1. Introduction
Haze is an atmospheric phenomenon that degrades the quality of captured images [
1]. Image dehazing aims to remove haze from hazy images to enhance image quality, which is of significant importance in applications such as object detection [
2]. For instance, vision-based intelligent driving systems are severely affected under foggy conditions and must effectively remove haze to reconstruct high-quality, haze-free images. The formation of haze in images is typically modeled using the atmospheric scattering model, which can be expressed as follows.
where
represents the hazy image captured by the camera,
denotes the clean image to be restored,
is the atmospheric light value,
is the transmission map, and
is determined by the atmospheric scattering coefficient and the scene depth. In the early stages, dehazing algorithms primarily employed hand-crafted prior-based methods [
3,
4,
5]. These methods leveraged the statistical properties or physical models of images to guide the dehazing process. However, hand-crafted prior-based algorithms rely heavily on prior knowledge, and variations in scenes significantly impacted the dehazing performance of these methods. With the rapid development of deep learning, numerous scholars have utilized Convolutional Neural Networks (CNNs) for image dehazing [
6,
7,
8,
9,
10,
11,
12], achieving satisfactory experimental results. Nevertheless, these methods faced challenges such as limited receptive fields and suboptimal overall image restoration quality.
As Transformer models have gained widespread application in the field of computer vision, some scholars have proposed dehazing algorithms based on Transformer models [
5,
13]. However, while Transformers focus on long-range dependencies, they often introduce unnecessary blurring and retain coarse details during the image reconstruction process [
13].
Although the aforementioned image dehazing algorithms have improved dehazing performance, these methods focus on feature recovery in the spatial domain and neglect the impact of haze features in the frequency domain on image restoration. First, haze degradation is a complex nonlinear process, and these nonlinear coupled degradations lead to significant asymmetries in the frequency domain of the image. However, most existing network architectures primarily concentrate on feature learning in the spatial domain [
14,
15,
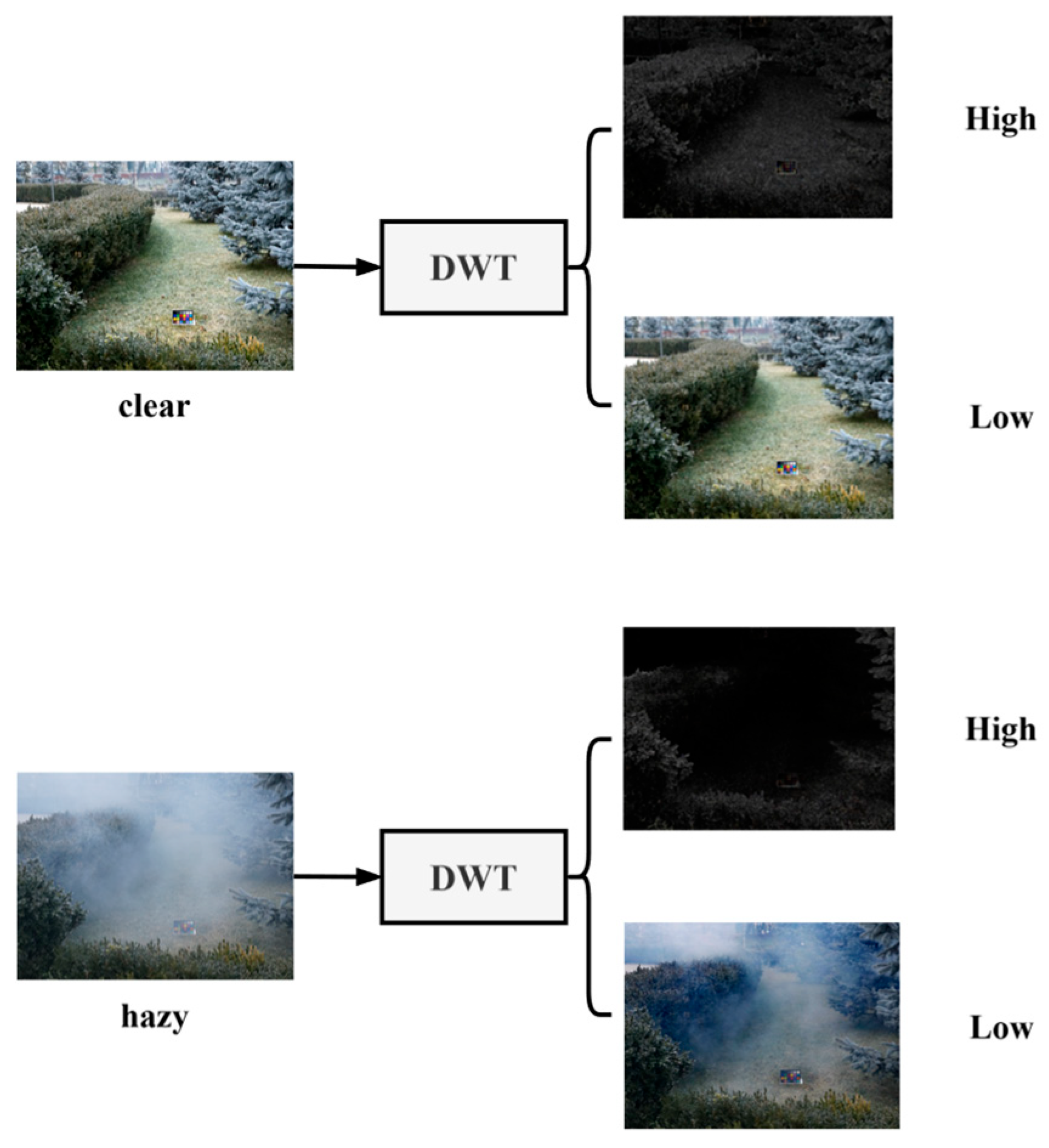
16], which is insufficient to fully express this nonlinear degradation. To illustrate this more clearly, we used the Discrete Wavelet Transform to separate the high- and low-frequency information in hazy and clear images, as shown in
Figure 1. The haze features in hazy images are predominantly present in the high-frequency features and severely interfere with the edge details of the image. Relying solely on spatial domain learning results in mediocre restoration outcomes. Subsequently, traditional CNN operations, limited by their receptive fields, struggle to capture long-range dependencies and non-local texture details. Even when Transformer structures are introduced on top of CNN operations to capture long-range dependencies, this approach still fails to eliminate the impact of haze on the frequency domain.
To address these challenges, we designed a Frequency-Guided Symmetric Dual-Branch Dehazing Network, which includes the Frequency Detail Extraction Module (FDEM), the Multi-scale Frequency-Guided Feature Extraction Module (DMFEM), and the Dual-Domain Guidance Module (DGM). Specifically, first, the FDEM focuses on frequency-domain feature learning. It transforms spatial-domain features into frequency-domain features, extracts both high-frequency and low-frequency features, and uses the global frequency features to guide the feature learning of the CNN module. Second, the DMFEM leverages gradient feature flows to extract local detail features from the image. Finally, the DGM aggregates features from the FDEM and DMFEM to enhance the perception of channel features and frequency-domain features.
Overall, our contributions are as follows.
We propose a novel dehazing network that utilizes frequency-domain information from the image to guide the spatial-domain feature learning for real-world image dehazing.
We propose the DMFEM, which enhances the extraction of spatial-domain features by utilizing convolutions with different kernel sizes and gradient feature information, thereby preserving the detail features of the image.
We introduce the FDEM to fully extract information across different frequencies, focusing particularly on high-frequency features and establishing long-range dependencies in the frequency domain. Additionally, we design the DGM to effectively integrate the frequency information generated by the FDEM with the spatial-domain information from the DMFEM, reducing redundant features and generating guiding weights.
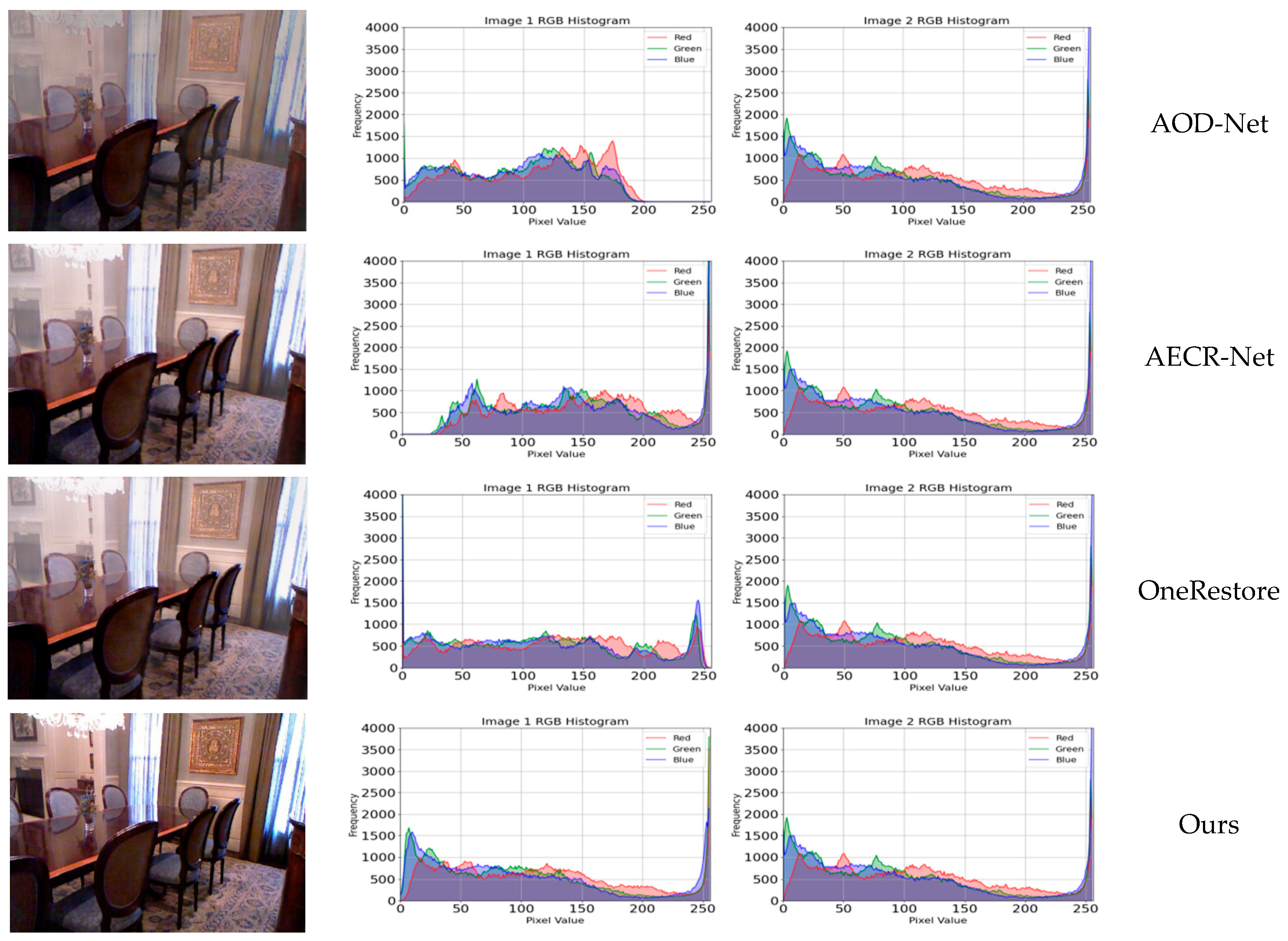
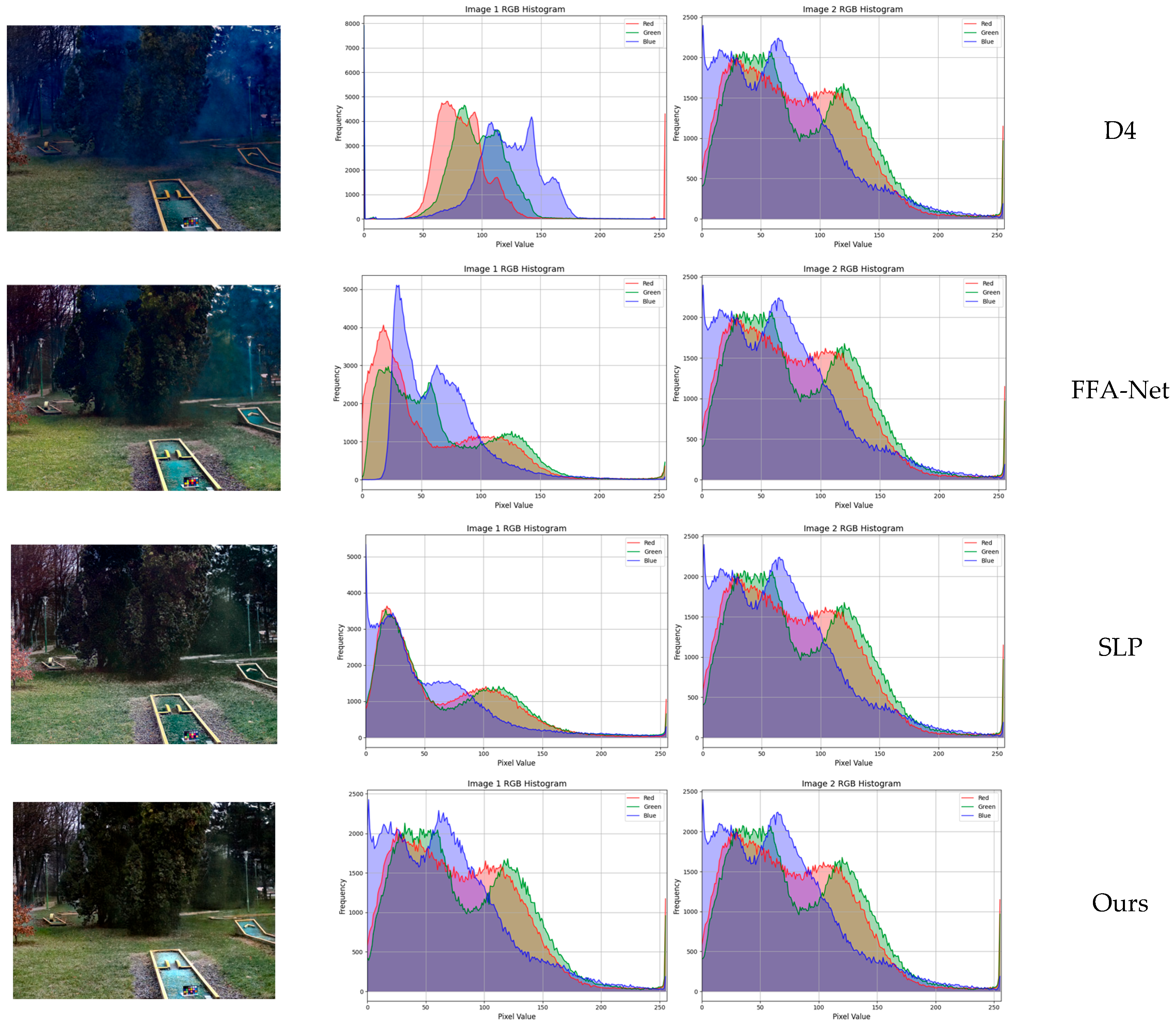
We conduct experiments on multiple synthetic datasets and real-world scenes, and the results demonstrate the superiority of our model.
3. Methodology
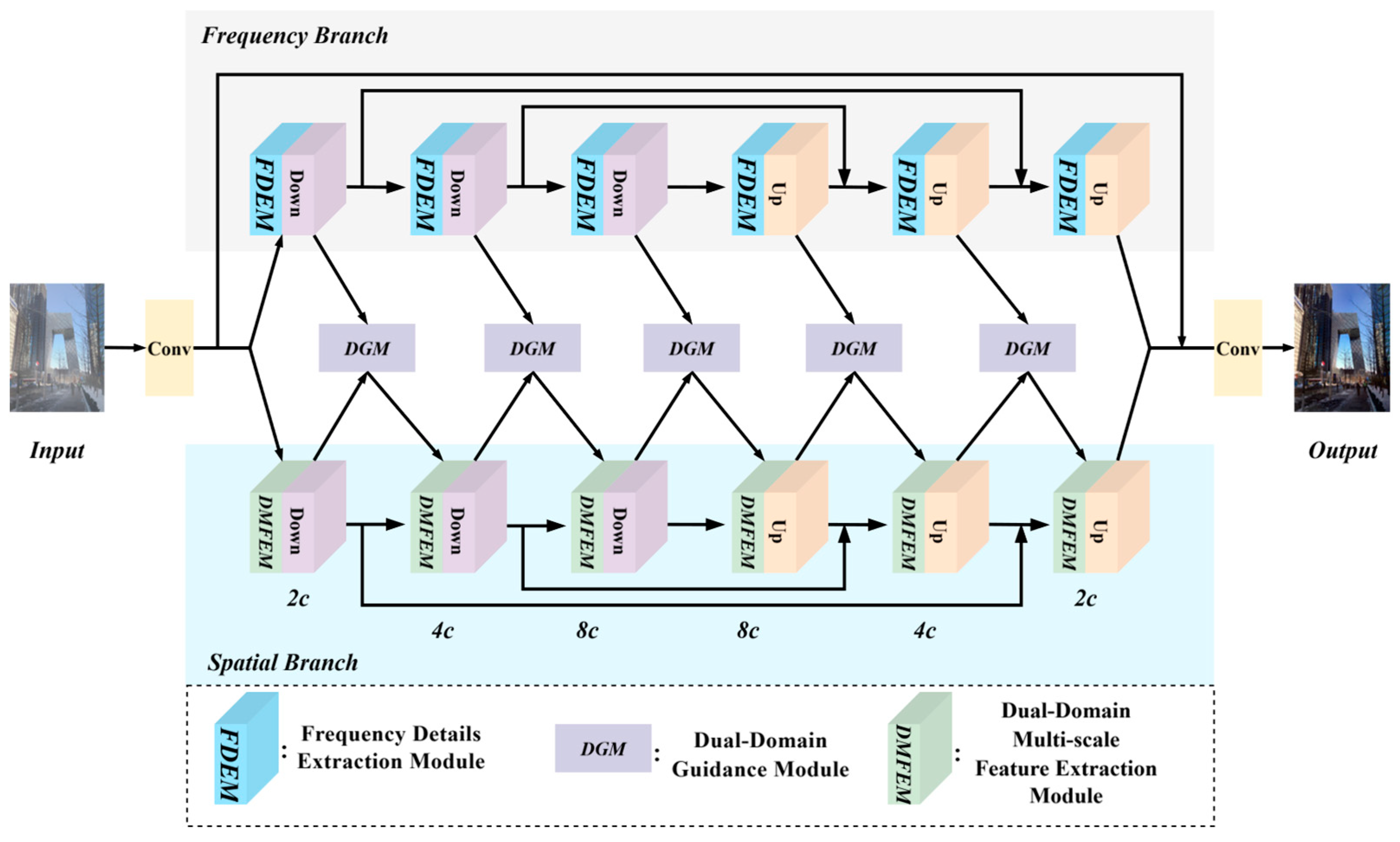
The overall architecture of the FIGD-Net is shown in
Figure 2, which mainly consists of three parts: the frequency branch, the spatial branch, and the Dual-Domain Guidance Module (DGM). The overall structure of the FIGD-Net is a dual-branch U-shaped architecture, with three downsampling operations for the encoding process and three upsampling operations for the decoding process in each branch. Both the downsampling and upsampling processes are implemented using strided convolutions.
Given a hazy image, the process begins with adjusting the number of channels using a 3 × 3 convolution. Subsequently, the feature map is fed into the two branches to extract spatial-domain features and frequency-domain features, respectively. During this process, the spatial-domain features and frequency-domain features are sent to the DGM to generate guiding weights, which are then fed back into the spatial branch to guide the learning process. Finally, multiple skip connections are used to preserve detail features and restore the clear image.
3.1. Dual-Domain Multi-Scale Feature Extraction Module
In the task of image dehazing, learning multi-scale features is of great importance [
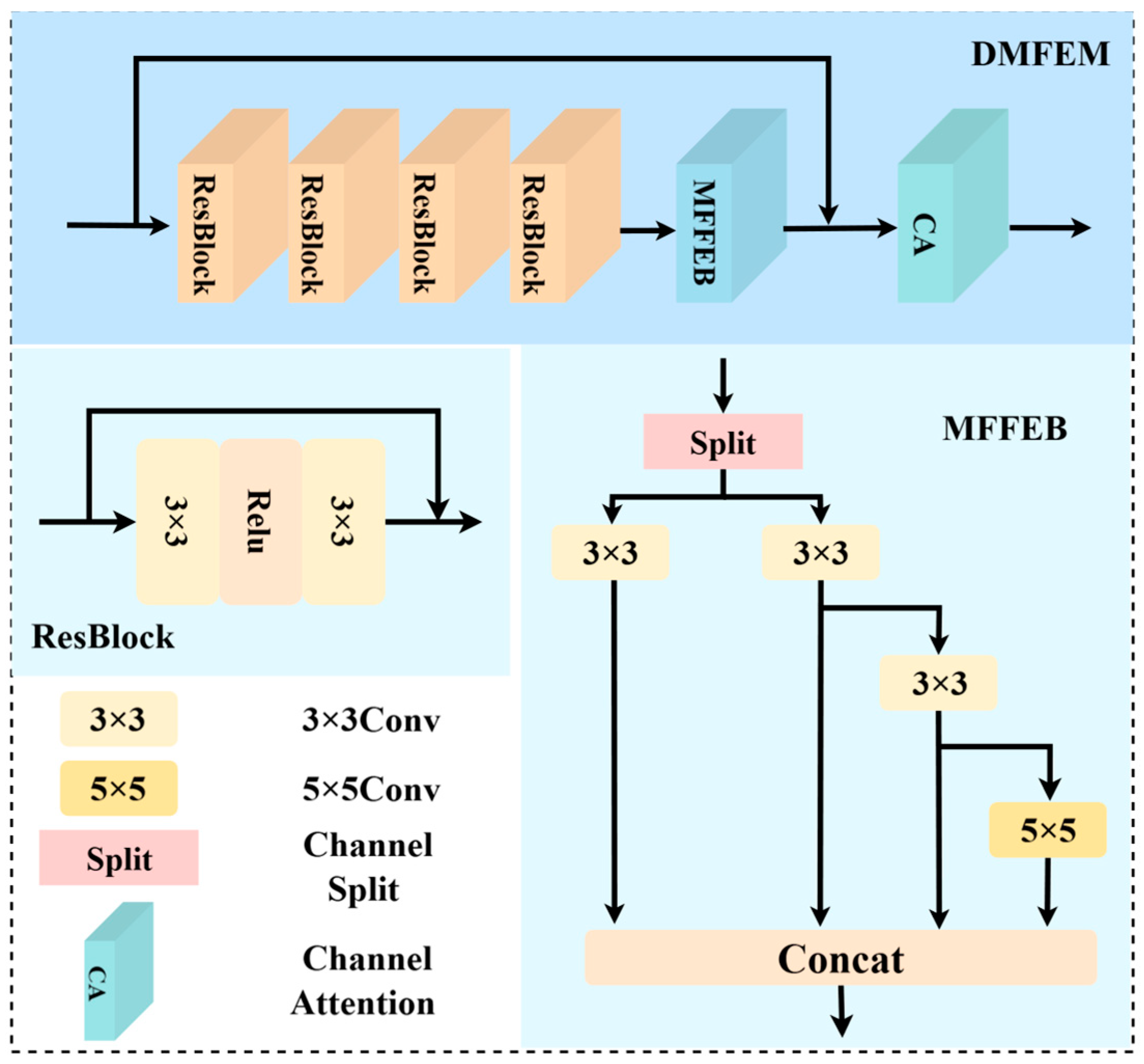
32]. Stacking convolutions with different kernel sizes is a simple way to obtain multi-scale features. However, the introduction of large convolution kernels also brings a significant computational burden. Moreover, since convolution is based on local perception, features extracted solely by convolution can lead to over-extraction of image edges and texture details, resulting in the retention of haze features. Therefore, we designed the Dual-Domain Multi-scale Feature Extraction Module (DMFEM), which consists of Residual Blocks (ResBlocks), Multi-scale Feature Flow Extraction Blocks (MFFEBs), and Channel Attention (CA). The overall structure is shown in
Figure 3.
First, by stacking multiple ResBlocks, we obtain the local detail features of the image and gradually integrate these local features. We then multiply the features generated by the ResBlocks with the frequency-guided weights generated by the DGM to adjust the feature information that each feature channel focuses on. This ensures that the subsequent processing pays more attention to haze features. The operation process is as follows:
where
denotes the feature input from the spatial branch,
represent the operation of the ResBlock, and
indicates the guiding weights generated by the DGM.
Subsequently, the frequency-guided weights are fed into the MFFEB (Multiscale Feature Flow Extraction Block). The MFFEB draws inspiration from the ELAN (Efficient Layer Aggregation Network) architecture in YOLOv7 [
33] and improves upon it. Specifically, the input features are split into two main branches, each receiving half of the channels. One of these branches is further divided into two sub-branches, with the channels being split equally again. The last branch uses a 5 × 5 convolution to further obtain multi-scale features, enhance feature representation, and prevent the vanishing gradient phenomenon that occurs with the continuous use of convolution kernels of the same size. This design effectively reduces computational complexity while leveraging both shallow detail information and deep semantic information, establishing long-range dependencies and enhancing the ability to capture multi-scale features and distinguish haze features. The operation process is as follows:
where
and
represent 3 × 3 convolution and 5 × 5 convolution. The padding and stride for the 3 × 3 convolution are both 1, and for the 5 × 5 convolution are 2 and 1, respectively.
,
,
, and
represent the first, second, third, and fourth branches, respectively.
Finally, the features are integrated through residual connections, and Channel Attention (CA) is applied to focus on the channel features, reducing the redundancy caused by the stacking of convolutions.
3.2. Frequency Details Extraction Module
Current dehazing algorithms perform well on artificially synthesized hazy datasets, as the haze distribution in these datasets is relatively uniform. Each clear image generates multiple hazy images that are perfectly aligned in both time and space. Therefore, even relying solely on CNNs or Transformer networks can achieve satisfactory dehazing results. However, when facing real-world datasets, existing algorithms often fall short due to issues such as misalignment and uneven haze distribution in the data. To address this issue, we design the Frequency Details Extraction Module, which aims to learn haze features in the frequency domain to enhance dehazing performance in real-world scenarios. The structure of this module is shown in
Figure 4.
To effectively extract frequency information, ref. [
27] employed convolutions with different kernel sizes to capture frequency information, while [
34] used a loss function to constrain the frequency information. However, these methods do not guarantee a fully controllable frequency separation. On the other hand, constraining frequency information using a loss function does not explicitly separate frequency components, leading to redundant feature information. Considering these limitations, we adopt the Discrete Cosine Transform (DCT), commonly used in image signal processing, to truly separate frequency components.
First, we perform the Discrete Cosine Transform on the input features. Leveraging the property that the high-frequency information of the image’s DCT is concentrated in the top-left corner of the feature map, we multiply the generated DCT matrix with a mask matrix to retain both high-frequency and low-frequency information. The high-frequency extraction operation is expressed as follows, and the low-frequency extraction is similar and will not be reiterated here:
where
represent the operations of Discrete Cosine Transform,
denote the generated mask matrix,
and
represent the height and width of the feature map, respectively.
represent the element-wise multiplication operation, and
represent the high-frequency information ratio, which is set to 0.05 in this paper.
Next, the Inverse Discrete Cosine Transform (IDCT) is employed to achieve lossless recovery of the original data. The extracted high-frequency and low-frequency information is then fed into a multi-head attention mechanism. By calculating the attention weights between the high-frequency and low-frequency information, the mechanism aggregates the haze-related features from both the low-frequency and high-frequency components. Leveraging the subspace properties of the multi-head attention mechanism, this process captures a more comprehensive set of haze features. The operation can be expressed as follows:
where
denotes the 1 × 1 convolution, which is used to map the high-frequency and low-frequency information into the query space;
represents the depthwise separable convolution;
splits
into Key and Value;
is a learnable parameter used to adjust the degree of attention focus; and soft is used to obtain the final weights.
Finally, the high-frequency feature information is integrated, and a 1 × 1 convolution is used to map the integrated features back to the original number of channels. The operation process can be expressed as follows:
3.3. Dual-Domain Guidance Module
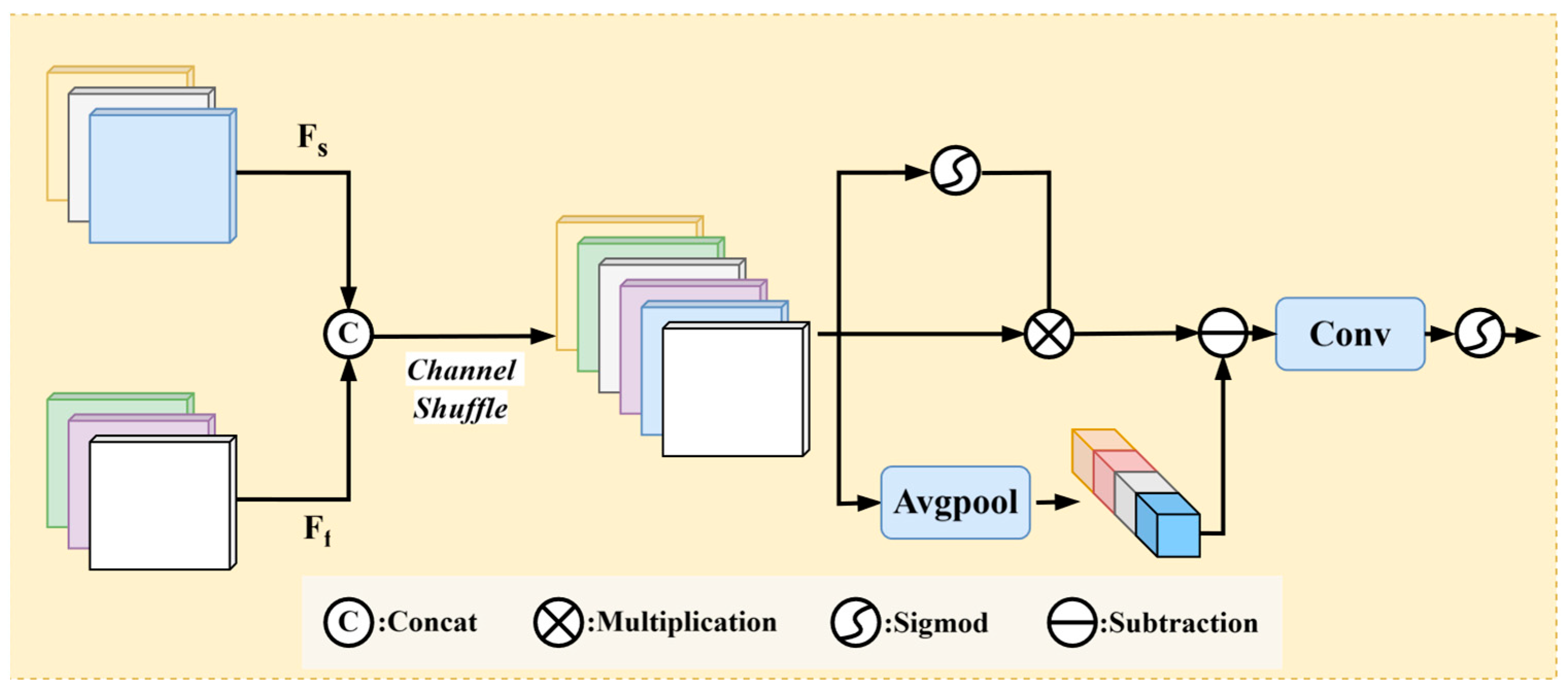
The frequency branch focuses on feature learning in the frequency domain and captures global signal features, while the spatial branch focuses on multi-scale local feature learning. To efficiently transmit the guiding information from the frequency domain to the spatial branch, we designed the Dual-Domain Guidance Module (DGM), the structure of which is shown in
Figure 5.
First, the feature maps from the two branches are concatenated and shuffled across channels, allowing for more thorough interaction and fusion of information between different channels. This mechanism helps to break down the isolation of information between channels, enabling the network to more effectively utilize multi-channel features.
Second, the shuffled feature map is passed through an average pooling operation to smooth the features and then subtracted to reduce overall haze interference, preserving the global structure in a balanced manner.
Next, a self-gating mechanism allows the model to dynamically select features that are more helpful for the dehazing task and more important frequency information, thereby enhancing the weights of key features.
Finally, a pointwise convolution adjusts the number of channels, and a sigmoid function generates the guiding weights, which are then fed into the spatial branch to guide its learning process.
The Dual-Domain Guidance Module breaks down the isolation of information between channels, fully interacts different domain features, smooths features through average pooling, reduces overall haze interference, and generates weight information to guide the feature learning in the spatial domain.
3.4. Loss Function
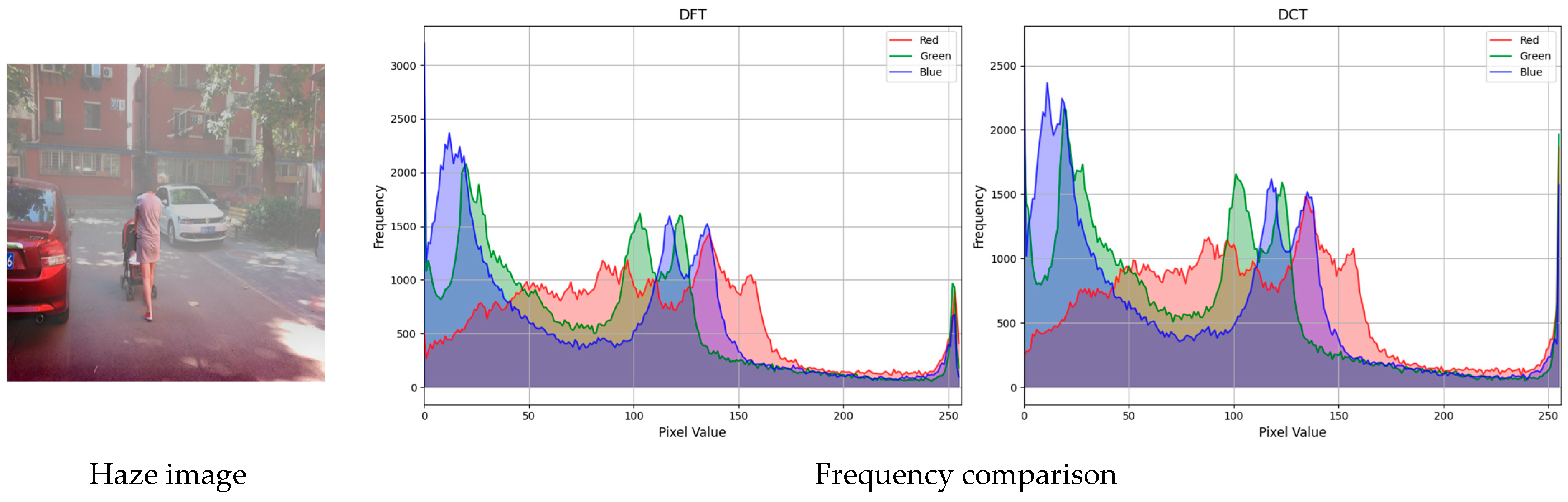
To enhance the feature learning capability in both domains, we propose a dual-domain combined
loss function to train the FIGD-Net. However, since PyTorch does not have a direct Discrete Cosine Transform (DCT) function, we implemented it manually. We conducted inference experiments with the Discrete Fourier Transform (DFT) loss function [
35] on the Haze4k dataset and analyzed the frequency bias between the inference results of the two to select the most suitable loss function. The results are shown in
Figure 6 and
Table 2.
From
Figure 6 and
Table 2, it can be seen that there is a certain frequency difference between the inference results of the DCT loss function and the DFT loss function, but it does not affect the image quality. This is due to the fact that DCT is a special case of DFT, and in terms of computational load, the DFT loss function requires much less computation than the manually implemented DFT loss function. Considering the model’s image dehazing capability and model size, we use the DFT as an alternative to the DCT. The definition is as follows:
where
represents the clear image,
represents the network-predicted image,
is the total number of elements used for normalization, and
is the Discrete Fourier Transform.
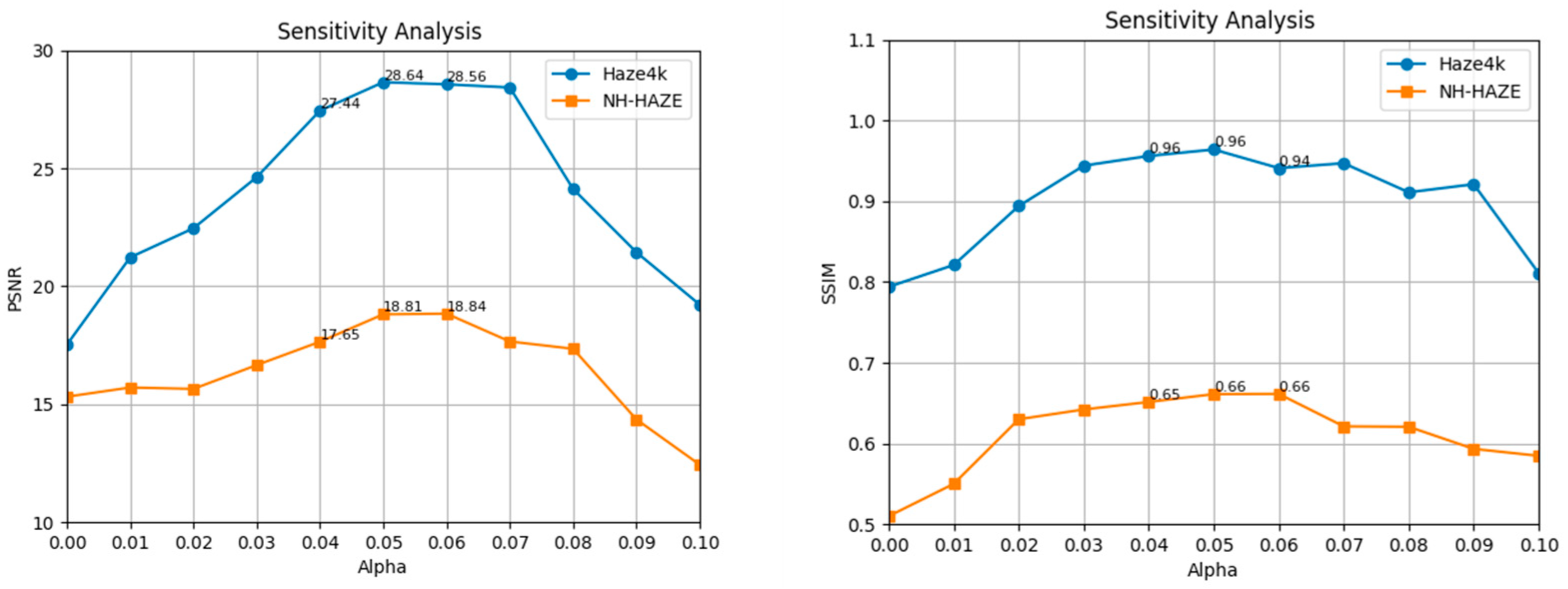
The final loss function is denoted as , with taking a value of 0.1.
5. Conclusions
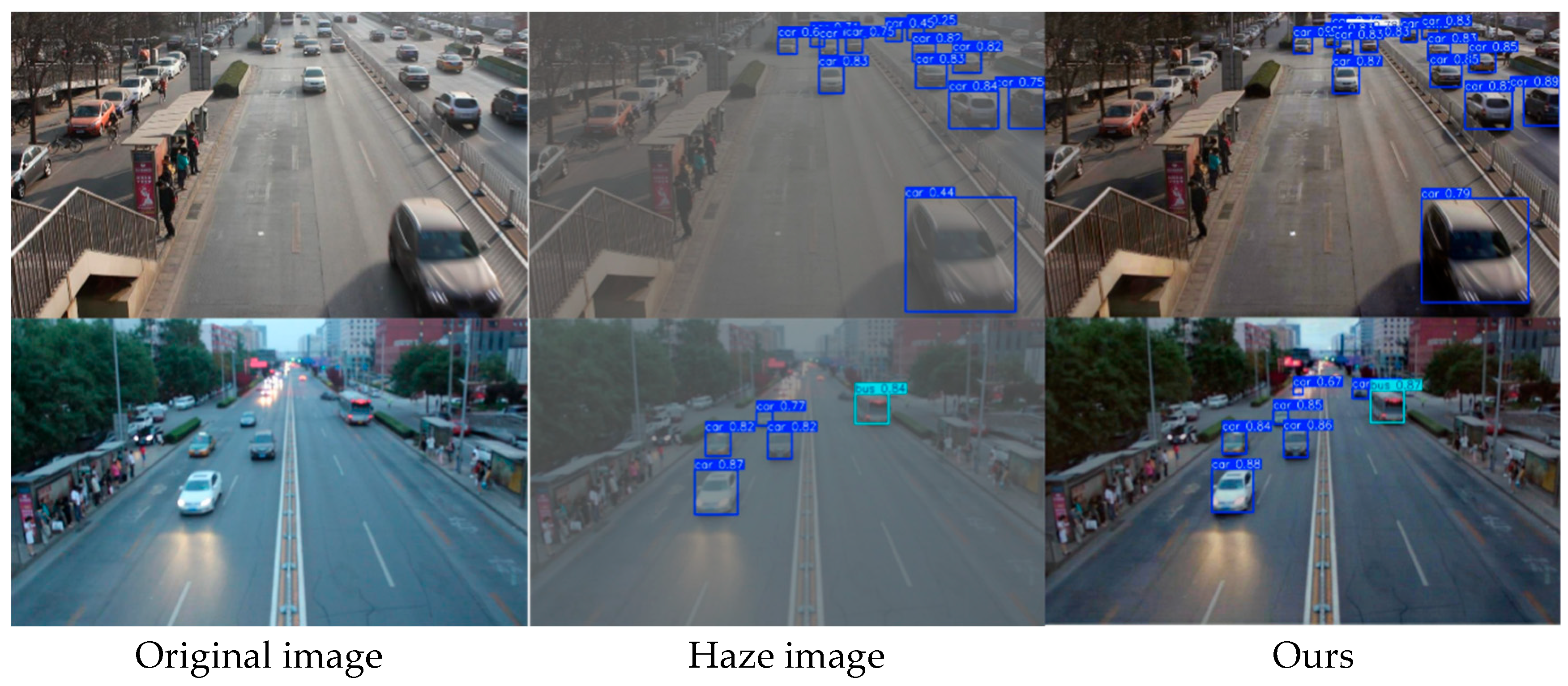
In this paper, we propose a symmetric dual-branch dehazing network guided by frequency-domain information. The proposed model mainly consists of three key modules: the Frequency Detail Extraction Module (FDEM), the Dual-Domain Multi-Scale Feature Extraction Module (DMFEM), and the Dual-Domain Guidance Module (DGM). The FDEM captures global haze features by learning frequency-domain features independently. The DMFEM extracts detailed image features through compact residual blocks and gradient feature information, and utilizes frequency-guided weights to more efficiently complete image restoration. The DGM acquires information from different feature domains, effectively fuses the information, and generates guidance weights for the spatial branch. Extensive experiments demonstrate that the network achieves optimal dehazing performance on multiple datasets. In addition, we applied the network to downstream tasks, which effectively improves the performance of object detection and provides assistance for the fields of intelligent transportation and autonomous driving. However, under extreme conditions, the use of frequency information may cause color differences in the dehazed images. In the future work, we will further optimize the FIGD-Net to enhance the image color restoration ability and explore the applications of FIGD-Net in other fields.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}