1. Introduction
General stochastic processes encountered in real life can be modeled using different distribution functions, depending on the methodological perspective. Rather than a unified approach to such problems, each field—whether natural, social, economic, or another area of human activity—permits specific interpretations and, consequently, mathematizations that can be adapted appropriately in each case. Often, it is the empirical observation of real-world data that suggests the most suitable distribution to model the process. In this direction, and inspired by the observed parallelism between the dynamics of ideal gas particles and certain modeled processes, our group has conducted various studies applying the chi distribution in different contexts in recent years, such as psychology and education, interpreting the collective results of these studies as those of a multidimensional ideal gas.
Thus, in Ref. [
1], motivated by the modeling of reaction times to sensory stimuli in a group of children, a study on the percentiles of the chi distribution was conducted. The main finding revealed that the ratios between percentiles are a fundamental characteristic of this distribution, independently of the parameter associated with its variance. The starting point, from a real-world perspective, was the observed similarity between this system—the group of children, where each child responded independently to stimuli—and a system of identical, independent particles in an ideal gas. This comparison demonstrated that the reaction times of the children, despite being independent, followed a pattern similar to that of particles in an ideal gas. In subsequent work, a study based on the Fourier transform and spectral entropy showed that the responses of children to visual stimuli are correlated. This forms the basis for the thermodynamic model proposed in [
2], where the response times of a group of children are represented using the Maxwel–Boltzmann distribution, drawing an analogy between the children and independent particles in an ideal gas.
In this paper, we aim to apply this type of analysis to the evaluation of sports competitions and examine the implications of the results for profiling a given professional athlete. Given the nature of the problem and leveraging our expertise in selecting empirically adapted distributions, we began by analyzing real-world data using modifications of the chi distribution.
The chi distribution, with varying degrees of freedom, is widely used in applied statistics [
3,
4,
5,
6,
7]. Its generation from Gaussian random variables offers distinct advantages for both simulations and interpretations, providing a robust tool for modeling such processes. The chi distribution with three degrees of freedom can be found in physics to represent the velocities of independent particles of an ideal gas in thermodynamic equilibrium at a specific temperature. Another typical case in physics is the Rayleigh distribution, which corresponds to a chi distribution with two degrees of freedom. Both cases can be found in general books on statistical mechanics such as [
8]. Other works that followed the ones mentioned above include simulations of the chi function, modified by variations in the generating Gaussian functions. In Ref. [
2] and other related works, we noticed that the limits within which the variances of the Gaussians can be varied to achieve a good fit of the resulting distribution function with the chi function are studied. In a similar simulation study [
9], the influence of the asymmetry of the generating functions on the resulting distribution function is analyzed. The generating functions are represented in this case by the so-called exGaussian distributions, which result from the convolution between a normal distribution and a decreasing exponential. This study explores the limits of asymmetry variation required to achieve a good fit with the chi function. Indeed, we explore the statistical behavior of a variable that emerges from a physical or biological process (depending on the context), which we hypothesize to follow a non-central, non-normalized chi distribution. This assumption is not arbitrary, since it is grounded in the observation that the variable under study exhibits both non-zero centrality (i.e., it is shifted from the origin) and asymmetry in its probability density, properties that cannot be captured by the standard chi or Maxwell–Boltzmann distributions.
Following this research plan, in this paper, we apply the method presented in the previous paragraphs to the assessment of sports performance. The chi function, this time in its non-centred variant [
10,
11], is used to model data from sports tests with the aim of characterizing the physical fitness of athletes. The main objectives of the work are, first, to propose an index to characterize physical fitness based on the non-centred chi function [
10,
11], where the generating functions are constructed from individual test data assumed to follow a Gaussian distribution, and second, to develop a methodology that serves as a working tool to classify athletes based on their results in individual tests.
The paper is structured as follows.
Section 1 discusses the theoretical model and presents simulations of the most relevant cases. In
Section 2, examples of the proposed methodology are applied to real sports data. The motivation behind our research is based on the potential use of the non-central chi probability distribution as an indicator of physical fitness, derived from the results of individual tests assumed to follow a Gaussian distribution. In
Appendix A, the strength, muscular endurance and cardiovascular endurance tests used to characterize physical fitness in this work are detailed [
12,
13].
2. Theoretical Background
The chi function is a continuous probability distribution widely used in applied statistics [
3,
4,
5,
6,
7]. It is generated by calculating the Euclidean norm of a vector whose components are independent variables distributed in a Gaussian manner. The standard normalized form in which the chi variable is expressed is
where
is the mean value of the random variable
is the standard deviation, and
k is the number of degrees of freedom of the total distribution. Its probability density function (PDF) is
where
is Euler’s Gamma function [
14], and its cumulative density function (CDF) is
where
is the incomplete Gamma function [
14].
It is clear that the centered chi distribution function (the means of the Gaussian variables involved are 0), as presented in Equations (
1)–(
3), does not distinguish between equal values with opposite signs in the generating Gaussian functions. This limitation poses an inconvenience when proposing an index based on this function, as will be explained in this paper. In this work, the non-centred chi function (which is called non-central chi distribution) is suggested instead of the centered one because it avoids this inconvenience in the cases that will be analyzed in this study.
If
are
k independent, normally distributed random variables with means
and variances
, then the variable
is distributed according to the non-central chi distribution [
10,
11]. The corresponding probability density function is expressed as
where
k specifies the number of degrees of freedom (i.e., the number of
), and
is related to the means of the random variables
by
The corresponding cumulative distribution function is then
where
is a modified Bessel function of the first kind, and
is the Marcum Q-function [
15]. The limit of the probability density function (Equation (
5)) as
tends to zero allows for the recovery of the probability density of the centered chi function from Equation (
2).
If we normalize the generating Gaussian functions, we lose information about the variance of each random variable. This means that it could be interesting for applications not to carry out this normalization, although this will depend on the context.
In order to retain information about the variance in the non-central chi distribution, we define the corresponding random variable as
Thus, to develop this hypothesis, we propose the following analytical ansatz for the probability density function:
where
k is the number of degrees of freedom,
is a non-centrality parameter defined as
, where
are the means of the random variables
,
is an inverse temperature-like parameter (a parameter to control the entropy of a distribution), which controls the spread, and
is a modified Bessel function of the first kind. Note that we treat the parameter
k as a natural number (
), since in our stochastic construction it represents the number of independent Gaussian components. However, the analytical formulae remain valid for any real
(the order of the Bessel function is
), but such a generalization is not used in the present work. Also note that the chi distribution is a continuous probability distribution of a random variable obtained as the positive square root of the sum of squared random variables, each following a standard normal distribution (mean
= 0; variance
= 1). In Ref. [
16], the authors analyzed the case in which the data follow non-standard normal distributions with equal, arbitrary positive variances and introduced
as a parameter related to the variance of the resulting chi distribution.
It should be pointed out that our
ansatz assumes two conditions: (1) the random variable must have real positive values, and, for the type of problems faced in this paper, it is enough to shift all values by at least 5 times the variance and (2) all variances of the generating Gaussian functions are the same. This function generalizes the classical chi distribution (central) by incorporating both non-centrality and a tunable scale (defined by the
T parameter), making it suitable for modeling systems where traditional assumptions fail. We are currently working on further generalizing the expression in Equation (
9).
To validate this model, we performed Monte Carlo simulations of the underlying process and empirically constructed the distribution of outcomes. We used FORTRAN language code, in which the underlying Gaussian distributions were generated using the built-in function
, which produces random numbers following a standard normal distribution. This function was implemented in the form
, where
a represents the standard deviation (
) and
b represents the mean (
). The parameter
r specifies the seed for random number generation. A total of 2 million random points were used to sample the function. Simulating the non-central chi distribution enables the numerical exploration of how systematic displacements affect a set of independent Gaussian variables. These simulations are particularly useful for studying how the distribution of the magnitude of a multidimensional random vector changes when its mean is varied, while its variance remains constant. The results, displayed in
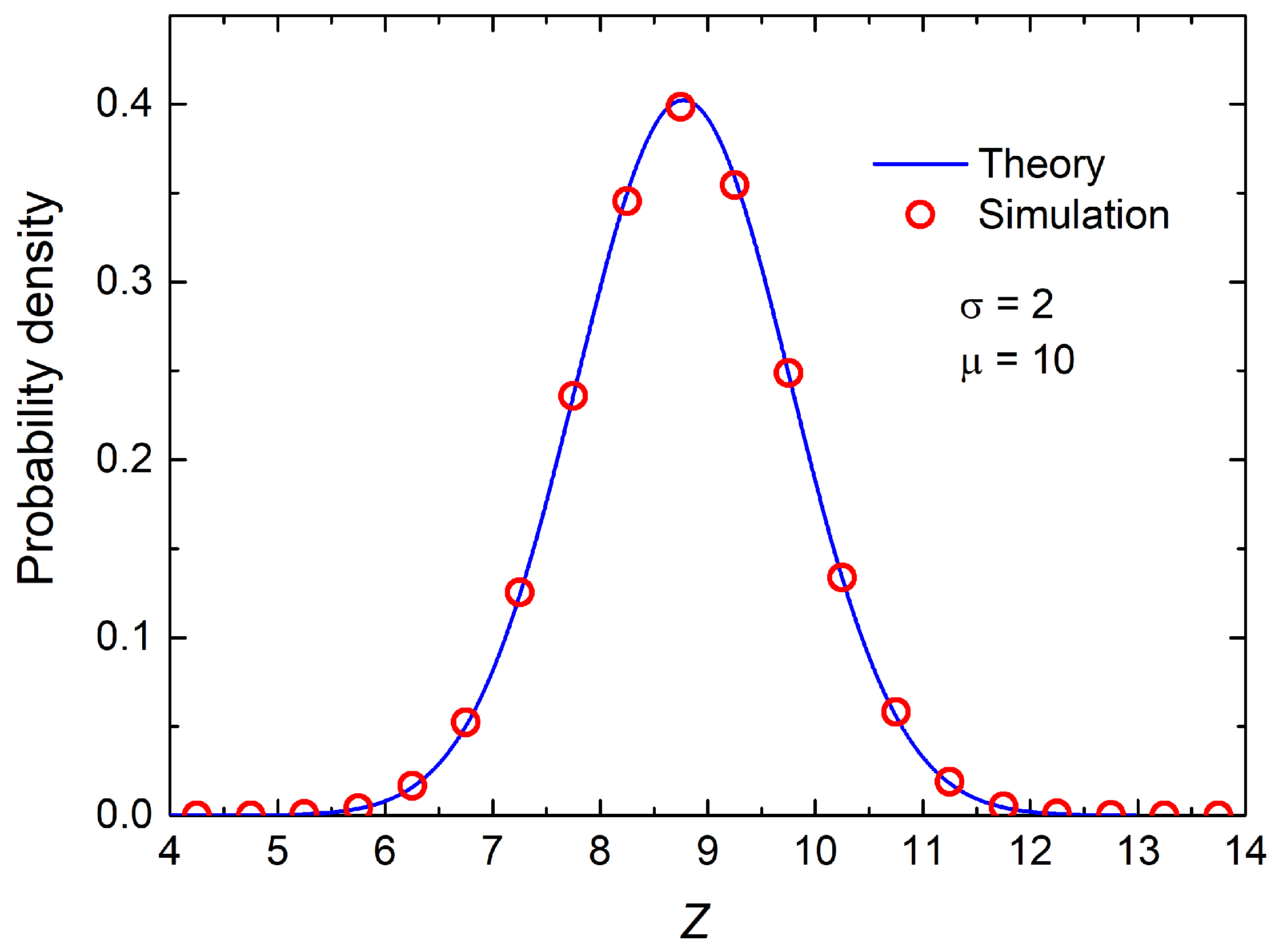
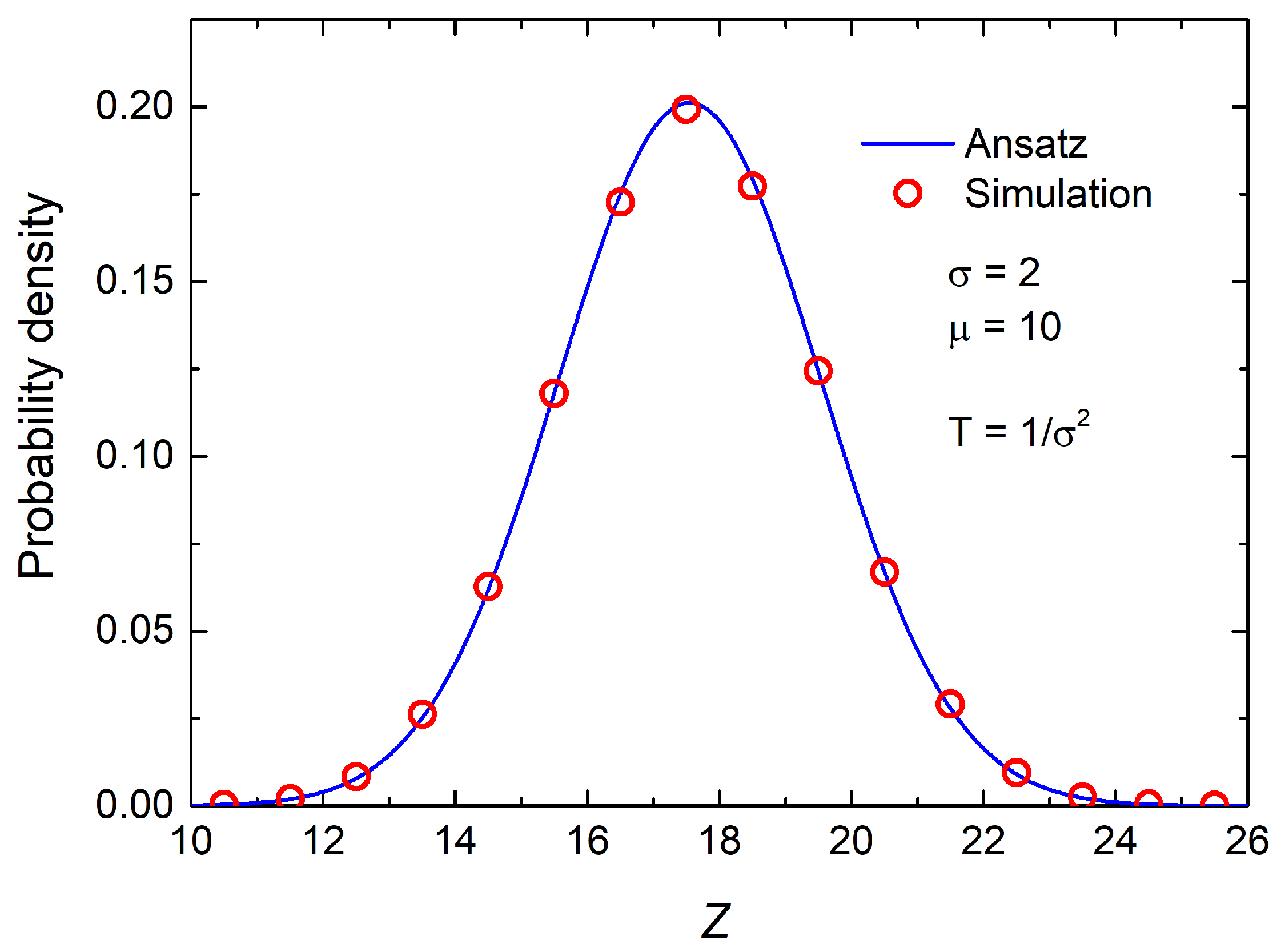
Figure 1 and
Figure 2, show a remarkable agreement between the simulated data (red circles) and the theoretical prediction (blue line). In particular,
Figure 1 presents the raw distribution from the simulation, which shows a mild but clear asymmetry—a longer right tail—typical of non-central chi distributions.
Figure 2 displays a normalized version of the same variable, where the distribution becomes symmetric around its mean, further reinforcing the interpretation of the non-central component as a shift in the distribution’s origin.
Although the curve in
Figure 2 appears visually quite symmetrical at first sight, closer inspection reveals that the right tail (corresponding to higher values of
Z) decays less gradually than the left. For example, the decay from
to
on the right is noticeably steeper than the decay from
to
on the left. This observation suggests a slight asymmetry to the right (i.e., a heavier right tail), which is consistent with the behavior of a non-centred or asymmetric distribution, such as a non-central chi distribution or some modified variant thereof.
In contrast, the curve shown in
Figure 1 appears to be almost symmetric with respect to its peak (located approximately at
). The slopes on either side of the maximum are visually and numerically similar, which is characteristic of a centered distribution, such as the standard normal or a chi distribution with symmetric parameters.
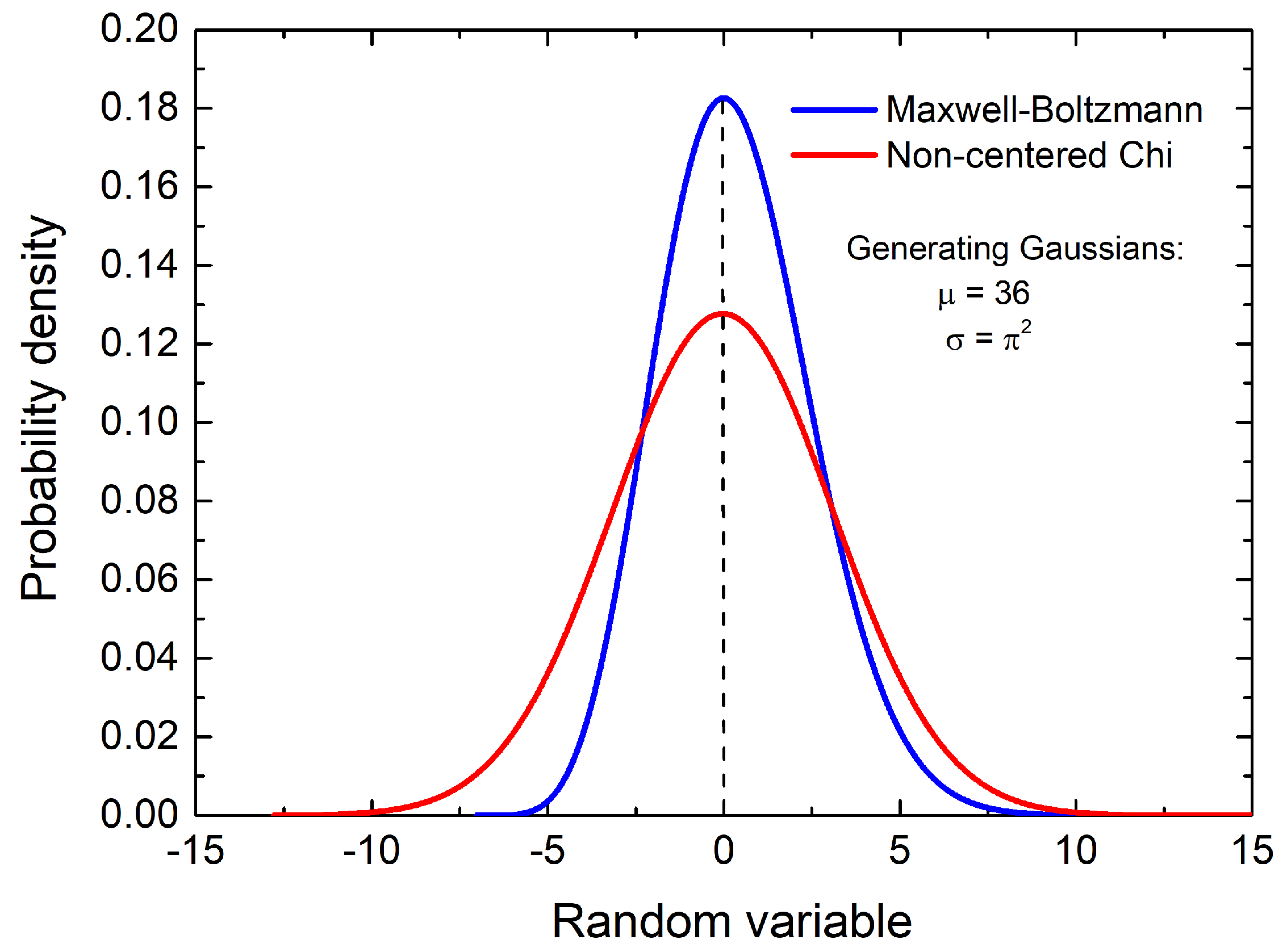
As previously mentioned, besides the parameter
, the function also depends on another parameter,
T [
2].
Figure 3 shows an example, a comparison between the centered chi function with
k = 6 degrees of freedom (the generalized Maxwell–Boltzmann distribution function [
1]) and the non-centred chi distribution for the same degrees of freedom.
As can be seen, the asymmetry is much more evident in the case of the Maxwell–Boltzmann distribution, whereas in the case of the non-centred chi distribution, it is not immediately apparent from a direct observation of the curve.
As we have already mentioned, our original motivation comes from models related to ideal gas dynamics. So, let us end the section by giving some hints on the physical interpretation of the non-centred chi distribution. From a physical perspective, the non-central chi distribution arises naturally when considering systems in which particles exhibit preferential motion in a specific spatial direction. Unlike the central chi distribution, which describes, for example, the magnitude of particle velocities in an ideal gas in thermal equilibrium, given by the Maxwell–Boltzmann function with degrees of freedom, the non-central version incorporates a displacement parameter. This displacement can be interpreted as the net mean velocity of the particle ensemble, suggesting a system observed from a non-inertial reference frame with respect to the gas.
This displacement parameter does not affect the temperature of the system, which remains proportional to the variance of the underlying Gaussian components. However, it does alter the shape of the distribution, reflecting the anisotropy introduced by the preferential motion. When observed from a reference system moving with that mean velocity, the distribution recovers its centered shape, i.e., it again behaves like a Maxwell–Boltzmann distribution. This property highlights the relevance of the non-centred chi distribution as a useful generalization for describing dynamical systems with directional structure, without involving a change in internal thermal energy.
Thus, this can model, for example, gases with collective motion in a specific direction or situations where a change in the reference frame has been applied to the system, as well as, for example, social and psychological phenomena which involve a non-centred starting point in the model’s expected distribution. To achieve this, independent Gaussian random variables are first generated, all with equal (or comparable) variance and zero mean. Then, a constant is added to each component, representing the system’s collective displacement. This ensures a homogeneous structure in the simulations, facilitating statistical analysis of the results.
4. Applications to Sports Performance Analysis
After establishing the mathematical properties in the previous section, we proceed to illustrate the practical applicability of the non-centred chi distribution by developing a detailed example in the context of sports assessment. Finding studies that explicitly employ the Maxwell–Boltzmann distribution to the context of sports is quite difficult, since this model comes from molecular physics. This distribution has been commonly used to obtain models concerning, for example, air pollutant concentration [
17] or zinc concentrations in soil samples [
18]. However, there are similar applications for physical models in sports related to fluids or collective influences. Recent studies, such as one on training load modeling in elite athletes [
19], have applied multivariate statistical methods similar to those implemented in this work, but they also found no model family to be preferred for athletic performance prediction in their dataset. Regarding the analysis of physical performance, modeling the distribution of the velocities of athletes is a powerful tool. Erdmann et al. [
20] analyzed velocity curves in Olympic female skiers, showing differences in the shape of the distribution between elite athletes and lower-level participants, highlighting the informative richness of distributional shapes. In another context, Pałka et al. [
21] applied a macroscopic model to the simulation of skier dynamics on slopes, achieving simulated velocities that faithfully reproduced distributions observed in real groups. These studies show the added value of applying physical distributions to real sports data. In this framework, we propose to use the non-centred chi distribution for modeling aggregate athletic performance metrics. The consistency of fits across gender and weight categories, with visibly consistent values of the non-centrality parameter
and temperature-related parameter
T, supports the underlying assumption that strength-based outcomes in Olympic weightlifting can be captured through multivariate Gaussian aggregation. In addition, the transition from raw score distributions to a unified probabilistic model facilitates a more appropriate comparison between athletes in different demographic categories.
In addition, the methodology allows for a statistically informed analysis of the dispersion of performance within each category. The different values of T not only reflect the variance in performance results but also suggest possible structural differences in training regimens or levels of specialization between groups.
In order to conduct our analysis, we followed a standard experimental procedure, collecting data and analyzing them in a systematic way.
4.1. Procedure for the Selection and Processing of Experimental Data
To assess the suitability of using the non-central chi distribution, we designed a structured methodology. The evaluation was carried out through the following steps:
First, in order to assess the normality of the individual test score distributions, we applied the Lilliefors test [
22], which is a variation of the Kolmogorov-–Smirnov test adapted for cases where the mean and variance are estimated from the data.
Second, any sample that did not satisfy the normality assumption according to the Lilliefors test was excluded from further analysis to ensure the robustness of the subsequent steps.
Third, we assumed that the variances of the retained distributions were similar, and we proceeded analogously to the Ideal Gas Model, generating a synthetic “gas” and determining its corresponding “temperature”.
Fourth, the individual test scores—those previously validated as normally distributed—were then combined into a composite physical fitness index using the Euclidean norm in k dimensions. This step reflects the aggregation of independent Gaussian variables into a single multivariate measure.
Finally, the distribution of this aggregated index was fitted to the non-central chi distribution, parameterized by the temperature
T and non-centrality parameter
, in accordance with Equation (
9).
This method was applied in the specific context of the 2019 Weightlifting World Championships. Data on the competition results can be readily accessed online [
23]. Our aim is to demonstrate how our methodology enables a more accurate (and arguably fairer) evaluation of the partial results, by aggregating them through our procedure based on the non-central chi distribution.
4.2. Olympic Weightlifting
In this section, the results of the 2019 Weightlifting World Championships will be analyzed [
23], which was the last competition before the Tokyo Olympics. It includes the men’s weight categories of −73 kg and −81 kg, and the women’s weight category of −76 kg. In most sports where categories are divided by the competitor’s mass, each category is noted as -
pkg to indicate that the competitor’s mass must be less than
pkg. This analysis aims to compare variances among different weight categories and between different genders. The data used are shown below; the rest are available in
Appendix A.
As is well known, weightlifting competitions consist of two events: the snatch and the clean and jerk. Given the two events in this discipline, the appropriate distribution to apply is the non-centred chi distribution with
(non-centred Rayleigh distribution). For the experiment, any subject without scores for either of the lifts was excluded, as well as those whose scores were too low to obtain Gaussian distributions. The fitting and the asymmetry results are detailed in
Table 1.
We carried out the
goodness-of-fit test to evaluate the goodness of fit, since it can be used to assess whether a set of categorized data follows a specific theoretical distribution [
24]. We obtained that for all examples included in
Table A3 the
goodness-of-fit test result was below 0.02, which shows a good fit. It can also be observed that there are differences in
between weight categories and genders because strength is highly dependent on body weight. Furthermore, differences in the values of
T, in other words, the variances of the distributions (related to their width), were also observed. We have distribution functions depending on the weight and biological sex of the evaluated subjects, unlike the experiments conducted in references [
9,
12], where the results were age-dependent.
In analyzing the behavior of the non-centered chi distributions across categories, it is important to highlight several relevant aspects. The heavier male categories exhibit larger values of the non-centrality parameter , which is consistent with the physiological expectation of higher absolute strength. Conversely, the lower values for in the female category reflect the comparatively lower load capabilities while still preserving the structural fit of the distribution. These outcomes reinforce the idea that the distribution model is sensitive to physical characteristics and performance profiles inherent to each demographic.
In terms of variance, represented by the parameter T, we observe wider distributions for the heavier male categories, whereas both the weight and T parameter values for the female −76 kg category are in between the values for the male categories. Regarding the parameter, which measures the asymmetry of each distribution, we found a significantly larger asymmetry value for the female category compared to the male categories, suggesting more consistent performance among elite lifters in those male groups. This higher asymmetry value for the female category may indicate greater heterogeneity in performance levels, which could be due to a broader competitive range, more diverse physiological profiles, or even potentially less specialization or homogeneity in training.
Regarding practical applications, the classification results generally follow the traditional format (the sum of the snatch and the clean and jerk events). However, it is noted that in the case of ties in the total weight lifted with different results in the events, their competition index, according the proposed methodology, differs, meaning it determines the difficulty of the event and serves as a tiebreaker between two subjects with the same weight lifted. For example, in
Table A1, for the female −76 kg category, Neisi Patricia Dajomes Barrera and Aremi Fuentes Zavala were tied according the traditional classification ranking), and the same happened with Mariia Vostrikova and Kristel Ngarlem. However, the proposed methodology can be used to provide a more granular ranking (
chi ranking), serving as tie breaker for the third and fourth positions and the eighth and ninth, respectively. Another triple tie can be found in
Table A2, where Briken Calja, Juhyo Bak, and Julio Ruben Mayora Pernia were in the fifth position according to the traditional ranking and were reordered with the proposed approach. In
Table A1,
Table A2 and
Table A3, we highlight ties according to the traditional ranking in bold. We can observe that there are ties in all three analyzed categories detailed in
Appendix A. Thus, ties are much more common than expected, and in all these cases, the proposed new ranking is able to resolve these ties. This is the main contribution regarding the practical application of our methodology. Using this procedure, it is possible to distinguish between situations that are different, although the difference is observed at a more advanced level in the comparison. Furthermore, more superficial aggregation methods are unable to distinguish between these situations.
Thus, this modeling framework not only provides a classification tool but also allows for a better understanding of the underlying dynamics of athlete development and competition structure. This further implies that the proposed statistical modeling not only captures average performance but also provides insight into variability within each group, which could be valuable for training strategies or talent identification. Finally, it is important to remark that, although the model has shown good fitting with the real sports data, no formal uncertainty quantification for the estimated parameters ( and T) was performed in this study. Future work should incorporate this analysis, since it would be valuable in order to assess the robustness and reliability of the model.


 ,
, 



{kind=link}
{kind=link}
{kind=link}