
Improvement and Optimization of Underwater Image Target Detection Accuracy Based on YOLOv8

Abstract
1. Introduction
- (1)
- The use of adaptive deformable convolution DCN v4 replaces specific original convolutions, which more cleverly limits the deformation and complex features of underwater targets.
- (2)
- Enhance the detection capability of multi-scale targets using Triplet Attention.
- (3)
- Replace the CIoU function with Shape IoU to improve the model’s overall efficacy.
2. Materials and Methods
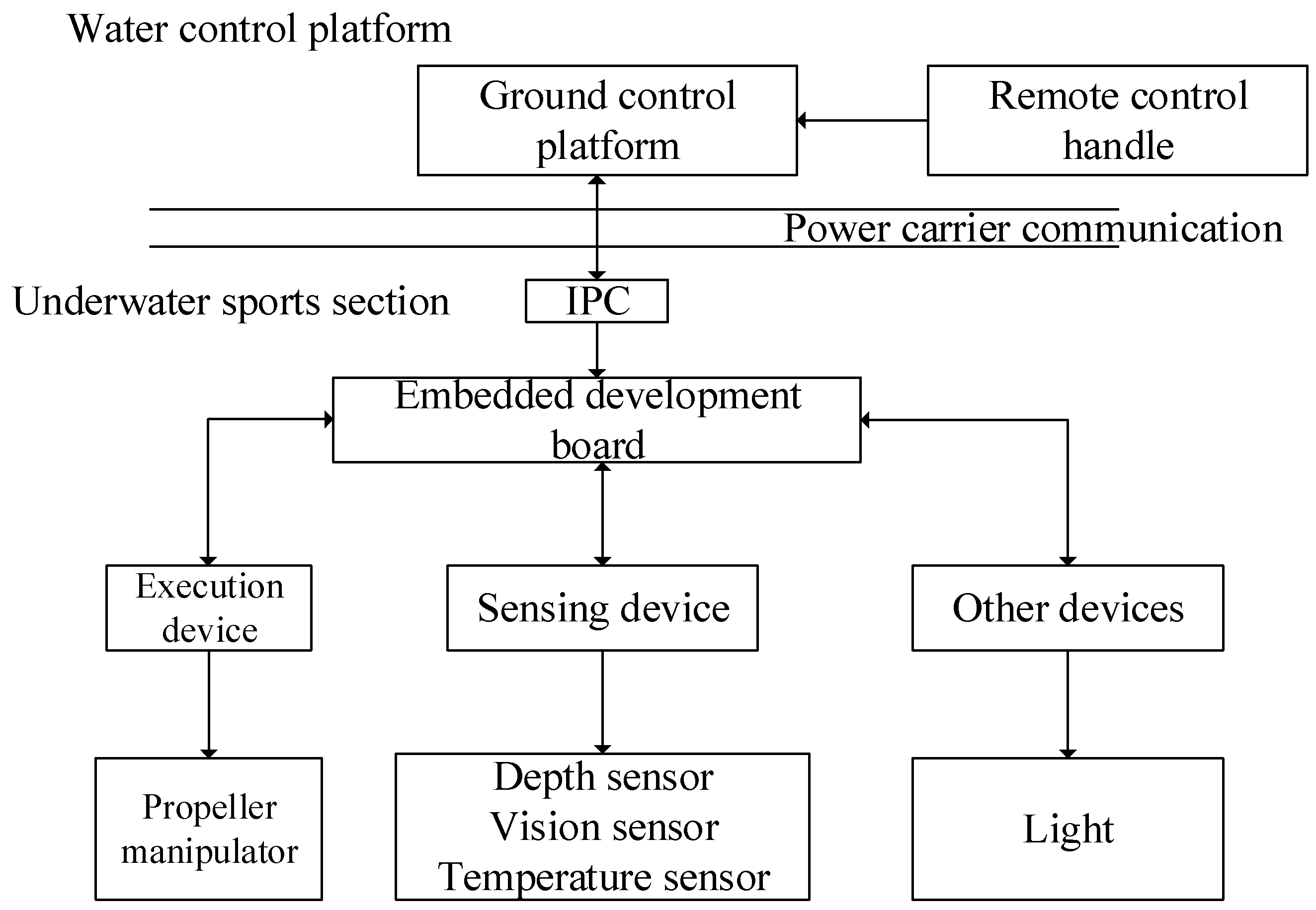
2.1. Robot Experiment Platform
2.2. ROV System Test
2.3. Research on Object Detection Algorithm Based on YOLOv8
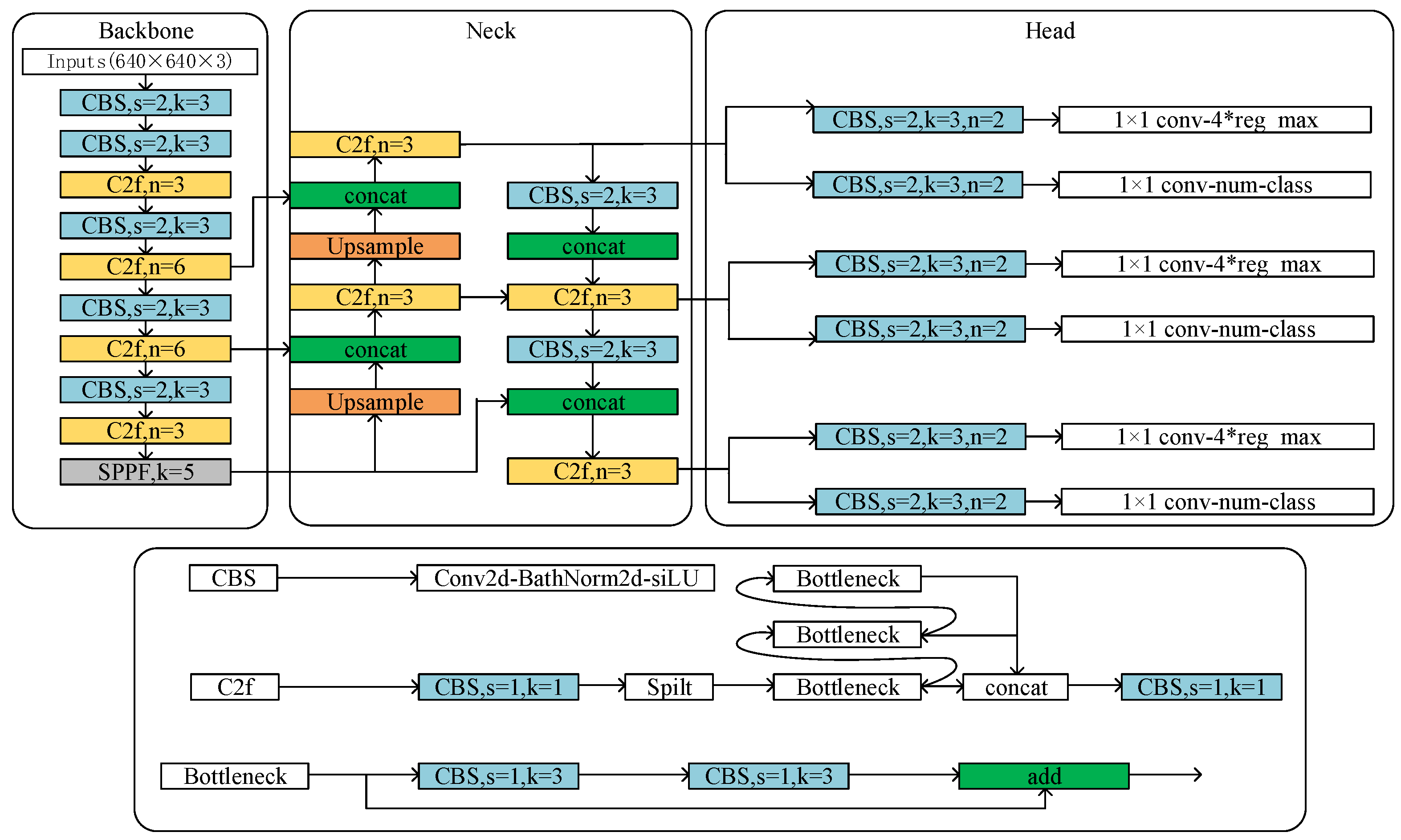
2.3.1. YOLOv8 Object Detection Algorithm
2.3.2. Improvement of YOLOv8s Object Detection Network
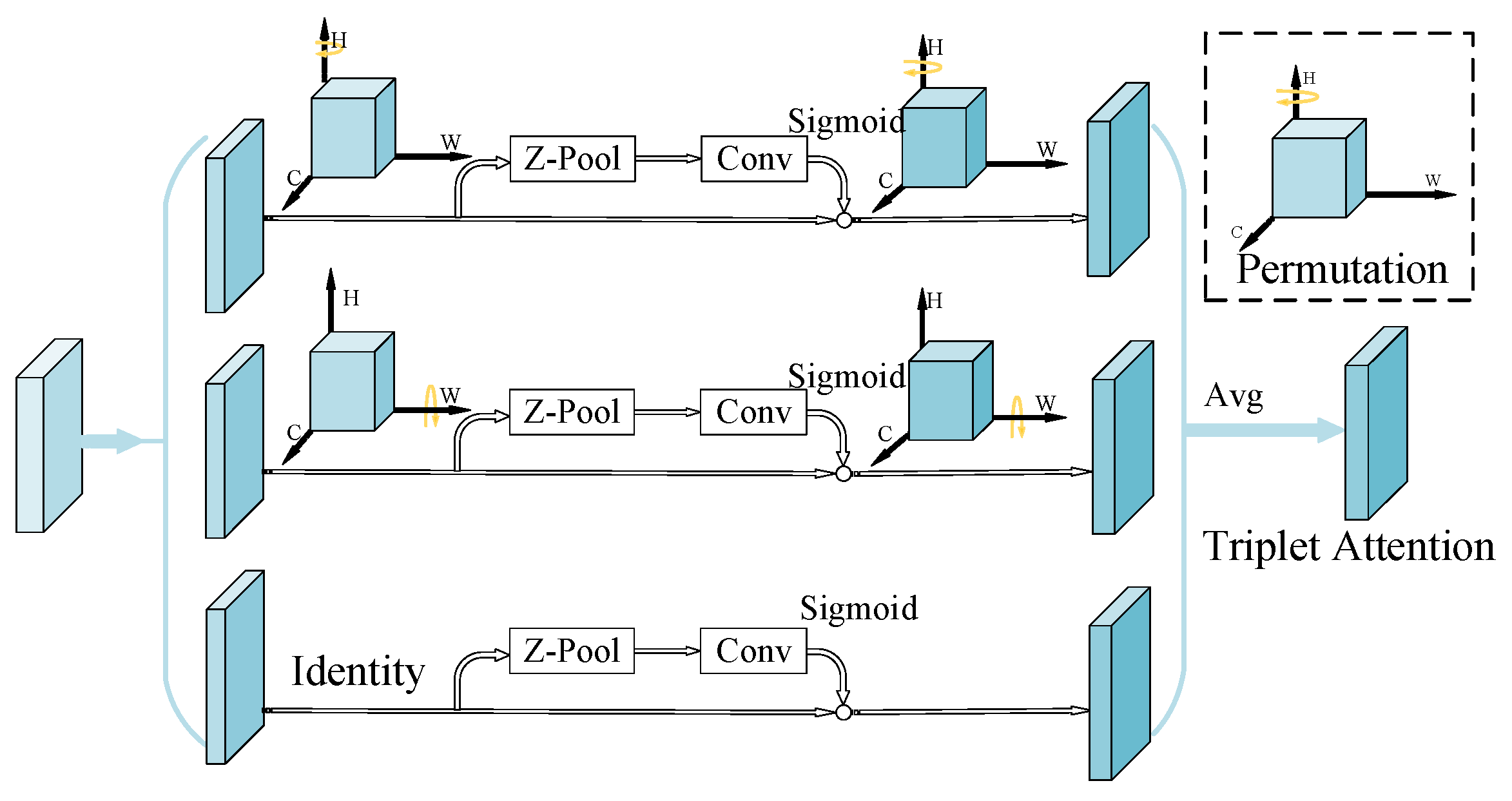
- A.
- Improvement of Attention Mechanism.
- B.
- Enhancement of Original Convolution
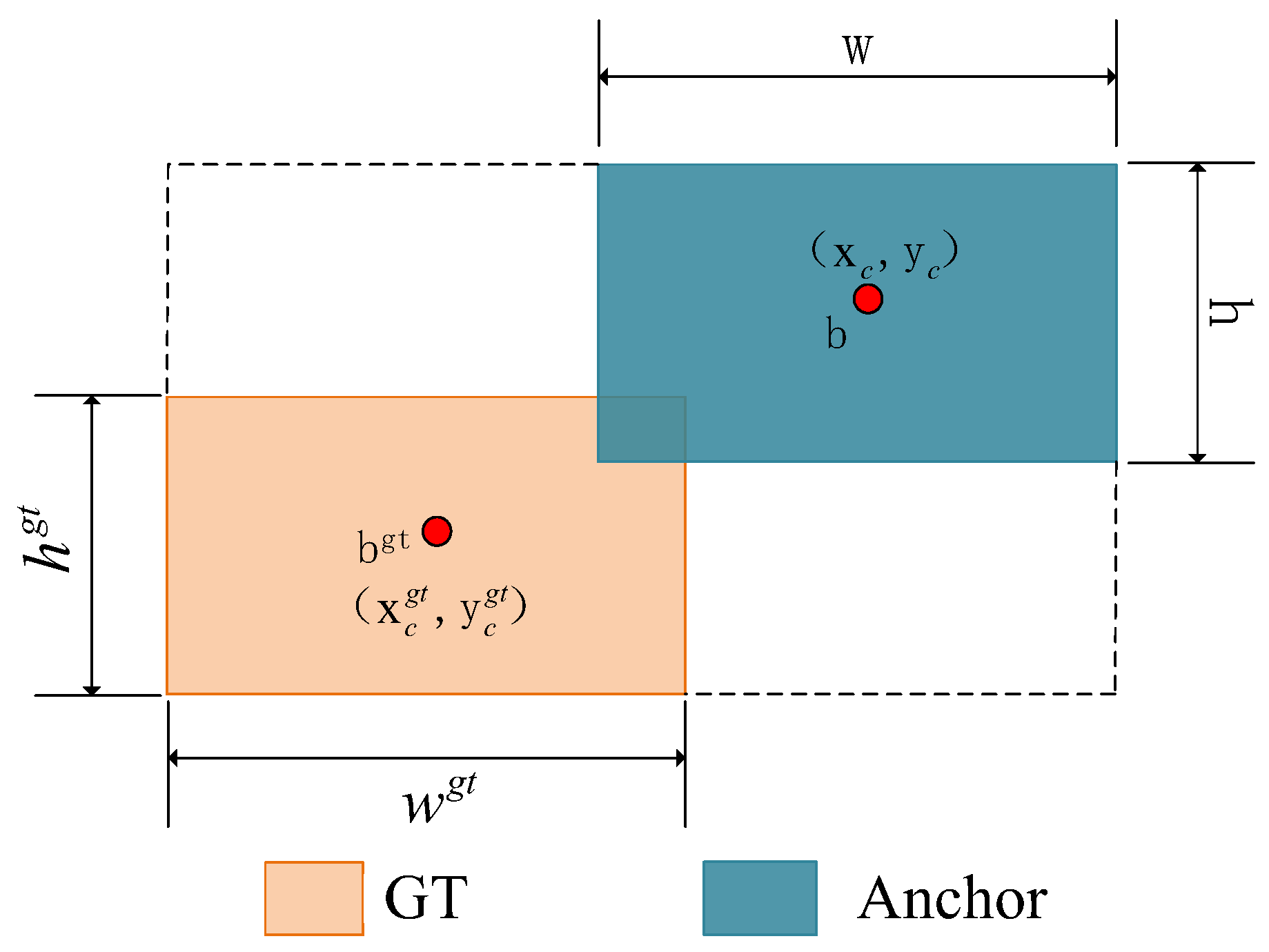
- C.
- Optimization of loss function
3. Results
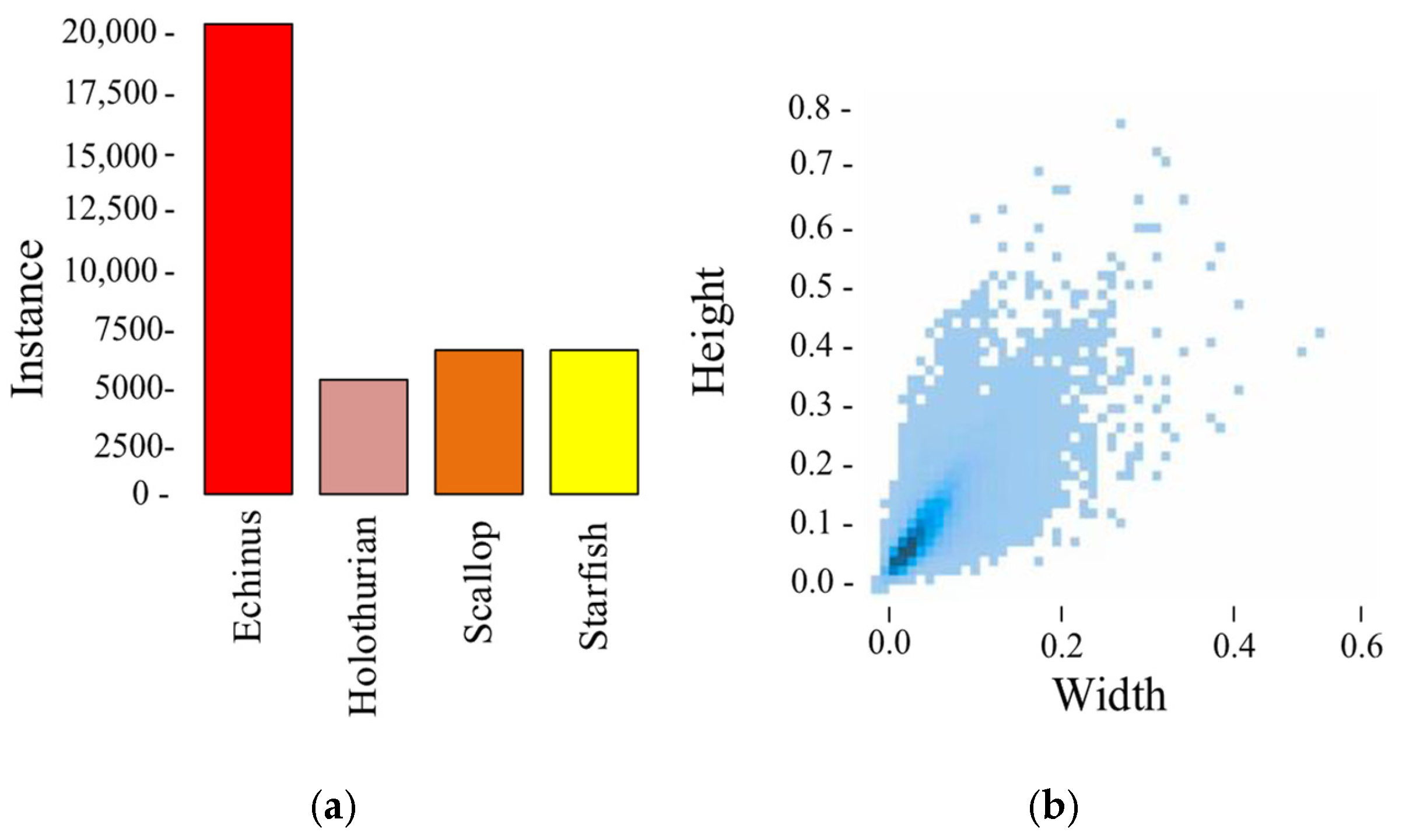
3.1. Data Collection and Experimental Setting
3.2. Evaluation Indicators
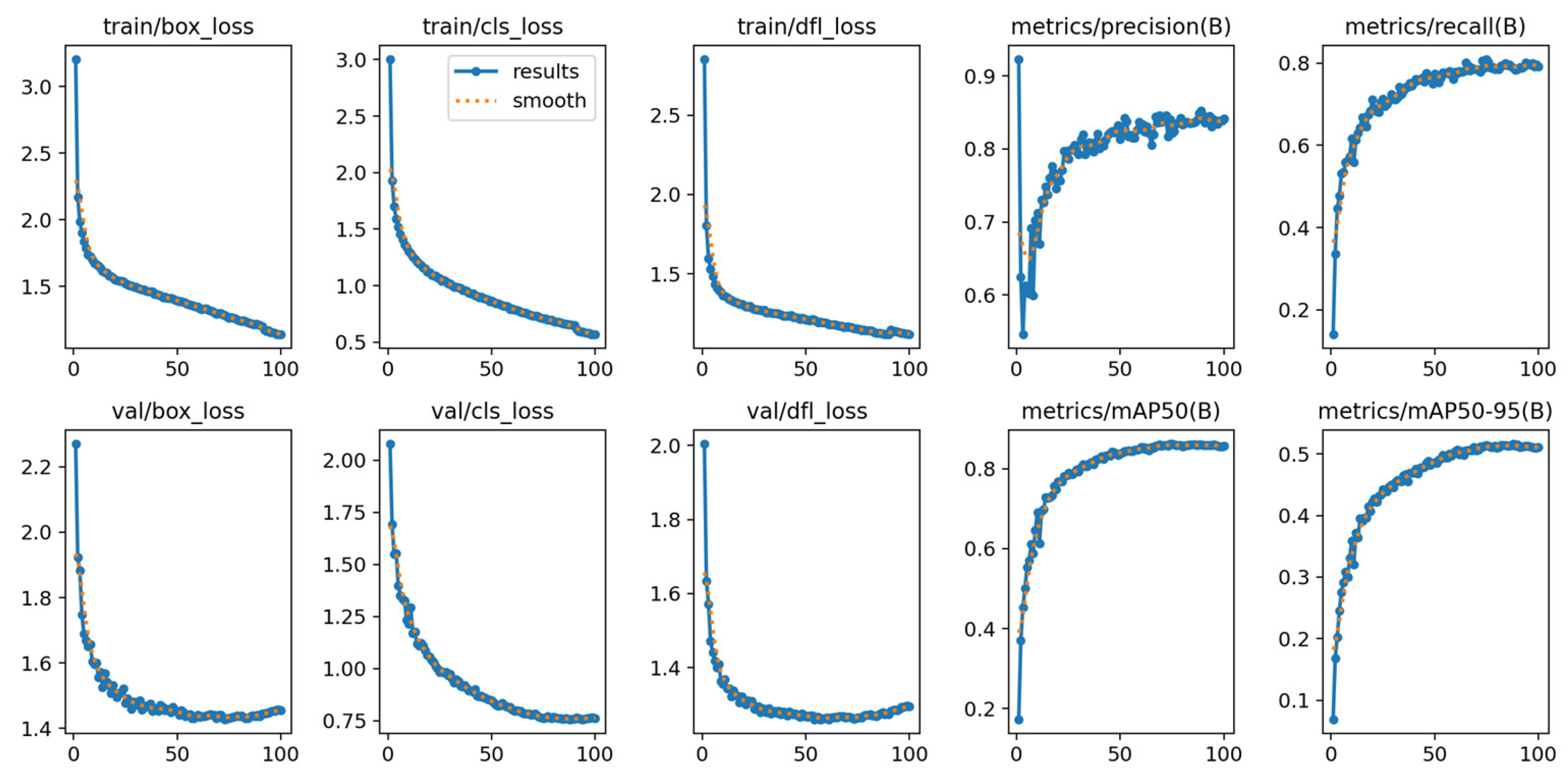
3.3. Results and Analysis of Experiments
3.3.1. Artificial Water Pool Experiment
3.3.2. Comparison of Detection Performance of Different Object Detection Models
3.3.3. Ablation Experiment
3.3.4. Analysis of Gripping Experiments and Results for an Underwater Robot Prototype
- A.
- Artificial aquatic experimentation
- B.
- Natural water experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ROV | Remotely Operated Vehicle |
| Fast R-CNN | Fast Region-Based Convolutional Neural Network |
| Faster R-CNN | Faster Region-Based Convolutional Neural Network |
| Mask R-CNN | Mask Region-based Convolutional Neural Network |
| SSD | Single Shot MultiBox Detector |
| YOLO | You Only Look Once |
| C2f | CSP Layer_2Conv |
| CSP | Common Spatial Pattern |
| ELAN | Efficient Layer Attention Network |
| SPPF | Spatial Pyramid Pooling Fusion |
| PAN | Path Aggregation Networks |
| FPN | Feature Pyramid Networks |
| SENet | Squeeze-and-Excitation Network |
| DCNv3 | Deformable ConvNet v3 |
| DCNv4 | Deformable ConvNet v4 |
| CIoU loss | Complete Intersection over Union Loss |
| Shape IOU loss | Shape-aware Intersection over Union Loss |
| URPC | Underwater Robot Professional Contest |
References
- Chen, L.; Zheng, M.; Duan, S.; Luo, W.; Yao, L. Underwater target recognition based on improved YOLOv4 neural network. Electronics 2021, 10, 1634. [Google Scholar] [CrossRef]
- Yu, Y.; Guo, B.; Chu, S.; Li, H.; Yang, P. A review of underwater biological target detection methods based on deep learning. Shandong Sci. 2023, 36, 1–7. [Google Scholar]
- Xu, S.B.; Zhang, M.H.; Song, W.; Mei, H.; He, Q.; Liotta, A. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Anilkumar, S.; Dhanya, P.R.; Balakrishnan, A.A.; Supriya, M.H. Algorithm for Underwater Cable Tracking Using Clahe Based Enhancement. In Proceedings of the 2019 International Symposium on Ocean Technology(SYMPOL), Ernakulam, India, 11–13 December 2019; IEEE: Ernakulam, India, 2019; pp. 129–137. [Google Scholar]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–127. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Bhatti, U.A.; Yu, Z.; Chanussot, J.; Zeeshan, Z.; Yuan, L.; Luo, W.; Nawaz, S.A.; Bhatti, M.A.; Ain, Q.U.; Mehmood, A. Local similarity-based spatial–spectral fusion hyperspectral image classification with deep CNN and Gabor filtering. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038–107057. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, Y.; Zhou, J. Underwater image enhancement method based on feature fusion neural network. IEEE Access 2022, 10, 107536–107548. [Google Scholar] [CrossRef]
- Wang, H.; Yang, M.; Yin, G.; Dong, J. Self-adversarial generative adversarial network for underwater image enhancement. IEEE J. Ocean. Eng. 2023, 49, 237–248. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Kumar, A.; Srivastava, S. Object detection system based on convolution neural networks using single shot multi-box detector. Procedia Comput. Sci. 2020, 171, 2610–2617. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutionalone—Stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, K.; Li, J.; Lin, W.; See, J.; Wang, J.; Duan, L.; Chen, Z.; He, C.; Zou, J. Towards accurate one-stage object detection with ap-loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15-20 June 2019; pp. 5119–5127. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor—Based and anchor—Free detection via adaptive training sample selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Sung, M.; Yu, S.-C.; Girdhar, Y. Vision based real-time fish detection using convolutional neural network. In Proceedings of the OCEANS 2017—Aberdeen, Aberdeen, UK, 19–22 June 2017; pp. 1–6. [Google Scholar]
- Zhu, S.; Hang, R.; Liu, Q. Underwater object detection based on class weighted YOLO network. J. Nanjing Norm. Univ. (Nat. Sci. Ed.) 2020, 43, 129–135. [Google Scholar]
- Wu, Q.; Cen, L.; Kan, S.; Zhai, Y.; Chen, X.; Zhang, H. Real-time underwater target detection based on improved YOLOv7. J. Real-Time Image Process. 2025, 22, 43–47. [Google Scholar] [CrossRef]
- Chen, X.; Yuan, M.; Yang, Q.; Yao, H.; Wang, H. Underwater-ycc: Underwater target detection optimization algorithm based on YOLOv7. J. Mar. Sci. Eng. 2023, 11, 995. [Google Scholar] [CrossRef]
- Gallagher, J. How to Train an Ultralytics YOLOv8 Oriented Bounding Box (OBB) Model. [2024-02-06]. Available online: https://blog.roboflow.com/train-yolov8-obb-model/ (accessed on 13 May 2025).
- Yuan, H.; Lei, T. Detection and identification of fish in electronic monitoring data of commercial fishing vessels based on improved YOLOv8. J. Dalian Ocean. Univ. 2023, 38, 533–542. [Google Scholar]
- Zhou, X.; Li, Y.; Wu, M.; Fan, X.; Wang, J. Improved YOLOv8 for underwater target detection. Comput. Syst. Appl. 2024, 33, 177–185. [Google Scholar]
- Zhang, M.; Wang, Z.; Song, W.; Zhao, D.; Zhao, H. Efficient small-object detection in underwater images using the enhanced yolov8 network. Appl. Sci. 2024, 14, 1095. [Google Scholar] [CrossRef]
- Song, G.; Chen, W.; Zhou, Q.; Guo, C. Underwater Robot Target Detection Algorithm Based on YOLOv8. Electronics 2024, 13, 3374. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. Yolov8: A novel object detection algorithm with enhanced performance and robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Su, J.; Feng, K.K.; Liang, B.; Hou, W. CoT-YOLO underwater target detection algorithm. Computer Eng. Des. 2024, 45, 2119–2126. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to Attention: Convolutional Triplet Attention Module. arXiv 2020, arXiv:2010.03045. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation net works. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Xiong, Y.; Li, Z.; Chen, Y.; Wang, F.; Zhu, X.; Luo, J.; Wang, W.; Lu, T.; Li, H.; Qiao, Y.; et al. In Proceedings of the Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications IEEE, Seattle, WA, USA, 16–22 June 2024. [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Batch size | 4 |
| Learning rate | 0.01 |
| Optimizer | SGD |
| Weight attenuation factor | 0.0005 |
| Confidence threshold | 0.5 |
| Model Name | AP(%) | mAP (%) | FPS (Hz) | |||
|---|---|---|---|---|---|---|
| Sea Urchin | Sea Cucumber | Sea Star | Scallop | |||
| SSD | 74.7 | 69.9 | 75.2 | 60.2 | 70.0 | 21 |
| YOLOv5s | 91.3 | 75.1 | 85.0 | 84.4 | 83.9 | 97 |
| RetinaNet | 77.2 | 68.1 | 78.3 | 61.2 | 71.2 | 26 |
| Faster R-CNN | 87.4 | 69.4 | 80.5 | 61.3 | 74.4 | 12 |
| YOLOv8s | 90.1 | 74.7 | 87.3 | 85.5 | 84.4 | 96 |
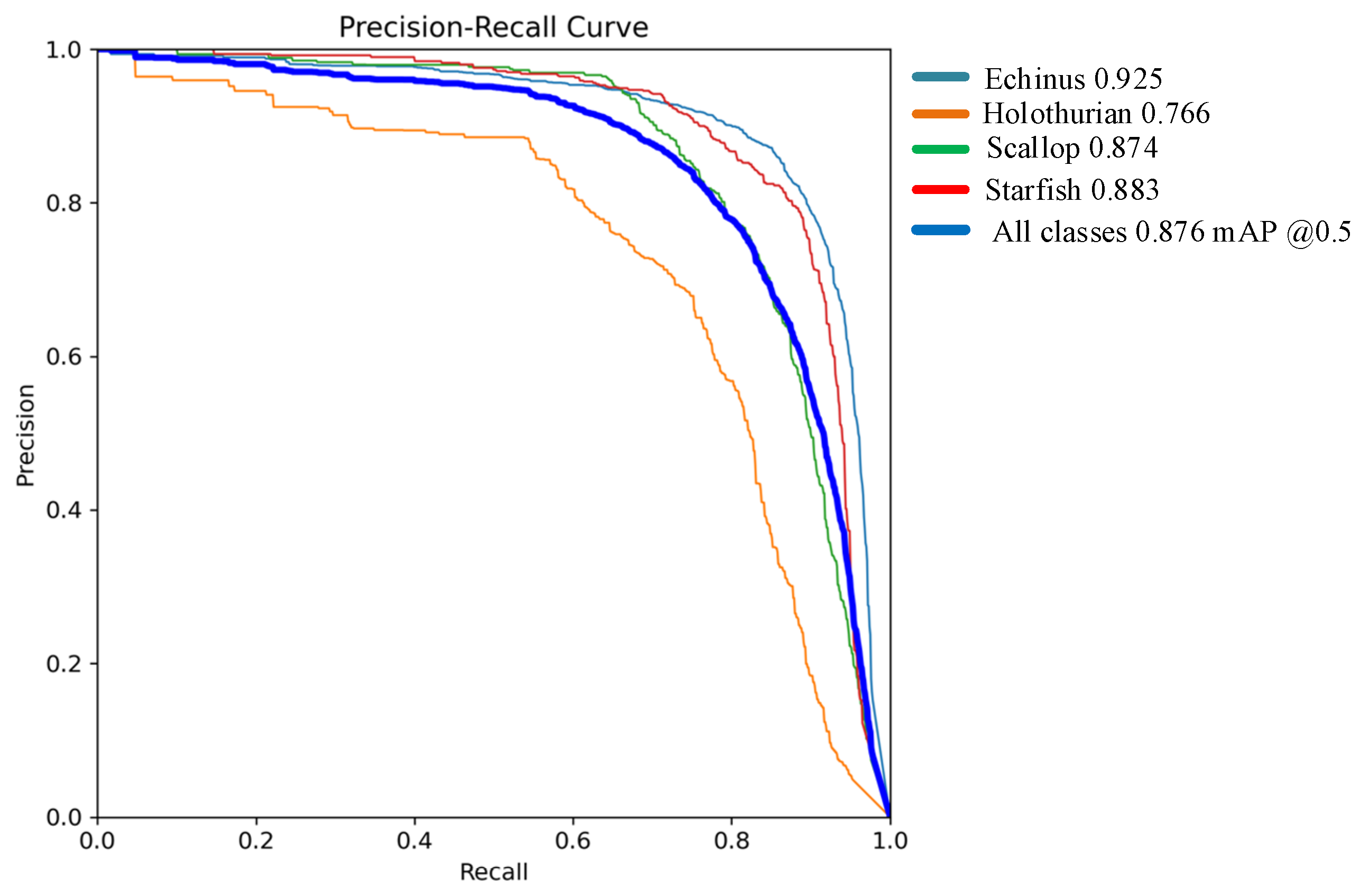
| Improved YOLOv8s | 92.5 | 76.6 | 88.3 | 87.4 | 87.6 | 87 |
| Model | B | T | D | S | mAP (%) | FPS | FLOPs (G) | Parameter Quantity (M) |
|---|---|---|---|---|---|---|---|---|
| 1 | √ | 84.9 | 96.3 | 28.4 | 11.1 | |||
| 2 | √ | 85.2 | 90.2 | 31.6 | 14.5 | |||
| 3 | √ | √ | 86.3 | 87.9 | 33.2 | 17.6 | ||
| 4 | √ | √ | √ | 87.6 | 87.1 | 33.2 | 17.6 |
| Real Sea Area | AP (%) | mAP (%) | F1 | |||
|---|---|---|---|---|---|---|
| Sea Urchin | Sea Cucumber | Sea Star | Scallop | |||
| YOLOv8s | 88.1 | 72.4 | 85.2 | 81.6 | 81.9 | 0.67 |
| Improved YOLOv8s | 90.6 | 82.4 | 85.1 | 84.7 | 85.7 | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Chen, W.; Wang, Q.; Fang, T.; Liu, X. Improvement and Optimization of Underwater Image Target Detection Accuracy Based on YOLOv8. Symmetry 2025, 17, 1102. https://doi.org/10.3390/sym17071102
Sun Y, Chen W, Wang Q, Fang T, Liu X. Improvement and Optimization of Underwater Image Target Detection Accuracy Based on YOLOv8. Symmetry. 2025; 17(7):1102. https://doi.org/10.3390/sym17071102
Chicago/Turabian StyleSun, Yisong, Wei Chen, Qixin Wang, Tianzhong Fang, and Xinyi Liu. 2025. "Improvement and Optimization of Underwater Image Target Detection Accuracy Based on YOLOv8" Symmetry 17, no. 7: 1102. https://doi.org/10.3390/sym17071102
APA StyleSun, Y., Chen, W., Wang, Q., Fang, T., & Liu, X. (2025). Improvement and Optimization of Underwater Image Target Detection Accuracy Based on YOLOv8. Symmetry, 17(7), 1102. https://doi.org/10.3390/sym17071102