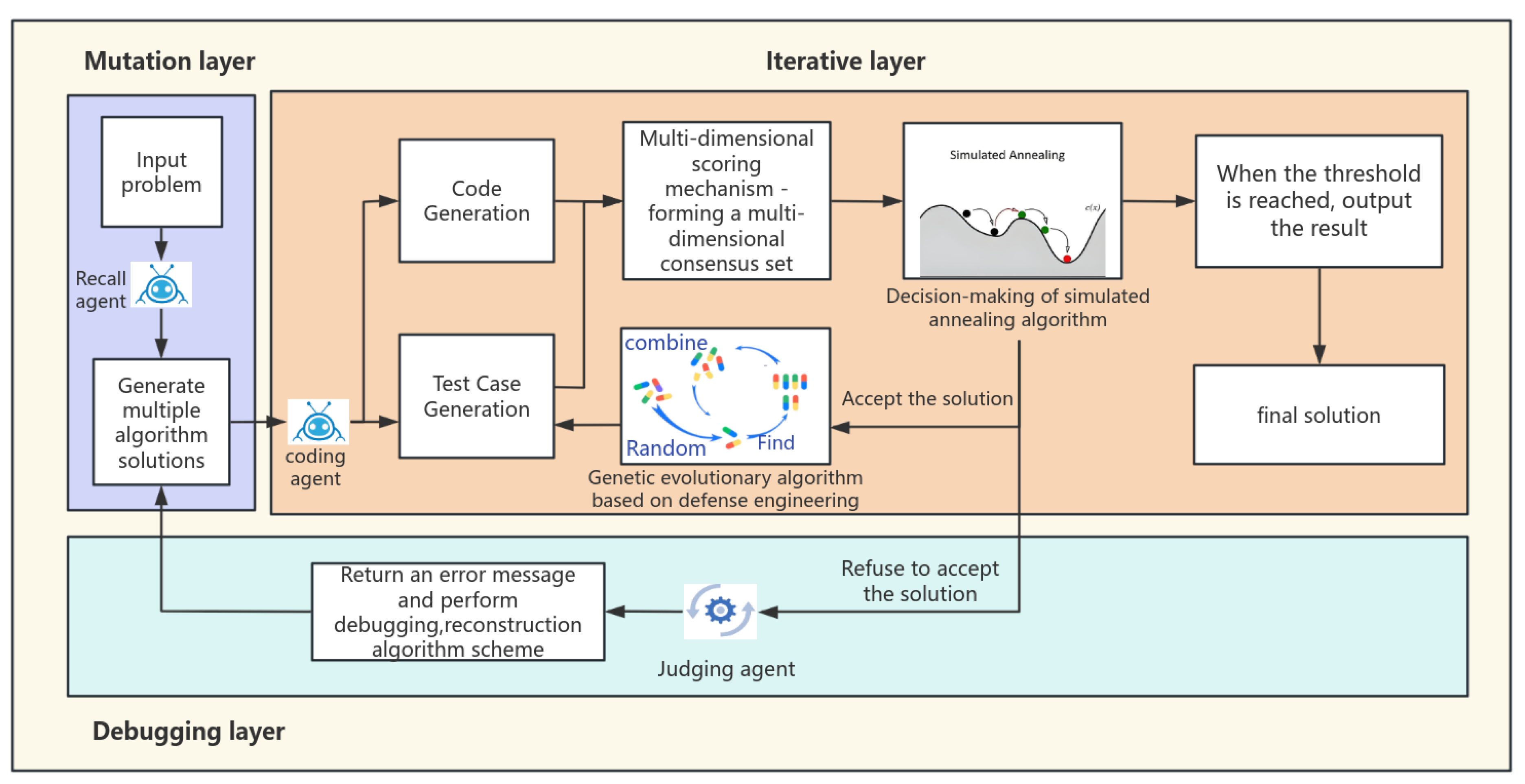
3.3.3. Multi-Dimensional Scoring System
In a multi-dimensional scoring system, the fitness scores are assessed based on four indicators. The dynamic weight allocation strategy was implemented for the four indicators to adapt to different problem complexities. The weights were determined through a combination of empirical results and expert insights. Initially, we conducted a series of experiments to assess the impact of different weight configurations on the optimization process. This involved testing various scenarios with distinct problem characteristics to identify the most effective weight settings. Concurrently, we consulted with domain experts to gain a deeper understanding of how certain weights might influence the algorithm’s performance. The final weight assignment was calibrated based on both the empirical data and expert recommendations to ensure a balanced approach that enhances the overall effectiveness of our model.Functional correctness is assessed by test case pass rates; execution efficiency is shown by normalized scores of time and memory utilization; logical branch symmetry is detected by controlling the flow balance degree, that is, by comparing the complexity differences of paired branches (such as if-else). If there are five nested layers of “if” and only one line of “else”, it is a kind of imbalance phenomenon. We clearly define it using the following formula:
Depth: Count the number of logical layers in the branch (1 point for each nested layer).
T: denotes the AST subtree. This metric (range 0–1) penalizes depth disparities; values <0.3 indicate severe asymmetry. For interface symmetry, that is, API consistency check, we detect whether the parameter styles of all methods in the class are uniform. Consistent design helps us achieve standardized tool interfaces and reduce the risk of API misuse. The calculation method is to select the benchmark method, calculate the similarity between other methods and the benchmark, and take the average of the similarities of all methods.
where
M is the method count and simsim computes the Jaccard similarity of parameter names/types. Scores below 0.5 reflect inconsistent designs. Readability is evaluated based on static analysis scores from Pylint. Concerning dynamic weight regulations, if the problem description includes terms like “efficient” or “low latency,”
is elevated to
. In the event that symmetry constraints are identified,
is established at a minimum of 0.3. Customized scoring criteria are established based on particular specifications, producing solutions that more closely conform to the intended standards. The intuitive description combines multiple evaluation dimensions into a single score to assess the solution quality comprehensively.
: the weight
is dynamically adjusted.
fi: The fitness score of the
i-th dimension. Weighted combination of functionality, efficiency, symmetry, and readability, with dynamic adjustments. (Examples of scoring are shown in
Table 2).
The weight adjustment of the scoring system relies on manual adjustment. Although it is simple to operate, its robustness is limited, which may lead to unstable weights and make it difficult to generalize well to different tasks. We need to explore an automated weight adjustment method based on task data and model performance. Bayesian optimization can be used to complete the task, reducing the subjectivity of manual adjustment and improving the rationality and adaptability of weight setting. First of all, we define the reward function and take the scores of dimensions such as functionality, efficiency, readability, and structural symmetry of the code as the reward signals. Secondly, the Bayesian optimization algorithm is selected during the training process to continuously adjust the weights to maximize the reward function and achieve dynamic weight adjustment. Meanwhile, we directly incorporate constraints such as the token budget into the optimization process to ensure that the generated code not only has high quality but also meets resource limitations and achieves the integration of the optimization goals.
3.3.4. Innovation Mechanism
In the annealing decision module, the acceptance probability of suboptimal solutions is governed by the temperature
T. We utilize a dynamic adjustment technique for temperature
T. The initial temperature
is established according to the problem’s complexity.
is defined by the quantity of initial candidate solutions and their respective fitness ratings. If the average fitness decreases, indicating a more challenging problem, we will increase the temperature to extend the exploration phase. The adaptive technique, unlike a constant temperature such as
set at 1000, facilitates expedited convergence and reduces computing expenses in simpler tasks while ensuring sufficient exploration in difficult tasks, enhancing convergence speed by 30% in datasets like APPS. Take a practical example. If a code generation task has an initial population with a low average fitness score (e.g., 0.4) and a fitness variance of 0.05, and there are 100 initial candidate solutions, the initial temperature
is calculated as
= 40. The initial temperature is set based on the problem’s complexity. More complex problems with lower average fitness receive a higher initial temperature to encourage broader exploration.
: the maximum value of fitness theory (such as the upper limit of scoring). : the average fitness score of the initial population. : initial fitness variance. : smoothing factor (to prevent the denominator from being 0, usually taking the value of ). The formula dynamically sets the initial temperature to suit the problem’s complexity. It ensures that harder problems, which usually have a lower average fitness in the initial population, obtain a higher T0. This allows for a broader exploration of the solution space. By doing so, it helps the algorithm to avoid becoming trapped in local optima early on and significantly improves the efficiency of the optimization process.
We employ an adaptive dynamic cooling adjustment method that integrates exponential cooling with variance feedback to mitigate temperature fluctuations. The present population fitness variance (
) indicates the diversity of solutions. An elevated value signifies more population diversity and a wider range of solutions, necessitating a reduced cooling rate to extend the exploration phase. Conversely, less variance in population fitness indicates an increasing homogeneity within the population, requiring expedited cooling for swifter convergence. The constant
C functions as a tuning parameter to regulate the sensitivity of the cooling rate to variability. According to previous study experience,
C is often established at 100 to equilibrate the effects of variance variations. This strategy adjusts the cooling rate based on population diversity. Higher diversity slows cooling to extend exploration, while lower diversity accelerates cooling for faster convergence.
: The temperature of the next generation controls the degree of attenuation of the acceptance probability of the inferior solution. : The current temperature affects the exploration ability of the current iteration. : The basic cooling coefficient is the reference rate of temperature attenuation that determines the temperature. : Population fitness variance measures the diversity of the current solution. C: Variance sensitivity adjustment constant controls the influence of variance on the cooling rate. This formula adjusts cooling based on solution diversity, slowing cooling to explore when diverse and speeding it up when converging.
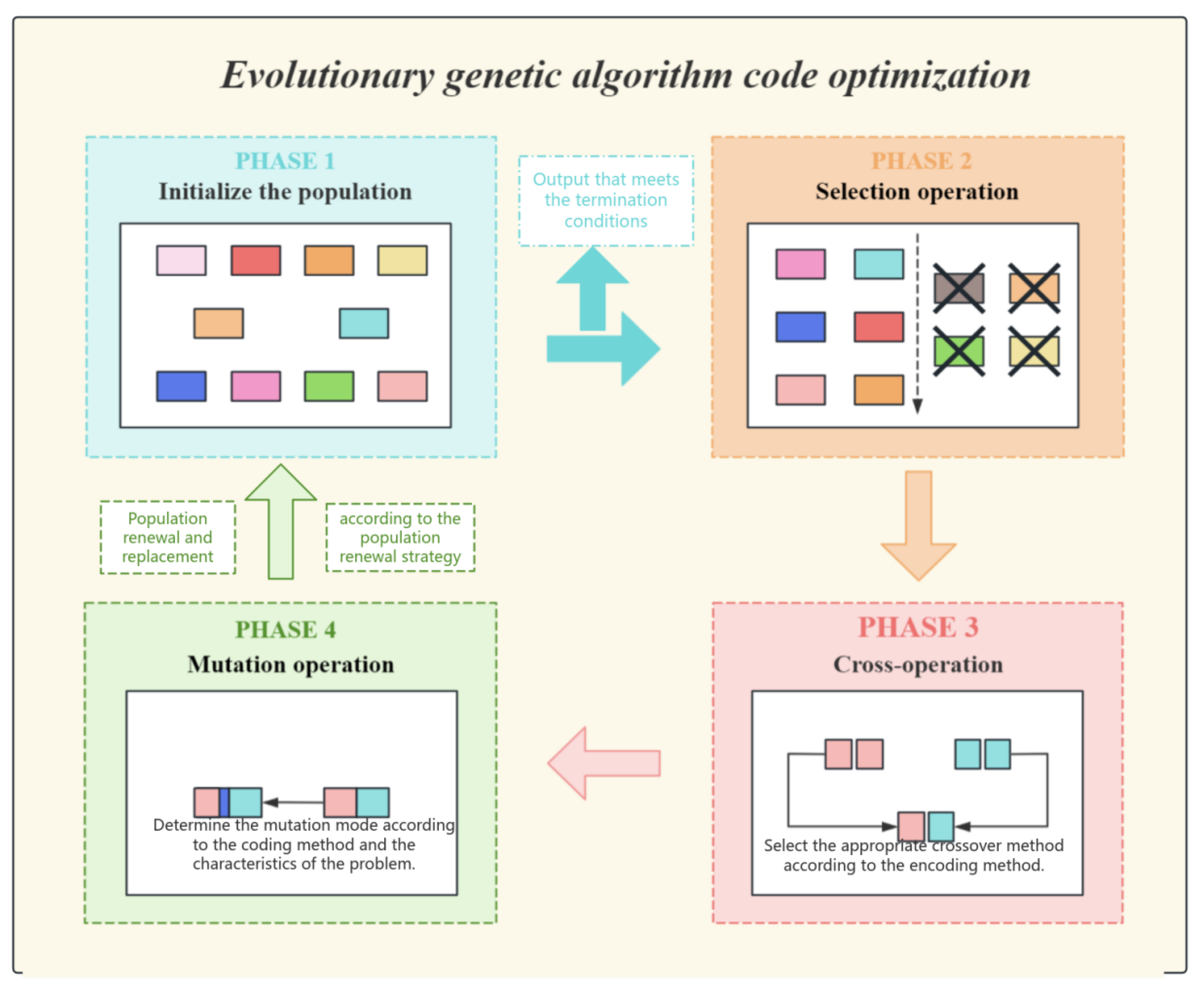
The dynamic temperature adjustment approach proficiently addresses the limitations of conventional exponential cooling, which employs a constant cooling rate such as
. This conventional method fails to ascertain the true condition of the population, which may result in premature convergence or superfluous iterations. Conversely, the hybrid strategy regulates temperature adaptively, enabling a reduction that responds dynamically to the problem’s complexity. When addressing issues of greater complexity or significant initial variance, this strategy automatically prolongs the high-temperature phase. It attains rapid convergence for less complex problems. (The schematic diagram of the evolutionary genetic algorithm is shown in
Figure 7).
The fundamental decision-making mechanism of simulated annealing relies on the probability acceptance criterion dictated by temperature
T. This criterion is the principal mechanism for determining the acceptance of a suboptimal solution—a new solution with a score inferior to the existing one.
is defined as Scorenew minus Scorecurrent, indicating the score disparity between the new and current solutions, and
T denotes the current temperature parameter. When
exceeds 0, it signifies that the new answer is superior and will be accepted unequivocally. Nevertheless, when
is less than or equal to zero, the new solution is deemed suboptimal. However, even if the new approach reduces the readability of the code while presenting an innovative structure, there is a certain likelihood of its preservation. The retention likelihood is predominantly influenced by temperature T. In the high-temperature phase, the algorithm is inclined to accept suboptimal solutions, promoting the exploration of novel regions, particularly in the initial phases. Conducting comprehensive searches throughout the solution space prevents entrapment in local optima. In the low-temperature phase, the algorithm prioritizes fine-tuning in its later phases, concentrating on high-quality solutions while nearly discarding all inferior options and prioritizing localized optimization.
: The probability of acceptance of the inferior solution. Score: The difference in fitness between the new solution and the current solution. T: Current temperature. At a high T, it accepts some worse solutions to escape local optima; at a low T, it becomes increasingly greedy.
The convergence determination formula provides a clear stopping condition for the algorithm. It halts the iterations when the maximum adaptation change in the last five iterations falls below a predefined threshold, indicating that the algorithm has reached a stable state. This ensures that computational resources are used efficiently, preventing unnecessary iterations once the solution has stabilized and saving time and computational power for more productive use. For example, in the code generation task, if we observe that the fitness changes of the last five iterations are 0.005, 0.003, 0.004, 0.002, and 0.001, respectively, then the maximum fitness change is 0.005. Since this value is less than the threshold
, according to Formula (5), the convergence mark will be set to 1, indicating that the algorithm has converged and the iteration can be stopped.
: the score changes in the last five iterations. : convergence threshold, termination when the score fluctuation is less than 1%. This formula flags convergence if the score improvements are less than 1% over five generations.
The resource consumption constraint formula acts as a financial advisor for the algorithm, meticulously setting a token budget to keep resource usage in check. For example, suppose our algorithm generates 50 candidate solutions in the first iteration, with each solution consuming 10 tokens. In the second iteration, it generates 40 candidate solutions, and in the third iteration, it generates 30 candidate solutions. Then, according to Formula (6), the first three iterations consumed a total of (50 + 40 + 30) × 10 = 1200 tokens. Assuming the maximum token budget
= 1500, it is still within the budget range at this time. However, if the fourth iteration continues to generate 30 candidate solutions, each consuming 10 tokens, then the total consumption will reach 1200 + 30 × 10 = 1500. Once the budget limit is reached, the algorithm will stop iterating.
: the number of candidate solutions generated in the KTH iteration. TokenCost: token consumption of a single candidate solution. : Maximum token budget. Enforces token/API call limits by reducing population size or early stopping when approaching the budget.
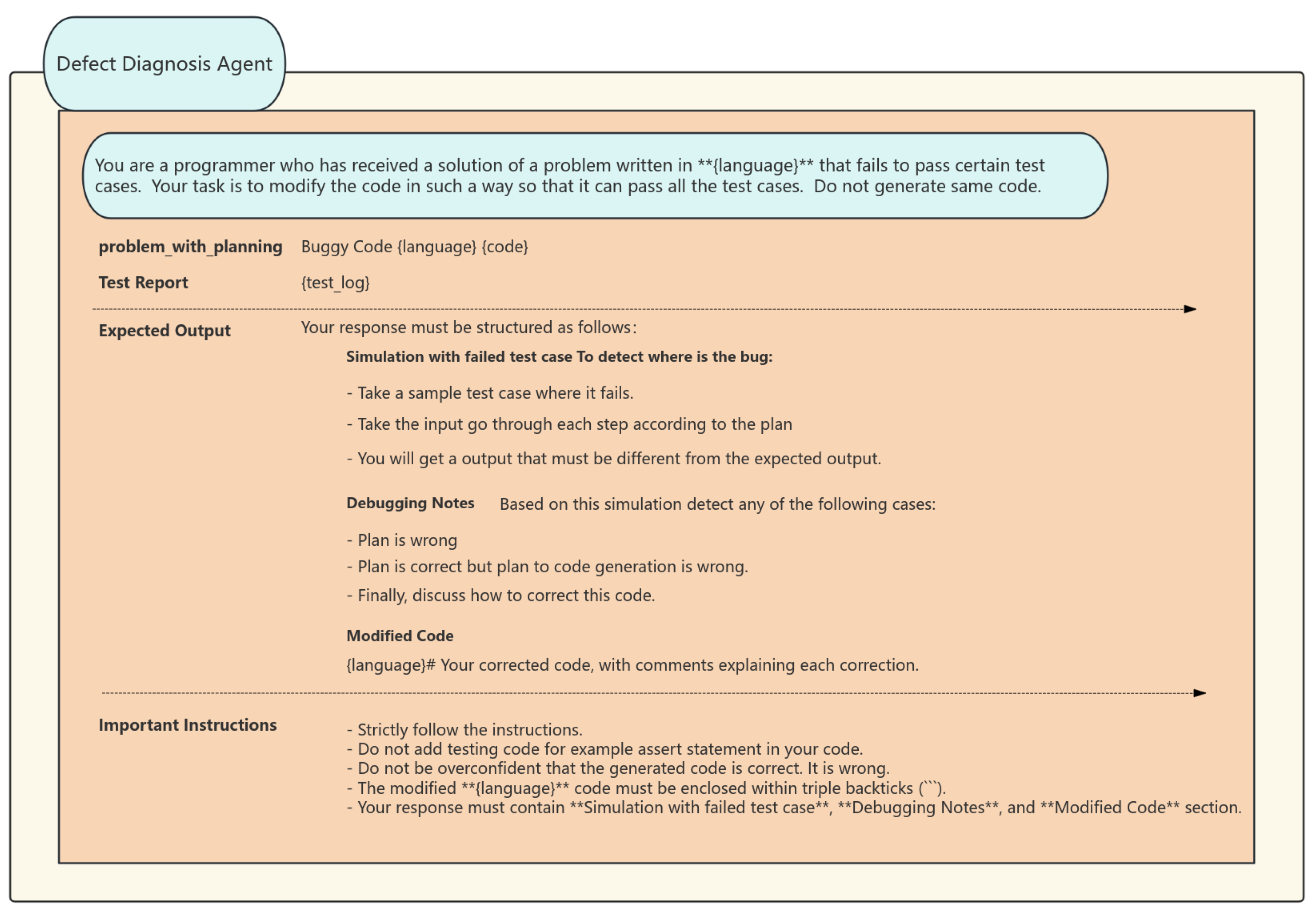
The essential component of the evolutionary operation is the evolving genetic algorithm, which employs a hybrid approach between elitism and tournament selection during the selection phase. Only individuals in the top ten percent of fitness are directly kept for the subsequent generation, while the remaining individuals produce parents via tournament selection. The intuitive description is that tournament selection increases the probability of selecting fitter individuals. The crossover operation can be incorporated with the defensive code template library, encompassing input validation, error handling, and boundary condition checks, thereby ensuring that the resulting code operates correctly and adheres to robust defensive programming principles. We employ directed syntax mutation to enhance code robustness, which has proven to be more effective than random mutation techniques. Utilizing boundary reinforcement, dynamic boundary verifications are incorporated within loops or conditional expressions.
: individual fitness. This formula is essentially a dynamic balance point established between “ensuring the convergence quality” and “maintaining the exploration ability”, and its parameters (10% elite ratio, tournament size 5) have been determined through empirical research as the optimal configuration for the code generation task.
The defensive cross-operation formula is like a clever safeguard woven right into the fabric of the code-generation crossover process. Enhances code robustness by integrating defensive programming elements during crossover. It is not just about mixing and matching code snippets; it is about embedding smart defensive programming techniques. By weaving in error-handling mechanisms that act like safety nets, catching and managing any unexpected hiccups, along with input validation that acts as a strict gatekeeper, ensuring only the right kind of data gets through, and boundary condition checks that keep a vigilant eye on the code’s operational limits, this formula gives the generated code a real boost in terms of robustness and reliability. This means fewer nasty runtime errors and exceptions popping up to ruin the party, and code that not only performs its job right but also stands strong against all sorts of error-inducing challenges. All in all, it is a significant win for the overall quality and maintainability of the software, making it easy to keep in top shape for the long haul.
: standard crossover operations, such as single-point crossover or uniform crossover. DefenseTemplate: a defensive code template library, including modules such as input validation and error handling. This formula flexibly combines the parent solution with the forcibly injected defense template (input validation, error handling) to enhance the defense performance of the generated code.
Directional grammar variation formula identifies vulnerable points in the code structure for mutation. By analyzing the code’s syntax and pinpointing areas that are prone to errors or have weak error-handling capabilities, it applies targeted mutations. This approach aims to optimize code quality and robustness, ensuring that the generated code can gracefully handle edge cases and exceptions, thereby improving its reliability and reducing the need for extensive post-generation debugging.
AST: the tree-like structure representation of the code. : the sensitivity of fitness score to code node s. We can use formulas to locate sensitive nodes through AST analysis, for example, automatically insert range validation logic above loop statements.
The formula for population diversity is designed to maintain a healthy balance within the genetic algorithm by monitoring the diversity of solutions. When the diversity is too low, it indicates that the population may be converging prematurely on a suboptimal solution. Conversely, when the diversity is too high, it may suggest that the algorithm is not effectively focusing on the most promising solutions. By tracking these levels, the formula ensures the algorithm does not settle for suboptimal results too quickly and continues to explore the solution space effectively. This balance is crucial as it prevents the algorithm from becoming trapped in local optima, instead encouraging a thorough exploration that can lead to the discovery of high-quality solutions that might otherwise be missed. The benefits of this mechanism are significant, as it enhances the algorithm’s ability to find more optimal solutions, improves the overall efficiency of the optimization process, and increases the likelihood of achieving better results in a wide range of applications. By maintaining this balance, the genetic algorithm can operate at its best, delivering more reliable and effective solutions to complex problems.
: population fitness variance. : population average fitness. The population diversity metric quantifies solution spread by normalizing fitness variance against mean fitness. It dynamically regulates exploration: triggers forced mutation when diversity drops below 5% (preventing premature convergence) and restricts crossover above 20% (controlling excessive randomness). This maintains optimal genetic variation throughout evolution.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}