1. Introduction
Detecting anomalies and defects is critical in modern industrial production and quality assurance systems. Traditional manual inspection methods often suffer from low efficiency, poor stability, and high susceptibility to human subjectivity, which may compromise the consistency and reliability of the inspection results. As the manufacturing industry advances toward greater automation and intelligence, the demand for efficient, stable, and high-precision defect detection solutions has become increasingly urgent. Consequently, the development of automated, intelligent algorithms for anomaly detection has emerged as a prominent research focus in the fields of smart manufacturing and industrial automation. In recent years, unsupervised learning methods have gained widespread attention in defect detection tasks due to their low dependency on annotated data. Unlike supervised approaches, which require large quantities of labeled defective samples, unsupervised methods are typically trained using only normal (i.e., non-anomaly) samples to learn their underlying feature distributions. During inference, these methods allow for the identification of anomalies by detecting deviations from the learned patterns characterizing normal samples. Representative techniques in this category include reconstruction-based methods such as Autoencoders (AEs) [
1,
2], Generative Adversarial Networks (GANs) [
3,
4,
5], and density estimation approaches such as normalizing flows (NFs) [
6,
7,
8]. These methods aim to model the statistical characteristics of normal samples and enable the localization of anomalies without any exposure to defect data during training.
Despite the practical effectiveness of unsupervised methods, several challenges remain unresolved. First, reconstruction-based approaches (e.g., AEs and GANs) often retain anomalous features during image reconstruction, weakening their ability to distinguish between normal and defective regions; this leads to compromised detection accuracy and robustness. Second, although normalizing flows allow for direct estimation of the likelihood of input samples, their performance relies heavily on the quality of the extracted features. This limitation becomes especially pronounced in scenes with complex backgrounds or scenarios involving multi-scale defects, where their performance tends to deteriorate. Enhancing the robustness and accuracy of unsupervised anomaly detection methods under such challenging conditions remains a critical area of ongoing research.
To overcome the limitations of existing unsupervised methods in complex defect detection scenarios, we propose a novel anomaly detection framework, called UAMS, which differs from the baseline PyramidFlow [
9]. UAMS introduces two modules for task adaptation and structural redesign: Multi-Scale Attention Aggregation (MSAA) [
10] and Self-Supervised Prediction Convolutional Attention Block (SSPCAB) [
11].
In contrast to previous applications of these modules, we integrate them into a reversible pyramid structure to ensure enhanced semantic consistency and self-guided feature discrimination in an unsupervised setting. The MSAA module is placed after the pyramid decomposition stage to adaptively fuse multi-scale features, thus reducing information loss and improving the obtained hierarchical representation. The SSPCAB module is introduced before the invertible layers and incorporates a novel masked prediction mechanism with dual attention (channel and spatial) to capture both fine-grained details and global structure in a self-supervised manner.
These two redesigned modules are seamlessly embedded into the flow-based pipeline, resulting in a more powerful anomaly localization model.
The main contributions of this work are as follows:
- 1.
We propose a Multi-Scale Attention Aggregation (MSAA) module that performs weighted fusion on multi-scale feature maps [
12] generated by the pyramid structure. This design enhances semantic consistency across scales and improves robustness against complex backgrounds and fine-grained defects.
- 2.
We introduce a Self-Supervised Predictive Convolutional Attentive Block (SSPCAB), which integrates channel attention and spatial selection mechanisms to reinforce critical feature responses in early-stage representations. This design significantly improves the model’s generalization ability and robustness in structurally complex settings.
- 3.
We integrate both the MSAA and SSPCAB modules into the PyramidFlow framework, forming a complete architecture which we call UAMS. This new model achieves superior performance in unsupervised anomaly detection tasks—particularly in localizing multi-scale defects—demonstrating improved detection accuracy and stability.
Extensive experiments on the MVTec-AD [
13] benchmark dataset confirm that the proposed UAMS method, equipped with the MSAA and SSPCAB modules, outperforms existing state-of-the-art unsupervised methods in terms of both accuracy and robustness. By rethinking the foundations of flow-based anomaly detection frameworks, our model strikes a rare balance between theoretical rigor, practical deployability, and competitive performance, all without any external supervision. As such, the proposed model has strong scalability and potential for use in high-precision applications such as industrial quality inspection and medical image analysis.
The remainder of this paper is organized as follows.
Section 2 reviews recent developments in unsupervised anomaly detection, with a focus on reconstruction- and flow-based approaches, as well as the role of attention mechanisms.
Section 3 introduces the proposed UAMS architecture, detailing the integration of the Multi-Scale Attention Aggregation (MSAA) and Self-Supervised Predictive Convolutional Attentive Block (SSPCAB) modules.
Section 4 details the comprehensive experimental evaluations on the MVTec AD dataset, including ablation studies and a comparative analysis with state-of-the-art methods.
Section 5 discusses the practical implications, strengths, and limitations of UAMS, along with future research directions. Finally,
Section 6 concludes the paper.
2. Related Work
2.1. Reconstruction-Based Anomaly Detection
Reconstruction-based anomaly detection methods identify abnormal regions by measuring the difference between input images and their reconstructions, either in the pixel or latent feature space. Autoencoders (AEs) and their extensions—such as Variational Autoencoders (VAEs) [
2]—learn low-dimensional representations of normal samples through an encoder–decoder structure to reconstruct the input [
14]. To alleviate the problems associated with these models, Memory-Augmented Autoencoders (MemAEs) [
14] feature explicit memory mechanisms to constrain the latent space representation, thereby suppressing the reconstruction of abnormal regions. On the other hand, Generative Adversarial Networks (GANs) utilize an adversarial training approach involving a discriminator, encouraging the generator to synthesize samples which resemble those in the normal distribution. Nonetheless, GAN-based models often suffer from mode collapse during training, which hampers their ability to represent fine-grained anomalies [
4]. Recent approaches, such as GANomaly, have attempted to integrate adversarial loss with reconstruction objectives to optimize the latent representation and enhance the anomaly detection capability of the resulting models. Despite these efforts, such methods remain prone to false positives under complex background textures (e.g., wood or fabric), revealing their limitations in detecting subtle anomalies.
2.2. Probability-Based Anomaly Detection
Normalizing flow (NF) models perform explicit probabilistic modeling by learning invertible mappings between the data space and latent space. Typical NF-based models, such as RealNVP [
15] and Glow [
16], employ coupling layers to estimate high-dimensional densities without approximation sampling.
However, these models are often constructed using shallow convolutional architectures, limiting their ability to capture complex semantic information. In the context of industrial visual inspection, CS-Flow [
6] introduces a multi-scale flow-based architecture to enhance distribution modeling, but fails to consider spatial dependencies across feature scales. Subsequent frameworks, such as PyramidFlow, leverage pyramid decomposition mechanisms to improve multi-scale representation; however, they still exhibits limitations in terms of fine-grained anomaly localization.
In general, most existing studies have built on the RealNVP framework; however, their convolutional designs are primarily focused on local structures, leading to an inability to model complex semantics. To improve the quality of representations, some methods incorporate image patch embeddings to compensate for the global context limitations inherent in pure convolutional structures. Early approaches often used global image encoding combined with pretrained backbones, while recent works tend to favor lightweight pretrained encoders for the extraction of local features. Although such strategies can enhance the detection performance of models, their strong reliance on task-irrelevant external pretrained knowledge limits their generalization ability in out-of-distribution or previously unseen anomaly scenarios.
2.3. Attention Mechanisms in Anomaly Detection
In recent years, attention mechanisms have been widely adopted in visual tasks to improve the ability of models to focus on critical regions. Channel attention and spatial attention modules, such as SE-Net [
17] and CBAM [
18], re-weight feature maps to guide the model toward semantically significant areas. However, these static attention schemes often struggle to adapt to multi-scale defect patterns, making it difficult to capture dynamic cross-scale variations. To address this limitation, several studies have proposed multi-scale attention designs—such as MS-CAM [
19]—which concatenate features from different resolutions to expand the receptive field. Nevertheless, a systematic approach to modeling interactions across various scales is still lacking.
To overcome these challenges we propose the MSAA module, which introduces dynamic cross-scale interaction mechanisms within a pyramid-based normalizing flow method to enable the adaptive fusion of multi-scale features. Simultaneously, the SSPCAB module combines self-supervised prediction with attention mechanisms to enhance the model’s ability to capture local context and semantic consistency. Together, these modules effectively compensate for the limitations of traditional attention mechanisms in complex industrial anomaly detection tasks.
3. Materials and Methods
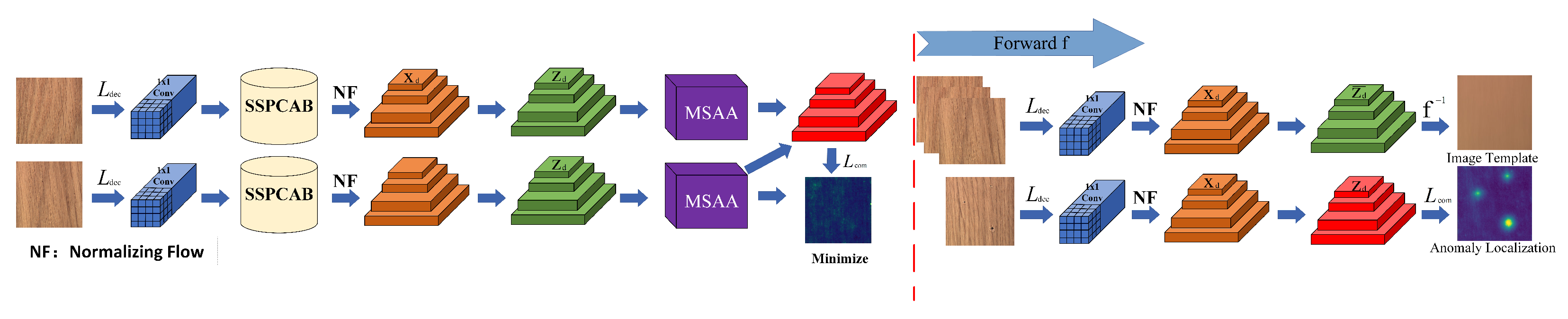
This section describes the overall architecture of the proposed method and elaborates on each component in detail. The proposed UAMS method consists of two primary stages: the training phase and the evaluation phase. These are illustrated in
Figure 1, which shows the overall workflow of the training and inference processes for PyramidFlow within UAMS. During training, we adopt a Siamese-style architecture with weight-sharing branches to facilitate effective feature learning. The feature recombination symmetry is utilized to coordinate the interactions between scale features by first down-sampling and then up-sampling. In the evaluation stage, the model extracts latent representations from normal training samples to construct reference templates. Subsequently, it performs feature comparison and multi-scale fusion to generate anomaly localization maps.
3.1. Normalizing Flow Modeling
Normalizing flow (NF) refers to a class of invertible neural networks that construct bijective mappings and allow for the explicit computation of Jacobian determinants, enabling the accurate modeling of input data distributions. Initially introduced for nonlinear independent component analysis [
20], NF has recently attracted significant attention in unsupervised anomaly detection tasks [
21] due to its reversible structure and robust density estimation capability. A typical NF architecture consists of multiple coupling layers, each of which is responsible for realizing nonlinear transformations while facilitating efficient Jacobian computation. The NICE [
21] was first proposed, including additive coupling layers with a unit Jacobian determinant, while RealNVP extended this design by introducing affine coupling layers that preserve volume while enabling tractable Jacobian computation. However, excessive volume freedom may increase the complexity of optimization and introduce a gap between maximum likelihood estimation and anomaly scoring, which can negatively impact the generalization ability of models in detection tasks.
Although most existing anomaly localization methods are based on RealNVP architectures, they still face several practical challenges. For example, some studies have shown that convolutional NF models tend to focus on local patterns rather than high-level semantics, which are typically captured through image embeddings. To address this, earlier approaches adopted pretrained backbones for feature extraction, while more recent methods have shifted toward patch embeddings derived from pretrained encoders. However, such reliance on task-irrelevant external priors can limit the generalization capability when deployed in out-of-distribution or unknown environments.
To address these limitations, this study extends the original PyramidFlow framework by constructing independent NF sub-networks at each level of the image pyramid to capture feature distributions across multiple scales. Furthermore, two key enhancement modules—namely, Multi-Scale Attention Aggregation (MSAA) and Self-Supervised Predictive Convolutional Attentive Block (SSPCAB)—are introduced to improve semantic fusion across scales [
22] and dual spatial–channel attention modeling, thereby significantly boosting the resulting model’s anomaly detection performance in complex scenarios.
3.2. UAMS: Anomaly Detection via Multi-Scale Normalizing Flow with Attention
To enhance robustness and accuracy in unsupervised anomaly detection, we propose an improved architecture based on the original PyramidFlow framework. While the original PyramidFlow utilizes a multi-scale image pyramid combined with NF to model the distributions of normal samples at various resolutions, it still relies on simple convolutional stacks with limited receptive fields and poor semantic understanding, ultimately restricting its ability to detect small-scale or high-frequency anomalies.
To address these limitations, we propose two novel modules: Multi-Scale Attention Aggregation (MSAA) and Self-Supervised Predictive Convolutional Attentive Block (SSPCAB).
MSAA enhances the model’s capacity to perceive diverse receptive fields by fusing multi-scale contextual features through attention mechanisms. It is embedded into each scale of the PyramidFlow sub-networks to refine feature representation before density estimation is performed.
SSPCAB, on the other hand, improves the model’s sensitivity to subtle and spatially localized anomalies through introducing a selective spatial–channel attention mechanism in a lightweight, self-supervised manner. It is integrated after the initial convolution layers of each sub-network, thus boosting feature discriminability.
While our method builds upon the backbone architecture of PyramidFlow [
9], two crucial innovations distinguish UAMS. First, we introduce the MSAA module, which enhances semantic feature fusion across different pyramid levels through a dynamic spatial and channel attention mechanism. Second, we integrate the SSPCAB before the normalizing flow modules to enrich local anomaly-aware features by reconstructing masked input regions in a self-supervised manner. These two modules are not present in the original PyramidFlow and significantly improve both the accuracy of anomaly detection and precision of localization (as confirmed in
Section 4).
3.3. Multi-Scale Attention Aggregation (MSAA)
Multi-scale representations are critical for robust feature modeling in the field of computer vision. Although pyramid structures offer a straightforward solution for multi-scale analysis, they often lead to semantic inconsistency and degraded performance due to discrepancies in receptive fields across scales. This issue is particularly pronounced in anomaly detection tasks that necessitate both the preservation of fine-grained details and global context modeling.
The detailed operation of the MSAA module is outlined in Algorithm 1, which provides a step-by-step procedure for spatial and channel attention fusion.
| Algorithm 1 Multi-Scale Attention Aggregation (MSAA) |
| Require: Feature map |
| Ensure: Enhanced feature map |
| 1: // Multi-scale convolutional fusion |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: // Spatial attention branch |
| 7: |
| 8: |
| 9: ▹ Element-wise multiplication |
| 10: // Channel attention branch |
| 11: |
| 12: |
| 13: |
| 14: ▹ Channel-wise multiplication |
| 15: |
| 16: return
|
To address the above-mentioned issues, we introduce the Multi-Scale Attention Aggregation (MSAA) module, whose architectural design and internal mechanisms are depicted in
Figure 2. In particular, it dynamically fuses multi-scale features while enhancing spatial and semantic alignment across the pyramid’s levels. MSAA employs parallel convolutional branches with varying kernel sizes (e.g., 3 × 3, 5 × 5, 7 × 7) to capture contextual information at different receptive fields. A combination of spatial and channel attention mechanisms is then used to refine the fused features [
23].
The MSAA module comprises two key paths: the spatial refinement path, which enhances the spatial localization of anomalies by applying multi-scale convolutions, followed by average and max pooling to generate a spatial attention map. This map is used to re-weight the original feature map. Meanwhile, the channel aggregation path learns global dependencies among channels using global average pooling and a two-layer fully connected network with ReLU and sigmoid activations. The resulting channel attention is applied in a multiplicative manner to reinforce important feature channels.
This design allows MSAA to effectively emphasize anomaly-relevant spatial patterns and semantic details with minimal computational overhead, making it well-suited for real-time industrial applications.
3.3.1. Overview of the MSAA Module
The Multi-Scale Attention Aggregation (MSAA) module is designed to enhance the cross-scale feature fusion performance, improving the model’s ability to perceive and represent multi-scale anomalies.
Let the encoder extract features from different levels, denoted as F1, F2, and F3. These features are concatenated along the channel dimension and passed through a fusion function to generate the aggregated feature representation
:
where Concat(·) denotes concatenation along the channel axis and F(·) typically consists of standard convolution followed by a nonlinear activation function. The resulting feature,
, is fed into two parallel branches—namely, the spatial refinement path and channel aggregation path—which enhance feature expression in spatial and semantic dimensions, respectively, thereby increasing the model’s sensitivity to multi-scale anomalies.
3.3.2. Spatial Refinement Path
The spatial refinement path focuses on improving the model’s localization capability, especially in scenes with complex backgrounds where anomalies may be subtle and difficult to detect. First, a 1 × 1 convolution reduces the number of channels in from to , where is a reduction ratio.
Next, multi-scale convolutions with kernel sizes of 3 × 3, 5 × 5, and 7 × 7 are applied in parallel to extract rich spatial context:
To enable the network to detect anomalies of varying spatial sizes, we design a multi-branch convolutional module using three different kernel sizes: 3 × 3, 5 × 5, and 7 × 7. This configuration is motivated by the need to balance fine-grained feature extraction and broad contextual understanding. The 3 × 3 kernel focuses on capturing local texture and edge details, which are essential for detecting small-scale surface defects. The 5 × 5 and 7 × 7 kernels progressively expand the receptive field, allowing the model to integrate medium- and large-scale structural information that is critical for the identification of contextual or distributed anomalies.
This design aligns with prior work on multi-scale representation learning (e.g., inception modules), where parallel convolutions of increasing kernel size have been shown to enhance spatial awareness. In our case, this setup ensures sufficient scale diversity while maintaining a tractable computational cost. We empirically found that the combination of 3 × 3, 5 × 5, 7 × 7 kernels consistently produced stable and high-quality results during development, and performed better than alternatives such as using only small kernels or incorporating overly large ones (e.g., 9 × 9), which may cause oversmoothing and/or increased computational burden.
Then, average pooling and max pooling [
24] are applied to
, and their outputs are concatenated and passed through a 7 × 7 convolution followed by a sigmoid activation to generate the spatial attention map:
where
(·) denotes the sigmoid function, ⊕ indicates channel-wise concatenation, and ⊙ denotes element-wise multiplication.
This path enables the model to focus more effectively on fine-grained anomalies while maintaining low computational overhead, making it suitable for industrial applications [
25] with high demands for both accuracy and real-time performance.
3.3.3. Channel Aggregation Path
The channel aggregation path aims to model global dependencies across channels and enhance the semantic discriminative power of the features. Given an input feature map F, global average pooling (GAP) is first applied to generate a channel-wise descriptor Z.
This descriptor is then passed through a two-layer fully connected network (or 1 × 1 convolutions) with ReLU and sigmoid activations to generate a channel attention map:
where
are learnable weight matrices (e.g., 1 × 1 convolutional kernels),
(.) denotes the ReLU activation, and
(.) denotes the sigmoid function.
The attention map
is then broadcast to match the shape of the spatially enhanced feature map
, and the two are combined via element-wise multiplication:
The final output, , integrates both spatial- and channel-level information, enabling the model to focus on discriminative patterns across dimensions.
3.3.4. Contribution of MSAA to Feature Optimization
The channel aggregation path in the MSAA module plays a crucial role in enhancing semantic discriminability by modeling inter-channel dependencies and promoting consistency among features extracted at different pyramid levels. Applying global average pooling to compress spatial dimensions, followed by a two-layer fully connected network [
26], the module nonlinearly learns channel relationships and produces attention weights. These weights are then used to adaptively re-weight the input features, amplifying responses in anomaly-sensitive channels while suppressing redundant or irrelevant ones. This lightweight design strengthens selectivity while preserving the method’s architectural simplicity, thus balancing expressive power with computational efficiency. As such, the proposed mechanism supports robust multi-scale feature fusion and improves overall discrimination performance. From the perspective of feature optimization, MSAA contributes to three additional key aspects:
- 1.
Enhancing the Local Feature Representation: Through multi-scale convolutions (e.g., 3 × 3), the model captures spatial information under various receptive fields. Combined with channel-wise fusion, this enables the model to detect fine-grained anomalies more effectively.
- 2.
Improving Feature Diversity: Compared to traditional single-scale feature extraction, MSAA increases the receptive field range and enriches semantic hierarchies without significantly increasing computational cost, enhancing sensitivity to anomalies of different sizes.
- 3.
Optimizing Feature Aggregation Strategy: Using 1 × 1 convolutions for dimensionality reduction and expansion enables the efficient integration of multi-scale features, reducing redundancy while maintaining discriminative performance.
Overall, these mechanisms make MSAA highly effective in complex scenarios, particularly for anomalies involving local structural deformations.
3.4. Self-Supervised Predictive Convolutional Attentive Block (SSPCAB)
In complex or structurally diverse images, traditional convolutional operations often struggle to effectively model the inter-channel dependencies in feature maps. This challenge is particularly critical in anomaly detection tasks, where the absence of adaptive channel weighting may result in insufficient expression of key anomalous features, thereby degrading the model’s overall detection performance.
The implementation details of SSPCAB are described in Algorithm 2, illustrating how the module integrates convolutional branches, SE attention, and self-supervised loss.
| Algorithm 2 SSPCAB: Self-Supervised Predictive Convolutional Attentive Block |
| Require: Input feature map , patch size , masking ratio |
| Ensure: Reconstructed feature map |
| 1: Divide x into non-overlapping patches of size |
| 2: ▹ Total number of patches |
| 3: Randomly select patches per image and per epoch |
| 4: Initialize binary mask with 1s |
| 5: Set selected patch regions in M to 0 (i.e., masked) |
| 6: ▹ Apply binary mask to input |
| 7: ▹ Compute padding size |
| 8: |
| 9: ▹ Define boundary shift |
| 10: ▹ Top-left region |
| 11: ▹ Bottom-left region |
| 12: ▹ Top-right region |
| 13: ▹ Bottom-right region |
| 14: ▹ Fuses contextual information from visible regions |
| 15: |
| 16: ▹ SE-based channel attention |
| 17: |
| 18: |
| 19: |
| 20: ▹ Predict missing content using attended context |
| 21: During training: |
| 22: return |
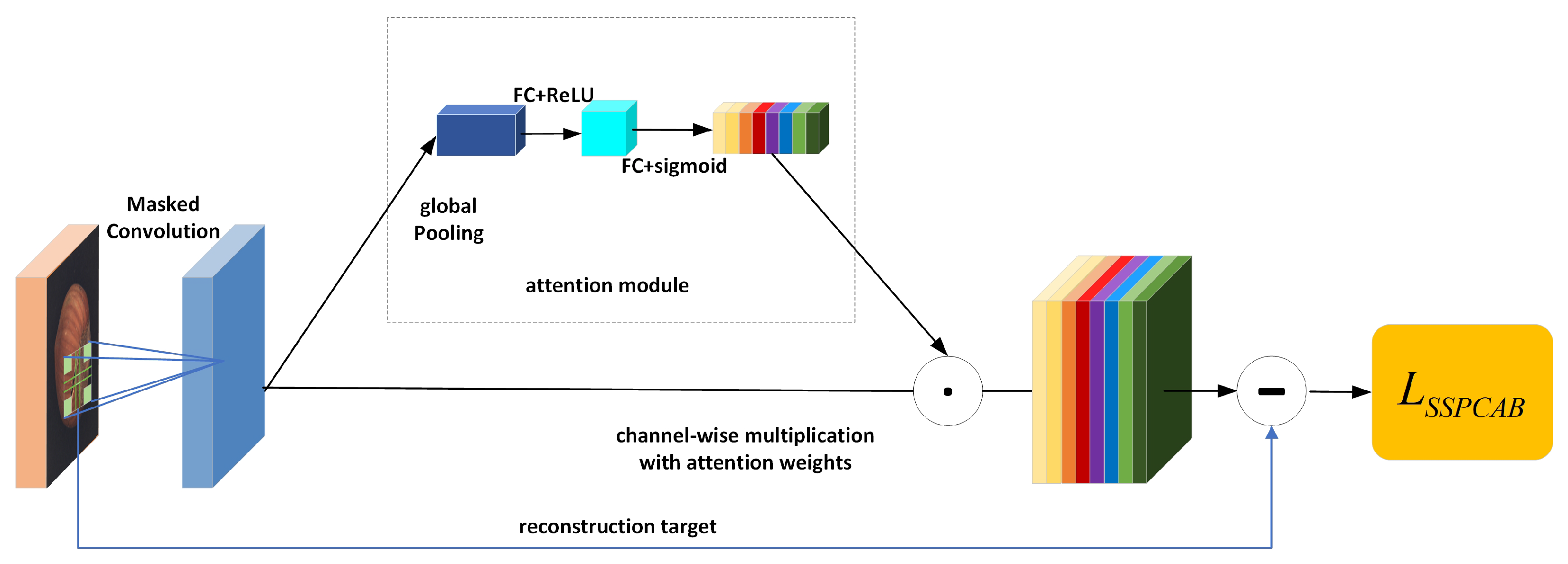
To address the abovementioned issues, we introduce the Self-Supervised Predictive Convolutional Attentive Block (SSPCAB). Its structure and function are illustrated in
Figure 3, integrating multi-scale convolutional structures, channel attention mechanisms, and a self-supervised learning strategy. The purpose of this module is to enhance the representational power of the model and improve its anomaly detection performance in complex scenarios.
Although the Self-Supervised Predictive Convolutional Attentive Block (SSPCAB) incorporates non-invertible operations (e.g., convolution, ReLU, attention), it is applied before the normalizing flow layers. Therefore, it does not affect the flow model. This design follows prior works such as DRAEM [
27] and FastFlow [
8], where non-invertible modules serve as feature enhancers prior to flow-based modeling.
3.4.1. Architecture Details
To enable self-supervised learning, we apply a patch-wise random masking strategy during training. Specifically, the input feature map
is divided into non-overlapping patches of size
. We randomly select 30% of the patches per image and per epoch and set the corresponding regions to zero, forming a binary mask
. The masked input is then computed as
. This stochastic masking ensures that the network learns to infer the missing content from surrounding visible regions. To enhance the perception of structures at different scales, the masked input
is first zero-padded and then processed by four parallel convolutional branches with shifted regions: top-left (TL), bottom-left (BL), top-right (TR), and bottom-right (BR). The outputs are fused by element-wise addition:
In Equation (
8), each
denotes a convolution applied to a distinct masked sub-region of the input, corresponding to the top-left, bottom-left, top-right, and bottom-right quadrants, respectively. This nonlinear activation not only suppresses insignificant responses but also enhances the model’s selectivity for salient regions. In addition, ReLU alleviates gradient vanishing issues, thereby contributing to more stable and efficient training.
To strengthen inter-channel dependency modeling, we employ a squeeze-and-excitation (SE) attention mechanism. This module first applies global average pooling to each channel to obtain a global context vector. Then, a two-layer fully connected network followed by a Sigmoid activation function generates channel-wise attention weights. These weights are broadcast and applied to the original feature map via channel-wise multiplication, enabling dynamic enhancement of critical channels.
3.4.2. Self-Supervised Prediction with Masked Reconstruction Loss
To prevent the network from simply interpolating or copying surrounding context to reconstruct masked regions, SSPCAB incorporates a self-supervised prediction task. During training, the input feature map is divided into 4 × 4 non-overlapping blocks, with 30% of the blocks randomly selected and masked [
28], and the network is trained to predict the missing content. The objective is to minimize the reconstruction error between the predicted and ground truth pixels:
where
and
are the predicted and true pixel values of the masked region, respectively, and N denotes the number of masked pixels.
This self-supervised strategy ensures that the network learns more discriminative latent features, rather than relying on trivial contextual inference. Additionally, SSPCAB facilitates integration with dilated convolutions, allowing the receptive field to be adjusted. This enables the model to capture both local and global contextual information, depending on the complexity of the considered application.
To converge the self-supervised loss in SSPCAB, we first use an attenuation weight table to calculate the loss. We plan to start from 1.0 and linearly reduce it to 0.1 in the first 15 cycles. Next, set the size of the convolution kernel in the receptive field perception structure to 3 and the dilation rate to 2. In addition, we use a reduction ratio of 8 in the SE block to maintain a strong balance between parameter efficiency and attention modeling ability.
3.4.3. Contributions of SSPCAB to Feature Optimization
From the perspective of feature optimization, SSPCAB significantly enhances the model’s representational ability and detection performance in the following three aspects:
- 1.
Enhanced Channel Selectivity for Anomalies: The channel attention mechanism adaptively adjusts the importance of each channel, allowing channels which are sensitive to anomalous patterns to receive stronger activation responses. This suppresses redundant or irrelevant features and significantly improves the model’s discriminative capacity.
- 2.
Improved Anomaly Localization via Spatially Selective Modeling: Through its attention-driven architecture and feature re-weighting, SSPCAB enhances the network’s focus on spatially relevant anomaly regions. This design ensures stronger responses to critical areas while reducing the influence of background noise.
- 3.
Robust Multi-Scale Feature Aggregation: Integrating multi-scale convolution and attention mechanisms, SSPCAB effectively captures and integrates anomaly features at multiple resolutions. This design strengthens the model’s generalization ability in both subtle and large-scale anomaly scenarios.
Although the SSPCAB incorporates non-invertible operations—such as multi-scale convolution, ReLU activation, and spatial–channel attention mechanisms—it is purposefully positioned before the core normalizing flow modules. As a result, the invertibility of the flow-based architecture remains intact. This decoupled design allows SSPCAB to serve purely as a feature enhancement module, enriching the semantic content of input features without interfering with the flow network’s ability to compute exact likelihoods via bijective mappings.
Furthermore, the self-supervised masked prediction task embedded within SSPCAB is applied exclusively during training and operates on the intermediate feature space. This auxiliary task encourages the encoder to learn more discriminative and anomaly-sensitive representations through the prediction of masked regions, thereby increasing its robustness to local and subtle defects. Importantly, this loss does not affect the flow model during inference.
This architectural separation follows a similar rationale to that of prior flow-based methods, such as FastFlow and DRAEM [
27], in that non-invertible modules are utilized for pre-processing or training guidance while preserving the theoretical guarantees of the flow model. Therefore, the inclusion of SSPCAB enhances the overall expressiveness and localization performance of the proposed method without compromising its core probabilistic modeling principles.
4. Results
We conducted unsupervised anomaly localization experiments on the MVTec Anomaly Detection (MVTecAD) dataset [
2], a widely used benchmark for industrial anomaly detection. This dataset comprises 15 categories of industrial defects, including 5 texture categories and 10 object categories. We evaluated the performance of models using two widely accepted metrics, allowing for comprehensive and fair comparisons: Area Under the Receiver Operating Characteristic Curve (AUROC) and Area Under the Per-Region Overlap (AUPRO). AUROC is one of the most commonly used evaluation metrics for anomaly detection, with a higher AUROC indicating that a model is more robust across varying threshold settings. However, AUROC tends to favor large-area anomalies and may be less sensitive to small or subtle defects. To complement this, we introduce AUPRO—a metric analogous to the Intersection over Union (IoU) [
29] in the context of semantic segmentation—which evaluates the localization accuracy of anomaly regions at various thresholds.
4.1. Effectiveness of the MSAA Module
We evaluated the impacts of the MSAA module on the feature representation and anomaly detection performance with respect to the MVTecAD dataset. To ensure consistent experimental conditions, we set the number of pyramid levels to L = 4, the number of feature channels to C = 16, and resized all input images to 256 × 256 resolution via bilinear interpolation. During training, the MSAA module first applies a 1 × 1 convolution to reduce channel dimensionality, followed by multi-scale convolutions with 3 × 3, 5 × 5, and 7 × 7 kernels to extract contextual information. A final 1 × 1 convolution restores the original channel size for downstream processing. We conducted extensive experiments based on the MSAA design, and the results are quantitatively summarized in
Table 1, which details the AUROC and AUPRO metrics across object and texture categories, described in
Section 3.1, and allows for comparison of the anomaly detection results across various object and texture categories.
As shown in
Table 1, including the MSAA module led to consistent improvements across most categories, as reflected in both the AUROC and AUPRO metrics. Further analysis of the feature distribution maps revealed that MSAA provided notable performance gains in structurally complex object categories such as capsule, pill, and toothbrush. Although improvements were also observed in texture categories (e.g., carpet, grid, zipper), the magnitude of gains was relatively modest in comparison. This indicates that MSAA is particularly effective in enhancing local structure modeling, thereby improving anomaly detection performance for object-type defects.
In summary, the performance improvements of MSAA are more prominent in object categories than in texture categories. This can be attributed to MSAA’s strong capability to enhance representations of fine-grained structural features. For anomalies with well-defined geometric deformations (e.g., capsule, pill), MSAA can accurately capture shape distortions, improving the detection precision. In contrast, its impact on large-area or homogeneous texture anomalies remains relatively limited. These results confirm the practical effectiveness and potential of MSAA in boosting detection performance for structure-dominated industrial anomalies.
4.2. Effectiveness of the SSPCAB Module
To evaluate the effectiveness of the Self-Supervised Predictive Convolutional Attentive Block (SSPCAB), we present performance comparisons in
Table 2, from which it can be seen to demonstrate consistent gains across various anomaly types. We conducted controlled experiments on the MVTecAD dataset by integrating SSPCAB into the front-end of the UAMS method, with the goal of assessing its impacts on feature expressiveness and anomaly detection accuracy under complex structural conditions. During training, SSPCAB combines multi-scale convolutions (3 × 3, 5 × 5, 7 × 7, and 9 × 9), channel attention via squeeze-and-excitation (SE) blocks, and a self-supervised masked region prediction loss. This hybrid structure aims to improve the model’s sensitivity to subtle anomalies by learning more discriminative representations. To ensure consistency, we retained the same hyperparameters used in the MSAA experiments: all input images were resized to 256 × 256, feature channels were set to C = 16, and the number of pyramid levels was L = 4. We evaluated the effect of SSPCAB by integrating it into the PyramidFlow baseline and comparing the performance metrics (i.e., AUROC and AUPRO). Representative results are summarized in
Table 2.
As shown in
Table 2, the inclusion of SSPCAB led to consistent performance improvements across both object and texture categories. In object categories such as metal nut, screw, and toothbrush, the improvement in AUPRO was especially pronounced, indicating that SSPCAB enhances the model’s localization precision for fine-grained defects. Even in texture categories such as tile and wood, in which local texture irregularities dominate, SSPCAB was found to contribute measurable gains.
These experimental results validate the effectiveness of SSPCAB in improving the model’s robustness, especially in scenarios involving subtle, spatially localized defects. Its lightweight and modular design makes it a valuable addition to the UAMS method, enabling accurate and efficient anomaly detection without significantly increasing the computational cost.
4.3. Comparative Evaluation on the MVTecAD Dataset
We conducted pixel-level anomaly localization experiments involving comprehensive comparisons with existing state-of-the-art methods on all 15 registered categories in the MVTecAD dataset, with the results detailed in
Table 3. To ensure fair evaluation, we categorized all methods that rely on pretrained models or external datasets as “external prior-based” approaches, as listed in the first column of
Table 3. In our implementation, we applied only basic data augmentation—namely, random horizontal flipping and rotation (each with a probability of 0.5)—to texture categories. No augmentation was applied to object categories, in order to avoid introducing external bias. Moreover, we deliberately excluded methods that employ complex data augmentation schemes or weak supervision strategies to maintain purity in the comparative setting, although our proposed method is theoretically compatible with such techniques and could potentially benefit further from them.
To ensure a fair and consistent comparison with prior methods, we report the AUROC results of various baseline models on the MVTec AD dataset by directly citing the values from the PyramidFlow [
9] study. All results in
Table 3—except for those for our proposed method—are taken as-is from that paper. This approach was necessary due to a lack of access to the original training configurations and codebases of several prior methods. Notably, in the PyramidFlow study, a comprehensive and systematic benchmark test was performed under a unified evaluation protocol, making the reported results a reliable reference for comparative analysis.
To conduct a balanced comparison, we included three representative unsupervised baseline methods that do not rely on external priors: AnoGAN, Vanilla VAE [
30], and AE-SSIM. These models served as fair baselines for direct comparison with our method. In addition, we compared our method against several external prior-dependent approaches, such as S-T [
32] and SPADE [
33], which utilize pretrained networks or external datasets for improved performance. All comparison methods were either adopted from their official implementations or reproduced using the AnomaLib method. To ensure consistent feature representations, we replaced the original 1 × 1 convolution modules in some models with the first two layers of a pretrained ResNet-18, extracting features at 1/4 spatial resolution with 64 channels.
We have noticed that the performance improvement in categories such as tiles and wood is relatively small. These categories often lack clear geometric structures and have small differences between samples, which fail to utilize the performance of UAMS fully.
Figure 4 shows a case of wood. Although anomalies can be visually observed from the original image, due to the lack of clear defect structures and weak contrast with normal patterns, the heatmap does not highlight the anomalies with high brightness.
4.4. Complementary Roles of SSPCAB and MSAA
To improve feature representation and anomaly localization, UAMS integrates two complementary modules: SSPCAB and MSAA. SSPCAB is applied after the encoder to enhance local anomaly-sensitive features through self-supervised masking and spatial–channel attention, while MSAA functions later in the pipeline to aggregate multi-scale spatial information after pyramid decomposition using adaptive convolutions (3 × 3, 5 × 5, 7 × 7). The two modules focus on different aspects of feature learning: SSPCAB refines fine-grained local details, and MSAA ensures semantic consistency across scales. Their combination avoids redundancy and leads to mutually reinforcing effects, resulting in more accurate and informative representations for robust anomaly detection.
Compared to CS-Flow [
6], which often yields fragmented or diffuse heatmaps, UAMS produces sharper and more coherent anomaly localization, particularly in texture-rich or small-defect categories such as capsule, pill, and zipper. These qualitative advantages are supported by higher pixel-level AUROC scores, as shown in
Table 3.
4.5. Evaluation on the BTAD Dataset
To further evaluate the generalization capability of UAMS in the context of industrial anomaly detection, we conducted additional experiments on the BeanTech Anomaly Detection (BTAD) dataset [
35], which consists of three visually and structurally diverse defect categories (Class01, Class02, Class03).
Table 4 summarizes the performance of PyramidFlow and our proposed method under two experimental settings: (1) a backbone-free setting with no external priors, and (2) a standard setting using ResNet-18, consistent with the PyramidFlow [
9] implementation.
In the absence of external priors, UAMS achieved an average image-level AUROC of 92.5% and pixel-level AUROC of 94.8%, outperforming PyramidFlow across all categories. Under the ResNet-18 configuration, the AUROC values obtained with UAMS further improved to 96.7% (image-level) and 97.9% (pixel-level), again surpassing PyramidFlow. These results demonstrate the model’s strong anomaly localization and classification capabilities.
Furthermore, these results highlight the robustness of our method across both constrained and standard settings. Notably, UAMS achieved high performance metrics even without pretrained backbones or dataset-specific tuning, confirming its suitability for deployment in real-world scenarios where computational resources or domain-specific priors may be limited.
Overall, UAMS consistently outperformed PyramidFlow in both settings, validating the effectiveness of the proposed MSAA and SSPCAB modules in enhancing the model’s generalization ability and anomaly sensitivity across diverse conditions.
To assess the practical deployment potential of our method, we compare the model size and inference speed between UAMS and FNF using a single RTX 4060 Ti GPU. As shown in
Table 5, UAMS contains 22.92 M trainable parameters and achieves an inference speed of 94.58 FPS with GPU memory. The differences in model size and speed between UAMS and FNF are very small, and both can achieve real-time detection on ordinary GPUs. This demonstrates that the proposed modules (MSAA and SSPCAB) enhance detection capability without significantly compromising efficiency.
4.6. Visualization Analysis
To further validate the effectiveness of the proposed UAMS and its constituent modules (MSAA and SSPCAB), we provide qualitative visualization results regarding its anomaly localization ability.
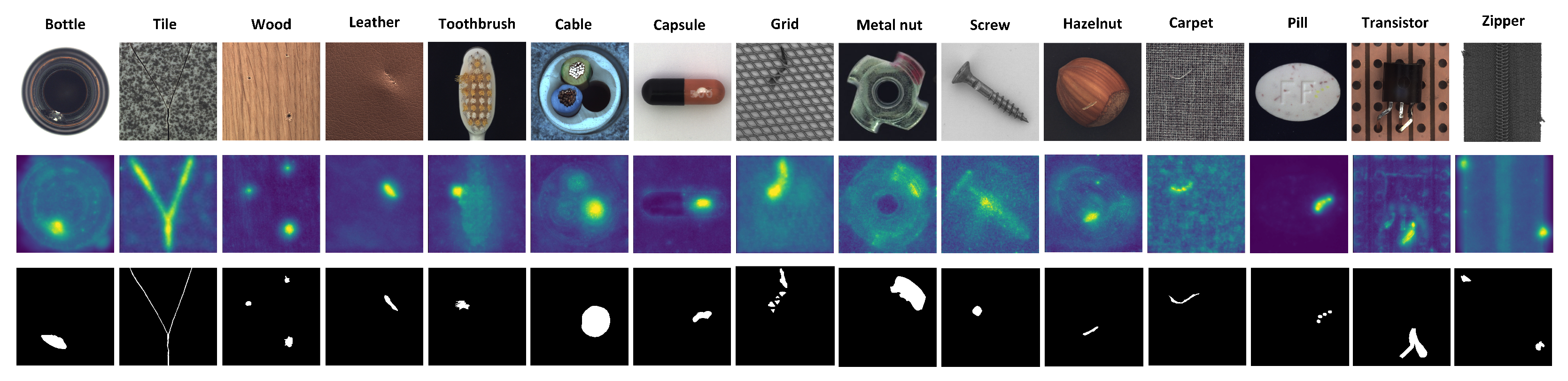
Figure 5 illustrates the pixel-level anomaly maps generated by different model variants on selected categories from the MVTecAD dataset, including both object-type (e.g., capsule, metal nut) and texture-type (e.g., carpet, tile) defects. Each subfigure shows (a) the original input image, (b) the result obtained with the complete UAMS (MSAA + SSPCAB), and (c) the ground truth annotation.
These visual results align with the quantitative improvements observed in terms of the AUROC and AUPRO metrics, offering intuitive insights into how each module contributes to better anomaly localization. They also demonstrate that UAMS not only has numerically improved performance but also offers interpretable and actionable outputs that are critical for real-world industrial inspection scenarios.
5. Discussion
The results of our experiments demonstrate that the proposed UAMS method delivers strong performance in terms of unsupervised industrial anomaly detection, particularly in pixel-level localization tasks. Compared to conventional approaches, our method exhibited notable advantages in robustness, precision, and interpretability, while maintaining a lightweight and fully unsupervised design. These advantages stem largely from the two core modules we propose; namely, the Multi-Scale Attention Aggregation (MSAA) and Self-Supervised Predictive Convolutional Attentive Block (SSPCAB) modules. The MSAA module enables more effective integration of multi-scale semantic information, significantly enhancing the model’s ability to detect local structural anomalies. Meanwhile, the SSPCAB module improves the discrimination ability of feature representations through the introduction of a channel attention mechanism and a self-supervised reconstruction loss, thus guiding the model to focus on semantically relevant regions. Together, these modules contribute to a notable improvement in anomaly localization accuracy, as evidenced by both quantitative metrics and visual results.
Another important aspect of our approach lies in its independence from pretrained models or external datasets. Unlike many prior methods, which rely on ImageNet-based backbones or extensive external supervision, UAMS is trained solely on normal samples from the target domain, making it more suitable for deployment in domain-specific or privacy-sensitive industrial applications. Furthermore, the interpretable anomaly heatmaps generated by our model provide valuable insights for real-world quality control, facilitating visual inspection and decision making in practical settings. The modularity of the method also allows for its flexible deployment and easy integration into existing inspection pipelines. Despite its advantages, UAMS is not without limitations. For texture-based categories (e.g., tile or wood), the model’s performance gains were found to be relatively limited. This can be attributed to the lack of well-defined geometric structure in such categories, where anomalies often present as subtle variations in patterning or shading rather than clear structural deformations. Additionally, while high-resolution latent modeling contributes to more precise anomaly localization, it may introduce increased intra-class variance, occasionally affecting AUROC scores in categories with ambiguous or fuzzy boundaries.
In future work, we plan to explore the integration of adaptive mechanisms that can dynamically adjust to the characteristics of different defect types, including both structural and texture-based anomalies. We are also interested in extending the current binary anomaly method towards multi-class anomaly classification, as well as applying our model to temporal settings such as video-based inspection or sequential monitoring in industrial production lines. Furthermore, given its general design, UAMS has the potential to be adapted to other high-resolution anomaly detection domains where fine-grained, label-efficient detection is of critical importance, such as medical imaging and remote sensing.
UAMS is a flow detection network that combines MSAA and SSPCAB, enabling it to better utilize multi-scale capture of context cues in anomaly detection and enhancing its sensitivity to minor deviations. These features are also sensitive to unstructured anomaly detection. Although the current assessment of UAMS focuses on structured anomaly detection in the industrial field and has not been evaluated on unstructured datasets such as skin diseases or satellite images, its network architecture determines that it has universality and generalization in unstructured anomaly detection.
In practical industrial applications, environmental challenges such as light changes, dust interference, and mechanical vibrations may be faced, which may reduce the robustness of UAMS model anomaly detection and make it difficult to meet the high precision requirements of precision products. Secondly, deployment on embedded and mobile devices faces limitations such as model size, power consumption, and hardware computing power, which may result in inference latency and deployment limitations. In the future, in the optimization of UAMS models, on the one hand, robustness improvements can be made to enhance the model’s adaptability to the environment, and on the other hand, research can be conducted on model compression and lightweighting to enable better embedded and edge deployment.
6. Conclusions
In this study, we proposed the UAMS method—a novel unsupervised anomaly detection method that integrates a multi-scale normalizing flow architecture with two key components: the Multi-Scale Attention Aggregation (MSAA) module and the Self-Supervised Predictive Convolutional Attentive Block (SSPCAB). Our goal in designing this method was to improve the detection accuracy and localization precision of fine-grained industrial defects without relying on any pretrained models or external supervision.
The MSAA module enhances the model’s multi-scale feature representation ability by enabling dynamic spatial and semantic interactions across pyramid levels, strengthening the ability to capture structural anomalies. The SSPCAB module further refines the feature extraction process through the incorporation of multi-scale convolution, a channel attention mechanism, and a self-supervised prediction loss, leading to improved discriminability and robustness.
We evaluated the proposed method across all 15 categories of the MVTecAD benchmark. The experimental results demonstrated that UAMS achieves superior performance in both the AUROC and AUPRO metrics when compared to existing unsupervised baselines and, in many cases, it even outperformed methods that rely on external priors. In-depth ablation studies and visual analyses further confirmed the contribution of each module and the interpretability of the model’s predictions.
In summary, UAMS offers a high-performance, lightweight, and fully unsupervised solution for industrial anomaly detection. Its plug-and-play design facilitates its integration into real-world inspection systems. Future work will explore extending the method to multi-class anomaly classification, incorporating temporal consistency for video-based inspection, and investigating its application in other high-resolution domains such as medical imaging and remote sensing.
Author Contributions
Z.L.: Conceptualization, Methodology, Software, Investigation, Formal analysis, Visualization, Data curation, Writing—original draft. W.C.: Conceptualization, Methodology, Validation, Funding acquisition, Writing—review and editing, Supervision. W.W.: Visualization, Data curation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the Hunan Provincial Natural Science Foundation of China (2023JJ50095), the Scientific Research Fund of Hunan Provincial Education Department (22B0728), the Scientific and Technology Innovation Program of Hunan Province, China (2016TP1020), “the 14th Five-Year Plan” Key Disciplines and Application-oriented Special Disciplines of Hunan Province (Xiangjiaotong [2022] 351).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018; pp. 622–637. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are gans created equal? A large-scale study. Adv. Neural Inf. Process. Syst. 2018, 31, 698–707. [Google Scholar] [CrossRef]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully convolutional cross-scale-flows for image-based defect detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1088–1097. [Google Scholar]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 98–107. [Google Scholar]
- Yu, J.; Zheng, Y.; Wang, X.; Li, W.; Wu, Y.; Zhao, R.; Wu, L. Fastflow: Unsupervised anomaly detection and localization via 2D normalizing flows. arXiv 2021, arXiv:2111.07677. [Google Scholar]
- Lei, J.; Hu, X.; Wang, Y.; Liu, D. PyramidFlow: High-Resolution Defect Contrastive Localization Using Pyramid Normalizing Flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14143–14152. [Google Scholar]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for remote sensing image semantic segmentation. arXiv 2024, arXiv:2405.10530. [Google Scholar]
- Ristea, N.C.; Madan, N.; Ionescu, R.T.; Nasrollahi, K.; Khan, F.S.; Moeslund, T.B.; Shah, M. Self-supervised predictive convolutional attentive block for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13576–13586. [Google Scholar]
- Wei, C.; Wang, W. RFAG-YOLO: A Receptive Field Attention-Guided YOLO Network for Small-Object Detection in UAV Images. Sensors 2025, 25, 2193. [Google Scholar] [CrossRef] [PubMed]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.v.d. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using real nvp. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. Adv. Neural Inf. Process. Syst. 2018, 31, 10215–10224. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3560–3569. [Google Scholar]
- Rudolph, M.; Wandt, B.; Rosenhahn, B. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1907–1916. [Google Scholar]
- Dinh, L.; Krueger, D.; Bengio, Y. Nice: Non-linear independent components estimation. arXiv 2014, arXiv:1410.8516. [Google Scholar]
- Rao, K.; Zhao, F.; Shi, T. FP-YOLOv8: Surface Defect Detection Algorithm for Brake Pipe Ends Based on Improved YOLOv8n. Sensors 2024, 24, 8220. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Pu, J.; Miao, D.; Zhang, L.; Zhang, L.; Du, X. SCGRFuse: An infrared and visible image fusion network based on spatial/channel attention mechanism and gradient aggregation residual dense blocks. Eng. Appl. Artif. Intell. 2024, 132, 107898. [Google Scholar] [CrossRef]
- Wu, B.; Feng, S.; Jiang, S.; Luo, S.; Zhao, X.; Zhao, J. EB-YOLO: An efficient and lightweight blood cell detector based on the YOLO algorithm. Comput. Biol. Med. 2025, 192, 110288. [Google Scholar] [CrossRef] [PubMed]
- Meng, W.; Shan, L.; Ma, S.; Liu, D.; Hu, B. DLNet: A Dual-Level Network with Self-and Cross-Attention for High-Resolution Remote Sensing Segmentation. Remote Sens. 2025, 17, 1119. [Google Scholar] [CrossRef]
- Ro, Y.M.; Cheng, W.H.; Kim, J.; Chu, W.T.; Cui, P.; Choi, J.W.; Hu, M.C.; De Neve, W. MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, Republic of Korea, 5–8 January 2020, Proceedings, Part II; Springer Nature: Berlin/Heidelberg, Germany, 2019; Volume 11962. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8330–8339. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In Advances in Visual Computing. Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; Springer: Cham, Switzerland, 2016; pp. 234–244. [Google Scholar]
- Matsubara, T.; Sato, K.; Hama, K.; Tachibana, R.; Uehara, K. Deep generative model using unregularized score for anomaly detection with heterogeneous complexity. IEEE Trans. Cybern. 2020, 52, 5161–5173. [Google Scholar] [CrossRef] [PubMed]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving unsupervised defect segmentation by applying structural similarity to autoencoders. arXiv 2018, arXiv:1807.02011. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4183–4192. [Google Scholar]
- Cohen, N.; Hoshen, Y. Sub-image anomaly detection with deep pyramid correspondences. arXiv 2020, arXiv:2005.02357. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. Padim: A patch distribution modeling framework for anomaly detection and localization. In Pattern Recognition. ICPR International Workshops and Challenges, Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; Springer: Cham, Switzerland, 2021; pp. 475–489. [Google Scholar]
- Mishra, P.; Verk, R.; Fornasier, D.; Piciarelli, C.; Foresti, G.L. VT-ADL: A vision transformer network for image anomaly detection and localization. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 01–06. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}