1. Introduction
The healthcare industry generates vast amounts of sensitive patient data, which has immense potential to revolutionize diagnostic decisions, advance medical research, and enable personalized treatment solutions. However, the utilization of these data is hindered by significant privacy and security concerns. Unauthorized data breaches and access to patient information pose severe risks, making healthcare data highly vulnerable. Traditional methods of data sharing and centralized storage exacerbate these vulnerabilities, as they often do not comply with stringent privacy regulations and are susceptible to cyberattacks. Consequently, healthcare institutions face substantial barriers to collaborative data sharing, which is essential to optimize the value of healthcare data while keeping patient trust and confidentiality. In recent years, the digitalization of healthcare data has further amplified concerns about privacy, security, and data authenticity. Health data, including medical histories, diagnoses, and treatment plans, is highly sensitive and a prime target for cybercriminals. Traditional approaches to securing healthcare data, such as centralized storage and management, are increasingly inadequate in the face of sophisticated cyber threats. Moreover, there is a growing reliance on data-driven artificial intelligence (AI) models, which require large datasets for optimal performance and thus inherently contain the possibility of illegal access and data leaks during sharing.
Federated learning (FL) proved to be a viable solution for healthcare collaborative learning that protects privacy. FL enables several healthcare organizations to work together to train machine learning models without directly sharing sensitive patient data. FL allows local model training within each institution in lieu of centralizing data. A central server receives only model updates, like gradients or parameters, for aggregation. The risk of data breaches is significantly reduced by this decentralized approach, which ensures that raw patient data remain within each institution’s secured limits. However, FL is not without limitations. Although it mitigates the risks associated with raw data sharing, providing a model with new parameters throughout the training stage can still expose sensitive information. Malicious actors can potentially exploit these updates to infer private patient data, leading to privacy breaches.
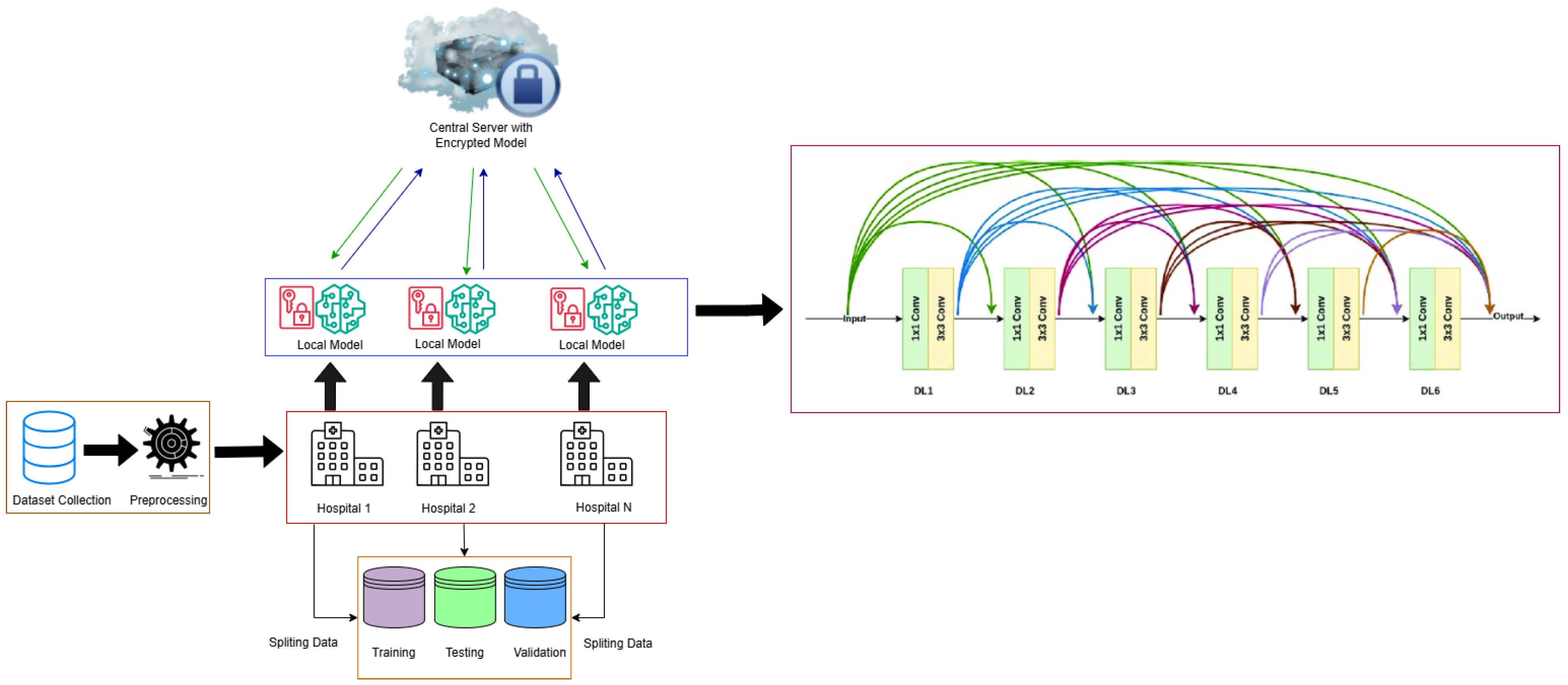
A hospital coalition trying to develop an advanced AI disease predictive tool faces resistance from members who want to prioritize protecting patient confidential information. A combination of homomorphic encryption technology and a federated learning framework allows them to achieve the results shown in
Figure 1. Medical records and other patient information reside securely in protected databases, which resemble digital vaults, before hospitals start sharing data. Homomorphic encryption allows data encryption in ciphertext to maintain privacy through secret code protocols. Data safety under homomorphic encryption creates an encrypted vault that protects information while allowing formulas to operate securely on the content within. The hospitals divide their shared information into encrypted codes before storing it remotely in a cloud-based system that prevents the exposure of raw data to others. The cloud system performs number-crunching procedures, such as optimizing the AI model directly on encrypted data while maintaining complete data security for all participants. The final result emerges from the homomorphic decryption of encrypted results, but patient data remain protected throughout the entire process without consequences. With these measures, healthcare institutions can achieve better care outcomes through collaboration while protecting data privacy at all times according to HIPAA and GDPR standards and ensuring patient security.
Additionally, the integration of cryptographic techniques, such as homomorphic encryption (HE), with FL frameworks introduces computational and communication overheads, which can hinder the scalability and efficiency of these systems. HE allows computations to be performed on encrypted data, ensuring end-to-end privacy during model updates and aggregation. However, the computational complexity of HE remains a significant deterrent to its application of deep learning in medical services for a wide range of people. The combination of FL and HE offers a transformative approach to secure data collaboration in healthcare. By leveraging FL’s decentralized model training and HE’s ability to perform computations on encrypted data, healthcare institutions can collaboratively train models while maintaining strict privacy standards. This integrative approach not only protects patient confidentiality but also ensures compliance with legal regulations, such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). Despite these advancements, several challenges remain. The scalability and efficiency of FL systems need to be improved to handle the increasing complexity and interconnectedness of modern healthcare systems. Furthermore, the risk of adversarial attacks, such as model inversion and targeted queries, poses a significant threat to the privacy of trained models. These attacks can exploit vulnerabilities in the model to infer sensitive patient information, even after the training phase. Therefore, there is a pressing need to develop robust privacy-preserving mechanisms that minimize the amount of sensitive information exchanged during training while maintaining model accuracy.
This research aims to design a federated learning framework that preserves privacy and allows the secure collaboration of healthcare data. The primary goal is to reduce the computational overhead associated with cryptographic techniques while ensuring data confidentiality. By addressing these challenges, this study seeks to unlock the full potential of healthcare data for innovation and collaboration, paving the way for advancements in medical research, personalized treatment, and improved patient outcomes. Model fairness and interpretability remain achievable through a symmetrical federated learning setup that requires identical model configurations from clients functioning equally in the learning process. Building on these challenges, the related work section reviews existing efforts to address privacy and security in healthcare data collaboration. The main contributions are as follows.
We give a privacy-preserving federated learning framework employing homomorphic encryption (HE) for healthcare data, PPFLHE, which preserves model privacy and computational efficiency while maintaining data availability and model correctness, which are critical for the healthcare application of FL.
In the local gradient case, to protect against inference attacks, CKKS is used to encrypt model updates on the client side so that a malicious server cannot decode into anything but nonsense and that can be easily interpreted by the client; the same is true in the case of sharing.
In the FedAvg algorithm, on the server side, encrypted updates from three clients are folded, and delays caused by unresponsive participants and communication overhead are reduced. Next, we investigate the efficiency and privacy of PPFLHE using the APTOS 2019 Blindness Detection dataset, achieving 83.19% precision with EfficientNet-B0, maintaining privacy and having low communication cost.
The paper is organized as follows. First, we review related work on FL and privacy techniques (
Section 2); then, we outline the system model and methodology (
Section 3). After, we analyze the system architecture and security (
Section 4), discsuss the experimental results (
Section 5), and draw our conclusion (
Section 6).
2. Related Work
The fast growth of healthcare data would require stronger protection of privacy and security due to increased AI capabilities and IoT technology development. The work of learned authors bases their privacy-preservation research on FL and blockchain security systems implemented with cryptographic approaches. The research concerning healthcare privacy has been examined here to demonstrate the approaches employed and data utilized along with the acquired results.
Mantey et al. [
1] used stochastic modification minimized gradient (SMMG) and Newton distributed estimate (NDE) algorithms to establish privacy-preserving collaborative learning, which tackles gradient leakage problems within federated systems. Bo Wang et al. [
2] developed PPFLHE as a new security framework that defends healthcare federated learning using homomorphic encryption. It protects user privacy through side encryption for model updates and authentication access controls. The study incorporated APTOS 2019 Blindness Detection together with the CIFAR-10 datasets for experimental assessment. The system received an ACK functionality for managing inactive clients which enhanced communication operations. The classification method achieves an 81.53% accuracy level that reaches a favorable balance between model performance and data privacy alongside transmission efficiency. As part of this research, the authors integrated cryptographic solutions with foundational system-level practical optimizations to advance healthcare applications of federated learning.
Wang et al. [
3] examined IoMT privacy issues specifically focused on recommender systems through their research study. The framework protected user privacy safely at the same time it achieved a high accuracy through innovations in optimization algorithms and homomorphic encryption implementation. Through FL, Hijazi et al. [
4] created an FHE system which protects IoT security within cognitive cities by applying the N-BaIoT dataset to reduce latency along with communication overhead. Gu et al. [
5] performed a review of privacy enhancement strategies for healthcare FL through differential privacy and blockchain technologies as well as hierarchical schemes, which they applied to diabetic retinopathy and COVID-19 forecasting. Operational problems caused by concerns about model convergence and system performance, along with privacy versus precision conflicts in personal data management, were recorded in the research. Applications of FL to electronic health records required solutions, according to research conducted by Antunes et al. [
6], to overcome interoperability and scalability problems. A privacy-preserving data-sharing platform was created by the authors through a combination of blockchain technology integrated with differential privacy standards for handling various healthcare information.
Zhou et al. [
7] produced adaptive segmented CKKS homomorphic encryption as a way to boost FL performance when working with federated averaging (FedAvg). Their approach achieved secure and efficient computations when it was implemented on MNIST and CIFAR-10 datasets. The medical professionals at Xu et al. [
8] implemented FHE to conduct secure FL operations for breast cancer detection from mammogram images. Complete model encryption required both extended processing power and large memory storage for execution but delivered nearly identical performance to standard techniques against inference attacks effectively. Khalid et al. [
9] conducted a review which examined secure multiparty computation techniques and blockchain systems and differential privacy solutions for protecting medical records such as EHRs and genomic data as well as imaging data. The paper examined multiple types of privacy intrusions and defense approaches yet suggested the need for legal and ethical systems to safeguard data privacy without compromising its worth.
Liu et al. [
10] developed a privacy-protected FL system for medical IoT skin lesion classification in healthcare operations. The model secured data sharing and model aggregation by implementing HE encryption and then combining it with Shamir’s secret sharing method as well as Diffie–Hellman key exchange [
11]. Through its use of HAM10000 dataset data, the solution reached high accuracy results together with better computational speed. Qayyum et al. [
12] built an FL framework that performed clustering diagnostics on COVID-19 through X-ray images together with ultrasound data analysis. Through the modification of the VGG16 neural network, higher F1 score results were achieved than what centralized model approaches delivered. The system established queryable data access across various sources to solve heterogeneity problems and computational limits by maintaining privacy protection. Future work should concentrate on building a personalized version of the model along with its scaling process.
Researchers created IoThC through the integration of FL and blockchain concepts, which forms the basis of an extensive IoT healthcare framework as described by Singh et al. [
13]. Blockchain technology creates data protection through its unmodifiable characteristics, while FL processes information across multiple users without needing direct system connections [
14]. This system combines differential privacy as an encryption method with homomorphic encryption protocols to protect sensitive data from leakage vulnerabilities [
15]. The case evaluation showed that the specified framework delivered successful privacy defense alongside stable ownership management in the system design. A collaborative filtering system for healthcare recommendations with privacy protection was created by Kaur et al. [
16] through the integration of multiparty random masking with polynomial aggregation and homomorphic encryption. Through their framework, the authors accomplished superior performance levels and better precision results when evaluating simulated healthcare and MovieLens datasets. A framework for mobile healthcare social networks data sharing was developed by Huang et al. [
17] by uniting both attribute-based and identity-based broadcast encryption methods. The platform provided a protected information exchange system for smart city healthcare providers by resolving problems with data processing overheads and exclusions within their simulated operational environment.
The research by Yang et al. [
18] introduced an integrated security solution to shield patient data during all cloud-based medical data-sharing tasks. The integration of vertical partitioned processing together with hybrid search protocols and anonymization methods let closed-system data management provide data usefulness and protect privacy. The solution tested in experimental trials upon electronic medical records (EMRs) demonstrated its practical viability [
19]. The protection of healthcare data improves via research that generates privacy mechanisms capable of maintaining operational performance. FL serves as an AI learning methodology that duplicates the study process from an unknown source to process distributed data systems. The storage of medical documents signed through encryption comes under the unalterable blockchain platform at each processing stage. The proposed solutions handle both training data leak problems and huge data handling needs as well as address system integration requirements and data unification challenges [
20,
21]. Li et al. [
22] explore federated learning (FL) through a detailed investigation as a privacy-focused distributed machine learning architecture in this study. Devices participate in model training through collaborative processes while sensitive user data remain on their devices, according to the authors. The article stands out from numerous dataset-focused research by avoiding dedicated analysis of one specific dataset and performance metrics. The paper performs an extensive analysis of FL’s privacy system architecture through the examination of both FedSGD and FedAvg methods and their identified security weaknesses encompassing model poisoning along with communication overloads and inference attacks. The research puts forward a set of defenses which include FHE homomorphic encryption together with differential privacy followed by secure aggregation and multiparty computation (MPC) to solve these dilemmas. The article functions as a foundational resource that provides technical guidance about building scalable privacy-protected robust federated learning systems for healthcare, IoT, smart cities and financial analytics despite absent accuracy performance evaluation information. Altaf et al. [
23] delivers an extensive evaluation of blockchain technology by examining its multi-tier system infrastructure alongside its agreement mechanisms and field implementations together with its main frameworks and protection vulnerabilities.
Table 1 shows a comparative survey of previous operations concerning federated learning and homomorphic encryption on medical and simulated data.
The paper discusses how the blockchain configuration supports privacy features because it functions with decentralized protocols that benefit from cryptographic hashes as well as consensus mechanisms, which remove requirements for trusted third parties [
27]. The technology guarantees unalterable data integrity, which proves vital for healthcare, together with finance sectors and IoT applications. This paper bases its findings on existing sources without conducting any experimental analysis with a definite dataset because it follows a survey-based approach [
28,
29]. The research paper collects and evaluates actual cases from multiple business domains, which include healthcare, energy, supply chain, and IoT, to show how blockchain technology improves data security and transparency as well as control over data [
24,
30]. The paper establishes that blockchain transforms digital trust and privacy, yet scientists must tackle issues regarding scalability, energy consumption, and interoperability because these barriers hinder further development. The research groups accomplished successful outcomes by implementing evaluation through the convergence of medical records with standardized MNIST datasets in real medical settings. This paper describes our method to join FL and HE frameworks to allow secure private healthcare data sharing in the methodology [
31,
32]. FL stands today as the principal defense mechanism that medical organizations use to handle their various machine learning distribution operations. The study conducted by Xu et al. [
33] demonstrated how FL supports collaborative model development from EHRs through a process that prevents the exchange of original medical data. The research used MIMIC-III, eICU, and Cerner Health Facts datasets for analytics before applying support vector machines and logistic regression and multilayer perceptrons, recurrent neural networks, autoencoders and tensor factorization for model development.
Researchers in [
34] addressed distribution issues in non-IID data and FL heterogeneity using three main approaches called federated averaging [
35], agnostic FL, and federated multi-task learning represented by MOCHA and VIRTUAL. Model compression, federated dropout, and resource-aware client selection methods reduced communication overhead [
36]. Pan et al. [
37] suggested a privacy-preserving federated learning framework, FedSHE, which is based on segmented CKKS homomorphic encryption. The framework has solved the issue of gradient leakage by optimization of the encryption parameter and the use of the segmented encryption technique when dealing with large model size. An assessment of examples on standard datasets shows that FedSHE yields similar model performance with less computational overhead and low communication overhead. It is more efficient and secure than Paillier and other CKKS-based methods, which theoretically make the implementation of fully homomorphic encryption feasible in realistic federated learning applications. A blockchain architecture developed by Iqbal et al. [
38] incorporated verification protocols for IoT devices together with protection elements for reliable data and secure energy deals implemented through smart contracts within net metering infrastructure. The authors used moving average and ARIMA models, which were combined with LSTM for energy consumption prediction throughout their research. Several professionals used data from the smart home dataset hosted on Kaggle for training their models based on appliance records and weather measurements recorded per minute. The energy consumption prediction using LSTM reached its highest accuracy rate [
25]. The solid smart contracts within the Ganache environment ensured secure automated peer-to-peer energy transactions by utilizing a private Ethereum blockchain. The study created a private smart home system with advanced functionality, yet it needed official verification together with performance enhancement [
39].
Li et al. [
40] developed a privacy-protected federated learning system which analyzes multi-site functional MRI (fMRI) data through decentralized operations. Using their decentralized deep learning method, the authors protect medical data by maintaining it at its source location for security reasons. The Autism Brain Imaging Data Exchange (ABIDE I) utilized sites NYU, UM, USM and UCLA for running both their model development and evaluation processes. Performance enhancement and privacy preservation occurs through a research approach which integrates differential privacy methods with domain adaptation methods utilizing Mixture of Experts and Adversarial Domain Alignment. The model succeeded in providing dependable ASD diagnosis through valid biomarker assessment, resulting in 80% reliable patient results across different clinical datasets. The research shows that domain adaptation methods improve model performance during federated operations by protecting patient privacy [
41]. Almaiah et al. [
42] put together a system which unites supervised machine learning (SML) frameworks with cryptographic encryption and decryption methods (CPBED) for user verification of Internet of Medical Things (IoMT)-based cyber-physical systems (CPSs) and healthcare dataset protection. Before implementing encryption, the system performs a distributed authentication of medical devices, thereby maintaining consistent data while ensuring privacy security. The dataset contained encrypted X-ray images that protected owner information during deep learning model analysis by analysts. Data encryption through this method leads to performance degradation but managed to preserve complete accuracy rates while experiencing a 1% reduction in accuracy points.
In addition to security and privacy, energy consumption is a new issue in the federated edge learning systems, especially in UAV-facilitated MEC systems. Sharma et al. [
43] worked on Mobile Edge Computing (MEC) as Unmanned Aerial Vehicles (UAVs) solutions have shown a lot more potential to offer on-demand computing services closer to the user equipment (UE), which in turn, lessens the latency and better enhanced the quality-of-service (QoS). Nevertheless, the energy consumption is a very serious problem because both UAVs and mobile devices have limited battery capacities. This problem is more evident in 5G and beyond 5G (B5G) networks, where a dynamic UE mobility and often task offloading require adaptive and smarter resource management. To deal with this, the recent research discusses energy-efficient optimization techniques in NOMA-based UAV-assisted MEC. It is worth noting that a multi-agent federated reinforcement learning (MAFRL) framework was suggested, where the Markov Decision Processes (MDPs) are used to model the problem, and Multi-Agent Reinforcement Learning (MARL) is used to obtain an optimal energy-aware offloading policy. The findings indicate better energy efficiency than the conventional centralized, single-agent schemes, showing the prospects of integration of federated learning, UAV-MBE-based MEC and NOMA technologies in next-generation networks to support energy/power-efficient edge computing on a large scale.
Pan et al. [
44] developed the application of SplitFed Learning (SFL) in MRI images classification of brain tumors and compared it with the other methods of federated and centralized learning. They applied a non-IID partitioned dataset composed of 3264 MRI scans and VGG19 to determine performance in different learning conditions. The experiment concluded that SFL consists of an acceptable trade-off between privacy and performance, as it only transmits intermediate activations rather than the raw parameters of the model, thereby using less communication overhead and providing more data security. Although the performance of centralized learning was the best, SFL provided similar results with enhanced privacy and reduced resource requirements and hence was adequate to handle sensitive medical tasks.
4. Privacy-Preserving Federated Learning Framework with Homomorphic Encryption
This study focuses on integrating homomorphic encryption (HE) with federated learning (FL) technology to let different decentralized health facilities securely share sensitive data from their patients.
Table 2 details important values of the configuration and training parameters for our federated model. These parameters were carefully chosen to optimize model performance and computational efficiency while ensuring the confidentiality of the data through encryption.
The described data layout reveals the system’s hardware structure as well as shows how privacy and performance work together in cutting-edge machine learning systems today. During training, the model calculates predictions against actual labels through cross-entropy to discover mismatches between expected results. By using Momentum-SGD, we optimize training because it improves the convergence rate through its parameter momentum acceleration vectors. Training improves when the momentum parameter keeps 90% of the past gradient direction at 0.9 to reduce updates and control oscillations. The model updates weights slowly during training because our learning rate stands at 0.01. After running the model for five local steps, each federated node sends its updated knowledge to the main model for overall training. The team processes training samples in groups of 32 samples to save processing time and produce better model results. Each of the three participating nodes trains its own local dataset independently before sending resulting model updates to the shared model. The setup allows decentralized devices to process private data locally with the updates joining the main model without harming its accuracy. We next explore how the model functions as part of its main elements.
4.1. Privacy Preserving Federated Learning Framework
The Privacy-Preserving Federated Learning with Homomorphic Encryption (PPFLHE) framework enables secure and efficient collaboration among sites through handling their sensitive healthcare data. The system operates with symmetric structure because clients begin with standard initialization procedures and standardized aggregation methods. Homomorphic encryption functions as part of this framework to safeguard model update confidentiality throughout the whole federated learning process.
4.2. Local Gradient Computation and Encryption
At every round, the central server transmits the plaintext global model weights, denoted as , to all participating clients. The model remains unencrypted on the client side, as decrypting it and simultaneously computing gradients is computationally expensive, particularly for large neural network models.
Each client i uses its local dataset and the received model to compute its local gradient . Since gradients are real-valued, we adopt the CKKS homomorphic encryption scheme, which supports approximate arithmetic over real numbers and enables the encryption of continuous values with controlled precision.
After computing the gradient, the client encrypts it using the public encryption key
:
For scenarios where gradient quantization is applied, the client may alternatively encrypt the quantized gradient:
The encrypted gradient is then sent to the central server for secure aggregation.
4.3. Homomorphic Aggregation
Once the server receives the encrypted gradients from each client, it performs aggregation using the additive homomorphic property of the CKKS encryption scheme. Let the encrypted gradients be denoted as shown below:
The server computes the encrypted sum of all gradients:
To calculate the average encrypted gradient, the server multiplies the result by
:
Only clients possessing the appropriate decryption key are able to decrypt
and obtain the average gradient
according to Equation (
4). This ensures that raw gradient values are never exposed to the server, thereby enabling secure collaborative learning through encrypted aggregation.
4.4. Threat Model and Security Considerations
The clients use CKKS because it enables approximate arithmetic over real numbers to encrypt local gradients in order to obtain training updates. This makes sure that no raw gradients are ever exposed even when the gradients have to be aggregated. Only encrypted updates are given to the server, and it is only able to perform homomorphic addition, which has a greatly reduced attack surface.
In this framework, model inversion attacks, in which the attacker aims to recover client information based on gradients, are resisted sturdily. Opponents cannot access raw model updates, because all updates are encrypted and decrypted locally. In addition, secure aggregation and the symmetric architecture used to prevent a particular client having excessive sway in the global model mitigate model poisoning attacks. Our construction follows well-established patterns in the existing literature [
2,
7,
24], which show that an efficient FL framework effectively secures inference and poisoning attacks and preserves model utility.
This algorithm develops a secure data collaboration method for healthcare organizations to share information without losing patient privacy. Algorithm 1 shows our steps to start one model per healthcare facility that uses local patient information to train. The models train from individual datasets without giving raw patient data to a central organization. Each institution updates their matching local model according to an optimization function that minimizes given loss standards from existing datasets. Local model upgrade information becomes encrypted when it shares to the system. At set times, we aggregate local model improvements to create one shared model instance for all levels of the system. A global model develops by averaging encrypted model updates from all institutions to share knowledge between centers while keeping patient data hidden. The institutions receive the new updated global model when the system completes its cycle. The procedure runs K times to build up the global model through consistent updates without revealing patient details.
| Algorithm 1: Privacy-preserving federated learning for secure healthcare data collaboration. |
Inputs: : Local datasets at N institutions. : Corresponding labels. : Local models with weights . : Encryption function; . K: Total number of global training rounds. : Global synchronization interval. : Local optimizers minimizing loss L. Algorithm: 1. Initialize local models: random for to N. 2. For to K: For each client to N: Compute gradient: Update local model: Encrypt weights: If : Aggregate: For each client to N: Update model: 3. Repeat until K rounds are complete. |
This secure data collaboration method functions in a real-world setting to measure its success.
5. Performance Analysis
In this section, we use the degree of diabetic retinopathy as a case study to evaluate the performance of the PPFLHE program. The effectiveness of this approach is demonstrated through experimental analysis, focusing on five key metrics from the APTOS 2019 Blindness Detection dataset: classification accuracy, F1 score, precision, recall, and the computational time required for encryption and decryption. Additionally, the privacy-preserving capabilities of the scheme are assessed, confirming its advantages through these detailed experiments. Efficient experiments required us to set up a specific computing space.
5.1. Experimental Setup
For our diabetic retinopathy (DR) detection experiments, we utilized an updated setup running on Python 3.10 with PyTorch (version 2.0.1). The experiments were performed on a Google Colab environment with a Tesla T4 GPU and 12 GB RAM.
5.2. Dataset
The research utilizes the APTOS 2019 BD dataset, which provides 3662 labeled retinal images for statistics. The research team obtained retinal images by testing rural India participants at Aravind Eye Hospital, which remains a top attraction for eye healthcare. The collection of data establishes an effective platform to train and test diabetic retinopathy detection models that develop during diabetes progression. The ready-for-model dataset serves three essential tasks with data preparation that includes the collection of labeled images plus quality checks and image updates for training. The dataset proves useful because it comes from real-life healthcare practice and shows multiple variations for testing and creating medical-oriented federated learning platforms.
Building on this data source, the study conducts a comprehensive evaluation of the proposed secure data collaboration model.
5.3. Model Accuracy
In order to comprehensively assess the PPFLHE framework, I compared the performance of three different models, i.e., EfficientNet-B0, MobileNet V2, and ResNet 50, on the APTOS 2019 database to classify diabetic retinopathy.
Table 3 indicates that EfficientNet-B0 has an accuracy of 83.19 %, whereas MobileNet V2 and ResNet 50 have an accuracy of 81.53% and 78.00%, respectively. This testing shows the possibility of the framework being able to effectively support various model architectures while attaining high performance on the APTOS 2019 dataset.
In addition to the experiment on reviewing performance on APTOS 2019, we also tested the EfficientNet-B0 model in a new modality with the MosMedData CT scan dataset. The findings, which are depicted in
Table 4, indicate that the framework can be generalized to different areas of medical imaging.
It was observed that EfficientNet-B0 performed better than both MobileNetV2 and ResNet50 due to its accuracy and effectiveness on the APTOS dataset in training. Also, on the MosMedData CT data, it attained an accuracy of 81.27%, leading it to show high adaptability to multiple types of medical imaging. These findings demonstrate the significance of the architecture and of the training processes in achieving high levels of performance. As revealed in
Table 5, the measurement of the models kept on improving round by round.
5.3.1. Client Behavior and Accuracy Analysis
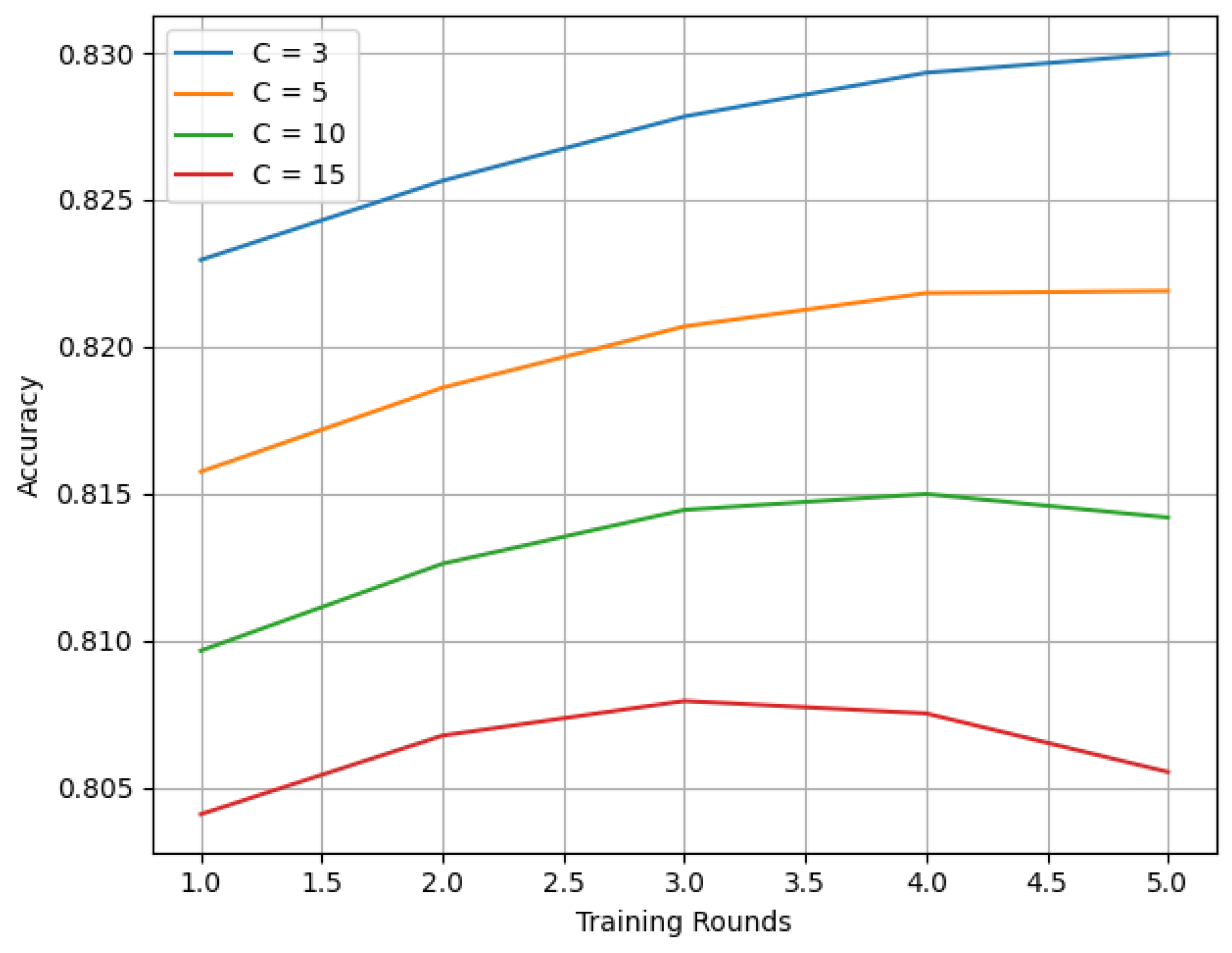
PPFLHE follows the model of symmetric federated learning. Each participating client is set up the same, so the model and its training settings provide equal and fair representation. The results from experiments suggest that as the number of clients is raised (C ∈ 3, 5, 10, 15), the system’s accuracy does not become less reliable, demonstrating how much the framework can handle.
The results of multiple training rounds on the APTOS 2019 Blindness Detection Dataset are shown in
Figure 3. It is apparent from the experiments that training mostly works the same for any number of clients. Even with only three clients, the model keeps showing strong and stable progress no matter the configuration.
5.3.2. Time Consumption in Federated Setup
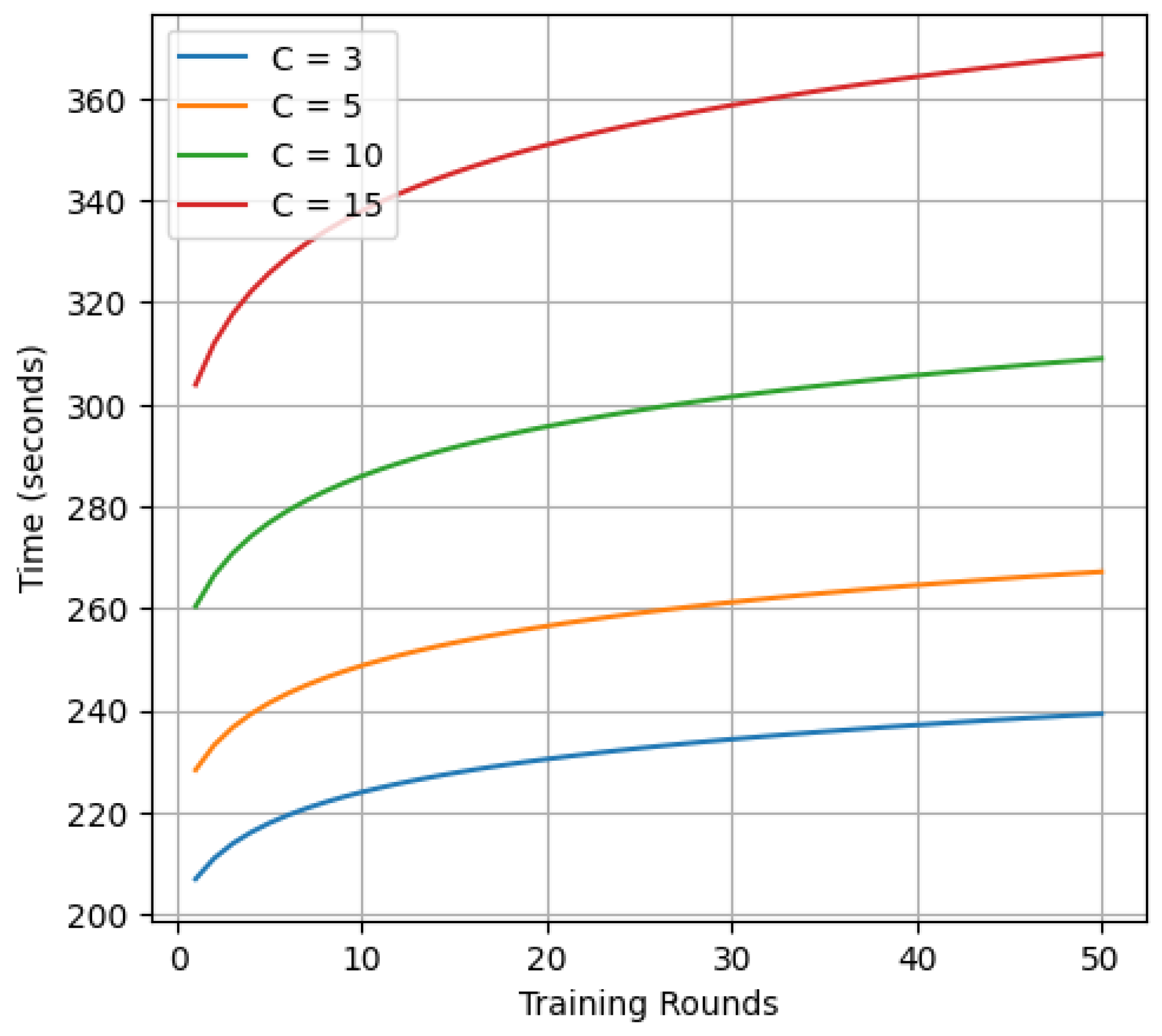
These results report two findings: first, they show a still subtle effect of the number of clients on the availability of PPFLHE, and lastly, that the average classification precision seems diverse by approximately
in different configurations. Additionally, the framework is robust to client dropout, as it does not significantly affect the overall accuracy of the model. Network communication between clients increases noticeably with time as the number of clients increases. For example, with
, the processing times corresponding well to those reported in
Figure 4 (see, for instance, the number of initial rounds around 200–250 s, depending on network traffic), and each round runs in rounds
. However, when
, the increase in coordination and encryption overhead results in worst-case scaling, and the time consumption increases.
Given the trade-off between performance and computational cost, we selected
as the optimal number of clients for this study, as shown in
Table 2. To measure the framework’s scalability in terms of time and computing power, more clients were included in the latency experiments, reaching up to 10. Based on the study, encryption and decryption times for users (approximately 6–8 s) do not change, but the overall time taken for each round of work increases according to the number of clients due to all the necessary encryption, transfer, and decryption work performed by the server.
When PPFLHE was enabled, it took 6 to 8 s to perform encryption, resulting in a total latency per round of almost 215 s, which was much longer than the 105 s for non-HE FL. Yet, using this extra processing increases the model’s accuracy. Consequently, using homomorphic encryption can safeguard the confidentiality of your data and, at the same time, support slightly better model results. From the results in
Table 6, we conclude that privacy technology is important, as it keeps data secure while still allowing learning to progress properly.
5.3.3. Privacy Preserving Analysis
The Privacy-Preserving Federated Learning with Homomorphic Encryption (PPFLHE) framework is evaluated with the APTOS 2019 Blindness Detection dataset with the aim of performing comparative experiments against a differential privacy (DP) approach. The performance metrics for the classification accuracy are shown in
Figure 5, and it is seen that the data utility degrades for DP noise. All of our previous studies [
1,
5,
6,
18] in a form similar to that of
Table 1 above and with related work are unable to guarantee model and data privacy and security at the same time. However, in comparison to the work in [
2], our PPFLHE framework has the same privacy and security levels inherited in [
2,
8], and at least on top of that, our PPFLHE framework outperforms the computationally intensive CKKS HE approach by collecting a higher classification accuracy and communication overhead than [
2]. In other words, PPFLHE does realize the trade-off between security, privacy, and performance in a secure collaboration of healthcare data.
Through our design, we develop secure patient data while offering solid and promising models for healthcare institutions. The system maintains symmetrical architecture between clients, which ensures all learners receive equivalent opportunities while lowering the potential for transfer of information about client relationships. The structure of our Privacy-Preserving Federated Learning with Homomorphic Encryption (PPFLHE) framework is depicted in
Figure 2, which guarantees an equitable computational load distribution among all participating clients, thus avoiding any single institution bearing a disproportionate amount of the training process. Using the methodology described, the system increases the utilization of available resources in healthcare networks using federated learning techniques, leading to 83.19% accuracy in the APTOS 2019 Blindness Detection dataset while protecting data privacy.
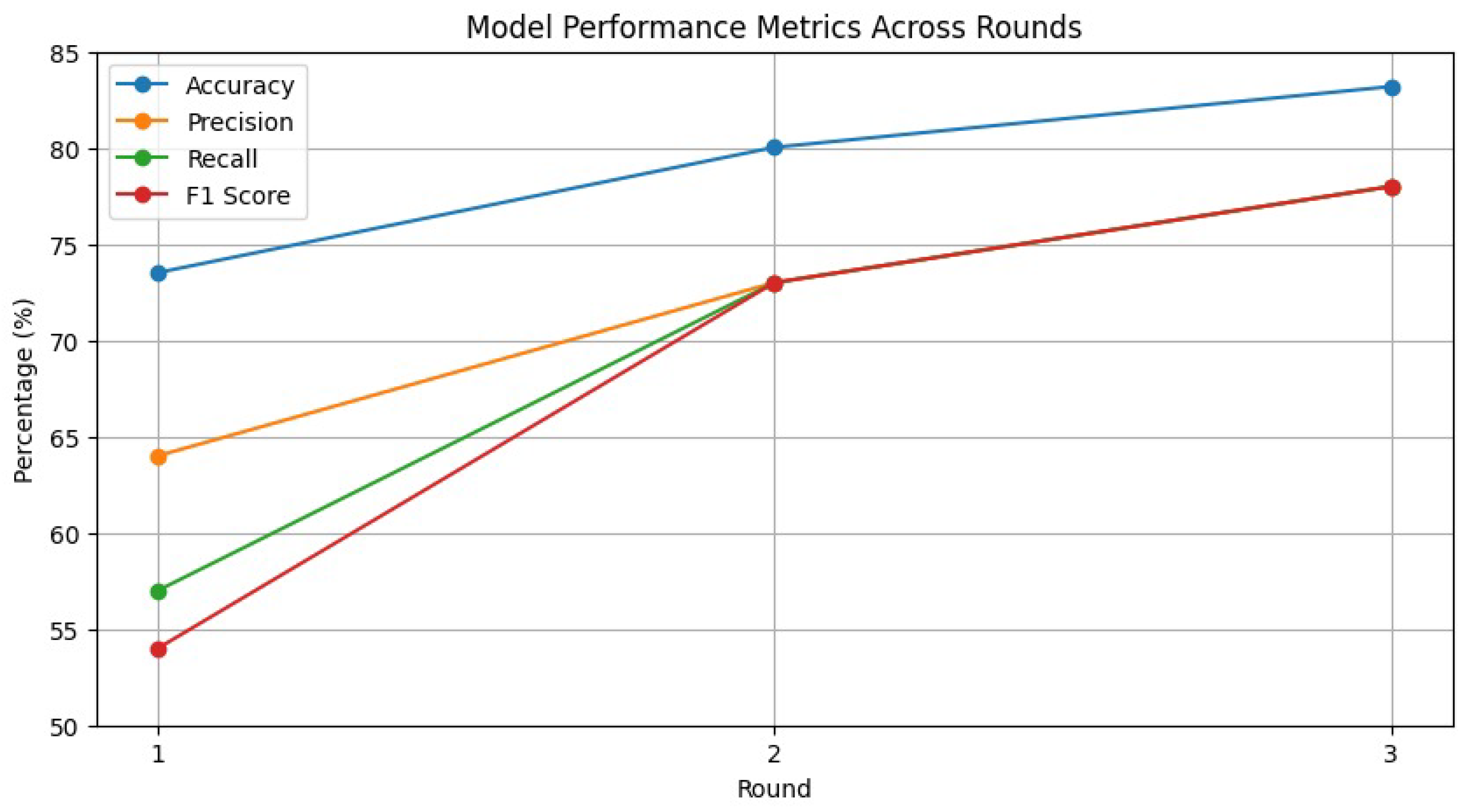
As shown in
Figure 6, the experiments prove that PPFLHE has better results when trained once or multiple times. With time, the model becomes better at classification as its training methods improve and it learns from the given data in the APTOS 2019 Blindness Detection Dataset. During those early stages, the model does not understand the basic patterns of the data, so it takes further rounds of training to perform well. Next, we added homomorphic encryption to our enhanced system performance in
Section 4 to let the server aggregate the models safely. The parallel handling of data in the PPFLHE framework helps create a well-balanced result between keeping people’s privacy and performing effective classifications. New insights from these tests prove that using iterative learning and proper aggregation methods boosts the performance of diabetic retinopathy detection with the EfficientNet-B0 model and results in a performance of 83.19%.
5.4. Real-World Robustness Discussion
We demonstrated the real-world usability of the suggested framework by utilizing the APTOS 2019 Blindness Detection dataset, which consists of images of diabetic retinopathy from patients. It makes certain that the results of the evaluation are accurate reflections of actual medical problems. The testing included three clients. Because all EfficientNet-B0 models are used and trained identically, every hospital or clinic node behaves similarly. With this scheme, the contributions of each model are balanced, which ensures it can run in real-world systems where healthcare is distributed.
6. Discussion
This section features a review and comparison between what the PPFLHE framework uncovered and what the existing studies in the literature have found. With papers such as those by Mantey, Lee, and Zhou, previous studies have outlined the need to integrate encryption with federated learning to improve privacy. However, the studies usually do not explain in depth how privacy and model performance can be balanced.
In short, the proposed PPFLHE framework is beneficial for keeping data confidential, ensuring accurate models, and improving communication. It managed to retain an accuracy of 83.19% on the dataset, as shown in
Table 7. The inclusion of CKKS homomorphic encryption helps to protect patients’ privacy in healthcare systems by supporting low communication traffic and delivering good performance. We have also discussed the threat model of PPFLHE to detail how the symmetric client design and encryption framework address primary key attack avenues, which are model inversion and poisoning. This assists in making sure PPFLHE is not only resistant to privacy but also resilient to the adversarial actions prevalent in federated learning.
Although the initial experiments applied to the APTOS 2019 dataset showed promising results, further testing of the MosMedData CT dataset provided validation of the strength of our approach. The PPFLHE framework was robust and had an average performance, regardless of the modality of the image, image resolution, or type of disease, indicating that it could be applied to a variety of clinical tasks. Data modality and distribution may have an effect on training dynamics as well as encryption performance. However, the model-agnostic symmetric scheme PPFLHE should generalize with the help of CKKS-based homomorphic encryption, so the connection to the model should be clean.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}