
WIGformer: Wavelet-Based Illumination-Guided Transformer

Abstract
1. Introduction
- Based on the transformer architecture and Retinex theory, we proposed the Wavelet-based Illumination-Guided Transformer (WIGformer) algorithm for low-light image enhancement.
- We propose a wavelet illumination estimator and design the WFEConv module to effectively capture the multi-scale features in the image by using the multi-scale characteristics of the Wavelet Transform (WT) to enhance the accuracy and detail of illumination estimation.
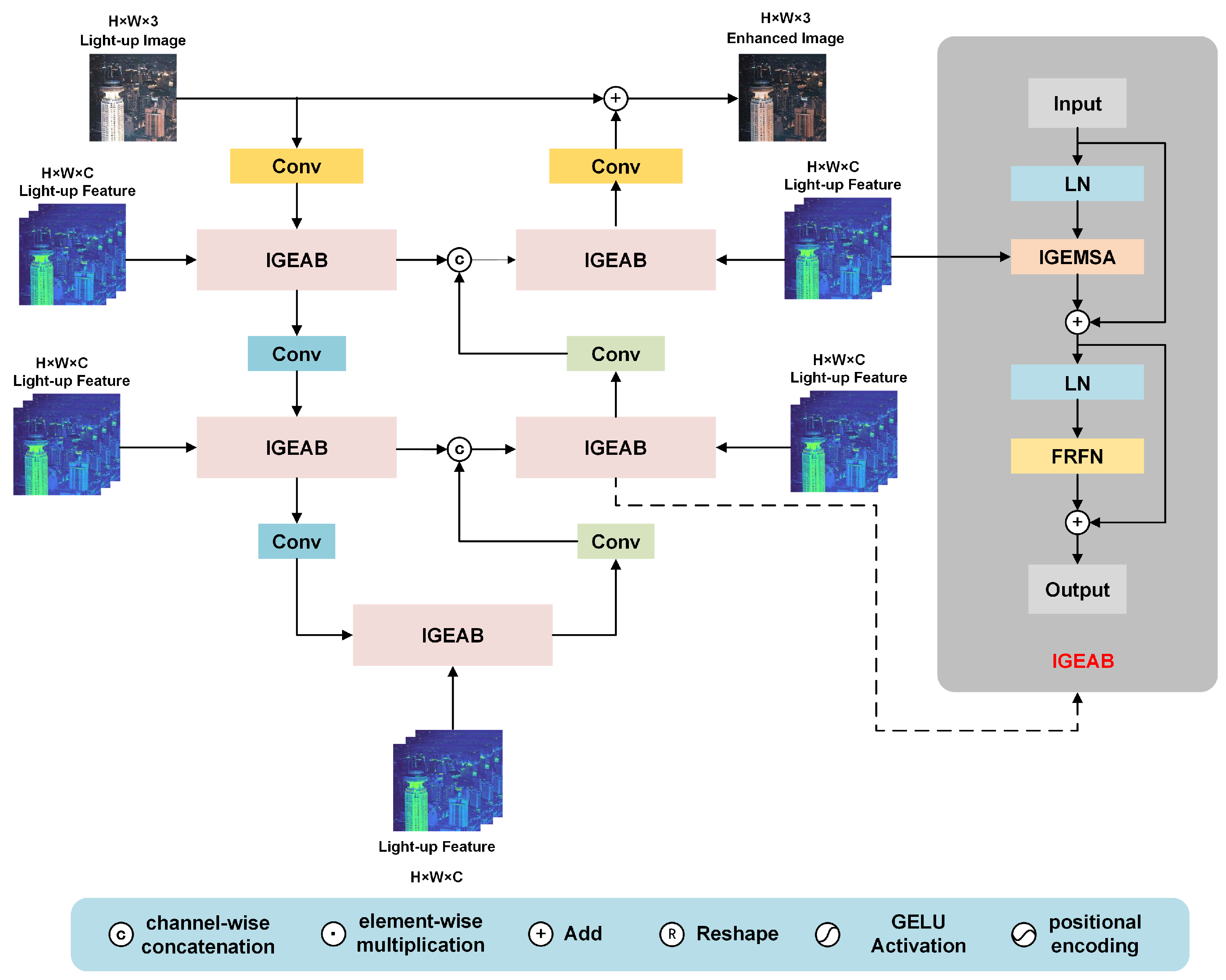
- We proposed an illumination feature-guided corruption restorer that adopts a three-scale U-shaped [28] structure, and design the Illumination-Guided enhanced Attention Block (IGEAB) for feature enhancement to correct low-light image noise, artifacts, color distortion, and other problems.
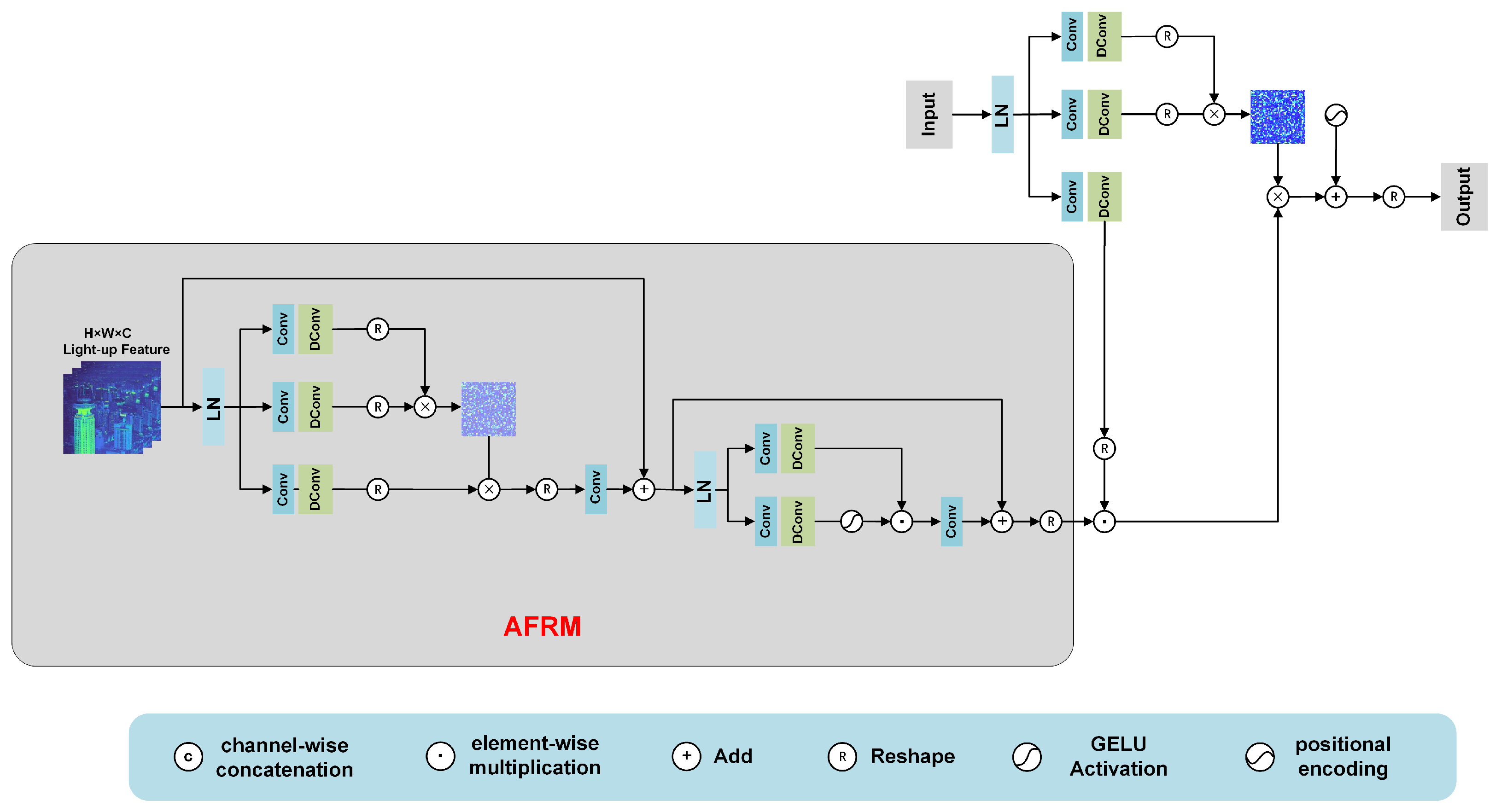
- We design a new self-attention mechanism called IGEMSA, which uses the AFRM module to better capture the complex structure and texture information of illumination features. This information is used to improve the performance of damage repair and correction and as key clues that guide the proposed long-range dependency modeling method.
2. Related Work
2.1. Traditional Methods for Low-Light Image Enhancement
2.1.1. Distribution Mapping Methods
2.1.2. Retinex-Based Methods
2.2. Deep Learning-Based Methods for Low-Light Enhancement
2.3. Wavelet Transforms in Deep Learning
3. Method
3.1. Retinex-Based Framework
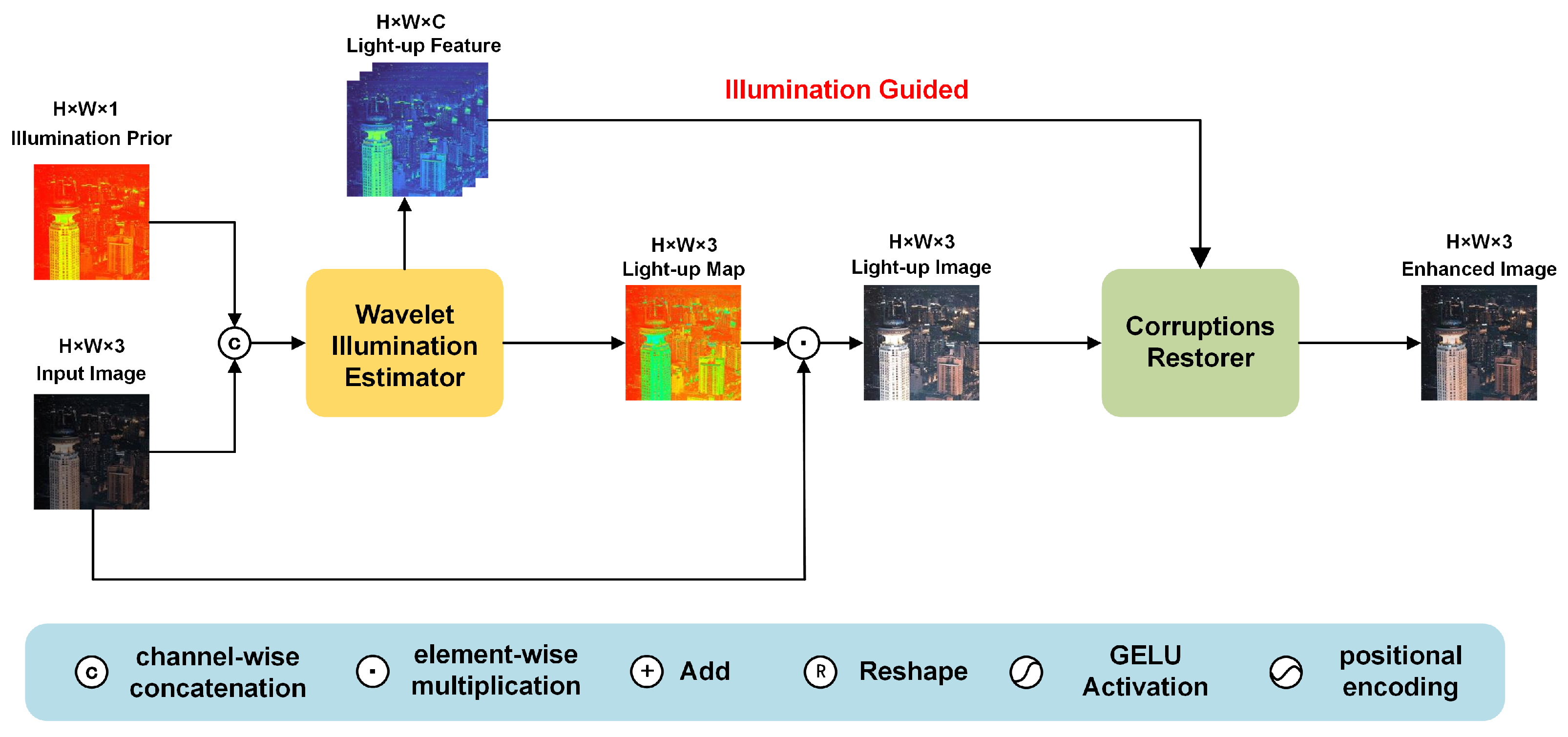
3.2. Overall Framework of WIGformer
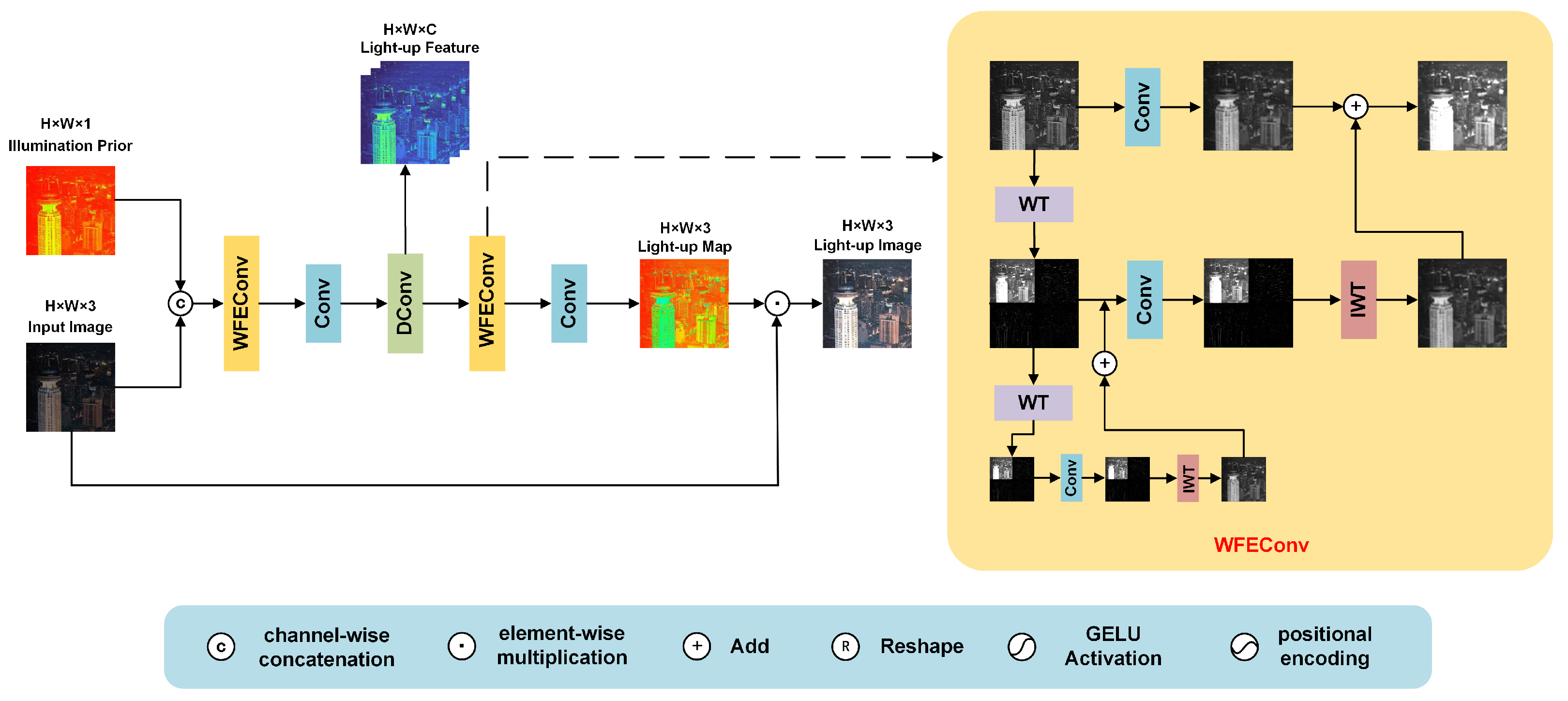
3.2.1. Wavelet Illumination Estimator
3.2.2. Illumination Feature-Guided Corruption Restorer
3.3. Core Modules of WIGformer
3.3.1. Wavelet Feature Enhancement Convolution (WFEConv)
| Algorithm 1 WFEConv |
Input: for
do end for for
do end for return
|
3.3.2. Illumination-Guided Enhanced Multihead Self-Attention (IGEMSA)
4. Experiments and Results Analysis
4.1. Dataset Description
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Low-Light Image Enhancement
4.4.1. Quantitative Analysis
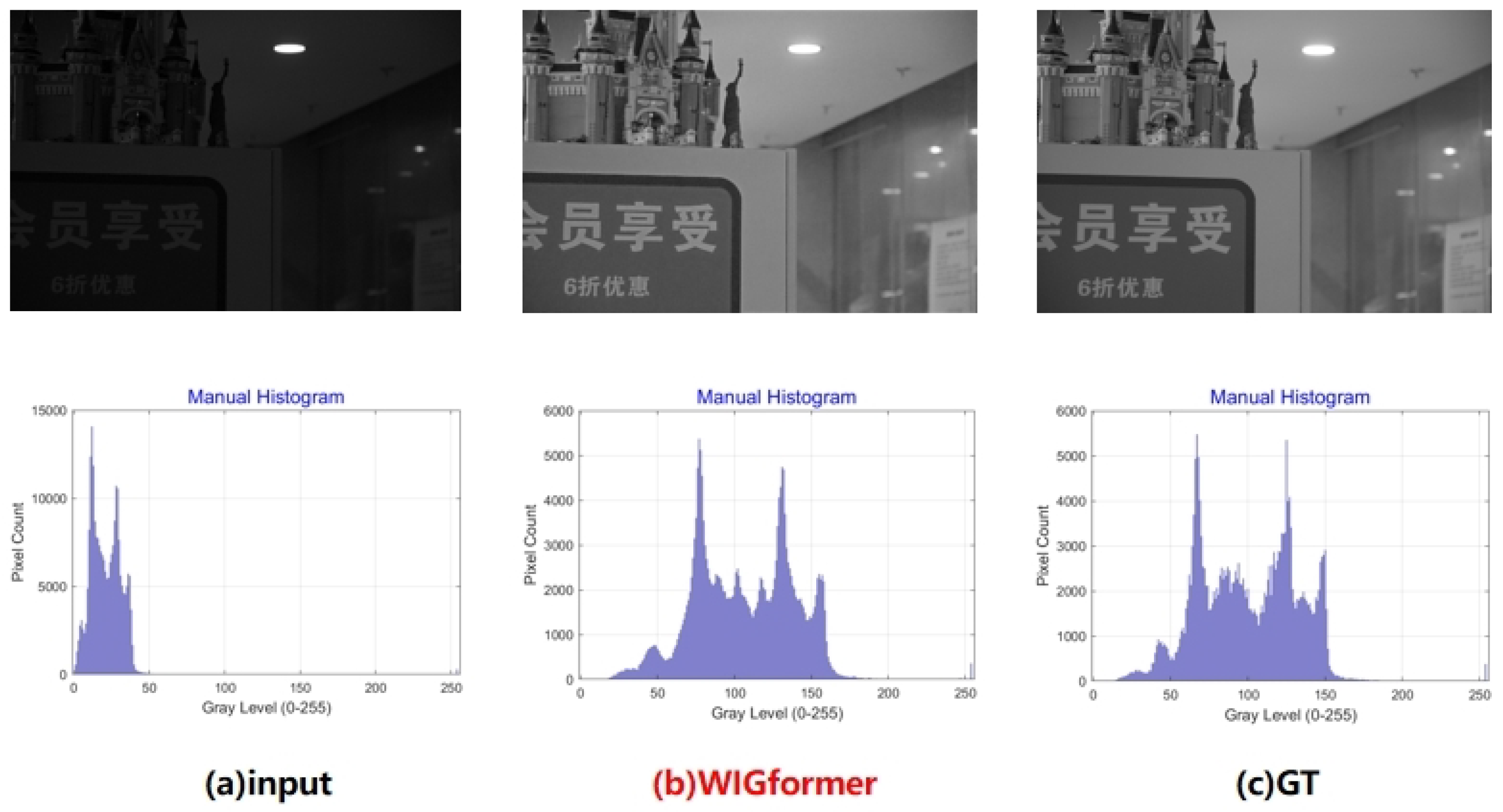
4.4.2. Qualitative Results
4.5. Ablation Study
4.6. Discussion
4.6.1. Discussion of Numerical Degradation
4.6.2. Discussion of Database Image Encoding
4.6.3. Discussion of the Impact of Pixel Quantization
4.6.4. Handling Non-Additive Noise in WIGformer
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ibrahim, H.; Kong, N.S.P. Brightness Preserving Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Celik, T.; Tjahjadi, T. Contextual and variational contrast enhancement. IEEE Trans. Image Process. 2011, 20, 3431–3441. [Google Scholar] [CrossRef]
- Cheng, H.D.; Shi, X. A simple and effective histogram equalization approach to image enhancement. Digit. Signal Process. 2004, 14, 158–170. [Google Scholar] [CrossRef]
- Huang, S.C.; Cheng, F.C.; Chiu, Y.S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef]
- Wang, Z.G.; Liang, Z.H.; Liu, C.L. A real-time image processor with combining dynamic contrast ratio enhancement and inverse gamma correction for PDP. Displays 2009, 30, 133–139. [Google Scholar] [CrossRef]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.u.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.u.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Rahman, Z.u.; Jobson, D.J.; Woodell, G.A. Retinex processing for automatic image enhancement. J. Electron. Imaging 2004, 13, 100–110. [Google Scholar]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2782–2790. [Google Scholar]
- Fu, X.; Zeng, D.; Huang, Y.; Liao, Y.; Ding, X.; Paisley, J. A fusion-based enhancing method for weakly illuminated images. Signal Process. 2016, 129, 82–96. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-light image/video enhancement using cnns. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; Northumbria University; Volume 220, p. 4. [Google Scholar]
- Wang, R.; Zhang, Q.; Fu, C.W.; Shen, X.; Zheng, W.S.; Jia, J. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6849–6857. [Google Scholar]
- Moran, S.; Marza, P.; McDonagh, S.; Parisot, S.; Slabaugh, G. Deeplpf: Deep local parametric filters for image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12826–12835. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 492–511. [Google Scholar]
- Xu, X.; Wang, R.; Fu, C.W.; Jia, J. Snr-aware low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17714–17724. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, Z.; Jiang, Y.; Jiang, J.; Wang, X.; Luo, P.; Gu, J. Star: A structure-aware lightweight transformer for real-time image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4106–4115. [Google Scholar]
- Cai, Y.; Bian, H.; Lin, J.; Wang, H.; Timofte, R.; Zhang, Y. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 12504–12513. [Google Scholar]
- Zhang, X.; Zhao, Y.; Gu, C.; Lu, C.; Zhu, S. Spa-former: An effective and lightweight transformer for image shadow removal. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Daubechies, I. Ten Lectures on Wavelets; SIAM: Philadelphia, PA, USA, 1992. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Wang, T.; Lu, C.; Sun, Y.; Yang, M.; Liu, C.; Ou, C. Automatic ECG classification using continuous wavelet transform and convolutional neural network. Entropy 2021, 23, 119. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1689–1697. [Google Scholar]
- Guo, T.; Seyed Mousavi, H.; Huu Vu, T.; Monga, V. Deep wavelet prediction for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 104–113. [Google Scholar]
- Duan, Y.; Liu, F.; Jiao, L.; Zhao, P.; Zhang, L. SAR image segmentation based on convolutional-wavelet neural network and Markov random field. Pattern Recognit. 2017, 64, 255–267. [Google Scholar] [CrossRef]
- Williams, T.; Li, R. Wavelet pooling for convolutional neural networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gal, R.; Hochberg, D.C.; Bermano, A.; Cohen-Or, D. Swagan: A style-based wavelet-driven generative model. ACM Trans. Graph. (TOG) 2021, 40, 1–11. [Google Scholar] [CrossRef]
- Guth, F.; Coste, S.; De Bortoli, V.; Mallat, S. Wavelet score-based generative modeling. Adv. Neural Inf. Process. Syst. 2022, 35, 478–491. [Google Scholar]
- Phung, H.; Dao, Q.; Tran, A. Wavelet diffusion models are fast and scalable image generators. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10199–10208. [Google Scholar]
- Finder, S.E.; Zohav, Y.; Ashkenazi, M.; Treister, E. Wavelet feature maps compression for image-to-image CNNs. Adv. Neural Inf. Process. Syst. 2022, 35, 20592–20606. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet convolutions for large receptive fields. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 363–380. [Google Scholar]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef]
- Liu, X.; Wu, Z.; Li, A.; Vasluianu, F.A.; Zhang, Y.; Gu, S.; Zhang, L.; Zhu, C.; Timofte, R.; Jin, Z.; et al. NTIRE 2024 challenge on low light image enhancement: Methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6571–6594. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Dong, X.; Pang, Y.; Wen, J. Fast efficient algorithm for enhancement of low lighting video. In Proceedings of the ACM SIGGRApH 2010 Posters, Los Angeles, CA, USA, 26–30 July 2010; p. 1. [Google Scholar]
- Li, M.; Liu, J.; Yang, W.; Sun, X.; Guo, Z. Structure-revealing low-light image enhancement via robust retinex model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for fast image restoration and enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1934–1948. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Liu, X.; Ma, W.; Ma, X.; Wang, J. LAE-Net: A locally-adaptive embedding network for low-light image enhancement. Pattern Recognition 2023, 133, 109039. [Google Scholar] [CrossRef]
- Guo, X.; Hu, Q. Low-light image enhancement via breaking down the darkness. Int. J. Comput. Vis. 2023, 131, 48–66. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Yi, X.; Ma, J. CRetinex: A progressive color-shift aware Retinex model for low-light image enhancement. Int. J. Comput. Vis. 2024, 132, 3610–3632. [Google Scholar] [CrossRef]
- Khan, R.; Mehmood, A.; Shahid, F.; Zheng, Z.; Ibrahim, M.M. Lit me up: A reference free adaptive low light image enhancement for in-the-wild conditions. Pattern Recognit. 2024, 153, 110490. [Google Scholar] [CrossRef]
- Wen, Y.; Xu, P.; Li, Z.; ATO, W.X. An illumination-guided dual attention vision transformer for low-light image enhancement. Pattern Recognit. 2025, 158, 111033. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Category | Representative Methods | Principles | Advantages | Limitations |
|---|---|---|---|---|
| Traditional | Histogram equalization and gamma correction | Manipulate pixel value distribution | Simple to implement, can enhance contrast | Color distortion, artifacts under complex lighting |
| Traditional | Retinex-based | Decompose image into illumination and reflectance | Intuitive physical explanation | Sensitive to parameter selection, poor generalization |
| Deep Learning | CNN-based | Use convolutional layers for feature extraction | Strong local feature extraction | Cumbersome multi-stage training, limited in long-range dependencies |
| Deep Learning | Transformer-based | Use self-attention for global context modeling | Can capture long-range dependencies | High computational cost |
| Model Type | Methods | Year | Paper/Conference | LOL-V1 | LOL-V2-Real | LOL-V2-Synthetic | Complexity | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB)↑ | SSIM (%)↑ | PSNR (dB)↑ | SSIM (%)↑ | PSNR (dB)↑ | SSIM (%)↑ | GFLOPS | Params (M) | ||||
| Traditional | Dong [45] | 2011 | ICME | - | - | 17.26 | 0.371 | - | - | - | - |
| RRM [46] | 2018 | TIP | - | - | 17.33 | 0.514 | - | - | - | - | |
| Deep Learning | LLNet [47] | 2017 | PR | - | - | 17.56 | 0.548 | - | - | - | - |
| DeepUPE [15] | 2019 | CVPR | 14.38 | 0.446 | 13.27 | 0.452 | 15.08 | 0.623 | - | - | |
| KinD [48] | 2019 | MM | 19.66 | 0.820 | 18.06 | 0.825 | 17.41 | 0.806 | - | - | |
| KinD++ [19] | 2020 | ICJV | 21.30 | 0.823 | 19.08 | 0.817 | - | - | - | - | |
| Zero-DCE [49] | 2020 | CVPR | 14.86 | 0.562 | 18.06 | 0.580 | - | - | - | - | |
| EnlightGAN [50] | 2021 | TIP | 17.48 | 0.650 | 18.23 | 0.617 | 16.57 | 0.734 | 61.01 | 114.35 | |
| RUAS [51] | 2021 | CVPR | 18.23 | 0.720 | 18.37 | 0.723 | 16.55 | 0.652 | 0.83 | 0.003 | |
| MIRNet [52] | 2022 | TPAMI | 24.14 | 0.830 | 20.02 | 0.820 | 21.94 | 0.876 | 785 | 31.76 | |
| Uformer [26] | 2022 | CVPR | 16.36 | 0.771 | 18.82 | 0.771 | 19.66 | 0.871 | 12 | 5.29 | |
| Restormer [53] | 2022 | CVPR | 22.43 | 0.823 | 19.94 | 0.827 | 21.41 | 0.830 | 144.25 | 26.13 | |
| SNR-Net [18] | 2022 | CVPR | 24.61 | 0.842 | 21.48 | 0.849 | 24.14 | 0.928 | 26.35 | 4.01 | |
| SCI [54] | 2022 | CVPR | 14.78 | 0.525 | 17.30 | 0.540 | - | - | - | - | |
| Retinexformer [23] | 2023 | ICCV | 25.16 | 0.816 | 21.43 | 0.814 | 24.16 | 0.930 | 17.02 | 1.61 | |
| LAE-Net [55] | 2023 | PR | - | - | 18.30 | 0.639 | - | - | - | - | |
| Bread [56] | 2023 | IJCV | 22.92 | 0.836 | - | - | - | - | - | - | |
| Cretinae [57] | 2024 | IJCV | 19.99 | 0.839 | - | - | - | - | - | - | |
| U2E-Net [58] | 2024 | PR | 23.92 | 0.847 | - | - | - | - | - | - | |
| IGDFormer [59] | 2025 | PR | 24.11 | 0.821 | 22.53 | 0.823 | 25.33 | 0.937 | 9.68 | 3.55 | |
| WIGFormer | 2025 | - | 26.12 | 0.871 | 22.61 | 0.831 | 25.60 | 0.935 | 11.73 | 1.96 | |
| Methods | LOL-V1 | LOL-V2-Real | LOL-V2-Synthetic | |||
|---|---|---|---|---|---|---|
| PSNR (dB)↑ | SSIM (%)↑ | PSNR (dB)↑ | SSIM (%)↑ | PSNR (dB)↑ | SSIM (%)↑ | |
| NoWFEConv | 25.82 | 0.852 | 21.83 | 0.818 | 25.18 | 0.912 |
| NoAFRM | 25.86 | 0.856 | 22.13 | 0.823 | 25.51 | 0.928 |
| WIGformer | 26.12 | 0.871 | 22.61 | 0.831 | 25.60 | 0.935 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, W.; Yan, T.; Li, Z.; Ye, J. WIGformer: Wavelet-Based Illumination-Guided Transformer. Symmetry 2025, 17, 798. https://doi.org/10.3390/sym17050798
Cao W, Yan T, Li Z, Ye J. WIGformer: Wavelet-Based Illumination-Guided Transformer. Symmetry. 2025; 17(5):798. https://doi.org/10.3390/sym17050798
Chicago/Turabian StyleCao, Wensheng, Tianyu Yan, Zhile Li, and Jiongyao Ye. 2025. "WIGformer: Wavelet-Based Illumination-Guided Transformer" Symmetry 17, no. 5: 798. https://doi.org/10.3390/sym17050798
APA StyleCao, W., Yan, T., Li, Z., & Ye, J. (2025). WIGformer: Wavelet-Based Illumination-Guided Transformer. Symmetry, 17(5), 798. https://doi.org/10.3390/sym17050798