

Full-Element Analysis of Side-Channel Leakage Dataset on Symmetric Cryptographic Advanced Encryption Standard
 , ,
, ,
Abstract
1. Introduction
- This is the first systematic analysis of public datasets in the side-channel domain integrating the results of the analysis, elaborating the sources and uses of curves in public datasets, and developing data analysis visualization scripts to make index queries and perform point trace visualization for typical datasets.
- We have conducted an innovative full-elemental analysis of side-channel analysis datasets. To promote the application of deep learning techniques in this field, we carried out an elemental analysis of full-volume sample datasets and statistically analyzed the distribution of the number of labels when performing [0,255] key guessing.
- We designed experiments regarding the impact of masked label samples on the training of deep learning methods, exploring the specific effects of the total number of sample features and the uniformity of label samples on the model, to provide operational suggestions and methodological references for the original collection of the dataset, the integration of the preprocessing, and the complementation of the data label features.
2. Related Work
- The format of the dataset is not yet uniform—The side-channel analysis community does not have a publicly available and centralized data center in which to house the datasets, with the data existing in a more dispersed state as shown in Table 3. Although HDF5 is advocated by some scholars and research institutes, each team still uses different instruments and equipment, and the file format of the capture export depends on one’s familiarity with the instrument used, such as the TRC file of a Liko oscilloscope, and algorithm dependence, such as in the development of NPY files in Python (a common problem).Table 3. Comparison of dataset storage formats.
hdf5 npy trc trs bin Source UIUC - LeCroy TRS_bai(trs) - Format Description Structured Container Multidimensional Array Two-Dimensional Binary Heterogeneous Text gbk Two-Dimensional Binary Index Structure Grouped Index Single-File Index Single-File Index - - Development Support Universal Python-Friendly Matlab-Friendly - Universal Development Dependencies h5py numpy LECROY_2_3
readTrc- - Storage Scale TB-Level Suitable for Lightweight Applications TB-Level TB-Level TB-Level Main Advantages Hierarchical | High-Scale
Cross-Platform ApplicationFast Reading and Writing Lightweight and Universal Main Disadvantages Complex API Poor Portability
Small Data ScaleStrong Instrument Dependence High Space Utilization - - There is a lack of work on datasets for native encryption and decryption scenarios—Most of the teams in the SCA community and their research target deep learning attacks in non-native scenarios involving the grouping of ciphered AESs, with a preponderance of soft implementation analyses based on the type of MCU but very little hard implementation analyses (a common problem).
- Technology-related work concerns the implementation of deep learning for the sake of researching deep learning—The bottleneck in the development of DL-SCA technology around datasets is that it is not performed in the context of carrying out an actual attack but rather in the context of researching neural networks in search of a fixed paradigm. It is difficult to generalize results to real analysis scenarios (common problems) if the research in question relies exclusively on public datasets.
- Datasets without full samples—Most of the datasets in this domain are characterized by long-tailed data, with too few samples. In adjacent domains, Doan et al. [39] used historical time series to analyze the price volatility of cryptocurrencies, which is conceptually parallel to the volatility and non-uniformity of the characteristic distribution of labeled curves. This idea can help establish a methodology for addressing the non-uniformity and instability of the characteristic distribution of side-channel curves. Algorithmic execution can be lazy in the application of DL-SCA techniques, an issue analogous to the ‘misleading evaluation results due to model overfitting’ in the application of large models. When performing 8-bit or multi-bit key guessing in a divide-and-conquer fashion, algorithms automatically perform guessing wherever there are more samples. Insufficient samples for a single feature will lead to model-training bias, resulting in the key problem of overfitting (a common problem).
- Insufficient technical interpretations—In the case of ASCAD, for example, the raw curves are processed, 700 points are extracted to characterize the executable causes of sensitive operational partially executed analyses, and key byte guesses are often not made explicit (personality issues).
- Limiting factor in model performance—Despite the technical attempts made in relation to TransNet, EstraNet, and improved TransNet, small-feature-sample datasets only require lightweight models to achieve a single key byte, which then constrains the application of new-and-improved Transformer-based technical methods (the problem of individuality).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. Materials and Methods
3.1. Visual Analysis of Dataset Traces
3.1.1. DPA Contest
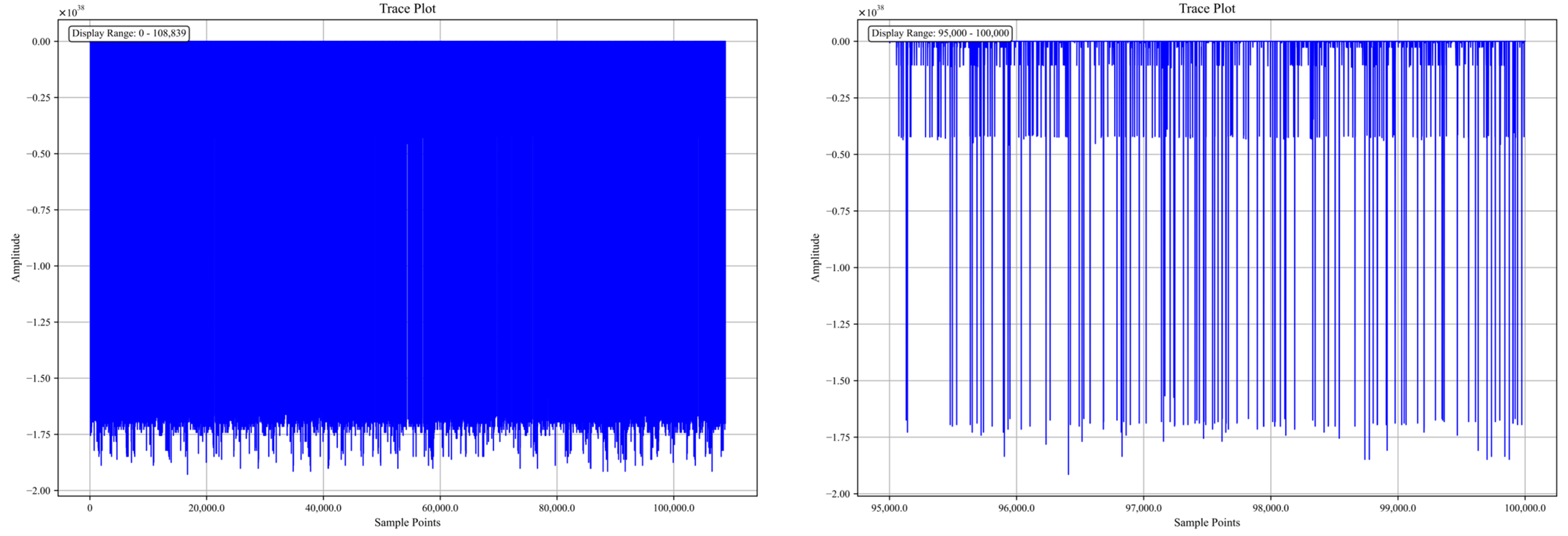
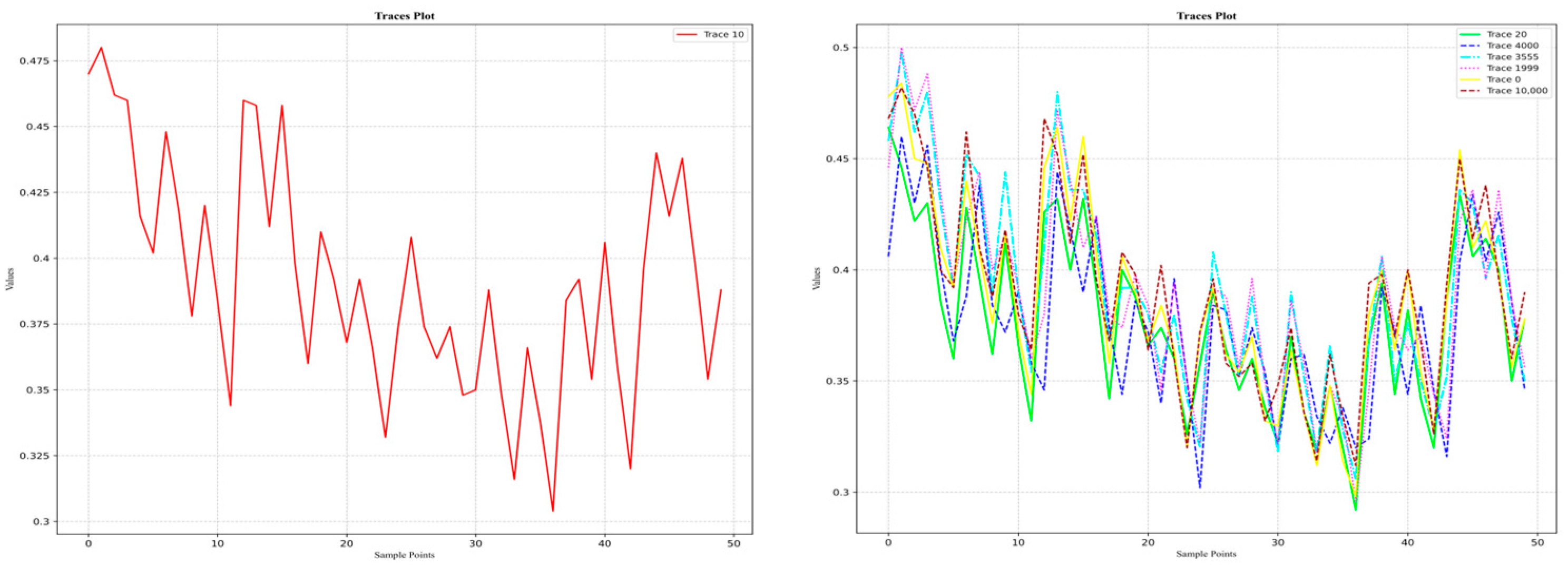
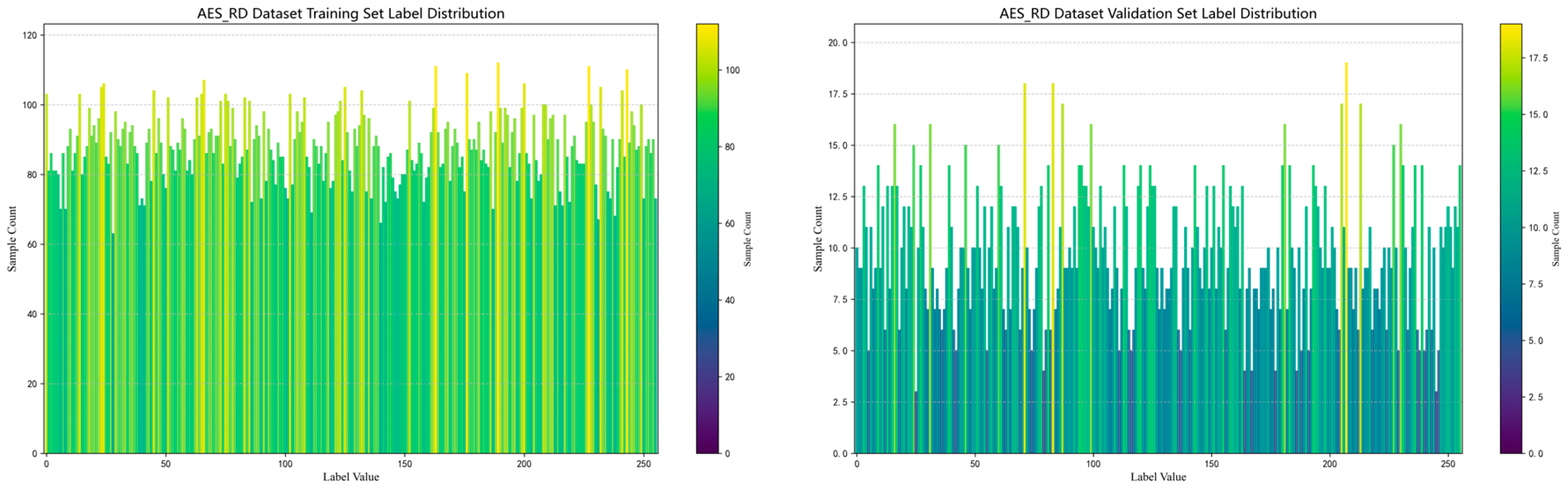
3.1.2. AES_RD
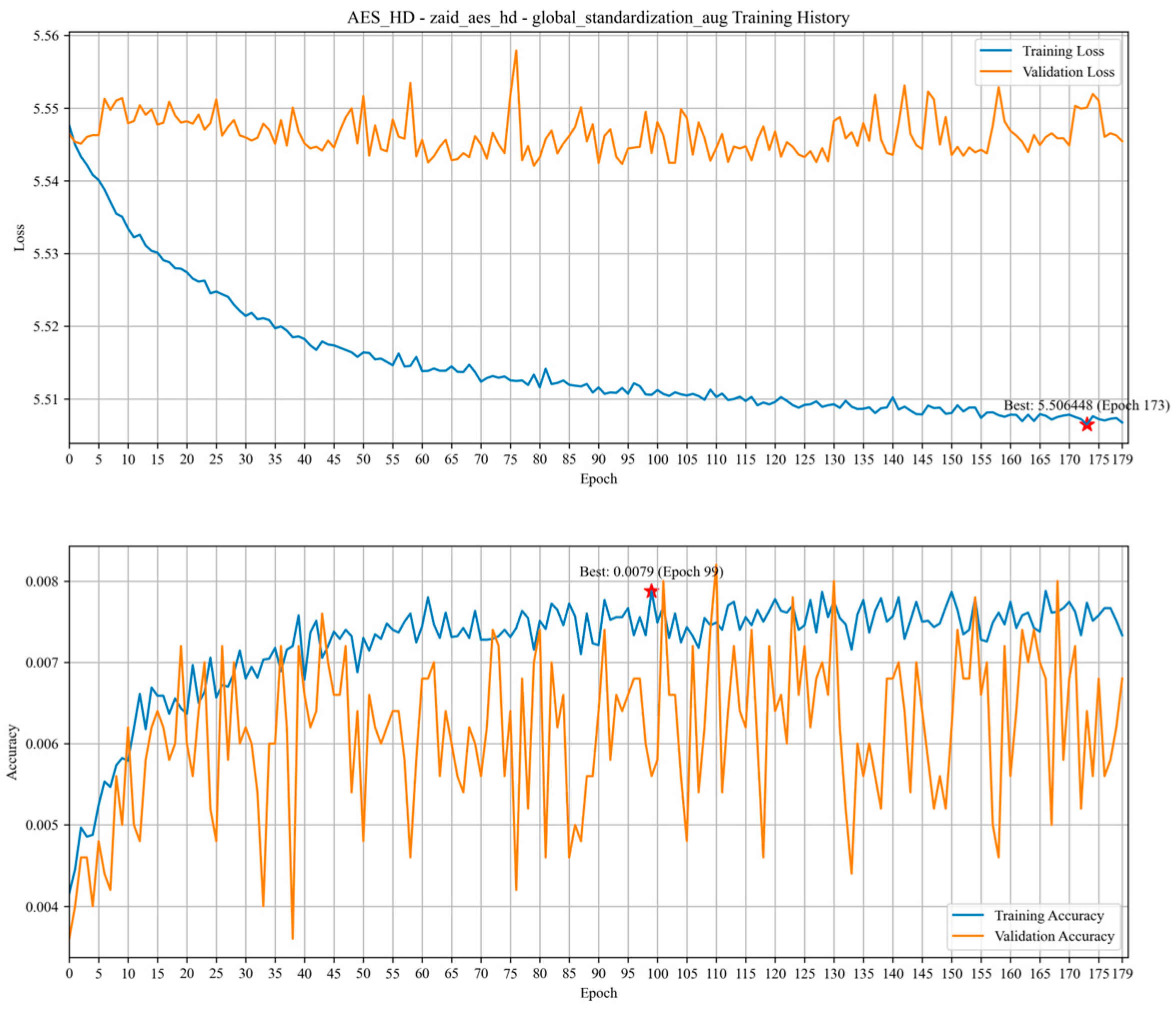
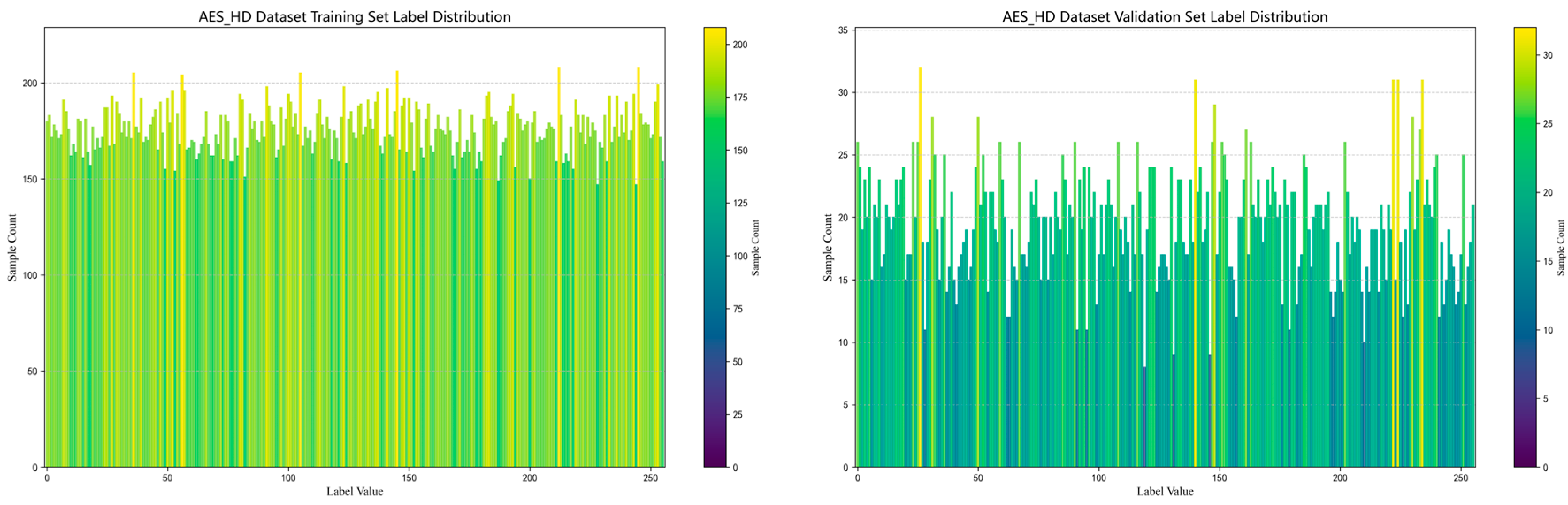
3.1.3. AES_HD
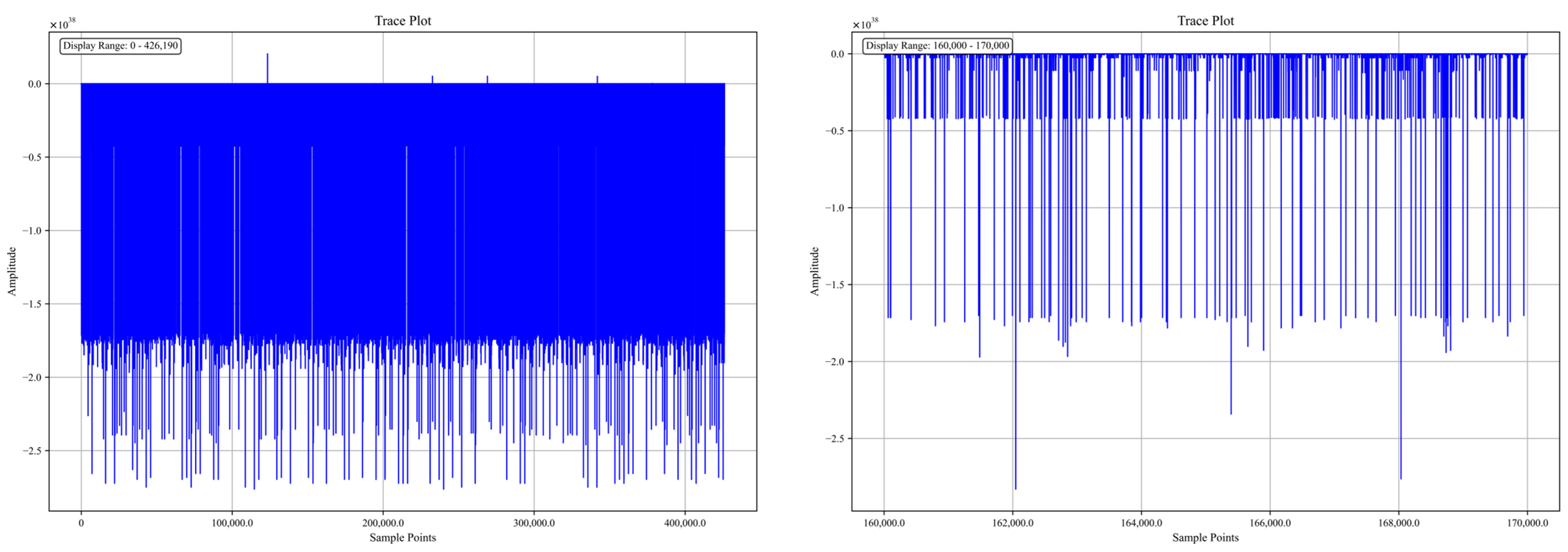
3.1.4. Grizzly
3.1.5. Panda2018 Challenge
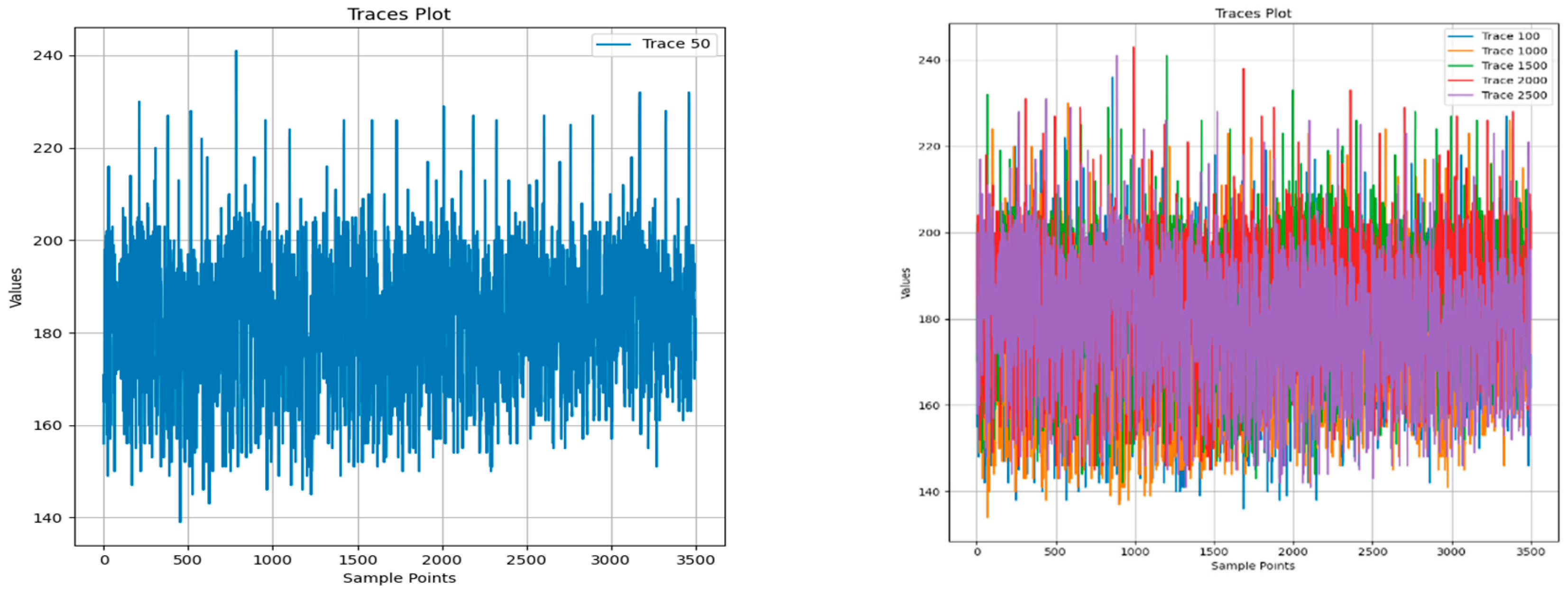
3.1.6. ASCAD
- For the soft implementation of AES-128 on ATMega with fixed key EM-side information leakage ASCAD_fixed_key, the storage and index structure can be represented as
- 2.
- For the soft implementation of AES-128 on ATMega with random key EM-side information leakage ASCAD_vriable_key, the storage and index structure is represented as
- 3.
- For the AES-128 soft implementation of the no-secret sharing ASCAD_v2 on STM32, the storage and index structure is represented as follows:
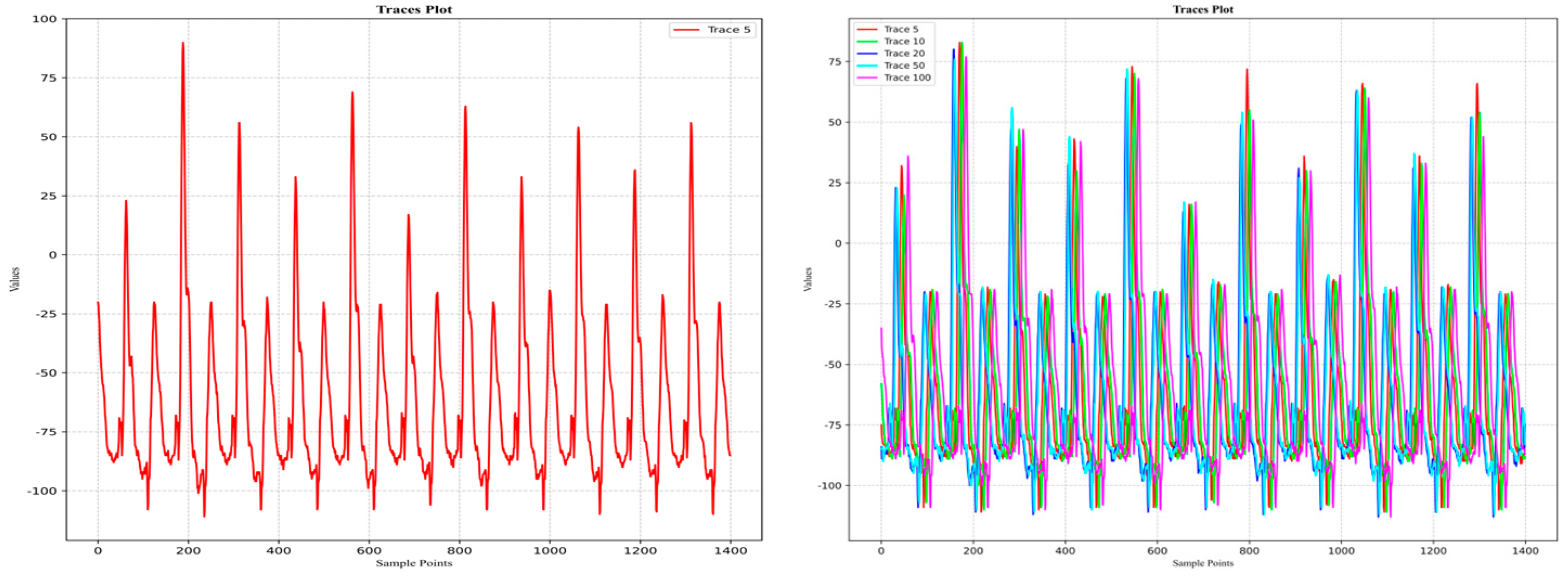
3.1.7. CHES_CTF_2018/2020
3.1.8. Portability (NDSS)
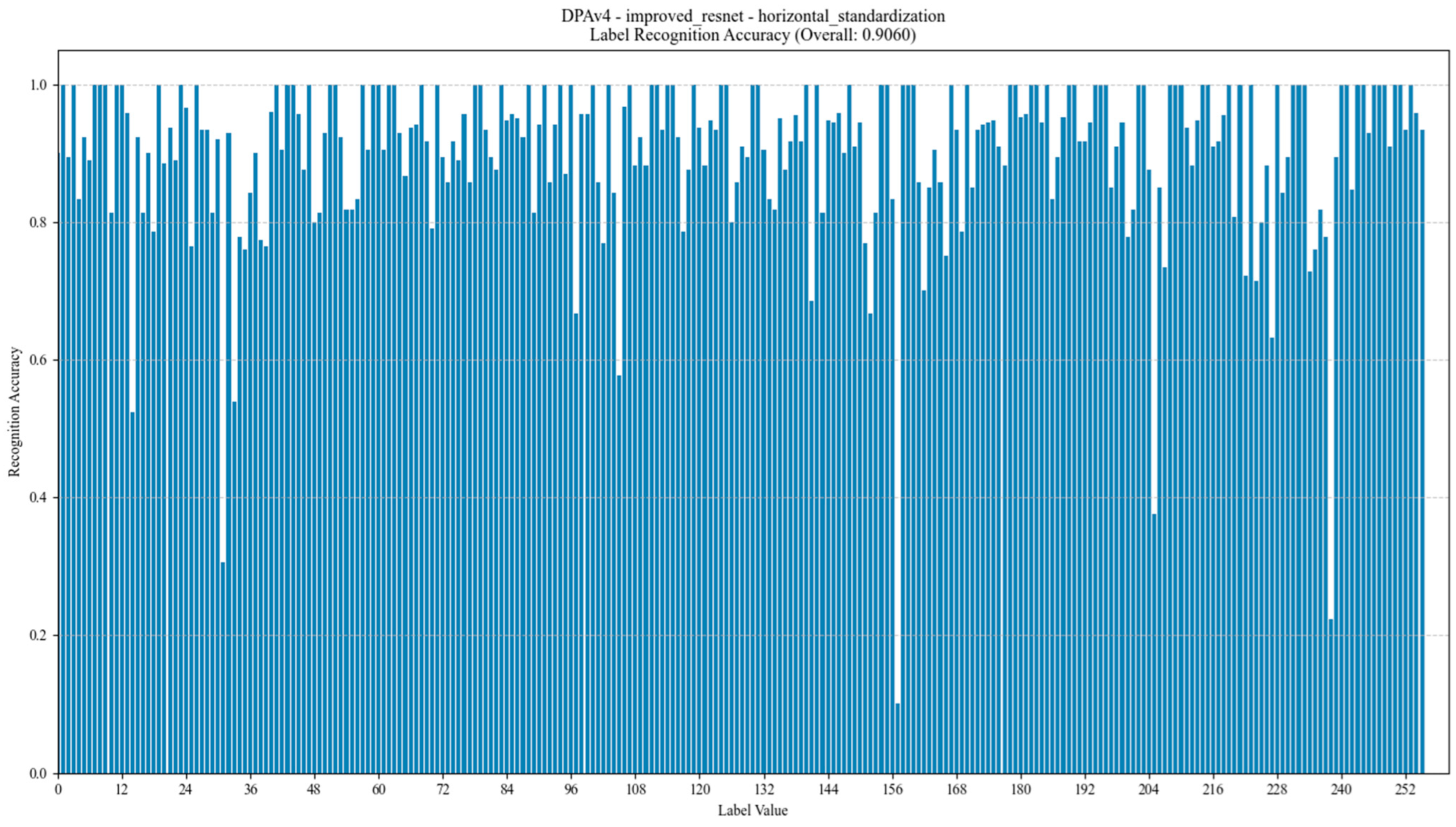
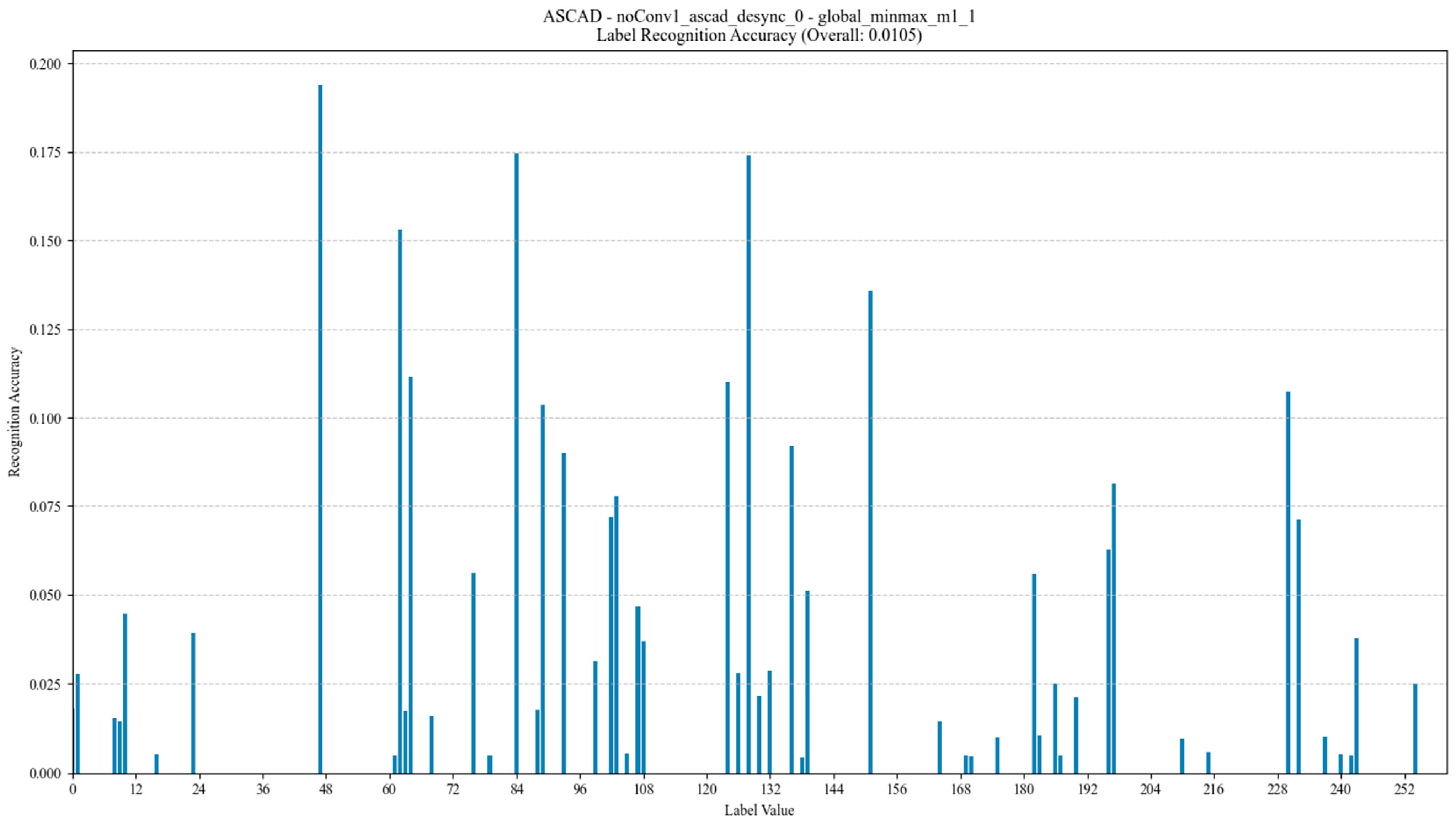
- An uneven distribution of labels is the main problem affecting model training performance, especially in the DPA_v4 and ASCAD datasets, where the distribution of labels shows a long-tail effect. For example, in the DPA_v4 dataset, the number of samples for label 14 is 10,000, while the number of labels other labels is only about 1000, leading to poor model training with a small number of labels. The ASCAD dataset also suffers from the problem of uneven labeling, and even though it has a large number of samples (up to 50,000), there is still a problem consisting of a small number of samples for some labels, leading to a significant degradation in the performance of the deep learning model, especially when making predictions on samples with few labels with low accuracy.
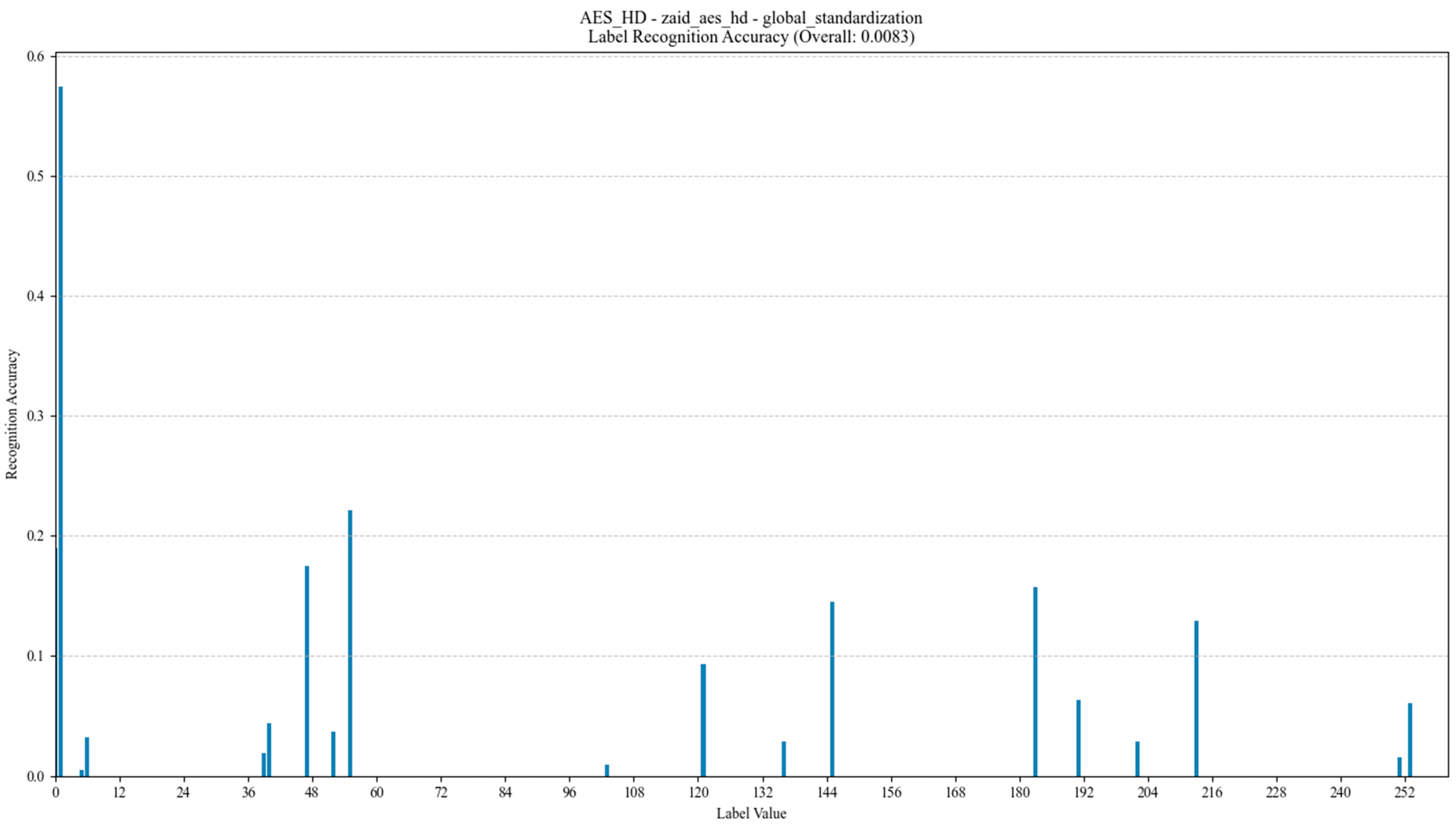
- Noise level has a significant impact on model training. The AES_RD and AES_HD datasets are noisy, which makes deep learning model training more challenging. Taking the AES_RD dataset as an example, even though it contains 25,000 samples, the training of the model is significantly affected by the high percentage of noise, especially for labels with higher accuracy (e.g., Label 14), where the model accuracy stays high, but for noisy labels, the accuracy is low.
- A balance between sample size and feature dimensionality is crucial for model training. Although the sample sizes of the Grizzly and Panda2018 datasets are relatively small (448,266 and 1044 samples, respectively), they provide high-quality feature data, making them more suitable for training low-complexity models. In contrast, the AES_HD and ASCAD datasets provide a large number of samples (e.g., 50,000 samples for AES_HD) and are suitable for training deep learning models, but they still suffer from label imbalance and feature inconsistency.
- Standardization of datasets will yield better results, especially for the AES_RD, AES_HD, and ASCAD datasets, and their curve processing is the most standardized and better suited for the application of deep learning techniques.
3.2. Overfitting Analysis of CNNs and Transformers
3.3. Feature Statistical Analysis
4. Experiments and Analysis
- In terms of data collection, the nature of the task should be taken into account, and failure to consider a uniformly homogeneous distribution of the number of labeled samples will pose the problem of guessing distortion.
- In preprocessing integration, the reason why the preprocessing of feature scales was effective in previous studies is also because of the relevant computation work on the valid labeled samples corresponding to the validation set.
- In terms of model training, the continuation of batch_valid_loss from previous work creates problems. Meanwhile, if we continue to refer to the conventional practices in other areas of deep learning, the experimental practice of slicing the dataset by 90% for the training set and 10% for the validation set will lead to a local optimum of the model. Therefore, the test set should not be biased, and a uniform number of test data should be acquired for accuracy.
- In the case of data label complementation, the corresponding intermediate value leakage should be collected against the missing part of the number of label feature samples to achieve a uniform homogeneous distribution.
- Change the model training process to complete training on the whole dataset, without distinguishing between the test set and validation set, and fixedly train the model for 500 epochs to observe the model’s accuracy performance on the whole dataset. Then, align the dataset again, removing redundant samples and eliminating long-tailed data, and train the new model for 500 epochs to observe the change in accuracy.
- Change the model training scheme from the batch_valid_loss in the original training process to the average loss per round on the whole validation set, train it for 500 epochs, store the model with the lowest valid_loss, and observe the model’s accuracy performance on the whole dataset. Then, align the dataset again by removing redundant samples and eliminating long-tailed data, and train the new model for 500 epochs to observe the effect on accuracy.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- DPA Contest. Available online: https://dpacontest.telecom-paris.fr/index.php (accessed on 10 August 2008).
- Clavier, C.; Danger, J.-L.; Duc, G.; Elaabid, M.A.; Gérard, B.; Guilley, S.; Heuser, A.; Kasper, M.; Li, Y.; Lomné, V.; et al. Practical improvements of side-channel attacks on AES: Feedback from the 2nd DPA contest. J. Cryptogr. Eng. 2014, 4, 259–274. [Google Scholar] [CrossRef]
- DPA contest v3. Available online: https://dpacontest.telecom-paris.fr/v3/index.php (accessed on 31 July 2012).
- DPA contest_v4. Available online: https://dpacontest.telecom-paris.fr/v4/index.php (accessed on 9 July 2013).
- Bhasin, S.; Bruneau, N.; Danger, J.-L.; Guilley, S.; Najm, Z. Analysis and Improvements of the DPA Contest v4 Implementation. In Proceedings of the Security, Privacy, and Applied Cryptography Engineering, Pune, India, 18–22 October 2014; Springer: Cham, Switzerland, 2014; pp. 201–218. [Google Scholar]
- Jean-S’ebastien, C.; Ilya, K. AES_RD: Randomdelays-Traces. Available online: https://github.com/ikizhvatov/randomdelays-traces (accessed on 14 April 2021).
- Coron, J.-S.; Kizhvatov, I. An Efficient Method for Random Delay Generation in Embedded Software. IACR Cryptol. ePrint Arch. 2009, 2009, 419. [Google Scholar] [CrossRef]
- Shivam Bhasin, D.J.; Picek, S.; AES_HD. Github Repository. Available online: https://github.com/AESHD/AES_HD_Dataset (accessed on 13 July 2018).
- Shivam Bhasin, D.J.; Picek, S. AES HD Dataset—500,000 Traces. Github Repository. Available online: https://github.com/AISyLab/AES_HD (accessed on 2 December 2020).
- Northeastern University TeSCASE Dataset. Available online: https://chest.coe.neu.edu/ (accessed on 1 January 2016).
- Choudary, M.O.; Kuhn, M.G. Grizzly: Power-Analysis Traces for an 8-Bit Load Instruction. Available online: http://www.cl.cam.ac.uk/research/security/datasets/grizzly/ (accessed on 22 December 2017).
- PANDA-2018. Panda 2018 Challenge1. Available online: https://github.com/kistoday/Panda2018 (accessed on 17 June 2019).
- Benadjila, R.; Prouff, E.; Junwei, W. ASCAD (ANSSI SCA Database). Available online: https://github.com/ANSSI-FR/ASCAD (accessed on 9 June 2021).
- Prouff, E.; Strullu, R.; Benadjila, R.; Cagli, E.; Canovas, C. Study of Deep Learning Techniques for Side-Channel Analysis and Introduction to ASCAD Database. IACR Cryptol. ePrint Arch. 2018, 2018, 53. [Google Scholar]
- Egger, M.; Schamberger, T.; Tebelmann, L.; Lippert, F.; Sigl, G. A Second Look at the ASCAD Databases. In Proceedings of the Constructive Side-Channel Analysis and Secure Design, Leuven, Belgium, 11–12 April 2022; Springer: Cham, Switzerland, 2022; pp. 75–99. [Google Scholar] [CrossRef]
- Riscure. CHES CTF. 2018. Available online: https://github.com/agohr/ches2018 (accessed on 30 January 2019).
- Gohr, A.; Laus, F.; Schindler, W. Breaking Masked Implementations of the Clyde-Cipher by Means of Side-Channel Analysis—A Report on the CHES Challenge Side-Channel Contest 2020. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2022, 2022, 397–437. [Google Scholar] [CrossRef]
- Bhasin, S.; Chattopadhyay, A.; Heuser, A.; Jap, D.; Picek, S.; Shrivastwa, R.R. Portability Dataset. Available online: http://aisylabdatasets.ewi.tudelft.nl/ (accessed on 1 January 2020).
- Weissbart, L.; Picek, S.; Batina, L. One Trace Is All It Takes: Machine Learning-Based Side-Channel Attack on EdDSA; Springer: Cham, Switzerland, 2019; pp. 86–105. [Google Scholar]
- Léo Weissbart, S.P.; Batina, L. Ed25519 WolfSSL.Github Repository. Available online: https://github.com/leoweissbart/MachineLearningBasedSideChannelAttackonEdDSA (accessed on 16 August 2019).
- Chmielewski, Ł. REASSURE (H2020 731591) ECC Dataset. Available online: https://zenodo.org/records/3609789 (accessed on 16 January 2020).
- Léo Weissbart, Ł.C.; Picek, S.; Batina, L.; Curve25519 Datasets. Dropbox. Available online: https://www.dropbox.com/s/e2mlegb71qp4em3/ecc_datasets.zip?dl=0 (accessed on 13 October 2020).
- Weissbart, L.; Chmielewski, Ł.; Picek, S.; Batina, L. Systematic Side-Channel Analysis of Curve25519 with Machine Learning. J. Hardw. Syst. Secur. 2020, 4, 314–328. [Google Scholar] [CrossRef]
- DPA Contest v4.1. Available online: https://dpacontest.telecom-paris.fr/v4/rsm_doc.php (accessed on 12 March 2012).
- DPA Contest_v4.2. Available online: https://dpacontest.telecom-paris.fr/v4/42_doc.php (accessed on 20 July 2015).
- Kim, J.; Picek, S.; Heuser, A.; Bhasin, S.; Hanjalic, A. Make Some Noise. Unleashing the Power of Convolutional Neural Networks for Profiled Side-channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 148–179. [Google Scholar] [CrossRef]
- Maghrebi, H. Deep Learning based Side Channel Attacks in Practice. IACR Cryptol. ePrint Arch. 2019, 2019, 578. [Google Scholar]
- Benadjila, R.; Prouff, E.; Strullu, R.; Cagli, E.; Dumas, C. Deep learning for side-channel analysis and introduction to ASCAD database. J. Cryptogr. Eng. 2020, 10, 163–188. [Google Scholar] [CrossRef]
- Paguada, S.; Armendariz, I. The Forgotten Hyperparameter: Introducing Dilated Convolution for Boosting CNN-Based Side-Channel Attacks. In Proceedings of the Applied Cryptography and Network Security Workshops: ACNS 2020 Satellite Workshops, AIBlock, AIHWS, AIoTS, Cloud S&P, SCI, SecMT, and SiMLA, Rome, Italy, 19–22 October 2020; Proceedings. Springer: Rome, Italy, 2020; pp. 217–236. [Google Scholar] [CrossRef]
- Gabriel Zaid, L.B.; Habrard, A.; Venelli, A. Methodology for Efficient CNN Architectures in Profiling Attacks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2020, 1–36. [Google Scholar] [CrossRef]
- Wouters, L.; Arribas, V.; Gierlichs, B.; Preneel, B. Revisiting a Methodology for Efficient CNN Architectures in Profiling Attacks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 147–168. [Google Scholar] [CrossRef]
- Yuanyuan, Z.; François-Xavier, S. Deep learning mitigates but does not annihilate the need of aligned traces and a generalized ResNet model for side-channel attacks. J. Cryptogr. Eng. 2020, 10, 85–95. [Google Scholar] [CrossRef]
- Xiangjun, L.; Chi, Z.; Pei, C.; Dawu, G.; Haining, L. Pay Attention to Raw Traces: A Deep Learning Architecture for End-to-End Profiling Attacks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 2021, 235–274. [Google Scholar] [CrossRef]
- Yoo-Seung, W.; Xiaolu, H.; Dirmanto, J.; Jakub, B.; Shivam, B. Back to the Basics: Seamless Integration of Side-Channel Pre-Processing in Deep Neural Networks. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3215–3227. [Google Scholar] [CrossRef]
- Hajra, S.; Saha, S.; Alam, M.; Mukhopadhyay, D. TransNet: Shift Invariant Transformer Network for Side Channel Analysis; Springer: Cham, Switzerland, 2022; pp. 371–396. [Google Scholar] [CrossRef]
- Pei, C.; Chi, Z.; Xiangjun, L.; Dawu, G.; Sen, X. Improving Deep Learning Based Second-Order Side-Channel Analysis With Bilinear CNN. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3863–3876. [Google Scholar] [CrossRef]
- Hajra, S.; Chowdhury, S.; Mukhopadhyay, D. EstraNet: An Efficient Shift-Invariant Transformer Network for Side-Channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2023, 2024, 336–374. [Google Scholar] [CrossRef]
- Picek, S.; Samiotis, I.P.; Heuser, A.; Kim, J.; Bhasin, S.; Legay, A. On the Performance of Deep Learning for Side-channel Analysis. IACR Cryptol. ePrint Arch. 2018, 2018, 4. [Google Scholar]
- Doan, M.L. Volatility and Risk Assessment of Blockchain Cryptocurrencies Using GARCH Modeling: An Analytical Study on Dogecoin, Polygon, and Solana. J. Digit. Mark. Digit. Curr. 2025, 2, 93–113. [Google Scholar] [CrossRef]
- Wang, C.; He, S.; Wu, M.; Lam, S.-K.; Tiwari, P.; Gao, X. Looking Clearer with Text: A Hierarchical Context Blending Network for Occluded Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2025, 20, 4296–4307. [Google Scholar] [CrossRef]
- Wang, C.; Cao, R.; Wang, R. Learning discriminative topological structure information representation for 2D shape and social network classification via persistent homology. Knowl.-Based Syst. 2025, 311, 113125. [Google Scholar] [CrossRef]
- Yadulla, A.R.; Maturi, M.H.; Meduri, K.; Nadella, G.S. Sales Trends and Price Determinants in the Virtual Property Market: Insights from Blockchain-Based Platforms. Int. J. Res. Metaverse 2024, 1, 113–126. [Google Scholar] [CrossRef]
- Wahyuningsih, T.; Chen, S.C. Analyzing sentiment trends and patterns in bitcoin-related tweets using TF-IDF vectorization and k-means clustering. J. Curr. Res. Blockchain 2024, 1, 48–69. [Google Scholar] [CrossRef]
- Wahyuningsih, T.; Chen, S.C. Determinants of Virtual Property Prices in Decentraland an Empirical Analysis of Market Dynamics and Cryptocurrency Influence. Int. J. Res. Metaverse 2024, 1, 157–171. [Google Scholar] [CrossRef]

















| Targeted Chip Devices | Cryptographic | Type of Analysis | Name of Data Set | Traces (Features) | Time | |
|---|---|---|---|---|---|---|
| 1 | SASEBO-W | AES-256 RSM | Electromagnetic | DPA contest_v4.1 [24] | 100,000 (5000/4000) | 2014 |
| ATMega-163 | AES-128 RSM | Electromagnetic | DPA contest_v4.2 [25] | 80,000 (1,704,400) | 2015 | |
| 2 | 8-bit Atmel AVR | Protected AES | Power consumption | AES_RD [6] | 50,000 (3500) | 2009 |
| 3 | 8-bit CPU Atmel XMEGA 256 A3U | AES-128 | Power consumption | Grizzly [11] | - | 2013 – 2017 |
| Grizzly: Panda | - | |||||
| 4 | AT89S52 | AES-128 | Power consumption | Panda 2018 Challenge1 [12] | - | 2018 |
| 5 | STM32 | AES-128 | Electromagnetic | CHES_CTF2018 [16] | 42,000 (650,000) | 2018 |
| 6 | ATMega | AES-128 | Electromagnetic | ASCAD [13] (ASCADf, ASCADv1, ASCADv2) | 60,000 (100,000) | 2018 |
| ATMega | AES-128 | Electromagnetic | 300,000 (250,000) | 2018 | ||
| STM32 | AES-128 | Electromagnetic | 810,000 (1,000,000) | 2021 | ||
| 7 | Atmel Mega | AES-128 | Electromagnetic | Portability [18] | 50,000 (600) | 2020 |
| 8 | STM32 | EdDSA | Electromagnetic | Ed25519 (WolfSSL) [20] | 6400 (1000) | 2019 |
| STM32 | EdDSA | Electromagnetic | Curve25519 (μNaCL) [21] | 5997 (5500) | 2020 | |
| STM32 | EdDSA | Electromagnetic | Curve25519 [22] | 300 (8000) | 2020 | |
| STM32 | EdDSA | Electromagnetic | Curve25519 [22] | 300 (1000) | 2020 |
| Targeted Chip Devices | Cryptographic | Type of Analysis | Name of Data Set | Traces (Features) | Time | |
|---|---|---|---|---|---|---|
| 1 | SASEBO-GII | DES AES-128 | Electromagnetic | DPA contest_v1 [1] | - | 2008 – 2014 |
| DPA contest_v2 [1] | 100,000 (3253) | |||||
| DPA contest_v3 [3] | - | |||||
| 2 | SASEBO-GII | AES-128 | Power consumption Electromagnetic | AES_HD [8] | 50,000 (1250) | 2018 |
| 3 | SASEBO-GII | AES-128 MAC-Keccak | Power consumption Electromagnetic | TeSCASE [10] (AES_HD_MM) | 5,600,000 (3500) | 2014 – 2016 |
| Nvidia TeslaC2070 Nvidia Kepler K40 | AES | - | ||||
| ARM Cortex M0+ | ECC | - | ||||
| 4 | Hardware | Clyde128 | CHES_CTF_2020 [17] | + | 2020 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Li, W.; Cao, X.; Fu, Y.; Wu, J.; Liu, J.; Chen, A.; Zhang, Y.; Wang, S.; Zhou, J. Full-Element Analysis of Side-Channel Leakage Dataset on Symmetric Cryptographic Advanced Encryption Standard. Symmetry 2025, 17, 769. https://doi.org/10.3390/sym17050769
Liu W, Li W, Cao X, Fu Y, Wu J, Liu J, Chen A, Zhang Y, Wang S, Zhou J. Full-Element Analysis of Side-Channel Leakage Dataset on Symmetric Cryptographic Advanced Encryption Standard. Symmetry. 2025; 17(5):769. https://doi.org/10.3390/sym17050769
Chicago/Turabian StyleLiu, Weifeng, Wenchang Li, Xiaodong Cao, Yihao Fu, Juping Wu, Jian Liu, Aidong Chen, Yanlong Zhang, Shuo Wang, and Jing Zhou. 2025. "Full-Element Analysis of Side-Channel Leakage Dataset on Symmetric Cryptographic Advanced Encryption Standard" Symmetry 17, no. 5: 769. https://doi.org/10.3390/sym17050769
APA StyleLiu, W., Li, W., Cao, X., Fu, Y., Wu, J., Liu, J., Chen, A., Zhang, Y., Wang, S., & Zhou, J. (2025). Full-Element Analysis of Side-Channel Leakage Dataset on Symmetric Cryptographic Advanced Encryption Standard. Symmetry, 17(5), 769. https://doi.org/10.3390/sym17050769