1. Introduction
Student engagement within online learning is an issue that teachers and parents have been paying close attention to [
1,
2]. Students who actively engage in learning activities are more likely to gain profound learning experiences and better academic achievements [
3,
4,
5,
6]. However, due to the separation of time and space between teachers and students during the online learning process, it is rather difficult for teachers to promptly perceive changes in students’ engagement. Meanwhile, students are highly susceptible to the interference of the external learning environment during online learning, which poses a challenge to their ability to maintain attention for a long period. As an important external manifestation of engagement, facial expressions can intuitively reflect students’ learning status and interest [
7]. Through the precise identification and analysis of these facial cues, it is possible to deduce the engagement levels of students.
Human facial emotional expressions are achieved through the synergistic actions of complex facial action units (AUs). For instance, AU1 represents the raising of eyebrows, AU6 represents the constriction of eyes, and AU12 represents the stretching of the corners of the mouth. Combinations of these AUs constitute a rich variety of facial expressions. However, when a person only raises one side of the mouth when expressing happiness or only lifts one eyebrow when expressing surprise, such asymmetry is a natural characteristic of emotional expression. Therefore, recognizing these asymmetric expressions is of great significance for understanding students’ genuine emotional states. Moreover, as students participate in online learning for relatively long periods, they will inevitably occasionally deviate from the field of view of the camera, revealing the side or partial contour of their faces. Such deviations can also lead to asymmetry in the facial presentation within the images, further intensifying the complexity of facial emotion recognition (FER) and posing a tremendous challenge to the precise identification of facial emotions.
In recent years, deep learning technologies have made significant progress in tasks such as feature extraction, classification, and recognition. In the field of computer vision, deep learning has been widely applied to tasks like object recognition, face detection, and emotion detection. With the rapid development of artificial intelligence (AI) and the widespread application of big data, the role of facial expression recognition in the teaching and learning process has become increasingly prominent, attracting the attention of more and more researchers [
8,
9]. Deep learning-based facial expression recognition technology enables “end-to-end” learning, directly extracting features from input images, which reduces human intervention and lowers the complexity of feature selection and extraction. Relying on this technology, teachers can more accurately understand the learning emotions of each student, adjust teaching strategies in a timely manner, and enhance student engagement and learning outcomes [
10,
11]. Therefore, developing an automatic facial expression recognition system for students is of great significance for improving the quality of education and the learning experience.
Meanwhile, the You Only Look Once (YOLO) series of models, an efficient real-time object detection framework, has been widely applied in fields such as autonomous driving and surveillance. Introduced by Redmon et al. [
12] in 2016, YOLO treats object detection as a single regression problem, directly predicting bounding boxes and class probabilities from images. This design enables YOLO to perform exceptionally well in both training and inference, allowing for the rapid identification of multiple objects within an image. However, YOLO still faces challenges in detecting small objects, dealing with complex backgrounds, and handling occlusions [
13]. For instance, poorly designed anchor boxes may lead to missed detections of small objects, noise in complex backgrounds can interfere with object detection, and partially occluded objects may be misdetected or missed due to reliance on anchor boxes and non-maximum suppression (NMS). Moreover, to maintain real-time performance, YOLO may sacrifice adaptability to new data distributions, thereby reducing detection accuracy and robustness [
14].
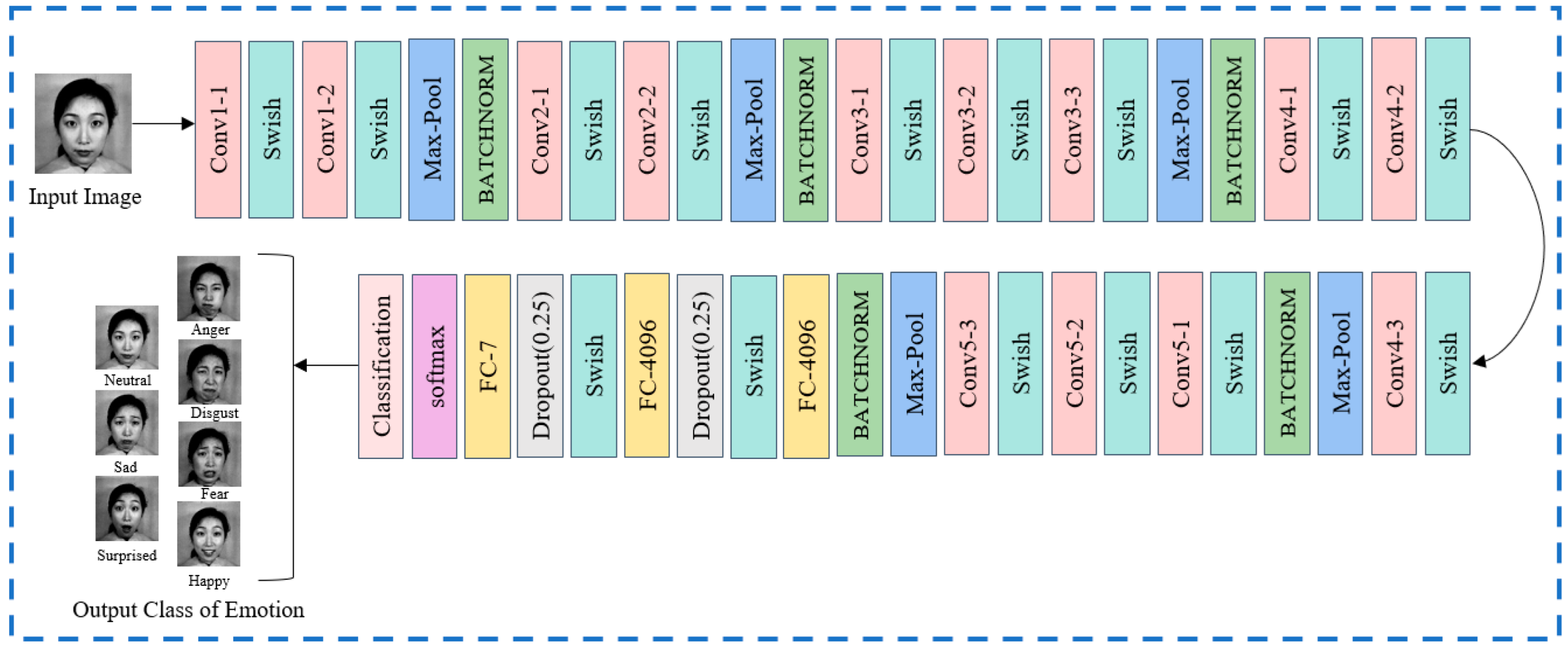
Based on these considerations, a novel VGG-SwishNet deep learning model is proposed, which can automatically detect seven types of facial emotions using the facial images in the dataset, and it is particularly proficient in identifying asymmetric emotions caused by facial expressions themselves and postures. The proposed model adopts the pre-trained visual geometry group 16 (VGG-16) architecture, combines it with transfer learning (TL) techniques, and introduces the Swish activation function and batch normalization (BN) layers into the model. TL strategies not only leverage the robust feature extraction capabilities of the VGG-16 model but also empower it to learn meaningful feature representations from new datasets. BN layers reduce internal covariate shifts, ensuring the stability of data distribution, which facilitates effective gradient propagation in subsequent layers. Furthermore, it accelerates the model’s training process, enhancing the convergence speed and overall stability of the model [
15].
The Swish activation function was proposed in 2017 and has drawn widespread attention in the field of deep learning [
16]. Compared to traditional activation functions, it allows for smoother nonlinear mapping and can automatically adjust its degree of nonlinearity through a self-gating mechanism, thereby helping to mitigate the vanishing gradient problem. When dealing with the asymmetry caused by facial postures, its nonlinear characteristics can assist the model in more effectively extracting complex asymmetric features under different postures, such as the changes in facial contours and facial features when the face is in profile. Regarding the asymmetry of facial expressions themselves, the smoothness of the Swish activation function enables the model to more accurately capture subtle differences in expressions, such as a raised corner of the mouth or a drooping eyelid. Therefore, the Swish activation function has a significant advantage in recognizing asymmetric facial expressions. In addition, dropout layers with a rate of 0.25 are incorporated to prevent model overfitting. Finally, the performance of the proposed model was evaluated on benchmark datasets and compared with the engagement detection and real-time performance of five different versions of the YOLOv9 model (YOLOv9t, YOLOv9s, YOLOv9m, YOLOv9c, and YOLOv9e) and the ViT-Base/16 model in online learning environments.
The general contributions of the paper can be outlined as follows:
- (i)
A novel and effective VGG-SwishNet model is proposed, which introduces the Swish activation function and BN layers based on the original VGG-16 model to improve the recognition capabilities for asymmetric facial emotions.
- (ii)
The proposed VGG-SwishNet model is applied to multi-face engagement detection in online learning environments, with visualization results provided. Additionally, the accuracy of the proposed model in engagement detection is validated through qualitative research methods involving semi-structured interviews.
The rest of this paper is organized as follows:
Section 2 presents a brief review of existing FER and engagement detection methods.
Section 3 provides a preliminary overview of the convolutional neural network (CNN), the VGG-16 model, TL, and Swish activation function; explains the architecture for engagement detection based on FER as well as the proposed VGG-SwishNet model; and describes the benchmark datasets and performance metrics used in the experiments.
Section 4 offers a detailed explanation of image preprocessing and experimental setup and provides a thorough discussion and comparative analysis of performance evaluations on benchmark datasets, as well as the results and related issues concerning online engagement detection.
Section 5 concludes the paper with a discussion of potential directions for future research.
5. Conclusions
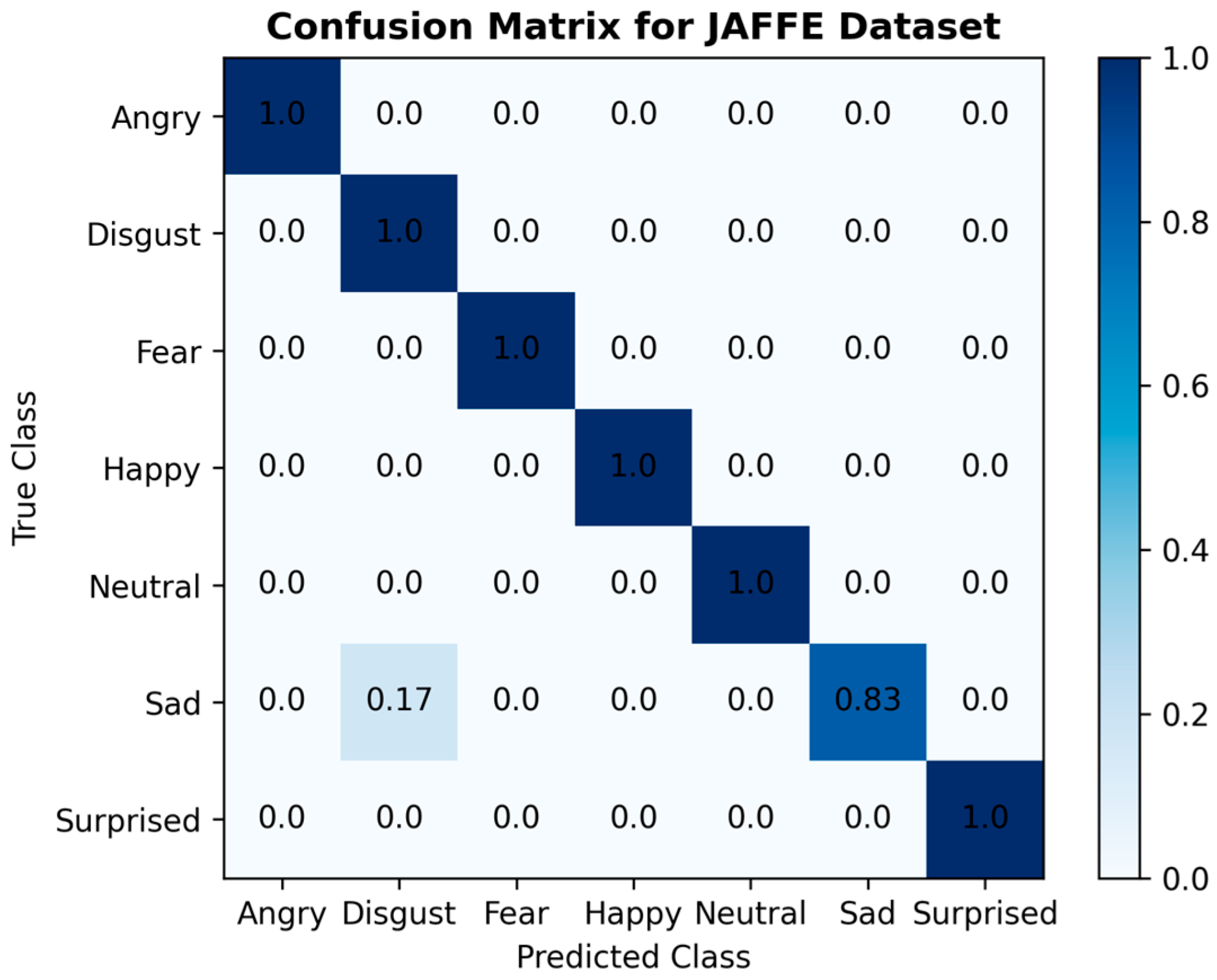
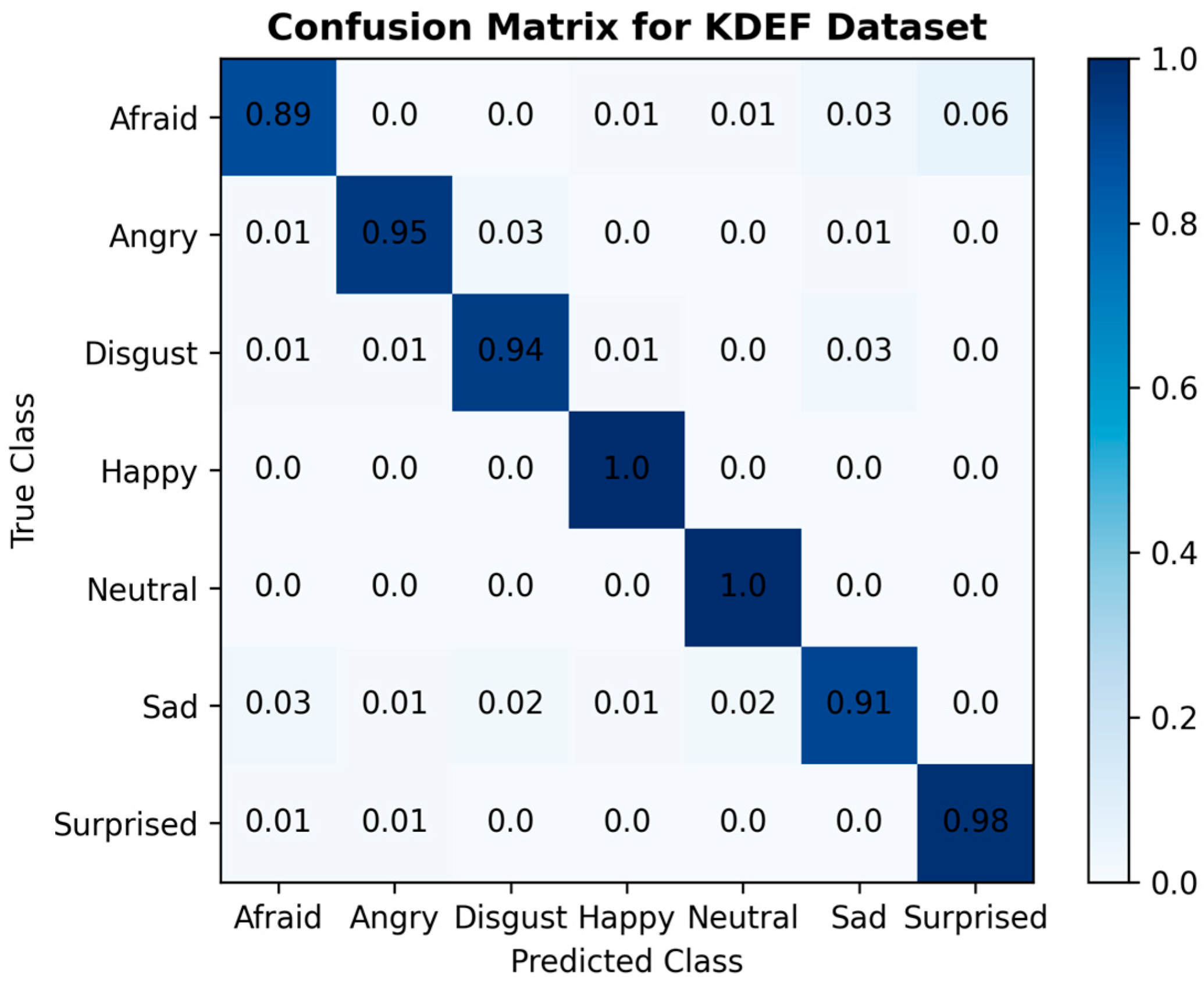
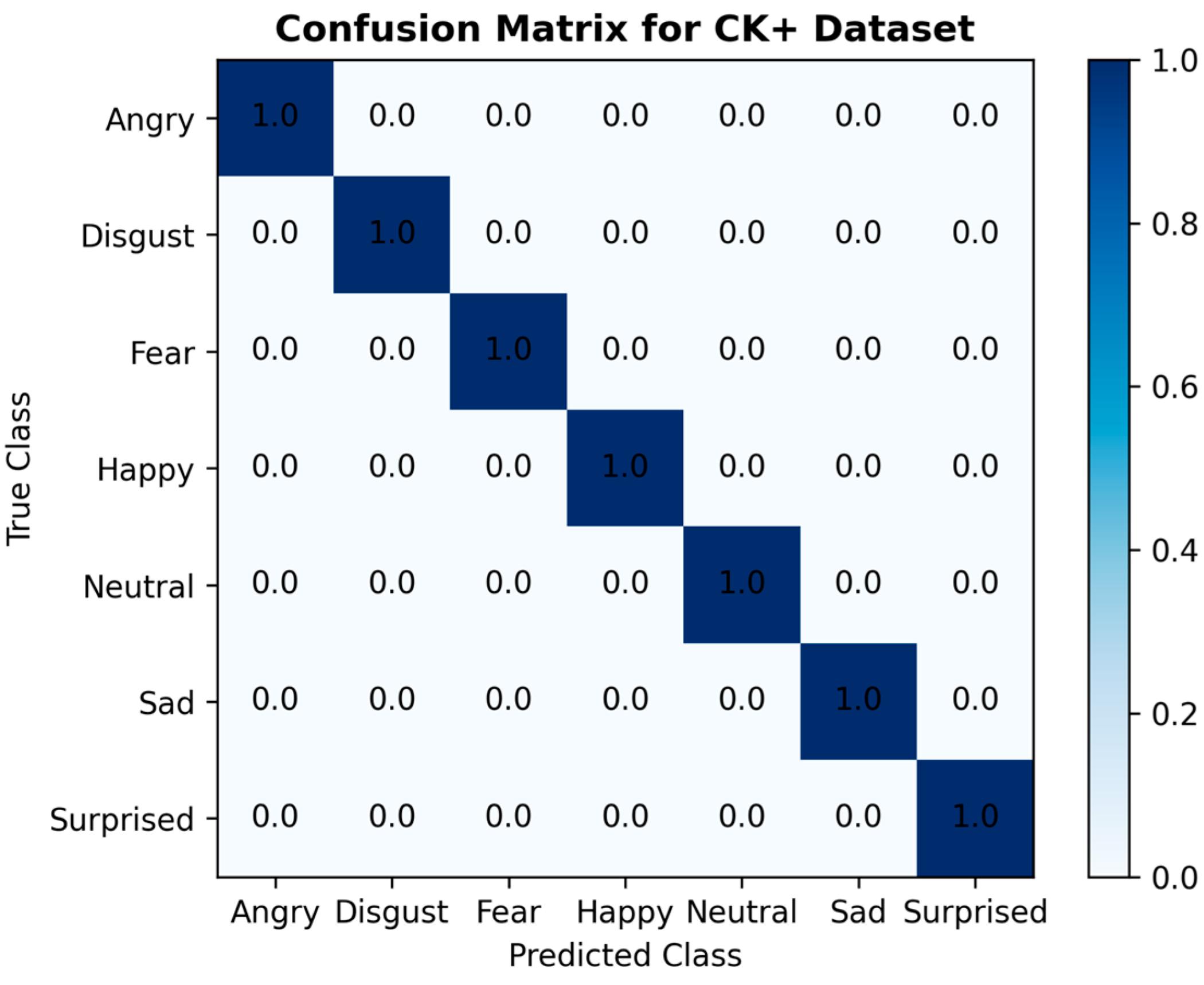
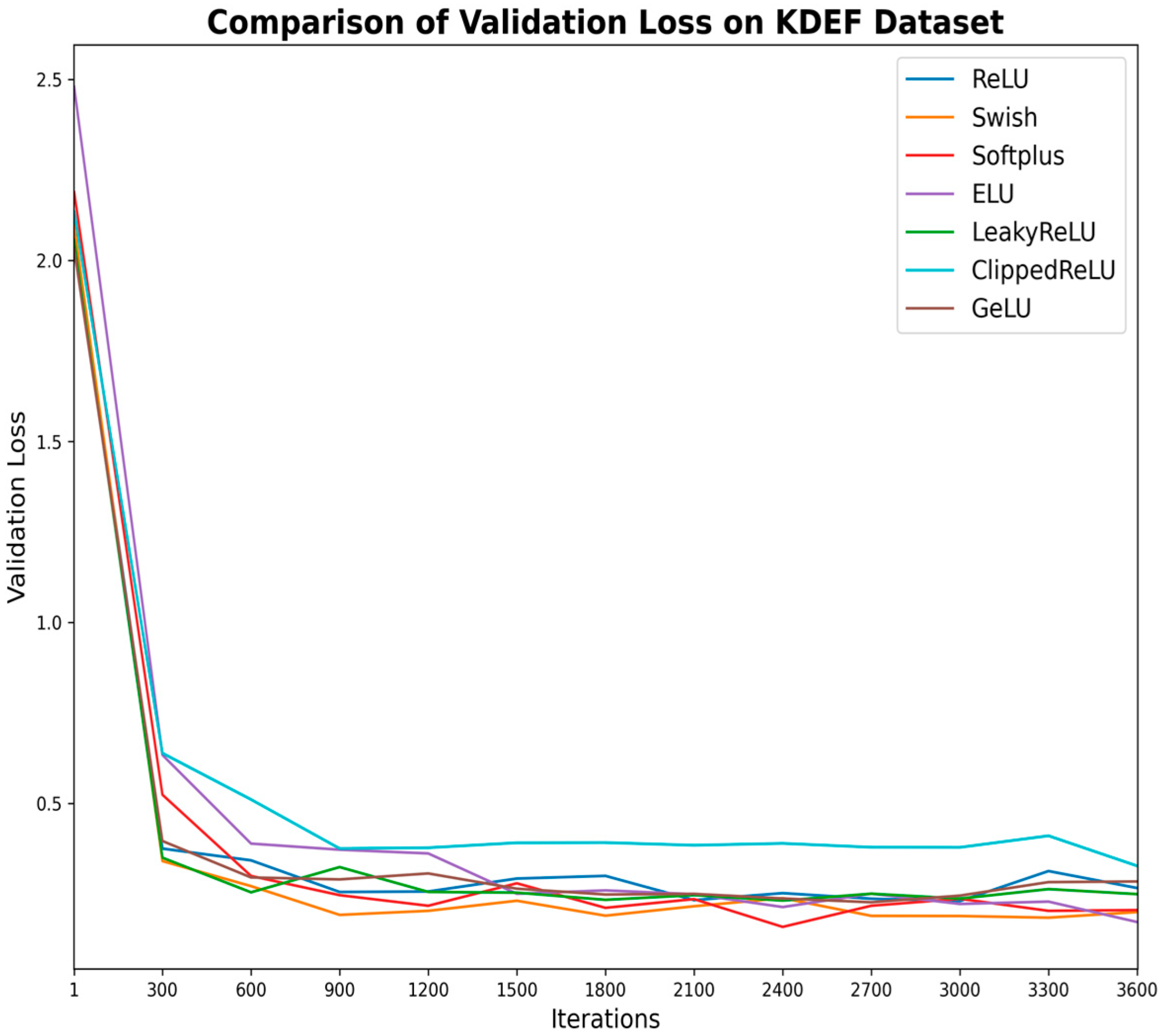
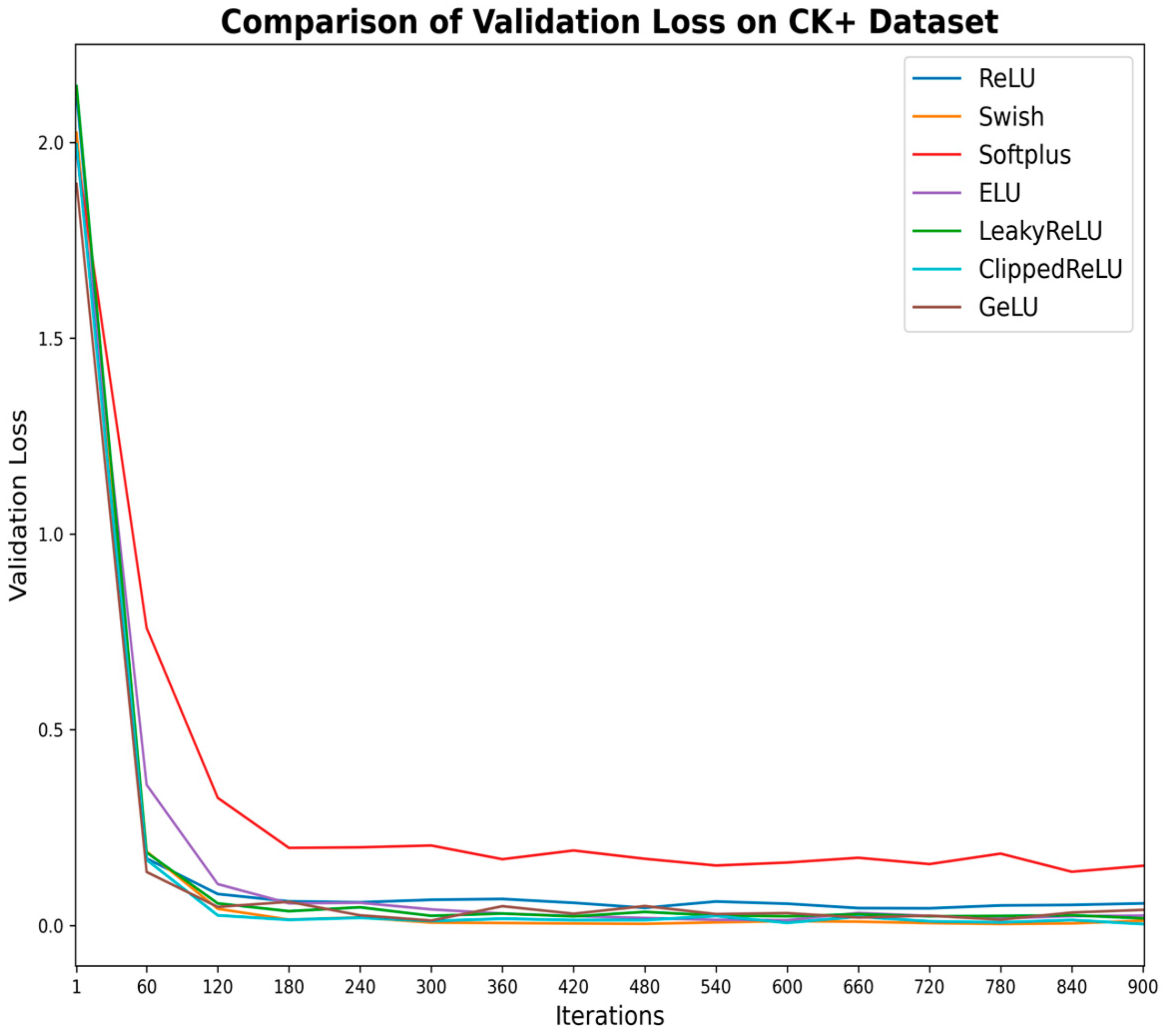
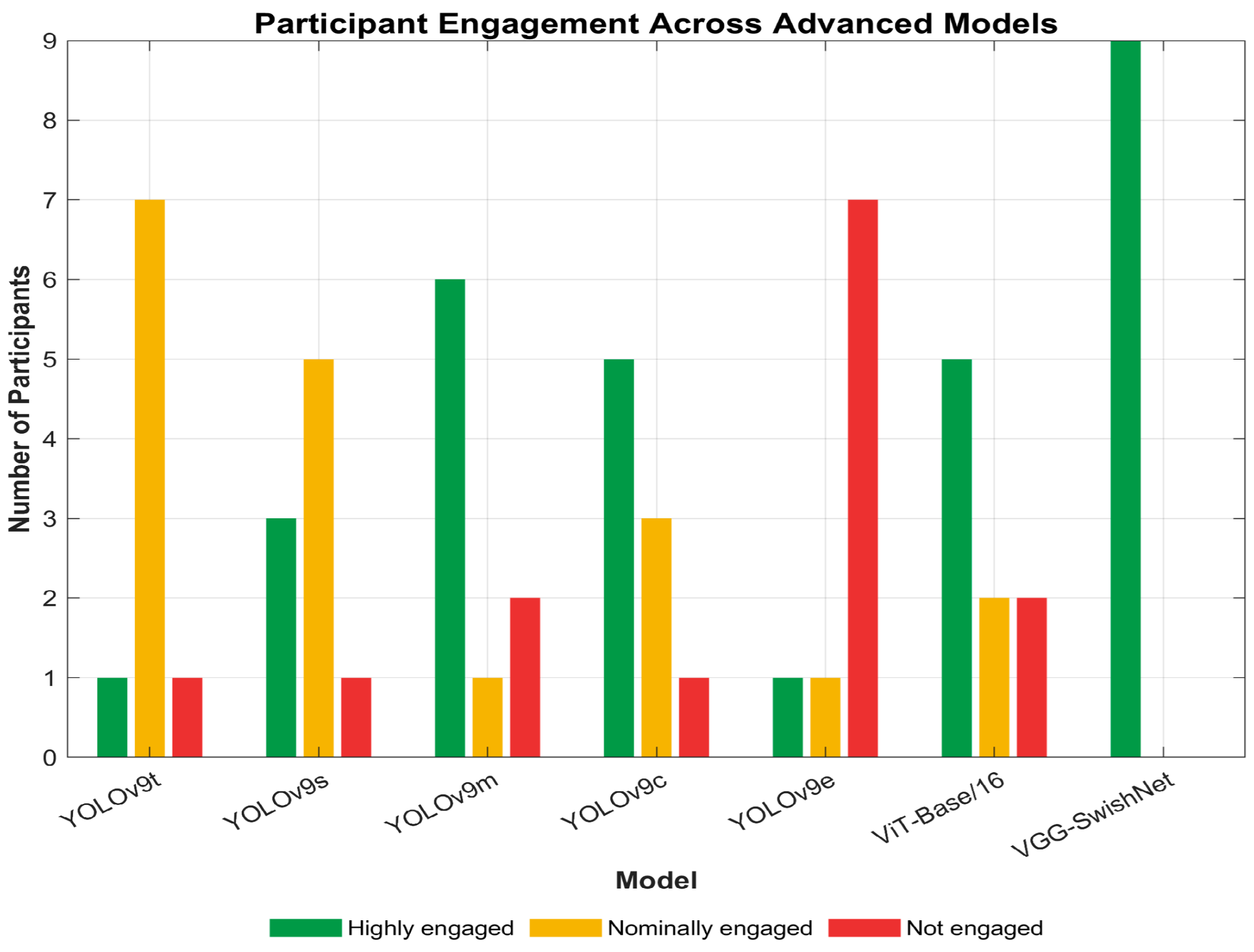
Comprehending the extent of student engagement in online learning environments is crucial for improving teachers’ online teaching strategies and enhancing students’ online learning experiences. This paper proposed a novel VGG-SwishNet model, which combines the VGG-16 architecture with the Swish activation function for the task of facial expression recognition. This integration fully leverages the powerful feature extraction capabilities of VGG-16 and the smoothness and self-gating mechanism of the Swish activation function, significantly enhancing the model’s performance. The incorporation of the Swish activation function aids in alleviating the vanishing gradient problem, thereby enabling the model to more effectively capture subtle and asymmetric features within facial expressions. This aspect has received less attention in previous studies but is a crucial issue in facial expression recognition. The proposed model was evaluated on the JAFFE, KDEF, and CK+ datasets, with both 80–20% splitting and 10-fold CV being employed. The results indicate that under both validation methods, the model achieved the best test accuracy of over 95% on all three datasets, demonstrating excellent robustness and competitiveness. Building on the accurate identification of each emotion using the proposed method, student engagement levels were assessed by integrating the corresponding weights of each emotion and categorizing them into three tiers: “Highly engaged”, “Nominally engaged”, and “Not engaged”.
The proposed approach was tested on nine students in an online learning environment, combining the results with semi-structured interviews, and the effectiveness of the VGG-SwishNet model in recognizing emotions and detecting engagement levels online was confirmed. Moreover, the VGG-SwishNet model is not only applicable to facial expression recognition tasks but can also be extended to other multi-class problems that require processing asymmetric features, such as identifying asymmetric tumor characteristics in the field of medical image recognition. In future research, we will also continue to explore more lightweight versions of the model. Specifically, we plan to utilize well-known lightweight network architectures, such as MobileNet and EfficientNet. By integrating these lightweight architectures into the proposed model, we aim to reduce the number of model parameters and computational complexity while further improving its scalability in online learning environments. At the same time, we are also aware of some limitations in this study. For example, the datasets used in the experiment (JAFFE, KDEF, and CK+) have a relatively small number of samples and are strictly controlled, which may not fully reflect the complexity of real-world online learning environments. Therefore, based on the model proposed in this study, we plan to establish a facial expression recognition system in a real online learning environment. During this process, we will collect real-world data to establish a facial expression dataset for online learning, thereby further enhancing the accuracy of student facial expression recognition in online learning environments.
In this study, the primary focus has been on developing a novel VGG-SwishNet model that can automatically and accurately detect students’ facial expressions during online learning. To validate the effectiveness of our proposed method, its performance was first comprehensively evaluated. Subsequently, the model was applied to engagement detection, and its practical effectiveness was further validated through semi-structured interviews. Moreover, comparisons with different variants of the YOLOv9 model and the ViT-Base/16 model have also confirmed that the proposed method has significant advantages in terms of engagement detection accuracy and computational efficiency in the context of online learning. However, it is also deeply recognized that this is merely a preliminary exploration. In future research, we plan to develop a more comprehensive engagement assessment system. Building on the accurate recognition of facial expressions, we will incorporate additional indicators of engagement, such as head movements and eye contact, to provide a more holistic and accurate evaluation of students’ engagement in online learning. This will be an important direction for our future work. Moreover, gaining a deep understanding of how different students’ engagement varies with different learning content is also crucial as it holds significant importance for promoting personalized learning. Therefore, we will also explore the complex relationship between learning content and changes in student engagement and assess the impact of different learning conditions (such as different subjects, teaching methods, or levels of interaction) on student engagement. This will help teachers more effectively improve their teaching strategies and enhance students’ engagement in online learning.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}