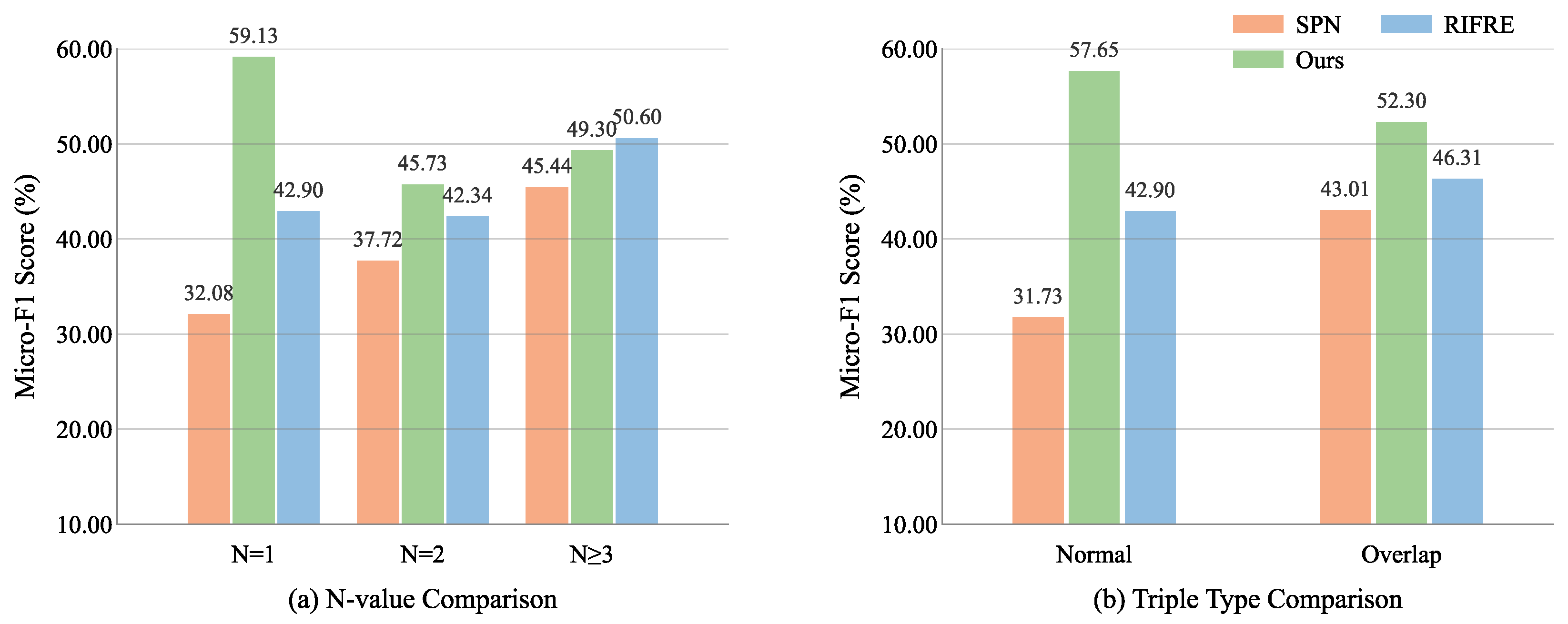1. Introduction
Cybersecurity has become a cornerstone of critical infrastructure protection in the digital era. Advanced Persistent Threats (APTs) employ sophisticated, multi-stage attack chains—including spear-phishing, lateral movement, and data exfiltration—to stealthily infiltrate and compromise target systems. Reports from MITRE ATT&CK, Qi An Xin Technology Group, and Picus Security indicate a significant global surge in APT activities, with attack techniques evolving at a pace that outstrips conventional defense mechanisms. The emergence of cyber threat intelligence (CTI) has accelerated the development of cybersecurity knowledge graphs (CKGs), which systematically integrate insights from unstructured data sources [
1,
2,
3,
4], including security advisories, vulnerability bulletins, and technical reports (as shown in
Figure 1). These CKGs facilitate semantic reasoning for real-time threat identification and attack attribution [
5,
6,
7,
8]. However, existing automated methods for CKG construction face several key challenges:
Long-tailed relation bias: Existing approaches favor high-frequency relational patterns, significantly diminishing their ability to capture low-frequency relations, thereby reducing the model’s semantic discriminative capacity.
Multi-role entity interactions: Conventional sequence modeling frameworks struggle to disentangle phase-specific functional semantics, particularly in overlapping entity scenarios, leading to semantic binding errors in multi-role interactions.
Global relation modeling deficiency: Current joint extraction paradigms fail to model global relational interactions effectively, limiting their ability to capture interdependencies among multi-relational triples and weakening the logical coherence analysis of complex attack chains.
Figure 1.
Example of threat intelligence text, where different types of entities are represented in different colors, while non-entity text is displayed in black.
Figure 1.
Example of threat intelligence text, where different types of entities are represented in different colors, while non-entity text is displayed in black.
Existing research predominantly adopts two methodological paradigms to tackle these challenges. Pipeline-based approaches employ a multi-stage process where relation extraction follows entity detection, such as the RoBERTa-CRF hybrid model proposed by Zhen et al. [
9] for attacker and victim profiling. However, these cascaded architectures suffer from error propagation and suboptimal contextual utilization due to fragmented inter-stage information. In contrast, end-to-end frameworks, such as Set Prediction Networks (SPNs) [
10], struggle to explicitly model syntactic patterns, particularly when handling entity overlap and complex sentence structures. Moreover, existing contrastive learning approaches fail to maintain relation-level semantic consistency, increasing the risk of misclassification for low-frequency relations.
Recent end-to-end methods have started integrating graph neural networks (GNNs) to enhance structural representation learning by explicitly modeling syntactic dependencies. For example, Shang et al. [
11] incorporated GNN-based modules into a span-based extraction paradigm, achieving notable improvements in contextual and structural awareness. However, these approaches still face significant limitations in handling semantic inconsistencies across relation instances, particularly for low-frequency classes. In parallel, contrastive learning techniques have been proposed to mitigate long-tail distribution issues by enhancing feature discrimination for minority relation types. Nevertheless, most existing contrastive learning methods focus solely on entity-level features or rely on static prototype modeling [
12,
13,
14], lacking dynamic alignment mechanisms necessary for maintaining semantic consistency at the relation level. Consequently, these methods remain insufficient for addressing challenges such as multi-relation extraction, entity overlap, and low-frequency relation modeling in CTI tasks.
To address these challenges, this study proposes SAPCL (Syntax-Aware Prototype Contrastive Learning), a multi-feature fusion framework that integrates syntactic structures with semantic representations to enhance the extraction of multi-relational triples. The proposed Syntax-Aware Graph Attention Network (SA-GAT) explicitly models syntactic symmetry by integrating dependency relation types, such as nominal subject (nsubj) and adverbial clause (advcl), into contextual semantics. This design enhances the structural consistency and interpretability of relation representations. In parallel, a triple prototype contrastive learning strategy is introduced to improve the discriminative power of low-frequency relations by leveraging hierarchical semantic alignment and momentum-based prototype evolution, effectively mitigating the limitations posed by long-tailed distributions. To further enhance extraction efficiency, a non-autoregressive parallel decoding architecture is designed to facilitate the generation of multi-relational triples while resolving semantic ambiguities in entity-overlapping scenarios through global contextual constraints. By jointly optimizing syntactic–semantic representation learning, low-frequency relation modeling, and decoding efficiency, SAPCL offers a comprehensive framework for more accurate and robust cyber threat intelligence extraction. The primary findings of this study can be succinctly outlined as follows:
SA-GAT facilitates syntactic–semantic fusion through type-specific dependency modeling, significantly enhancing parsing accuracy for complex attack chain narratives.
The triple prototype contrastive learning framework improves semantic differentiation, while the non-autoregressive decoder reduces misclassification in entity-overlapping cases.
Extensive evaluations on HACKER, ACTI, and LADDER datasets demonstrate that SAPCL outperforms existing joint extraction baselines.
The remainder of this paper is structured as follows:
Section 2 provides a systematic review of entity–relation extraction, graph neural networks, and prototype contrastive learning in cybersecurity.
Section 3 details the SAPCL framework and its technical implementation.
Section 4 presents empirical evaluations, including comparative experiments and ablation studies on multiple CTI datasets.
Section 5 discusses limitations, followed by conclusions in
Section 6.
2. Related Work
2.1. Entity Relation Extraction Methods
The evolution of entity–relation extraction in cybersecurity has progressed from pipeline-based architectures to end-to-end joint modeling. Early methods predominantly adopted staged processing frameworks, exemplified by Zhen et al.’s RoBERTa-CRF model [
9], which sequentially performed entity recognition and relation classification, thereby enhancing stability in Advanced Persistent Threat (APT) attack report parsing. However, such cascaded architectures are inherently susceptible to error propagation [
15,
16,
17,
18], particularly in entity-overlapping scenarios where boundary misidentification compromises relation classification accuracy [
19,
20,
21,
22].
To improve task coherence, recent studies have shifted toward end-to-end joint modeling. Sui et al. [
10] reformulated joint extraction as a set prediction task, integrating bipartite matching algorithms to optimize entity–relation pair generation. While this approach improves extraction accuracy, its high computational complexity limits scalability in large-scale cyber threat intelligence applications. In contrast, Shang et al. [
11] proposed a span-based paradigm that enhances contextual awareness by leveraging unified span representations to encode both entity boundaries and relational semantics. However, empirical analyses indicate that this method struggles to explicitly model syntactic structures [
23,
24], limiting its effectiveness in handling nested entities (e.g., “APT41-associated malicious software X”). Alternatively, Liu et al. introduced a multi-task learning framework that enhances efficiency through parameter sharing; however, challenges persist in mitigating semantic ambiguities in multi-relational overlap scenarios [
25,
26]. These challenges underscore the need for more robust architectures capable of jointly modeling syntactic dependencies and semantic relations.
2.2. Graph Attention Networks
Graph Attention Networks (GATs) have been widely employed in structured data modeling due to their adaptive weight aggregation mechanisms. While conventional GATs have demonstrated effectiveness in social network analysis through uniform neighbor aggregation strategies, their inability to distinguish syntactic variations has significantly constrained their applicability in cybersecurity text processing. To address this limitation, Wang et al. [
27] introduced preconfigured syntactic proximity decay functions to emphasize short-range dependencies, yielding measurable improvements in vulnerability description parsing. However, such static weighting paradigms remain inadequate for capturing dynamically evolving attack patterns inherent in cyber threat intelligence. Xiao et al. [
28] proposed a method that integrates heterogeneous data from APTs using a multimodal feature fusion approach. Their method employs a heterogeneous attributed graph to model APT reports and associated Indicators of Compromise (IOCs), combining attribute-type, text, and topological features. They introduced multilevel heterogeneous GATs that capture deeper semantic information through IOC type-level, neighbor node-level, and semantic-level attention.
Despite these advancements, existing methods, including generic fusion strategies and GAT variants [
29,
30], still struggle to capture cybersecurity-specific dependency structures, such as trigger–impact relationships in exploit chains. The main challenges lie in the lack of domain-specific optimization and the difficulty in modeling dynamic interactions across different attack phases, highlighting the need for further research into syntax-aware semantic fusion mechanisms tailored to cybersecurity contexts.
2.3. Prototype Contrastive Learning
Contrastive learning has demonstrated distinct advantages in mitigating the long-tailed distribution problem in relation extraction. Ye et al. [
31] proposed an entity-level approach that enhances attack entity differentiation by constructing a localized semantic space. However, this method lacks global consistency modeling for relational triples, limiting its effectiveness in supporting multi-hop attack chain inference. At the relation-level, Ding et al. [
12] introduced prototype representation learning, which optimizes prototype distributions via geometric constraints to improve relational semantics in low-resource scenarios. However, its static modeling paradigm struggles to adapt to dynamically evolving attack behaviors, posing limitations on cyber threat intelligence (CTI) extraction.
To address relational prototype optimization, Gao et al. [
13] proposed the Support-Query Guided Enhancement (SQGE) framework, which integrates support-query set features to mitigate intra-class dispersion and inter-class ambiguity. Its positive–negative contrastive mechanism enhances semantic consistency among target entities and improves feature space separability between target and interference classes, offering a novel approach to entity-role disentanglement in APT attack scenarios. However, SQGE fails to model global dependencies among relational triples, constraining its ability to capture semantic continuity in multi-stage attacks.
For dynamic semantic representation, Wang et al. [
14] designed the Prototype Evolution Network (PEN), incorporating a sliding average update strategy that enables adaptive prototype evolution, thereby optimizing the adaptability of low-frequency relation representations. Despite these advancements, existing contrastive learning frameworks face fundamental challenges in cross-granularity semantic alignment, particularly in capturing interdependencies among entity–relation triples and refining adaptive prototypes. These challenges are particularly pronounced in modeling dynamically evolving inter-phase semantic transitions within APT attack chains (e.g., the progression from phishing to lateral movement to data exfiltration).
Recent studies [
32,
33,
34,
35] suggest that synergistically integrating syntactic pattern modeling with prototype contrastive learning is a key pathway to overcoming these challenges. However, current research lacks a unified framework that simultaneously incorporates syntax-aware modeling, relation-level prototype learning, and global triple consistency mechanisms. This gap highlights the necessity of developing syntax–semantic co-enhancement frameworks to facilitate fine-grained inference and dynamic threat modeling in APT attack chain analysis.
3. Methods
3.1. Overview of SAPCL Framework
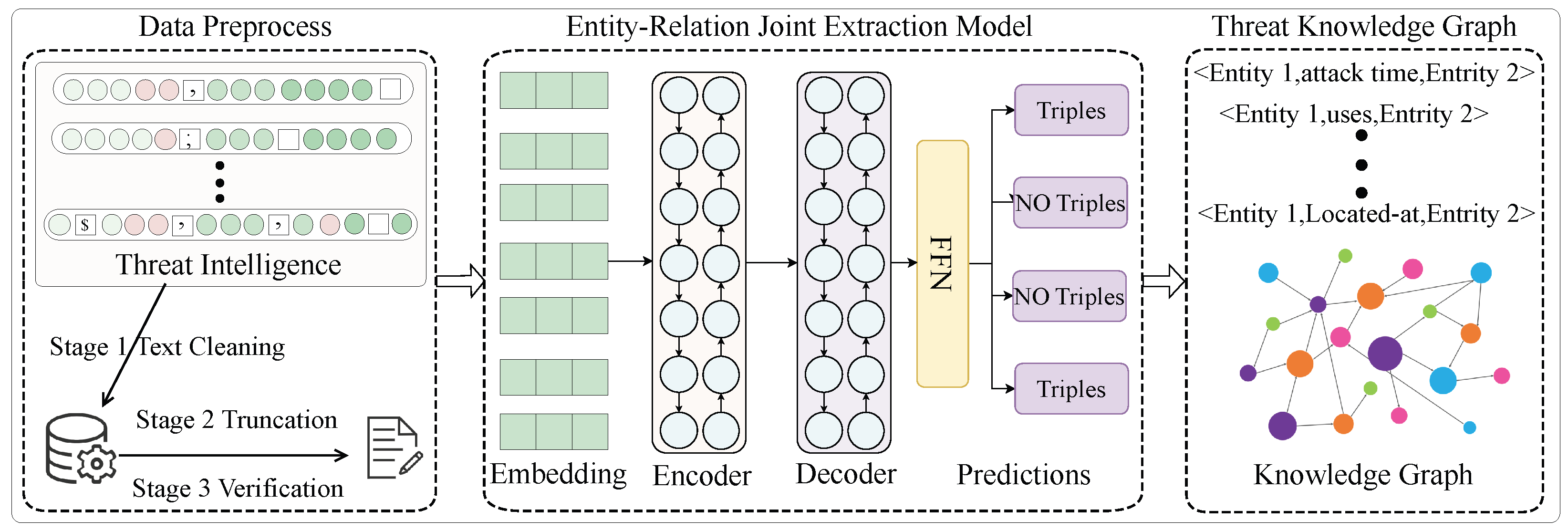
To address key challenges in cyber threat intelligence extraction, such as low-frequency relations, entity overlap, and complex syntactic dependencies—we propose SAPCL (Syntax-Aware and Prototype Contrastive Learning), a unified framework for structured CTI knowledge graph construction. As shown in
Figure 2, SAPCL follows an encoder–decoder architecture enhanced with syntax-aware and contrastive learning modules, jointly transforming unstructured CTI texts into relational triples for downstream analysis. SAPCL adopts a systematic workflow that begins by preprocessing raw CTI texts to ensure data normalization and entity integrity, followed by an encoder–decoder architecture enhanced with syntax-aware and contrastive learning modules to extract structurally and semantically rich relational triples. These triples are finally organized into a structured CTI knowledge graph, representing entities as nodes and semantic relations as labeled edges. This modular approach supports component-level optimization and easy integration with diverse CTI datasets.
SAPCL’s modular architecture addresses three specific technical challenges: (1) capturing syntactic dependencies for accurate extraction of fine-grained entity–relations; (2) enhancing generalization capability for low-frequency relations via semantic prototype alignment; and (3) improving decoding efficiency to mitigate exposure bias in multi-relation extraction scenarios. Detailed implementations and innovations of each module are elaborated in the following sections.
3.2. Module Details
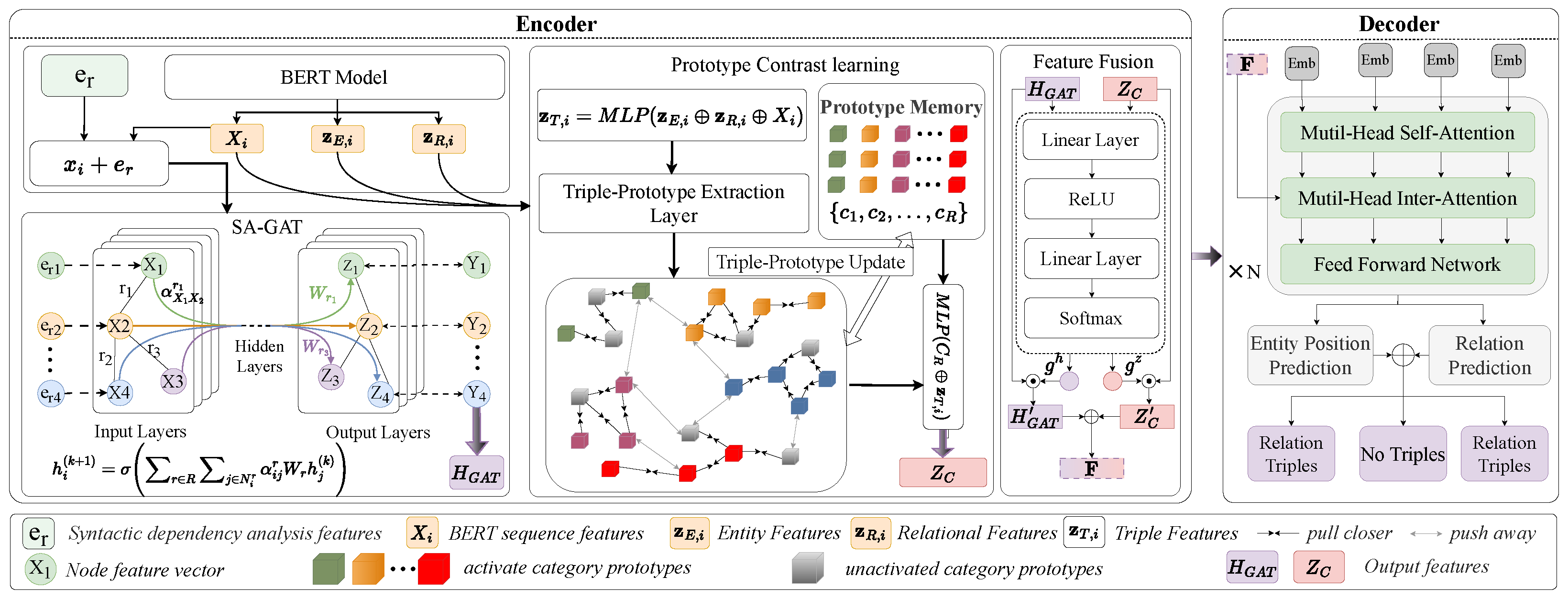
Building on the overall workflow introduced above, SAPCL comprises three core components: the Syntax-Aware Graph Attention Network (SA-GAT), the prototype contrastive learning module, and the non-autoregressive decoder.
Figure 3 illustrates the detailed internal architecture and interactions among these modules. In this section, we present each module in detail, highlighting their specific contributions to addressing the aforementioned CTI extraction challenges.
The encoder layer aims to capture contextual semantics and syntactic dependencies in threat intelligence texts. Given an input sequence of length l, the token embeddings can be denoted as . The pre-trained BERT model encodes input CTI texts into contextual representations through , where (with ) denotes the contextual embedding matrix and l is the sequence length. The multi-head attention in BERT encodes token-level dependencies, providing rich contextual features for downstream extraction modules.
3.2.1. Syntax-Aware Graph Attention Network
Unlike standard Graph Attention Networks (GATs), our proposed Syntax-Aware Graph Attention Network (SA-GAT) explicitly integrates dependency relation embeddings and relation-specific transformations to effectively capture structural dependencies and syntactic nuances in threat intelligence texts. Traditional GATs typically ignore dependency types, treating edges uniformly, which significantly restricts their capability to handle complex syntactic scenarios. To address these limitations, we propose the Syntax-Aware Graph Attention Network (SA-GAT), which dynamically refines attention weights using dependency relation embeddings
to better capture semantic distinctions. Additionally, it enables multi-relation modeling by incorporating relation-specific weight matrices
, thereby enhancing the expressiveness and discriminative power of syntactic representations, as illustrated in
Figure 3.
where
are learnable weight matrices that operate on node feature vectors
and
, respectively, generating query and key representations.
projects the concatenated node features
into the dependency embedding space. Here,
is the embedding of dependency relation type
r, incorporating relation-aware elements;
is a learnable parameter for weighting relation-aware terms, with ⊙ denoting element-wise multiplication and ‖ indicating vector concatenation; and
d is the vector dimension. The representation of node
i at the
k-th GAT layer is updated as
Here,
denotes the set of neighbors of node
i connected via relation type
r, and
is the corresponding relation-specific transformation matrix. After multiple SA-GAT layers, syntax-aware representations
enriched with dependency type information are obtained. The dependency embedding
and the relation-aware term
enable dynamic adjustment of attention weights based on dependency types, capturing semantic differences between grammatical relations. Simultaneously, the relation-specific weight matrices
facilitate multi-relation modeling, significantly enhancing the discriminative power of syntactic representations [
36].
3.2.2. Prototype Contrastive Learning
To address the pronounced long-tail distribution of relation categories in threat intelligence datasets, we adopt a prototype contrastive learning strategy. Existing contrastive learning approaches often fail to account for the pronounced long-tail distribution of relation categories in cybersecurity texts, and typically lack task-specific adaptation mechanisms. Therefore, we propose a dynamic prototype updating mechanism specifically designed to improve representation learning for low-frequency relations and mitigate the negative impact of data imbalance.
Our method constructs prototype representations for each relation category and guides the embedding of relational triples toward semantically coherent clusters. As illustrated in
Figure 3, this design enhances the model’s ability to capture fine-grained semantic distinctions among relations, ultimately improving the precision of triple extraction in threat intelligence tasks.
First, entity embeddings are derived by integrating entity boundary positions and contextual representations to effectively distinguish entities. Relation feature vectors are extracted to capture contextual variations in relationship semantics. Then, triple embeddings are generated through concatenation and projection as follows: , represents the entity embedding, denotes the relation feature vector, and corresponds to the global contextual representation.
To address the noise sensitivity caused by sample scarcity in low-frequency relations, we introduce a sample-aware dynamic prototype update mechanism (see Algorithm 1 and
Figure 3). During model initialization, the first update cycle leverages full data statistics to initialize prototypes, preventing cold-start bias. In subsequent iterations, prototypes are dynamically updated using an exponential moving average strategy:
where
denotes the prototype representation of relation category
k at iteration
t, and
represents the sample size in the current batch. The momentum coefficient
is adaptively adjusted as
, ensuring stability under low-resource conditions. Specifically, when
is small, a higher
value retains more historical prototype memory, suppressing single-sample deviations. Conversely, when
is sufficiently large,
approaches the base momentum
, increasing sensitivity to new feature updates. After each iteration, L2 normalization is applied to the prototype matrix
C, enforcing geometric consistency in contrastive space and enhancing representation stability.
In the contrastive phase, the system creates multi-granularity positive and negative samples. Positive pairs include embeddings from the same relational category and their augmented semantic variations. Negative samples include cross-relation mismatches and incorrect model predictions. By actively distinguishing semantically similar from dissimilar triples, the model achieves refined semantic boundaries.
| Algorithm 1: Prototype Contrastive Learning |
![Symmetry 17 01013 i001]() |
As shown in Algorithm 1, our framework enhances the robustness of low-frequency relations in APT attack chains (e.g., targeted infiltration, data exfiltration) by enforcing semantic clustering through dynamic prototype updates. This strategy enforces semantic clustering, drawing similar triples closer while pushing apart dissimilar ones. The resulting representations capture both class-level consistency and instance-level nuances. These are further fused with contextual BERT embeddings and syntax-aware SA-GAT outputs to form the final feature representation , integrating semantic, syntactic, and contextual cues for more accurate threat intelligence extraction.
3.2.3. Non-Autoregressive Decoder
The decoder adopts a non-autoregressive decoding strategy to generate relational triples
in parallel. Unlike autoregressive methods that rely on sequential decoding [
37], our approach initializes a fixed number
m of query embeddings
, each independently predicting a candidate triple. The value of
m is empirically set based on dataset statistics, allowing full coverage of possible triples while eliminating error accumulation across decoding steps.
To capture interactions among candidate triples and encoder features, the decoder incorporates a multi-head attention mechanism consisting of self-attention and cross-attention layers. Self-attention models dependencies within the query set, while cross-attention enables semantic alignment between decoder queries and encoder outputs F. These are followed by residual connections and layer normalization to improve stability. This parallel decoding design improves efficiency and robustness in multi-entity and multi-relation scenarios common in threat intelligence texts.
The decoder outputs are processed through a feed-forward network (FFN) to predict relation types and entity boundaries:
, where
denotes the attention-processed decoder query output, and
is a learnable weight matrix. Entity boundaries are predicted via contextual interaction:
where
represents the fused encoder features,
are learnable parameters, and
is a weight vector.
Candidate triples are formed if the relation probability surpasses a threshold (
, where
) and the entity overlap satisfies
(where
). The resulting candidate set is denoted as
. To mitigate redundancy, a cost matrix
is constructed between predictions and ground truth triples
, where
represents the matching cost between the
i-th prediction and the
j-th ground truth:
Here,
quantifies the entity boundary overlap as
; the hyperparameters are set as
and
. To obtain the optimal alignment between predictions and ground truths, the Hungarian algorithm is applied:
. Unmatched predictions are considered as negative samples during the loss computation, enhancing the model’s robustness in distinguishing valid and spurious triples.
3.2.4. Loss Function and Optimization
To jointly optimize entity boundaries and relation classification, we define a multi-task loss function guided by the Hungarian matching algorithm. It consists of three components: span prediction loss, relation classification loss, and prototype contrastive loss.
To ensure accurate entity boundary detection, we adopt a token-level cross-entropy loss over the start and end positions:
where
and
denote the ground truth label and the predicted probability at position
i for boundary type
t, respectively.
To address the class imbalance commonly observed in CTI datasets, we enhance the standard cross-entropy loss with Focal Loss, placing greater emphasis on hard-to-classify, low-frequency relations:
Here,
is a weighting coefficient,
is the focusing parameter, and
and
are the true label and predicted probability for relation
r, respectively.
To enhance semantic consistency in relational triple representations, we employ a dynamic prototype contrastive loss:
where
denotes cosine similarity,
is the temperature coefficient,
is the embedding of the
i-th triple, and
is the prototype of the corresponding relation class. This loss promotes intra-class compactness and inter-class separability in the embedding space.
The final objective function integrates all loss components: , where , , and are hyperparameters that balance the contributions of different losses.
To optimize the model efficiently, we employ the AdamW optimizer with weight decay to mitigate overfitting. Additionally, a dynamic learning rate strategy is utilized to accelerate convergence and enhance model stability.
3.3. Data Preprocessing
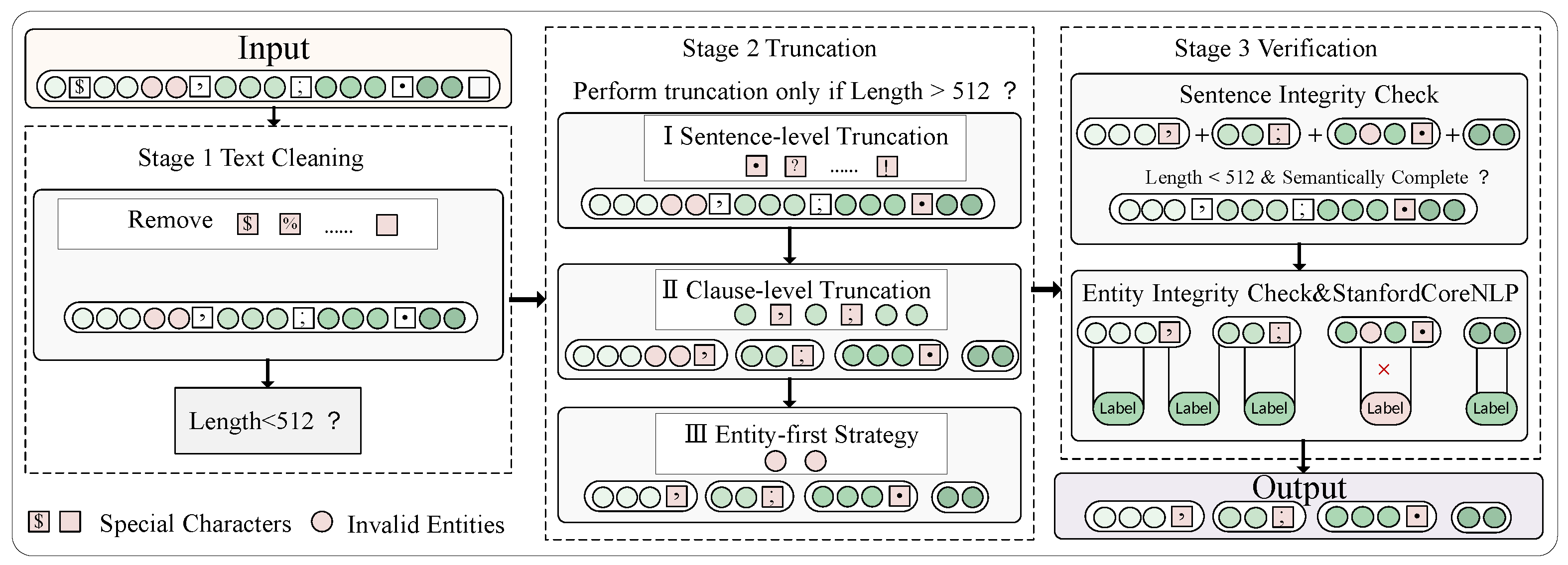
As illustrated in
Figure 4, the preprocessing pipeline consists of four stages designed to accommodate the constraints of pre-trained models:
Text Sanitization: HTML tags are removed using pattern matching. Non-ASCII characters and redundant whitespaces are filtered through Unicode normalization, while encoding is standardized to UTF-8 to ensure compatibility with language model tokenizers.
Semantic Segmentation: Sentences are split at terminal punctuation marks (./?/!) to create clause-level units. A retention strategy prioritizes clauses containing security indicators (e.g., CVE IDs, malware hashes) via regular expression matching, while other clauses are placed in candidate pools for potential recall.
Adaptive Truncation: For clauses exceeding 512 subword tokens, dependency tree analysis from Stanford CoreNLP guides syntax-aware truncation. Core entities with key dependency relations (e.g., nsubj, amod) are prioritized for retention using subtree preservation algorithms.
Span Reindexing: Entity boundaries are recalibrated based on the final tokenization outputs to prevent fragmentation (e.g., partial entity “documents of APT37” from “Malicious documents of APT37”). This is achieved through byte-pair alignment and BIOES tagging verification.
Figure 4.
Overview of the syntax-guided preprocessing workflow. It ensures semantic coherence under the token length constraint (≤512), preserving key attack chain information for effective CTI modeling.
Figure 4.
Overview of the syntax-guided preprocessing workflow. It ensures semantic coherence under the token length constraint (≤512), preserving key attack chain information for effective CTI modeling.
This syntax-guided preprocessing workflow optimizes semantic coherence preservation in attack chain narratives while maintaining strict length constraints.
3.4. Implementation Details
The SAPCL framework was implemented using PyTorch 2.10, with BERT
base as the encoder, and trained on NVIDIA Tesla A800 GPUs. The detailed configurations of key modules—SA-GAT (
Section 3.2.1), prototype contrastive learning (
Section 3.2.2), and non-autoregressive decoder (
Section 3.2.3)—are described in the previous sections. The detailed hyperparameters and training settings are discussed in
Section 4.2. All experiments used fixed random seeds (primary seed = 2025) to ensure reproducibility, with robustness confirmed by additional seed variations.
4. Experiments
4.1. Datasets
To ensure a comprehensive and fair evaluation of the proposed framework, we selected three datasets based on the following criteria: (1) coverage of diverse cyber threat intelligence scenarios to ensure broad applicability; (2) variation in dataset scale, relation type diversity, and structural complexity to evaluate performance across different levels of extraction difficulty; and (3) differences in annotation quality and noise levels to assess model robustness and generalizability under realistic conditions.
We evaluated our framework on three public cyber threat intelligence datasets representing different operational scenarios: APT campaign reports (HACKER), vehicle security incidents (ACTI), and malware threat intelligence (LADDER). Each dataset has been meticulously annotated and partitioned into training, validation, and testing subsets in an 8:1:1 ratio to ensure reliable evaluation.An overview of the statistical composition of the datasets is presented in
Table 1.
The HACKER dataset [
38] was constructed through neural network-assisted dark web monitoring and contains 2153 curated APT reports with 3597 sentences and 6686 relational triples across 21 attack patterns.
ACTI [
39] aggregates 908 cybersecurity incidents from NVD and Upstream feeds, containing 8195 security entities (CVE IDs, IoCs) and 4852 triples across 10 malware-centric relations, including exploit_uses and vulnerability_affects.
The LADDER [
40] dataset was constructed by Alam et al. by crawling and integrating publicly available cyber threat intelligence (CTI) reports. The data were primarily derived from over 12,000 open-source CTI reports covering cyber threat intelligence between 2010 and 2021. The dataset contains 10,664 named entities and 5332 triples. It is used for attack pattern extraction and cyber threat intelligence knowledge graph construction.
4.2. Experimental Parameters
Environment: Ubuntu 20.04, NVIDIA Tesla A800 GPU (80GB), PyTorch 2.10, Python 3.8. To ensure reproducibility and experimental reliability, all experiments were conducted using a fixed random seed (seed = 2025). For robustness verification, we additionally tested seeds 2022, 2023, and 2024, and observed consistent performance trends. An early stopping strategy was also employed to avoid overfitting, with the patience parameter set to 10 epochs. The early stopping criterion was based on the F1 score on the validation set.
Table 2 shows key parameters that significantly affect performance and stability. The encoder–decoder uses different learning rates
with weight decay
. SA_GAT has 2 layers. Contrastive learning uses
,
, and momentum
to optimize embeddings. Entity loss weights
and gradient clipping
ensure stability.
4.3. Baseline Models
We benchmark our approach against three state-of-the-art joint entity–relation extraction frameworks representing distinct technical paradigms:
PRGC [
41]: Proposes an end-to-end framework that filters possible relationship categories through a potential relationship prediction module and directly predicts triples based on the global correspondence matrix, significantly reducing the computational overhead of redundant relationship classification.
RIFRE [
42]: A heterogeneous graph neural network that performs iterative message passing between entity and relation nodes through dedicated interaction layers, effectively capturing local semantic dependencies.
SPN [
10]: Formulates extraction as a set prediction task using learnable query embeddings, then applies the Hungarian algorithm to optimize bipartite matching loss between predictions and ground truth, enhancing generation efficiency.
For a fair comparison, all models were initialized with BERT_base (cased) pre-trained weights and fine-tuned with the same settings.
4.4. Main Results
To address class imbalance, we used micro-precision (P), micro-recall (R), and micro-F1 (F1) as metrics. We compared our model with baselines on HACKER, ACTI, and LADDER.
As shown in
Table 3, our SAPCL model achieves an F1-score of 56.63% on the challenging HACKER dataset, significantly outperforming the state-of-the-art (SOTA) models PRGC and RIFRE by 15.73 and 14.59 percentage points, respectively. The notable difficulty of the HACKER dataset arises from inherent noise due to distant supervision annotations and extreme class imbalance, with 33% of triples classified as low-frequency relations (
Table 1). Such conditions typically degrade baseline model performance substantially; however, SAPCL demonstrates exceptional robustness against these factors. This substantial improvement in performance compared to established methods underscores the effectiveness of integrating syntax-aware modeling and dynamic prototype contrastive learning, effectively mitigating noise and class imbalance issues prevalent in CTI extraction tasks.
On the ACTI and LADDER benchmarks, SAPCL obtains F1-scores of 60.21% and 53.65%, surpassing the SPN baseline by 0.82 and 6.36 percentage points, respectively. Although SPN achieves a higher recall (70.41%) on ACTI, it suffers significantly lower precision (51.35%), trailing SAPCL by 15.67 percentage points. Moreover, SAPCL demonstrates a considerable 10.67 percentage-point F1 improvement over PRGC on ACTI. These consistent and significant gains across datasets of varying sizes and annotation complexities clearly demonstrate the superiority and robustness of our method. Compared directly with multiple state-of-the-art methods (PRGC, RIFRE, SPN), SAPCL maintains a balanced precision–recall trade-off, affirming that our quantitative results represent substantial, statistically robust, and practically meaningful advancements for real-world CTI extraction scenarios.
4.5. Low-Frequency Triple Extraction
To address the challenge of data sparsity associated with low-frequency relationships (i.e., tail categories in long-tailed distributions) in threat intelligence, the proposed model demonstrates remarkable robustness when handling relationship types that occur fewer than 30 times in both the HACKER and ACTI datasets. As shown in the experimental results (
Figure 5 and
Figure 6), the model achieves significant improvements in performance, particularly for low-frequency relationships. The prototype-based contrastive learning mechanism plays a critical role in enhancing performance in these cases. By dynamically updating prototypes based on sample counts, the model effectively suppresses the impact of noisy samples, leading to more accurate predictions for underrepresented relationship categories.
As shown in
Figure 5, SAPCL consistently outperforms both SPN and RIFRE across the majority of low-frequency relations in the HACKER dataset. Notably, for the critical “target user” relation (19 instances), SAPCL achieves an F1 score of 62.86%, substantially outperforming SPN (40.00%) and RIFRE (42.42%). Similarly, for the extremely rare “IP address used” relation (4 instances), SAPCL reaches 75.00% F1, while RIFRE obtains only 28.57%, and SPN achieves 54.55%. These clear margins, as visualized in
Figure 5, demonstrate that SAPCL delivers substantial and consistent performance advantages for rare categories within the long-tail spectrum. Such improvements highlight the model’s capacity to effectively alleviate representation bias and optimize learning for sparse relations.
Figure 6 further reinforces these findings on the ACTI dataset. SAPCL maintains superior performance across low-frequency relations. For the “mitigates” relation (5 instances), SAPCL achieves an F1 score of 57.14%, compared to 33.33% from both SPN and RIFRE. Additionally, on the “located-at” relation (17 instances), SAPCL reaches 66.67% F1, surpassing SPN (58.57%) and RIFRE (49.41%). The observable trend across both datasets, as shown in
Figure 5 and
Figure 6, consistently demonstrates SAPCL’s robustness in handling extreme data sparsity scenarios, delivering stable improvements for multiple low-frequency relation types across different CTI corpora.
Taken together, the consistent performance improvements observed across both the HACKER and ACTI datasets—particularly for multiple low-frequency relation types—demonstrate the quantitative adequacy and robustness of SAPCL in handling severe data sparsity. These improvements are not limited to isolated categories but are evident across a broad range of tail relations, exhibiting clear and statistically significant improvements in F1-scores compared to established baselines, such as SPN and RIFRE.
4.6. Multi-Relation and Overlapping Entity Extraction
This section evaluates the model’s ability to handle multi-relational coordination parsing in APT attack chains and the semantic disambiguation of overlapping threat entities. We conducted controlled experiments on multi-relation density (N-value) gradients and entity overlap conflict scenarios within the HACKER dataset, using micro-F1 as the unified evaluation metric.
As illustrated in
Figure 7a, as the number of triples per sentence increases from
to
, the F1 score of our model decreases from 59.13% to 49.30%, yet still surpasses SPN by 3.86 percentage points at
. Meanwhile, SPN, despite showing a higher score at
compared to
, remains consistently lower than our model across all settings. Despite the natural performance degradation in high-density scenarios, our model demonstrates greater robustness, maintaining a more consistent performance trend across different relation densities. In entity overlap scenarios (
Figure 7b), our method achieves an F1 score of 52.30, outperforming SPN by 9.29 percentage points, while also demonstrating superior performance in normal scenarios. Experimental results show a 5.99 percentage point improvement in F1 over RIFRE (equivalent to an 11.15% relative reduction in parsing errors), while maintaining stable performance in base scenarios.
Overall, SAPCL demonstrates superior robustness in both multi-relation density and entity overlap scenarios. As shown in
Figure 7a, even when the number of triples per sentence increases from
to
, SAPCL maintains a higher F1 score (49.30%) than SPN and RIFRE, with a 3.86 percentage point lead over SPN and a 4.70 percentage point margin over RIFRE at
. In entity overlap cases (
Figure 7b), SAPCL achieves 52.30% F1, outperforming SPN by 9.29 percentage points and RIFRE by 5.99 percentage points (an 11.15% relative error reduction compared to RIFRE). These consistent quantitative improvements stem from the synergistic effects of our dynamic contrastive learning module and syntax-aware Graph Attention Network. Specifically, the contrastive learning component effectively disentangles shared entities (e.g., “Microsoft Exchange”) into distinct relational spaces via hierarchical semantic prototype alignment, while SA-GAT captures contextual semantic roles through type-specific dependency attention. This co-optimization enables SAPCL to maintain both high precision and recall under conditions characterized by complex relation densities and entity-role ambiguities. These gains are statistically significant and practically meaningful for real-world CTI extraction, especially in scenarios with frequent multi-triple sentences and overlapping entities.
4.7. Ablation Experiments
This section investigates the sensitivity of the SA-GAT network’s depth to syntactic modeling by comparing performance variations with different numbers of layers (ranging from 1 to 4) across three datasets.
As shown in
Table 4, variations in the number of SA-GAT layers significantly influence the model’s performance. The single-layer structure exhibits notable performance degradation across all three datasets, primarily due to insufficient depth in syntactic relationship modeling. When the number of layers is increased to three, the model faces challenges related to noise accumulation, which occurs during cross-layer communication, leading to slight fluctuations in performance. Furthermore, expanding the number of layers to four results in a substantial performance decline across all datasets. In contrast, the two-layer model strikes an optimal balance, capturing local syntactic dependencies (e.g., nsubj and dobj) and accurately modeling direct interactions between entities through typed attention.
To further evaluate the contribution of each module to overall performance, we conducted an ablation study by progressively removing key components.
Table 5 presents the results of the ablation study, which demonstrates a catastrophic performance decline when BERT is replaced with random embeddings, with F1 scores dropping by 32.88 percentage points on the HACKER dataset, 33.7 percentage points on the ACTI dataset, and 36.20 percentage points on the LADDER dataset. This underscores the crucial role of pre-trained language models in understanding contextual threat semantics, which is vital for downstream tasks. Replacing SA-GAT with a vanilla GCN leads to a 11.51 percentage point reduction in F1 on the HACKER dataset, highlighting the importance of dependency-type-aware modeling.
Our SA-GAT approach mitigates the structural bias observed in conventional GCNs through type-specific attention weight calibration, particularly enhancing focus on security-relevant dependencies such as nsubj and advcl. The removal of the contrastive learning module leads to an F1 decrease from 13.31 percentage points to 14.45 percentage points across datasets, thereby validating the effectiveness of the contrastive mechanism in optimizing low-frequency relation representations via entity–relation-triple hierarchical alignment.
The synergistic effect between SA-GAT and contrastive learning is particularly evident on the LADDER dataset, where the combined removal of both modules results in a 16.36 percentage-point drop in performance—exceeding the average degradation of 13.88 percentage points on the LADDER dataset when removing individual modules. This complementary relationship emerges as SA-GAT enforces local syntactic constraints on attack chains, while contrastive learning ensures global semantic consistency, together enabling more precise threat association parsing.
4.8. Case Study: Parsing the Stuxnet Attack Chain
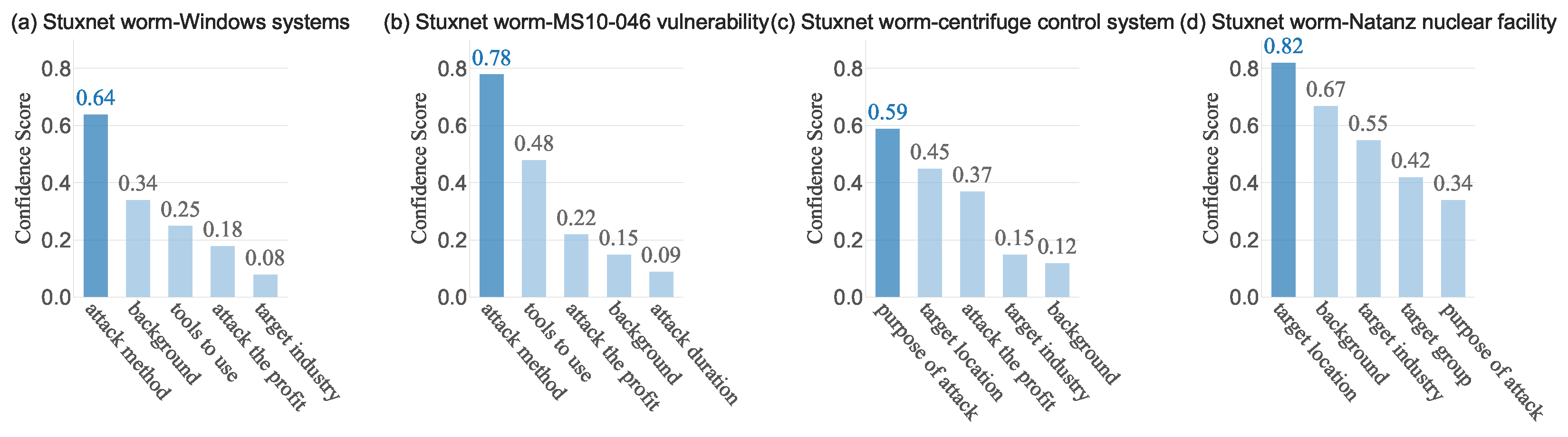
To validate the model’s capability in parsing real-world threat intelligence, we present a case study on the Stuxnet attack chain, demonstrating SAPCL’s proficiency in extracting critical entities and relational triples from unstructured text. The input text describes the following: “The Stuxnet worm infected Windows systems through the MS10-046 vulnerability, exploited the Siemens Step7 software vulnerability to hijack the PLC controller, and ultimately disrupted the centrifuge control system at the Natanz nuclear facility in Iran”.
As illustrated in
Figure 8a–d, SAPCL effectively parses various critical aspects of the attack chain. This includes identifying attack methods (e.g., from “Stuxnet worm infiltrates Windows systems via rootkit techniques”,
Figure 8a), accurately capturing vulnerability exploitation (e.g., from “Stuxnet exploits MS10-046 vulnerability to escalate privileges”,
Figure 8b), deeply understanding attack intent (e.g., from “Stuxnet aims to sabotage centrifuge control systems”,
Figure 8c), and inferring strategic target locations (e.g., from “Stuxnet primarily targets Natanz nuclear facility in Iran”,
Figure 8d). The model consistently generates structured triples with high confidence, demonstrating its ability to map logical associations, capture the weaponization of vulnerabilities, reflect deep semantic parsing of attack intent, and perform strong inference for target locations. These prediction results, supported by a clearly defined confidence gradient, systematically validate SAPCL’s effectiveness in multidimensional relationship extraction for APT attack chain parsing.
To complement the above case study, we conducted a systematic evaluation of SAPCL’s inference efficiency under three representative deployment environments: a high-end GPU (NVIDIA A800), a mid-range GPU (NVIDIA T4 on Google Colab), and a CPU-only setup (also on Google Colab). Evaluation inputs were sampled from the HACKER dataset’s test split and categorized by input length into short (fewer than 150 tokens), medium (150–300 tokens), and long (over 300 tokens, up to approximately 500 tokens), reflecting diverse CTI-style sentence complexities. The assessment focused on average inference latency, P99 tail latency, throughput under varying batch sizes, and model loading time. As summarized in
Appendix A (
Table A1 and
Figure A1), SAPCL achieves sub-second average latency for short and medium inputs, with significantly higher throughput on GPU platforms. Even in CPU-only environments, the model maintains reasonable responsiveness (average latency of 0.34 s), underscoring its applicability to near real-time CTI tasks.
5. Discussion
The SAPCL framework demonstrates significant advancements in APT attack chain parsing by jointly optimizing syntactic dependencies and prototype contrastive learning. One major reason behind these improvements lies in the synergistic design of the SA-GAT and prototype contrastive modules. Specifically, the SA-GAT network enhances the model’s ability to capture dependency-based structural features (e.g., subject–object relations, modifiers) by assigning relation-type-specific attention weights. This syntactic awareness helps the model to correctly differentiate between multiple roles of overlapping entities, leading to more accurate triple extraction in complex scenarios. At the same time, the prototype contrastive learning mechanism reinforces semantic consistency across low-frequency relation instances by dynamically aligning them with evolving class-level prototypes. This reduces variance among minority classes and suppresses noise in the feature space. Together, these two components causally contribute to the model’s robustness and performance improvements, especially under long-tailed and noisy conditions, as confirmed by the results in
Table 3 and
Figure 5,
Figure 6 and
Figure 7.
Empirical results confirm that SAPCL consistently outperforms state-of-the-art baselines across multiple datasets and extraction scenarios. Specifically, on the HACKER dataset, SAPCL achieves a notable 14.59% improvement in micro-F1 over RIFRE, effectively handling noisy and imbalanced conditions. SAPCL also demonstrates clear advantages in extracting low-frequency relations (e.g., target user, IP address used) and exhibits robustness in entity-overlap scenarios. Compared to established methods (PRGC, RIFRE, SPN), which typically yield micro-F1 scores between 37% and 54%, SAPCL achieves significantly higher scores of 56.63%, 60.21%, and 53.65% on the HACKER, ACTI, and LADDER datasets, respectively. Ablation studies further validate each module’s substantial contribution, reinforcing the statistical robustness and practical value of SAPCL in addressing long-tailed distribution and complex extraction challenges.
Nonetheless, several limitations remain. The reliance on general-purpose dependency parsers can introduce domain mismatches, impairing the accuracy of syntactic modeling for cybersecurity-specific constructs. In addition, prototype contrastive learning may become unstable when applied to extremely sparse categories. Lastly, the model’s fixed-length context window restricts its capacity to capture long-range dependencies across sentences, which can affect semantic coherence in extended attack chain narratives. Future work will explore domain-adaptive parsing, document-level modeling, and meta-learning approaches to address these challenges.
6. Conclusions
In this study, we propose the SAPCL framework, which combines syntax-aware modeling and dynamic contrastive learning to tackle key challenges in APT attack chain parsing, including complex syntactic structure analysis, low-frequency relationship modeling, and entity overlap disambiguation. By leveraging multilevel syntactic–semantic collaboration and dynamic representation optimization, SAPCL enhances both the robustness and accuracy of threat intelligence extraction. The framework’s core innovation lies in the integration of a dependency-aware adaptation mechanism within Syntax-Aware Graph Attention Networks (SA-GATs), along with a hierarchical semantic alignment strategy based on prototype contrastive learning. This synergy facilitates real-time reasoning, improves the semantic consistency of multi-stage attack behavior associations, and strengthens the dynamic modeling of threat intelligence. Additionally, SAPCL significantly contributes to the construction of a knowledge graph, providing a structured representation of threat intelligence that can be leveraged for more effective and scalable cybersecurity analysis.
SAPCL offers a scalable solution for automated threat hunting and active defense, contributing to the advancement of cybersecurity operations. Future research will aim to improve the accuracy of syntactic parsing by fine-tuning general-purpose dependency parsers with domain-specific CTI corpora, enabling the SA-GAT module to more effectively recognize specialized terminology such as threat actor aliases and malware tool names. To address the limitations imposed by fixed-length context windows in capturing inter-sentence dependencies, we plan to explore hierarchical document-level modeling strategies, including context-aware sliding window mechanisms, discourse-level graph representations, and memory-augmented architectures. These enhancements are expected to strengthen the model’s ability to capture long-range semantic relations across sentence boundaries. Moreover, to better support low-resource scenarios, we will investigate few-shot learning approaches through the development of a meta-learning-based framework that leverages synthetic attack chain data and cross-relational knowledge transfer.
Author Contributions
Conceptualization, Z.H.; Methodology, Z.Z. and Z.L.; Formal analysis, Z.Z.; Investigation, Z.Z.; Validation, Z.L.; Resources, Z.H.; Writing—original draft, Z.Z.; Writing—review and editing, Z.L. and Z.Z.; Visualization, Z.Z.; Supervision, Z.H.; Project administration, Z.H.; Funding acquisition, Z.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by Gansu Province Higher Education Institution’s Industrial Support Program under grant number 2020C-29, and in part by the National Natural Science Foundation of China under grant number 61562002.
Data Availability Statement
The datasets generated and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Inference Efficiency Evaluation
We evaluated the inference efficiency of SAPCL across three representative hardware platforms: (1) an NVIDIA A800 GPU (80GB) deployed on a shared high-performance computing cluster, (2) an NVIDIA T4 GPU (16GB), and (3) a CPU-only node—both (2) and (3) were hosted on Google Colab. Evaluation inputs were sampled from the test split of the HACKER dataset and stratified by input length into three categories: short (fewer than 150 tokens), medium (150–300 tokens), and long (over 300 tokens, up to approximately 500 tokens). The short and medium groups each comprised 100 CTI-style sentences, and the long group included 29 sentences. All groups covered the relationship types in the dataset. This evaluation protocol ensures both semantic diversity and realistic task complexity, enabling a reliable analysis of SAPCL’s inference performance under varied deployment conditions.
Table A1.
Model performance comparison across different hardware.
Table A1.
Model performance comparison across different hardware.
| Model (HW) | Throughput (sent/s) 1 | P99 Latency (s) | Mem (MB) | Avg. Latency (s) 2 | Load Time (s) 3 |
|---|
| A800 | 67.13 | 0.0148 | 766.8 | 0.0196 | 4.310 |
| T4 (Colab) | 31.01 | 0.0580 | 886.5 | 0.0372 | 6.560 |
| CPU (Colab) | 2.93 | 0.6136 | 3200.8 | 0.3409 | 12.680 |
Figure A1.
Inference throughput (a) and average latency (b) across input lengths and hardware configurations.
Figure A1.
Inference throughput (a) and average latency (b) across input lengths and hardware configurations.
Table A1 and
Figure A1 jointly summarize SAPCL’s inference performance across hardware platforms and input lengths. As shown in
Figure A1, SAPCL consistently achieves sub-second average latency for short and medium CTI-style inputs, with CPU latency ranging from 0.182 to 0.341 s. GPU-based configurations provide significantly higher throughput, processing up to 75.2 and 48.2 sentences per second on the A800 and T4, respectively, for short inputs. The CPU remains a feasible option for lightweight deployments, achieving up to 4.0 sentences/sec on short inputs. The aggregate results across all input lengths are summarized in
Table A1, further demonstrating SAPCL’s scalability and its ability to support real-time or near-real-time applications in varied deployment scenarios.
References
- Wang, G.; Liu, P.; Huang, J.; Bin, H.; Wang, X.; Zhu, H. KnowCTI: Knowledge-based cyber threat intelligence entity and relation extraction. Comput. Secur. 2024, 141, 103824. [Google Scholar] [CrossRef]
- Yuan, C.; Xie, Q.; Ananiadou, S. Temporal relation extraction with contrastive prototypical sampling. Knowl.-Based Syst. 2024, 286, 111410. [Google Scholar] [CrossRef]
- Zhao, X.; Jiang, R.; Han, Y.; Li, A.; Peng, Z. A survey on cybersecurity knowledge graph construction. Comput. Secur. 2024, 136, 103524. [Google Scholar] [CrossRef]
- Zhao, X.; Deng, Y.; Yang, M.; Wang, L.; Zhang, R.; Cheng, H.; Lam, W.; Shen, Y.; Xu, R. A comprehensive survey on relation extraction: Recent advances and new frontiers. ACM Comput. Surv. 2024, 56, 1–39. [Google Scholar] [CrossRef]
- Ren, Y.; Xiao, Y.; Zhou, Y.; Zhang, Z.; Tian, Z. CSKG4APT: A cybersecurity knowledge graph for advanced persistent threat organization attribution. IEEE Trans. Knowl. Data Eng. 2022, 35, 5695–5709. [Google Scholar] [CrossRef]
- Li, Z.; Zeng, J.; Chen, Y.; Liang, Z. AttacKG: Constructing technique knowledge graph from cyber threat intelligence reports. In Proceedings of the European Symposium on Research in Computer Security; Springer: Berlin/Heidelberg, Germany, 2022; pp. 589–609. [Google Scholar]
- Chen, B.; Li, H.; Zhao, D.; Yang, Y.; Pan, C. Quality assessment of cyber threat intelligence knowledge graph based on adaptive joining of embedding model. Complex Intell. Syst. 2025, 11, 54. [Google Scholar] [CrossRef]
- Li, Z.X.; Li, Y.J.; Liu, Y.W.; Liu, C.; Zhou, N.X. K-CTIAA: Automatic analysis of cyber threat intelligence based on a knowledge graph. Symmetry 2023, 15, 337. [Google Scholar] [CrossRef]
- Zhen, Z.; Gao, J. Chinese Cyber Threat Intelligence Named Entity Recognition via RoBERTa-wwm-RDCNN-CRF. Comput. Mater. Contin. 2023, 77, 299–323. [Google Scholar] [CrossRef]
- Sui, D.; Zeng, X.; Chen, Y.; Liu, K.; Zhao, J. Joint entity and relation extraction with set prediction networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 12784–12795. [Google Scholar] [CrossRef]
- Shang, W.; Wang, B.; Zhu, P.; Ding, L.; Wang, S. A Span-based Multivariate Information-aware Embedding Network for joint relational triplet extraction of threat intelligence. Knowl.-Based Syst. 2024, 295, 111829. [Google Scholar] [CrossRef]
- Ding, N.; Wang, X.; Fu, Y.; Xu, G.; Wang, R.; Xie, P.; Shen, Y.; Huang, F.; Zheng, H.T.; Zhang, R. Prototypical Representation Learning for Relation Extraction. arXiv 2021, arXiv:2103.11647v1. [Google Scholar]
- Gao, C.; Zhang, X.; Jin, Z.; Cai, W.; Wang, D.; Du, K.; Yin, C.; Li, T. SQGE: Support-query prototype guidance and enhancement for few-shot relational triple extraction. Neural Netw. 2025, 185, 107172. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Chen, Y.; Huang, R.; Qin, Y. A prototype evolution network for relation extraction. Appl. Intell. 2025, 55, 8. [Google Scholar] [CrossRef]
- Wang, C.; Li, A.; Tu, H.; Wang, Y.; Li, C.; Zhao, X. An advanced bert-based decomposition method for joint extraction of entities and relations. In Proceedings of the 2020 IEEE Fifth International Conference on Data Science in Cyberspace (DSC), Hong Kong, China, 27–30 July 2020; pp. 82–88. [Google Scholar]
- Mouiche, I.; Saad, S. Entity and relation extractions for threat intelligence knowledge graphs. Comput. Secur. 2025, 148, 104120. [Google Scholar] [CrossRef]
- Ainslie, S.; Thompson, D.; Maynard, S.; Ahmad, A. Cyber-threat intelligence for security decision-making: A review and research agenda for practice. Comput. Secur. 2023, 132, 103352. [Google Scholar] [CrossRef]
- Wang, X.; Liu, J. A novel feature integration and entity boundary detection for named entity recognition in cybersecurity. Knowl.-Based Syst. 2023, 260, 110114. [Google Scholar] [CrossRef]
- Jo, H.; Lee, Y.; Shin, S. Vulcan: Automatic extraction and analysis of cyber threat intelligence from unstructured text. Comput. Secur. 2022, 120, 102763. [Google Scholar] [CrossRef]
- Ahmed, K.; Khurshid, S.K.; Hina, S. CyberEntRel: Joint extraction of cyber entities and relations using deep learning. Comput. Secur. 2024, 136, 103579. [Google Scholar] [CrossRef]
- Eberts, M.; Ulges, A. Span-based joint entity and relation extraction with transformer pre-training. In Proceedings of the ECAI 2020, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 2006–2013. [Google Scholar]
- Liu, C.; Wang, J.; Chen, X. Threat intelligence ATT&CK extraction based on the attention transformer hierarchical recurrent neural network. Appl. Soft Comput. 2022, 122, 108826. [Google Scholar]
- Lv, H.; Han, X.; Cui, H.; Wang, P.; Zuo, W.; Zhou, Y. Joint Extraction of Entities and Relationships from Cyber Threat Intelligence based on Task-specific Fourier Network. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Tang, B.; Li, X.; Wang, J.; Ge, W.; Yu, Z.; Lin, T. STIOCS: Active learning-based semi-supervised training framework for IOC extraction. Comput. Electr. Eng. 2023, 112, 108981. [Google Scholar] [CrossRef]
- Zuo, J.; Gao, Y.; Li, X.; Yuan, J. An end-to-end entity and relation joint extraction model for cyber threat intelligence. In Proceedings of the 2022 7th International Conference on Big Data Analytics (ICBDA), Guangzhou, China, 4–6 March 2022; pp. 204–209. [Google Scholar]
- Liu, Y.; Han, X.; Zuo, W.; Lv, H.; Guo, J. CTI-JE: A Joint Extraction Framework of Entities and Relations in Unstructured Cyber Threat Intelligence. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; pp. 2728–2733. [Google Scholar]
- Wang, X.; Xiong, M.; Luo, Y.; Li, N.; Jiang, Z.; Xiong, Z. Joint learning for document-level threat intelligence relation extraction and coreference resolution based on gcn. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2020; pp. 584–591. [Google Scholar]
- Xiao, N.; Lang, B.; Wang, T.; Chen, Y. APT-MMF: An advanced persistent threat actor attribution method based on multimodal and multilevel feature fusion. Comput. Secur. 2024, 144, 103960. [Google Scholar] [CrossRef]
- Du, Y.; Ren, W.; Song, X.; Li, W. Research on APT group classification method based on graph attention networks. J. Supercomput. 2025, 81, 563. [Google Scholar] [CrossRef]
- Ren, W.; Li, W.; Hong, Y.; Du, Y.; Gao, Y.; Zhang, H.; Xia, M. GC-PTransE: Multi-step attack inference method based on graph convolutional neural network and translation embedding. Knowl. Inf. Syst. 2025, 67, 5215–5245. [Google Scholar] [CrossRef]
- Ye, H.; Zhang, N.; Deng, S.; Chen, M.; Tan, C.; Huang, F.; Chen, H. Contrastive triple extraction with generative transformer. Proc. Proc. Aaai Conf. Artif. Intell. 2021, 35, 14257–14265. [Google Scholar] [CrossRef]
- Cao, Y.; Kuang, J.; Gao, M.; Zhou, A.; Wen, Y.; Chua, T.S. Learning relation prototype from unlabeled texts for long-tail relation extraction. IEEE Trans. Knowl. Data Eng. 2021, 35, 1761–1774. [Google Scholar] [CrossRef]
- Liao, Z.; Fei, J.; Zeng, W.; Zhao, X. Few-shot named entity recognition with hybrid multi-prototype learning. World Wide Web 2023, 26, 2521–2544. [Google Scholar] [CrossRef]
- Hu, C.; Yang, D.; Jin, H.; Chen, Z.; Xiao, Y. Improving Continual Relation Extraction through Prototypical Contrastive Learning. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 1885–1895. [Google Scholar]
- Fan, C. The Entity Relationship Extraction Method Using Improved RoBERTa and Multi-Task Learning. Comput. Mater. Contin. 2023, 77, 1719–1738. [Google Scholar] [CrossRef]
- Sun, L.; Li, Z.; Xie, L.; Ye, M.; Chen, B. APTKG: Constructing Threat Intelligence Knowledge Graph from Open-Source APT Reports Based on Deep Learning. In Proceedings of the 2022 5th International Conference on Data Science and Information Technology (DSIT), Shanghai, China, 22–24 July 2022; pp. 1–6. [Google Scholar]
- You, Y.; Jiang, Z.; Zhang, K.; Feng, H.; Jiang, J.; Yang, P. TiGNet: Joint entity and relation triplets extraction for APT campaign threat intelligence. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; pp. 1687–1694. [Google Scholar]
- Luo, Y.; Ao, S.; Luo, N.; Su, C.; Yang, P.; Jiang, Z. Extracting threat intelligence relations using distant supervision and neural networks. In Proceedings of the Advances In Digital Forensics XVII: 17th IFIP WG 11.9 International Conference, Virtual Event, 1–2 February 2021; Revised Selected Papers 17. Springer: Berlin/Heidelberg, Germany, 2021; pp. 193–211. [Google Scholar]
- Wang, Y.; Ren, Y.; Qin, H.; Cui, Z.; Zhao, Y.; Yu, H. A dataset for cyber threat intelligence modeling of connected autonomous vehicles. Sci. Data 2025, 12, 366. [Google Scholar] [CrossRef]
- Alam, M.T.; Bhusal, D.; Park, Y.; Rastogi, N. Looking beyond IoCs: Automatically extracting attack patterns from external CTI. In Proceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, Hong Kong, China, 16–18 October 2023; pp. 92–108. [Google Scholar]
- Zheng, H.; Wen, R.; Chen, X.; Yang, Y.; Zhang, Y.; Zhang, Z.; Zhang, N.; Qin, B.; Ming, X.; Zheng, Y. PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 6225–6235. [Google Scholar]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction. Knowl.-Based Syst. 2021, 219, 106888. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}