
Dynamic Adaptation for Class-Imbalanced Streams: An Imbalanced Continuous Test-Time Framework


Abstract
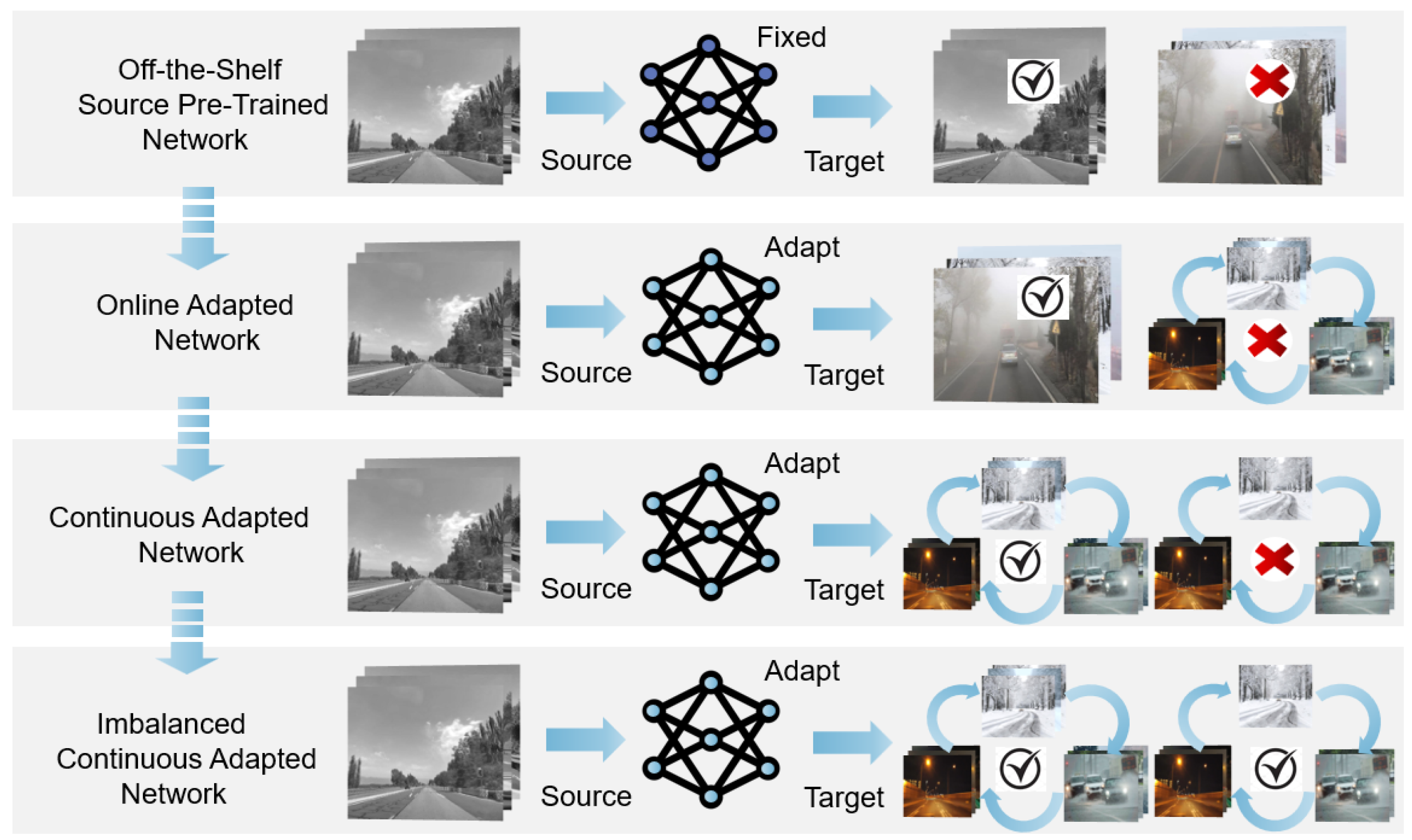
1. Introduction
- To the best of our knowledge, we are the first to propose ICTTA, a novel test-time adaptation setting that explicitly addresses class imbalance in dynamically evolving test data streams, a challenge previously overlooked in CTTA research.
- We construct an imbalanced perturbation dataset that simulates real-world streaming data, enabling rigorous evaluation under dynamic conditions.
- We propose a class-aware adaptive loss function that dynamically adjusts loss weights based on real-time class distribution shifts, ensuring effective learning from minority classes while maintaining performance on majority classes. Furthermore, we provide a theoretical analysis demonstrating the effectiveness of our method in the ICTTA setting.
- Experiments on CIFAR and ImageNet demonstrate that our method significantly outperforms state-of-the-art TTA approaches, effectively mitigating performance degradation caused by class imbalance.
2. Related Work
2.1. Transfer Learning
2.2. Domain Adaptation
2.3. Domain Generalization
2.4. Test-Time Training
2.5. Test-Time Adaptation
2.6. Class Imbalanced Learning
3. Method
3.1. Preliminaries
3.1.1. Test-Time Adaptation (TTA)
3.1.2. Continual TTA (CTTA)
- A teacher–student framework with momentum updates:where m is the momentum coefficient ().
- Augmentation anchoring:
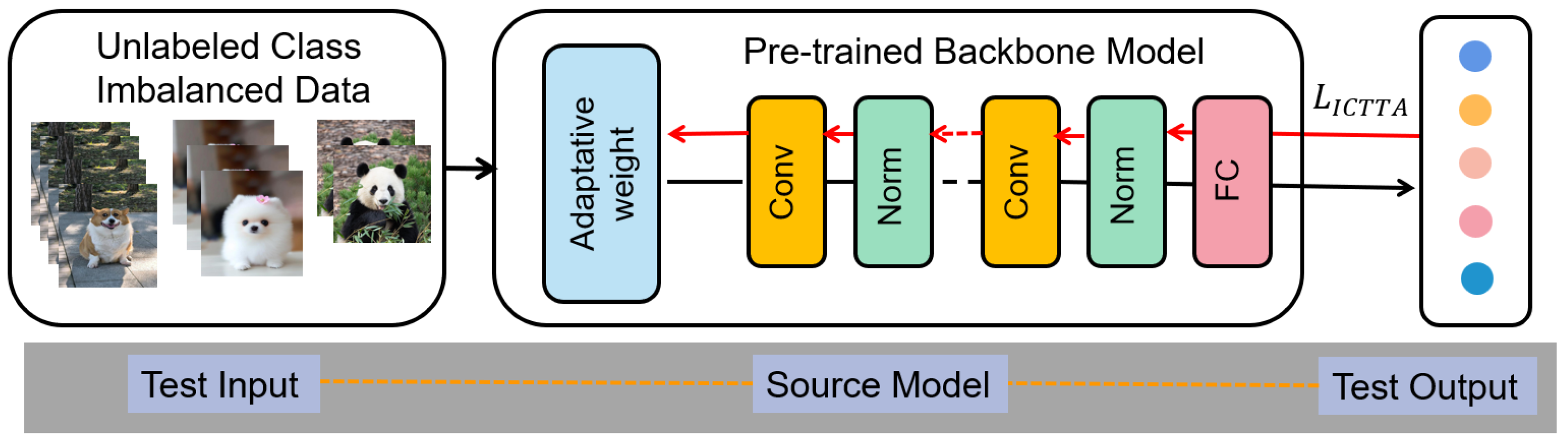
3.2. Imbalanced Continual Test-Time Adaptation (ICTTA)
3.2.1. Supervision of Sample Difficulty
3.2.2. Confidence-Weighted Loss Design
- and are the highest and second-highest softmax probabilities for sample .
- is the focusing parameter () that controls the rate at which easy samples are down-weighted.
- is the confidence threshold () that determines the minimum confidence required for a sample to contribute to adaptation.
3.2.3. Theoretical Analysis
3.3. Source Model and Auxiliary Information
4. Experiment
4.1. Benchmarks
4.1.1. Datasets
- ImageNet-C: ImageNet-C is a large-scale dataset featuring 75 unique corruptions across 15 categories, including noise, blur, weather, and digital distortions. Each corruption type is tested at five severity levels. With 1000 classes, it is one of the largest and most widely used benchmarks for evaluating robustness to image corruptions.
4.1.2. Network Architectures
- WideResNet-28-10: A popular architecture in the TTA literature, this model features 28 layers and a width of 10, providing a balanced capacity suitable for a wide range of tasks.
- WideResNet-40-2: This variant is characterized by a 40-layer depth and a width of 2, offering a different depth–width ratio to explore model performance from an alternative perspective.
- ResNet-50: The ResNet-50 architecture is a deep residual network with 50 layers, designed to address the vanishing gradient problem through residual connections. This network uses batch normalization and ReLU activations after each convolutional layer, which helps in improving gradient flow and accelerating training. It has become one of the most widely used architectures for various vision tasks due to its effectiveness in deep learning models.
4.1.3. Compared Methods
- Source: Direct application of the pre-trained model without adaptation. The baseline approach, where the pre-trained model is directly applied to the test data without any adaptation. This method serves as a control to assess the effectiveness of more sophisticated TTA strategies as it depends solely on the training data distribution, potentially leading to performance degradation under domain shifts or corrupted test data.
- BN Stats Adapt: Recalibration of batch normalization statistics using test data [24]. This method recalibrates the batch normalization (BN) statistics using the test data. It recomputes the running mean and variance during the test phase, allowing the model to adapt to the new data distribution. This approach is computationally efficient, requiring only a forward pass through the test data.
- TENT: Optimization of BN parameters via entropy minimization [24]. TENT builds upon BN Stats Adaptation by optimizing the scale and shift parameters of the BN layers through gradient-based backpropagation. The objective is to minimize the entropy of the model’s predictions, improving confidence and accuracy. This lightweight adaptation process strikes a balance between computational cost and performance enhancement.
- CTTA: Teacher–student framework with weight-averaged updates [7]. CTTA is a well-established method that utilizes a teacher–student framework to iteratively improve model performance during test-time adaptation. In this approach, a student network learns from the predictions of a teacher network, gradually minimizing prediction errors. To enhance adaptation under domain shifts, CTTA selectively restores a small subset of the pre-trained weights, allowing the model to better adjust to the changing environment while preserving essential knowledge from the source domain.
4.2. Experiments on CIFAR Dataset
4.2.1. Experimental Settings
4.2.2. Experiment Results
4.3. Experiments on the ImageNet Dataset
4.3.1. Experimental Settings
4.3.2. Experiment Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Zhang, M.; Tian, X. Transformer architecture based on mutual attention for image-anomaly detection. Virtual Real. Intell. Hardw. 2023, 5, 57–67. [Google Scholar] [CrossRef]
- Weng, W.; Pratama, M.; Za’in, C.; de Carvalho, M.; Appan, R.; Ashfahani, A.; Yee, E.Y.K. Autonomous Cross Domain Adaptation Under Extreme Label Scarcity. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 7894–7907. [Google Scholar] [CrossRef]
- Li, K.; Lu, J.; Zuo, H.; Zhang, G. Source-free multi-domain adaptation with fuzzy rule-based deep neural networks. IEEE Trans. Fuzzy Syst. 2023, 31, 4180–4194. [Google Scholar] [CrossRef]
- Wang, Q.; Fink, O.; Van Gool, L.; Dai, D. Continual Test-Time Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1234–1243. [Google Scholar]
- Zhou, A.; Levine, S. Training on test data with bayesian adaptation for covariate shift. arXiv 2021, arXiv:2109.12746. [Google Scholar]
- Zhu, J.; Li, W.; Wang, X. Clustering Environment Aware Learning for Active Domain Adaptation. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 610–623. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Zhou, K.; Yang, Y.; Qiao, Y.; Hospedales, T. Domain Generalization with MixStyle. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain generalization: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4396–4415. [Google Scholar] [CrossRef]
- Muandet, K.; Balduzzi, D.; Schölkopf, B. Domain generalization via invariant feature representation. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 10–18. [Google Scholar]
- Liu, Y.; Kothari, P.; van Delft, B.; Bellot-Gurlet, B.; Mordan, T.; Alahi, A. Adaptive Batch Normalization for Practical Domain Adaptation. Pattern Recognit. Lett. 2021, 148, 56–63. [Google Scholar] [CrossRef]
- Balaji, Y.; Sankaranarayanan, S.; Chellappa, R. Metareg: Towards domain generalization using meta-regularization. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31, pp. 998–1008. [Google Scholar]
- Dou, Q.; Coelho de Castro, D.; Kamnitsas, K.; Glocker, B. Domain generalization via model-agnostic learning of semantic features. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 1–12. [Google Scholar]
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. Augmix: A simple data processing method to improve robustness and uncertainty. arXiv 2019, arXiv:1912.02781. [Google Scholar]
- Sun, Y.; Wang, X.; Liu, Z.; Miller, J.; Efros, A.; Hardt, M. Test-time training with self-supervision for generalization under distribution shifts. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 9229–9248. [Google Scholar]
- Liu, Y.; Kothari, P.; van Delft, B.; Bellot-Gurlet, B.; Mordan, T.; Alahi, A. Ttt++: When does self-supervised test-time training fail or thrive? In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 21808–21820. [Google Scholar]
- Gandelsman, Y.; Sun, Y.; Chen, X.; Efros, A. Test-time training with masked autoencoders. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 29374–29385. [Google Scholar]
- Wang, D.; Shelhamer, E.; Liu, S.; Olshausen, B.; Darrell, T. Tent: Fully test-time adaptation by entropy minimization. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Liang, J.; Hu, D.; Feng, J. Do we really need to access the source data? Source hypothesis transfer for unsupervised domain adaptation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 6028–6039. [Google Scholar]
- Mummadi, C.K.; Hutmacher, R.; Rambach, K.; Levinkov, E.; Brox, T.; Metzen, J.H. Test-time adaptation to distribution shift by confidence maximization and input transformation. arXiv 2021, arXiv:2106.14999. [Google Scholar]
- You, F.; Li, J.; Zhao, Z. Test-time batch statistics calibration for covariate shift. arXiv 2021, arXiv:2110.04065. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Song, J.; Park, K.; Shin, I.; Woo, S.; Kweon, I.S. CD-TTA: Compound Domain Test-time Adaptation for Semantic Segmentation. arXiv 2022, arXiv:2212.08356. [Google Scholar]
- Jing, M.; Zhen, X.; Li, J.; Snoek, C. Variational model perturbation for source-free domain adaptation. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 17173–17187. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Sun, P.; Wang, Z.; Jia, L.; Xu, Z. SMOTE-kTLNN: A hybrid re-sampling method based on SMOTE and a two-layer nearest neighbor classifier. Expert Syst. Appl. 2024, 238, 121848. [Google Scholar] [CrossRef]
- Hu, X.; Uzunbas, G.; Chen, S.; Wang, R.; Shah, A.; Nevatia, R.; Lim, S.N. Mixnorm: Test-time adaptation through online normalization estimation. arXiv 2021, arXiv:2110.11478. [Google Scholar]
- Lee, S.; Kim, J.; Hong, J. Rebalancing Replay Buffer for Class-Imbalanced Continual Learning. Neurocomputing 2024, 580, 1–10. [Google Scholar]
- Wang, Y.; Zhang, L.; Chen, H. Online Test-Time Adaptation with Imbalanced Data Streams. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10234–10247. [Google Scholar]
- Zhang, R.; Wang, M.; Zhao, X. A Survey on Class-Imbalanced Continual Learning: Challenges, Methods, and Future Directions. ACM Comput. Surv. 2024, 56, 1–35. [Google Scholar]
- Hendrycks, D.; Dietterich, T.G. Benchmarking neural network robustness to common corruptions and perturbations. arXiv 2019, arXiv:1903.12261. [Google Scholar]
- Croce, F.; Andriushchenko, M.; Sehwag, V.; Debenedetti, E.; Flammarion, N.; Chiang, M.; Mittal, P.; Hein, M. RobustBench: A standardized adversarial robustness benchmark. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, Online, 6–14 December 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 73.4 | 67.0 | 75.6 | 51.2 | 54.6 | 39.5 | 48.5 | 24.8 | 40.9 | 25.3 | 9.8 | 46.7 | 27.3 | 50.7 | 26.5 | 44.1 |
| BN Stats Adapt | 29.1 | 26.4 | 36.4 | 13.4 | 36.6 | 16.6 | 13.7 | 19.8 | 18.8 | 16.5 | 11.1 | 15.2 | 26.0 | 20.0 | 27.8 | 21.8 |
| TENT | 26.8 | 20.6 | 27.3 | 11.1 | 28.2 | 12.8 | 10.7 | 14.8 | 14.0 | 13.9 | 7.9 | 12.3 | 19.7 | 14.8 | 19.4 | 16.9 |
| CTTA | 26.3 | 23.0 | 28.1 | 12.5 | 29.5 | 14.4 | 12.5 | 17.6 | 16.4 | 14.4 | 9.8 | 12.1 | 19.9 | 14.9 | 19.2 | 18.0 |
| ICTTA (Ours) | 26.4 | 19.8 | 26.6 | 10.7 | 28.0 | 12.1 | 10.4 | 14.5 | 14.2 | 12.6 | 7.6 | 11.3 | 18.6 | 14.4 | 20.0 | 16.5 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 28.4 | 21.6 | 24.4 | 9.5 | 20.0 | 11.6 | 10.2 | 13.5 | 14.8 | 18.2 | 8.4 | 20.4 | 14.1 | 37.1 | 13.0 | 17.7 |
| BN Stats Adapt | 18.8 | 17.3 | 22.4 | 10.7 | 24.4 | 12.2 | 12.5 | 14.9 | 15.3 | 16.3 | 10.0 | 13.8 | 18.0 | 15.6 | 18.4 | 16.0 |
| TENT | 15.8 | 11.1 | 14.8 | 7.8 | 16.6 | 9.2 | 8.1 | 10.3 | 9.5 | 12.1 | 7.3 | 9.5 | 14.8 | 10.7 | 14.8 | 11.5 |
| CTTA | 17.7 | 15.4 | 18.7 | 10.5 | 20.6 | 12.8 | 11.7 | 14.5 | 13.6 | 17.2 | 9.1 | 17.8 | 16.0 | 12.4 | 14.8 | 14.8 |
| ICTTA (Ours) | 15.9 | 10.6 | 14.7 | 7.4 | 16.0 | 8.7 | 7.7 | 9.6 | 8.7 | 10.8 | 6.8 | 8.1 | 13.3 | 9.6 | 14.0 | 10.8 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 60.2 | 63.1 | 45.7 | 62.3 | 56.7 | 65.9 | 64.0 | 73.7 | 69.7 | 75.7 | 85.4 | 66.4 | 70.8 | 68.5 | 69.6 | 66.5 |
| BN Stats Adapt | 65.8 | 67.5 | 59.1 | 80.7 | 60.2 | 77.4 | 80.6 | 74.8 | 75.2 | 77.7 | 83.1 | 79.0 | 69.2 | 74.2 | 66.8 | 72.8 |
| TENT | 68.0 | 73.5 | 66.6 | 84.8 | 66.1 | 83.0 | 86.3 | 81.6 | 82.8 | 83.5 | 89.7 | 85.5 | 77.6 | 82.7 | 78.3 | 79.3 |
| CTTA | 68.7 | 70.9 | 67.0 | 81.8 | 65.4 | 79.5 | 81.9 | 76.2 | 77.3 | 79.8 | 84.3 | 82.1 | 73.6 | 78.9 | 74.4 | 76.1 |
| ICTTA (Ours) | 68.2 | 74.4 | 67.7 | 86.2 | 67.1 | 85.4 | 87.5 | 84.2 | 84.5 | 85.5 | 90.6 | 85.4 | 77.2 | 82.9 | 76.9 | 80.2 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 74.4 | 78.1 | 72.5 | 87.6 | 76.8 | 83.8 | 85.7 | 82.8 | 81.4 | 81.5 | 86.6 | 78.2 | 82.0 | 73.4 | 83.1 | 80.5 |
| BN Stats Adapt | 75.6 | 76.9 | 71.8 | 83.7 | 70.5 | 82.0 | 82.1 | 79.3 | 78.7 | 78.0 | 84.4 | 80.1 | 76.4 | 78.8 | 75.9 | 78.3 |
| TENT | 78.6 | 84.9 | 81.3 | 89.9 | 79.8 | 88.4 | 89.6 | 86.9 | 88.3 | 85.9 | 91.2 | 89.3 | 83.1 | 87.9 | 84.1 | 86.0 |
| CTTA | 77.3 | 79.1 | 76.0 | 84.1 | 74.6 | 81.8 | 83.0 | 80.4 | 80.9 | 77.5 | 85.4 | 77.3 | 78.8 | 82.4 | 79.7 | 79.9 |
| ICTTA (Ours) | 78.4 | 84.9 | 80.9 | 90.5 | 80.3 | 89.6 | 91.1 | 88.4 | 90.8 | 87.2 | 91.6 | 90.2 | 84.5 | 89.4 | 83.8 | 86.8 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 27.0 | 34.3 | 27.1 | 53.0 | 46.8 | 65.7 | 58.5 | 74.5 | 57.4 | 74.4 | 90.3 | 53.8 | 72.5 | 41.0 | 70.0 | 56.4 |
| BN Stats Adapt | 71.6 | 73.8 | 64.4 | 87.2 | 65.1 | 84.6 | 87.8 | 81.7 | 81.9 | 85.0 | 90.3 | 86.0 | 75.4 | 80.7 | 72.4 | 79.2 |
| TENT | 73.4 | 77.6 | 70.5 | 87.9 | 67.9 | 85.3 | 87.5 | 81.5 | 81.7 | 82.9 | 90.0 | 85.0 | 75.1 | 80.1 | 74.5 | 80.1 |
| CTTA | 74.8 | 77.1 | 73.0 | 87.6 | 70.3 | 85.7 | 88.1 | 82.6 | 83.0 | 86.2 | 90.5 | 87.9 | 78.9 | 84.1 | 79.6 | 82.0 |
| ICTTA (Ours) | 73.9 | 78.2 | 70.7 | 87.8 | 66.7 | 84.8 | 86.1 | 80.7 | 80.5 | 82.9 | 90.0 | 86.0 | 75.8 | 80.0 | 74.4 | 79.9 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 71.4 | 77.0 | 75.9 | 90.1 | 78.8 | 89.4 | 90.6 | 85.9 | 83.8 | 82.2 | 91.7 | 79.3 | 85.0 | 58.4 | 85.4 | 81.7 |
| BN Stats Adapt | 82.4 | 83.9 | 78.5 | 90.1 | 76.7 | 88.9 | 88.8 | 86.2 | 85.4 | 84.9 | 91.1 | 86.5 | 82.8 | 85.3 | 82.7 | 84.9 |
| TENT | 84.3 | 88.0 | 82.9 | 91.3 | 80.1 | 88.9 | 89.9 | 86.4 | 86.6 | 84.5 | 90.1 | 87.8 | 80.3 | 84.8 | 80.8 | 85.8 |
| CTTA | 84.0 | 85.8 | 82.3 | 90.4 | 80.6 | 88.1 | 89.4 | 86.7 | 87.1 | 84.0 | 91.7 | 82.5 | 84.7 | 88.6 | 85.9 | 86.1 |
| ICTTA (Ours) | 84.3 | 88.5 | 82.5 | 91.2 | 79.5 | 88.5 | 89.7 | 86.0 | 86.8 | 84.7 | 90.7 | 89.4 | 81.4 | 86.3 | 82.2 | 86.1 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 23.1 | 30.8 | 20.5 | 50.0 | 40.4 | 60.2 | 52.3 | 71.9 | 56.8 | 72.9 | 86.4 | 52.1 | 68.9 | 39.8 | 68.1 | 52.9 |
| BN Stats Adapt | 66.3 | 68.7 | 59.0 | 82.6 | 59.4 | 79.0 | 82.5 | 75.8 | 76.5 | 79.4 | 84.9 | 80.3 | 69.7 | 75.4 | 67.4 | 73.8 |
| TENT | 68.7 | 74.5 | 67.2 | 85.8 | 65.4 | 83.4 | 86.2 | 80.9 | 81.8 | 82.6 | 89.5 | 84.6 | 75.6 | 80.8 | 75.6 | 78.8 |
| CTTA | 69.3 | 72.3 | 67.7 | 83.9 | 65.4 | 81.4 | 83.8 | 77.8 | 79.0 | 81.7 | 86.3 | 84.0 | 75.1 | 80.6 | 75.9 | 77.6 |
| ICTTA (Ours) | 69.0 | 75.3 | 68.0 | 86.7 | 65.4 | 84.7 | 86.4 | 81.8 | 81.9 | 83.8 | 90.1 | 85.4 | 76.0 | 81.0 | 75.1 | 79.4 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 70.3 | 76.2 | 72.0 | 88.5 | 75.4 | 85.4 | 87.3 | 83.2 | 81.5 | 80.3 | 88.2 | 76.4 | 82.4 | 58.0 | 83.7 | 79.2 |
| BN Stats Adapt | 76.9 | 78.6 | 72.9 | 85.8 | 71.1 | 84.0 | 84.1 | 81.1 | 80.4 | 79.7 | 86.4 | 81.6 | 77.6 | 80.3 | 77.5 | 79.9 |
| TENT | 80.2 | 86.1 | 81.6 | 90.4 | 79.0 | 88.4 | 89.6 | 86.5 | 87.3 | 84.9 | 90.4 | 88.2 | 81.2 | 86.0 | 82.0 | 85.4 |
| CTTA | 78.6 | 80.7 | 76.9 | 86.2 | 75.2 | 83.3 | 84.8 | 81.9 | 82.5 | 78.7 | 87.4 | 77.5 | 80.1 | 83.9 | 81.2 | 81.3 |
| ICTTA (Ours) | 78.4 | 84.9 | 80.9 | 90.5 | 80.3 | 89.6 | 91.1 | 88.4 | 90.8 | 87.2 | 91.6 | 90.2 | 84.5 | 89.4 | 83.8 | 86.8 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 93.7 | 93.7 | 92.9 | 86.0 | 91.4 | 87.5 | 76.7 | 84.8 | 80.2 | 78.1 | 45.9 | 95.3 | 86.9 | 74.5 | 66.1 | 82.2 |
| BN Stats Adapt | 87.9 | 88.6 | 85.9 | 87.9 | 89.0 | 78.9 | 66.5 | 69.4 | 71.0 | 55.8 | 38.5 | 89.2 | 63.0 | 58.1 | 69.6 | 73.3 |
| TENT | 86.5 | 83.8 | 79.4 | 83.6 | 81.9 | 71.7 | 60.9 | 66.9 | 65.6 | 55.1 | 40.7 | 79.1 | 56.9 | 54.2 | 60.8 | 68.5 |
| CTTA | 88.3 | 87.1 | 82.9 | 84.6 | 84.8 | 74.9 | 67.4 | 67.8 | 66.9 | 58.1 | 47.5 | 74.6 | 57.3 | 52.8 | 57.1 | 70.2 |
| ICTTA (Ours) | 86.4 | 83.3 | 78.7 | 83.1 | 80.8 | 71.3 | 60.5 | 66.8 | 65.9 | 55.0 | 41.3 | 78.0 | 57.4 | 53.3 | 60.0 | 68.1 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 5.4 | 7.0 | 7.4 | 12.3 | 7.8 | 12.3 | 23.2 | 16.8 | 22.6 | 26.6 | 53.6 | 4.5 | 15.4 | 27.2 | 35.0 | 18.5 |
| BN Stats Adapt | 11.5 | 11.3 | 12.7 | 11.2 | 10.4 | 20.7 | 34.0 | 31.1 | 29.4 | 43.5 | 61.3 | 10.5 | 35.2 | 41.3 | 29.6 | 26.2 |
| TENT | 13.1 | 16.0 | 19.3 | 15.8 | 17.3 | 28.0 | 38.0 | 33.4 | 33.9 | 44.7 | 59.8 | 20.5 | 43.1 | 45.2 | 37.5 | 31.0 |
| CTTA | 11.8 | 14.0 | 15.7 | 14.2 | 14.7 | 24.2 | 33.7 | 33.0 | 31.6 | 42.4 | 53.4 | 24.6 | 42.3 | 47.6 | 41.0 | 29.6 |
| ICTTA (Ours) | 13.1 | 16.4 | 19.8 | 16.2 | 18.2 | 27.8 | 39.0 | 33.5 | 33.2 | 44.4 | 59.3 | 20.3 | 42.3 | 46.8 | 38.0 | 31.2 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 6.1 | 6.0 | 7.7 | 15.2 | 10.0 | 13.0 | 22.9 | 15.4 | 20.8 | 23.2 | 54.8 | 4.3 | 14.3 | 26.4 | 35.4 | 18.4 |
| BN Stats Adapt | 12.3 | 11.7 | 13.6 | 12.3 | 11.9 | 22.4 | 35.2 | 32.5 | 30.2 | 45.5 | 63.6 | 10.1 | 40.2 | 43.1 | 31.7 | 27.8 |
| TENT | 13.9 | 16.6 | 20.2 | 16.6 | 20.0 | 29.4 | 39.6 | 34.9 | 35.7 | 47.0 | 61.4 | 20.1 | 45.9 | 46.7 | 40.3 | 32.6 |
| CTTA | 12.3 | 13.4 | 17.1 | 15.2 | 16.5 | 26.4 | 34.1 | 34.4 | 33.9 | 43.5 | 54.5 | 25.1 | 44.8 | 49.1 | 43.9 | 30.9 |
| ICTTA (Ours) | 14.1 | 17.2 | 21.1 | 17.0 | 20.8 | 29.4 | 40.1 | 34.9 | 35.0 | 46.6 | 60.6 | 21.0 | 45.3 | 47.8 | 40.6 | 32.8 |
| Method | Gaussian | shot | impulse | defocus | glass | motion | zoom | snow | frost | fog | brightness | contrast | elastic_trans | pixelate | jpeg | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 4.7 | 5.2 | 6.0 | 11.4 | 6.9 | 10.6 | 19.6 | 14.1 | 18.8 | 21.8 | 50.6 | 3.5 | 12.5 | 23.2 | 31.4 | 16.0 |
| BN Stats Adapt | 10.5 | 9.9 | 11.6 | 10.3 | 9.6 | 19.4 | 31.6 | 28.8 | 26.7 | 41.3 | 59.5 | 8.7 | 34.4 | 39.1 | 27.7 | 24.6 |
| TENT | 11.9 | 14.3 | 17.7 | 14.4 | 16.1 | 25.9 | 35.9 | 31.2 | 31.8 | 42.6 | 57.8 | 18.2 | 40.8 | 43.0 | 35.9 | 29.2 |
| CTTA | 10.3 | 11.9 | 14.5 | 13.1 | 13.6 | 22.9 | 30.5 | 30.2 | 29.5 | 39.6 | 50.6 | 22.4 | 39.6 | 44.4 | 39.1 | 27.5 |
| ICTTA (Ours) | 11.9 | 14.7 | 18.4 | 14.7 | 16.9 | 26.0 | 36.6 | 31.1 | 31.2 | 42.3 | 57.0 | 18.5 | 40.1 | 44.0 | 36.5 | 29.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, W.; Yang, H. Dynamic Adaptation for Class-Imbalanced Streams: An Imbalanced Continuous Test-Time Framework. Symmetry 2025, 17, 1050. https://doi.org/10.3390/sym17071050
Ma W, Yang H. Dynamic Adaptation for Class-Imbalanced Streams: An Imbalanced Continuous Test-Time Framework. Symmetry. 2025; 17(7):1050. https://doi.org/10.3390/sym17071050
Chicago/Turabian StyleMa, Wuxi, and Hao Yang. 2025. "Dynamic Adaptation for Class-Imbalanced Streams: An Imbalanced Continuous Test-Time Framework" Symmetry 17, no. 7: 1050. https://doi.org/10.3390/sym17071050
APA StyleMa, W., & Yang, H. (2025). Dynamic Adaptation for Class-Imbalanced Streams: An Imbalanced Continuous Test-Time Framework. Symmetry, 17(7), 1050. https://doi.org/10.3390/sym17071050