1. Introduction
Emotion, as a pervasive and intricate psychological phenomenon, exerts profound and extensive impacts on individuals’ daily lives. A deeper understanding of emotions is not only critical for self-awareness but also serves as a fundamental basis for analyzing interpersonal interaction patterns. If machines could automatically recognize human emotional states, they would be better equipped to serve humans in human–computer interaction scenarios. Consequently, emotion recognition technology has found wide applications in domains such as social security, healthcare, education, entertainment, and intelligent driving.
Current research on emotion recognition primarily focuses on unimodal or bimodal approaches. Unimodal methods typically rely on a single source of information, such as facial expressions, speech, or body posture. However, due to the complexity of emotional expressions, relying solely on one modality often fails to capture the full spectrum of emotions, making such methods susceptible to modality-specific limitations or missing data issues. In contrast, multimodal approaches integrate information from multiple modalities, providing a more comprehensive description of emotional states. Nevertheless, multimodal emotion recognition still faces several challenges, such as modality heterogeneity, the design of effective fusion strategies, and efficient feature extraction.
By thoroughly analyzing the strengths and limitations of existing studies, this paper proposes a novel multimodal emotion recognition model that leverages deep learning techniques to integrate information from three distinct modalities: facial expressions, speech, and body posture. Extensive experiments and optimizations are conducted on the CREMA-D video dataset [
1], evaluating various network architectures and configurations. Notably, the E-Branchformer network [
2], originally designed for speech processing tasks, is extended to emotion recognition tasks. Beyond its application in processing speech signals, its architecture and parameters are optimized to handle facial expression information.
To enhance the performance of the emotion recognition model, this work introduces body posture information. OpenPose [
3] is utilized for human pose estimation, and a novel body posture representation is designed, transforming body key points into a matrix format to facilitate processing by neural networks.
The proposed model integrates facial expressions, acoustic signals, and body posture to comprehensively capture and deeply understand emotional expressions in videos. Specifically, the visual module extracts facial expression features, the acoustic module processes speech features, and the posture module analyzes body posture features. A carefully designed shared module then performs deep fusion of features from these three modalities. The resulting fused emotional feature vector serves as the input for emotion classification.
During the experimental phase, both Conformer [
4] and E-Branchformer networks are employed to construct the visual, acoustic, posture, and shared modules. Rigorous testing and comparisons reveal that the model built with the E-Branchformer network exhibits superior performance.
This paper makes the following key contributions: We propose a trimodal emotion recognition model that embodies a symmetrical design principle. The model processes facial expressions, speech, and body posture in parallel as equal sources of information and achieves balanced fusion in the shared module, thereby enhancing emotion recognition performance. Furthermore, we introduce the E-Branchformer network, originally designed for speech processing, into the emotion recognition task, demonstrating its effectiveness in multimodal learning. In addition, our approach reduces the model’s parameter size, achieving a 33.3% reduction compared to the VAVL baseline.
2. Background and Related Works
2.1. Overview of Emotion Recognition
2.1.1. Emotion Models
To achieve emotion recognition, it is essential to first understand and classify human emotions. Researchers generally categorize emotion theories into two main models: the discrete emotion model and the dimensional emotion model.
The discrete emotion model posits that emotions are finite and consist of distinct categories. Ekman and colleagues [
5] argued that emotions are innate and instinctive, leading individuals to exhibit similar emotional responses under the same circumstances. According to this model, physiological patterns are consistent when experiencing basic emotions. Zhang et al. [
6] proposed that humans experience six basic emotions: happiness, sadness, fear, anger, disgust, and surprise. Other non-basic emotional states, such as fatigue, anxiety, contentment, confusion, and frustration, are constructed from these basic emotions. Each emotion is characterized by unique internal experiences, external expressions, and physiological patterns. Due to its clear categorization standards and identifiable features, the discrete emotion model has been widely applied in facial expression and emotion recognition research.
The dimensional emotion model, on the other hand, suggests that emotions can vary continuously across dimensions such as valence (pleasure–displeasure) and arousal (high–low). Wundt [
7] proposed a dimensional theory of affect, encompassing three dimensions: pleasure versus displeasure, excitement versus calmness, and tension versus relaxation. Different combinations of these dimensions create a diverse range of emotional states, offering a multidimensional framework for understanding human emotions. This model is particularly suitable for analyzing complex and blended emotional states, facilitating the understanding of the continuous relationships between emotions.
2.1.2. Sources of Emotional Information
Machines and humans share similarities in emotion recognition as both require information from various sources to understand and determine emotional states. By capturing subtle variations in these sources, it is possible to identify the emotions embedded within. The most common sources of emotional information include facial expressions, body posture, speech, text, and various physiological signals [
8]. The most common emotional information includes facial expressions, body posture, speech, text, and various physiological signals. This paper utilizes information from the first three.
Facial expressions are one of the most common and intuitive ways for people to express emotions. Whether it is happiness or sadness, these emotions can be easily conveyed through the movement of facial muscles.
Body posture and gestures are also important means of emotional expression, though research into their interaction with emotions is still in its early stages. People often convey their emotional states through different postures and gestures, such as crossing their arms, tilting their head, or tapping a foot. These non-verbal expressions play a significant role in interpersonal communication.
Speech, audio, or spoken language contains rich emotional information. Through detailed analysis of speech inputs, it is possible to select and extract key elements and classify them into different emotional categories. This process aids in a deeper understanding of the emotions underlying speech, enabling the accurate acquisition of emotional information [
9].
2.2. Multimodal Emotion Recognition
The expression of human emotions is inherently complex and multidimensional. For example, happiness may be conveyed through smiling, a cheerful tone, or energetic body language, whereas sadness is not always directly communicated via speech. Early studies (e.g., those of Baltrušaitis et al. [
10] and Gu et al. [
11]) have demonstrated that multimodal fusion captures richer emotional signals and that integrating modalities such as video, audio, and text leads to more comprehensive judgments in emotion recognition.
In addition, Jian Huang et al. [
12] introduced a Transformer-based fusion approach using multi-head self-attention to integrate audio and video features, laying a foundation for continuous emotion recognition. Tian et al. [
13] employed deep convolutional neural networks combined with Bayesian methods to fuse visual and audio information, establishing a correspondence between emotion categories and emotional dimensions. Later, Gong et al. [
14] developed the unified audio-visual model (UAVM) with shared Transformer layers, while the AuxFormer framework by Busso et al. [
15] leverages a shared loss mechanism to enhance robustness under challenging conditions. Furthermore, the VAVL framework proposed by Goncalves et al. [
16] addresses practical issues such as missing modalities and flexible task switching, achieving excellent performance on the CREMA-D and MSP-IMPROV datasets.
Recent advances have built on these foundations to further extend the capabilities of multimodal emotion recognition. Lin et al. [
17] demonstrated that multimodal information can significantly enhance unimodal performance in few-shot learning settings. Li et al. [
18] proposed Decoupled Multimodal Distilling for Emotion Recognition, which addresses the inherent heterogeneity among modalities through a decoupled distillation strategy, enabling more flexible and adaptive cross-modal knowledge transfer.
Zhang et al. [
19] proposed a cross-modal federated learning framework that enables multimodal prediction through unimodal training while preserving user privacy via hierarchical aggregation. Moreover, Wu et al. [
20] introduced Wearable Emotion Recognition, which leverages a Transformer-based self-supervised learning framework to extract features from physiological signals captured by wearable devices, improving the efficiency of multimodal emotion recognition. Ge et al. [
21] presented the Video Emotion Open-Vocabulary Recognition Based on Multimodal Large Language Model, which employs multimodal large language models and open-vocabulary techniques to capture subtle emotional expressions in video-based emotion recognition.
Although multimodal emotion recognition systems offer significant advantages in terms of accuracy and robustness compared to unimodal systems, the challenges of integrating heterogeneous modality information, varying data characteristics, and noise levels make the choice of fusion strategies, parameter settings, and algorithms even more critical. Therefore, continuous exploration of new algorithms and techniques is imperative to further improve performance and precision in multimodal emotion recognition.
2.3. Overview of E-Branchformer and Conformer
In the field of emotion recognition, multimodal fusion technology has become key to improving recognition accuracy. Researchers have applied various advanced neural network architectures to this field, among which the Transformer and its derived networks, such as Conformer and E-Branchformer, have garnered significant attention. Below is an introduction and comparison of the two algorithms.
The Conformer network [
4] combines convolutional neural networks (CNN) and self-attention mechanisms, significantly enhancing the performance of tasks like speech recognition and speech synthesis. This network architecture captures local features through convolution while processing global dependencies using self-attention mechanisms, demonstrating powerful feature modeling capabilities. However, Conformer also has certain limitations. For example, the static single-branch structure lacks flexibility, the interpretability and tunability of the network are restricted, and understanding the inner workings of the model is difficult. Additionally, the self-attention and convolution operations in Conformer exist in a fixed interleaved structure, which may not always be suitable for all speech processing tasks.
The E-Branchformer network [
2] is an enhancement and upgrade of the original Branchformer [
22] network, significantly improving its performance in speech recognition tasks. The E-Branchformer network introduces a two-branch architecture, with one branch using self-attention mechanisms to capture global information and the other branch using a convolution-gated multi-layer perceptron (cgMLP) to capture local information. This branching design not only enhances the flexible modeling of both local and global features but also allows for the replacement of the self-attention module with a more efficient attention mechanism depending on the task requirements. Furthermore, the cgMLP module in E-Branchformer has demonstrated performance superior to or equivalent to the standard convolution module in Conformer for multiple speech processing tasks.
One of the core improvements in E-Branchformer is the introduction of the merge module, which effectively integrates the features from different branches through weighted fusion, allowing the model to more clearly demonstrate how local and global information is utilized at different levels. Research has shown that adding deep convolution operations to the merge module can further enhance model performance. According to a study by Peng et al. [
23], E-Branchformer achieves a performance comparable to or better than Conformer on nearly all datasets and shows more stable training when the model is larger or the dataset is smaller.
3. Model Design and Implementation
3.1. Model Overview
As illustrated in
Figure 1, the proposed model architecture is determined through extensive experimentation, and consists of a Feature Extraction Layer and Modal Processing Layer, followed by the Shared Layer and the final Emotion Classification Layer. The model first extracts features independently for each modality, then integrates these features efficiently through a well-designed fusion mechanism, and then finally performs classification predictions using the fused features. The components of the Modal Processing Layer—namely, the Visual Layer, Acoustic Layer, and Pose Layer, along with the Shared Layer and Emotion Classification Layer—are trained simultaneously using the backpropagation algorithm. While the Modal Processing Layer employs a consistent network design across its subcomponents, the number of E-Branchformer networks used varies to optimize the processing of visual, acoustic, and pose information.
At the lowest level of the architecture is the Feature Extraction Layer, whose primary task is to distill critical information from raw data. This layer comprises three main components: a Facial Expression Feature Extractor, an Acoustic Feature Extractor, and a Pose Estimation Tool. The Facial Expression Feature Extractor and Acoustic Feature Extractor leverage pre-trained models to extract features, producing a 1408-dimensional vector for each video frame and a 1024-dimensional vector for each audio frame, respectively. These feature vectors are subsequently fed into their corresponding Modal Processing Layers. Meanwhile, the Pose Estimation Tool transforms its extracted pose information into a 2D matrix, which is detailed further in
Section 3.2.3.
The next level, the Modal Processing Layer, processes features received from the Feature Extraction Layer. This layer is composed of the Visual Layer, Acoustic Layer, and Pose Layer, all built upon the same foundational structure and trained under a unified mechanism, which was designed symmetrically. In the optimal network structure obtained through the experiments in this study, each of these layers utilizes an E-Branchformer network, ensuring both efficiency and accuracy in processing multimodal information. The Visual Layer focuses on extracting facial expression and visual information from video frames; the Acoustic Layer specializes in capturing vocal and tonal characteristics from audio sequences; and the Pose Layer captures dynamic human motion data from video inputs. Each of these layers transforms its feature vectors into a unified 50-dimensional space, ensuring consistency in dimensionality across modalities for seamless integration in the Shared Layer.
The Shared Layer serves as the core processing module, responsible for receiving and fusing features from the various modalities. Its primary task is to deeply integrate multimodal features, learning and generating an intermediate multimodal representation. Structurally, the Shared Layer is built using E-Branchformer encoders and employs residual connections. These connections preserve single-modality feature information while simultaneously merging it with the multimodal representation, thereby enhancing the model’s robustness. This design allows the model to capture inter-modal relationships while retaining modality-specific information, resulting in a more comprehensive and complete representation.
The Emotion Classification Layer is the final component of the model, tasked with converting the fused multimodal features from the Shared Layer into emotion category predictions. The input to this layer is a concatenated 1536-dimensional feature vector derived from the Modal Processing Layers. The Emotion Classification Layer is structured as a multi-layer fully connected network that progressively transforms and combines features from different modalities into a more abstract and comprehensive representation. The first fully connected layer is designed to match the dimensionality of the input data. At the end of the Emotion Classification Layer, a softmax layer is employed to convert the output feature vector into a probability distribution over emotion categories, enabling accurate classification of the final emotion labels.
3.2. Feature Extraction Methods
3.2.1. Facial Feature Extraction
To extract facial features, the first step involves performing face detection on every frame of the input video, as shown in
Figure 2. For this purpose, the Multi-Task Cascaded Convolutional Neural Network (MTCNN) [
24] is employed. The MTCNN is chosen for its efficiency and accuracy in precisely locating and extracting facial regions from video frames. Once the facial regions are detected, they are saved as images and resized to dimensions of 224 × 224 × 3 (width × height × RGB channels), as shown in
Figure 3, to prepare them for subsequent feature extraction.
To extract facial expression features from the facial images, the EfficientNet-B2 network [
25] is utilized. The EfficientNet series is renowned for its efficiency in image recognition tasks, with the B2 variant striking a balance between accuracy and computational efficiency. By applying the EfficientNet-B2 network to each facial image frame, rich and detailed facial expression features can be extracted.
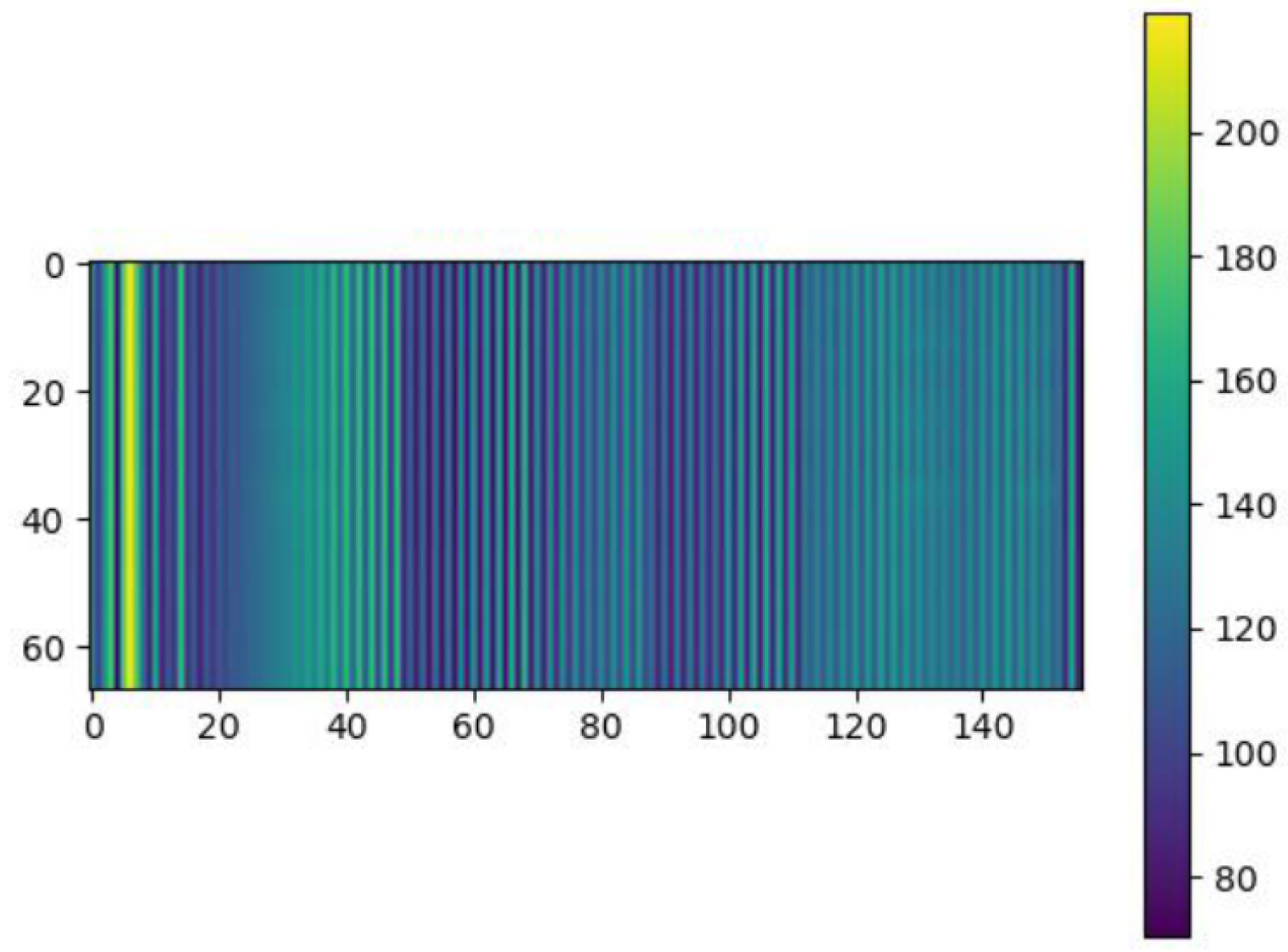
To facilitate subsequent data processing and emotion analysis, the facial features of all frames in each video are consolidated and saved as a single npy file. The npy file format, a binary file format specifically designed for NumPy, is used to efficiently store large numerical datasets. This approach allows for seamless loading, analysis, and fusion of the extracted features in later steps.
Figure 4 provides a visual representation of facial expression features extracted from video frames, stored in the npy file format.
3.2.2. Acoustic Feature Extraction
For each input video, the audio stream is first extracted and saved in the WAV format. Each WAV file is tightly linked to its corresponding video and encapsulates the specific emotional information conveyed by the video. To process these audio data, this study employs the powerful wav2vec2-large-robust pre-trained model [
26] from the Hugging Face library. Trained on a vast number of audio data, this model has demonstrated strong capabilities in extracting essential acoustic features from raw audio signals. By inputting the WAV files into the model, key acoustic features can be automatically extracted.
The wav2vec2-large-robust model can accurately extract frame-level representations from audio data. These representations not only capture the acoustic characteristics of the audio but also encode rich emotional information, making them a robust foundation for downstream acoustic feature processing.
3.2.3. Body Pose Estimation
This study employs OpenPose for body pose estimation. Developed by Carnegie Mellon University (CMU), OpenPose is a widely used open-source library capable of real-time multi-person pose key point detection. The library can accurately identify human poses in images or videos, capturing key points of the human body, such as the head, limbs, hands, and feet. By connecting these key points, OpenPose constructs a comprehensive 2D human pose model. The body pose information detected by OpenPose is saved in JSON files, which contain a series of key points. Specifically, the body pose includes 25 key points, while the facial pose captures 70 key points.
To extract body pose information from the emotional video dataset, OpenPose is applied to process each frame of every video. It performs skeleton key point and facial key point detection for each person in the frame. The detection results from OpenPose are output in two formats: images and JSON files. The images visually display the detected body poses and facial expressions, while the JSON files provide detailed coordinates and confidence scores for each key point in every frame. The results of body pose detection for individuals exhibiting various emotional states are illustrated in
Figure 5.
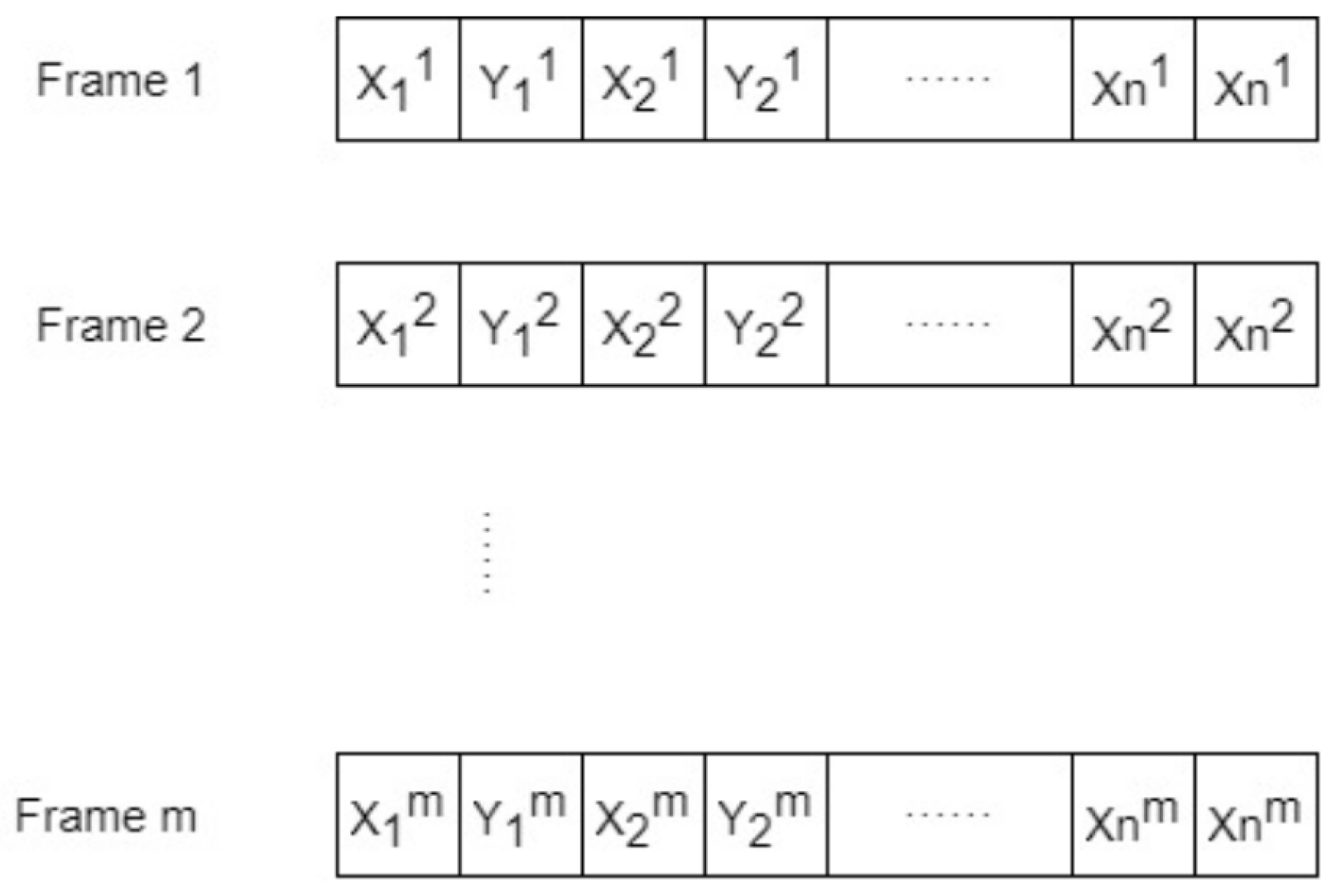
To transform the pose information output by OpenPose into a specific format suitable for further processing in the Pose Layer, this study designs a 2D matrix to store the pose information for each video, as shown in
Figure 6. The size of this matrix is m × n, where m represents the number of frames in the video, and n corresponds to twice the number of skeletal key points per frame. This is because each key point requires two coordinate values (x and y) to represent its position.
For each frame of the video, all the key point coordinates of the person in that frame are extracted from the OpenPose output. These coordinates are arranged in the default order defined by OpenPose, as illustrated in
Figure 7. The horizontal (x) and vertical (y) coordinates of each key point are sequentially stored in the current row of the matrix, with each key point occupying two column positions—one for the x-coordinate and the other for the y-coordinate. In this way, a structured 2D matrix is generated, containing the body pose information of all individuals in the video. This matrix can be efficiently accessed and utilized by the subsequent processing algorithms in the Pose Layer.
In the CREMA-D dataset, the videos primarily focus on the upper body of individuals, resulting in pose information that includes only the eight key points of the upper body. These key points correspond to the following indices in
Figure 8: 0, 1, 2, 5, 15, 16, 17, and 18. Additionally, this dataset allows for the complete detection of all facial key points, totaling 70. Combining the upper body and facial key points, each frame can extract a total of 78 key points. Since each key point requires two pieces of information—its horizontal (x) and vertical (y) coordinates—the matrix used to store pose information has dimensions of
, where
n = 156.
3.3. Loss Function
The loss function of the proposed model is applied at the multimodal level after feature fusion in the Emotion Classification Layer and consists of two main components: classification loss and reconstruction loss.
For the classification loss
represents the ground-truth emotion label, and pred denotes the predicted emotion category. This component adopts multi-class cross-entropy loss, as shown in the following formula, to measure the difference between the predicted probability distribution and the actual labels. Specifically, the
i-th element of the predicted probability distribution represents the probability of the sample belonging to the
i-th category. By minimizing the cross-entropy loss, the model is effectively guided to produce more accurate emotion classification results. This loss function is widely used in multi-classification tasks.
Additionally, the model incorporates a reconstruction loss, , which aims to enable the model to learn the ability to reconstruct the input feature representations from the Shared Layer. This loss helps the model capture more generalized features while retaining the unique information of each modality.
Specifically,
represents the global representation obtained by applying average pooling to the input features, and
is the reconstructed feature output from the Shared Layer. The difference between
and
is computed using the Mean Squared Error (MSE), defined as follows. By minimizing this error, the model optimizes its ability to reconstruct shared features effectively. Here,
n denotes the number of samples,
is the actual value of the
i-th sample, and
is the model’s prediction for the
i-th sample:
The Mean Squared Error (MSE) is chosen due to its ability to directly measure the distance between predicted and actual values in a simple and efficient manner. The incorporation of reconstruction loss not only facilitates the collaborative learning of features across different modalities but also preserves the specificity of each modality, thereby enhancing the model’s generalization capabilities. The overall design of the loss function balances classification accuracy and feature reconstruction ability, ensuring that the model excels in emotion classification tasks while extracting more generalizable and robust feature representations.
No independent loss is applied to individual modalities as the entire model is trained end to end to optimize joint multimodal representations.
3.4. Evaluation Metrics
The evaluation of the emotion classification task primarily involves the following metrics: the confusion matrix, precision, recall, and F1-score. In multi-label classification, the F1-score can be calculated using two approaches, the Macro Average approach and the Micro Average approach, which consider the performance of individual classes differently. The Macro F1-score (F1-score Macro) is computed by calculating the F1-score for each class individually and then taking the average of these scores. The formula is as follows:
where
n is the total number of labels,
represents the precision for label
i, and
represents the recall for label
i.
The Micro F1-score (F1-score Micro) is calculated by treating all samples across all classes as a single set, computing the overall precision and recall, and then deriving the F1-score. The formula is as follows:
In this study, both the Macro and Micro F1-scores are used as key metrics to evaluate the model’s performance.
4. Experimental Results and Analysis
4.1. Emotional Corpora
4.1.1. CREMA-D Corpus
The corpus used in this study is the CREMA-D (Crowd-Sourced Emotional Multimodal Actors Dataset), which was designed for multimodal emotion research and includes both audio and visual data.
The dataset consists of 7442 video clips performed by 91 actors from various ethnic backgrounds. In these clips, the actors deliver the same twelve sentences, each presented with one of six emotions (anger, disgust, fear, happiness, neutral, and sadness) at one of four emotional intensity levels (low, medium, high, and unspecified). Each video, lasting a few seconds, focuses on conveying a specific emotion displayed by the actor, as shown in
Figure 9.
To comprehensively evaluate these video clips, 2443 annotators assessed them across three dimensions: audio, visual, and audio-visual. These annotations provide perceptual emotion classification labels and ground-truth intensity values, enriching the corpus with a diverse and in-depth set of emotional data.
4.1.2. eNTERFACE’05 Corpus
The eNTERFACE’05 Emotional Corpora [
27] are specifically designed for audio-visual emotion analysis, intended to test and evaluate the performance of video, audio, or audio-visual joint emotion recognition algorithms. The corpora were recorded by 42 participants from 14 different countries and cover six emotions: happiness, sadness, surprise, anger, disgust, and fear, as shown in
Figure 10.
During the recording process, each participant was asked to listen to six short stories, each aimed at evoking one of the six emotions. After listening to the stories, the participants were required to respond to five predefined sentences in English in as “emotional” a manner as possible, with each sentence corresponding to a specific emotional response. To ensure the quality of the corpora, two experts evaluated the emotional responses of the participants. Only those samples that clearly expressed the corresponding emotion were included in the corpora, while samples that did not meet this criterion were excluded.
4.2. Experimental Environment and Parameters
The model is implemented using the PyTorch 1.12.1 framework and trained for 20 epochs with the ADAM optimization algorithm. The learning rate is set to , with a weight decay of to prevent overfitting. The exponential moving average of the gradients is set to 0.95, while the exponential moving average of the squared gradients is set to 0.999 to enhance model stability and convergence. The model uses the CrossEntropyLoss loss function, which implicitly applies the softmax function to the raw output of the model, converting it into a probability distribution to obtain the final emotion classification results. The weight updates are achieved through end-to-end backpropagation, where the gradient of the total loss L propagates from the Emotion Classification Layer and the Shared Layer to each modality-specific processing layer. In the CREMA-D Emotional Corpora, the batch size is set to 8. The entire training process is accelerated using an RTX 3090 GPU.
This paper introduces several improvements to the E-Branchformer network architecture. First, the activation function in the feed-forward layer is replaced with Swish, which enhances the network’s nonlinear expressiveness and helps mitigate the vanishing gradient problem. The parameters of the feed-forward layer are detailed in
Table 1.
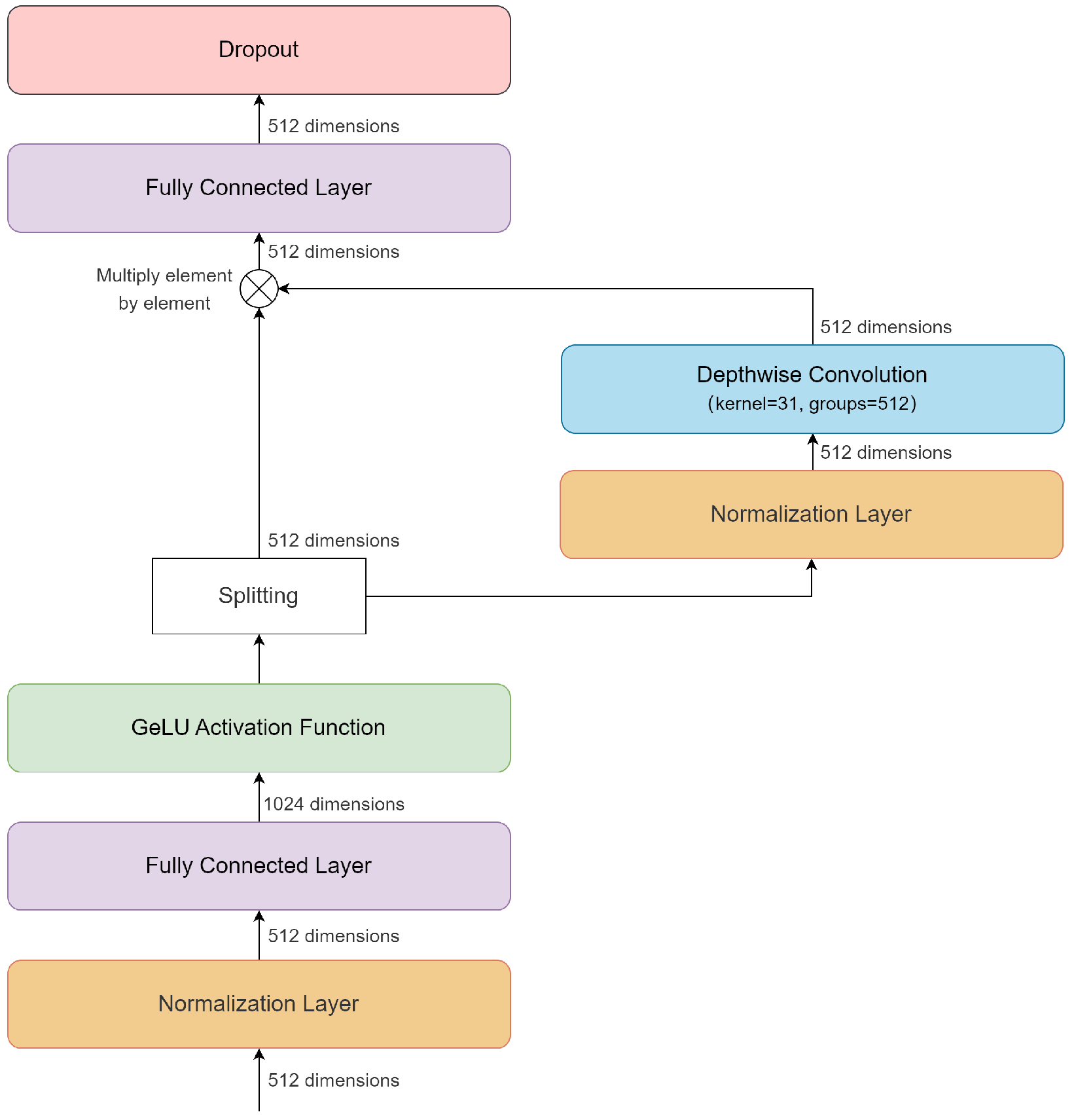
Next, we incorporate depthwise separable convolution with a large kernel size (kernel = 31) in the convolutional-gated MLP (cgMLP) module shown in
Figure 11. The depthwise separable convolution is configured with an input/output channel size of 512 and a group size of 512, meaning that each input channel is processed independently without inter-channel information mixing. This design enhances the model’s ability to capture local contextual dependencies. Meanwhile, a branched feature processing strategy is adopted, where another 512-dimensional part remains unprocessed. Finally, the two feature vectors are element-wise multiplied before being passed through a fully connected layer, maintaining an input and output feature size of 512 dimensions.
4.3. Exploring the Optimal Network Configuration
To achieve the best performance of the model, this paper introduces networks with different quantities in the Visual Layer, Acoustic Layer, Pose Layer, and Shared Layer. A series of experiments is designed and conducted to address the issue of how many networks should be stacked in each layer. The goal of these experiments is to determine the optimal number of networks in different layers, aiming to optimize the model’s performance while maintaining the lowest number of parameters. The dataset used in this section is CREMA-D.
4.3.1. Optimal Network Configuration for the Conformer Network
Table 2 provides a detailed presentation of the model’s performance and parameter count when configuring different numbers of Conformer networks in the Visual Layer, Acoustic Layer, Pose Layer, and Shared Layer. The configurations with the best performance are highlighted in bold in the table.
The CREMA-D dataset is divided into training, validation, and test sets, accounting for 70%, 15%, and 15% of the data, respectively. No actor appeared in multiple subsets simultaneously. To ensure more stable and reliable results, five different data splits are adopted. For each split, we follow the same procedure for model training and evaluation: the model is trained on the corresponding training set and validated on the respective validation set. The best-performing model from each evaluation process is then selected for testing on the associated test set. This process is repeated five times (once for each split), and the F1-score is computed for each iteration. To obtain a more robust performance assessment, the final model performance is reported as the average of these five test results.
It is noteworthy that the model achieves the best performance when one Conformer network is configured in each of the Visual, Acoustic, and Pose Layers, with an additional network in the Shared Layer. Specifically, the Macro F1-score for this configuration is 0.802, while the Micro F1-score reaches 0.852, the highest among all test configurations. Furthermore, the parameter count for this configuration is 39.97 M, the lowest among all the compared combinations.
4.3.2. Optimal Network Configuration for the E-Branchformer Network
The Visual Layer, Acoustic Layer, and Pose Layer in the model are structurally identical, with the same number of E-Branchformer networks configured in each. The Shared Layer, however, can be configured with a different number of networks as needed. The aim of the experiment is to explore how to maximize model performance with the fewest parameters under different configurations.
Table 3 provides a detailed listing of the model’s performance and parameter count when configuring different numbers of E-Branchformer networks in the Visual Layer, Acoustic Layer, Pose Layer, and Shared Layer, with the optimal performance highlighted in bold. The performance of these models is evaluated based on the F1-score, and each F1-score is derived from the average of the test results across five different splits of the dataset. Specifically, when one E-Branchformer network is configured in the Visual Layer, one network in the Acoustic Layer, one network in the Pose Layer, and two networks in the Shared Layer, the model demonstrates the best performance. In particular, the Macro F1-score reaches 0.814, while the Micro F1-score is 0.853, the highest value among all configurations. In this case, the parameter count is 40.94 M, which is moderate.
4.4. Comparison Between E-Branchformer and Conformer Networks
First, we train the model with the optimal configuration based on the Conformer network in the CREMA-D Emotional Corpora. The results of training with five different data splits are shown in
Table 4, and the confusion matrices for the five training runs are shown in
Figure 12.
Subsequently, we train the optimally configured model based on the E-Branchformer network using the same approach. The test results across five different data splits are presented in
Table 5, while the confusion matrices from the five test runs are illustrated in
Figure 13.
To mitigate the risk of overfitting during training, we apply a dropout rate of 0.1 to all E-Branchformer layers and implement an early stopping mechanism. Specifically, training is terminated if the validation loss does not improve for five consecutive epochs. Moreover, the model demonstrates stable performance across the five data splits (
Table 4 and
Table 5), with F1-score standard deviations remaining within a low range.
The models undergo five independent training runs, and the average results of these runs are calculated to serve as the final performance metrics. To provide a more intuitive comparison of the model’s performance, the results of the two proposed models are contrasted with those of baseline models, including VAVL [
16], UAVM [
14], and AuxFormer [
15].
Among the baseline models, VAVL and UAVM share similarities in their overall network architecture as both focus on leveraging information from facial expressions and speech modalities. In these models, facial expression and speech data are processed separately through two independent network modules with identical structural parameters. A fusion module then integrates the processed information from these modules to achieve final emotion classification.
The VAVL model employs a consistent structure for its facial expression and speech processing modules, both of which utilize Conformer networks as their core components. Additionally, the fusion module incorporates two Conformer networks to ensure effective and accurate integration of multimodal information. In contrast, the UAVM is built on a Transformer-based architecture. Its facial expression processing module, speech processing module, and fusion module all adopt Transformer networks, showcasing the Transformer’s powerful capability in handling multimodal information.
Compared to the VAVL model and UAVM, the proposed model incorporates body posture information into its design, an innovative adjustment aimed at enhancing performance. To comprehensively evaluate the effectiveness of this improvement, extensive experiments are conducted using five different data split methods. The results from these experiments are aggregated and carefully averaged to derive the final evaluation metrics. This approach to data processing and analysis aligns with the methodology employed by Goncalves et al. in the VAVL model, further validating the reliability and effectiveness of the evaluation strategy used for the proposed model.
Table 6 presents a performance comparison of the proposed models (trimodal models based on Conformer and E-Branchformer) and three baseline models (VAVL, UAVM, and AuxFormer) on the CREMA-D Emotional Corpora.
The results show that the trimodal model based on Conformer and E-Branchformer significantly outperforms the three baseline models in both F1-Macro and F1-Micro metrics, with the E-Branchformer-based model achieving the best performance. The Conformer-based trimodal model reaches F1-Macro and F1-Micro scores of 0.802 and 0.852, representing improvements of 2.3% and 2.6% compared to the best-performing baseline model (VAVL), respectively. This indicates that Conformer is more effective at integrating facial expression, speech, and body posture features, significantly enhancing emotion recognition accuracy. The E-Branchformer-based trimodal model further improves the F1-Macro and F1-Micro Scores to 0.814 and 0.853, respectively. Compared to the VAVL baseline model, the F1-Macro is improved by 3.5%, and the F1-Micro by 2.7%. Compared to the Conformer-based model, the F1-Macro is improved by 1.2%, and the F1-Micro is improved by 0.1%. This demonstrates that E-Branchformer excels in multimodal emotion feature extraction and fusion.
In terms of parameters, the two proposed models significantly reduce the parameter count while achieving superior performance compared to the VAVL model, which has 61.38 M parameters, showcasing a strong advantage in model design. The Conformer-based model has 39.97 M parameters, and the E-Branchformer-based model has 40.94 M parameters, with only a 1 M difference between them. This suggests that, although the E-Branchformer model has a slightly higher parameter count, the performance improvement is significant, offering a high cost–performance ratio.
In conclusion, the trimodal emotion recognition model based on E-Branchformer proposed in this paper excels in both performance and parameter efficiency. It not only effectively integrates facial expressions, speech, and body posture information but also outperforms existing baseline models, providing a new solution for multimodal emotion recognition.
4.5. Ablation Studies
To validate the necessity of integrating all three modalities—facial expressions, speech, and body posture—we conduct ablation studies by training different variants of the proposed model with various modality combinations. These variants are derived from the optimal trimodal emotion recognition model based on E-Branchformer identified in the previous experiments.
Table 7 presents the results on the CREMA-D corpus.
Among the bimodal models, the Expression + Speech combination achieves the best performance (F1-Macro: 0.801, F1-Micro: 0.848), indicating a strong complementary relationship between facial expressions and speech in emotion recognition. In contrast, the Speech + Posture combination performs the worst (F1-Macro: 0.647, F1-Micro: 0.711), suggesting that body posture alone is insufficient to compensate for the absence of facial information.
The trimodal model, which integrates facial expressions, speech, and body posture, demonstrates the highest overall performance, confirming that multimodal fusion significantly enhances emotion recognition accuracy. Notably, body posture information, when combined with other modalities, provides unique contextual signals, contributing to greater model robustness.
4.6. Comparative and Dataset Expansion Experiments
4.6.1. Dataset Expansion
To address the issue of limited and homogeneous data, this study expands the dataset by incorporating the eNTERFACE’05 dataset, merging it with the CREMA-D dataset for experiments. Prior to merging, all video sequences expressing surprise emotions were removed from the eNTERFACE’05 dataset to ensure that the emotional categories in both datasets are fully consistent. The merged dataset covers a wider range of emotions and scenarios, providing a richer and more diverse data foundation for subsequent model training. Following the experimental setup from earlier, the merged dataset is split into three parts: a training set, validation set, and test set. The training set accounts for 70% of the total dataset, the validation set comprises 15%, and the remaining 15% is used for testing.
4.6.2. Experimental Results Analysis
The experiments are conducted on four models, including the baseline model VAVL and three models of the proposed in this paper. These three models are the facial expression and speech bimodal emotion recognition model based on the E-Branchformer network; the facial expression, speech, and posture trimodal emotion recognition model based on the Conformer network; and the facial expression, speech, and posture trimodal emotion recognition model based on the E-Branchformer network. The experimental results are shown in
Table 8.
To evaluate the generalization ability of our model, we test the four models trained on CREMA-D directly on an extended dataset incorporating eNTERFACE’05, without any fine-tuning. Among them, the performance of the baseline model, VAVL, declines, making it the lowest-performing model among the four.
In contrast, the proposed optimal model, the facial expression, speech, and posture trimodal emotion model, achieves a 7% higher Macro F1-score and a 6.1% higher Micro F1-score compared to the baseline model VAVL. This result indicates that our model can effectively adapt to datasets with different cultural backgrounds and recording conditions, demonstrating superior generalization capability.
Additionally, when compared to the bimodal model, although its model parameter count increases by nearly 9 M, its Macro F1-score and Micro F1-score are approximately 4% higher, demonstrating stronger generalization performance. This experimental result highlights the effectiveness of the trimodal model proposed in this paper.
5. Discussion
The proposed model has demonstrated excellent performance on controlled laboratory datasets (CREMA-D and eNTERFACE’05); however, its applicability in real-world scenarios requires further investigation. By integrating facial expressions, speech, and body posture, the model enables a more precise understanding of complex emotional expressions, making it suitable for mental health monitoring, intelligent education systems, and service robots. Compared to bimodal systems, the inclusion of body posture information enhances the model’s adaptability when a single modality fails or is affected by external interference. Future work will focus on evaluating the model’s real-world applicability and optimizing its real-time computational performance on resource-constrained mobile devices.
In addition to these technical challenges, significant ethical and bias issues need to be addressed before deploying emotion recognition systems in real-world environments. The unauthorized collection of sensitive data—such as facial expressions, speech, and posture—in public spaces poses serious privacy concerns. It is essential that data acquisition adheres to strict ethical standards and legal requirements, ensuring informed consent is obtained from individuals prior to data collection.
Moreover, inherent biases in emotion recognition models can lead to unfair or inaccurate predictions, particularly affecting underrepresented groups. As highlighted by Luo et al. [
28], traditional evaluation metrics may fail to capture the fluid and culturally nuanced nature of gender and emotion, thereby embedding sociotechnical biases within the system. Similarly, Alabdulmohsin et al. [
29] demonstrate that even state-of-the-art multimodal models can inadvertently absorb stereotypes if the training data are imbalanced. These studies underscore the need for integrating bias mitigation strategies and sociotechnical evaluation frameworks to enhance both fairness and reliability.
Therefore, future research should not only aim to improve technical performance and real-time processing capabilities on mobile devices but also prioritize the development of robust ethical guidelines and bias correction mechanisms. This dual focus is critical to ensuring that the deployment of emotion recognition technologies promotes efficiency while safeguarding individual privacy and social fairness.
6. Conclusions
This paper presents a novel multimodal emotion recognition model that integrates facial expressions, speech, and body posture information to improve the accuracy and efficiency of emotion recognition. Notably, the model employs a symmetrical architecture that treats each modality—facial, acoustic, and posture—as a separate yet equally important branch. Each branch is processed in parallel and merged through a shared module, ensuring balanced integration of information without any single modality dominating the fusion process. The E-Branchformer network is introduced and extended from speech processing tasks to multimodal emotion recognition tasks. Additionally, this study designs a body posture representation based on OpenPose, effectively converting posture information into an input that can be processed by neural networks, further enriching the diversity of emotion feature expressions.
In the experiments, a series of comparative and optimization experiments is conducted on the CREMA-D dataset and the extended dataset that includes eNTERFACE’05. The results show that the proposed model significantly outperforms the baseline models in key metrics such as the F1-score, especially after the inclusion of body posture information, where the multimodal fusion effect becomes more pronounced. Moreover, compared to the Conformer network, the E-Branchformer network demonstrates higher performance and lower parameter count, validating its applicability and superiority in emotion recognition tasks.
Overall, the research presented in this paper provides an effective and innovative solution for multimodal emotion recognition, overcoming the limitations of unimodal or bimodal approaches. Moreover, compared to the VAVL baseline model, the proposed approach reduces the number of parameters by 33.3%, thereby lowering computational complexity.
Author Contributions
Conceptualization, S.F. and C.W.; methodology, S.F.; validation, S.F., J.J. and C.W.; formal analysis, S.F.; investigation, J.J.; resources, C.W.; data curation, S.F.; writing—original draft preparation, S.F.; writing—review and editing, J.J. and C.W.; visualization, S.F.; supervision, C.W.; project administration, C.W.; funding acquisition, C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Beijing Education Science “14th Five-Year Plan” Key Project “Research on Classroom Interaction Behavior Evaluation Based on Artificial Intelligence” (project no. CHAA22058).
Data Availability Statement
The datasets used in this study are publicly available and can be accessed through public repositories.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Wu, F.; Peng, Y.; Pan, J.; Sridhar, P.; Han, K.J.; Watanabe, S. E-branchformer: Branchformer with enhanced merging for speech recognition. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 84–91. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Wundt, W. Vorlesungen über Menschen-und Thierseele; Leopold Voß: Rome, Italy, 1863; Volume 1. [Google Scholar]
- Ezzameli, K.; Mahersia, H. Emotion recognition from unimodal to multimodal analysis: A review. Inf. Fusion 2023, 99, 101847. [Google Scholar] [CrossRef]
- Asiya, U.; Kiran, V. A Novel Multimodal Speech Emotion Recognition System. In Proceedings of the 2022 Third International Conference on Intelligent Computing Instrumentation and Control Technologies (ICICICT), Kannur, India, 11–12 August 2022; pp. 327–332. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Gu, X.; Shen, Y.; Xu, J. Multimodal emotion recognition in deep learning: A survey. In Proceedings of the 2021 International Conference on Culture-oriented Science & Technology (ICCST), Beijing, China, 18–21 November 2021; pp. 77–82. [Google Scholar]
- Huang, J.; Tao, J.; Liu, B.; Lian, Z.; Niu, M. Multimodal transformer fusion for continuous emotion recognition. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3507–3511. [Google Scholar]
- Tian, J.; She, Y. A visual–audio-based emotion recognition system integrating dimensional analysis. IEEE Trans. Comput. Soc. Syst. 2022, 10, 3273–3282. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, A.H.; Rouditchenko, A.; Glass, J. Uavm: Towards unifying audio and visual models. IEEE Signal Process. Lett. 2022, 29, 2437–2441. [Google Scholar] [CrossRef]
- Goncalves, L.; Busso, C. AuxFormer: Robust approach to audiovisual emotion recognition. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 7357–7361. [Google Scholar]
- Goncalves, L.; Leem, S.G.; Lin, W.C.; Sisman, B.; Busso, C. Versatile audio-visual learning for emotion recognition. IEEE Trans. Affect. Comput. 2024, 16, 306–318. [Google Scholar] [CrossRef]
- Lin, Z.; Yu, S.; Kuang, Z.; Pathak, D.; Ramanan, D. Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 19325–19337. [Google Scholar]
- Li, Y.; Wang, Y.; Cui, Z. Decoupled Multimodal Distilling for Emotion Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6631–6640. [Google Scholar]
- Zhang, R.; Chi, X.; Liu, G.; Zhang, W.; Du, Y.; Wang, F. Unimodal Training-Multimodal Prediction: Cross-modal Federated Learning with Hierarchical Aggregation. arXiv 2023, arXiv:2303.15486. [Google Scholar]
- Wu, Y.; Daoudi, M.; Amad, A. Transformer-Based Self-Supervised Multimodal Representation Learning for Wearable Emotion Recognition. IEEE Trans. Affect. Comput. 2024, 15, 157–172. [Google Scholar] [CrossRef]
- Ge, M.; Tang, D.; Li, M. Video Emotion Open-vocabulary Recognition Based on Multimodal Large Language Model. arXiv 2024, arXiv:2408.11286. [Google Scholar]
- Peng, Y.; Dalmia, S.; Lane, I.; Watanabe, S. Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 17627–17643. [Google Scholar]
- Peng, Y.; Kim, K.; Wu, F.; Yan, B.; Arora, S.; Chen, W.; Tang, J.; Shon, S.; Sridhar, P.; Watanabe, S. A Comparative Study on E-Branchformer vs Conformer in Speech Recognition, Translation, and Understanding Tasks. arXiv 2023, arXiv:2305.11073. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Hsu, W.N.; Sriram, A.; Baevski, A.; Likhomanenko, T.; Xu, Q.; Pratap, V.; Kahn, J.; Lee, A.; Collobert, R.; Synnaeve, G.; et al. Robust wav2vec 2.0: Analyzing domain shift in self-supervised pre-training. arXiv 2021, arXiv:2104.01027. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 audio-visual emotion database. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Luo, S.; Kim, S.J.; Duan, Z.; Chen, K. A Sociotechnical Lens for Evaluating Computer Vision Models: A Case Study on Detecting and Reasoning about Gender and Emotion. arXiv 2024, arXiv:2406.08222. [Google Scholar]
- Alabdulmohsin, I.; Wang, X.; Steiner, A.P.; Goyal, P.; D’Amour, A.; Zhai, X. CLIP the Bias: How Useful is Balancing Data in Multimodal Learning? In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
Figure 1.
Emotion recognition model structure, consisting of a Feature Extraction Layer, Modal Processing Layer, Shared Layer, and Emotion Classification Layer.
Figure 1.
Emotion recognition model structure, consisting of a Feature Extraction Layer, Modal Processing Layer, Shared Layer, and Emotion Classification Layer.
Figure 2.
Video screenshot of an angry emotion from the dataset.
Figure 2.
Video screenshot of an angry emotion from the dataset.
Figure 3.
Detected facial features of a person.
Figure 3.
Detected facial features of a person.
Figure 4.
Facial expression feature visualization of an angry emotion in a video.
Figure 4.
Facial expression feature visualization of an angry emotion in a video.
Figure 5.
Body posture detection results for people with various emotions: (a) anger; (b) disgust; (c) fear; (d) happiness; (e) neutral; (f) sadness.
Figure 5.
Body posture detection results for people with various emotions: (a) anger; (b) disgust; (c) fear; (d) happiness; (e) neutral; (f) sadness.
Figure 6.
Representation of human posture information in a video.
Figure 6.
Representation of human posture information in a video.
Figure 7.
Body key points output by OpenPose.
Figure 7.
Body key points output by OpenPose.
Figure 8.
Face key points output by OpenPose.
Figure 8.
Face key points output by OpenPose.
Figure 9.
Screenshot from the CREMA-D corpus.
Figure 9.
Screenshot from the CREMA-D corpus.
Figure 10.
Screenshot from the eNTERFACE’05 corpus.
Figure 10.
Screenshot from the eNTERFACE’05 corpus.
Figure 11.
Improved cgMLP module architecture.
Figure 11.
Improved cgMLP module architecture.
Figure 12.
Confusion matrices of five training runs based on the Conformer network in the CREMA-D Emotional Corpora: (a) Split 1; (b) Split 2; (c) Split 3; (d) Split 4; (e) Split 5.
Figure 12.
Confusion matrices of five training runs based on the Conformer network in the CREMA-D Emotional Corpora: (a) Split 1; (b) Split 2; (c) Split 3; (d) Split 4; (e) Split 5.
Figure 13.
Confusion matrices of five training runs based on the E-Branchformer network in the CREMA-D Emotional Corpora: (a) Split 1; (b) Split 2; (c) Split 3; (d) Split 4; (e) Split 5.
Figure 13.
Confusion matrices of five training runs based on the E-Branchformer network in the CREMA-D Emotional Corpora: (a) Split 1; (b) Split 2; (c) Split 3; (d) Split 4; (e) Split 5.
Table 1.
The feed-forward layer of the E-Branchformer network.
Table 1.
The feed-forward layer of the E-Branchformer network.
| Network | Input Dimension | Onput Dimension | Dropout Rate |
|---|
| LayerNorm | 512 | 512 | - |
| Linear | 512 | 2048 | - |
| Swish | - | - | - |
| Dropout | - | - | 0.1 |
| Linear | 2048 | 512 | - |
| Dropout | - | - | 0.1 |
Table 2.
Model performance under different Conformer networks in the CREMA-D Emotional Corpora.
Table 2.
Model performance under different Conformer networks in the CREMA-D Emotional Corpora.
| Visual Layer | Acoustic Layer | Pose Layer | Shared Layer | F1-Macro | F1-Micro | Parameters |
|---|
| 1 | 1 | 1 | 1 | 0.802 | 0.852 | 39.97 M |
| 1 | 1 | 1 | 2 | 0.797 | 0.848 | 46.29 M |
| 1 | 1 | 1 | 3 | 0.796 | 0.843 | 52.61 M |
| 1 | 1 | 1 | 4 | 0.791 | 0.839 | 58.94 M |
| 2 | 2 | 2 | 1 | 0.797 | 0.848 | 58.94 M |
Table 3.
Model performance under different E-Branchformer networks in the CREMA-D Emotional Corpora.
Table 3.
Model performance under different E-Branchformer networks in the CREMA-D Emotional Corpora.
| Visual Layer | Acoustic Layer | Pose Layer | Shared Layer | F1-Macro | F1-Micro | Parameters |
|---|
| 1 | 1 | 1 | 1 | 0.803 | 0.854 | 34.46 M |
| 1 | 1 | 1 | 2 | 0.814 | 0.853 | 40.49 M |
| 1 | 1 | 1 | 3 | 0.805 | 0.847 | 47.42 M |
| 1 | 1 | 1 | 4 | 0.789 | 0.845 | 53.89 M |
| 2 | 2 | 2 | 1 | 0.788 | 0.842 | 53.89 M |
Table 4.
Test results and standard deviation of five splits using the optimal Conformer-based configuration on the CREMA-D Emotional Corpora.
Table 4.
Test results and standard deviation of five splits using the optimal Conformer-based configuration on the CREMA-D Emotional Corpora.
| | Split 1 | Split 2 | Split 3 | Split 4 | Split 5 | Standard Deviation |
|---|
| F1-Macro | 0.825 | 0.815 | 0.763 | 0.777 | 0.831 | 0.031 |
| F1-Micro | 0.862 | 0.851 | 0.838 | 0.834 | 0.874 | 0.017 |
Table 5.
Test results and standard deviation of five splits using the optimal E-Branchformer-based configuration on the CREMA-D Emotional Corpora.
Table 5.
Test results and standard deviation of five splits using the optimal E-Branchformer-based configuration on the CREMA-D Emotional Corpora.
| | Split 1 | Split 2 | Split 3 | Split 4 | Split 5 | Standard Deviation |
|---|
| F1-Macro | 0.828 | 0.818 | 0.809 | 0.781 | 0.833 | 0.021 |
| F1-Micro | 0.865 | 0.849 | 0.837 | 0.835 | 0.878 | 0.018 |
Table 6.
Performance comparison of the proposed models and three baseline models on the CREMA-D Emotional Corpora.
Table 6.
Performance comparison of the proposed models and three baseline models on the CREMA-D Emotional Corpora.
| Models | F1-Macro | F1-Micro | Parameters |
|---|
| VAVL | 0.779 | 0.826 | 61.38 M |
| UAVM | 0.749 | 0.769 | - |
| AuxFormer | 0.698 | 0.763 | - |
| Conformer (Expression, Speech, and Posture) | 0.802 | 0.852 | 39.97 M |
| E-Branchformer (Expression, Speech, and Posture) | 0.814 | 0.853 | 40.94 M |
Table 7.
Ablation study results of different modality combinations based on the E-Branchformer model on the CREMA-D Corpus.
Table 7.
Ablation study results of different modality combinations based on the E-Branchformer model on the CREMA-D Corpus.
| Models | F1-Macro | F1-Micro |
|---|
| Expression and Speech | 0.801 | 0.848 |
| Expression and Posture | 0.781 | 0.839 |
| Speech and Posture | 0.647 | 0.711 |
| Expression, Speech, and Posture | 0.814 | 0.853 |
Table 8.
Comparison of model performance on the extended dataset.
Table 8.
Comparison of model performance on the extended dataset.
| Models | F1-Macro | F1-Micro | Parameters |
|---|
| VAVL | 0.634 | 0.655 | 61.38 M |
| E-Branchformer (Expression and Speech) | 0.664 | 0.683 | 31.22 M |
| Conformer (Expression, Speech, and Posture) | 0.698 | 0.716 | 39.97 M |
| E-Branchformer (Expression, Speech, and Posture) | 0.704 | 0.729 | 40.94 M |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}