1. Introduction
A vehicle’s driving trajectory and motion trend is reflected by its motion state. Recognizing vehicle motion states can enhance driving safety and meet the development needs of intelligent transportation and navigation. In urban environments, the vehicle’s motion state is influenced by many factors, such as topography, road conditions, sensor precision, and so on. Thus, extracting valid motion features from a large amount of sensor data and then accurately identifying the vehicle motion state is the key challenge.
At present, there are two kinds of approaches to recognize vehicle motion states. One kind is to use raw sensor data directly, and the other relies on machine learning. In the first kind of approach, raw sensor data is compared with the predefined threshold to detect motion states. Specifically, Hu et al. proposed using vehicle acceleration and speed data as detection values to identify four motion states: acceleration, deceleration, idling, and uniform speed [
1]. Yu et al. used IMU (Inertial Measurement Unit) data to classify vehicle motion states based on zero-velocity and non-holonomic constraint criteria, but this method is vulnerable to environment interference [
2]. Zhang et al. proposed a driving behavior recognition method based on the spatial–temporal trajectory. This method realizes the real-time detection of turning and speed variation by directly processing vehicle trajectory data [
3]. In [
4], a vehicle stop-state detection method based on speed threshold was proposed by Yu et al., but it is sensitive to sensor noise and low-speed jitter. In [
5], a method of classifying the motion state based on the time window was proposed by analyzing the transfer mechanism of motion states. Kalman filtering (KF) is one of the most common methods for sensor data fusion. An EKF (Extended Kalman Filtering)-based interactive multiple-model method was developed, employing parallel EKF models with dynamic weight adjustment to cope with sudden motion transitions [
6]. In [
7], an adaptive KF method was used to filter the inertial sensor data, enabling the recognition of various vehicle motion states and improving the accuracy in complex environments. Martí et al. employed unscented KF to fuse IMU, digital compass, and GPS (Global Positioning System) data [
8]. In this method, unscented transformation, which is capable of modeling the nonlinear system, is beneficial to estimate motion states. In [
9], a MultiWave filter was developed to replace the fixed sliding window, and statistical features were extracted from different sensors and different axes, successfully achieving the recognition of five steering modes. Ye et al. estimated vehicle motion states using model-derived constraints and a Kalman filter, avoiding complex vehicle models [
10].
The above approaches are effective in recognizing distinct motion states, but they typically rely on fixed rules, which limit their ability to cope with complex dynamic changes. Additionally, their sensitivity to noise and irregular motion reduces robustness. Machine learning that recognizes complex patterns through training on large datasets can adapt to dynamic changes. It improves robustness to irregular motion and mitigates the limitations of traditional rule-based methods. As a result, machine learning has been increasingly applied to recognize vehicle motion states. In [
11], a cascaded Support Vector Machine (SVM) classifier achieved 93% classification accuracy with hierarchical decision-making. In [
12], another hierarchical SVM recognition method based on the finite state machine achieved 95.16% accuracy with relatively low computational cost. Li et al. developed a decision tree-based recognition method that reached 95.2% accuracy in distinguishing three basic motion states: stationary, straight-line driving, and turning [
13]. Ding et al. developed a triboelectric electrostatic sensing method integrated with Long Short-Term Memory network (LSTM), converting mechanical energy into electrical signals for pattern recognition [
14]. Chen et al. designed a panoramic segmentation neural network for driving context recognition, integrating Kalman filtering for motion state prediction to achieve robust estimation [
15]. An enhanced temporal Convolutional Neural Network (CNN) can effectively recognize vehicle motion states but encounters computational limitations inherent in deep learning models [
16]. A novel multi-dimensional motion perception network is able to perform drift-resistant estimations of vehicle speed and angular velocity, realizing high-precision motion state recognition while maintaining sensitivity to motion details [
17]. Jiang et al. proposed a novel Bayesian network that incorporates a filtering method designed to improve data quality and ensure reliable recognition [
18]. Wang et al. proposed a serial feature network that achieves 10-class pattern classification by fusing multi-scale spatiotemporal features [
19]. In [
20], a temporal CNN provided an efficient time-series analysis of vehicle maneuvering patterns, but it poses significant computational demands for modeling long-range temporal dependencies. The hybrid method of CNN and LSTM was developed for vehicle motion state recognition by synergistically combining CNN’s spatial feature extraction with LSTM’s temporal modeling strength [
21]. Subsequent improvements have further optimized this hybrid method, including Savitzky–Golay filtering for data denoising [
22], SoftMax probability output for reliable confidence estimation [
23], and a dual network architecture for complementary feature learning through parallel processing [
24]. Peng et al. converted time-series driving data into grayscale images and used a vision transformer with transfer learning to achieve 95.65% accuracy in lane-change prediction [
25]. Chen et al. combined an attention-based LSTM with an interactive multiple model (IMM) algorithm to improve prediction by weighting Gaussian process and Kalman filter models [
26].
Artificial intelligence methods, such as SVM, CNN, and LSTM, can achieve good classification accuracy; however, CNN requires a complete image to identify a certain motion state, and this limits its real-time performance, resulting in the inability to identify the changes in the motion state in a timely manner. Training LSTM requires a large amount of data and computing power, while SVM performs well when the amount of data is small. More importantly, these methods all have limitations in modeling complex time dependence, and they are difficult for representing implicit transitions between motion states, which limits their ability to recognize continuous state changes. They also lack robustness to noise and ambiguous motion states, leading to a reduced performance in real-world traffic scenarios. Furthermore, the duration of motion states cannot be modeled. To address these issues, this paper proposes a novel hybrid method, which combines the temporal modeling advantage of the Hidden Markov Model (HMM) with the classification capability of SVM. The main contributions of this paper are as follows:
HMM is introduced to model the complex time dependence. Temporal features of vehicle motion data are extracted based on a state transition mechanism, and implicit state transitions can be modeled, providing more accurate features for motion state recognition.
By combining HMM with SVM, the limitations of a traditional single model in modeling time-series data are overcome, and the recognition accuracy of vehicle motion states is improved.
A Kalman filter is applied to denoise the MEMS IMU data, which is more conducive to extracting features from this data.
The remaining paper is organized as follows. In
Section 2, the proposed system architecture is introduced, and the implement details of HMM–SVM are explained. In
Section 3, three experiments are conducted, respectively, to validate the denoising ability of Kalman filtering, verify the classification performance of HMM–SVM, and present the recognition results of different motion states. Finally, a discussion and some conclusions are provided in
Section 4.
2. A Vehicle Motion State Recognition Method Based on HMM–SVM
2.1. System Architecture
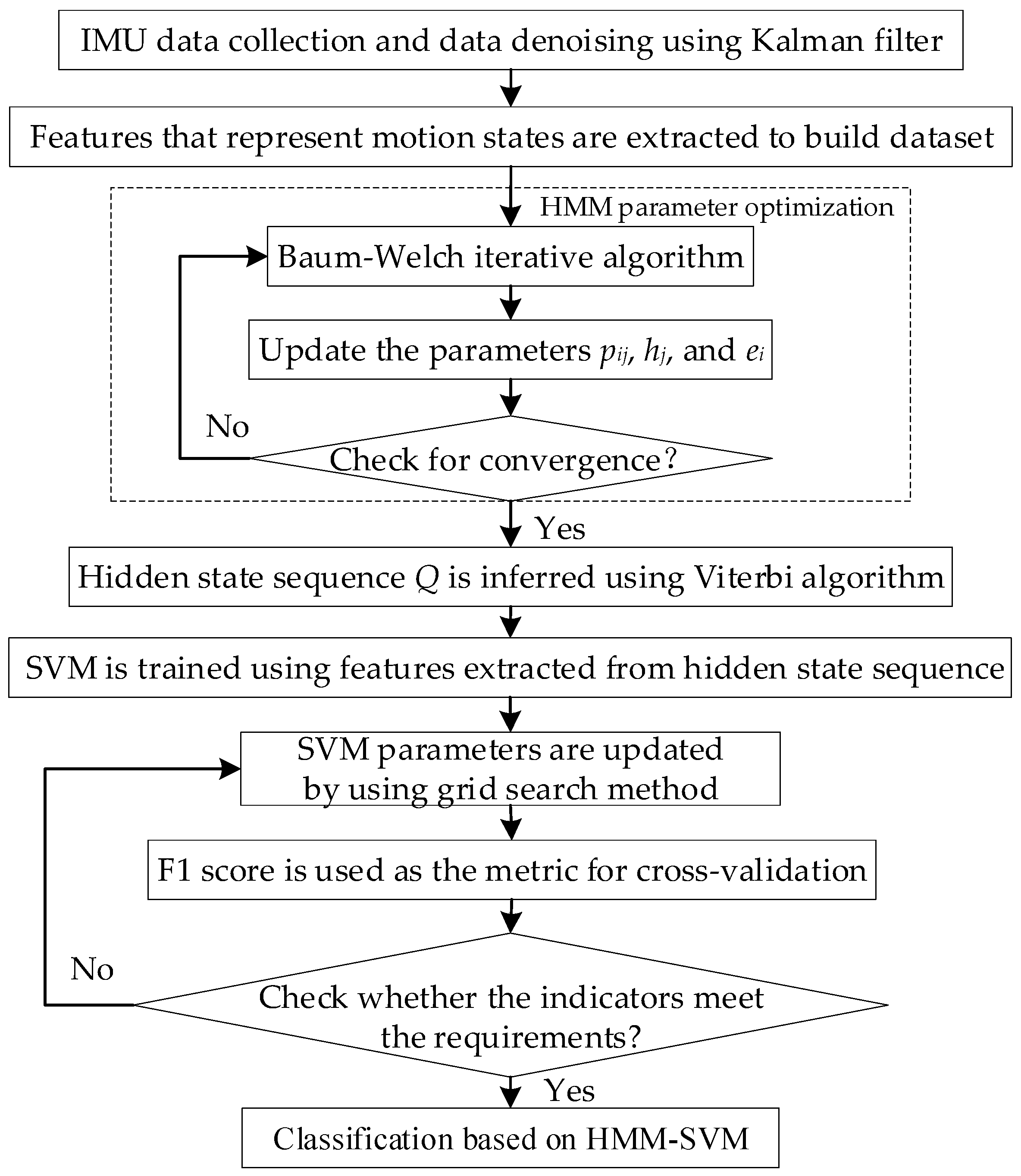
In
Figure 1, the proposed system architecture consists of three components: data acquisition, data processing, and motion state recognition. Firstly, triaxial acceleration data and triaxial angular velocity data are collected from MEMS (Micro-Electro-Mechanical Systems). Next, KF is applied to smooth the noise of MEMS data, and multiple features are extracted to build a dataset capable of recognizing different motion states. At last, the HMM–SVM model is trained and used to recognize the vehicle’s motion state.
2.2. Kalman Filter-Based Sensor Data Denoising
KF is a linear estimation algorithm based on minimum mean square error criterion. It recursively predicts and corrects the system state to obtain the optimal estimation. In this paper, the state vector is composed of triaxial acceleration (
), triaxial angular velocity (
), and angle (
). Therefore, it is represented as follows:
where
denotes the system state vector.
KF uses both a state equation and measurement equation to estimate the system state. State equation describes the state transition over time, and a linear equation is usually used to predict the system state at the next moment. It is shown as follows:
where
represents the state transition matrix, and
represents the process noise vector.
The matrix
is constructed based on the state transition relationship among the members of
. Given the time interval
between two consecutive states,
is defined as follows:
Sensor outputs are taken as the measurement
, which is composed of triaxial acceleration (
), triaxial angular velocity (
), and angle (
). Since
is linearly related to
, the measurement equation is as follows:
where
represents the measurement matrix, and
represents the measurement noise.
2.3. SVM-Based Motion State Classification
SVM is widely used for pattern recognition, with strong generalization ability and strength in processing high-dimensional data. It achieves high accuracy and stability of the model by maximizing the margin between categories, and it is suitable for complex multi-category classification tasks.
In the case of nonlinearly separable problems, a kernel function is used to map the data to a high-dimensional space, where a linearly separable hyperplane is found for classification. The kernel function computes the inner product of data samples in the high-dimensional space without explicitly performing the mapping. Commonly used kernel functions include linear kernel, polynomial kernel, sigmoid kernel, and RBF (Radial Basis Function) kernel. The RBF kernel has a strong nonlinear fitting ability and wide applicability; thus, it is chosen to solve the linear inseparable problems.
SVM separates two categories by searching a hyperplane in the high-dimensional space to seek the minimum classification error. When using SVM for motion state recognition, the motion states can be mapped to the high-dimensional space through the RBF kernel in Equation (6).
where
represents the RBF kernel function, in which
and
are two input samples;
represents the exponential function;
is the squared Euclidean distance, which measures the similarity between two samples;
and
represent the sample indices; and
is the width of the RBF kernel.
When converting the hyperplane solution into a decision function for motion state classification, the decision function is designed as follows:
where
which represents the decision function, outputs the classification result;
is the feature vector of the new sample to be classified;
represents the sign function, outputting
or
based on the operand value;
represents the Lagrange multiplier (support vector weight), in which the superscript
denotes the optimal solution;
represents the true label of the feature vector
;
is the kernel function measuring similarity between two feature vectors;
represents the bias term, computed through the support vectors; and
represents the number of feature vectors.
and
are the core parameters of SVM. The former encodes the classification rule through the selection of support vectors, while the latter adjusts the hyperplane’s position via the bias. In [
27],
and
satisfy the following relationship:
where
represents the maximum value when the variable
is the optimal solution,
;
denotes the constraints;
represents the penalty parameter, which controls the tolerance for classification errors; and
which represents the indices set of all support vectors.
2.4. Modeling Temporal Dependency Based on HMM
Although SVM has good classification performance, its modeling ability for temporal dependence is limited, making it difficult to identify hidden dynamic changes. HMM is capable of modeling long-term dependencies in time series and capturing hidden state transitions, thereby improving the performance of dynamic behavior recognition. In view of this, HMM is introduced to compensate for the shortcomings of SVM.
HMM is a statistical model based on Markov chain theory, typically used to describe time-series data with hidden states. In the proposed method, HMM is used to model the dependence between hidden states and time series. The observation model in HMM follows a polynomial distribution. Its model parameters are obtained by applying the Baum–Welch algorithm, and the hidden state sequence is inferred using the Viterbi algorithm, thereby providing data features for SVM.
The Baum–Welch algorithm iteratively updates HMM parameters to maximize the likelihood of the observed sequence. It is implemented based on the forward–backward process, which outputs the probability of each moment and state. State probabilities and state transition probabilities are calculated using re-estimation formulas until convergence is reached.
represents the probability of state
at time
, and
represents the transition probability from the state
to
at time
.
and
are respectively defined as follows [
28]:
where
represents the state transition probability of HMM, reflecting the possibility of transition from state
to state
;
and
represent the state indices;
is the probability of observing
given the state
;
represents the probability of observing the current sequence at time
, which is computed using the forward method;
represents the probability of the future observation sequence given the state
at time
, and it is recursively computed using the backward method.
where
represents the forward probability at the previous moment;
represents the probability of observing
given that the system is in state
;
represents the backward probability at time
for state
; and
represents the number of states.
The expressions for the transition probability
, the observation probability
and the initial state distribution probability
are the following, respectively:
where
represents the probability of observing
given that the system is in the state
;
represents an indicator function, which equals 1 when the observation
is equal to
and
otherwise;
represents the probability that the state is
at the initial time; and
represents the end time.
Once HMM parameters are obtained, the most likely hidden state can be inferred based on the Viterbi algorithm for a given observation sequence. The optimal path probability refers to the joint probability of the path with the highest probability among all possible hidden state sequences, given the observation sequence
. The maximum path probability at the initial time is the following:
where
represents the joint probability of state
at the initial time (
);
represents the probability of observing
given the state
.
Then, the maximum probability is recursively calculated as follows:
The optimal predecessor state
is defined as follows:
where
represents the optimal preceding state
at time
, given that the system is in the state
at time
.
The optimal state at end time is as follows:
The hidden state at each moment is determined by backtracking. The expression is the following:
At last, the final hidden state sequence is obtained for SVM classification.
Furthermore, to transform the hidden state sequences produced by HMM into feature vectors suitable for SVM classification, we employed a sliding window-based feature extraction approach. The size of the sliding window is 25 samples, and the window updates 1 sample each time. Statistical features, such as the occurrence probability of each hidden state, the probability of transitions between each pair of states, and the average duration of each hidden state, are extracted. These features were then concatenated to form the final input vector for SVM. This approach effectively captures the temporal dynamics embedded in the hidden state sequences while maintaining computational efficiency.
In summary, the whole process of vehicle motion state recognition based on HMM–SVM is shown in
Figure 2.
In
Figure 2, firstly, real-time motion data collected from the IMU sensor is calibrated, and data noise is smoothed by applying Kalman filtering. Then, distinct features are extracted to construct the training dataset, which is subsequently input into HMM. The parameters (including the state transition probability
, the observation probability
, and the state distribution probability
) of HMM are iteratively updated using the Baum–Welch algorithm until the likelihood function converges to a stable value. The Viterbi algorithm is applied to decode the hidden state sequence
, which reflects the temporal variation of the vehicle’s motion states. Furthermore, high-level features are extracted from the decoded sequence for training SVM, and a grid search is applied to find the optimal parameters of SVM. Five-fold cross-validation was adopted, and the F1 score was used as the evaluation metric. After optimal parameters are obtained, SVM is used as the classifier to recognize motion state.
3. Experiment Results and Analysis
In this experiment, a MEMS IMU WT901SDCL is placed at the front of the vehicle to collect sensor data in various motion states. Meanwhile, data collection covers various road conditions in both urban and rural areas. The parameters of WT901SDCL are shown in
Table 1.
The sensor is first calibrated and then samples the data at a rate of 50 Hz. Noise was removed during the data preprocessing to eliminate irrelevant or erroneous information that could negatively impact the model’s training. Statistical values such as mean, standard deviations, and peak values were generated. The dataset was constructed by using representative statistical values that can reflect motion states. It comprised 50,399 samples, categorized according to different motion states and manually labeled. Moreover, the dataset was partitioned into 24,299 training samples (for model training and parameter optimization) and 26,100 test samples (for validation). Vehicle motion states were classified into four categories: stationary, lane changing, straight driving, and turning, which respectively contained 10,632, 9869, 15,731, and 14,167 samples.
The model’s ability to generalize across various environments was achieved through diverse data collection and the application of data normalization. By collecting data from different road types, weather conditions, and driving behaviors, the model was able to learn the inherent environmental variations and reduce the risk of overfitting. Temporal and spatial diversity further enhanced the model’s adaptability to different temperature and infrastructure types. Normalization ensured consistent sensor data across all conditions. These strategies jointly enhance the robustness of the model, enabling it to perform reliably in various real-world scenarios. To prevent overfitting, model complexity was controlled by regularization and tuning model parameters. Additionally, early stopping was employed by checking the validation results, halting the training process before overfitting occurs.
Three experiments were carried out to validate the proposed method. The first experiment was constructed to show the temporal features of sensor data under different motion states and verify the denoising effect of the Kalman filter. In the second experiment, the performance of five typical machine learning methods in recognizing motion states, as well as the performance of SVM using different kernel functions, was evaluated. In the last experiment, a comparison was made between HMM–SVM and SVM to demonstrate the improvements.
3.1. Sensor Data Denoising and Motion State Illustration
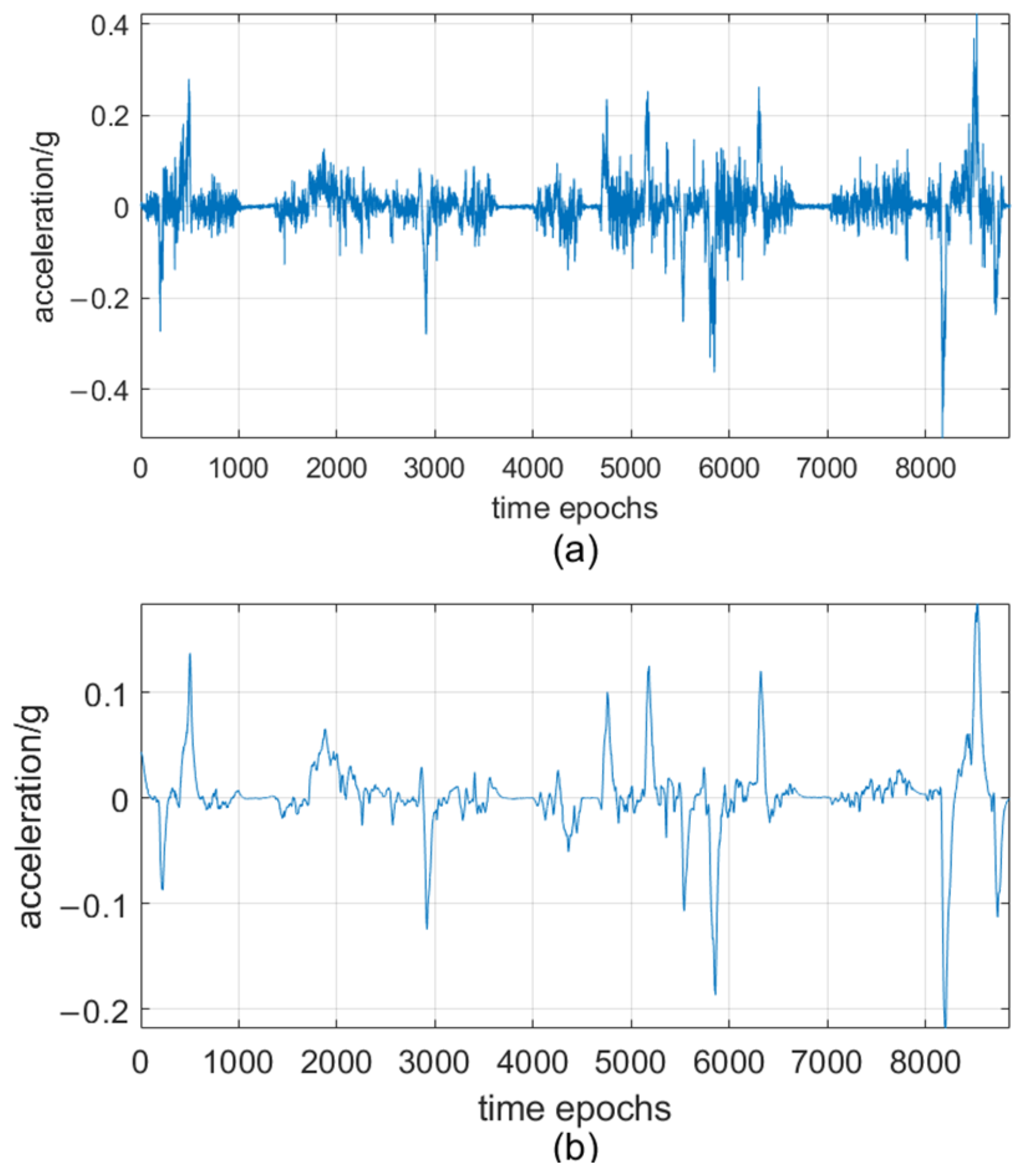
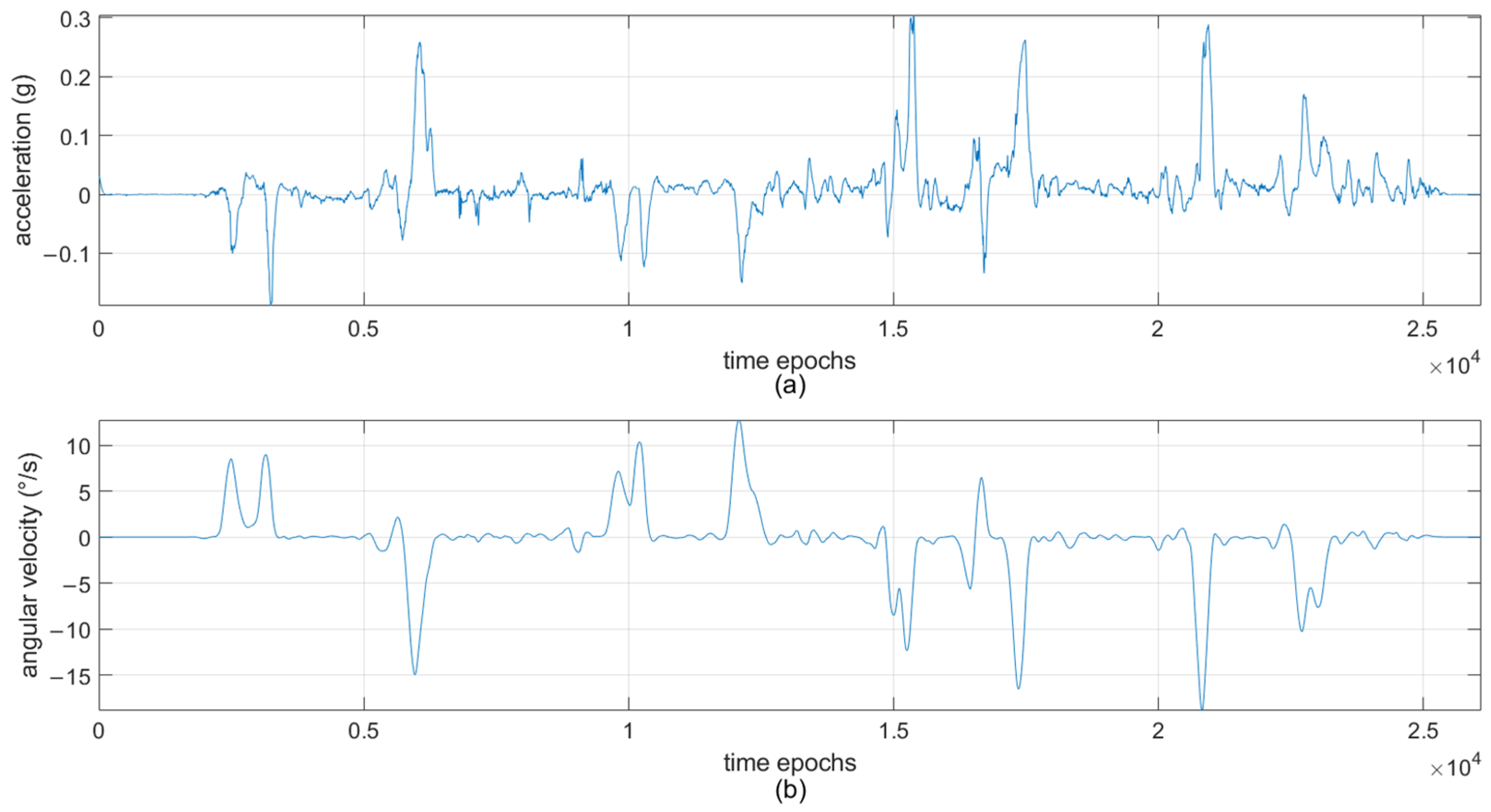
Figure 3 shows the acceleration data before and after applying Kalman filtering. In
Figure 3a, the raw data has noticeable noise jitter. In contrast,
Figure 3b shows that the filtered data curve becomes smooth and stable, high-frequency noise is suppressed, and the main features of raw data are preserved.
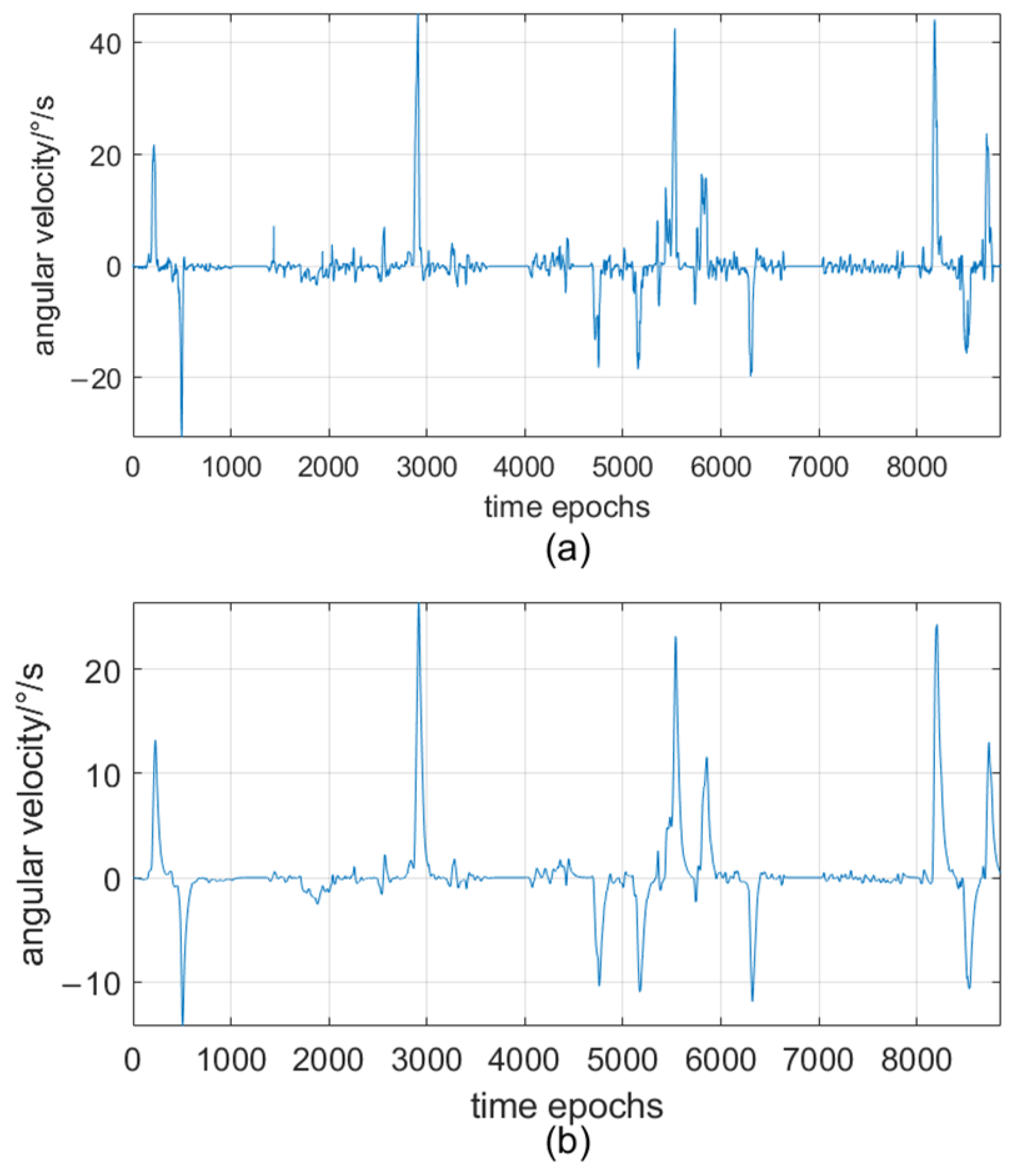
Figure 4 illustrates the angular velocity data before and after applying Kalman filtering. Compared with
Figure 4a,
Figure 4b shows an improvement in smoothness, which can more clearly reflect the true characteristics of angular velocity. The two comparisons prove that Kalman filtering can effectively remove noise from sensor data while retaining the key motion features, which is conducive to the subsequent feature extraction.
There are four categories of vehicle motion states, and each motion state corresponds to a data feature. In
Figure 5, motion states are illustrated through the different features of acceleration data and angular velocity data.
The data points from 650 to 1150 epochs in
Figure 5a show the characteristics of the straight driving state, which is represented by slight undulation of the acceleration data. The data points from 1241 to 1600 epochs show the characteristics of the stationary state, and at this time, the acceleration values are close to zero. In
Figure 5b, the lane changing state (epochs 120–190) is indicated by a small up-and-down fluctuation of the angular velocity data, which shows the symmetry feature after rotating 180 degrees. This feature is helpful for identifying the dynamic state transition, especially when the boundaries between different states are not clear. The left turning state (epochs 475–593) is characterized by a large fluctuation in the positive direction, while the right turning state (epochs 2305–2440) is characterized by a large fluctuation in the negative direction.
3.2. Performance Comparison of Different Machine Learning Methods
SVM, KNN (K-Nearest Neighbor), DT (Decision Tree), RF (Random Forest), and NB (Naive Bayes) are five common machine learning methods. To ensure fair comparisons, all models were optimized using the grid search method and evaluated through five-fold cross-validation. The parameter configuration was as follows: the regularization parameter of SVM was set to 100 to balance margin maximization against classification error, the kernel coefficient gamma was tuned to 0.1 to control the influence range of the individual training example on the decision boundary. The neighborhood size in KNN was set to 5, which determined the number of samples. Smaller values increased the sensitivity to local patterns, while larger values smoothed the decision boundaries. RF was configured with 100 trees, with a maximum tree depth of 20 to prevent overfitting and a minimum sample size of 2 for internal node splitting. The number of features considered in each segmentation was set as the square root of the total number of features. DT was configured with a maximum tree depth of 10 to balance the model complexity and generalization, a minimum sample size of 2 for node splitting, and a leaf node requirement of 1 to ensure that each terminal node contained sufficient samples. NB adopted a smoothing parameter of 1.0 to avoid the zero probability of unseen features, and the variance stabilization parameter was set to 1 × 10−9 to ensure the numerical stability during the process of probability calculation.
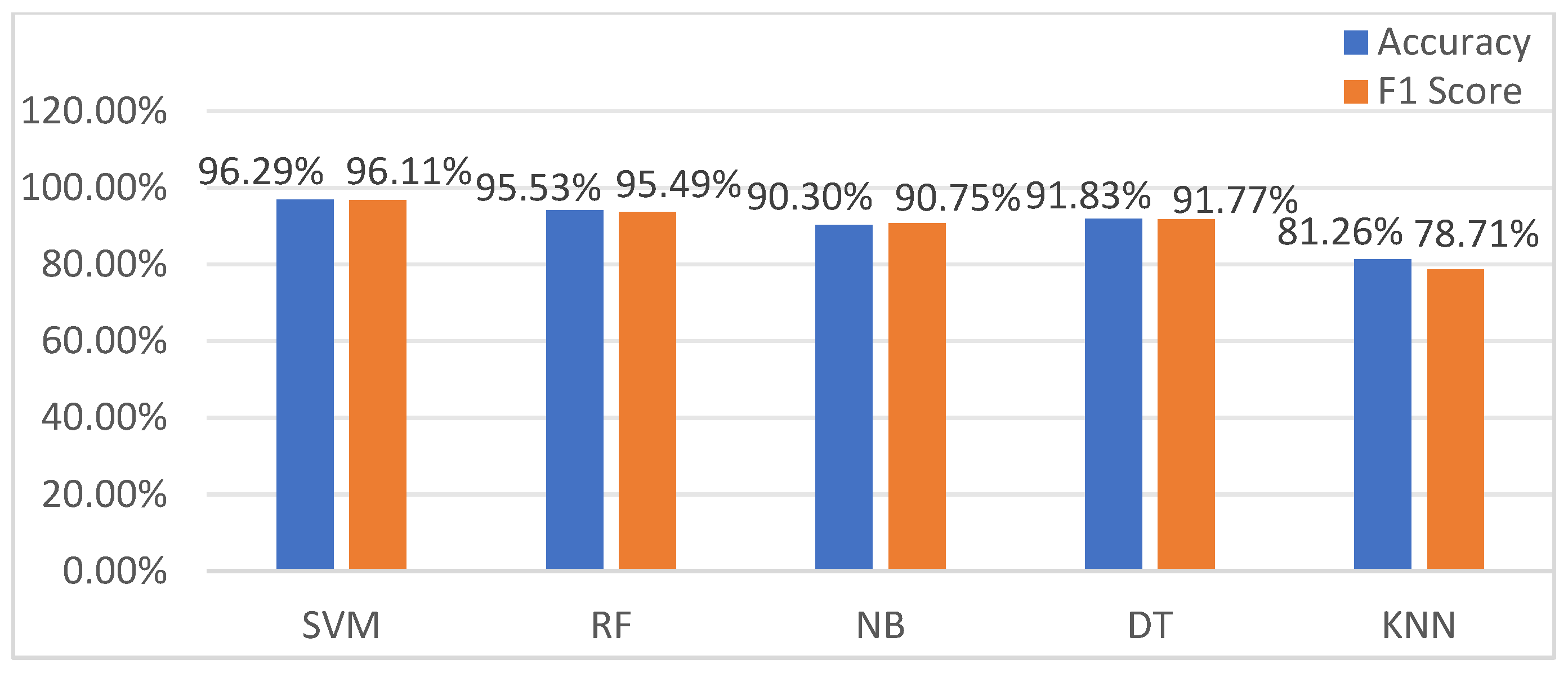
The experiment results of motion state recognition are presented in
Figure 6. KNN has the lowest accuracy and F1 score, while SVM performs best in both assessment indicators, achieving the best classification results.
The performance of SVM depends on the kernel function, which implicitly maps the inseparable low-dimensional data into a higher-dimensional feature space, making the data linearly separable. A comparative test was conducted to evaluate the performance differences of different kernel functions. In
Table 2, test results were summarized. The sigmoid kernel performed the worst on all metrics and had the longest runtime. Both the linear kernel and poly kernel had shorter runtimes, but their performance was moderate. The RBF kernel achieved the highest scores in accuracy, precision, recall, and F1 score [
29], but it had a long runtime. Overall, the RBF kernel had the best performance, and it was selected as the kernel function of SVM in this paper.
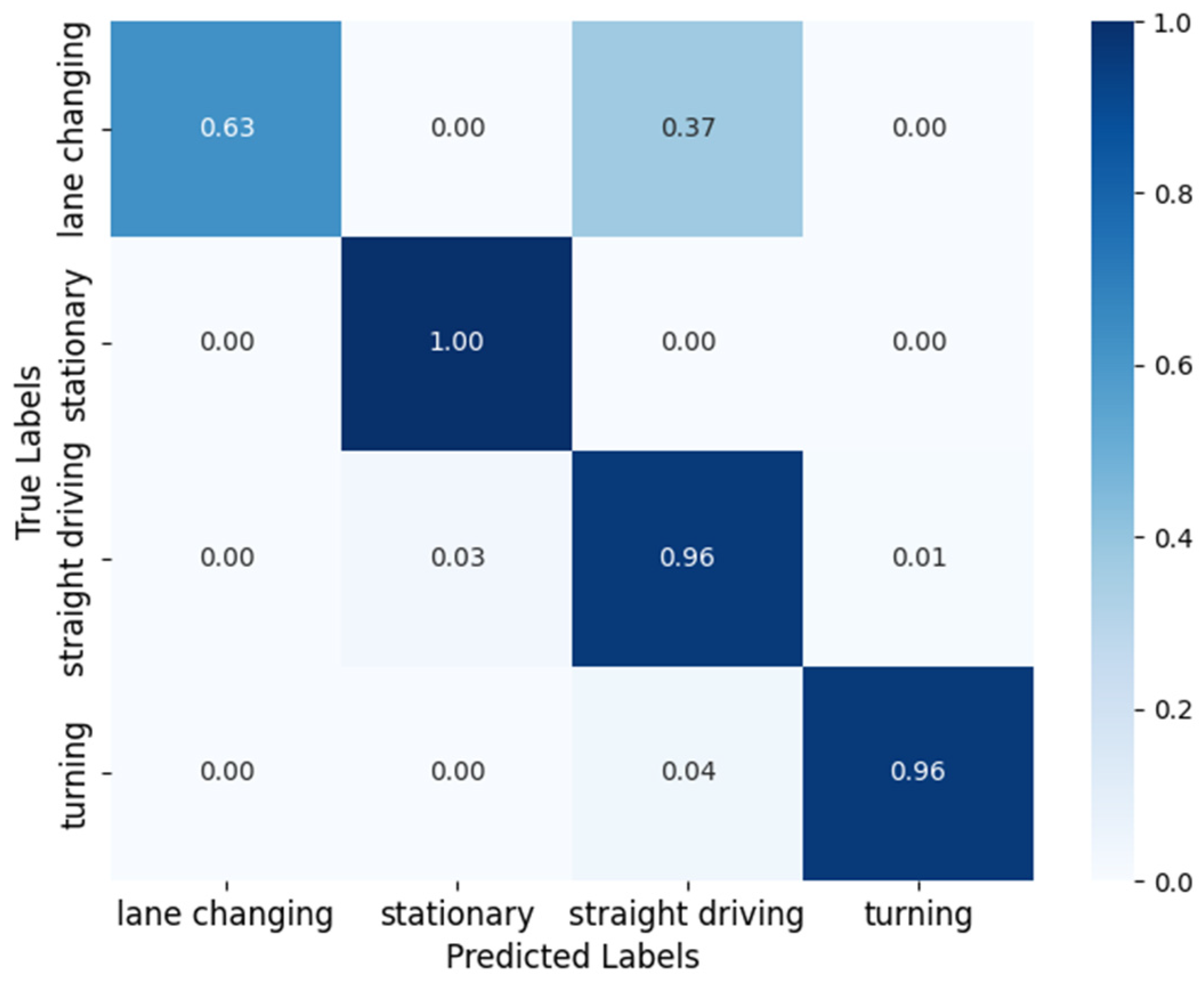
Furthermore, the classification ability of SVM using the RBF kernel is verified, and the confusion matrix of motion states is displayed in
Figure 7. In the confusion matrix, rows indicate the true labels, columns indicate the predicted labels, and the value in each cell reflects the classification probability. The “stationary” state achieves high classification accuracy. However, there is confusion in classification between some states. The confusion between “lane changing” and “straight driving” is the most significant, and the probability is 37%. The “straight driving” state is incorrectly classified as “stationary” and “turning”, with a probability of 3% and 1%, respectively. Additionally, there is a slight confusion of 4% between “turning” and “straight driving”. In summary, SVM shows a good discernment for motion states, but further optimization is required to improve accuracy for states with similar characteristics.
3.3. Recognition Results of Motion States
In
Section 3.2, it was observed that SVM has difficulty in identifying state transitions between two adjacent states, thereby reducing the classification accuracy. To address this problem, HMM was introduced to combined with SVM to model the adjacent states in this paper.
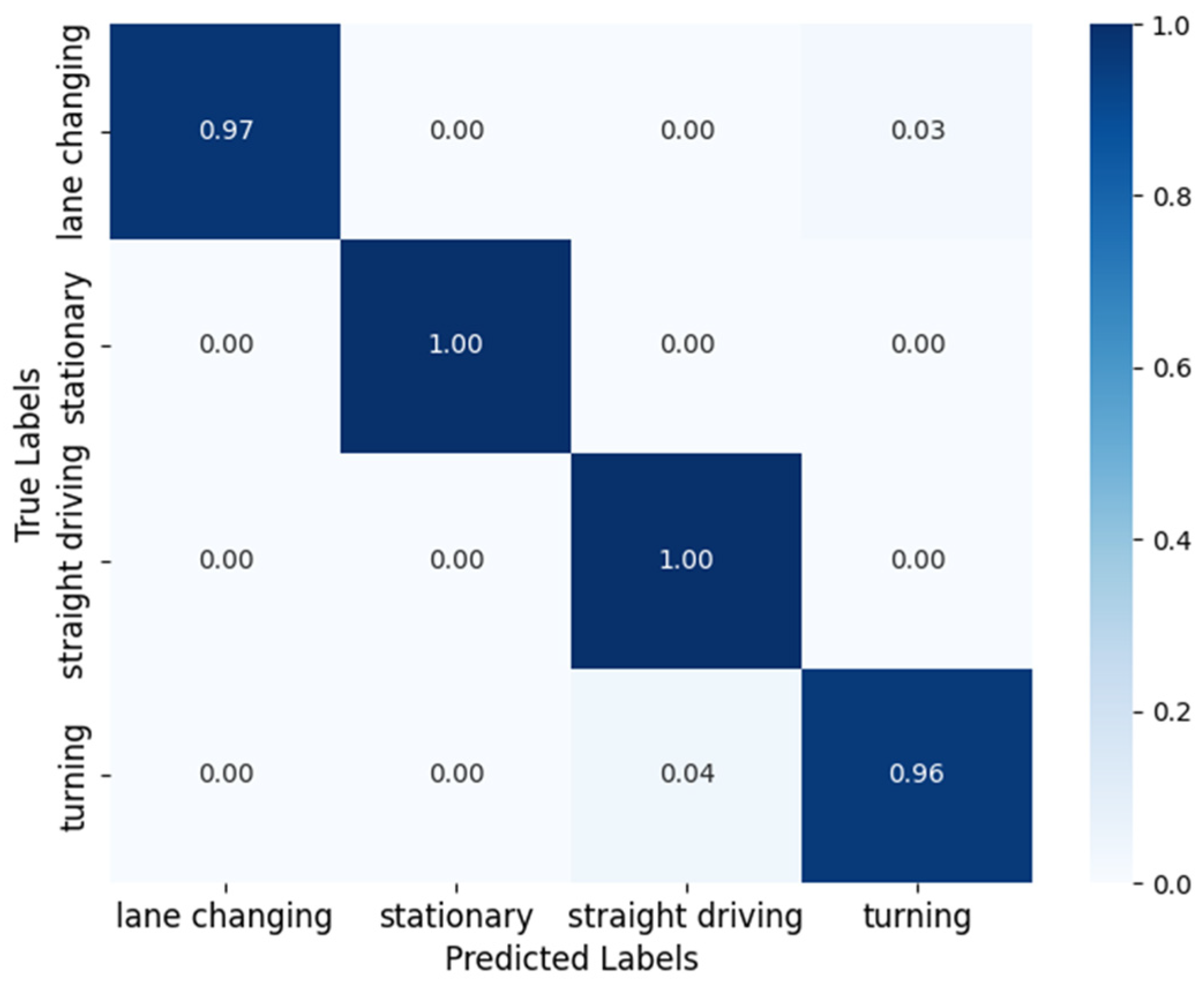
Figure 8 shows the confusion matrix of the proposed method HMM–SVM. As seen in the figure, the motion states “stationary” and “straight driving” can achieve 100% classification accuracy. The “lane changing” state achieves a relatively high accuracy of 97%, with a 3% probability of being incorrectly identified as “turning”, and the “turning” state is wrongly identified as “straight driving” with a probability of 4%. These results indicate that HMM–SVM improves the performance of motion state recognition by integrating the modeling ability of HMM for continuous state transitions.
The performance comparison between SVM and HMM–SVM are presented in
Table 3. The accuracy of HMM–SVM was 98.57%, which is 2.28% higher than that of SVM. The precision was 98.41%, an increase of 2.24%. Recall rate and F1 score increased by 2.29% and 1.84%, respectively.
To confirm the performance improvement of HMM–SVM, we conducted paired t-tests on 10 experiments for each model under the same test conditions. The results show that HMM–SVM outperformed the baseline SVM across all metrics. Specifically, the mean differences in accuracy, precision, recall, and F1 score were 2.28%, 2.24%, 2.29%, and 1.84%, respectively. The corresponding p-values for these metrics were all below 0.004, indicating that the performance improvements achieved by HMM–SVM are statistically significant.
At last, an experiment is constructed to illustrate the visualized results of motion state recognition.
Figure 9 displays the filtered angular velocity data and acceleration data in the new test set.
Figure 10 presents the recognition results of SVM and HMM–SVM, where the labels are as follows: 0: lane changing; 1: stationary; 2: straight driving; and 3: turning. In comparison with
Figure 9, the motion states recognized by both SVM and HMM–SVM between 101 and 5207 epochs are consistent. However, during the lane changing state, between 5450 and 5600 epochs, the state is incorrectly classified as the straight driving state by SVM. Moreover, the turning state is also incorrectly classified by SVM between 9590 and 9680 epochs. On the contrary, HMM–SVM has correct classification and identifies the state transition 36 epochs in advance within 22,100 to 22,490 epochs, which is highly synchronized with the actual changes.
From the above results, it can be concluded that applying SVM achieves accurate recognition in most cases; however, its accuracy decreases during transitions between similar motion states, accompanied by a decline in real-time performance. Thus, SVM has limitations in processing complex motion state transitions. In contrast, HMM–SVM achieves a higher accuracy in motion state recognition and better real-time performance during state transitions. This improvement results from HMM’s ability to model temporal dependency between motion states, enabling the early prediction of state changes and enhancing the recognition performance during dynamic state transitions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}