1. Introduction
Steel is commonly used in the construction of various infrastructures, particularly in industries such as automotive, aerospace, and machinery, where there are strict requirements for surface precision. From the perspective of materials science, the essence of surface defects lies in local symmetry breaking. However, traditional detection methods such as manual inspection, non-destructive testing, and laser scanning detection suffer from limitations including inefficiency, inadequate precision, and difficulties in defect classification for such symmetry-breaking anomalies. Machine vision methods, due to their high computational complexity and limited adaptability to different scenarios, also present certain constraints in this field. With the introduction of the AlexNet [
1] network in 2012, Convolutional Neural Networks (CNN) have significantly excelled in the area of computer vision, fostering rapid advancements in deep learning-based object detection. CNNs offer benefits such as high speed, robustness, accuracy, and strong adaptability.
Currently, common target detection algorithms fall into two categories. The first category comprises two-step algorithms such as Region-based Convolutional Neural Network (R-CNN) [
2], Fast R-CNN [
3], Faster R-CNN [
4], and Mask R-CNN [
5]. These algorithms follow a two-step process of feature extraction and candidate box selection, resulting in lower error rates and missed detection rates. Zhao et al. [
6] reconstructed the Faster R-CNN feature extraction network using deformable convolution to improve the network’s feature extraction capacities. They introduced a feature pyramid network to fuse multi-scale feature maps, thereby improving the network’s ability to detect surface defects in steel. Another approach by Junting and Xiaoyang [
7] proposed an R-CNN defect detection algorithm based on a cascaded attention mechanism, effectively enhancing feature extraction capabilities by inserting lightweight attention modules into the convolutional neural network. This method achieved high-quality classification and localization of defects on metal surfaces. Xia et al. [
8] displayed an improved Faster R-CNN detection algorithm that incorporates the Convolutional Block Attention Module (CBAM) [
9] into the Region Proposal Network (RPN) structure. They adopted the Path Augmented Feature Pyramid Network (PAFPN) structure to fuse multi-layer features, enhancing the model’s capability to distinguish defects from the background. Li et al. [
10] integrated the PAFPN into the backbone feature extraction network and employed soft non-maximum suppression to further improve the detection performance of Faster R-CNN.
Another category includes single-stage algorithms such as the Sum of Squared Differences (SSD) algorithm and the YOLO (You Only Look Once) series, which directly predict classification and localization after feature extraction. Lin et al. [
11] improved the SSD algorithm to learn steel defects, employing the Residual Network (ResNet) for defect classification and optimizing steel surface defect detection. Zhang et al. [
12] based on YOLOv5, introduced a micro scale detection layer and incorporated the CBAM into the feature fusion layer, so as to decrease the loss of feature information for small target defects. Wang et al. [
13] proposed an enhanced YOLOv7 algorithm, constructing an image-enhanced feature extraction branch and introducing the context transfer module. This module fuses features from the original and enhanced images. Additionally, Focal EIOU serves as the bounding box regression loss of the model to mitigate performance degradation resulting from overlapping underwater objects. Bhookya Nageswararao Naik et al. [
14] put forward an enhanced single-stage object detection model, which utilizes the exponential linear unit activation function in the convolution layers and the sigmoid activation function at the output layer, thus enhancing detection accuracy. As reported in the relevant literature, researchers have improved the feature extraction capabilities of detection models by modifying the network architectures and introducing attention mechanism modules. Moreover, the use of more rational and comprehensive loss functions has significantly enhanced the precision of bounding box localization.
In defect detection tasks, the primary challenge is to ensure both rapid detection speed and high accuracy. The two-stage R-CNN algorithms provide high detection accuracy but suffer from slower processing speeds. In contrast, the one-stage YOLO and SSD algorithms improve detection speed at the expense of some accuracy. Typically, a processing speed of 30 FPS is required for real-time detection, and an accuracy exceeding 80% is considered adequate for practical applications.
The two-stage R-CNN series algorithms exhibit high detection accuracy but slower detection speeds. In contrast, single-stage algorithms like YOLO and SSD enhance detection speed at the expense of some accuracy. How to maintain the efficient inference speed of a single-stage algorithm, while optimizing the feature extraction mechanism and bounding box regression strategy to achieve high-precision detection of multiple types and scales of surface defects in steel, is a key challenge in current research.
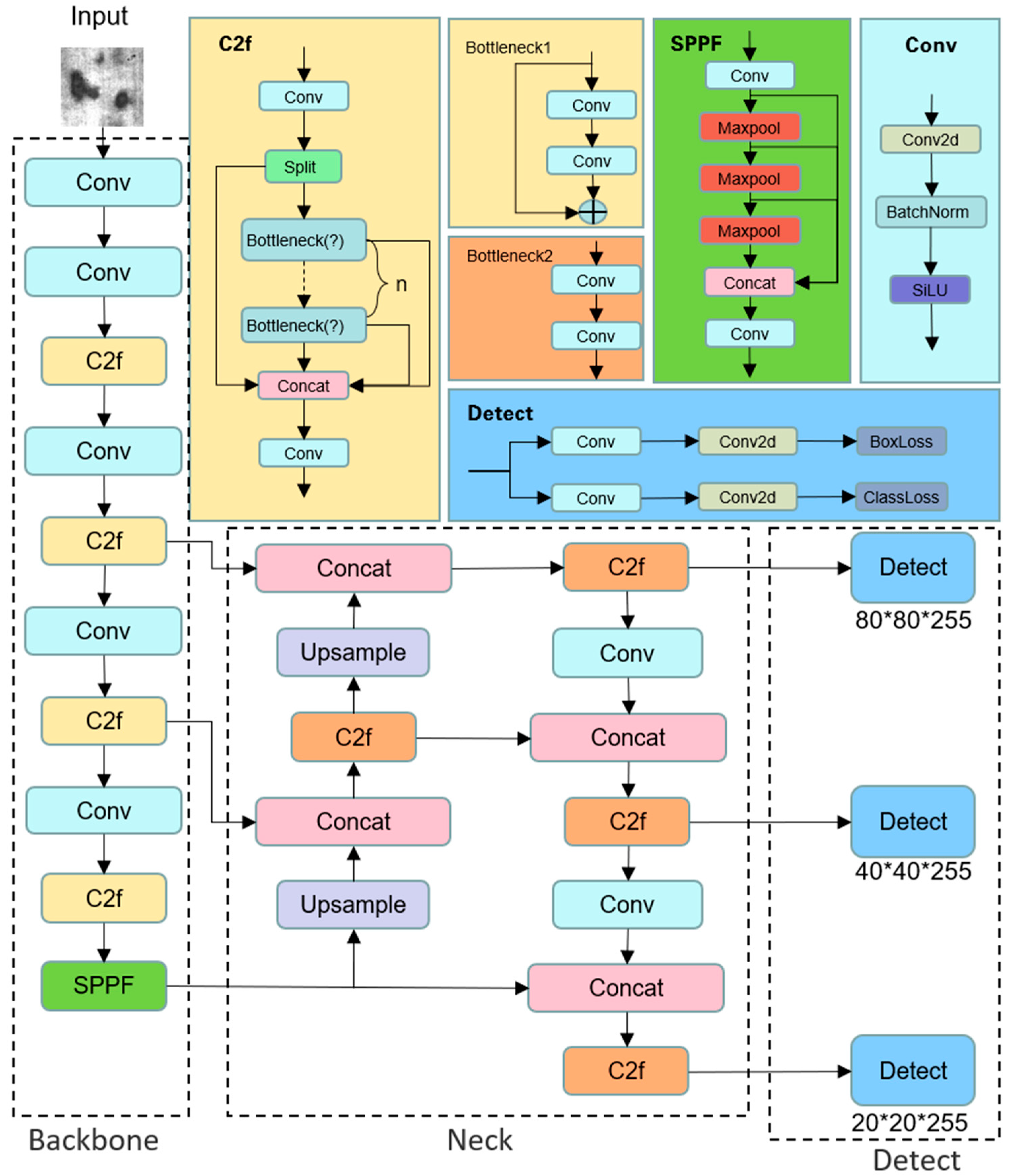
To further improve the performance of single-stage object detection algorithms, this paper, based on the YOLOv8s network architecture, integrates the ODConv dynamic convolution with an attention mechanism into the feature extraction network. This integration elevates the weight of effective information in the feature maps, enabling the model to accurately identify various defect targets. Simultaneously, to enhance model convergence speed, the WIoU bounding box loss function is employed for loss value computation, achieving a rapid and accurate detection of defects.
The paper is organized as follows:
Section 2 briefly introduces the research dataset and outlines the key methods, focusing on improving feature extraction and the loss function to enhance detection performance.
Section 3 evaluates the model performance, validating the effectiveness of the improved methods through comparative and ablation experiments, and compares the performance with other algorithms. The conclusion is presented in
Section 4, along with future research directions.
3. Results and Discussion
This study utilized a self-built experimental environment with the PyCharm IDE, and the details of the environment are displayed in
Table 1. During this model training stage, Mosaic data augmentation was applied at the input end to scale and concatenate four images. This method aims to enhance the detection of small targets, ultimately improving the performance and robustness of the model. The network training parameters are outlined in
Table 2.
The YOLOv8s training weights provided by the official source were used for weight initialization. To ensure a fair comparison, the baseline YOLOv8s and its improved variant were trained with identical configurations, thereby objectively quantifying the performance gains and validating the refinement strategy.
This section is structured into subsections to present a succinct yet comprehensive overview of the experimental outcomes, their contextual interpretation, and the resulting implications derived from the study.
The YOLOv8s training weights provided by the official source were used for weight initialization. All experiments used the identical parameters for training the original and improved models, facilitating a comparison of the model performances and validating the effectiveness of the model improvements.
3.1. Evaluation Criteria
To objectively evaluate the effectiveness of the model, precision (P), recall (R), and mean average precision (mAP) [
31] were employed as metrics to assess the accuracy of the model’s detections, calculated as per Formulas (6)–(8).
In these formulas, TP (true positive) denotes the count of correctly detected defects, FP (false positive) represents the count of defects erroneously detected, and FN represents the count of defects not detected. AP (Average Precision) denotes the average detection accuracy for each defect type, while mAP is the average of AP values across all defect categories, where n is the number of defect types.
3.2. Experimental Results
3.2.1. Performance Analysis of the Model
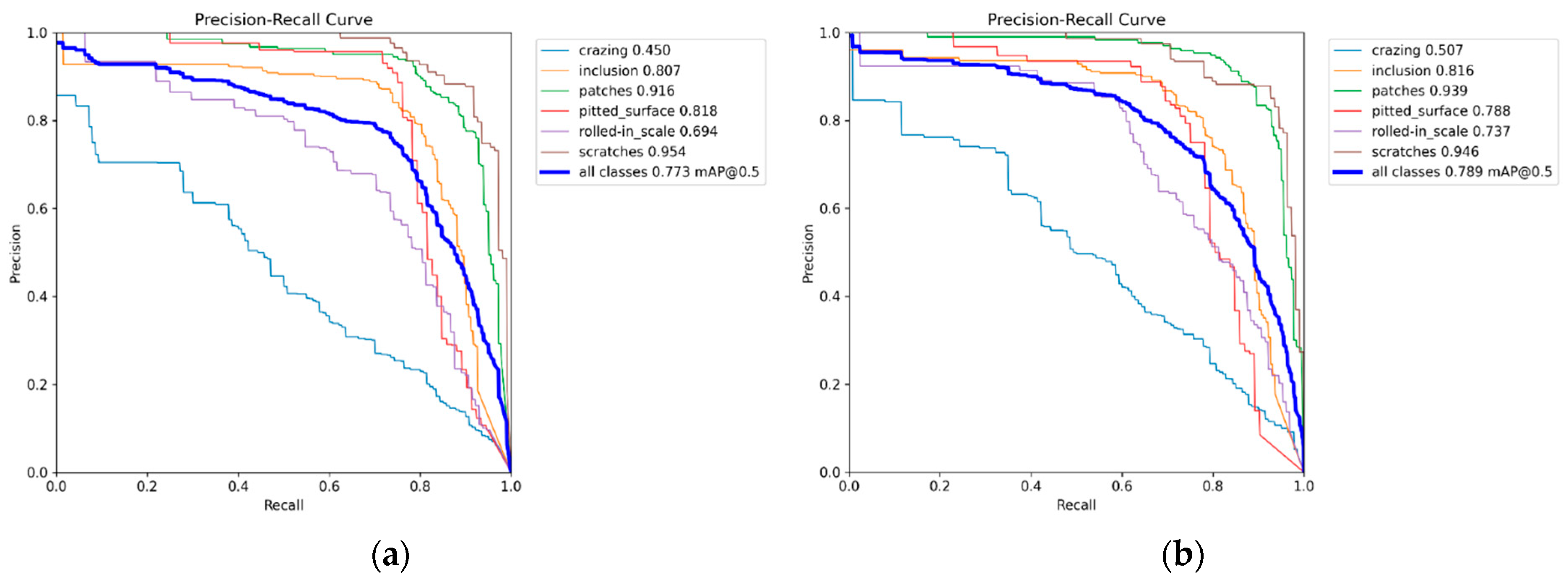
As displayed in
Figure 6, to analyze the effectiveness of the enhanced model in steel defect detection and visually compare the performance, PR curves before and after the model improvement are contrasted. A larger area under the curve suggests better detection performance.
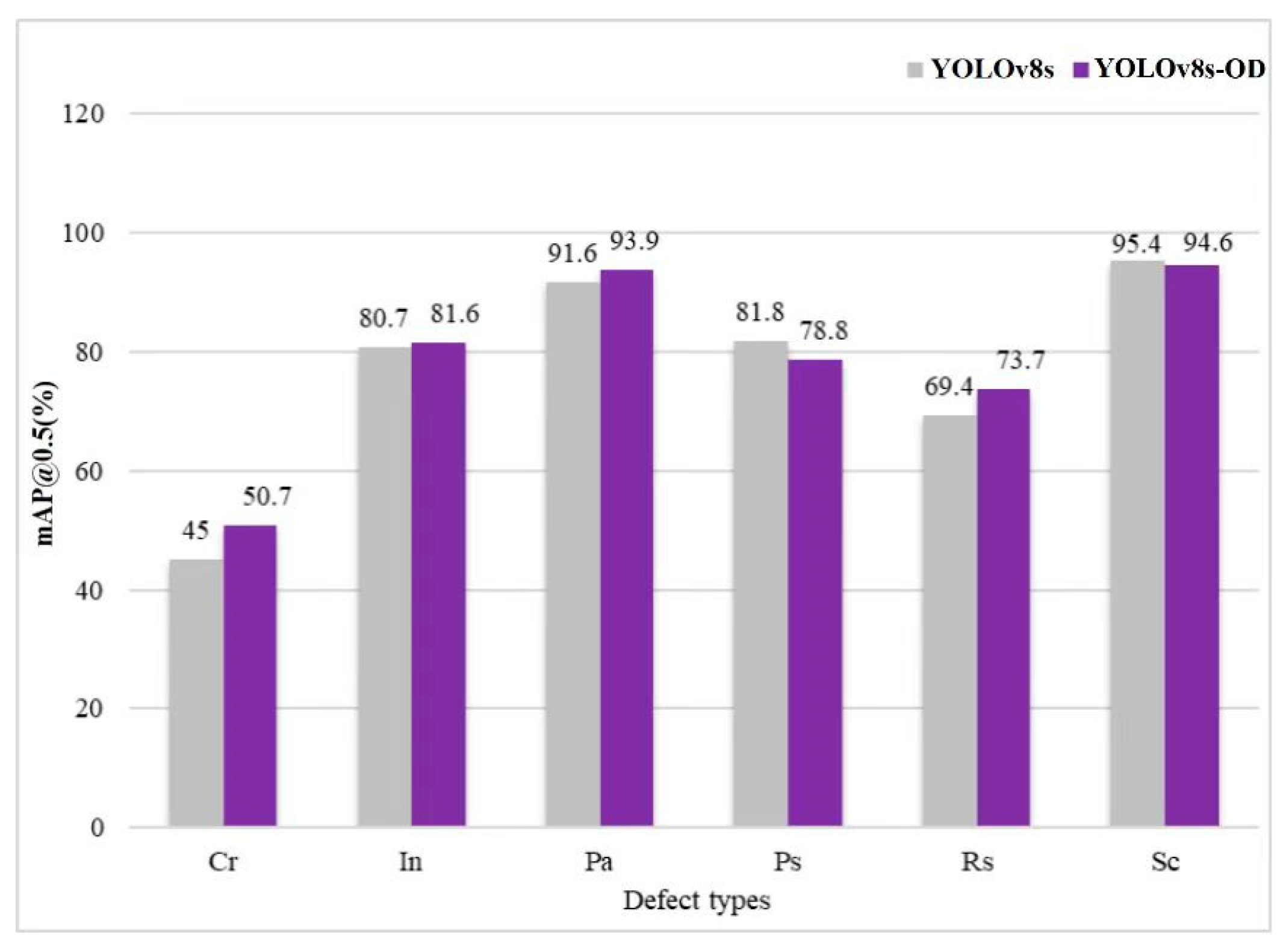
Figure 7 illustrates a comparative analysis between the original YOLOv8s and the proposed YOLOv8s-OD algorithm in the detection of various defect types. Owing to the relatively less distinctive characteristics of Cr (crazing) and Rs (rolled-in scale) compared to the other five defect categories, the corresponding mAP values are comparatively lower. The improved YOLOv8s-OD model demonstrates an AP enhancement in most defect types, except for Ps (pitted surface) and Sc (scratches), where there is a slight decrease. Particularly, noticeable improvements are observed in the identification of Cr (crazing) and Rs (rolled-in scale), with increases of 5.7% and 4.3%, respectively. As shown in the analysis of
Figure 6, the integration of ODConv into the backbone network and the substitution of the bounding box regression loss function with WIoU have significantly enhanced the model’s feature extraction capabilities, thereby effectively improving the precision of defect detection.
3.2.2. Comparative Experiment
To evaluate the efficacy of the proposed enhancements, a controlled ablation study is implemented with YOLOv8s as the reference architecture. The selection of the objective function critically influences the model’s detection robustness, particularly in steel surface defect analysis where the alignment precision between predicted regions and annotated defects is governed by the overlap-based error metric. Consequently, a systematic benchmarking of prevalent IoU variants is performed, with empirical outcomes quantitatively summarized in
Table 3. To ensure a more stable regression process for the model, WIoU is selected as the bounding box loss function, which significantly improved in the accuracy of defect detection.
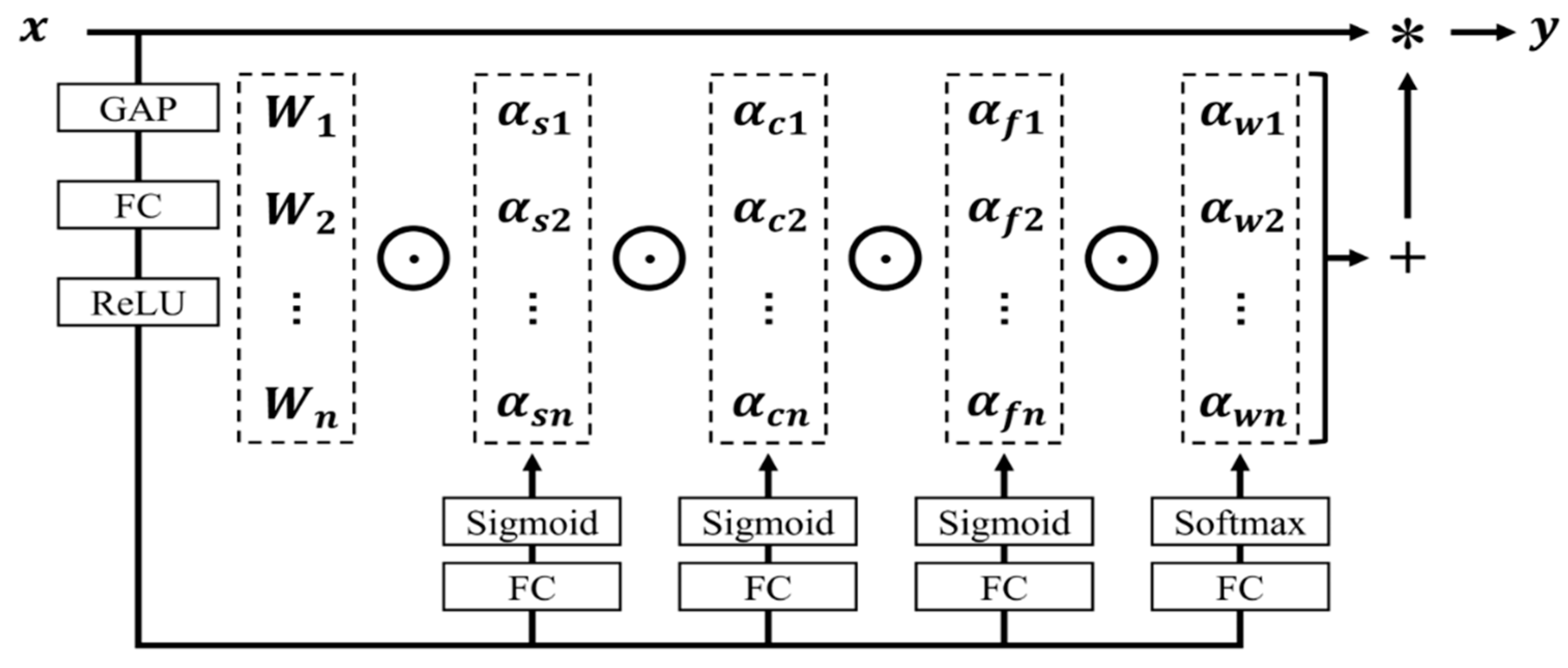
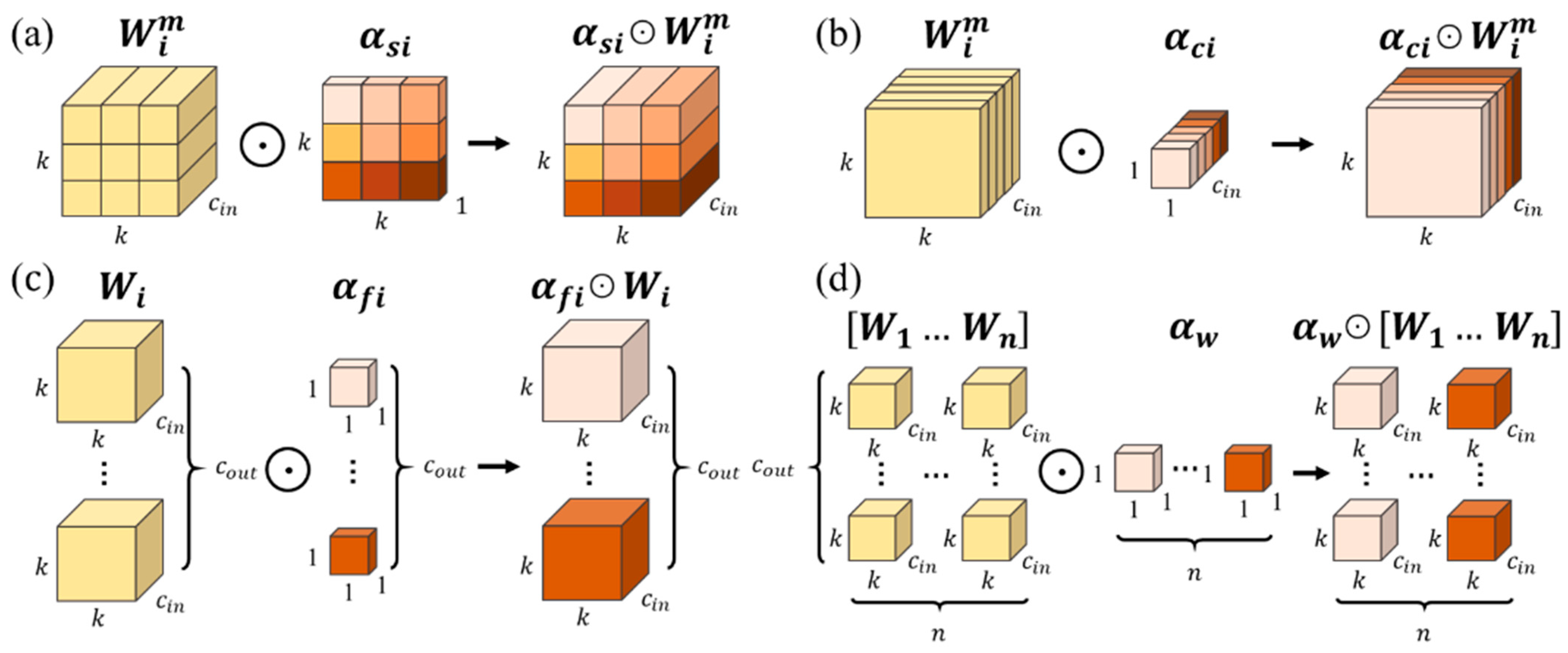
As the Omni-Dimensional Dynamic Convolution (ODConv) introduces attention across all four dimensions of convolution, a set of comparative experiments with current mainstream attention mechanisms was designed, and the results are displayed in
Table 4. Compared to the baseline model, including the popular SE [
32], CA [
33], and CBAM, ODConv shows a significant enhancement in model performance, with a 1.3% marginal increments in accuracy. Notably, the computational complexity of the model is reduced to 24.7 GFLOPs, and the increase in the number of model parameters is minimal. These experimental results validate the effectiveness of the introduced ODConv in enhancing the detection performance of this model.
3.2.3. Ablation Experiment
In conclusion, to quantify the efficacy of different improvement methods on the model, four sets of comparative ablation experiments were constructed in this study. Each experiment used the same dataset and training parameters, and the results are shown in
Table 5. The checkmark (√) shows if WIoU and ODConv are used in the experiment. Analysis reveals that the YOLOv8s experiment represents the original network model. The YOLOv8s1 experiment introduces the WIoU bounding box loss based on the original network, enhancing the precision of bounding box regression and subsequently enhancing the model’s accuracy in defect detection, leading to a 1.8% enhance in accuracy. The YOLOv8s2 experiment incorporates ODConv into the original network, integrating attention within the convolution, thereby improving the feature extraction capability of the backbone network, and both accuracy and mAP values show improvement. The YOLOv8s-OD experiment combines the above two methods, and compared to the original YOLOv8s network, it significantly improves accuracy and mAP values but with a slight decrease in recall—a common issue in tasks related to object detection.
In summary, relative to the original YOLOv8s network model, the improved YOLOv8s-OD network model in this study achieved a 4.5% increase in detection accuracy, reaching an mAP of 78.9%. Additionally, the reduction in computational complexity reflects an enhancement in model performance, highlighting its practical application value.
3.2.4. Comparison of Different Algorithms
To assess the efficacy and comparative advantages of the YOLOv8s-OD model in localizing defects on steel surface datasets, we benchmarked it against state-of-the-art detection frameworks, with empirical outcomes quantitatively summarized in
Table 6. From the detection results, the improved YOLOv8s-OD algorithm in this study exhibits better defect detection performance relative to other mainstream algorithms. Faster R-CNN, belonging to the two-stage detection category, demonstrates good detection performance, but its larger model size results in slower detection speed. The YOLO algorithm, while having an advantage in speed, shows poorer performance in detecting complex textures and weak features. In comparison to the original YOLOv5, the improved YOLOv8s-OD not only achieves faster detection speed but also significantly improves accuracy for all defect types except for pitted surface (Ps). Compared to the latest YOLOv8s, it shows a 0.9% and 4.3% improvement in AP values for inclusion and rolled-in scale, respectively, highlighting that the use of ODConv improves the model’s feature extraction capacity, especially for defects with weak characteristics. In terms of detection accuracy, the mAP value of the model in this study attains 78.9%. Additionally, the model maintains a high detection speed of 89 FPS while having a compact size of 21.5 Mb.
3.3. Comparison of Detection Results
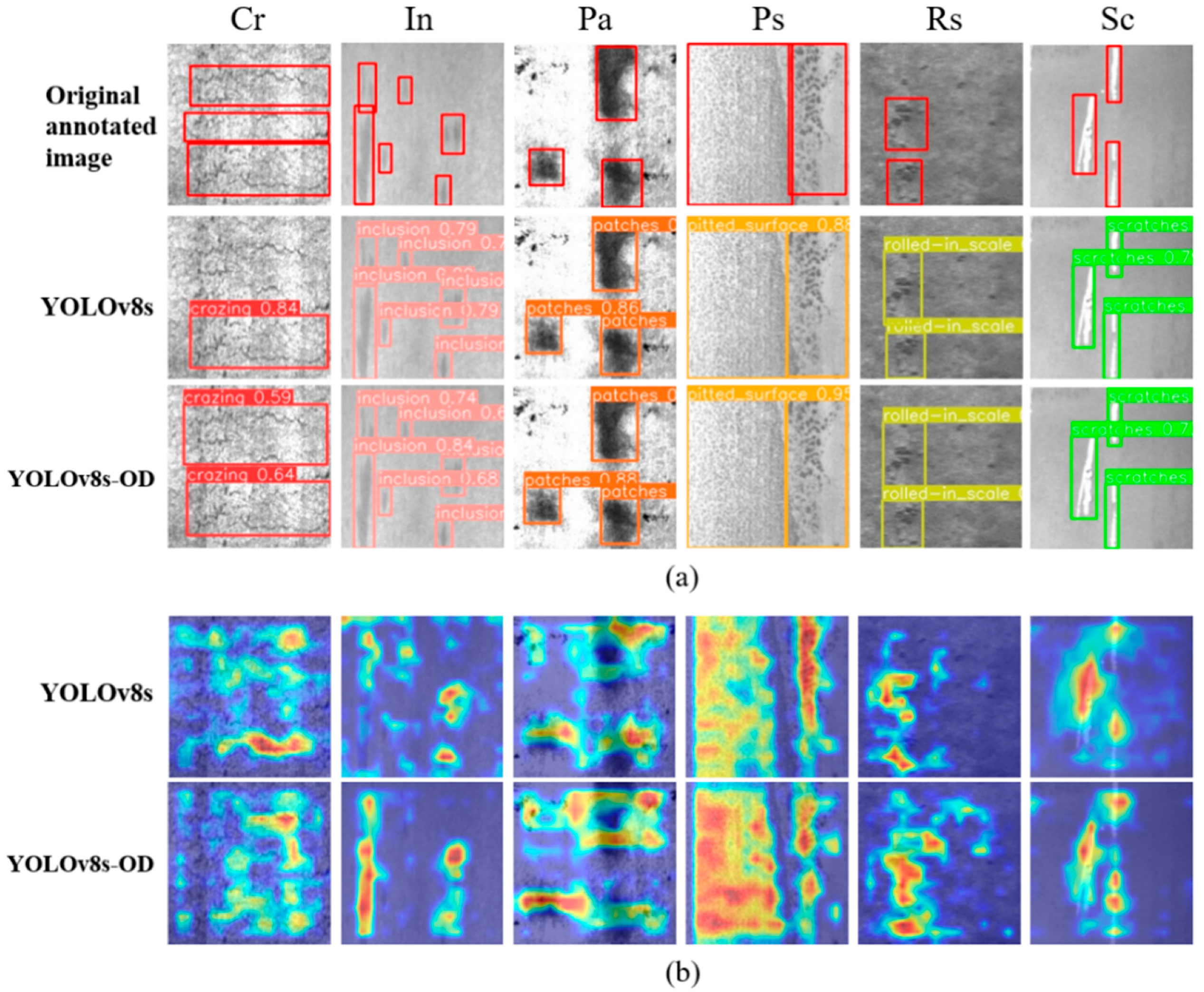
To offer a more visual comparison of the defect detection capabilities of the models, some detection results are presented in
Figure 8. Contrasting with the original annotated images, it can be observed that the YOLOv8s model has instances of missed detection for the Cr (crazing) defect, while the proposed YOLOv8s-OD model demonstrates better detection performance (as shown in
Figure 8a). Furthermore, comparing the heatmaps of features obtained from the original YOLOv8s and the YOLOv8s-OD backbone networks, where deeper red indicates a stronger focus of the model on that region. The optimized model demonstrates a more precise concentration on the defect features of the steel, allowing for better differentiation between the target and background, thus enhancing the model’s feature extraction capability (as illustrated in
Figure 8b). It can be seen that the improved model provides more comprehensive and accurate identification of surface defects on the steel, with detection results nearly matching the annotations.
4. Conclusions
In resolving the issue of steel surface defect detection, this paper proposes an enhanced detection algorithm based on the YOLOv8s network model. Considering the complex and diverse characteristics of steel surface defect features, a Dynamic Convolutional operation, ODConv, is introduced into the backbone feature extraction network. By applying attention weighting to the four dimensions of the convolutional kernel space, it reinforces target features, thereby improving the detection effectiveness for target defects. Simultaneously, this approach reduces the computational complexity of the model. The algorithm utilizes the WIoU bounding box loss function, incorporating a dynamic non-monotonic focusing mechanism. By employing outlier deviation instead of IoU for anchor box quality assessment, this strategy not only diminishes the competitiveness of high-quality anchor boxes but also mitigates harmful gradients produced by low-quality examples. This allows WIoU to focus on anchor boxes of ordinary quality, enhancing the overall performance of the detector.
The experimental results confirm the effectiveness of the proposed model enhancements. The improved model demonstrates a 4.5% increase in accuracy over the original YOLOv8s, achieving a mAP of 78.9%, with an average inference time of 11.2 milliseconds per image. Leveraging Mosaic image augmentation during model training and the inherent multi-class object recognition capabilities of the YOLO model, the proposed system is able to simultaneously detect multiple defects within a single image. Therefore, the proposed model exhibits commendable detection performance and practical value.
The model has not yet been deployed in an automated system. In future work, it will be integrated with real-world applications, with further optimization of the network model and improvements to the detection recall rate. Furthermore, the experimental dataset was captured under controlled, uniform conditions, which may affect the model’s accuracy in practical applications. To mitigate this, additional data will be collected from real production environments to expand the dataset and improve the model’s generalization performance.
This study has certain limitations, namely that the model’s recognition stability is insufficient for sporadically occurring special-shaped defects in actual production. This study has direct application value for metallurgical enterprises to enhance their steel quality control level. It can help enterprises quickly and accurately identify defects in the production process, thereby reducing the costs associated with manual inspection and the rate of misjudgment.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}