1. Introduction
In today’s digital era, graph-structured data are widely used in social networks, transportation networks, and biological networks [
1,
2,
3,
4,
5]. These graph-structured data usually have complex topologies and contain rich hidden information. However, effective analysis and learning of large-scale graph-structured data usually requires a large amount of labeled data to train machine learning models. Obtaining labeled data is often challenging due to issues such as the scarcity of labeled data and the high cost of labeling. In the field of machine learning, feature selection is one of the key methods to optimize model performance and reduce the risk of overfitting [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. However, with the high dimensionality of data and complex feature space, traditional feature selection methods lose important feature information, especially in the context of active learning. It is especially critical to select the most informative features to improve model performance.
Graph Convolutional Networks (GCNs) are a specialized class of deep learning models designed for processing graph-structured data. They extend the capabilities of traditional Convolutional Neural Networks (CNNs) to enable direct feature learning and prediction on non-Euclidean spaces (e.g., graphs, social networks, molecular structures) [
16,
17,
18,
19,
20,
21,
22,
23]. The core concept revolves around local information aggregation to extract feature representations of nodes and their neighborhoods within the graph. In recent years, research on feature selection and active learning based on Graph Convolutional Networks (GCNs) has attracted lots of attention [
24,
25,
26,
27]. In 2016, Kipf and Welling first proposed a semi-supervised classification method based on GCNs [
12]. The method significantly improved the performance of the semi-supervised learning task by utilizing the relationship information between nodes in graph-structured data. In 2022, Zhang et al. proposed a graph convolutional network method based on node feature convolution [
15]. By introducing the node feature convolution mechanism in GCNs, the method captured more nonlinear relationships between node features, improving the modeling capability of graph-structured data. In 2023, Chen et al. proposed a graph convolutional network-based feature selection method specifically for processing high-dimensional low-data-volume data [
28]. The method selected the most representative subset of features through the graph structure information transfer mechanism of GCNs, improving the performance and the generalization ability of the model.
Federated Learning (FL) is a distributed machine learning framework that enables multiple clients, such as mobile devices and medical institutions, to collaboratively train a shared model using their local data without directly exchanging raw data [
29,
30,
31]. Its core principle lies in transmitting only model parameters (e.g., gradients) instead of the underlying data, thereby preserving data privacy. Meanwhile, a central server aggregates local updates from participating clients to construct a global model.
In federated learning, how to effectively select data for training local models poses a significant challenge. Furthermore, data leakage and misuse may occur during the processes of data transmission and aggregation [
29]. In addition to these privacy and security concerns, the decentralized nature of FL also makes it vulnerable to poisoning attacks. In model poisoning attacks, adversaries manipulate local model parameters and upload carefully crafted malicious updates to the server, aiming to compromise the integrity of the global model [
32,
33,
34,
35,
36,
37,
38,
39]. Such compromised participants are referred to as malicious users.
Based on the above problem analysis, our technical approach consists of three key modules:
First, the integration of active learning with Graph Convolutional Networks (GCNs) not only facilitates the selection of the most representative and informative samples for labeling, but also allows dynamic adjustment of the data selection strategy according to varying data distributions and task-specific characteristics during the learning process.
Second, homomorphic encryption techniques enable computations on encrypted data without requiring decryption, thereby providing strong guarantees for data security. This ensures that data remain encrypted throughout the entire lifecycle (including transmission, storage, and processing), effectively preventing data leakage and unauthorized use.
Third, a Key Generation Center (KGC) is employed to verify user-submitted updates and detect malicious users. The KGC has the capability to decrypt user ciphertexts. After the server performs model aggregation, the KGC uses the global model parameters to validate each client’s update, identifying and filtering out any potentially malicious contributions. Subsequently, the KGC uploads only the parameters from legitimate users back to the server for further aggregation. This mechanism ensures that the final global model does not incorporate any parameters from malicious users, thereby effectively defending against model poisoning attacks.
The main contributions of this paper are as below.
Firstly, this paper proposes a graph convolutional network model based on feature enhancement. By averaging the feature vectors output from multiple convolutional layers, the multi-level features of nodes can be better captured. The feature similarity between labeled and unlabeled data is utilized so that the unlabeled data that are more different from the labeled data can be selected to obtain more representative data.
Secondly, by applying the proposed GCNs as a substitute for the initial poor target model, this paper proposes an active learning model based on augmented GCNs, which is able to select more representative data, enabling the active learning model to achieve better classification performance with limited labeled data.
Thirdly, this paper proposes a homomorphic encryption-based federated active learning model to improve the data utilization and enhance the security of private data. In the federated active learning model, Client is employed as the proposed active learning based on augmented GCNs, to achieve privacy protection and improve the performance of the active learning model.
2. Preliminaries
2.1. Definition of the Problem
GCNs are deep learning models specialized in processing graph-structured data and incorporating active learning methods to select the most informative nodes for labeling. In GCNs, we let the graph contain nodes, denoted as , where denotes the set of nodes and denotes the set of edges. Each node i has a feature representation h_i, and these node features can be combined into a feature matrix , where , and denotes the feature dimension of each node. The graph structure can be represented by an adjacency matrix , , where denotes whether node to node is connected by an edge. The node representation of each layer is updated by aggregating the information of its neighboring nodes, denoted as , where denotes the node representation of the th layer, f denotes the aggregation function, and is the adjacency matrix. And in the first layer of GCNs, the input node feature matrix is usually directly used as the initial node representation matrix , i.e., . By stacking multiple layers, the node representations can be gradually updated for tasks such as node classification, graph classification, etc. The core idea of GCNs is to utilize the connectivity information between the nodes in the graph structure to enhance the capability of representation learning so that it can effectively handle graph data tasks.
In active learning, there is a collection of unlabeled nodes and a collection of labeled nodes , where the concatenation of and constitutes the entire collection of nodes, i.e., . The goal of active learning is to select the most informative nodes for labeling so as to maximize the model performance. In this process, the active learning algorithm selects the most valuable nodes for labeling based on the current model state and the information of the unlabeled nodes.
Combining GCNs and active learning, by training GCNs as samplers for active learning, it is possible to select the most informative nodes for labeling, thus improving the performance of the active learning model.
2.2. Graph Convolutional Network
Graph Convolutional Networks (GCNs) bridge the gap between graph-structured data and convolutional neural networks (CNNs) by adapting the powerful feature extraction capabilities of CNNs to non-Euclidean domains. Graph Convolutional Networks (GCNs) are a specialized class of deep learning models designed for processing graph-structured data.
denotes an undirected graph, and
represents the sets of edges that connect different nodes of set
. An adjacency matrix
describes the connectivity between nodes
in the graph. Typically,
is a sparse matrix, where
indicates whether there is an edge or connection between node i and node j. In GCNs, the adjacency matrix
is used to propagate the feature information of the nodes and realize the information interaction between nodes. In GCNs, the relationship between nodes is represented by the adjacency matrix of the graph, and the information propagation and feature extraction of the graph structure are achieved by updating the representation of the nodes by aggregating the information of their neighboring nodes. The feature matrix propagation in GCNs is shown in Equation (1):
is the node identity matrix of layer , is the symmetric adjacency matrix formed by adding the self-connections to the adjacency matrix , is the degree matrix of , is the weight matrix of layer , and is the activation function, where .
The propagation rule Equation (1) is derived from spectral graph theory [
12], where
ensures each node aggregates its own features.
symmetrically normalizes the adjacency matrix to avoid numerical instability and maintain scale-invariant features. The weight matrix
learns layer-specific transformations. This formulation approximates a first-order Chebyshev polynomial filter on the graph Laplacian, balancing local feature aggregation and computational efficiency.
GCNs achieve efficient processing of graph data by defining convolution operations on the nodes of the graph structure. In GCNs, each node exchanges information with its neighboring nodes and updates its own feature representation. Through multi-layered graph convolution operations, GCNs are able to utilize the connectivity between nodes to learn the node representations, thus enabling feature extraction and prediction on graph data.
2.3. Homomorphic Encryption
Homomorphic encryption is a cryptographic method that allows specific types of algebraic operations to be performed on ciphertext, producing an encrypted result that, when decrypted, matches the result of performing the same operations on the corresponding plaintext. In other words, this technology enables operations such as retrieval and comparison to be carried out directly on encrypted data, yielding correct results, without the need to decrypt the data throughout the entire processing process. A homomorphic encryption scheme consists of four probabilistic polynomial time algorithms: public key and key generation algorithm, encryption algorithm, decryption algorithm, and ciphertext evaluation algorithm.
KeyGen (): Input security parameter , output public key evk for ciphertext evaluation and secret key sk.
Enc (pk, m): Input public key pk and message m, output ciphertext c.
Dec (sk, c): Input ciphertext c and secret key sk, output message m.
Eval (evk, f, ): Input ciphertexts , public key evk for ciphertext evaluation and a function f, where f: . Input ciphertexts into function f using evk, output ciphertext .
2.4. Federated Learning
In federated learning, a central server aggregates locally computed models from clients to train a global model. There are n clients, and each client has its own dataset . The central server has initial model . After receiving the model from the server, client uses to compute the gradient, where and D is the cost function. Client computes the local model and sends it to the server. Then the server carries out aggregation to derive the global model as follows: . The iterative training process does not terminate until the model converges.
3. Our Methodology
3.1. Feature Enhancement-Based GCNs
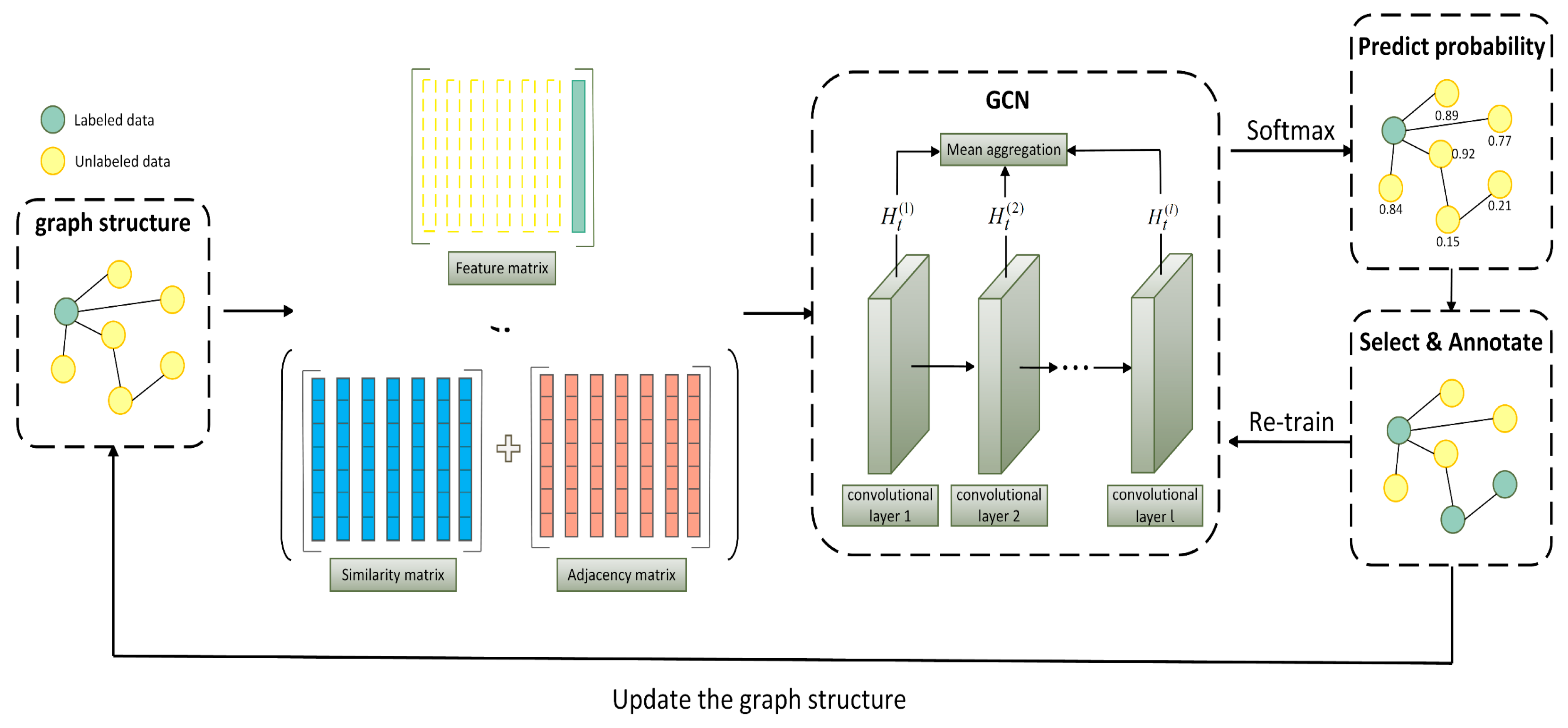
The original GCN merely learned the feature information of nodes through the feature matrix. This paper further incorporates the similarity matrix and adjacency matrix based on the feature matrix. The addition of these matrices can enhance the feature learning ability of GCN. Moreover, by using a multi-layer feature fusion method, the ability of GCN to extract features is further strengthened. In this section, we propose a feature enhancement-based graph convolutional network model, which acts as a sampler for data selection, making the selected data more representative. The feature enhancement in the proposed model works in three aspects. Firstly, by combining the feature similarity and adjacency matrix of labeled and unlabeled nodes, the unlabeled nodes with the least correlation with the labeled nodes are selected. Secondly, the representation of nodes is improved by aggregating the node feature information output from different convolutional layers and combining local and global information. Finally, the feature similarity between labeled and unlabeled data is utilized to enable the graph convolutional network to predict whether the input data are labeled or not, so that the unlabeled data which are more different compared to the labeled data can be selected to ensure that the selected data are more representative. The graph convolutional network model based on feature enhancement is shown in
Figure 1.
3.1.1. Node Feature Similarity
In GCNs, the adjacency matrix describes the connectivity between nodes in the graph. Typically, is a sparse matrix, where indicates whether there is an edge or connection between node i and node j. In GCNs, the adjacency matrix is used to propagate the feature information of the nodes and realize the information interaction between nodes.
Node features are vectors describing the attributes or characteristics of a node in a graph, which are usually used to represent information on various attributes of a node in the graph. Node feature vectors can provide more key information about the nodes themselves, which can help distinguish the feature differences between different nodes and help the model learn the relationships between nodes in the graph data.
Although the adjacency matrix can reflect the connection relationship between nodes, when calculating node correlation, not only the adjacency matrix is needed, but also the similarity of node features. The node feature vector reflects the attribute information of the nodes, which can help distinguish the feature differences between different nodes, while the adjacency matrix describes the connectivity relationship between nodes, which can reveal the topology between nodes.
Traditional GCNs rely solely on the adjacency matrix A to propagate node information, which may fail to capture latent relationships between semantically similar but topologically distant nodes. To address this, we introduce a feature similarity matrix S computed via cosine similarity (Equation (2)), as the cosine metric is robust to high-dimensional sparse features. The combined correlation matrix C = αA + βS leverages both topological connectivity and feature semantics. Our ablation study shows that combining A and S improves accuracy by 5.3% compared to using A alone, validating the necessity of the similarity matrix.
We assume that the feature matrix of labeled nodes is
and the feature matrix of unlabeled nodes is
, where
is the number of labeled nodes,
is the number of unlabeled nodes, and
is the dimensionality of the feature vectors.
can be computed by cosine similarity as shown in Equation (2):
where
denotes the feature vector of labeled node
i and
denotes the feature vector of unlabeled node
j. By cosine similarity calculation, we can get a similarity value ranging between [−1, 1], where 1 means completely similar and −1 means not similar at all. The feature similarity matrix
is shown in Equation (3):
The adjacency matrix
represents the adjacency between nodes,
, where
is the total number of nodes. The correlation calculation is shown in Equation (4):
where
and
are weight parameters to balance the effects of feature similarity and adjacency in the correlation calculation.
is the feature similarity term, which represents the similarity between the feature vector
of the labeled node i and the feature vector
of the unlabeled node j.
is the adjacency term, which represents the adjacency relationship between the labeled node
and the unlabeled node
. The graph convolutional network feature matrix propagation in this paper’s method is conducted as shown in Equation (1):
The feature matrix is computed through layer-wise propagation, where the adjacency matrix is normalized by to avoid numerical instability. The weight matrix is initialized using Xavier initialization, and ReLU is chosen as the activation function due to its effectiveness in mitigating vanishing issues in deep GNNs.
By combining feature similarity and adjacency, the degree of association between labeled and unlabeled nodes is determined through correlation, which in turn, selects the unlabeled nodes that are least relevant to the labeled nodes. This approach mines potential relationships between nodes in the graph and helps to select the unlabeled nodes that have the greatest feature differences from the labeled nodes.
3.1.2. Multi-Layer Feature Fusion
In GCNs, the aggregation of node features is a key process that aims to integrate a node’s own features and the features of its neighboring nodes in order to update the node’s representation. By continuously aggregating information from neighboring nodes, the representation of a node gradually incorporates more information about its surrounding structure and context, thus improving the node feature representation. Nodes throughout the graph go through this aggregation process, allowing each node’s representation to learn global structural information.
In the traditional node feature aggregation process, after multiple information transfers, the node will learn more information about its neighboring nodes, resulting in the loss of key feature information about the node itself. In this paper, we propose a multi-layer feature fusion approach to improve the representation of nodes by aggregating the node feature information output from different convolutional layers and combining local and global information. The feature vector of node
in the
th round and
th layer is calculated as shown in Equation (5):
where
denotes the eigenvector of node
at round
, layer l.
and
denote the eigenvector of node
, node
at round
, and layer
.
is the weight matrix at round
, and layer
.
is the set of neighbors of node
.
denotes the correlation between node
and node
.
is the activation function. The process of multi-layer feature fusion is shown in Equation (6):
where
is the feature vector of node i in the tth round,
is the feature vector of node
in the
th round and
th convolutional layer, and
denotes the number of convolutional layers. When all the
(
i = 1, 2, …,
n) are obtained, the feature matrix after the average aggregation at round
can be obtained. The feature matrix after the average aggregation at round
is shown in Equation (7):
By averaging the feature vectors of nodes at different convolutional layers, the feature information learned by each node at different convolutional layers is actually being aggregated. This operation enables the model to synthesize multi-layered feature representations from different convolutional layers, combining local and global information and improving the performance of the model for node feature extraction.
The advantage of the multi-layer feature fusion approach is that by combining the feature information learned from different convolutional layers, the model is able to better capture the complex relationships and structural features of the graph data. By integrating local and global information, the multi-layer feature fusion approach can enhance the model’s ability to model node features, thereby improving the model’s performance in the node classification task.
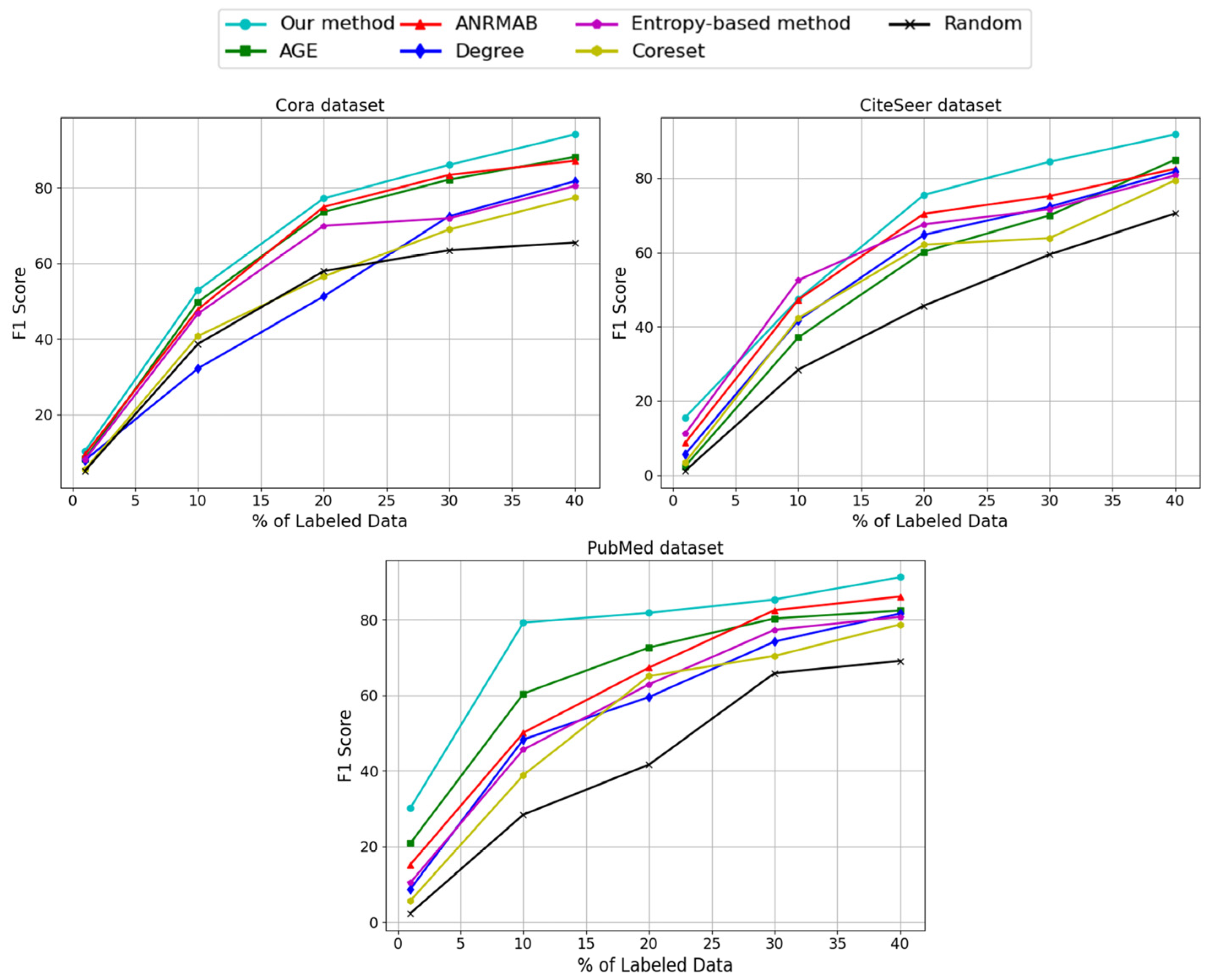
3.2. Active Learning Based on Augmented GCNs
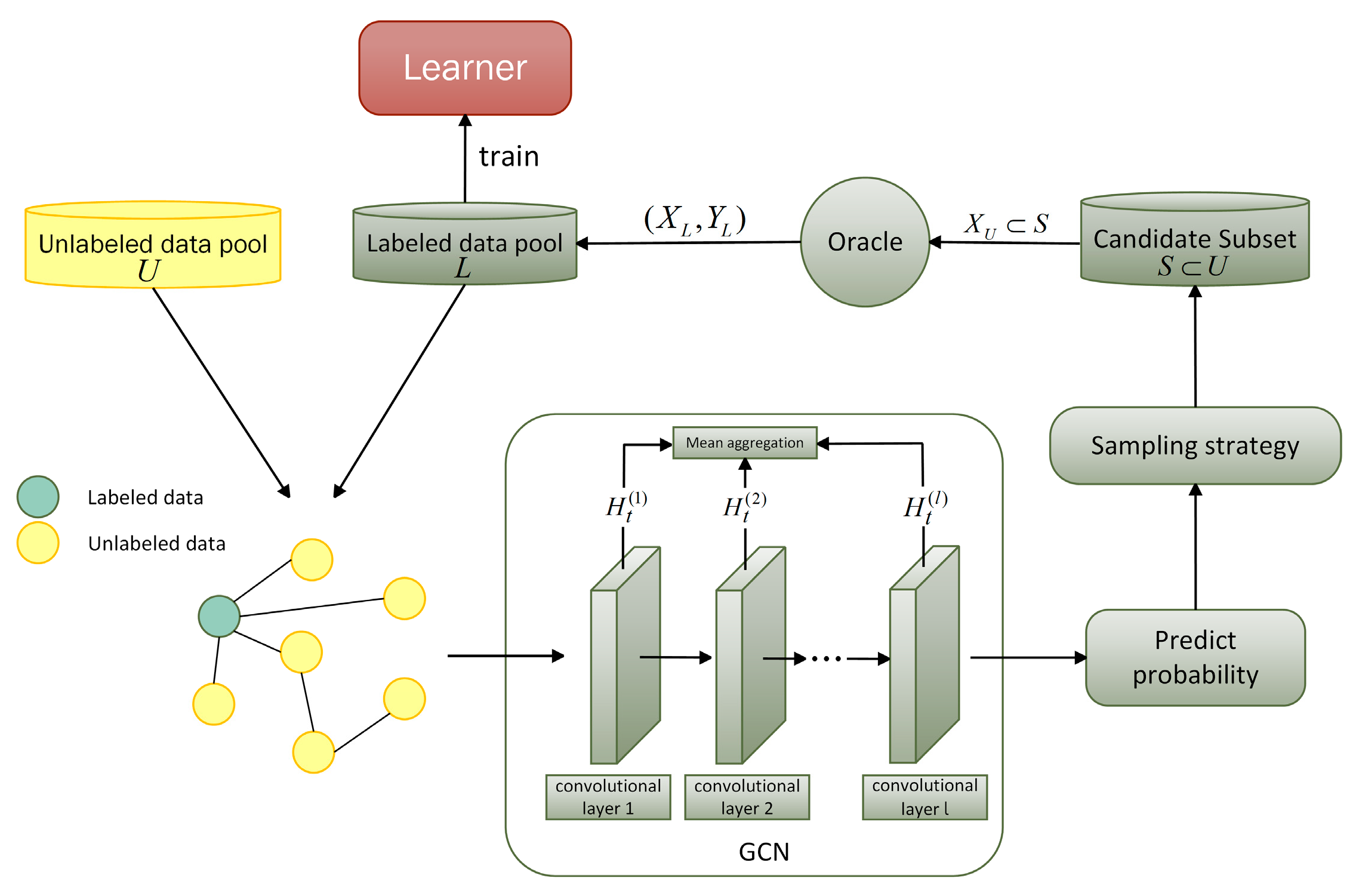
The feature-enhanced graph convolutional network model based on features, instead of the target model, acts as a sampler for data selection, and the active learning can select representative nodes more efficiently, which makes the model pay more attention to those nodes that have an important impact on model parameter updating during the training process, and thus improves the performance of the model. By predicting the nodes based on their feature similarity, representative nodes can be better selected and the efficiency of node selection can be improved. Then, the active learning model is trained based on the graph-structured data selected by this augmented graph convolutional network model, and the active learning model based on an augmented graph convolutional network is proposed, which achieves the maximization of the classification performance of the active learning model on graph-structured data with less labeled data. The active learning model based on an augmented graph convolutional network is shown in
Figure 2.
The node classification objective function is shown in Equation (8):
where
and
are the real labels of node
and node
,
is the set of labeled nodes,
is the set of unlabeled nodes, and
and
are the prediction results of whether node
and node
are labeled or not. The node feature objective function is shown in Equation (9):
where
is the aggregated feature vector of labeled node
, and
is the aggregated feature vector of unlabeled node
. By combining Equations (8) and (9), the complete objective function for training the graph convolutional network model can be obtained as shown in Equation (10):
where
and
are hyperparameters that determine whether the graph convolutional network effectively distinguishes between nodes with and without labels.
In this approach, the classification layer of the graph convolutional network is binary, where nodes with features similar to those of the labeled data are likely to be predicted as labeled nodes, while the opposite case will be predicted as unlabeled nodes. The cost of labeling nodes is reduced by selecting nodes that need to be manually labeled through the confidence level of the graph convolutional network model on the nodes. Based on the predicted probability to determine whether a node has labeled data or not, the nodes with the smallest probability value of being predicted as unlabeled nodes are selected to be manually labeled and the labeled nodes are added to the set of labeled nodes .
For the classification task, the active learning model is trained using the set of labeled nodes
. The loss function is shown in Equation (11):
where
is the number of samples in the training set;
is the number of categories;
denotes the parameters of the active learning model;
is the true label value of the
th category of the
th node; and
is the prediction probability of the model for the
th category of the
th sample. By minimizing the cross-entropy loss function, the prediction result of the active learning model can be made as close as possible to the true label, thus improving the classification accuracy of the active learning model.
3.3. Homomorphic Encryption Algorithm Based on Identity Authentication
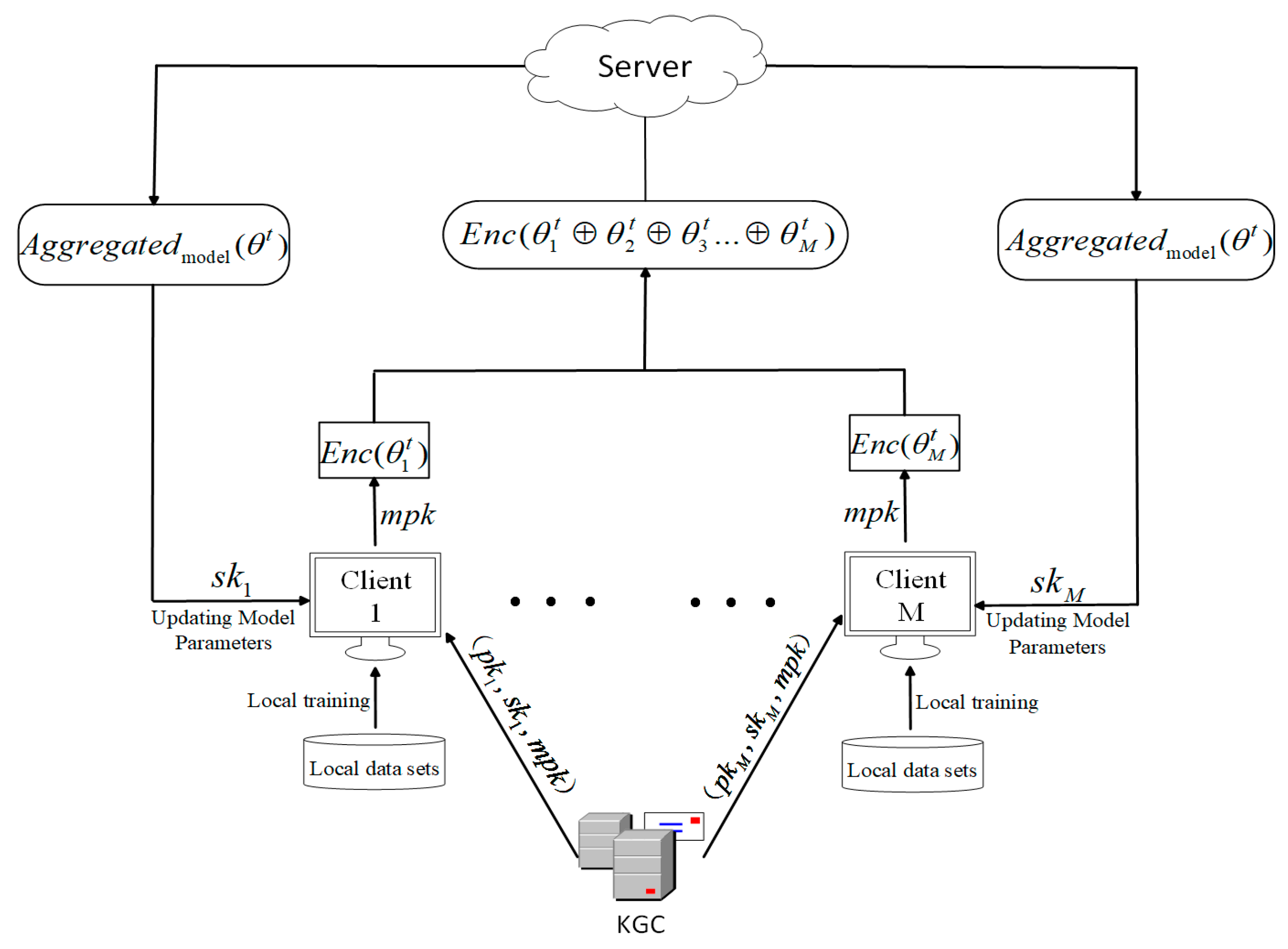
To protect the client’s private data from leakage, we introduce homomorphic encryption to resist against model poisoning attacks in federated learning. The legitimacy of the client needs to be verified. In this paper, we propose a homomorphic encryption algorithm based on authentication using the Paillier algorithm. The algorithm can verify the functionality of client legitimacy, while KGC is a trusted third party. Identity authentication acts to verify whether participants in federated learning are legitimate users or malicious adversaries. By calculating the mean, median and standard deviation of the first-round gradient data, abnormal data can be identified, and then the source of malicious users can be identified. The identified malicious users will be isolated in the following submitting stages, achieving the purpose of identity authentication. Eventually, a homomorphic encryption algorithm based on identity authentication is implemented. In the proposed homomorphic encryption algorithm, only data from honest users are aggregated and decrypted, which ensures the isolating of malicious data, preserving the client’s private data from leakage. The proposed homomorphic encryption scheme consists of five core algorithms: Key Generation, Encryption, Verification, Aggregation, and Decryption. The homomorphic encryption algorithm based on authentication is shown in
Figure 3. The detailed homomorphic encryption algorithm is as follows.
Key generation: KGC selects two large prime numbers and and calculates ; then it calculates , where denotes the least common multiple; it then randomly selects an integer , , and calculates , where . The master key pair for generating the KGC can be represented as follows: master public key , master private key . For each client , a large integer is randomly generated and ensures that is mutually prime with . The client public key is obtained by performing a computation on the client private key (. The key pair for each client can be expressed as follows: private key , public key .
Encryption: Each client uses the master public key to encrypt its locally trained model parameters to obtain the ciphertext model parameter . The encryption process can be expressed as follows: , where is a random number.
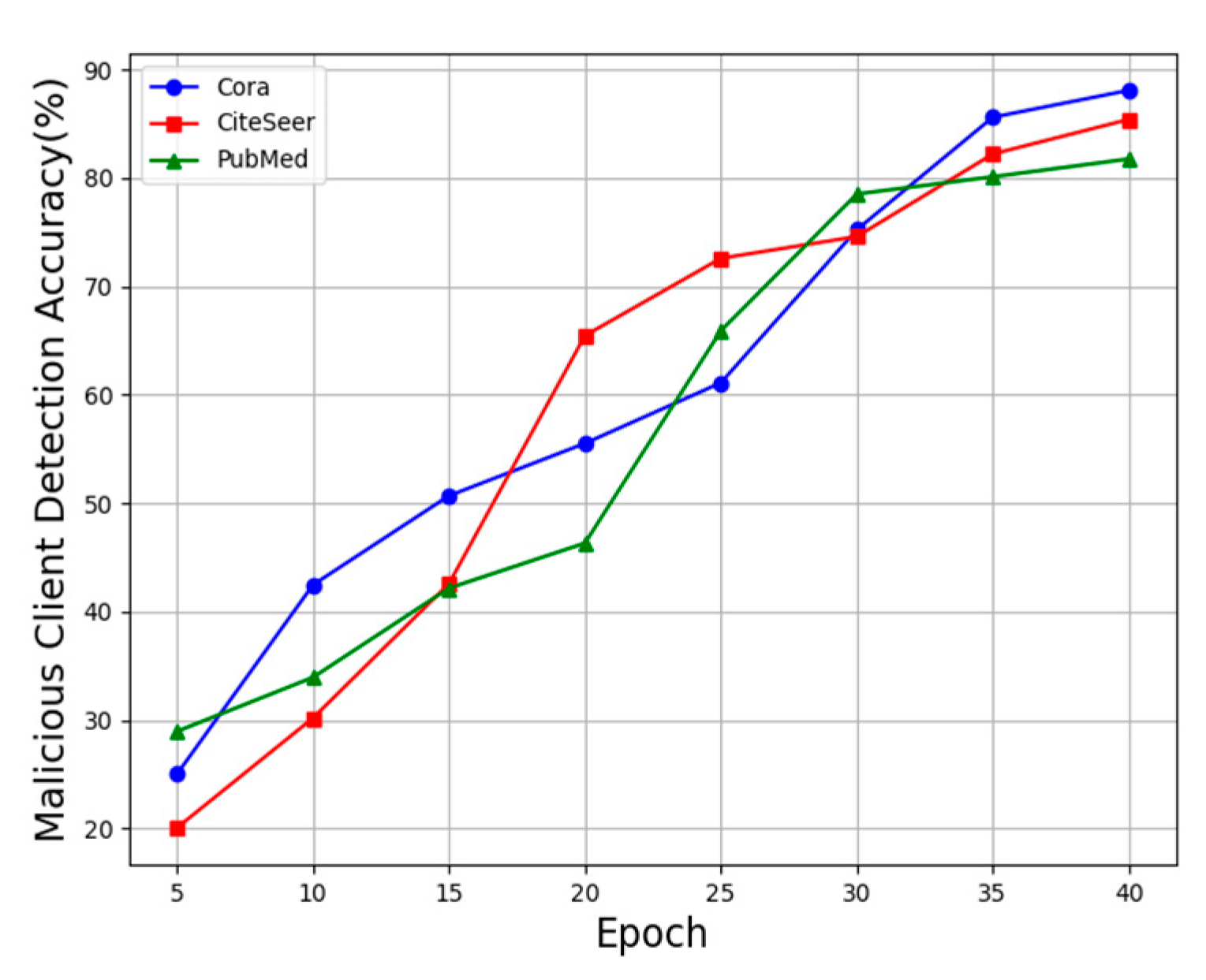
Verification: KGC uploads the first round of received directly to the server, which obtains the encrypted global model parameter by the homomorphic encryption algorithm and sends it down to KGC. KGC decrypts the global model parameter of the first round by using the master private key , and the decryption process can be expressed as follows: . KGC decrypts using the master private key to obtain the model parameter for each client, and the decryption process can be expressed as follows: . It then calculates the cosine similarity of the model parameters to the global model parameters for all clients. The mean (), median () and standard deviation () of the cosine similarity of all legitimate clients are then calculated. If , the cosine similarity value will be lower than for most potentially illegitimate clients. If , client is illegitimate, and is a hyper-parameter.
Aggregation: Starting from the second iteration loop, KGC removes the model parameters uploaded by illegitimate clients and uploads the remaining ciphertext model parameters to the server, which performs aggregation by homomorphic encryption and sends the aggregated ciphertext global model parameters to KGC.
Decryption: The KGC decrypts using the master private key to obtain the global model parameters. Then it encrypts and sends it down using the legitimate client’s public key , and client decrypts it using its own private key to obtain the plaintext global model parameters to update the local model.
3.4. Homomorphic Encryption-Based Federated Active Learning
Federated learning allows multiple participants to train models at the same time, which solves the problem of data sharing but also carries the risk of privacy breaches. Homomorphic encryption allows computations to be performed on encrypted data without the need to decrypt the data. This means that in federated learning, participants can share encrypted data or model parameters without exposing the original data, thus realizing privacy protection. Combining homomorphic encryption algorithms with federated learning can further enhance data privacy and security.
In this section, active learning privacy protection is realized for graph-structured data, and a federated active learning system based on homomorphic encryption is proposed by designing a homomorphic encryption algorithm based on authentication, as shown in
Figure 4. When handling graph-structured data, the system employs an active learning model based on augmented graph convolutional networks to enhance training efficiency and model performance while ensuring data privacy.
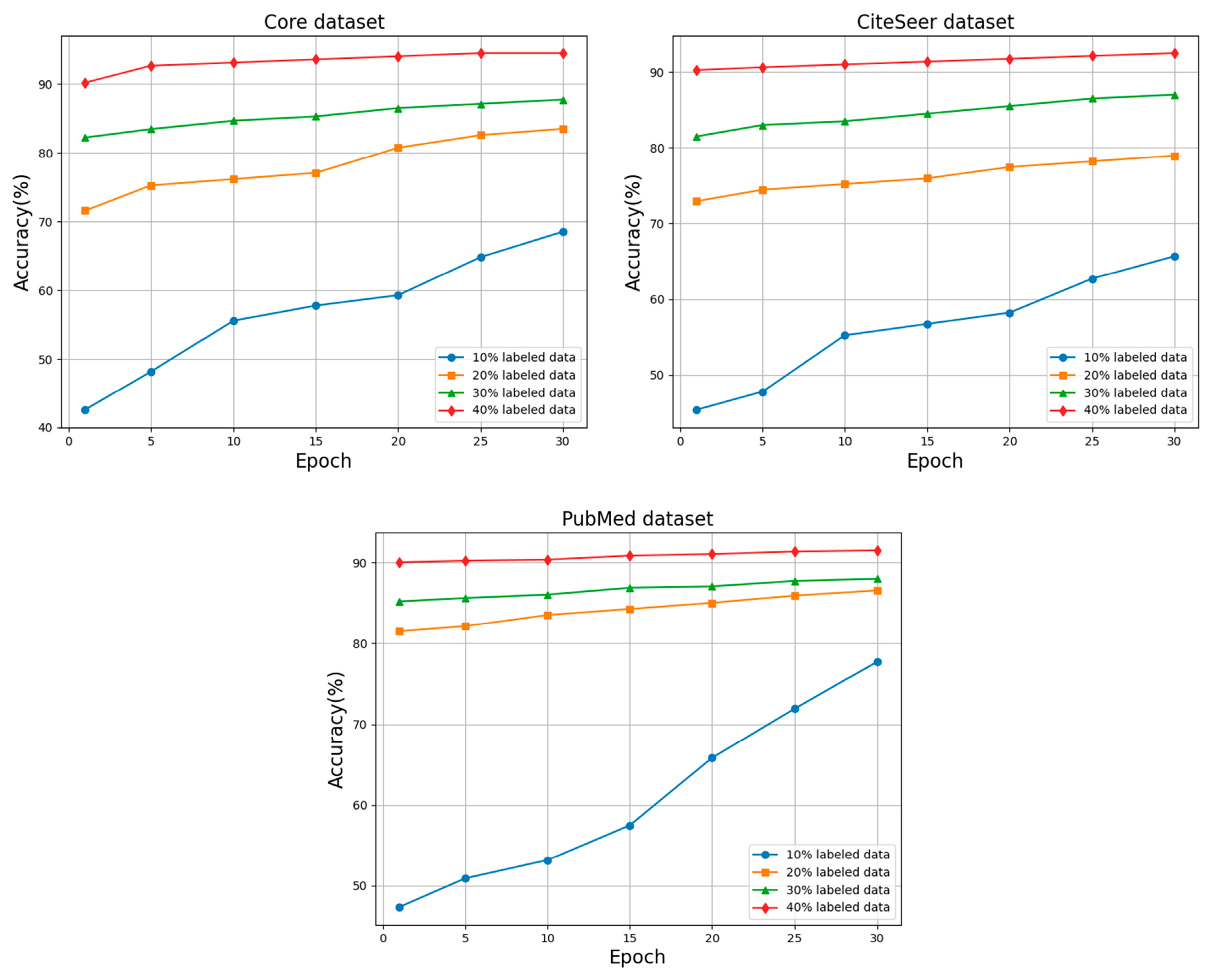
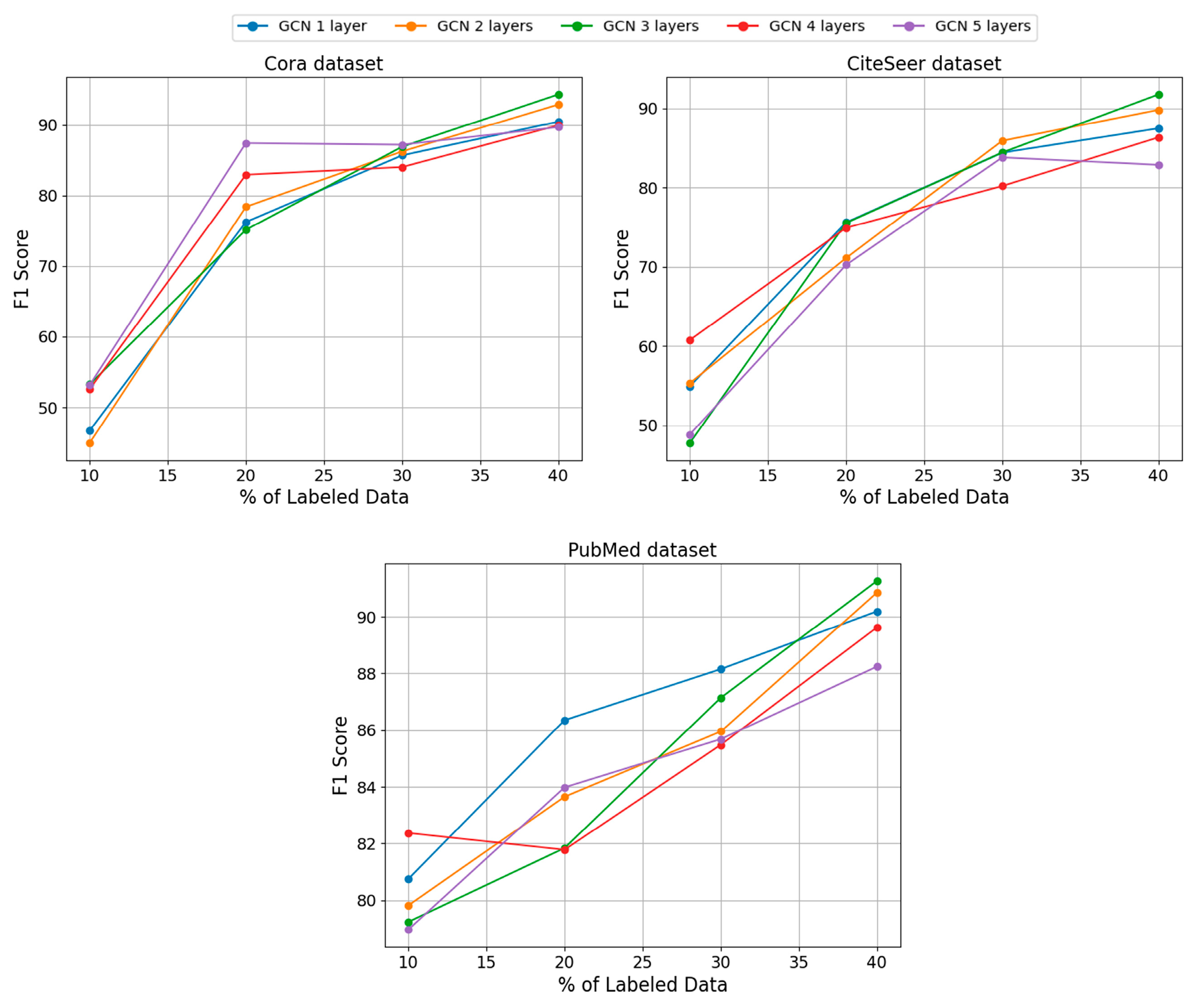
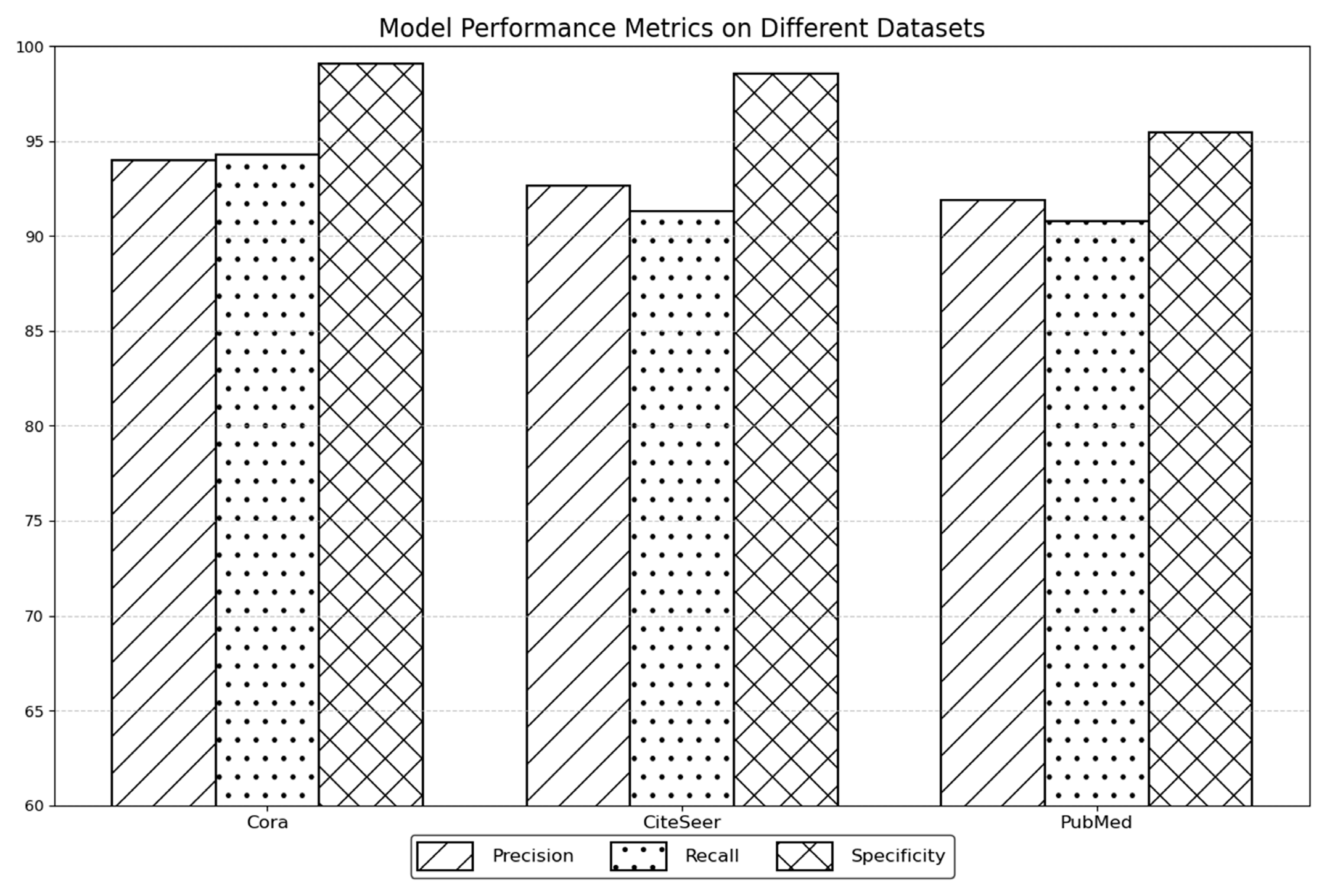
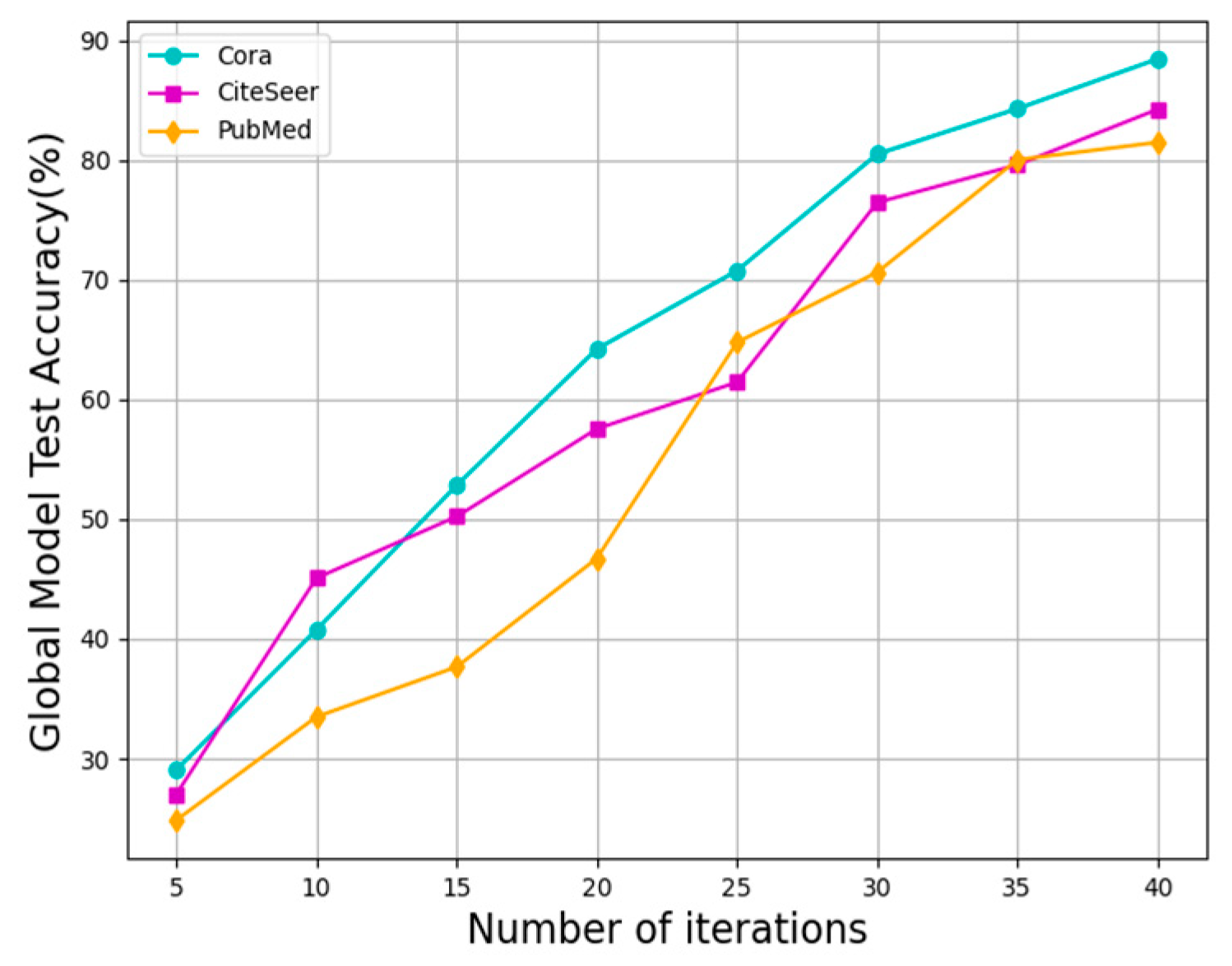
Specifically, for the graph-structured data, federated active learning is implemented on datasets, Cora, CiteSeer, and PubMed, respectively. The specific process includes the active learning training phase, encryption phase, authentication phase, federation aggregation phase, and decryption phase.
Active Learning Training Phase: There are clients, and each client trains an active learning model by a feature-enhanced graph convolutional network using the structural dataset of this graph-structured data to obtain the local model parameters .
Encryption phase: client encrypts the local model parameters of the t th round of their respective training using the master public key to obtain , respectively, and uploads the encrypted local model parameters to KGC.
Authentication phase: The KGC verifies the legitimacy of client according to the homomorphic encryption algorithm based on authentication and uploads the cipher model parameters of the legitimate client to the server.
Federated Aggregation Phase: The server takes the cipher model parameters uploaded by KGC received in the
th round and aggregates them against the cipher model parameters of legitimate client
.
Decryption phase: The server sends the aggregated encrypted model parameters to KGC, which decrypts the global model parameter using the master private key . KGC encrypts the encrypted global model parameters using the public key of the legitimate client and sends it to the legitimate client , which decrypts the encrypted global model parameters using the private key and obtains the global model parameters in plaintext.
Active Learning Model Parameter Update Phase: Legitimate clients use the decrypted global model parameters to update the local model parameters and improve the local active learning model performance.
Since client data are encrypted using the homomorphic algorithm during the federated learning process, the ciphertext remains encrypted both during transmission and while stored on the server. This prevents the leakage of information related to gradients. Before the ciphertext is submitted to the server for computation, the key generation center performs authentication, which can identify non-compliant data and malicious users. As a result, this mechanism effectively defends against poisoning attacks.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}