A Symmetric Dual-Drive Text Matching Model Based on Dynamically Gated Sparse Attention Feature Distillation with a Faithful Semantic Preservation Strategy


Abstract
1. Introduction
- Dynamic gated projection sparse attention: We innovatively proposed to outperform the limitations of static gating, fixed block size compression, and the lack of adaptive padding of NSA (native sparse attention) by learning gated weight fusion branching, linear projection compression of feature dimensions, and supporting adaptive padding.
- Feature distillation strategy: Based on dynamic gating sparse attention combined with gradient inversion, SoftMax, and the projection theorem, this strategy accurately captures weakly correlated features, removes noise, and extracts key features.
- Faithful semantic preservation: A new strategy is designed to introduce interval loss and cosine similarity to ensure that the key features are faithful to the original semantics and improve accuracy.
- The method proposed in this study seamlessly integrates pre-trained language models and has been validated on a wide range of datasets in both specialized and general domains.
2. Related Work
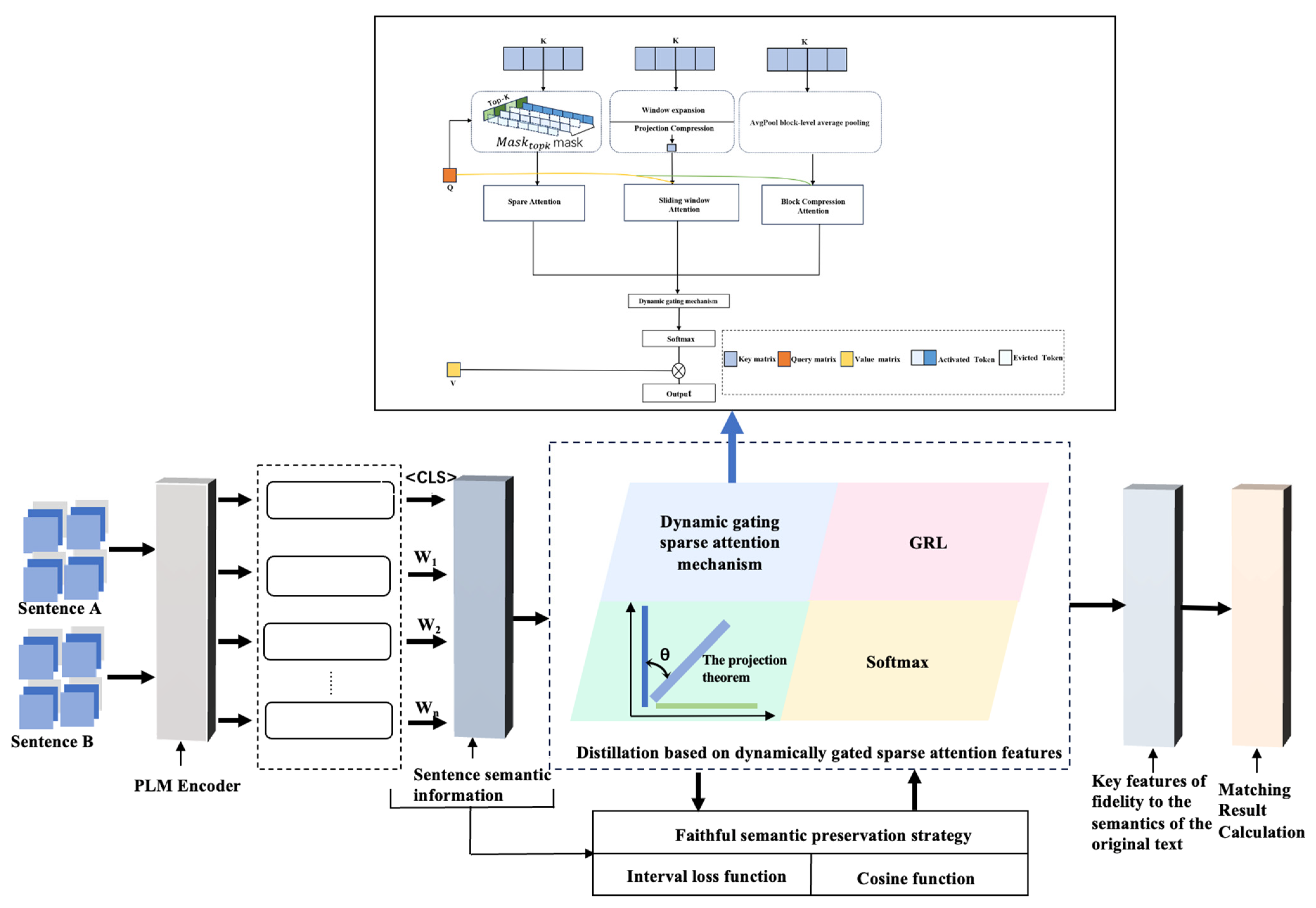
3. Design of Text Matching Model Based on Dynamically Gated Sparse Attention Feature Distillation with Faithful Semantic Preservation Strategy
3.1. Global Matching Using Key Features
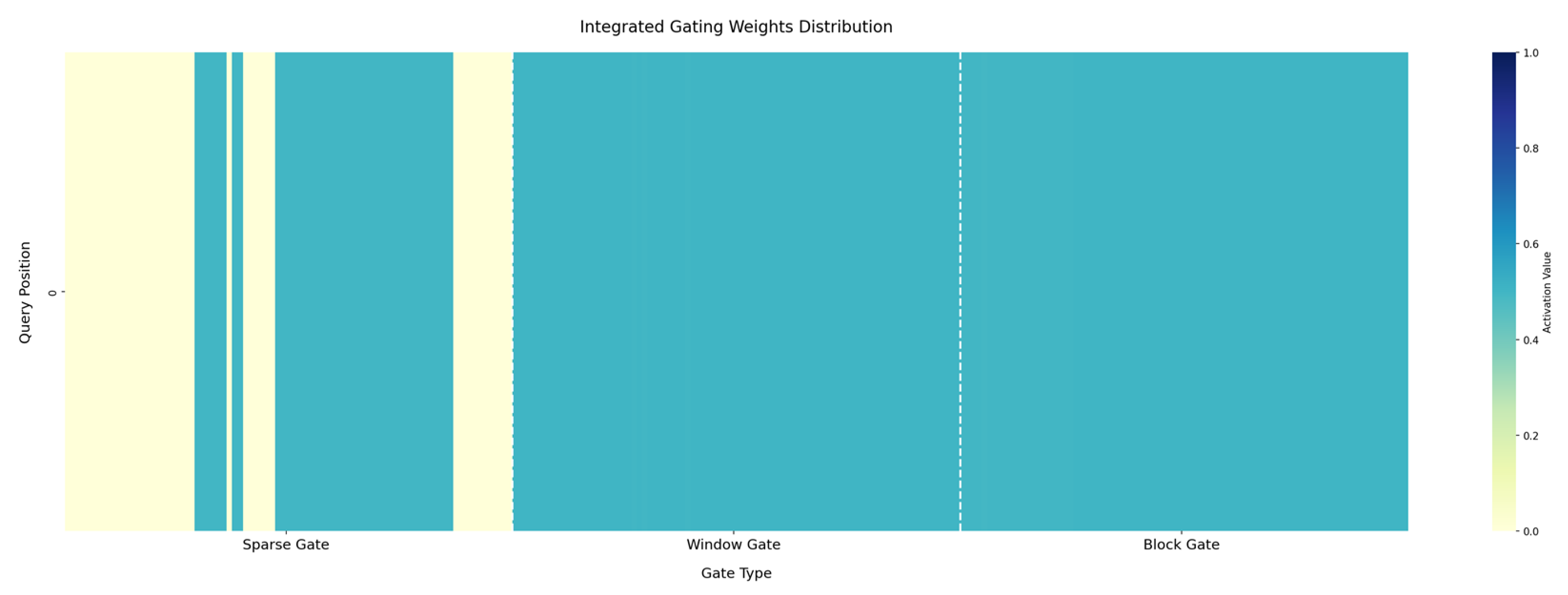
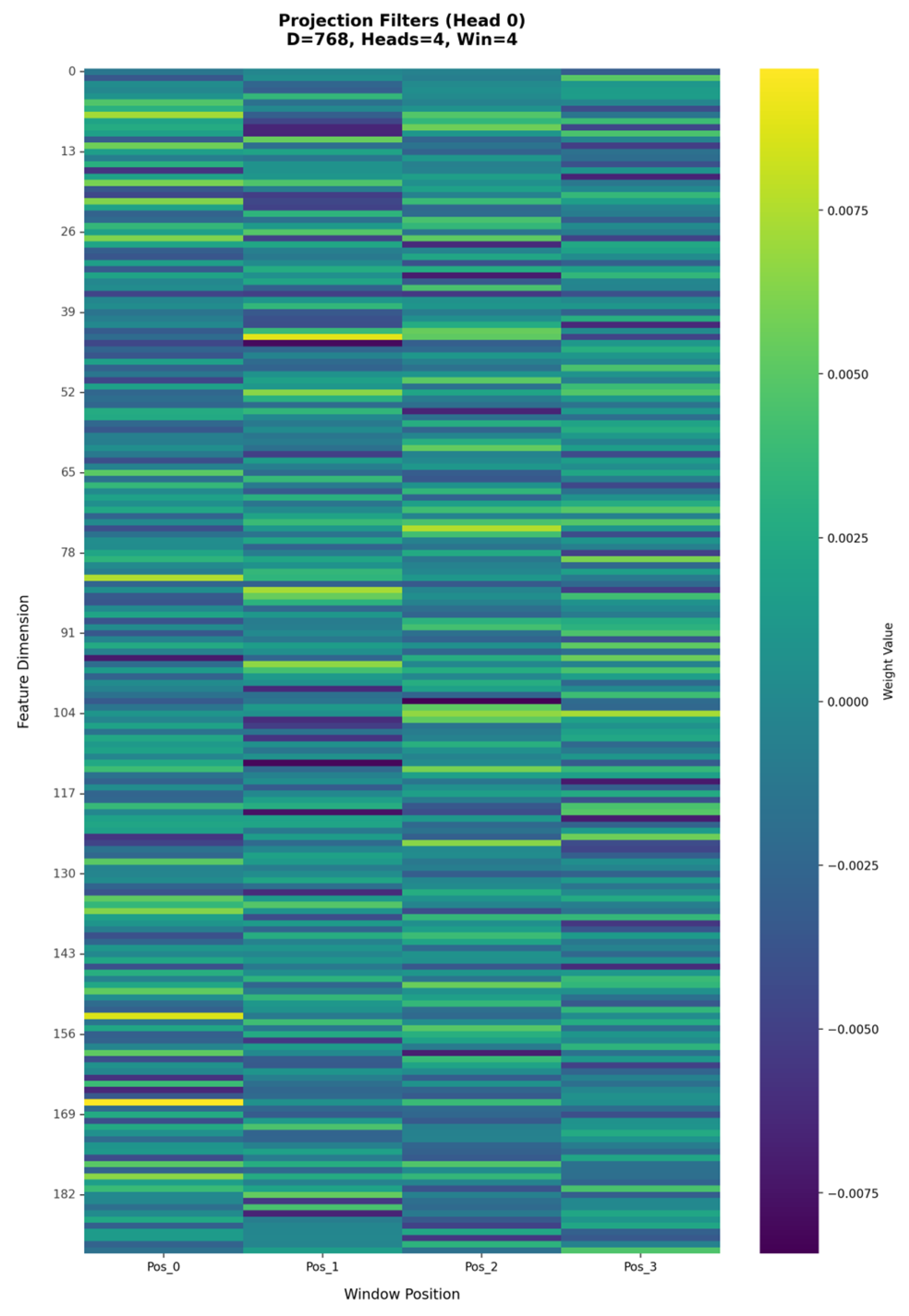
3.1.1. Dynamic Gating Sparse Attention Mechanism
3.1.2. Extraction of Core Semantic Features
3.2. Faithful Original Text Semantic Retention Strategies
3.2.1. Cosine Similarity Calculation
3.2.2. Similarity and Overfitting Regulation Module
3.3. Multi-Loss Synergistic Optimization Strategy
| Algorithm 1. Text Matching Model Based on Dynamically Gated Sparse Attention Feature Distillation with Faithful Semantic Preservation Strategy |
| Require: input_ids, token_type_ids, attention_mask, labels |
| 1: // Gradient Reversal Components |
| 2: function GradientReversalForward(x,) |
| 3: Save in context} |
| 4: return x |
| 5: end function |
| 6: function GradientReversalBackward(grads) |
| 7: dx − grads |
| 8: return dx, None |
| 9: end function |
| 10: // Enhanced Sparse Attention Mechanism |
| 11: function EnhancedSparseAttention (Q,K,V,mask) |
| 12: B, S, D shape(K) |
| 13: num_heads 4, sparse_ratio 0.5 |
| 14: // Sparse Attention Branch |
| 15: |
| 16: |
| 17: |
| 18: Window Attention Branch |
| 19: |
| 20: |
| 21: //W: window projection |
| 22: // Block Compression Branch |
| 23: |
| 24: //C: compressed blocks |
| 25: // Dynamic Gating Fusion |
| 26: |
| 27: |
| 28: // Mask & Normalization |
| 29: |
| 30: return attnV |
| 31: end function |
| 32: // Main Model Forward Pass |
| 33: function ModelForward}{…} |
| 34: |
| 35: |
| 36: // Common Space Projection |
| 37: |
| 38: /h: pooled_output, c: common_emb |
| 39: final_emb |
| 40: // Multi-Task Loss Calculation |
| 41: |
| 42: |
| 43: |
| 44: |
| 45: return L, logits |
| 46: end function |
4. Experimental Setup
4.1. Dataset
4.2. Parameter Settings
5. Results and Analyses
5.1. Accuracy Test Results in the English Dataset
- (1)
- Experimental results on the MRPC dataset
- (2)
- Experimental results on the Scitail dataset
5.2. Test Results on the Chinese Dataset
- (1)
- Experimental results on the PAWS dataset
- (2)
- Experimental results on the Ant Financial Services dataset
5.3. Ablation Experiments
5.4. Performance Analysis of Noisy Data and Low-Resource Scenarios
5.5. Time and Space Complexity Analysis
5.6. Runtime Comparison
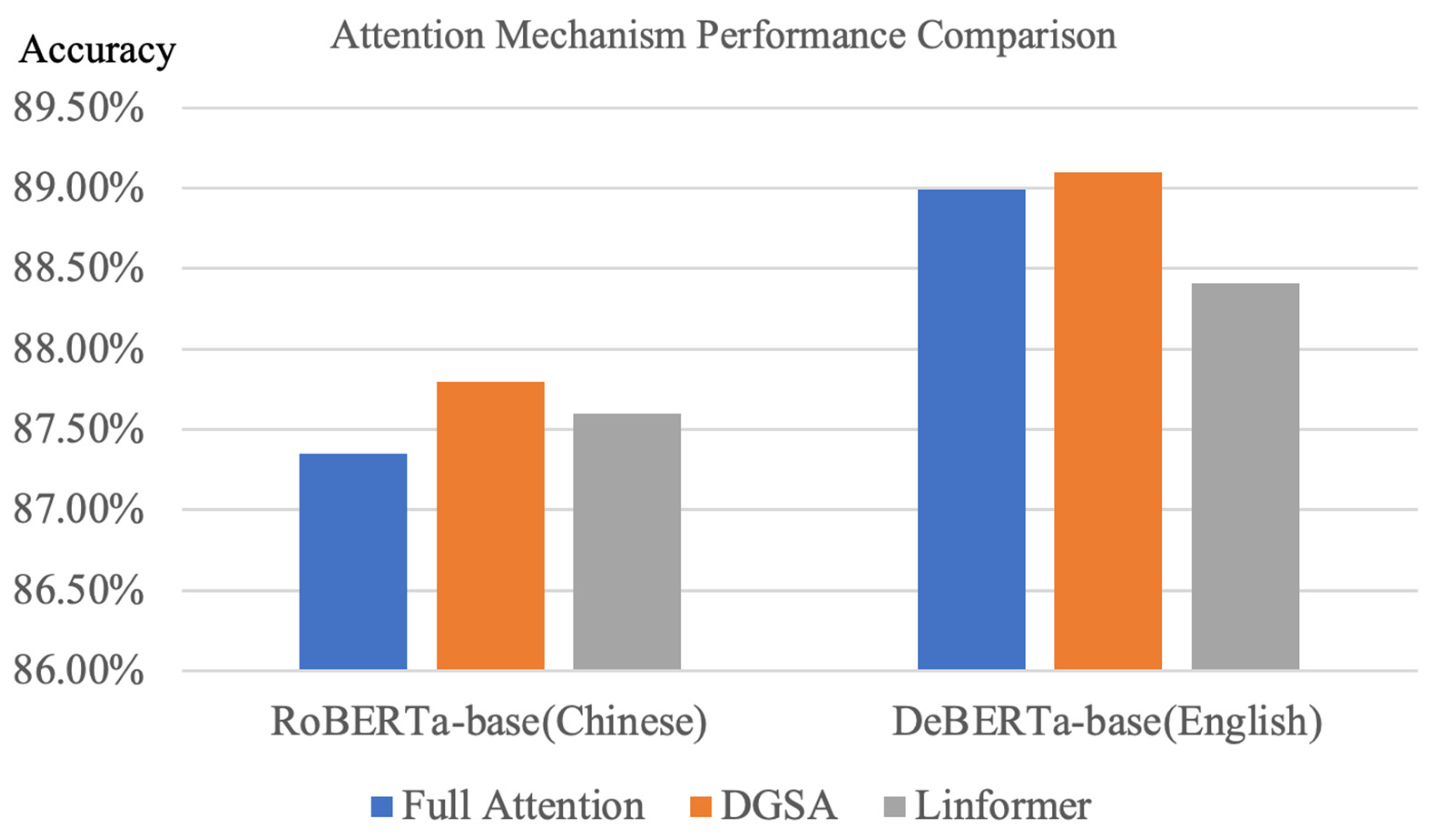
5.7. Performance Comparison of Attention Mechanisms
5.8. Optimizing Interval Loss and Cosine Similarity to Capture Subtle Semantic Changes
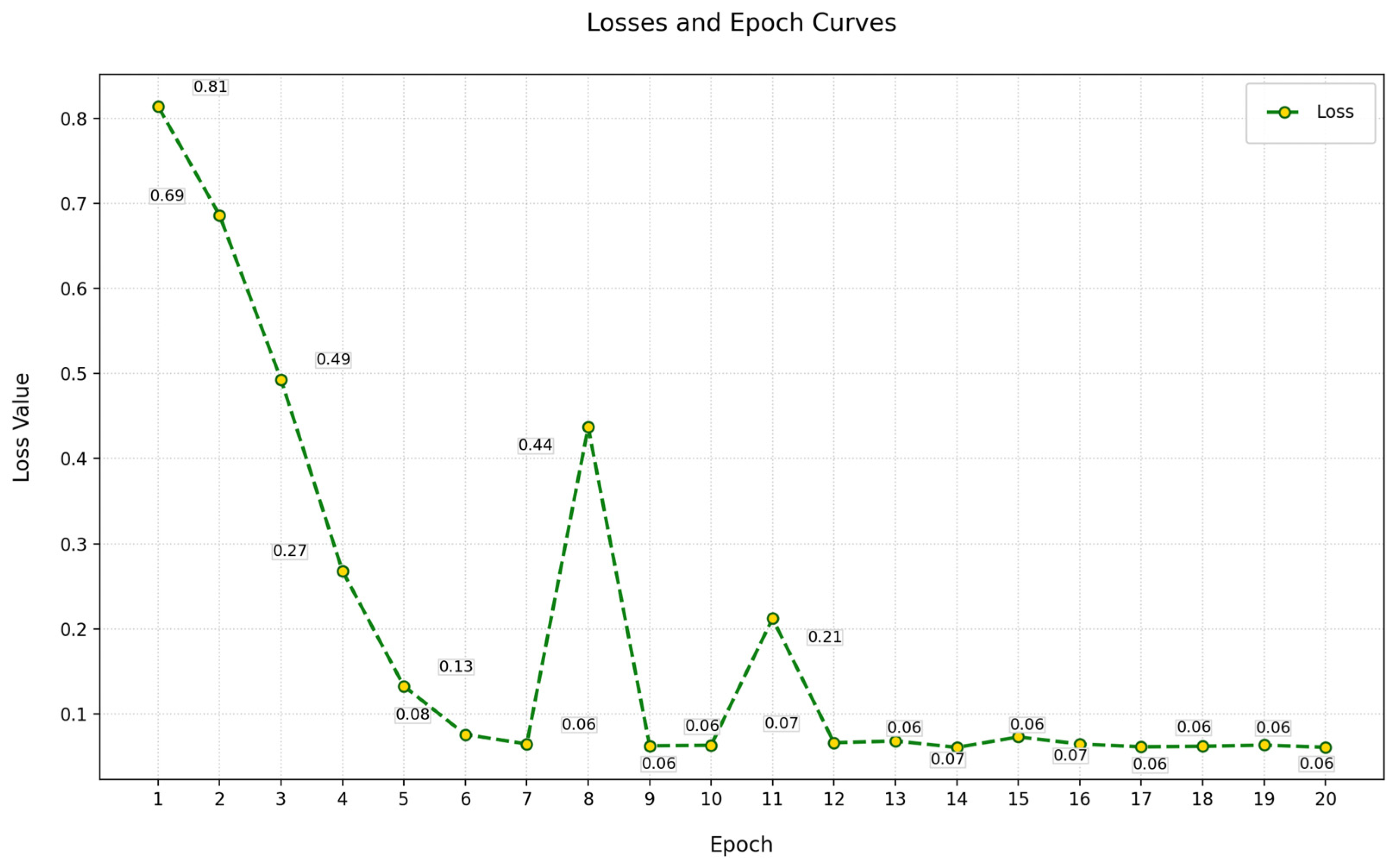
5.9. Model Training Dynamics and Generalizability Validation
5.10. Case Show
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Han, H.; Shomer, H.; Wang, Y.; Lei, Y.; Guo, K.; Hua, Z.; Long, B.; Liu, H.; Tang, J. RAG vs. GraphRAG: A Systematic Evaluation and Key Insights. arXiv 2025, arXiv:2502.11371. [Google Scholar]
- Neeman, E.; Aharoni, R.; Honovich, O.; Choshen, L.; Szpektor, I.; Abend, O. Disentqa: Disentangling Parametric and Contextual Knowledge with Counterfactual Question Answering. arXiv 2022, arXiv:2211.05655. [Google Scholar]
- Zhong, M.; Liu, P.; Chen, Y.; Wang, D.; Qiu, X.; Huang, X. Extractive Summarization as Text Matching. arXiv 2020, arXiv:2004.08795. [Google Scholar]
- Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X. Deepseek-R1: Incentivizing Reasoning Capability in Llms via Reinforcement Learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Achiam, J.; Adler, J.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Song, Z.; Yan, B.; Liu, Y.; Fang, M.; Li, M.; Yan, R.; Chen, X. Injecting Domain-Specific Knowledge into Large Language Models: A Comprehensive Survey. arXiv 2025, arXiv:2502.10708. [Google Scholar]
- Wang, X.; He, J.; Wang, P.; Zhou, Y.; Sun, T.; Qiu, X. DenoSent: A Denoising Objective for Self-Supervised Sentence Representation Learning. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; AAAI: Menlo Park, CA, USA, 2024; pp. 19180–19188. [Google Scholar]
- Gan, L.; Hu, L.; Tan, X.; Du, X. TBNF: A Transformer-Based Noise Filtering Method for Chinese Long-Form Text Matching. Appl. Intell. 2023, 53, 22313–22327. [Google Scholar] [CrossRef]
- Feng, H.; Fan, Y.; Liu, X.; Lin, T.-E.; Yao, Z.; Wu, Y.; Huang, F.; Li, Y.; Ma, Q. Improving Factual Consistency of News Summarization by Contrastive Preference Optimization. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; ACL: Stroudsburg, PA, USA, 2024; pp. 11084–11100. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the The 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: Cambridge, MA, USA, 2015; pp. 1180–1189. [Google Scholar]
- Chen, Y.; Wang, S.; Liu, J.; Xu, X.; de Hoog, F.; Huang, Z. Improved Feature Distillation via Projector Ensemble. In Proceedings of the Advances in Neural Information Processing Systems 22: 36th Annual Conference on Neural Information, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 12084–12095. [Google Scholar]
- Li, J.; Xiao, D.; Lu, T.; Wei, Y.; Li, J.; Yang, L. HAMFace: Hardness Adaptive Margin Loss for Face Recognition with Various Intra-Class Variations. ESWA 2024, 240, 122384. [Google Scholar] [CrossRef]
- Jiang, P.; Cai, X. A Survey of Text-Matching Techniques. Information 2024, 15, 332. [Google Scholar] [CrossRef]
- Wang, Z.; Hamza, W.; Florian, R. Bilateral Multi-Perspective Matching for Natural Language Sentences. arXiv 2017, arXiv:1702.03814. [Google Scholar]
- Zhang, K.; Lv, G.; Wang, L.; Wu, L.; Chen, E.; Wu, F.; Xie, X. Drr-Net: Dynamic Re-Read Network for Sentence Semantic Matching. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; AAAI: Menlo Park, CA, USA, 2019; pp. 7442–7449. [Google Scholar]
- Zhang, K.; Chen, E.; Liu, Q.; Liu, C.; Lv, G. A Context-Enriched Neural Network Method for Recognizing Lexical Entailment. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI: Menlo Park, CA, USA, 2017; Volume 31, pp. 3127–3133. [Google Scholar]
- Wang, Z.; Mi, H.; Ittycheriah, A. Sentence Similarity Learning by Lexical Decomposition and Composition. arXiv 2016, arXiv:1602.07019. [Google Scholar]
- Tomar, G.S.; Duque, T.; Täckström, O.; Uszkoreit, J.; Das, D. Neural Paraphrase Identification of Questions with Noisy Pretraining. arXiv 2017, arXiv:1704.04565. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-Enhanced Bert with Disentangled Attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Zhang, Y.; Zhu, H.; Wang, Y.; Xu, N.; Li, X.; Zhao, B. A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-Wise Perspective in Angular Space. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; ACL: Stroudsburg, PA, USA, 2022; pp. 4892–4903. [Google Scholar]
- Yu, E.; Du, L.; Jin, Y.; Wei, Z.; Chang, Y. Learning Semantic Textual Similarity via Topic-Informed Discrete Latent Variables. arXiv 2022, arXiv:2211.03616. [Google Scholar]
- Zou, Y.; Liu, H.; Gui, T.; Wang, J.; Zhang, Q.; Tang, M.; Li, H.; Wang, D.; Assoc Computa, L. Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents. arXiv 2022, arXiv:2203.02898. [Google Scholar]
- Yao, D.; Alghamdi, A.; Xia, Q.; Qu, X.; Duan, X.; Wang, Z.; Zheng, Y.; Huai, B.; Cheng, P.; Zhao, Z. A General and Flexible Multi-Concept Parsing Framework for Multilingual Semantic Matching. arXiv 2024, arXiv:2403.02975. [Google Scholar]
- Li, B.; Liang, D.; Zhang, Z. Comateformer: Combined Attention Transformer for Semantic Sentence Matching. arXiv 2024, arXiv:2412.07220. [Google Scholar]
- Wang, Y.; Zhang, B.; Liu, W.; Cai, J.; Zhang, H. STMAP: A Novel Semantic Text Matching Model Augmented with Embedding Perturbations. Inf. Process. Manag. 2024, 61, 103576. [Google Scholar] [CrossRef]
- Yuan, J.; Gao, H.; Dai, D.; Luo, J.; Zhao, L.; Zhang, Z.; Xie, Z.; Wei, Y.; Wang, L.; Xiao, Z. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. arXiv 2025, arXiv:2502.11089. [Google Scholar]
- Zhao, J.; Zhan, W.; Zhao, X.; Zhang, Q.; Gui, T.; Wei, Z.; Wang, J.; Peng, M.; Sun, M. RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction. arXiv 2023, arXiv:2306.04954. [Google Scholar]
- Dolan, B.; Brockett, C. Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the Third International Workshop on Paraphrasing, Jeju Island, Republic of Korea, 14 October 2005; AFNLP: Jeju Island, Republic of Korea, 2005; pp. 9–16. [Google Scholar]
- Khot, T.; Sabharwal, A.; Clark, P. Scitail: A Textual Entailment Dataset from Science Question Answering. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), Hilton New Orleans Riverside, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, X.; Liu, Q.; Gui, T.; Zhang, Q.; Zou, Y.; Zhou, X.; Ye, J.; Zhang, Y.; Zheng, R.; Pang, Z. Textflint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, Online, 1–6 August 2021; ACL: Stroudsburg, PA, USA, 2021; pp. 347–355. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-Training with Whole Word Masking for Chinese Bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, L.; Lv, G.Y.; Wang, M.; Chen, E.H.; Ruan, S.L.; Assoc Advancement Artificial, I. Making the Relation Matters: Relation of Relation Learning Network for Sentence Semantic Matching. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; AAAI Press: Palo Alto, CA, USA, 2021; pp. 14411–14419. [Google Scholar]
- Kim, S.; Kang, I.; Kwak, N. Semantic Sentence Matching with Densely-Connected Recurrent and Co-Attentive Information. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; AAAI: Menlo Park, CA, USA, 2019; pp. 6586–6593. [Google Scholar]
- Parikh, A.P.; Täckström, O.; Das, D.; Uszkoreit, J. A Decomposable Attention Model for Natural Language Inference. arXiv 2016, arXiv:1606.01933. [Google Scholar]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H.; Inkpen, D. Enhanced LSTM for Natural Language Inference. arXiv 2016, arXiv:1609.06038. [Google Scholar]
- Tay, Y.; Tuan, L.A.; Hui, S.C. Compare, Compress and Propagate: Enhancing Neural Architectures with Alignment Factorization for Natural Language Inference. arXiv 2017, arXiv:1801.00102. [Google Scholar]
- Tay, Y.; Tuan, L.A.; Hui, S.C. Co-Stack Residual Affinity Networks with Multi-Level Attention Refinement for Matching Text Sequences. arXiv 2018, arXiv:1810.02938. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C. Hermitian Co-Attention Networks for Text Matching in Asymmetrical Domains. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4425–4431. [Google Scholar]
- Yang, R.; Zhang, J.; Gao, X.; Ji, F.; Chen, H. Simple and Effective Text Matching with Richer Alignment Features. arXiv 2019, arXiv:1908.00300. [Google Scholar]
- Li, Y.; Yan, D.; Jiang, W.; Cai, Y.; Tian, Z. Exploring Highly Concise and Accurate Text Matching Model with Tiny Weights. World Wide Web 2024, 27, 39. [Google Scholar] [CrossRef]
- Jiang, K.; Zhao, Y.; Jin, G.; Zhang, Z.; Cui, R. KETM: A Knowledge-Enhanced Text Matching Method. In Proceedings of the International Joint Conference on Neural Networks, Gold Coast, QLD, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Liao, Y.; Jiang, S.; Wang, Y.; Wang, Y. MING-MOE: Enhancing Medical Multi-Task Learning in Large Language Models with Sparse Mixture of Low-Rank Adapter Experts. arXiv 2024, arXiv:2404.09027. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-Attention with Linear Complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.; Mohiuddin, A.; Kaiser, L. Rethinking Attention with Performers. arXiv 2020, arXiv:2009.14794. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-Bert: Sentence Embeddings Using Siamese Bert-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Task | Train | Dev | Test | Domain | Language | Class |
|---|---|---|---|---|---|---|---|
| MRPC | Paraphrase | 3668 | 408 | 1725 | general domain | English | 2 |
| Scitail | Textual Entailment | 23,596 | 1304 | 2126 | scientific domain | English | 2 |
| PAWS | Semantic Equivalence Identification/Paraphrase Identification | 49,401 | - | 2000 | general domain | Chinese | 2 |
| Ant Financial Services | QA | 29,998 | 3668 | 3668 | Financial domain | Chinese | 2 |
| KUAKE-QTR | Medical Search Query Terms—Page Title Relevance | 24,174 | - | 2913 | Medical domain | Chinese | 4 |
| Model | MRPC |
|---|---|
| CENN [16] | 76.47% |
| L.D.C [17] | 78.47% |
| BiMPM [14] | 79.6% |
| DRCN [36] | 82.57% |
| DRr-Net [15] | 82.97% |
| R2-Net [35] | 84.37% |
| SimCSE-BERTbase [22] | 74.43% |
| ArcCSE-BERTbase [22] | 74.78% |
| DisRoBERTa [23] | 88.06% |
| DC-Match [24] (DeBERTa-base) | 88.8% |
| MCP-SM [25] (DeBERTa-base) | 88.9% |
| BERT [19] | 83.94% |
| RoBERTa [21] | 87.83% |
| DeBERTa [20] | 88.46% |
| Our (DeBERTa-base) | 89.10% |
| Model | Accuracy (Ori → Our) | F1 (Ori → Our) |
|---|---|---|
| BERT-base [19] | 83.94% → 84.81% (0.87) | 88.43% → 89% (0.57) |
| RoBERTa-base [21] | 87.83% → 88.46% (0.63) | 91.10% → 91.28% (0.18) |
| DeBERTa-base [20] | 88.46% → 89.10% (0.64) | 91.59% → 91.90% (0.64) |
| Model | SciTail |
|---|---|
| DecAtt [37] | 72.3% |
| ESIM [38] | 70.6% |
| BiMPM [14] | 75.3% |
| CAFÉ [39] | 83.3% |
| CSRAN [40] | 86.7% |
| DGEM [31] | 77.3% |
| HCRN [41] | 80.0% |
| RE2 [42] | 86.0% |
| DRr-Net [15] | 87.4% |
| AL-RE2 [43] | 87.02 % |
| KETM-KB∗ [44] | 89.5% |
| KETM∗ [44] | 90.4% |
| KETM-KB (BERT)∗ [44] | 92.1% |
| KETM (BERT) [44] | 92.6% |
| BERT-Base-Comateformer [26] | 92.4% |
| RoBERTa-Base-Comateformer [26] | 93.2% |
| BERT-base [19] | 93.23% |
| RoBERTa-base [21] | 93.74% |
| DeBERTa-base [20] | 94.64% |
| Our(DeBERTa-base) | 95.01% |
| Model | Accuracy (Ori → Our) | F1 (Ori → Our) |
|---|---|---|
| BERT-base [19] | 93.23% → 93.41%(0.18) | 91.42% → 91.64%(0.22) |
| RoBERTa-base [21] | 93.74% → 94.17%(0.43) | 91.99% → 92.55%(0.56) |
| DeBERTa-base [20] | 94.64% → 95.01%(0.37) | 93.36% → 93.76%(0.4) |
| Model | Accuracy |
|---|---|
| STMAP [27] | 81.2% |
| Mac-BERT [19] | 84.95% |
| RoBERTa-base [21] | 87% |
| Our (RoBERTa-base) | 87.8% |
| Model | Accuracy (Ori → Our) | F1 (Ori → Our) |
|---|---|---|
| Mac-BERT [19] | 84.95% → 85.05% | 82.69% → 82.90% |
| RoBERTa-base [21] | 87% → 87.80% | 85.31% → 86.37% |
| Model | Accuracy |
|---|---|
| Mac-BERT [19] | 79.14% |
| RoBERTa-base [21] | 79.61% |
| Our (RoBERTa-base) | 80.32% |
| Model | Accuracy (Ori → Our) | F1 (Ori → Our) |
|---|---|---|
| Mac-BERT [19] | 79.14% → 79.69% | 79.06% → 79.17% |
| RoBERTa-base [21] | 79.61% → 80.32% | 79.15% → 80.27% |
| Model | Scitail (Accuracy) | Scitail (F1) | MRPC (Accuracy) | MRPC (F1) |
|---|---|---|---|---|
| DeBERTa-base [20] | 94.64% | 93.36% | 88.46% | 91.59% |
| DeBERTa-base + LJ + LGRL | 94.92% | 93.71% | 88.75% | 91.53% |
| Our (DeBERT-base + LJ + LGRL + LI) | 95.01% | 93.76% | 89.10% | 91.90% |
| Model | PAWS (Acc.) | PAWS (F1) | Ant (Acc.) | Ant (F1) |
|---|---|---|---|---|
| RoBERTa-base [21] | 87% | 85.31% | 79.61% | 79.15% |
| RoBERTa-base + LJ + LGRL | 87.1% | 85.24% | 80.15% | 79.90% |
| Our (RoBERTa-base + LJ + LGRL + LI) | 87.8% | 86.37% | 80.31% | 80.27% |
| Model | MRPC_BackTrans | MRPC_Appendlrr | MRPC_Punctuation |
|---|---|---|---|
| Our (RoBERTa) | 86.67% | 86.84% | 88.29% |
| Our (DeBERTa) | 87.71% | 87.82% | 88.93% |
| Model | Macro-F1 |
|---|---|
| MING-MOE(1.8 B) [45] | 56.06% |
| MING-MOE(4 B) [45] | 62.08% |
| MING-MOE(7 B) [45] | 64.20% |
| MING-MOE(13 B) [45] | 67.29% |
| RoBERTa-base [21] | 67.46% |
| Our (RoBERTa-base) | 68.08% |
| Model | KUAKE-QTR (Acc.) | KUAKE-QTR (Macro-F1) |
|---|---|---|
| RoBERTa-base [21] | 69.45% | 67.46% |
| RoBERTa-base + LJ + LGRL | 69.72% | 67.71% |
| Our | 70.10% | 68.08% |
| Model | Complexity Type | Component/Operation | Main Influencing Factors | Calculation Formulae |
|---|---|---|---|---|
| Methodology of this paper (DeBERTa-base) | time complexity | (1) DeBERTa-base encoder; (2) enhanced sparse attention; (3) explicit projection; (4) interval loss function | (1) Number of layers L = 12, decoupled attention mechanism introduces 3QK computation; (2) h = 4 heads, w = 4 windows, k = 4 blocks; (3) two explicit projection operations (b × d2 each time); (4) cosine similarity computation | O(L(3n2d + 2nd2) + bh(n2 + nw + nk)) |
| memory complexity | (1) DeBERTa-base parameter; (2) encoder intermediate activation; (3) sparse attention intermediate result; (4) projection intermediate result; (5) optimizer state (AdamW) | (1) 150M parametric quantities; (2) decoupled attention requires storage of relative position encoding matrices; (3) three-way attention branching storage; (4) two projections intermediate storage; (5) parameters, gradients, momentum, and second-order momentum | O(L(3n2 + 2nd) + 3bhS2) | |
| DeBERTa-base | time complexity | (1) DeBERTa-base encoder (2) Classifier | (1) Number of layers L = 12, decoupled attention mechanism introduces 3QK computation; (2) number of classification labels k = 2 | O(L(3n2d + 2nd2) |
| memory complexity | (1) DeBERTa-base parameters; (2) encoder intermediate activation; (3) optimizer state (AdamW) | (1) Parameter count 150M; (2) decoupled attention required to store relative position coding matrix; (3) parameters, momentum, and second-order momentum | O(L(3n2 + 2nd) + 150M) | |
| DC-Match (RoBERTa-base) | time complexity | (1) Triple encoder forward computation; (2) mean pooling operation; (3) classifier computation; (4) KL scatter loss computation | (1) L = 12 layers, n = 512 sequence length, d = 768 hidden dimensions; (2) batch size b = 16/64 and sequence length n = 512; (3) number of labels k = 2/3; (4) joint probability distribution dimension k × k | O(3L(n2d + nd2) + 4bn2d) |
| memory complexity | (1) Triple encoder parameters; (2)attention matrix storage; (3) intermediate activation values; (4) optimizer state (AdamW) | (1) RoBERTa-base parameter count of 125M (three independent encoders); (2) number of layers L = 12, the number of attention heads h = 12, and the length of the sequence n = 512; (3) hidden states and pooled intermediate results of the three-time encoder; (4) parameters, gradients, momentum, and second-order momentum | O(3L(n2 + nd) + 375M + 3Lhn2) | |
| Methodology of this paper (RoBERTa-base) | time complexity | (1) RoBERTa encoder; (2) enhanced sparse attention; (3) explicit projection; (4) interval loss function | (1) L = 12 layers, n = 512 sequence lengths, d = 768 hidden dimensions; (2) h = 4 heads, w = 4 windows, k = 4 block sizes; (3) two explicit projection operations (b × d2 each time); (4) cosine similarity calculation | O(L(n2d + nd2) + bh (n2 + nw + nk)) |
| memory complexity | (1) RoBERTa-base parameter; (2) encoder intermediate activation; (3) sparse attention intermediate result; (4) projection intermediate result; (5) optimizer state (AdamW) | (1) Parameter count 125M; (2) storage of attention matrix and hidden states; (3) three-way attention branching storage; (4) twice-projected intermediate storage; (5) cosine similarity matrix storage; (5) parameters, gradient, momentum, and second-order momentum | O(L(n2 + nd) + 3bhS2) | |
| RoBERTa-base | time complexity | (1) RoBERT-base encoder; (2) classifier | (1) Sequence length n = 512, hidden layer dimension d = 768, and number of layers L = 12; (2) batch size b = 64 and hidden layer dimension d = 768 | O(L(n2d + nd2)) |
| memory complexity | (1) MacBERTa-base parameters; (2) attention matrix; (3) intermediate activation values; (4) optimizer state (AdamW) | (1) Number of parameters 125M; (2) batch size b = 16/64, number of attention heads h = 12, and sequence length n = 512; (3) hidden layer dimension d = 768, sequence length n = 512, and number of layers L = 12; (4) number of parameters 125M, momentum and gradient storage | O(L(n2 + nd) + 125M) |
| Model | Training Time (Seconds) | Testing Time (Seconds) |
|---|---|---|
| BERT | 2766.61 | 3.07 |
| Our (BERT) | 2803.61 | 3.12 |
| RoBERTa | 2854.36 | 3.06 |
| Our (RoBERTa) | 2919.21 | 3.24 |
| DeBERTa | 3561.23 | 3.89 |
| Our (DeBERTa) | 3582.38 | 3.83 |
| Model | Training Time (Seconds) | Testing Time (Seconds) |
|---|---|---|
| Mac-BERT | 12,346.73 | 5.35 |
| Our (Mac-BERT) | 13,279.30 | 5.62 |
| RoBERTa | 39,090.76 | 16.70 |
| Our (RoBERTa) | 41,078.63 | 17.68 |
| Methods | Computational Complexity | Description of Key Parameters |
|---|---|---|
| Standard Point Multiplier Attention [29] | O(BHS2d) | S: sequence length, d: feature dimension |
| Sparse attention [28] | O(BHS2d⋅ρ) | ρ: Sparsity ratio (0–1) |
| Linformer [46] | O(S⋅K) | S: sequence length, K: control sequence compression ratio |
| Performer [47] | O(Srd) | S: sequence length, d: feature dimension, r: random feature dimension |
| NSA [28] | O(BHSd log S + BHSkd) | k: number of hash buckets, b: compressed/selected block size |
| Attention to this paper | O(BHS2d(2 + 1/b) + BHSwd2) | w: window size, b: block size |
| Model | MRPC_Appendlrr |
|---|---|
| Our (RoBERTa) | 86.84% |
| Our (RoBERTa) | 87.19% |
| Our (DeBERTa) | 87.82% |
| Our (DeBERTa) | 87.83% |
| Datasets | Sentence Pair | Labels | The Labels Generated by the Methods in This Paper | ||
|---|---|---|---|---|---|
| MRPC | Sentence A: PCCW ‘s chief operating officer, Mike Butcher, and Alex Arena, the chief financial officer, will report directly to Mr So Sentence B: Current Chief Operating Officer Mike Butcher and Group Chief Financial Officer Alex Arena will report to So. | 1 | 1 | ||
| Sentence A: A tropical storm rapidly developed in the Gulf of Mexico Sunday and was expected to hit somewhere along the Texas or Louisiana coasts by Monday night. Sentence B: A tropical storm rapidly developed in the Gulf of Mexico on Sunday and could have hurricane-force winds when it hits land somewhere along the Louisiana coast Monday night. | 0 | 1 | |||
| KUAKE-QTR | Sentence A: 儿童远视眼怎么恢复视力 Sentence A: How to restore vision in hyperopic children Sentence B: 远视眼该如何保养才能恢复一些视力 Sentence B: What you can do to take care of your farsightedness to regain some vision | 1 | 1 | ||
| Sentence A: 脸上皮炎多年能自愈吗 Sentence A: Can dermatitis on the face heal on its own over the years Sentence B: 我面部皮炎已有十多年了, 一擦皮. Sentence B: I’ve had facial dermatitis for over a decade, and when I rub my skin. | 1 | 0 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, P.; Cai, X. A Symmetric Dual-Drive Text Matching Model Based on Dynamically Gated Sparse Attention Feature Distillation with a Faithful Semantic Preservation Strategy. Symmetry 2025, 17, 772. https://doi.org/10.3390/sym17050772
Jiang P, Cai X. A Symmetric Dual-Drive Text Matching Model Based on Dynamically Gated Sparse Attention Feature Distillation with a Faithful Semantic Preservation Strategy. Symmetry. 2025; 17(5):772. https://doi.org/10.3390/sym17050772
Chicago/Turabian StyleJiang, Peng, and Xiaodong Cai. 2025. "A Symmetric Dual-Drive Text Matching Model Based on Dynamically Gated Sparse Attention Feature Distillation with a Faithful Semantic Preservation Strategy" Symmetry 17, no. 5: 772. https://doi.org/10.3390/sym17050772
APA StyleJiang, P., & Cai, X. (2025). A Symmetric Dual-Drive Text Matching Model Based on Dynamically Gated Sparse Attention Feature Distillation with a Faithful Semantic Preservation Strategy. Symmetry, 17(5), 772. https://doi.org/10.3390/sym17050772