1. Introduction
The control of nonlinear systems with non-minimum phase (NMP) behavior remains a fundamental and long-standing challenge in the field of control engineering. These systems are particularly difficult to handle due to the presence of unstable internal zeros, which hinder precise output tracking and jeopardize the stability of internal states. This issue has attracted significant research attention and led to the development of numerous control strategies.
For example, Jouili et al. [
1] proposed an adaptive control approach for DC–DC converters under constant power load conditions, emphasizing the challenge of achieving both output regulation and internal stability. Cecconi et al. [
2] analyzed benchmark output regulation problems in NMP systems and identified the limitations of conventional methods. In the context of fault-tolerant control, Elkhatem et al. [
3] addressed robustness concerns in aircraft longitudinal dynamics with NMP characteristics. Sun et al. [
4] introduced a model-assisted active disturbance rejection scheme, and Cannon et al. [
5] presented dynamic compensation techniques for nonlinear SISO systems exhibiting non-minimum phase behavior.
Alongside these contributions, various classical approaches have also been developed to address NMP-related difficulties. Isidori [
6] introduced the concept of stable inversion for nonlinear systems, which was later extended by Hu [
7] to handle trajectory tracking in NMP configurations. Khalil [
8] proposed approximation methods based on minimum-phase behavior, while Naiborhu [
9] developed a direct gradient descent technique for stabilizing nonlinear systems. Although these strategies provide valuable insights, they often offer only local or approximate solutions and may be less effective in highly nonlinear or uncertain environments.
Other significant efforts include the approximate input–output linearization using spline functions introduced by Bortoff [
10], the continuous-time nonlinear model predictive control investigated by Soroush and Kravaris [
11], and the hybrid strategies combining backstepping and linearization for NMP converter control developed by Villarroel et al. [
12,
13].
Within this framework, Jouili and Benhadj Braiek [
14] proposed a cascaded design composed of an inner loop for input–output linearization and an outer loop using a gradient descent algorithm to stabilize the internal dynamics. Their stability analysis, based on singular perturbation theory, could potentially be reinforced by identifying and leveraging symmetric properties inherent in system dynamics.
Nevertheless, the reliance on gradient-based optimization presents notable shortcomings, especially in uncertain or highly variable environments. These limitations underscore the need for more intelligent and adaptive solutions, where recognizing symmetrical patterns in control structures and system behavior may offer enhanced generalization and robustness.
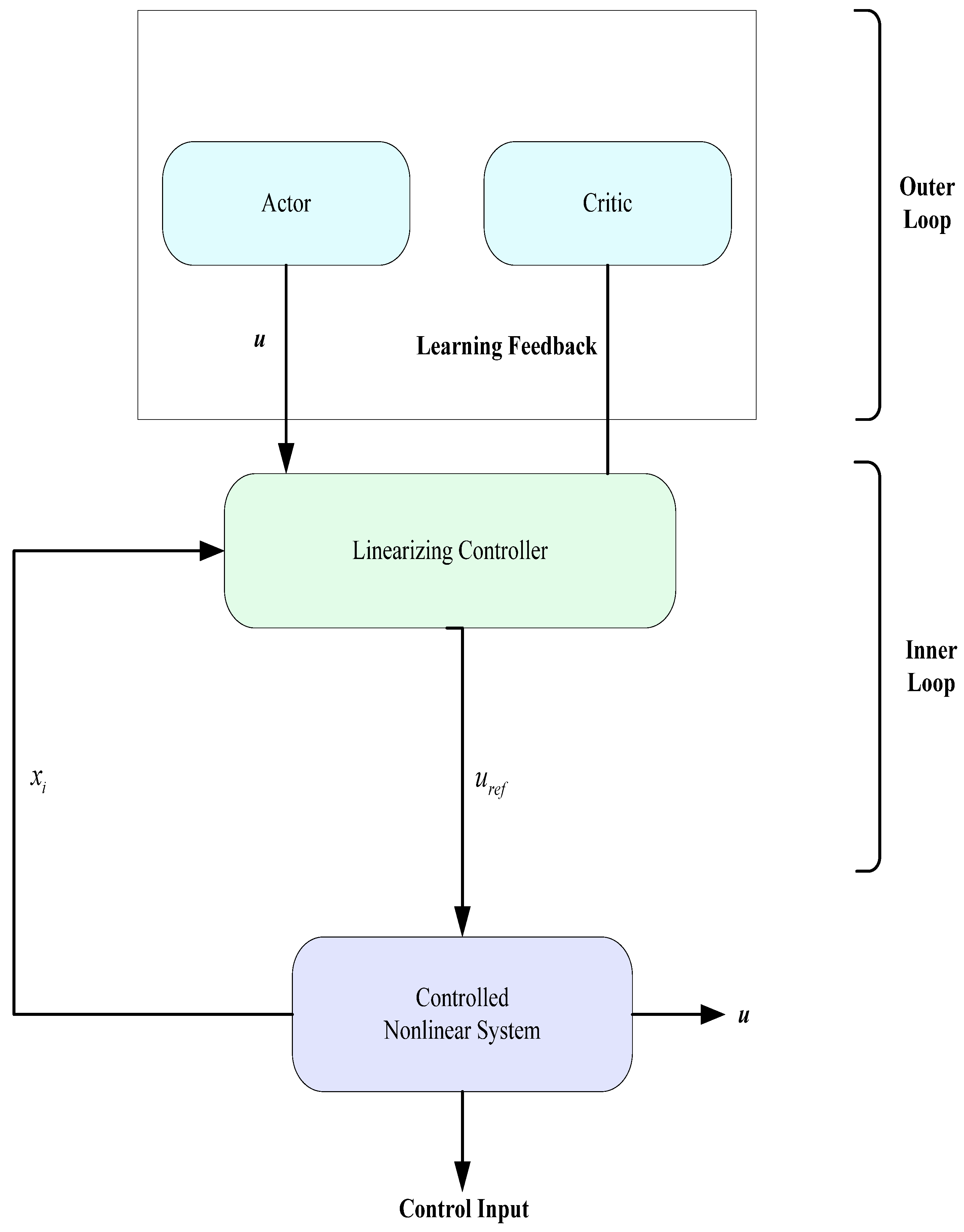
Our contribution lies in this direction: this article presents an innovative reformulation of the framework by Jouili and Benhadj Braiek [
14], integrating a Reinforcement Learning (RL) approach, specifically through an Actor–Critic agent [
15,
16], to improve stability, robustness, and output tracking accuracy. The Actor–Critic approach allows an intelligent agent to learn an optimal control policy through continuous interaction with the system, guided by a reward function based on tracking accuracy and internal state stability. The Actor generates control actions, while the Critic evaluates the quality of these actions through value function estimates.
The resulting control scheme still relies on a cascaded architecture, where the inner loop is ensured by input–output linearization, and the outer loop is driven by the RL agent. The RL agent replaces the gradient descent controller with an adaptive and optimized policy during interaction. The stability analysis of the entire system is established using singular perturbation theory [
8].
The proposed approach is evaluated through a case study involving an inverted pendulum on a cart, enabling a comparison of performance regarding tracking accuracy, stability, and transient response.
This article is organized as follows.
Section 2 describes the architecture of the proposed control scheme.
Section 3 covers the mathematical modeling of the system, while
Section 4 discusses reinforcement-learning-based control.
Section 5 presents the stability analysis of the control scheme, followed by the simulation results in
Section 6. Finally,
Section 7 concludes the article and suggests future research directions.
6. Simulation Results
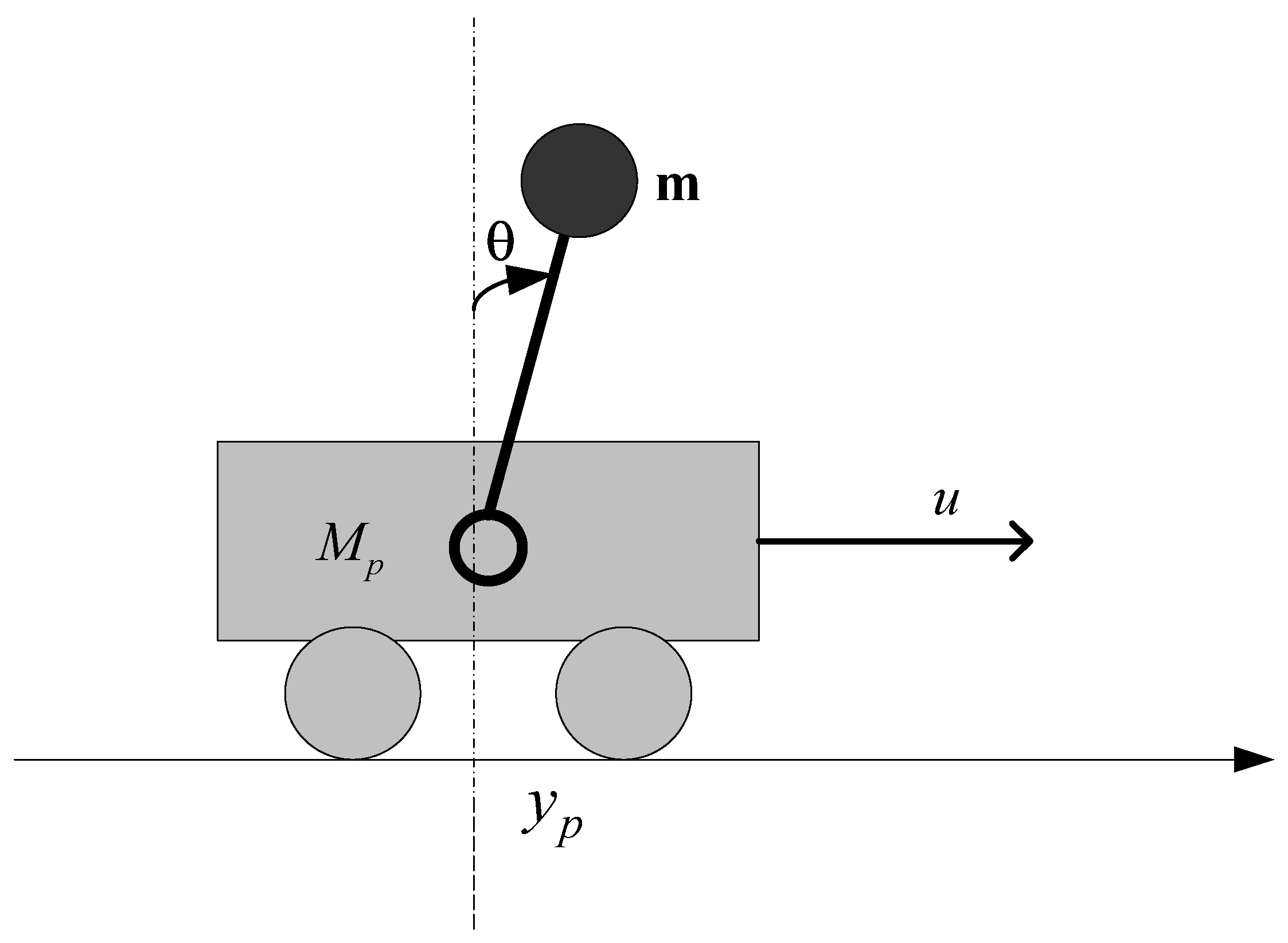
To evaluate the effectiveness of the proposed cascade control architecture integrating an Actor–Critic agent, we present a case study involving a benchmark nonlinear system: the inverted pendulum mounted on a cart (
Figure 3). This system is well known in control theory for its pronounced nonlinear characteristics and non-minimum phase behavior, making it an ideal candidate for testing intelligent and adaptive control strategies.
The system consists of a horizontally moving cart of mass
M, on which a pendulum of mass
m and length
l is hinged. The pendulum can freely swing around its pivot point. The system state is defined by four variables: the cart position
x, the pendulum angle
θ measured from the vertical, and their respective time derivatives
and
. By applying Lagrange’s equations to this mechanical configuration, one obtains a set of two coupled nonlinear differential equations describing the system dynamics:
where
u is the external control force applied to the cart, and
is the gravitational constant. The control objective is to regulate the pendulum angle
θ, which acts as a non-minimum phase output due to the unstable dynamics associated with the cart position
x.
Consider
as the output and let
. The inverted cart–pendulum can be written as the system (1). Hence, one has the following:
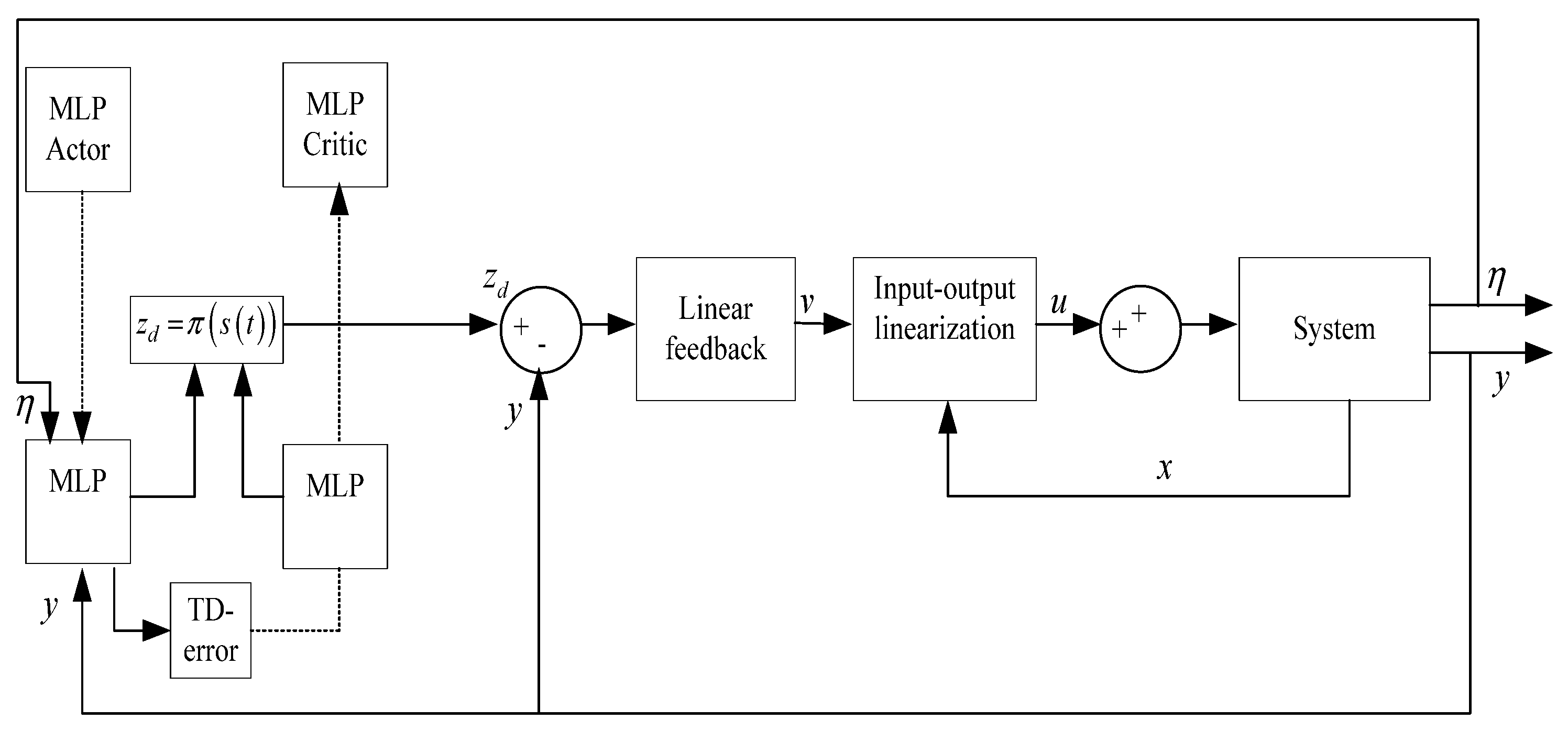
To facilitate controller design, the system is first transformed into its Byrnes–Isidori normal form, enabling the separation between the input–output dynamics, which are directly controllable, and the internal dynamics, which must be stabilized indirectly. The control input is then applied to the output θ using input–output linearization, while the internal state x is indirectly regulated through reference trajectory generation.
Two control strategies were developed and evaluated within an identical cascade control framework. The first strategy, used as a benchmark and inspired by the approach in reference [
1], generates the desired trajectory
zd(
t) through a conventional gradient descent algorithm, following the methodology proposed by Jouili and Benhadj Braiek [
14]. In contrast, our proposed approach generates the reference signal in real time using an Actor–Critic agent trained via reinforcement learning. This agent leverages a reward function tailored to meet specific performance objectives, as outlined in
Section 5. For both strategies, the inner control loop applies the same linearizing control law (22); the main difference resides in the outer loop, which defines the mechanism for reference trajectory generation.
Our approach is based on the integration of an Actor–Critic agent, trained online using a specifically designed reward function to optimize the behavior of the inverted pendulum on a cart system.
The goal of the agent is to generate a dynamic reference trajectory zd(t) that feeds into the inner linearizing control law to stabilize the pendulum, while ensuring robustness of the internal dynamics.
- i.
Actor: MLP Producing the Intermediate Reference zd(t)
The Actor is a Multi-Layer Perceptron (MLP) neural network, representing a parameterized policy:
where
θ represents the weights and biases of the neural network.
The typical MLP Architecture is as follows:
This output
zd(
t) is passed to the control law:
which drives the physical system.
- ii.
Critic: MLP Estimating the Value Function V(s(t))
The Critic evaluates the quality of each state
s(
t) by approximating the value function:
where
ϕ represents the Critic’s weights and biases.
The typical MLP Architecture for the Critic is as follows:
Layer 1: 20 neurons with ReLU
Layer 2: 10 neurons with ReLU
Output layer: 1 neuron (linear)
- iii.
Learning via Backpropagation—TD Update
The learning process is driven by the TD error, computed at each time step.
The Reward Function: To reflect the control objectives, the reward function is defined as
with the discount factor γ = 0.99.
The weight updates:
The gradients are obtained through automatic differentiation implemented using MATLAB 2023a.
- iv.
Online Reinforcement Learning Process
The learning is updated continuously, at every time step, using the following procedure:
- a.
Observe current state s(t)
- b.
Compute action
- c.
Apply control u(t) using the cascade linearized control law
- d.
Simulate system to reach next state s(t + 1)
- e.
Compute reward r(t)
- f.
Compute TD error δt
- g.
Update Critic network (minimize )
- h.
Update Actor network (maximize expected return)
The simulations were conducted using MATLAB R2023a and Simulink on a Windows 11 platform, utilizing both the Reinforcement Learning Toolbox and the Deep Learning Toolbox. The Actor–Critic agent was trained online through a custom implementation integrated into Simulink, with neural network updates managed via MATLAB 2023a scripts using the trainNetwork() function and rlRepresentation objects, with the following parameters: a cart mass of M = 1.0 kg, a pendulum mass of m = 0.1 kg, a pendulum length of l = 0.5 m, , initial angle θ(0) = 0.3 rad, initial angular velocity , a total simulation time of 10 s, and a sampling period of 0.01 s.
The selected sampling interval is 10 ms, corresponding to a frequency of 100 Hz, which is sufficient to maintain the stability and performance of the controlled system. Both neural networks—the Actor and the Critic—are updated at each time step using discretized versions of the inputs, system states, and rewards. The continuous control signal, as defined in Equation (30), is computed at every sampling instant and then applied in a discrete manner to the simulated system operating in a closed-loop configuration. Finally, the numerical integration of the differential equations is carried out using a fixed-step solver, such as a fourth-order Runge–Kutta or an adjusted ode45, while the controller itself operates in a step-by-step mode.
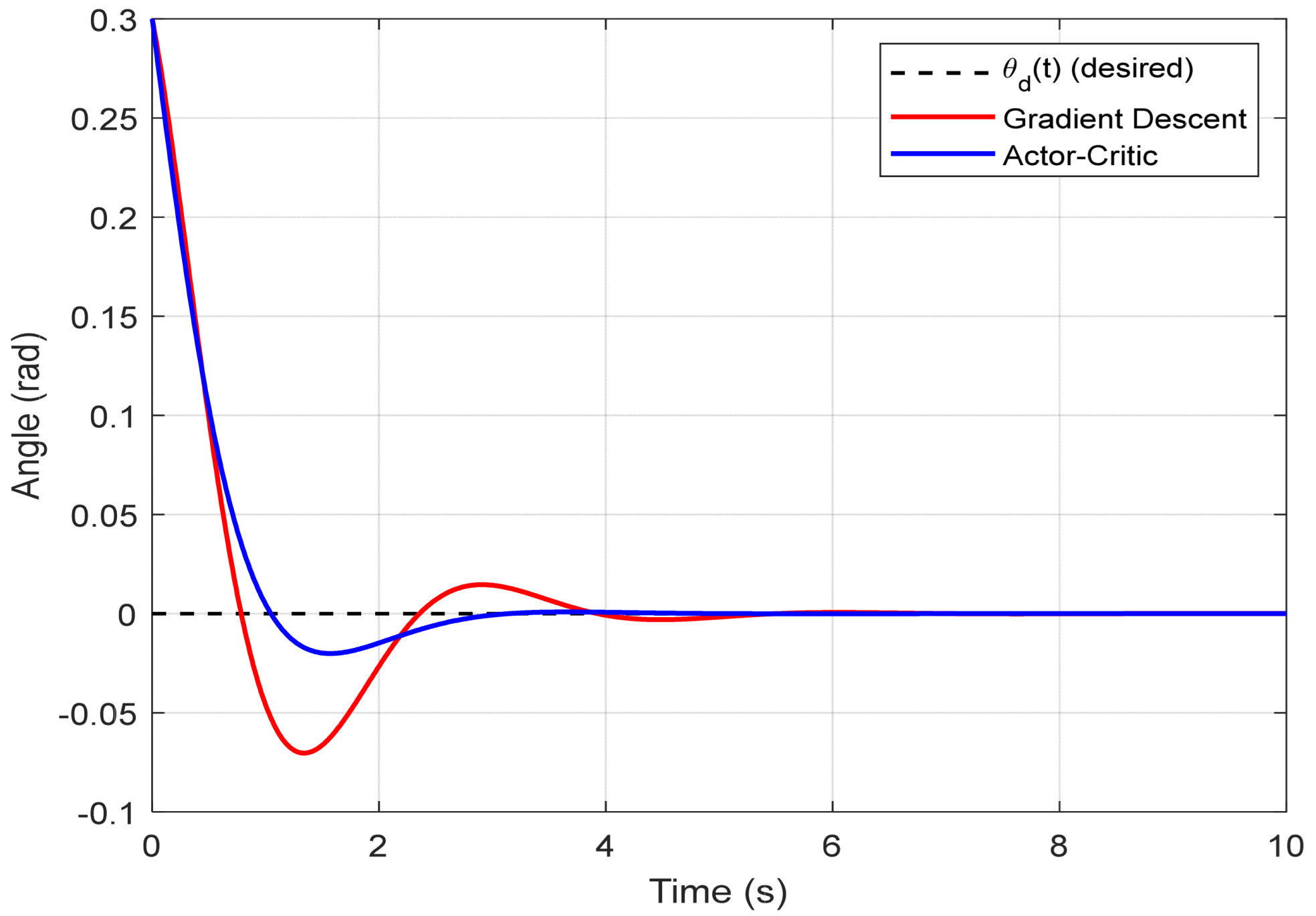
The simulation outcomes are illustrated in three comparative plots that highlight the dynamic performance of both control strategies. In
Figure 4, which presents the evolution of the pendulum angle
θ(
t), it is evident that the Actor–Critic approach achieves faster convergence with significantly reduced oscillations compared to the gradient descent method. The pendulum under RL-based control stabilizes around the vertical position within approximately 2.1 s, whereas the gradient descent strategy requires around 3.5 s to reach a similar state, exhibiting more pronounced transient deviations.
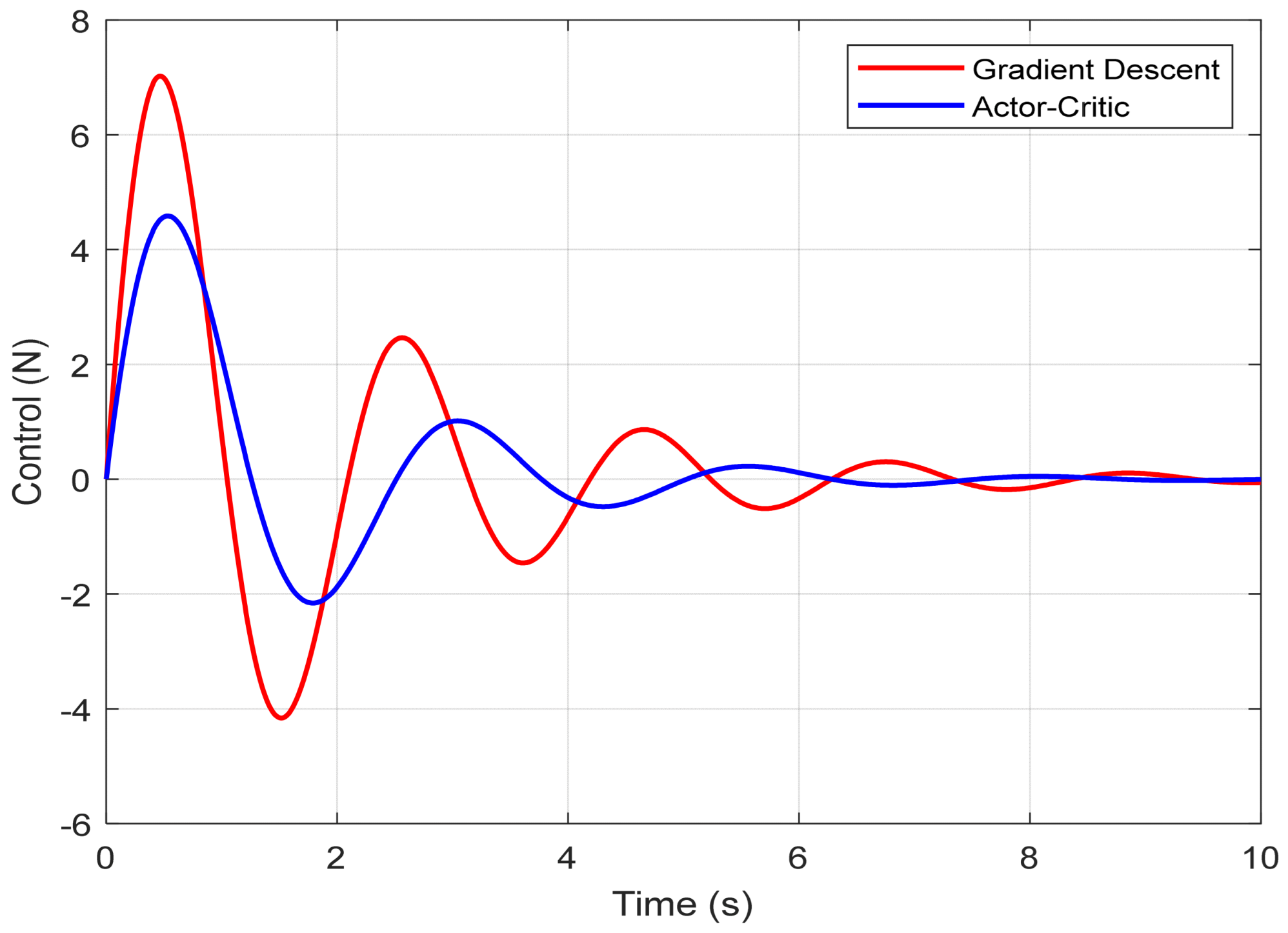
Figure 5 shows the control signal
u(
t) applied to the cart. The Actor–Critic agent generates a smoother and more energy-efficient control input, with lower peak magnitudes. The maximum control force produced using the RL method is approximately 6.7 newtons, while the traditional approach leads to more abrupt control actions, peaking at around 9.3 newtons. This indicates a clear advantage in terms of actuator stress and potential energy consumption when using the Actor–Critic controller.
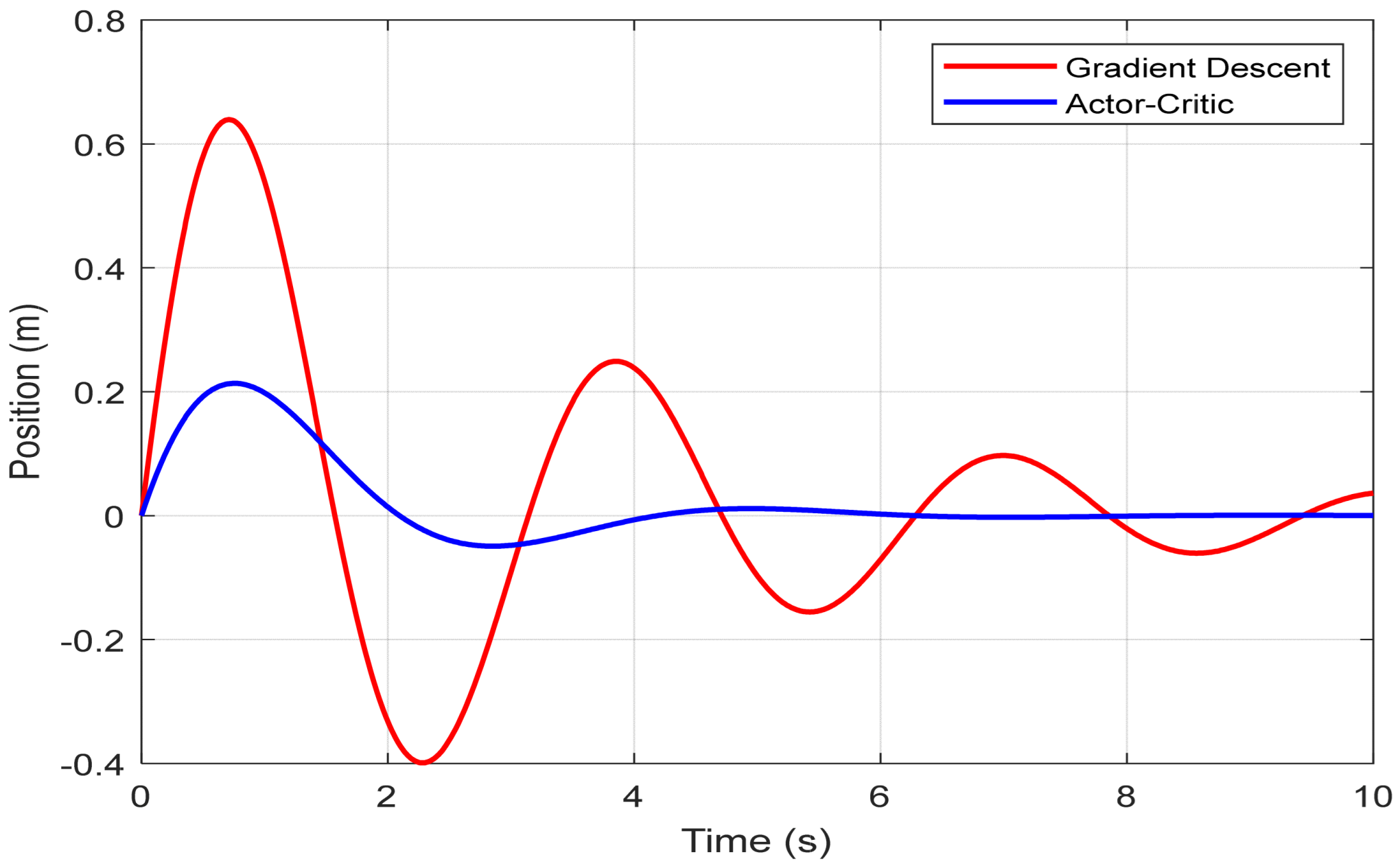
In
Figure 6, the position of the cart
x(
t) is displayed over time. The cart displacement is better contained when using the Actor–Critic policy. The maximum lateral deviation of the cart is limited to approximately 0.55 m, compared to a more substantial swing of about 0.82 m observed with the gradient-descent-based control. This improved containment demonstrates the RL agent’s ability to better regulate the internal dynamics of the system while simultaneously stabilizing the output.
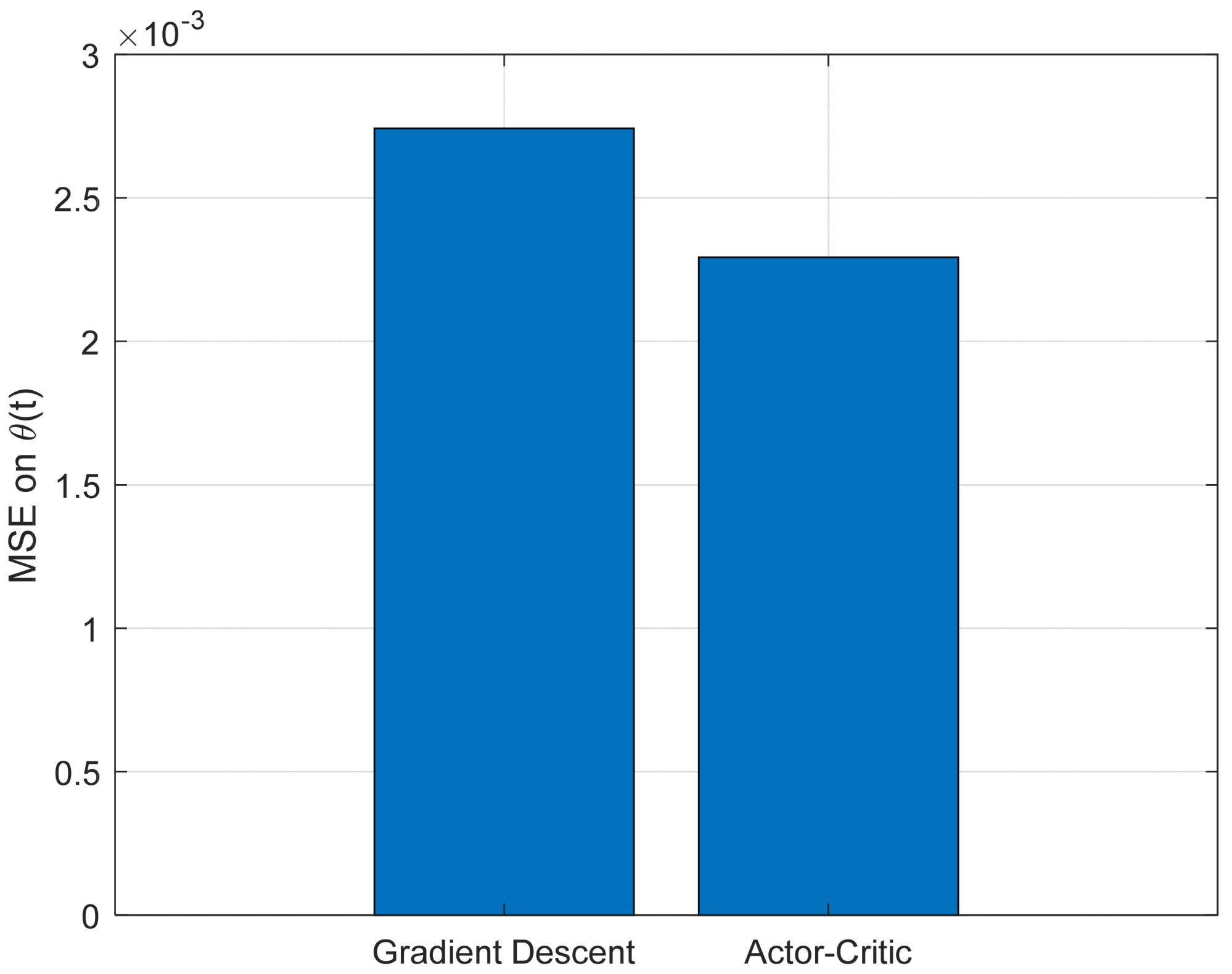
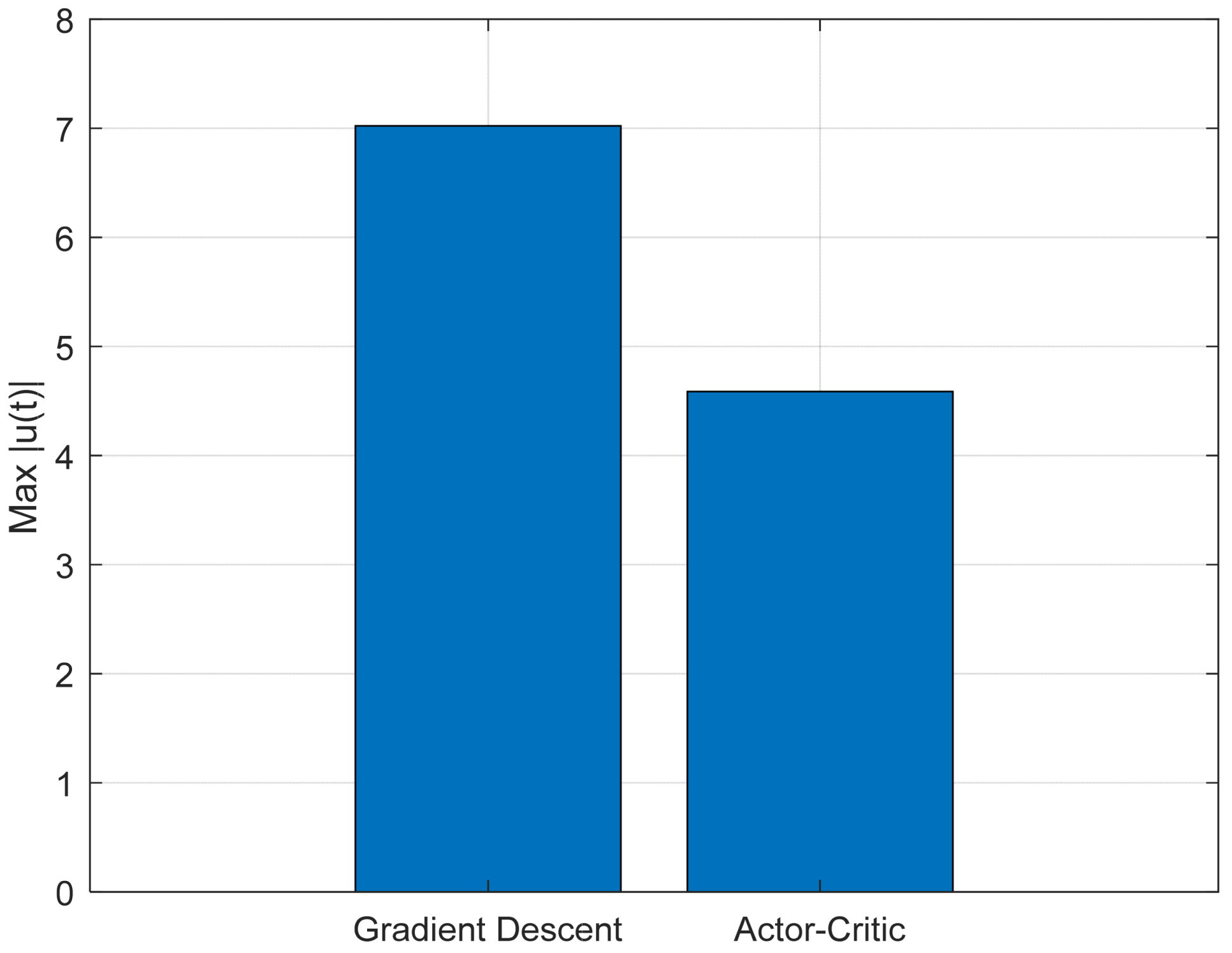
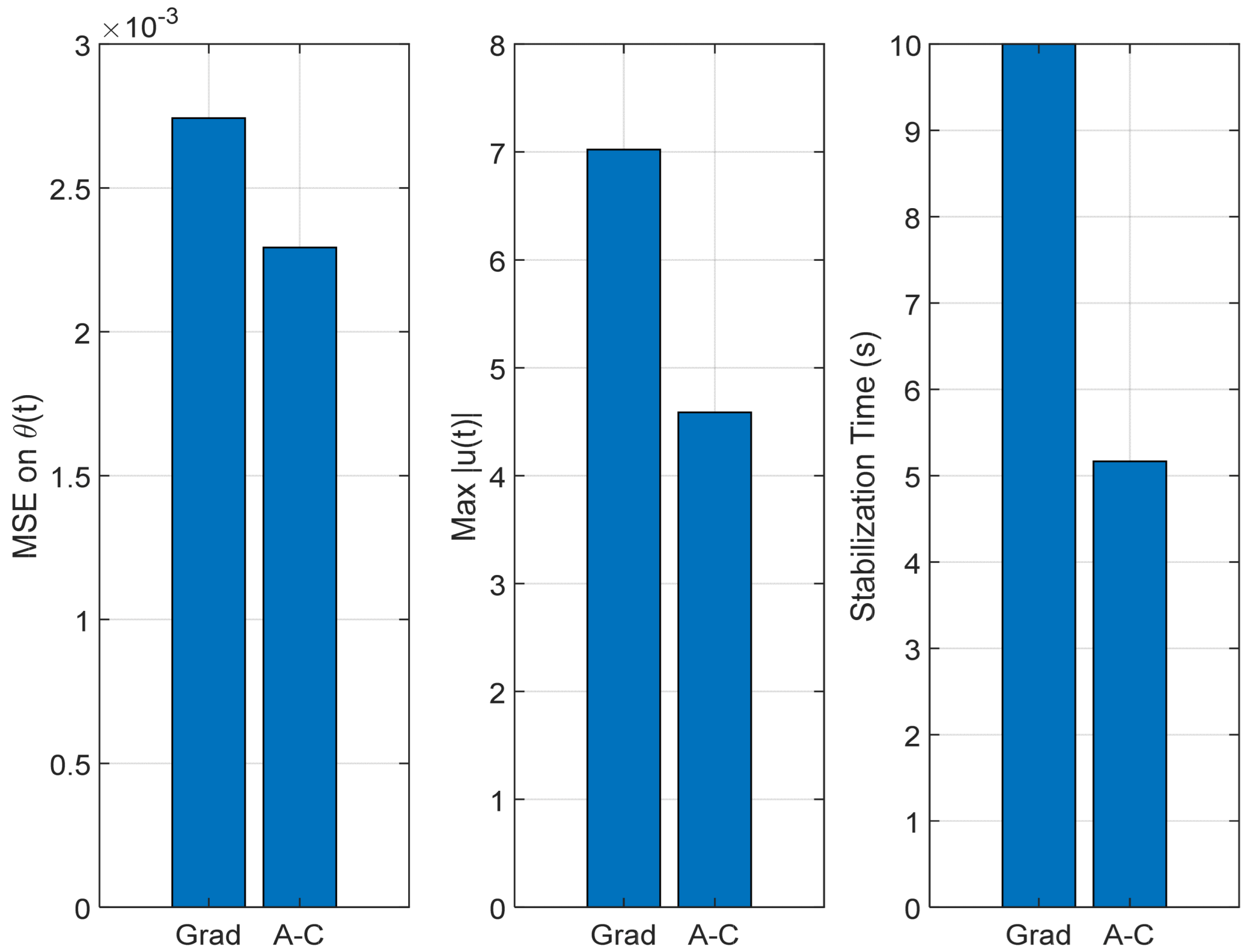
The performance of the two control strategies was evaluated based on three criteria: the mean squared error (MSE) of the pendulum angle θ(t), the maximum control effort ∣u(t)∣, and the settling time of the cart position x(t).
Figure 7,
Figure 8 and
Figure 9 provide a quantitative comparison between the classical gradient descent method and the Actor–Critic reinforcement learning approach across these key performance metrics.
Figure 7 depicts the tracking mean squared error of the angle θ(t). It is evident that the Actor–Critic method significantly reduces the tracking error compared to the traditional approach, demonstrating improved accuracy in stabilizing the desired trajectory.
Figure 8 illustrates the maximum control effort ∣u(t)∣ produced by each method. The Actor–Critic algorithm generates a more moderate control signal, indicating a more efficient and energy-saving control action, which is advantageous for resource-constrained real-world systems.
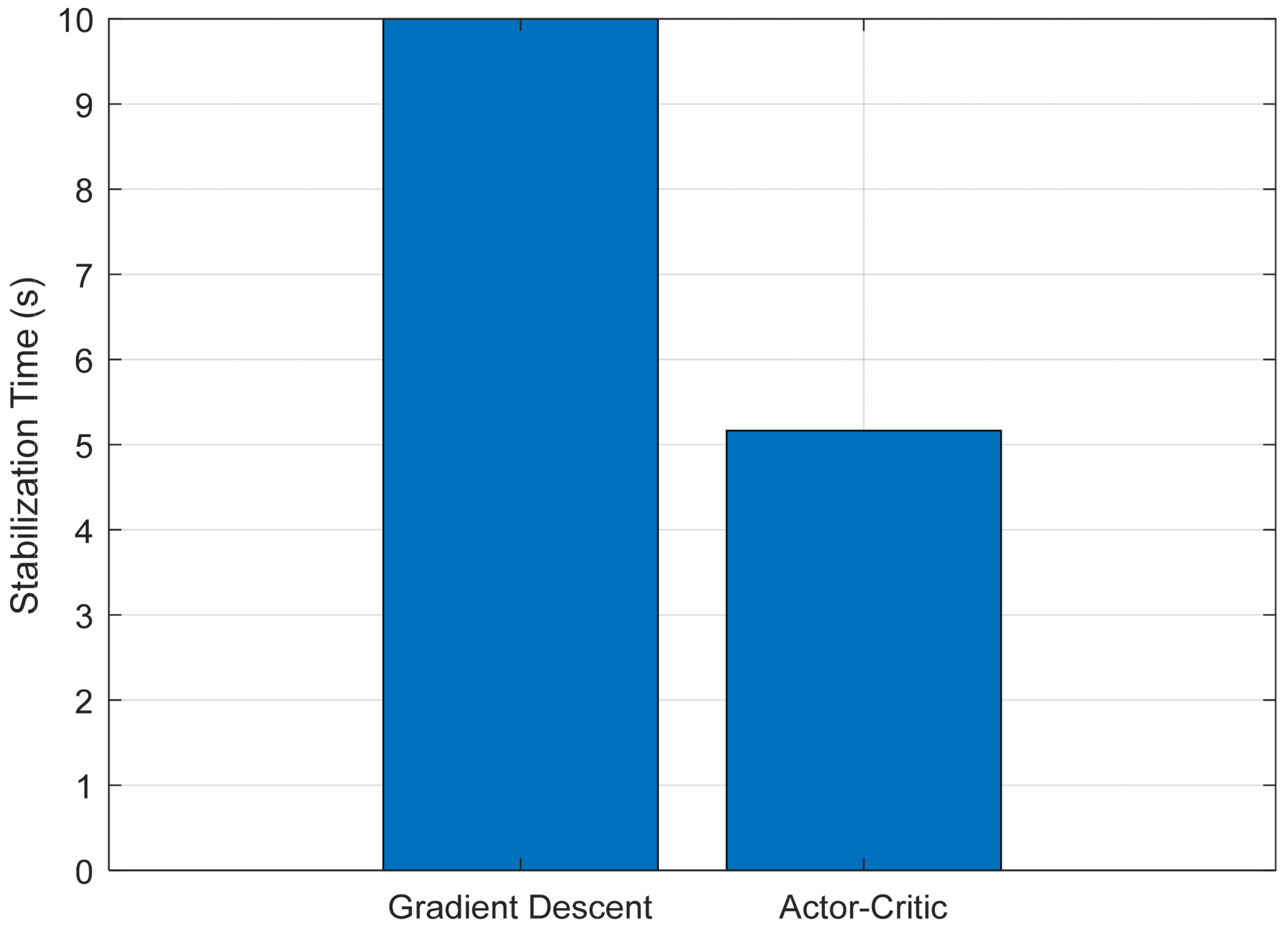
Finally,
Figure 9 shows the settling time of the cart position x(t), defined as the moment after which the response remains within ±5% of its maximum amplitude. The RL-based controller achieves faster stabilization due to better damping of internal oscillations.
These results confirm the effectiveness of the Actor–Critic approach, which enhances the precision, stability, and control effort efficiency of the nonlinear system.
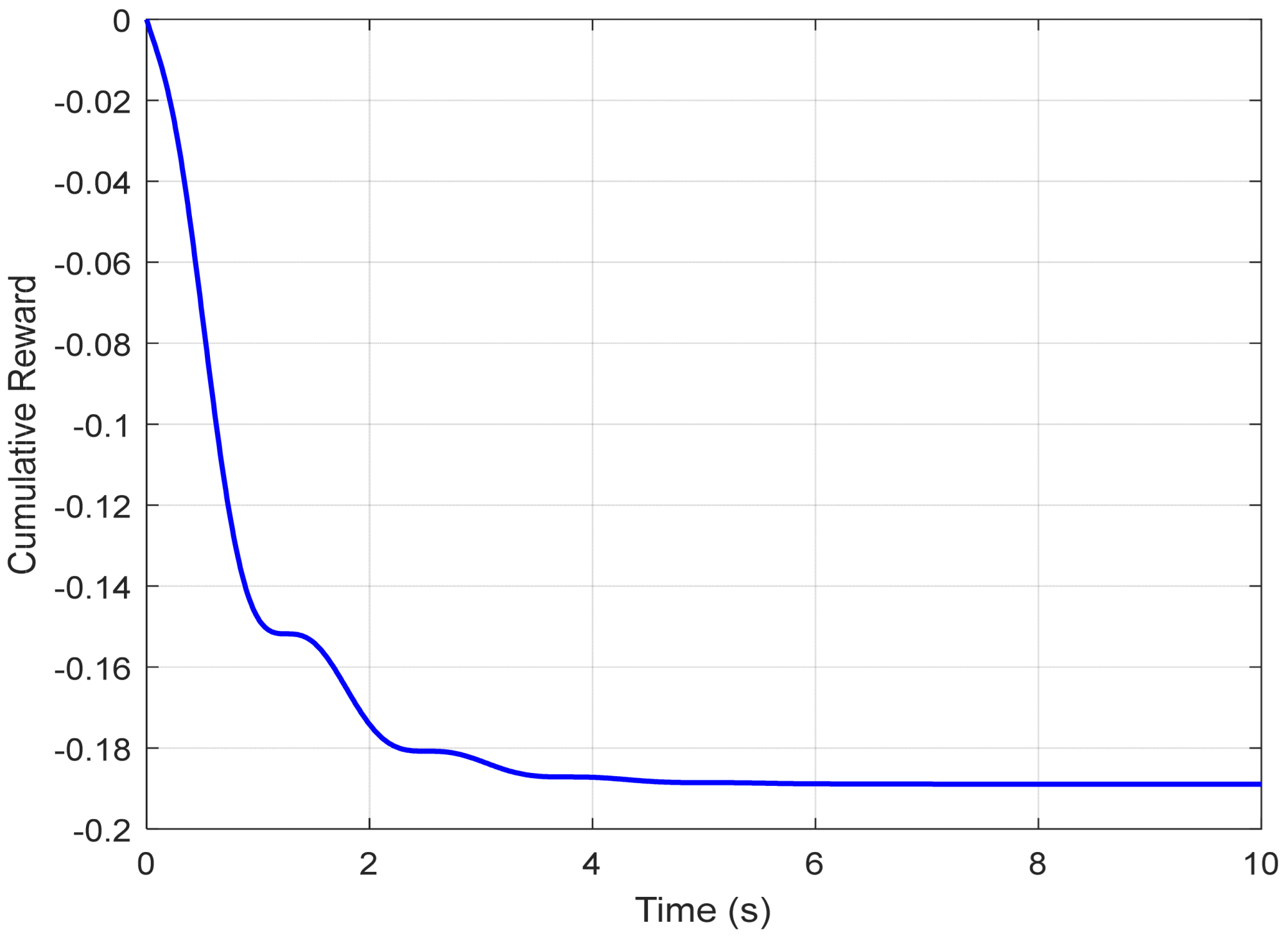
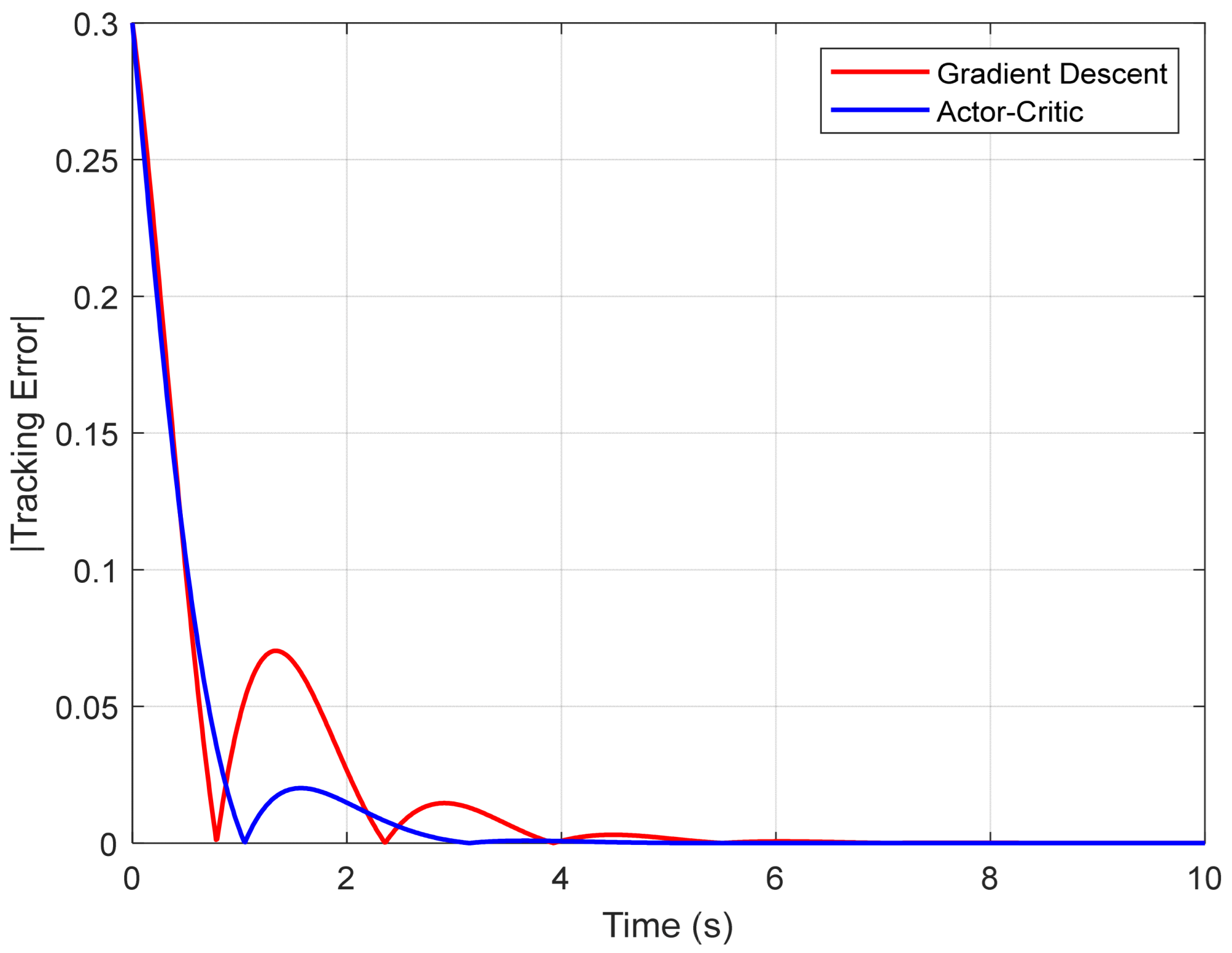
A new figure illustrates the evolution of the cumulative reward obtained by the agent over time, highlighting the gradual convergence of the learned policy toward a stable and efficient solution. Simultaneously, another plot depicts the time-varying tracking error for each control strategy, specifically comparing the Actor–Critic method and gradient descent. This visual representation enables a comparative analysis of the error magnitude, the speed of stabilization, and the overall tracking performance. To complement these visual results, quantitative indicators such as the mean squared error (MSE) have been included in a comparative table, offering an objective assessment of each approach’s effectiveness.
The presented figures provide a detailed insight into the learning dynamics and performance of the proposed control strategy.
Figure 10 shows the evolution of the cumulative reward achieved by the Actor–Critic agent throughout the simulation episode. The increasing trend of this curve demonstrates the agent’s ability to progressively improve its control policy, indicating convergence toward increasingly optimal behavior.
Figure 11 illustrates the absolute tracking error of the pendulum angle
θ(
t) with respect to the reference signal for both control strategies: gradient descent and Actor–Critic. It can be observed that the reinforcement-learning-based algorithm is able to reduce the initial error more quickly and maintain more accurate tracking over time, with fewer oscillations.
Figure 12 presents the key performance indicators used to assess the effectiveness of the proposed control approach: mean squared error (MSE), peak control effort, and stabilization time. The MSE measures how accurately the system follows the desired trajectory. The peak control effort indicates the highest level of control input applied during operation, and the stabilization time reflects how quickly the system settles into a steady state. Together, these metrics provide a well-rounded evaluation of the system’s performance in terms of precision, efficiency, and responsiveness.
7. Conclusions and Perspectives
This study introduced a novel cascade control strategy tailored to nonlinear non-minimum phase systems by embedding reinforcement learning techniques within a traditional control architecture. The core contribution lies in replacing fixed, gradient-based trajectory generation with a dynamic policy learned online by an Actor–Critic agent, enabling the system to adapt continuously to evolving conditions. The effectiveness of this approach was validated using the inverted pendulum on a cart—an established benchmark for testing nonlinear control schemes. By reformulating the system into the Byrnes–Isidori normal form, the method enabled clear decoupling between the controllable input–output dynamics and the internal dynamics, which were regulated indirectly through the learned intermediate reference signal zd(t). Within this framework, the Actor, modeled as an MLP, was responsible for generating context-sensitive control references based on the system state, while the Critic, also implemented as an MLP, estimated the long-term performance of those decisions using temporal difference learning. The learning process was driven by a carefully designed reward function that balanced trajectory tracking, internal stability, and control efficiency. Comparative simulations confirmed that this intelligent control strategy outperformed traditional gradient-based methods across multiple dimensions, including faster stabilization, reduced oscillations, and lower actuator effort, thereby demonstrating its potential for adaptive real-time control of NNMP systems.
Building upon the promising results obtained, several directions for future research are envisioned. First, the current formulation, applied to a SISO system, can be extended to MIMO systems, where inter-channel dependencies require more advanced coordination strategies. Second, the Critic component could be further enhanced using model predictive control concepts, allowing for the integration of predictive dynamics in value estimation to better anticipate system behavior. Third, and crucially, moving from simulation to real-world experimentation—using physical testbeds such as robotic platforms, inverted pendulum rigs, or autonomous vehicles—will be essential to assess the robustness, generalization, and practical viability of the proposed method under real-time constraints and disturbances.
In conclusion, the results of this work illustrate the significant promise of combining reinforcement learning with classical nonlinear control techniques. The integration of Actor–Critic learning into a cascade control structure offers a scalable and intelligent solution for tackling the challenges of NNMP systems, paving the way for more autonomous, resilient, and energy-efficient control architectures.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}