall | F1-Score | AUC-ROC |
|---|---|---|---|---|---|---|
| Random Forest | Original (No Weighting) | 0.6990 ± 0.0131 | 0.6158 ± 0.0232 | 0.4598 ± 0.0336 | 0.5260 ± 0.0274 | 0.7840 ± 0.0055 |
| LightGBM | 0.7082 ± 0.0118 | 0.6006 ± 0.0162 | 0.5923 ± 0.0278 | 0.5961 ± 0.0194 | 0.7813 ± 0.0065 | |
| XGBoost | 0.7020 ± 0.0082 | 0.5940 ± 0.0127 | 0.5743 ± 0.0224 | 0.5837 ± 0.0139 | 0.7748 ± 0.0088 | |
| Random Forest | Original (With Weighting) | 0.7169 ± 0.0059 | 0.5840 ± 0.0076 | 0.7737 ± 0.0214 | 0.6654 ± 0.0080 | 0.7844 ± 0.0043 |
| LightGBM | 0.7350 ± 0.0062 | 0.6093 ± 0.0078 | 0.7585 ± 0.0163 | 0.6757 ± 0.0081 | 0.7814 ± 0.0075 | |
| XGBoost | 0.7426 ± 0.0036 | 0.6092 ± 0.0057 | 0.8174 ± 0.0163 | 0.6980 ± 0.0046 | 0.7775 ± 0.0077 | |
| Random Forest | SMOTE (No Weighting) | 0.7147 ± 0.0039 | 0.5814 ± 0.0062 | 0.7741 ± 0.0158 | 0.6639 ± 0.0033 | 0.7855 ± 0.0039 |
| LightGBM | 0.7287 ± 0.0094 | 0.6054 ± 0.0117 | 0.7321 ± 0.0246 | 0.6626 ± 0.0132 | 0.7818 ± 0.0076 | |
| XGBoost | 0.7273 ± 0.0101 | 0.6047 ± 0.0117 | 0.7245 ± 0.0254 | 0.6590 ± 0.0146 | 0.7781 ± 0.0064 | |
| Random Forest | SMOTE (With Weighting) | 0.7147 ± 0.0039 | 0.5814 ± 0.0062 | 0.7741 ± 0.0158 | 0.6639 ± 0.0033 | 0.7855 ± 0.0039 |
| LightGBM | 0.7287 ± 0.0094 | 0.6054 ± 0.0117 | 0.7321 ± 0.0246 | 0.6626 ± 0.0132 | 0.7818 ± 0.0076 | |
| XGBoost | 0.7327 ± 0.0076 | 0.5911 ± 0.0088 | 0.8630 ± 0.0092 | 0.7015 ± 0.0056 | 0.7772 ± 0.0062 |
| Model | Dataset | Mean Recall | Std Dev | 95% CI Low | 95% CI High | Interpretation |
|---|---|---|---|---|---|---|
| Random Forest | Original (No Weighting) | 0.460 | 0.038 | 0.413 | 0.506 | Stable |
| LightGBM | 0.592 | 0.031 | 0.554 | 0.631 | Stable | |
| XGBoost | 0.574 | 0.025 | 0.543 | 0.605 | Highly stable | |
| Random Forest | Original (With Weighting) | 0.774 | 0.024 | 0.744 | 0.804 | Highly stable |
| LightGBM | 0.758 | 0.018 | 0.736 | 0.781 | Highly stable | |
| XGBoost | 0.817 | 0.018 | 0.795 | 0.840 | Highly stable | |
| Random Forest | SMOTE (No Weighting) | 0.774 | 0.018 | 0.752 | 0.796 | Highly stable |
| LightGBM | 0.732 | 0.028 | 0.698 | 0.766 | Highly stable | |
| XGBoost | 0.724 | 0.028 | 0.689 | 0.760 | Highly stable | |
| Random Forest | SMOTE (With Weighting) | 0.774 | 0.018 | 0.752 | 0.796 | Highly stable |
| LightGBM | 0.732 | 0.028 | 0.698 | 0.766 | Highly stable | |
| XGBoost | 0.863 | 0.010 | 0.850 | 0.876 | Highly stable |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yun, S.Y.; Cho, N.-W. A Machine Learning-Based Detection for Parameter Tampering Vulnerabilities in Web Applications Using BERT Embeddings. Symmetry 2025, 17, 985. https://doi.org/10.3390/sym17070985
Yun SY, Cho N-W. A Machine Learning-Based Detection for Parameter Tampering Vulnerabilities in Web Applications Using BERT Embeddings. Symmetry. 2025; 17(7):985. https://doi.org/10.3390/sym17070985
Chicago/Turabian StyleYun, Sun Young, and Nam-Wook Cho. 2025. "A Machine Learning-Based Detection for Parameter Tampering Vulnerabilities in Web Applications Using BERT Embeddings" Symmetry 17, no. 7: 985. https://doi.org/10.3390/sym17070985
APA StyleYun, S. Y., & Cho, N.-W. (2025). A Machine Learning-Based Detection for Parameter Tampering Vulnerabilities in Web Applications Using BERT Embeddings. Symmetry, 17(7), 985. https://doi.org/10.3390/sym17070985