3.2.1. Motivation for Two-Stage Design
In black-box adversarial attack tasks, there is often a fundamental trade-off between attack effectiveness and the imperceptibility of perturbations. The former typically requires strong perturbations to alter the model’s prediction, whereas the latter demands minimal changes to preserve visual similarity to the original image. This inherent conflict poses a substantial challenge for designing a unified reward function within an RL framework, thereby hindering both policy convergence and the overall stability of the training process.
As illustrated in
Figure 2, we plot the dynamic trajectories of the target class prediction probability and the structural similarity index (SSIM) during progressive perturbations applied to various input samples. These two metrics exhibit a clear inverse relationship: as the prediction probability for the target class increases, the SSIM value consistently decreases. This monotonic divergence highlights a fundamental structural conflict between attack success and perceptual similarity, indicating that
where
x is the original sample,
is the adversarial perturbation,
denotes the predicted probability of the target category, and
is the structural similarity function. Evidently, the two objective functions exhibit opposing gradient directions, indicating that they guide the optimization process toward different and potentially conflicting, trajectories in the perturbation space. When both objectives are incorporated simultaneously into the reward function of a reinforcement learning framework, we have, for example,
Consequently, the overall gradient of the reward function can be expressed as
where the perturbation
is initialized based on
.
This staged structure enables the policy to focus on attack effectiveness during the initial training phase, thereby avoiding interference caused by conflicting gradients. In the subsequent phase, the optimization process builds upon the adversarial perturbations learned previously and further concentrates on improving the quality of the perturbations. Compared to the direct weighted combination approach employed in single-phase optimization, the proposed method explicitly decouples the optimization objectives at the structural level, which facilitates more stable convergence of the model and enhances the final perturbation quality.
3.2.3. Phase I: Learning to Attack
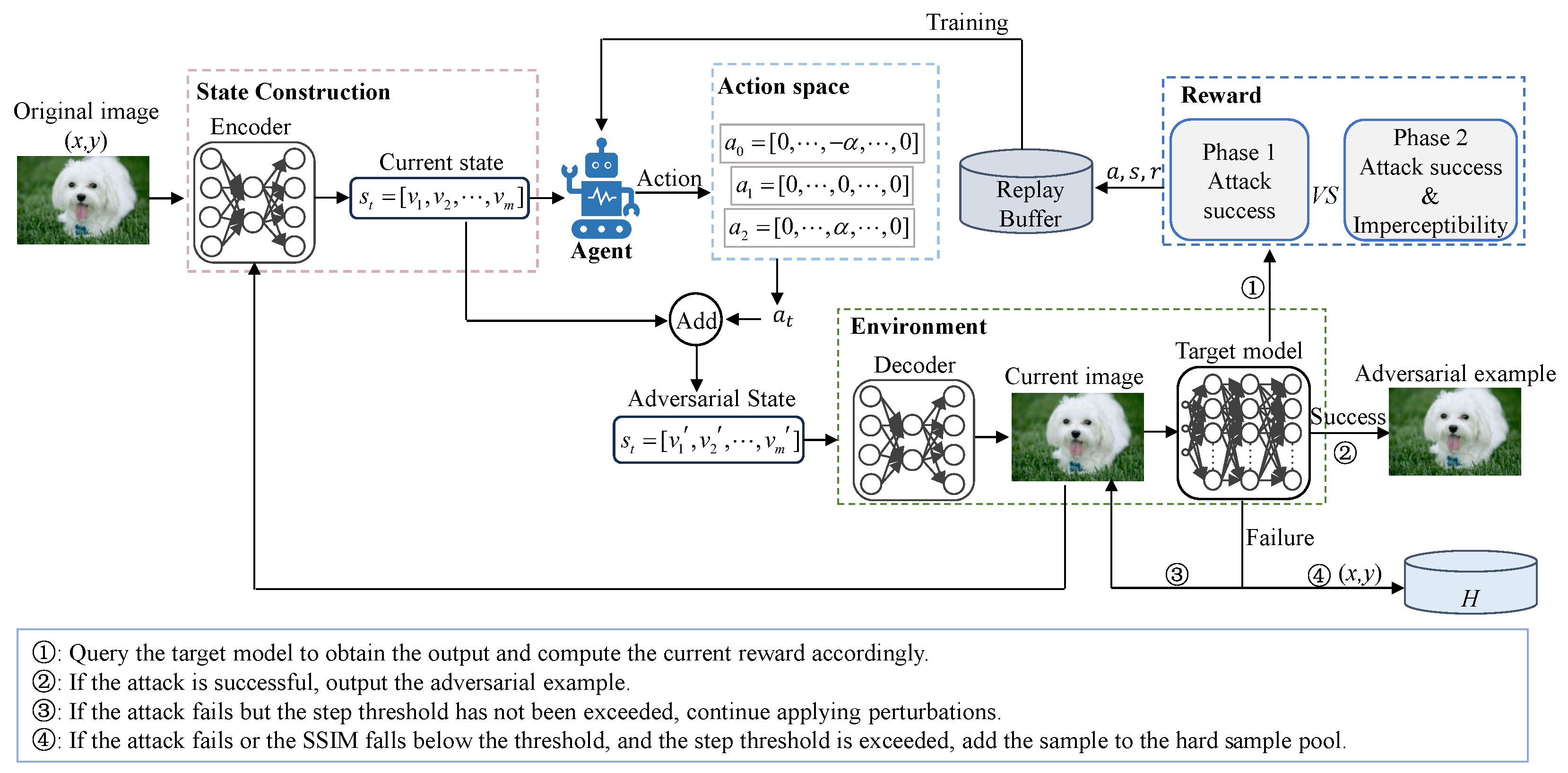
In the first phase of the proposed framework, the objective is to train an RL agent to acquire effective attack policies that maximize the ASR of adversarial examples. At this phase, the focus is solely on achieving attack success, without regard for perceptual similarity. Specifically, the agent incrementally explores and optimizes action strategies through the RL mechanism to induce incorrect predictions from the target model. The core components of the RL formulation used in this phase are summarized in
Table 1.
Environment. In QTRL, the environment is composed of a decoder d and a target model f. The decoder reconstructs the latent representations from the feature space into the pixel space, whereas the target model receives the generated adversarial examples and performs classification or prediction.
Action space. The action space is defined as
, where each action represents a perturbation applied to the input image. Specifically, each action is a sparse vector with the same dimensionality as the feature vector
v, perturbing only a single dimension with a fixed magnitude. This design simulates fine-grained adjustments to the input representation. For each dimension, three types of operations are considered:
, 0, and
. The action set is formally expressed as
Each vector applies the corresponding perturbation to the j-th dimension while leaving all other elements unchanged. The complete action space can thus be written as .
Given the discrete nature of the action space in this study, Q-learning algorithms demonstrate significant adaptability and advantages for such tasks. By directly learning the state-action value function, Q-learning avoids the need for the explicit modeling of the policy distribution, resulting in more stable training and faster convergence when dealing with high-dimensional yet structurally well-defined discrete action spaces. Moreover, Q-learning can utilize past experiences more efficiently, thereby enhancing data efficiency, which is particularly important in black-box attack scenarios with limited query budgets. Considering both the characteristics of the task and the need for training stability, this study selected the Double Deep Q-Network (DDQN) as the foundational reinforcement learning algorithm.
State space. The initial state space is defined as , where , and N represents the number of images. As actions are performed, the dimensionality of the state space gradually increases.
Policy. The agent follows an -greedy policy, selecting actions based on the exploration-exploitation trade-off.
Reward function design. In contrast to traditional gradient-based methods, our agent operates in the latent feature space, which is derived from a pre-trained autoencoder. Each action taken by the agent results in a small transformation within this latent space, which is then decoded back into the pixel space to generate a perturbed image. The reward function is designed to incentivize the agent to increase the confidence in non-ground-truth classes. A significant reward is given when the prediction shifts away from the original label. In the first phase, QTRL adopts a success-oriented reward function:
where
and
are weighting coefficients. Let
denote the maximum probability among all non-ground-truth classes predicted by the target model
f for the current sample
at state
, and let
represent the highest such probability observed across all previous samples during the agent’s trajectory. Then,
is defined as
and
denotes whether the attack succeeds:
where
denotes the predicted probability of the GT by the target model
f for the current sample
at state
.
Hard sample mining mechanism. To improve the robustness and generalization ability of the agent, a hard example mining mechanism is introduced in QTRL. The process is illustrated in
Figure 4. Specifically, a hard example pool
H is constructed to store challenging samples identified during the training process. These hard samples can be categorized into two main types: (1) those for which the attack fails and (2) those for which the attack succeeds but the SSIM between the adversarial and original images falls below a predefined threshold. Such samples are typically more resistant to adversarial perturbations or exhibit greater perceptual differences, thereby posing increased challenges to the attack strategy. By repeatedly training on these hard examples, the agent gains deeper insight into the decision boundaries and perceptual constraints of the target model, ultimately improving both the reliability and stealth of its learned attack policy. The detailed process is outlined in Algorithm 1.
It should be noted that while this mechanism improves the robustness and generalization capability of the policy, it also introduces certain resource overheads. Specifically, during each training iteration, the system must evaluate the performance of training samples under the current policy to select hard samples. Since these hard samples are often reused in subsequent training, a small cache must be maintained in memory. In scenarios involving large-scale datasets or high-resolution images, the high dimensionality and complex distribution of samples can significantly increase the frequency of selection and caching demands, thereby resulting in additional memory and computational burdens. This mechanism can be flexibly adjusted according to specific experimental requirements to balance efficiency and performance.
The proposed hard sample mining mechanism dynamically samples instances that either fail to generate successful adversarial examples or exhibit poor perturbation quality during training, thereby continuously enhancing the agent’s adaptability to boundary cases. This difficulty-driven training signal facilitates the learning of a more discriminative policy function, ultimately improving the model’s generalization capability on out-of-distribution samples. Moreover, hard samples often emerge during training phases where the policy has not yet converged or the model exhibits significant performance fluctuations. Prioritizing such samples in training helps improve the agent’s stability and convergence efficiency when dealing with weak gradient signals or noisy feedback. This mechanism further strengthens the robustness of the policy learning process under conditions of reward bias or noise, contributing to the stability of training in complex or non-ideal environments.
Model training. At each step, the agent selects an action
based on policy
given the current state
, transitions to the next state
, and receives a reward
from the environment. The tuple
, referred to as a transition sample, is stored in the replay buffer for the subsequent training of the evaluation
Q-network. During training, a batch of transitions is randomly sampled from the replay buffer to update the evaluation
Q-network. The target value used for this update is computed by the target
Q-network, as defined in Equation (
16):
where
denotes the parameters of the target
Q-network, and
is the discount factor. The loss function used to train the evaluation
Q-network is defined as
| Algorithm 1: Hard Sample Mining Mechanism. |
- Input
Phase indicator , similarity function , similarity threshold , hard pool size threshold , policy - 1
Initialize the hard sample pool: - 2
for each episode do: - 3
Obtain input sample - 4
while not reached max_step and attack is unsuccessful do: - 5
Generate the adversarial example - 6
Evaluate attack success and compute the similarity score - 7
if then: - 8
if attack is unsuccessful then: - 9
- 10
end if - 11
else: - 12
if attack is unsuccessful or then: - 13
- 14
end if - 15
end if - 16
if and then: - 17
Randomly sample a mini-batch from H - 18
Perform additional training on to refine the policy - 19
end if - 20
end for - Output
Updated agent policy with enhanced robustness and generalization
|
3.2.4. Phase II: Optimizing for Imperceptibility
After the agent has learned to attack successfully, QTRL incorporates visual imperceptibility into the reward function to balance attack effectiveness with perceptual quality. Specifically, the SSIM is adopted as the similarity metric, and the reward function is redesigned as follows:
where
and
are weighting coefficients,
is defined as
and
is defined as
where
and
are both SSIM threshold values, and
denotes a constant..
Equation (
18) is designed to motivate the agent to achieve adversarial misclassification while preserving the visual similarity to the original input as much as possible. Phase II training is initiated after a predetermined number of training episodes. Algorithm 2 presents the overall procedure of the proposed two-phase reinforcement learning framework. In each training episode, the agent interacts with the target model in a black-box manner by perturbing the feature representation
of the input image. Depending on the current phase, the agent receives the corresponding reward signals: Phase I focuses on improving the attack success rate, while Phase II emphasizes both attack effectiveness and the preservation of perceptual quality. Samples that consistently fail to be perturbed successfully or have an SSIM below the threshold are added to a hard sample pool
H for more focused training attention.
| Algorithm 2: Two-phase reinforcement learning framework. |
- Input
Target model f, training dataset , encoder e, decoder d, agent policy , learning rate , maximum steps per episode T, total number of episodes N, phase transition threshold - 1
Initialize the agent parameters , replay buffer B, hard sample pool , historical maximum confidence , phase indicator - 2
for episode = 1 to N do - 3
if and then - 4
- 5
end if - 6
Sample from D or H according to a predefined schedule - 7
Encode features: , initialize the state - 8
Initialize the confidence tracker - 9
for to T do - 10
Select action - 11
Update state: , decode - 12
Query target model: , obtain prediction - 13
Compute reward: - 14
Store transition in buffer B - 15
Update policy using DDQN with samples from buffer B - 16
if attack is successful then - 17
break - 18
end if - 19
end for - 20
Add samples to H based on the Algorithm 1 - 21
end for - Output
Trained agent policy
|
By virtue of the QTRL framework’s design principle that effectively decouples attack success from perturbation optimization objectives, the implementation details of the reward functions in both stages demonstrate strong robustness. Specifically, provided that the reward function clearly drives attack success in the first stage and effectively guides perceptual similarity optimization in the second stage, the framework’s core mechanism can operate stably and achieve the intended objectives. Meanwhile, the hard sample mining mechanism, through dynamic identification and training on samples with failed attacks or low-quality perturbations, enhances the agent’s adaptability to boundary samples. This dual mechanism not only reduces reliance on complex reward shaping but improves the method’s practicality and deployability across diverse scenarios.
3.2.5. Attack Cost Modeling and Efficiency Evaluation
To quantitatively evaluate the overall efficiency of the QTRL method in practical black-box attack scenarios, a theoretical model is established to analyze the total cost incurred during the adversarial attack process. The total attack cost associated with QTRL can be divided into two main components: the first is the computational resource overhead required during the training phase, representing the one-time policy learning cost; the second is the query cost generated from interactions with the target model during the attack phase. Specifically, the total attack cost is defined as follows:
where
denotes the fixed computational overhead required for training the RL policy. This is a one-time cost independent of the number of attack samples.
represents the average cost per query during the attack process.
Q is the average number of queries required per attack.
N denotes the total number of attack samples.
Although QTRL introduces a fixed training overhead , it significantly reduces the average number of queries Q required per attack. Consequently, the total cost tends to grow approximately linearly with the number of attack samples. As the attack scale increases, QTRL becomes more cost-efficient compared to strategies that require no training but incur a higher average number of queries per attack.
Furthermore, a cost-equilibrium point
can be defined as the minimum number of attack samples that satisfies the following condition:
where
is the reference metric, representing the average number of queries required per attack in the absence of an agent-based training mechanism. When the number of attack samples
N exceeds
(i.e.,
), the query cost savings achieved by QTRL outweigh its training overhead, thereby demonstrating a significant advantage in overall efficiency.
Therefore, the design of QTRL is well suited for large-scale black-box attack tasks in practical scenarios. In applications involving attacks on multiple target images or the continuous execution of attack strategies, the initial training cost can be rapidly amortized, while the reduced online query overhead significantly improves overall attack efficiency. This cost structure not only ensures the method’s effectiveness but also endows QTRL with strong scalability and practical deployment value.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}