1. Introduction
Discriminating between original paintings and replicas presents a significant challenge that requires the integration of diverse evidence, including historical documentation, material analysis, and stylistic comparisons. Despite the meticulous examination of these factors by art experts, definitive conclusions are frequently elusive [
1].
Over the past two decades, several computational tools have been proposed to assist experts in differentiating original paintings from replicas. These methodologies primarily rely on the analysis of artist brushstrokes [
2,
3,
4], painting textures and colors [
1,
5,
6,
7], and the geometric properties of painting shapes [
8,
9]. Among the techniques for analyzing paintings, fractal geometry has proven to be a valuable tool for characterizing artists [
10,
11,
12,
13,
14], pictorial genres [
15,
16,
17,
18], and historical periods [
19,
20,
21]. Most of these studies use the fractal dimension (FD), a quantitative metric that describes the complexity with which a shape fills its defined space [
22], to analyze the paintings. Shapes that exhibit similar patterns at increasingly smaller scales are called self-similar. Self-similarity, also known as expanding symmetry, is a property analyzed using the FD in various contexts, including the study of natural patterns [
23,
24].
Using a sliding window to process signals is a widely adopted technique across various fields [
25,
26,
27]. In cultural heritage, this technique has been used to analyze different elements, including buildings, murals, ancient manuscripts, and paintings [
28,
29,
30,
31]. The sliding window technique has recently been used to compute the fractal dimension of several types of signals, such as electroencephalograms [
32], 4D point clouds [
33], time series [
34], and medical images [
35]. However, to the best of our knowledge, the sliding window approach has not previously been used to analyze the fractal dimension of paintings.
In the present study, we address the following research questions: (1) Is the FD computed from the color information of the images a useful metric for comparing original paintings to replicas? (2) Can the sliding window technique provide a parameterizable solution that avoids the need for the manual selection of painting regions for analysis? (3) Is it possible to obtain comparable or better results than state-of-the-art techniques for forgery detection by integrating color-FD computation into a sliding window approach?
To address these questions, we introduce a novel FD-based methodology for differentiating original paintings from replicas. Recently, several new techniques have been proposed to accurately compute the FD of color images by jointly considering all color channels in the FD estimation process [
36,
37,
38]. Our approach uses one such technique for FD computation [
37] by integrating it into a sliding window process of the painting. To the best of our knowledge, this is the first color-FD-based method for distinguishing between original paintings and replicas. Moreover, our methodology does not require the manual selection of painting regions for analysis.
2. Related Work
FD has already been used to differentiate between original paintings and replicas. Taylor et al. [
8] analyzed the FD of Jackson Pollock’s paintings, comparing them to similar poured paintings created by art students. In their study, the FD was calculated separately for specific color channels within each painting (black, aluminum, gray, light yellow, and dark yellow) using the box-counting algorithm for binary images [
22]. Taylor et al. demonstrated that the FD values of Pollock’s original works exhibited a distinct pattern, meeting specific criteria that were not observed in the FD values of the student-generated paintings.
Abry et al. [
5] applied multifractal analysis [
39] to differentiate original paintings and replicas created by the same artist under identical conditions (paints, grounds, and brushes). They manually selected corresponding patches from both the original and replica, ensuring consistent spatial location. Subsequently, they calculated the multifractal parameters (
hm,
c1, and
c2) for these selected patches and statistically compared the resulting values between originals and replicas. This multifractal analysis was conducted independently for several image channels (red, green, blue, hue, saturation, lightness, and gray-level intensity). Their findings revealed significant differences in multifractal parameters for five of the seven original–replica pairs.
Recently, Shamir et al. [
7] demonstrated that the FD provides the strongest discriminatory power between authentic and non-authentic Jackson Pollock paintings, outperforming a wide range of other image metrics (including texture descriptors, color features, edge statistics, object statistics, distribution of pixel intensity values, multi-scale histograms, and Chebyshev statistics). Shamir et al. estimated the FD using the box-counting algorithm applied to the grayscale images of each painting at multiple resolutions [
40].
The FD can also be incorporated as a feature within machine learning algorithms for classifying paintings as originals or replicas, as demonstrated by Albadarneh et al. [
6]. In their approach, the painting was divided into a regular grid of patches; then, the image in each patch was binarized using a segmentation algorithm, after which the FD was computed in each binarized patch using the box-counting algorithm [
41].
Although the FD parameter has proven its efficacy as a metric for distinguishing between original paintings and replicas, previous studies have not fully utilized all the available information within each painting. Methodologies described in [
6,
8] require the binarization of the paintings, omitting color information. In [
5,
7], a broader spectrum of data from each image channel is incorporated into the fractal analysis, but only at the grayscale level. Moreover, several of these methodologies require experts to manually select painting regions for analysis [
5], preventing the automated processing of the datasets.
Alternatively, other methodologies [
1,
3,
6] use machine learning classifiers trained using features extracted from each individual patch and tested by classifying individual patches as well. Various types of features are used in these studies, such as those based on the hidden Markov tree multiresolution model in [
1], the histogram of oriented gradients technique in [
3], and the FD combined with other grayscale and texture features in [
6].
3. Material and Methods
3.1. Test Datasets
To assess the efficacy of FD in distinguishing original paintings from replicas, we used two publicly accessible datasets derived from controlled experiments. A notable feature of both datasets is that the originals and replicas were produced by the same artist under identical conditions, ensuring maximum similarity between the paintings. The images in both datasets were obtained from their authors at a very high resolution under the same acquisition conditions for original paintings and replicas, so no further pre-processing was necessary to apply our methodology to them.
The first dataset, which was created by the Machine Learning and Image Processing for Art Investigation Research Group at Princeton University (USA), can be found at
https://web.math.princeton.edu/ipai/datasets.html (accessed on 1 May 2025). We refer to this dataset as the Princeton dataset throughout this paper. It has been thoroughly described in previous studies [
1,
3,
5], so we provide only a brief overview here. The Princeton dataset consists of seven original paintings by the artist Charlotte Caspers and their respective replicas, which were painted by the same artist two weeks later (see
Figure 1). The original paintings were created using various brushes, canvases, and paints, while the replicas were generated under identical conditions and with the same materials as the corresponding originals.
Table 1 shows the relevant data for each original–replica pair within the dataset.
The second dataset was generated as part of the study by Ji et al. [
2] at Case Western Reserve University (Cleveland, OH, USA). This dataset is available for download at
https://github.com/hincz-lab/machine-learning-for-art-attribution (accessed on 1 May 2025). Four students from the Cleveland Institute of Art painted three copies of a photograph of a water lily (see
Figure 2). All paintings were created using the same oil colors and paintbrushes on paper. The scanned image of each painting measures 3000 × 2400 pixels. We refer to this dataset as the Cleveland dataset throughout this paper.
It would be valuable to test our methodology with a dataset including different artistic styles and epochs. However, we were unable to find such a dataset in the public domain. The datasets utilized in this study provide pairs of original–replica paintings that are as similar as possible, as they were created under identical controlled conditions using various canvases, brushes, and paints. Creating such a dataset that also includes significant diversity in artistic styles remains challenging.
3.2. The DBC-RGB Algorithm
As described later, our approach to analyze the paintings involves computing the fractal dimension (FD) of a set of square patches extracted from the paintings. Several methods for estimating the FD of color images have been proposed in recent years [
36,
37,
38,
42,
43,
44,
45]. The most common approach has been to extend the differential box-counting (DBC) algorithm for grayscale images to the color domain [
36,
37,
38,
44,
45]. Among these methods, the ultra-fast DBC-RGB algorithm presented in [
37] stands out because its accuracy is comparable to reference algorithms while being much faster due to its parallel nature, which enables GPU implementation. This characteristic is crucial for the present study, as a large number of patches in each painting must be processed. A detailed description of the DBC-RGB algorithm and its GPU implementation can be found in [
37]. Below, we briefly describe the fundamentals of the algorithm.
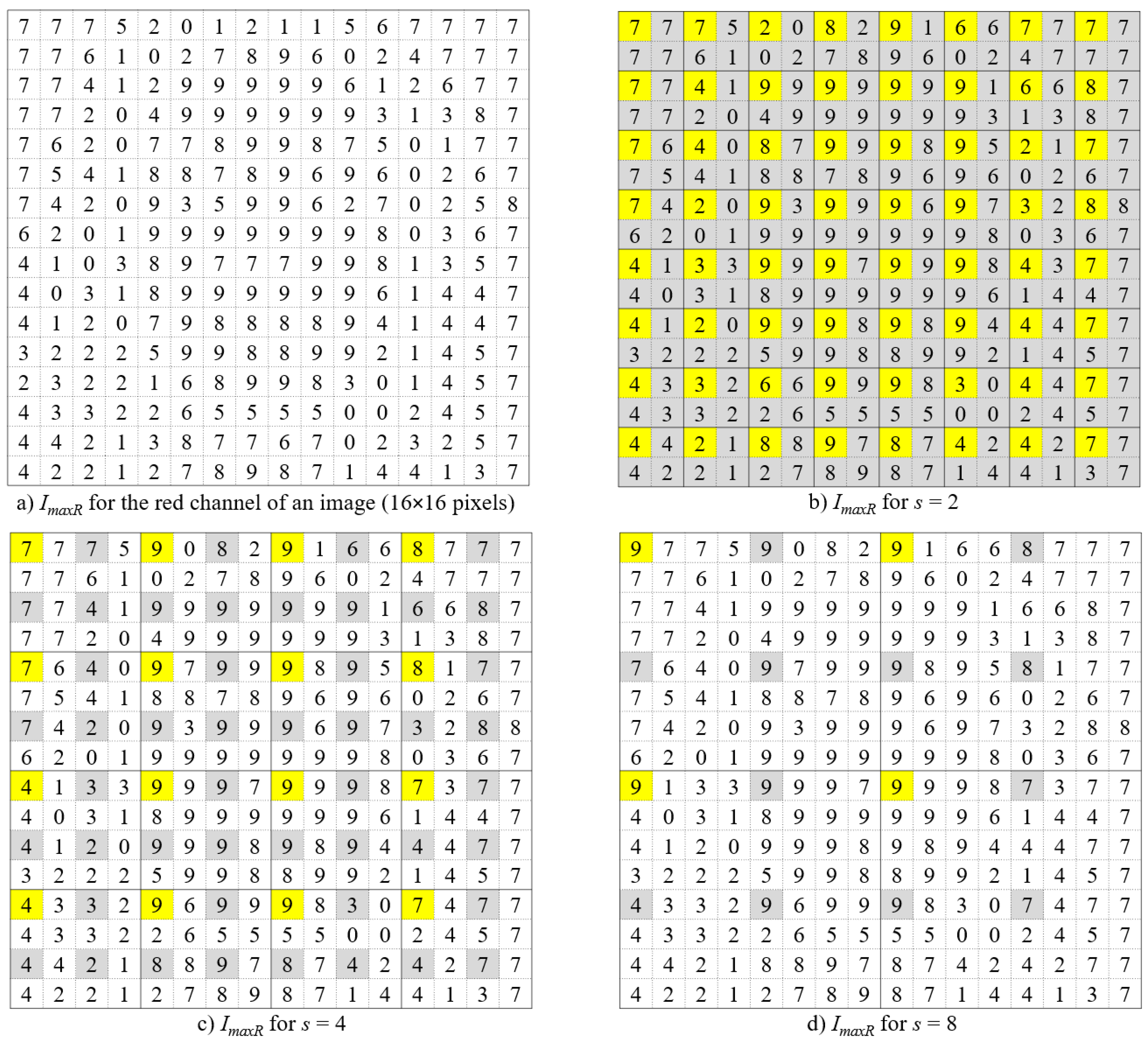
In the DBC-RGB algorithm (see the pseudo-C code in Listing 1), each pixel in the image is represented as a five-dimensional vector (x, y, r, g, b), where (x y) denote the pixel coordinates, while (r, g, b) represent the respective intensity levels of the colors red, green, and blue. The image of M × M pixels is divided into grids of boxes of size s × s, with each grid corresponding to an RGB cube of size h × h × h. Here, h is calculated as , where G is the total number of intensity levels for each color and the grid size s ranges from 2 to . The method then counts the number of boxes of size s × s × h × h × h that cover at least one pixel of the image. To accomplish this, the distribution of pixels along each of the R, G, and B axes is computed independently as follows: (1) For each channel c (R, G, and B) of the image, the boxes containing the maximum and minimum intensity levels within the grid (i, j) are denoted as kc and lc, respectively; and (2) the count for each channel c in the grid (i, j) is then calculated as nrc(i, j) = kc − lc + 1. Once the count nrc(i, j) for each channel is computed, the number nr(i, j) of boxes covering pixels in the grid (i, j) is estimated by multiplying these three counts: nrR(i, j) · nrG(i, j) · nrB(i, j). Finally, the total box count Nr is computed as Nr = for scale r ranging from to , and the fractal dimension of the RGB image is determined by calculating the slope of the linear regression of the points .
A parallel and highly efficient implementation of the DBC-RGB algorithm is achieved in [
37] by considering only grid sizes,
s, that are powers of two; this approach avoids repeatedly scanning the image to compute each
Nr value. The algorithm implementation initializes six buffers (
ImaxR,
IminR,
ImaxG,
IminG,
ImaxB, and
IminB) with the red, green, and blue channels of the image, respectively (see
Figure 3a and lines 4–7 in Listing 1). For
s = 2, the maximum and minimum intensity levels in each 2 × 2 grid are obtained for each color channel (see
Figure 3b and lines 18–25 in Listing 1), and the three counts
nrR,
nrG, and
nrB are calculated. These counts are multiplied to obtain
nr; then,
Nr is computed as described previously (see lines 26–29 in Listing 1). The maximum and minimum values are then stored in the (0, 0) positions of their respective grids (see yellow cells in
Figure 3). For subsequent values of
s (
s = 4,
s = 8, …, and
s =
), the algorithm uses the four previously stored values (from the sub-grids) to efficiently obtain the new maximum and minimum values for each grid (see gray cells in
Figure 3c,d), avoiding the need to compare all intensities within that grid.
| Listing 1. Pseudo-C implementation of the DBC-RGB algorithm in [37]. |
![Symmetry 17 00703 i001]() |
To efficiently process the patches within each painting, we used the fast parallel code of the DBC-RGB algorithm, which was implemented in CUDA for GPU execution and made publicly available by its authors in [
37].
3.3. The Sliding Window Methodology
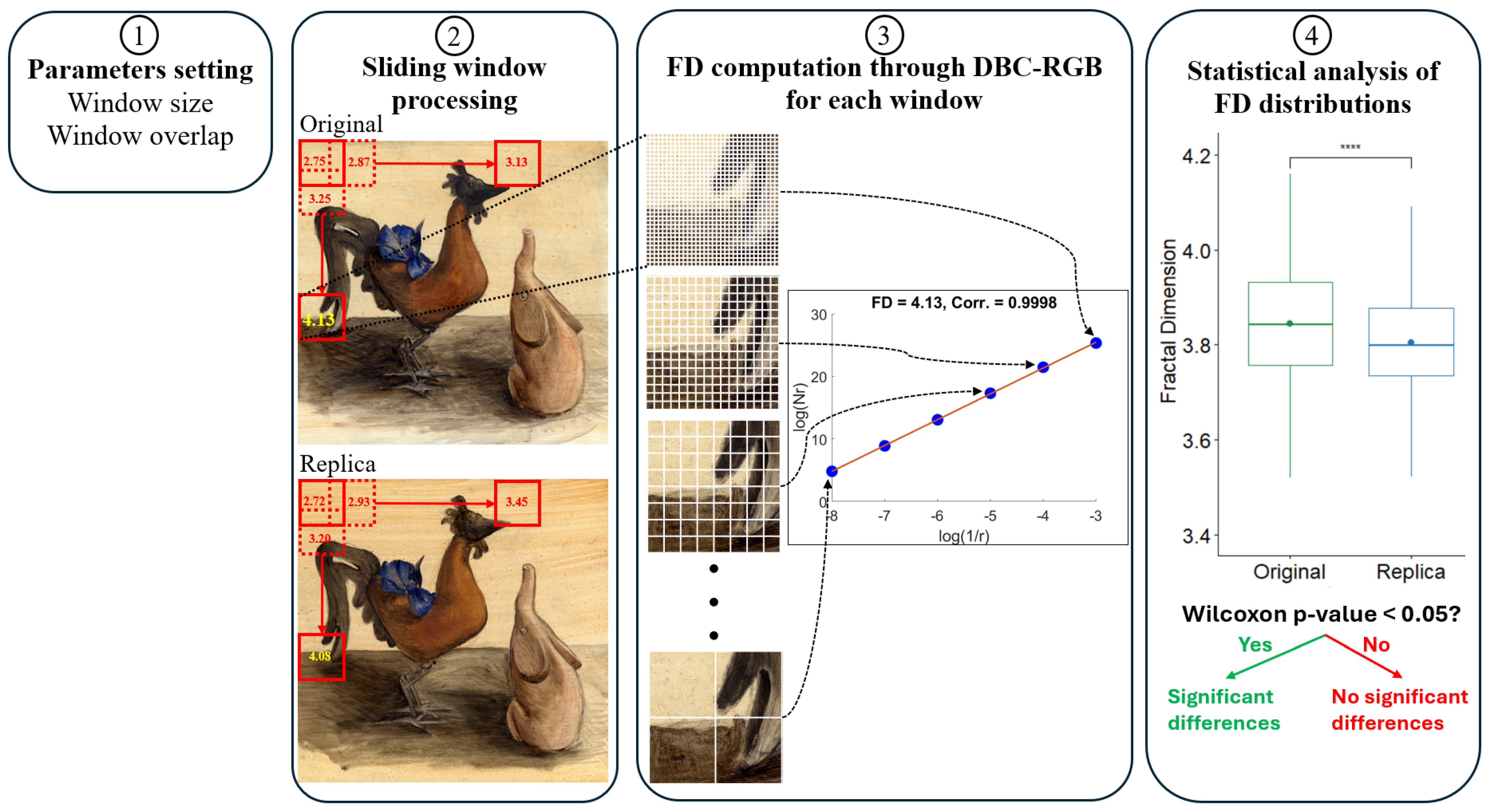
The sliding window technique involves dividing the study signal, the image of the painting, into fixed-size segments, called windows. These windows move across the signal with a specified shift, which can be equal to or less than the window length. If the shift is less than the window size, the windows overlap by a certain percentage. Each window is processed individually, and the resulting values are then combined to obtain a representation for the full signal.
Figure 4 graphically illustrates the sliding window computation of the fractal dimension for an original–replica pair of paintings in the Princeton dataset. The sliding window process has two parameters (see
Figure 4, step 1): (1) the size of the window, which defines the dimensions of the square patches (e.g., 512 × 512 in the example shown in
Figure 4), and (2) the overlap percentage, which establishes the number of pixels that the window shifts by to define the next patch to be processed (e.g., yielding 25% overlap in the example shown in
Figure 4). The FD is then computed using the DBC-RGB algorithm for each patch defined by the sliding window (see step 3 in
Figure 4). The set of computed FD values from all patches is used to statistically compare the original painting with the replica (see step 4 in
Figure 4).
We followed a single criterion when selecting the patch size for processing the two datasets in our study to perform an analysis as similar as possible to those conducted in previous studies using these datasets, ensuring a fair comparison of our results. For the paintings in the Princeton dataset, we selected a window size of 512 × 512 pixels, as recommended in [
5]. A patch of 512 × 512 pixels covers approximately 5 × 5 cm
2 of the painting surface, which roughly corresponds to the size of the brushstrokes. Moreover, a patch size of 512 × 512 pixels ensures sufficient scale for the linear regression required in the DBC-RGB algorithm’s FD computation. An average correlation coefficient of 0.9997 was obtained for the linear regression calculation performed during FD computation for all 512 × 512-pixel patches across all paintings in the Princeton dataset.
For the paintings in the Cleveland dataset, we used a window size of 256 × 256 pixels. This size, corresponding to a painting patch of approximately 1 × 1 cm
2, was selected based on the recommendations in [
2], where the authors found that the optimal size for analyzing that dataset ranged between 100 × 100 pixels and 300 × 300 pixels. Since the DBC-RGB algorithm requires patch sizes with dimensions that are powers of two, we considered two possible patch sizes in that range: 128 × 128 and 256 × 256 pixels. Finally, we selected a patch size of 256 × 256 pixels to ensure a wider range of scales for the linear regression calculation in the FD computation, similar to the case with the Princeton dataset. This selection allowed us to obtain an average correlation coefficient of 0.9992 in the linear regression performed during the FD computation for all 256 × 256-pixel patches across all paintings in the Cleveland dataset.
As shown, patch size selection is highly dependent on the characteristics of the painting images being analyzed. General recommendations for selecting the patch size include the following trade-offs: (1) Small patches enable a detailed analysis of the painting but require longer computation times, may overlook key characteristics like brushstroke size, and might not provide a sufficient range of scales for the linear regression calculation in FD computation. (2) Large patches speed up calculations, but they may result in too few FD values for statistical comparisons, as they could be analyzed overly large portions of the painting, thus introducing excessive heterogeneity in terms of painting techniques and brush combinations.
In our experiments, we tested five different window overlap percentages: 0%, 25%, 50%, 75%, and 90%. Rather than seeking optimal values for each dataset, this incremental selection of window overlaps aimed to observe the relationship between this parameter and the emergence of significant differences in painting comparisons. This approach also allows us to identify which painting comparisons might benefit from further analysis with a higher window overlap percentage.
Table 2 shows the number of patches generated for paintings in both datasets using each sliding window configuration.
It is not currently possible to automatically determine the optimal window overlap parameter for comparing pairs of paintings in a specific dataset. As we will show in the
Section 4, increasing the window overlap percentage leads to identifying more significant differences between paintings within the two datasets, albeit with increased computation times. Therefore, some empirical experimentation is required when analyzing a new dataset, starting with a low value (fastest processing) and then increasing it when no significant differences are found.
Once the window size and overlap percentage are chosen, our methodology operates automatically, eliminating the need for manual patch selection and ensuring a detailed analysis of the entire painting.
The C++ source code for computing the FD of a painting and processing the two datasets using our sliding window methodology is publicly available at
https://www.ugr.es/~demiras/swfd (accessed on 1 May 2025).
3.4. Statistical Analysis
To study the differences between the distributions of FD values from patches in original and replica paintings, we performed the nonparametric Wilcoxon rank-sum test (see step 4 in
Figure 4). Note that this is the same test used for non-pairwise comparisons in [
5]. Since several groups (paintings) were compared simultaneously, the Wilcoxon test was configured with a Bonferroni post hoc correction for multiple comparisons to control the overall probability of making a Type I error. Statistical test results were considered significant when the
p-value obtained was below 0.05. All statistical analyses were performed using R version 4.2.1 with the Stats package.
5. Discussion and Conclusions
In this study, we introduced a novel, color-FD-based method for differentiating original paintings from replicas. By using a sliding window approach and recent color-FD computation techniques [
37], our method effectively analyzed two public datasets, identifying significant differences between original and replica paintings. These findings suggest that combining the FD of color images with a sliding window approach is a promising tool for forgery detection.
Previous multifractal analysis of the Princeton dataset [
5] revealed significant differences in only three of seven original–replica painting comparisons, whereas our method, employing the same statistical test, detected significant differences in all seven. This enhanced performance required a more intensive image analysis, using a 90% window overlap, in contrast to the expert-driven manual patch selection employed by the multifractal approach in [
5].
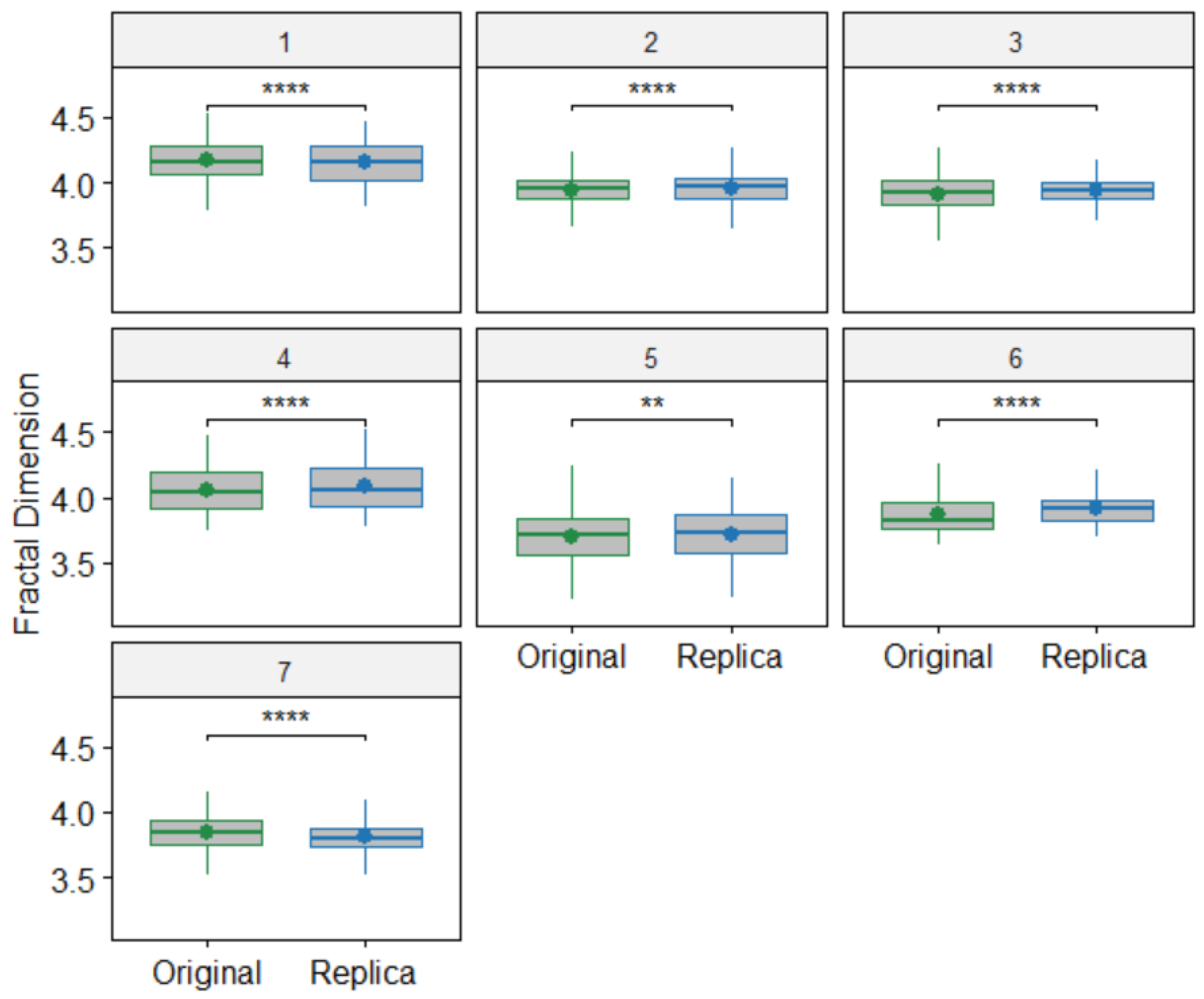
The analysis of the Princeton dataset revealed that most replica paintings had higher average FD values compared to their original counterparts (see
Table 4 and
Figure 5). This finding aligns with the increased multifractal parameter values reported in [
5] for cases where significant differences between originals and replicas were detected. In the case of original paintings, the artist’s hand movements, brush strokes, and color application may be more spontaneous and natural, leading to a lower FD value. Replicas, on the other hand, might be created with a more deliberate and controlled approach, as the artist attempted to replicate the original work. This more methodical process could result in a higher FD value due to the presence of more intricate and detailed patterns. In contrast, in the Cleveland dataset, we did not observe a similar pattern in the average FD values. This discrepancy may be attributed to the fact that all three paintings by each artist in the Cleveland dataset are copies of a photograph rather than replicas of an original painting.
While FD distributions are quite similar for paintings in the Princeton dataset, greater variability in FD distribution is observed in paintings by the same artist in the Cleveland dataset. One possible reason is that the artist in the first dataset was instructed to make the replica paintings as faithful to the originals as possible. However, for the second dataset, the artists were simply instructed to make copies of the water lily photograph, ensuring that the copies maintained the same style.
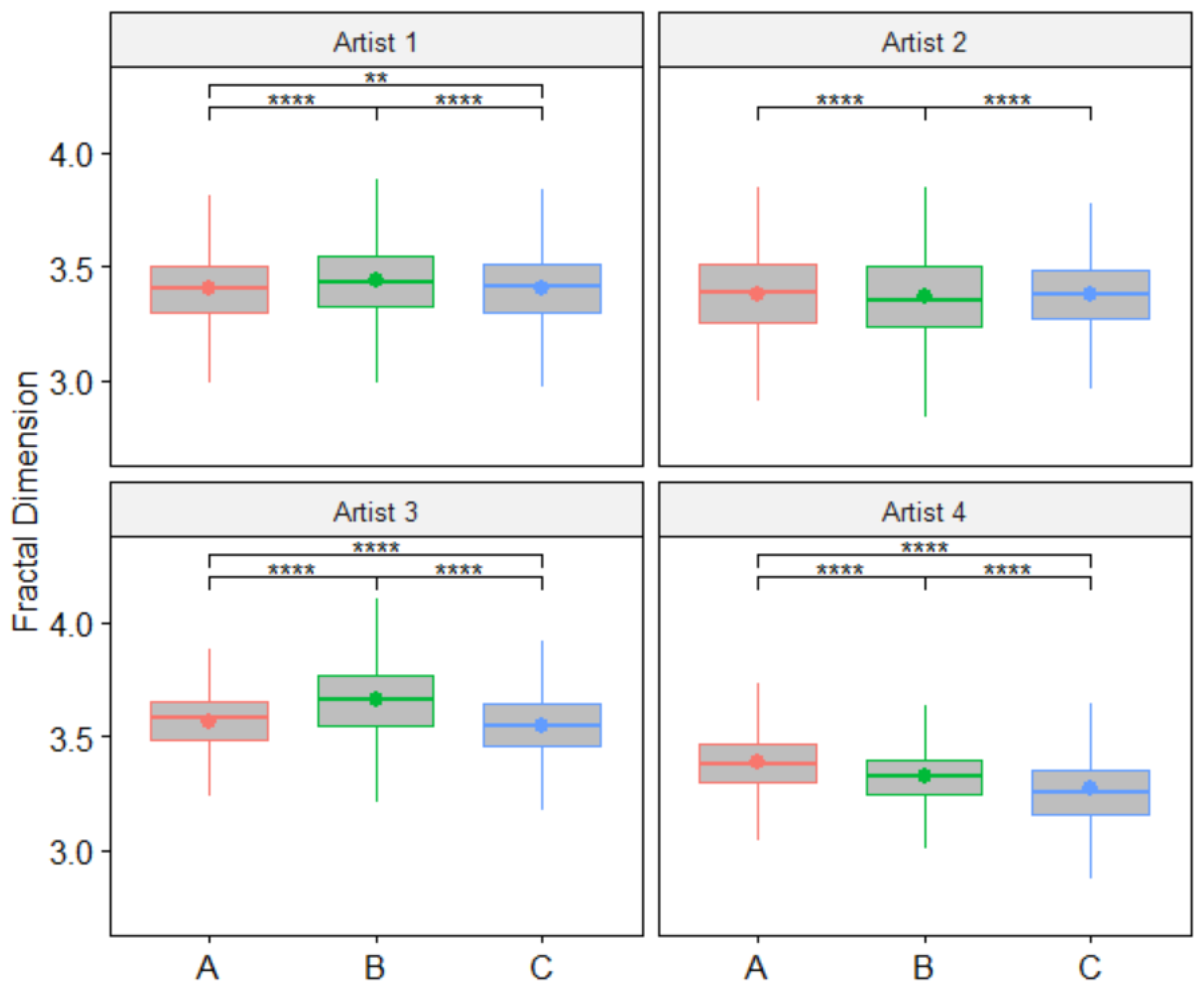
The Cleveland dataset allowed us to test our methodology by comparing pairs of paintings by the same artist as well as similar paintings from different artists created under identical controlled conditions. This scenario closely resembles the typical forgery detection problem addressed in several recent studies [
2,
7]. Our results indicate that the methodology was able to identify significant differences in nearly all comparisons: 96.6% when comparing pairs of paintings from different artists (see
Table 6) and 100% for inter-artist comparisons (see
Table 7). Although accuracy metrics vary across studies, our results are comparable to or better than those in recent forgery detection research: 95% accuracy in [
2] and a 96% hit rate in [
7].
Previous studies that used the Princeton dataset [
1,
3,
6] did not compare original paintings and replicas directly; instead, they used machine learning classifiers that were trained with the features extracted from each individual patch and tested by classifying individual patches as well. This analysis of original–replica paintings is different from the approach followed in [
5] and in our study, so their results cannot be directly compared to ours and those obtained in [
5]. Nevertheless, these studies based on machine learning classifiers provided metrics of accuracy for the classification of patches, and if we consider that an accuracy value above 75% for correctly classifying these patches is equivalent to a correct distinction between the original painting and its replica, then we can make a kind of comparison between the results of those previous studies based on machine learning and our results. In [
1], a hidden Markov tree multiresolution model was used to extract the features for each patch, and their best classification technique correctly distinguished originals from replicas in three out of seven pairs of paintings in the Princeton dataset. In [
3], the features computed for each patch were based on the histogram of oriented gradients technique, and they correctly classified seven out of seven pairs of paintings in the Princeton dataset, obtaining an equivalent result to ours. The last study analyzing the Princeton dataset was conducted in [
6]. They extracted a total of 153 features for each patch, and their best result achieved correct classification in three out of seven pairs of paintings.
Two other studies in forgery detection analyzed abstract paintings by the artist Jackson Pollock and fake paintings attempting to imitate his unique style [
7,
8]. Although these studies did not try to differentiate between originals and replicas of the same painting, their results demonstrate that FD features provide strong discriminatory power between authentic and fake Jackson Pollock paintings. In these two studies, the FD was computed on the grayscale representation [
7] or via black-and-white binarization [
8] of the image of the painting. Our results using the FD at the color level of images suggest that their results could be further improved by applying FD computation algorithms such as DBC-RGB.
Since the present study has proven the effectiveness of our FD-based methodology for differentiating between original paintings and replicas, further research could also be directed towards incorporating the FD value computed at each individual patch through the DBC-RGB algorithm as a feature in machine learning models used in previous studies [
1,
2,
3,
6]. Among them, only the model described in [
6] incorporated the FD as one of the features describing each patch. However, they used an FD computation approach based on the pre-binarization of the patches. We think that processing the full color information using algorithms such as DBC-RGB could further enhance the results of these machine learning classifiers.
Our methodology requires establishing two key parameters: patch size and window overlap percentage. To ensure fair comparisons in the present work, we selected the same patch sizes recommended by the studies that analyzed the same datasets [
2,
5]. In general, small patches allow for a detailed analysis of the painting but at the cost of longer computation times and potentially overlooking key painting characteristics such as the size of the brushstrokes. Conversely, large patch sizes accelerate the calculations, but the number of FD values for statistical comparisons of the paintings could be insufficient, and the portion of the painting analyzed in each patch could be too large, including too much heterogeneity (painting techniques and combinations of brushes). According to our experiments, increasing the window overlap percentage leads to the detection of a greater number of significant differences between paintings within the datasets. While a higher window overlap parameter value allows for more detailed analysis, it also demands longer computation times. Nevertheless, establishing a high window overlap does not ensure finding significant differences when comparing every pair of paintings, as seen in the case of paintings A and C by artist 2 in the Cleveland dataset. This pair of paintings was further examined using extremely high window overlaps of 95% and 99%, yet no significant differences were found. Unfortunately, we cannot provide general rules or criteria for automatically determining the optimal patch size and window overlap parameters. Therefore, some empirical experimentation is required depending on the characteristics of the dataset of paintings being analyzed.
In order to use our approach on other datasets, the following considerations must be taken into account: (1) High-resolution images are needed to capture as much as possible the subtle details of the paintings that can differentiate between originals and replicas. (2) Since the FD computation method in our methodology is based on the color intensities, the acquisition of images for each original–replica pair must be performed under identical conditions, and (3) the patch size in sliding window processing must be large enough to obtain a number of scales that ensure an accurate linear regression computation in the FD estimation through the DBC-RGB algorithm (at least 128 × 128 pixels as suggested in [
37]). Images of the paintings at a low resolution could imply that the patch size does not meet this requirement.
The primary limitation of our sliding window FD algorithm is its high computational demand, particularly when processing high-resolution images with a large window overlap. Unfortunately, prior related studies have not reported the computation times of their respective algorithms, making it impossible to make a direct performance comparison. Nonetheless, given that our methodology is based on a fast algorithm executed in parallel on a GPU [
37], we believe that our computation times would not be significantly worse than those obtained in similar studies, particularly those that also process grids of patches within the painting [
1,
2,
3,
6]. As we demonstrated with our OpenMP implementation, the overall dataset processing can be significantly optimized through the parallel processing of multiple paintings. In this scenario, the number of paintings processed concurrently depends on the available GPUs, CPU cores, RAM, and GPU global memory of the computing system.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}