1. Introduction
Consider an arbitrary nondeterministic polynomial time Turing machine
N, running on arbitrary input
w of length
n, in
steps—where
k is a constant. Formulating
-completeness entails representing the behavior of a hypothetical accepting computation path
p of
N on input word
w, with
using propositional logic. The path depends on the execution of uniquely labeled instructions, such as the following one:
This nondeterministic instruction, labeled , can be split into two distinct deterministic instructions as follows:
.
.
Each deterministic instruction is assigned a unique label (e.g., ).
Instruction specifies that when N is in state and reading symbol a, the machine is supposed to transition to state and rewrite the symbol a as b, and the tape head should move one cell to the left (−). A plus sign (+) indicates a unary move to the right.
Standard treatments of
-completeness use the concept of a
tableau—a matrix with
rows and
columns, depicted in
Table 1—to conceptualize the hypothetical computation path
p. Each row in this tableau represents a Turing machine configuration of
N, framed by boundary markers at the beginning and end. Successive rows evolve from their predecessors based on
N’s transition function. A portion of one tableau, related to instruction
, is shown on the left in
Table 2, while a portion of another tableau, associated with instruction
, is displayed on the right.
The two illustrations in
Table 2 are slight variations of those presented by Sipser [
1] (p. 280). In a similar vein, Papadimitriou introduces the concept of a “computation table” [
2] (Section 8.2). Likewise, Hopcroft, Motwani, and Ullman use the term “array of cell/ID facts” [
3] (p. 443). Finally, Aaronson also conveys the idea of a tableau, using slang in his popularizing book [
4] (p. 61). To the best of our knowledge, all approaches to
-completeness rely on a tableau, ultimately tracing back to Cook’s seminal paper [
5].
The symbol sequence “
”, which appears in both top rows of
Table 2, signifies that the machine is currently in state
, with its head oriented towards the tape cell containing the symbol
a. This information is expressed propositionally through the conjunction of two Boolean variables,
and
, where indices
i and
j denote the row
i and column
j in a tableau.
A tableau is deemed
accepting when it represents a non-hypothetical accepting computation branch of
N on
w. The task of determining whether
N accepts
w is equivalent to ascertaining the existence of an accepting tableau for
N on
w. To achieve this, one must establish the satisfiability of
,
a propositional logic formula that encodes the intended meaning of the tableau. This reasoning closely follows Sipser’s account [
1] (Section 7.4).
To elucidate the variables within , consider Q and as, respectively, the state set and tape alphabet of N. Define , where ⊢ and ⊣ are boundary markers. For each i and j ranging from 1 to, respectively, and , and for every symbol s in we introduce a Boolean variable, . We have a total of such variables.
Definition 1. A Boolean formula in conjunctive normal form is referred to as a 3cnf formula if each clause consists of exactly three literals. If each clause contains at most two literals, the formula is called a 2cnf formula. We refer to a formula as “a 2cnf–Horn formula” if it qualifies as both a 2cnf and a Horn formula.
Remark 1. More rigorous definitions can be found in Appendix A. Remark 2. Determining the satisfiability of 2cnf formulas or Horn formulas is substantially more efficient than for genuine 3cnf formulas [6]. 1.1. Problem Statement
An accepting tableau provides a visual framework to demonstrate the satisfiability of , affirming that N accepts w. The formula comprises two key components: and , both expressed as 3cnf formulas. Intuitively, , which incorporates constraints pertaining to the step-by-step behavior of N on w, appears to pose a much greater challenge for satisfiability. This raises the question of whether the distinction between being a 3cnf formula and being a cheap 2cnf formula actually matters.
1.2. Results
In this paper, we introduce our
FHB algorithm (“Filling Holes with Backtracking”) along with its refinement, the
rFHB algorithm. We show that if
can, hypothetically, be succinctly represented as a Horn formula, then the distinction between
being a 3cnf versus a simpler 2cnf formula becomes smaller. In this case, satisfying
can be achieved with the
rFHB algorithm in at most
steps, where
N operates within
steps and both
k and
K are constants. Here,
or arguably even
We further contextualize this result in
Section 7. In future work, we will explain how the method presented in this article can be applied iteratively, progressively reducing the exponent
.
1.3. Relevance
The immediate value of this work is twofold. First, it complements the author’s ongoing efforts to represent
—specifically, the step-by-step behavior of certain well-chosen nondeterministic machines in particular contexts—using Horn clauses to the fullest extent possible. Second, it provides an analysis that tackles one of the first nontrivial questions—outlined below—that engineering students commonly ask when encountering
-completeness in standard treatments [
1,
6,
7].
To illustrate part of this roadmap in a simplified manner, consider computational models with a constant number of nondeterministic choices. A conceptual example is solving a Sudoku puzzle, where constant nondeterminism can be leveraged as follows:
Guess a number for a single Sudoku cell.
After making this guess, follow the deterministic rules of Sudoku (each row, column, and box must contain the digits 1–9 exactly once) to fill in the rest of the grid.
If the puzzle is unsolvable with that guess, try another guess for the same cell.
In this Sudoku context, the Turing machine’s step-by-step behavior is a priori known to be deterministic in large predefined regions of the tableau. As a result, it can naturally be expressed as a Horn formula in those regions. While this may be nearly trivial from a theoretical perspective, software engineers exploit such application-specific properties to optimize performance.
Remark 3. In connection with related and upcoming results—where the author demonstrates how a binary choice an sich
can be reformulated using a Horn formula—see his Turing machine simulation on YouTube (click here: https://youtu.be/3jmBcgjES5I (accessed on 4 April 2025)) and his theory building [8]. Mathematical engineers, in contrast, also seek to explore a broader, context-independent question: Given two 3cnf formulas, and , which—if either—becomes easier to satisfy when the other is fully, yet hypothetically, transformed into an equivalent Horn formula? This theoretical question frequently arises among engineering students studying computational complexity, at least in the author’s experience.
In this paper, we assume that can be reformulated as an equivalent Horn formula. The reverse hypothetical scenario—where we assume that can be reformulated as a Horn formula—is not explored here.
1.4. Previous Work
Although contemporary accounts of -completeness are widely available, there is a notable absence of studies specifically addressing holes in a tableau. Theoretically, each cell always contains a single symbol, both initially and throughout. See the previously cited works of Sipser, Papadimitriou, Hopcroft et al., and Aaronson. We aim to fill that void by enhancing and utilizing geometrical symmetry within the “tableau with holes” framework.
1.5. Methodology
This paper contributes to the field of -completeness, with a focus on its foundational aspects. The research is supported by mathematical arguments, along with figures, tables, and graphs. While references to an off-the-shelf solver and algorithmic techniques (e.g., backtracking) stem not only from the literature but also from engineering practice, the content of this article is purely conceptual.
1.6. Outline
This paper is organized as follows. In
Section 2, we refine the problem statement involving
, and in
Section 3, we introduce an auxiliary formula,
. Then, we delve into the concept of a tableau with holes and prove three related claims in
Section 4. Next, we present and analyze the proposed backtracking algorithm in
Section 5, followed by a refinement thereof in
Section 6. Finally, we present our conclusions in
Section 7. This paper includes four appendices: standard definitions are given in
Appendix A, lemmas are provided in
Appendix B, a geometrical proof is presented in
Appendix C, and a solution to a recurrence relation is derived in
Appendix D.
2. Refining the Problem Statement
In a tableau, each of the
entries is referred to as a
cell. Specifically, the cell located in row
i and column
j is denoted as
and is supposed to contain a symbol from the set
. The contents of these cells are represented using the variables of
. When the variable
is assigned the value 1, it signifies that
contains the symbol
s. We also denote this situation as follows:
Similarly, we write
or
when
is assigned 0. We use ¬ and the overbar interchangeably to enhance readability.
2.1. Formula
The 3cnf formula
is constructed as a conjunction of two segments,
and
, structured as follows:
The first segment enforces that at least one variable is “turned on” per cell in the tableau, while the second segment ensures that at most one variable is “turned on” per cell. Although qualifies as a 2cnf–Horn formula, it is clear that is neither a 2cnf nor a Horn formula.
2.2. Formula
The second component of
is defined as:
The satisfiability of
, a 2cnf–Horn formula of size
, guarantees that the initial row of the tableau represents the start configuration of
N on
w, of length
n.
| = | |
| | | |
The boundary markers are denoted by ⊢ and ⊣, while □ represents the blank symbol.
The satisfiability of
, a 2cnf–Horn formula of size
, entails that no cell in the tableau may contain the state symbol
, thereby ensuring that an accepting tableau corresponds to a computation path
p that does not reach the
state.
For readers unfamiliar with this convention, see Grädel [
7] (p. 32).
To address the satisfiability of
, which captures the step-by-step behavior of
N on
w, we focus on the aforementioned instruction
as it applies to the following Turing machine configuration, denoted as
C:
We analyze the execution of instructions
and
separately—both outcomes are depicted on the left and right sides of
Table 2, respectively—before combining them into a single implication. This results in an expression of the form:
where both
and
take the form
. Ultimately, this forms a 3cnf formula corresponding to Sipser’s notion of a
window [
1] (p. 280). By taking conjunctions over all
windows defined by
N, and for each row and column in the tableau, we derive a 3cnf formula
of size
.
Whether the meaning of the formula
can be compactly expressed as a Horn formula
remains an open question. If one could answer this affirmatively, independent of a specific engineering context, it would provide a significantly simpler characterization of
-completeness than those found in the current textbooks. The only remaining non-Horn formula would be
, whereas current accounts characterize
-completeness in terms of two non-Horn formulas:
and
. See, for instance, Sipser [
1] (Section 7.4).
Hypothetically, if such a Horn formula does exist, it must differ from , i.e., . The Greek letter eta (), resembling the Latin letter h, is used here to highlight that the formula in question is a Horn formula.
By contrast, other formulas, such as
, are inherently Horn formulas:
For simplicity and readability, however, we often write
instead of
.
2.3. Trimming Down
Does the fact that is a 3cnf formula inherently make , with , computationally expensive to satisfy? To explore this question, we introduce one simplification, one assumption, and one extension—enabling a transition from to a trimmed-down formula, .
The simplification is as follows: we substitute the truth value of 1 for in , yielding , a 2cnf–Horn formula of size , for some constant . The satisfiability of allows for the presence of multiple empty cells, or “holes”, in the tableau.
The
assumption is the existence of the Horn formula
, of size
, where
is a constant. Consequently, we now replace
with
, defined as:
where Horn formula
is of size
, for some constant
.
The extension involves introducing extra constraints, represented by , a Horn formula of size , where is a constant. We define in the next section. The satisfiability of is implied by the satisfiability of .
From these three moves, we obtain:
where
Horn formula
is of size
, for some constant
.
Instead of working directly with , we focus on for the remainder of this paper. Typically, the tableau corresponding to a satisfiable contains holes. Consequently, it does not encode a single accepting path p of N on w; instead, it indirectly represents exponentially many paths. From this point forward, unless explicitly stated otherwise, any discussion of tableaux and propositional variables will pertain to , not .
Under significant nondeterminism (e.g., when the Turing machine N functions as a solver processing a nontrivial input w), and given that is satisfiable, using an off-the-shelf solver on the formula leads to nearly all cells of the tableau containing holes.
This insight can be derived through conceptual reasoning or practical implementation via computer programming, both of which the author has employed. The worst-case assumption—that the solver N makes several nondeterministic choices early in the computation—is realistic. Consequently, nearly all rows in the tableau remain undetermined, except for a few at the top.
Solver assigns a default truth value of 0 (i.e., false) to each propositional variable, switching a value from 0 to 1 (i.e., true) only when compelled by the constraints of the given Horn clauses. The solver never reverts a propositional variable assigned the value 1 back to 0. Since satisfying is sufficient, rather than the full , solver can satisfy while leaving nearly all propositional variables turned off.
Remark 4. To efficiently implement solver with a few for
loops, see the work of Dowling and Gallier [9]. Definition 2. Given and a corresponding tableau, we say that in the tableau contains a hole if is false for all
Definition 2 does not rule out the possibility that a specific variable
, for some
, may eventually be “turned on”, thereby filling the hole with symbol
at a later stage. For instance, consider the case where
contains a hole but is later filled by the user of solver
with the state symbol
, as illustrated in
Table 3. What are the implications of this action? To explore this, we now define the Horn formula
.
3. Formula
The formula
captures some global properties of a Turing machine computation. While it is redundant in the context of
’s satisfiability, it generally proves useful when
is satisfiable, i.e., when the tableau is potentially accepting but still contains holes. To formally define
, we begin by examining the example in
Table 3.
If
holds, where
—meaning
has a value of 1—then the tape head of
N can never visit any of the crossed-out cells in
Table 3. This restriction arises from the fact that a Turing machine can move its tape head only one cell to the left or right with each instruction and thus with each transition between consecutive rows in the tableau. Moreover, in each column of the tableau, all crossed-out cells either store or are expected to store the same tape symbol
. This restriction follows from the fact that a Turing machine can only modify a tape symbol when the head is positioned over that specific cell.
Therefore, filling the hole in with the state symbol effectively amounts to filling in all crossed-out cells, albeit indirectly. The requirement that holds implies that only cells that are not crossed out can contain the binary choices made by N on w.
Formula
expresses these restrictions as a conjunction of three parts:
The single part,
, ensures that at most one state symbol is stored per row. The left part,
, addresses the crossed-out cells to the left of
in
Table 3, while the right part,
, handles the crossed-out cells to the right.
Remark 5. Technical simplifications are possible in the following discussion but would come at the cost of pedagogical clarity.
3.1. The Single Part
We define
as follows:
where
and the column index
ranges from 1 to
. This condition ensures that if the state symbol
q is stored in
, it is the only state symbol in row
i. In other words, no state symbol
can be stored in any other cell within the same row.
Remark 6. The possibility of with is ruled out due to the satisfiability of . Suppose that holds; then, according to , no other symbol (e.g., ) can be stored in . Additionally, the reader will note that can already be deduced from . Nonetheless, explicitly stating this property does no harm.
3.2. The Left Part
We define
as follows:
On the one hand, we reason from row
i both towards earlier rows (
) and towards later rows (
):
where the restriction on
, denoted by
, is defined by the following inequalities:
Additionally, the expression
is shorthand for:
Example 1. For instance, if and hold, then the following must also hold:where is defined by the following inequalities: The reader can verify that all relevant cells range from at the top to at the bottom. These five cells correspond to the crossed-out entries in column in Table 3. On the other hand, we reason from the earliest row (
) and, respectively, the latest row (
) toward row
i:
where
is defined as the maximum (not the minimum) of the set:
Similarly,
is defined as the maximum of the set:
The satisfiability of ensures that if a specific cell, such as for some fixed m, is filled with the tape symbol , then—through a chain reaction partially facilitated by —all crosses in column are replaced with the symbol . A similar observation applies to the satisfiability of , which affects the propagation from an earlier cell, i.e., .
3.3. The Right Part
Given the inherent symmetry of the problem, the formal definition of closely mirrors that of and is therefore omitted from this paper.
3.4. Consolidation
In summary,
is indeed a Horn formula, with a size of
, where the constant
k corresponds to the running time
of machine
N. Furthermore, its satisfiability is trivially implied by the satisfiability of
. This last observation leads to the conclusion that if
is satisfiable, then
, with
is also satisfiable. Moreover, if
is satisfiable without any holes, then
is also satisfiable, indicating that
N accepts the input word
w.
4. Tableau with Holes
We assume that is satisfiable and that the tableau reflects this condition, typically containing several holes. A hole in the tableau, located at row index i and column index j, represents more than just an empty cell. To be conservative, we stipulate the following:
Single Hole: If is the only hole in the tableau, it corresponds to at most possible accepting computation paths, where is the cardinality of . (In fact, in this scenario, it contributes to representing at most one accepting path.)
Two Holes: If is one of two holes in the tableau, it contributes to representing up to possible accepting computation paths.
Three Holes: If is one of three holes, it contributes to representing up to possible accepting computation paths.
This pattern continues, with each additional hole multiplying the maximum number of possible accepting computation paths by .
In the general case, the tableau, composed of a polynomial number of cells, indirectly represents an exponentially large number of paths for N on w, including paths that are syntactically inadmissible from the perspective of N’s step-by-step behavior. Among the syntactically admissible paths, there are both rejecting and accepting paths.
This flexibility is achieved by leaving most cells unfilled. The Horn clauses associated with
remain implicitly active in the background, waiting for an external user to fill in a hole via an additional specification, such as:
Consequently, the solver
is called upon again, now tasked with satisfying
which stands for
. After two more user interventions, the solver is tasked with satisfying the following type of formula:
However, when the user’s guess, such as leads the solver to determine that the formula is unsatisfiable, backtracking becomes necessary. For instance, the user may replace with , where . Fortunately, as will be demonstrated by Claim 3 in this section, filling any hole in the center row of a convex polygon of holes scales the space for binary choices by a factor , with .
The remainder of this section is divided into three parts. First, we give examples to build intuition (
Section 4.1). Next, we increase the symmetry in our “tableau with holes” (
Section 4.2). Third, we leverage this symmetry to establish three claims (
Section 4.3).
4.1. Examples
The reader may compare
Table 3 with
Table 4, where the state symbol
is positioned two rows lower (row
). In this example, filling a hole closer to the center horizontal line of the tableau proves slightly more effective, resulting in 59 crossed-out cells compared to 57 for the original position. However, this is not universally the case, as
Table 5 illustrates.
To deepen intuition, three more observations can be made:
Regardless of the specific placement of
in row
in
Table 4, at least 50 out of the 110 cells will always be crossed out. This lower bound is illustrated in
Table 5.
Transitioning from
Table 5 to a higher-resolution tableau of 15 by 16 cells, as depicted in
Table 6, highlights a steady approach toward the limit of
crossed-out cells.
A second intervention in row 4 is shown in
Table 7, where the external user enforces
. This action results in 41 additional crossed-out cells.
Remark 7. To simplify our exposition, the leftmost columns in our depicted tableaux do not contain the boundary marker ⊢. However, strictly speaking, column 1 should contain the boundary marker ⊢, while state and tape symbols appear only from column 2 onward.
A previously unmentioned detail regarding
Table 5,
Table 6 and
Table 7 is that, due to the satisfiability of
, the state symbol
must be positioned in the upper-left corner of the tableau. Consequently, all other cells in row 1 must be crossed out, and the additional crossed-out cells in
Table 8 must also be accounted for.
We now discuss some specific base cases, where all rows but one contain a state symbol. Without loss of generality, the nondeterminism associated with Turing machine N consists solely of binary choices. For each such choice, say, between and , the movement of is to the left (−), while the movement of is to the right (+).
The first base case is shown in
Table 9. Although the state
, with the value
v stored in
, presents a binary choice between
to the left and
to the right, the presence of
ensures that only
can lead to an accepting tableau. Thus, this base case can be resolved automatically by the
solver
, without requiring any external user intervention. We realistically assume that
addresses this deterministic scenario.
An initial true base case is depicted in
Table 10. Since the path from row 1 to row 6 is fully determined, we can assume, without loss of generality, that a specific symbol, say, the symbol
b, is stored in
. The binary choice in row 7 is then defined by, say, the following two instructions:
.
.
As a result, either or must contain the symbol or , respectively. This problem features three holes and exhibits symmetry. Assuming the user selects , he fills the hole in with the symbol . Consequently, the other two holes are automatically filled in as well. Thus, in this base case, we achieve a filling factor of .
What if we consider
Table 11 instead? The only difference between this table and
Table 10 lies in the indexing of the rows. Since the top row begins with index 100, there is no guarantee that the values of the crossed cells in this row are already determined. In this scenario, there could be multiple possible ways for
N to transition from state
to state
, each involving a movement of one unit to the right. As a result, the values of the crossed cells in the immediate vicinity of
also remain undetermined. However, this situation is tangential to the main point. For, ultimately, there are at most
ways to resolve the binary choices (plural) in row 107, where
denotes the cardinality of
Q. For example, in addition to
and
as specified earlier, suppose
N also includes
and
as instructions originating from state
:
.
.
Consequently, either will eventually hold or , or will eventually hold or . The external user selects one of possibilities, and the solver automatically crosses out the remaining two holes accordingly, once again achieving a filling factor, regardless of whether concludes with “satisfiable” or “unsatisfiable”.
4.2. Enhancing Symmetry
Let us now adopt a more rigorous approach. A tableau with holes can be viewed geometrically as a collection of one or more convex polygons, each representing a maximum pocket of holes within the tableau.
When a straight line cuts a convex polygon, it divides the polygon into two smaller convex polygons. We assume familiarity with the following definition and lemma:
Definition 3. A polygon is a closed, two-dimensional geometric figure made up of a finite number of straight line segments. These segments, called edges or sides, are joined pairwise at their endpoints, known as vertices. The sides of a polygon do not cross each other, and the figure encloses a region in a plane. A convex polygon is a polygon in which all interior angles are less than , and every line segment drawn between any two points inside the polygon lies entirely within the polygon.
Lemma 1 (Cutting a Convex Polygon with a Straight Line)
. A straight line that intersects a convex polygon will divide the polygon into exactly two convex polygons, provided the line does not pass solely through one vertex or lie entirely along an edge.
Example 2. Consider an initially empty tableau, constituting a convex polygon P. Suppose, for illustrative purposes, that it is the user who injects into the tableau. As shown in Table 8, this action results in a straight line of crosses spanning from to that intersects P. This line forms a angle with both the horizontal and vertical edges of P. To further refine the symmetry of our geometric perspective, we introduce a few additional assumptions about the Turing machine N and its tableau representation. These assumptions are made without loss of generality.
First, we disregard boundary markers in our geometric considerations. As a result, column 1 directly contains state and tape symbols, while the rightmost column is indexed as . Formally, boundary markers can be included in our discourse if needed, but they are omitted here for simplicity.
Second, we assume that machine
N processes only inputs
w of even length. This condition can be ensured by designing the encoding function from natural numbers to strings
w to enforce this property [
10]. The implication is that
and
are always even and
and
are always odd, thereby simplifying our forthcoming case analysis.
Third, we emphasize that, after performing at most
steps, an accepting Turing machine
N does not halt upon reaching the
state (see Definitions A4 and A5). Moreover, we now generalize as follows: the machine need not remain in the
state, as long as it does not enter the
state (recall the definition of
in
Section 2.2). Going forward, we assume that the satisfiability of
ensures that
N roams in the
state around the central column
, moving towards the bottommost rows of the tableau. Specifically, the condition
must hold for some
. In fact, we aim to assert shortly that
.
Remark 8. Just like machine N with , it is possible to design nondeterministic Turing machine , which operates in time for some constant , such that . Suppose nondeterministic Turing machine , running in time for some constant , with , operates similarly to our original machine N, but with two tapes instead of one. The second (auxiliary) tape contains strokes before the computation of on w begins. We can make this assumption because any reasonable encoding function that maps natural numbers to string representations on the Turing machine’s tapes is of our choosing. As processes the input word w on its first tape, it simultaneously erases one stroke per step on the auxiliary tape. Once has finished processing w on the first tape and has entered the state, it ignores the first tape altogether and uses the remaining strokes on the auxiliary tape to determine how to enter or re-enter the state at . The two-tape machine is converted into the equivalent one-tape Turing machine, , with a polynomial overhead. Thus, we now have a nondeterministic one-tape Turing machine , operating in time, ensuring thatholds if and only if N accepts w within time. Building on the insights provided from Remark 8, and with a harmless abuse of notation, we assume that for machine
N the satisfiability of
guarantees
. In other words, the condition
is satisfied if and only if
N on
w accepts.
The caveat, however, is that encoding a natural number as an input string on the tape of
N does not necessarily comply with the stipulations defined by
earlier in this paper (see
Section 2.2). Simulating a two-tape Turing machine with a one-tape Turing machine requires a setup different from the assumptions made thus far. Furthermore, to enhance geometric symmetry, we aim for the satisfiability of
to ensure that the state symbol
is placed at the center of the first row, rather than in the leftmost cell.
This implies the following: the symbol
in row 1 is flanked by alternating stroke symbols and half of the input to its immediate left, while the other half of the input is interspersed with strokes on its immediate right. All other cells, with the exception of the boundary markers, contain the blank symbol □. The precise details of this arrangement are not central to our discussion. More important is that the input word
w has an even length
n (as noted earlier), which in turn ensures that both
and
are also even. Specifically, the satisfiability of
guarantees that the following condition is met:
To enhance symmetry one final time, we add an extra row at the bottom, forming a square grid with
rows and
columns, as shown in
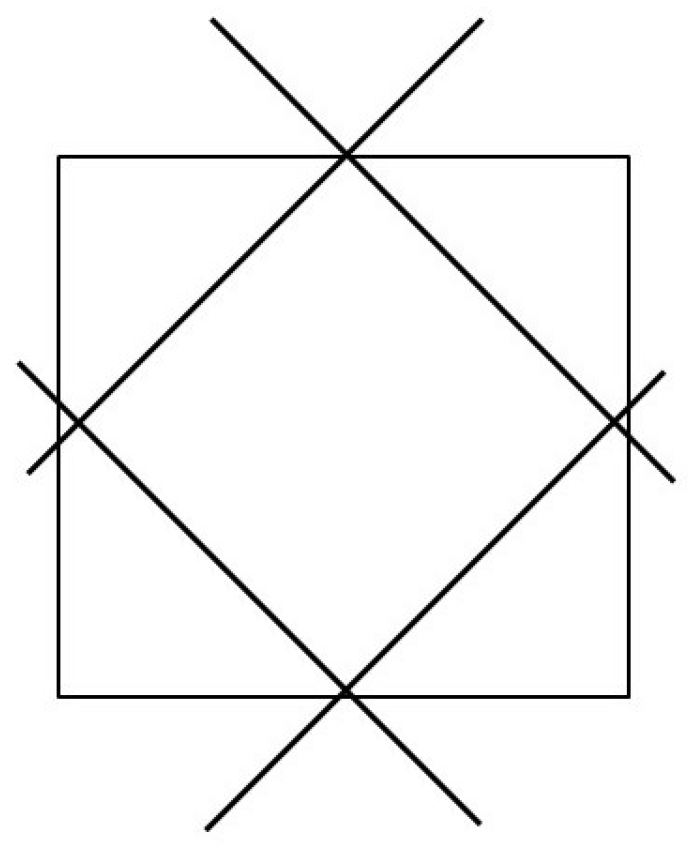
Figure 1. The top cross corresponds to
, while the bottom cross represents
. Consequently, for accepting
w, machine
N remains in the
state or re-enters it upon visiting
, instead of making this stipulation for
.
Table 12 illustrates this, with
.
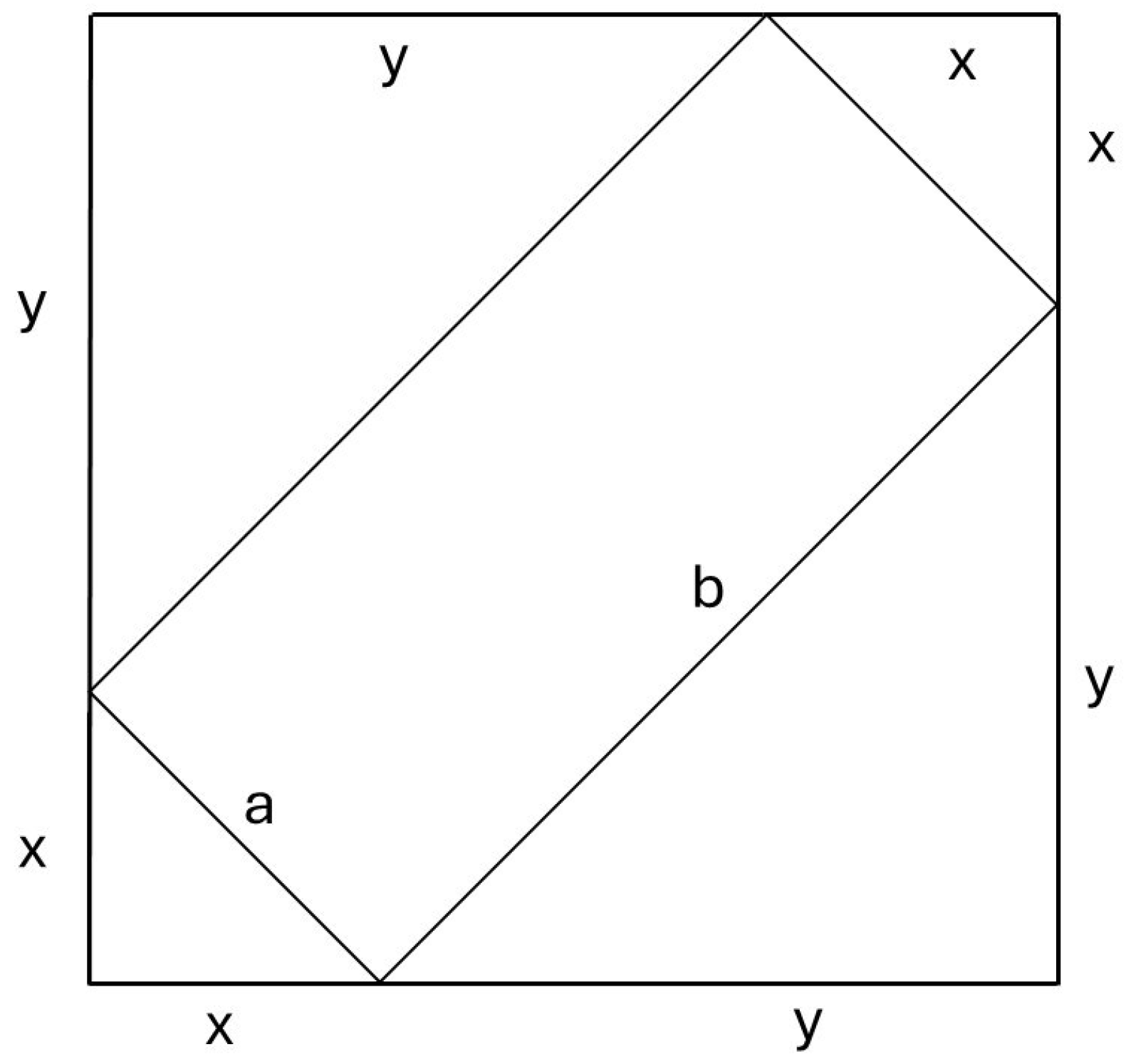
The result is a diamond-shaped polygon spanning
rows and
columns. See all the blank cells in
Table 12 to visualize this polygon,
. A sketch of
can be found in the top-left part of
Figure 2, where the center row, indexed at
, is highlighted with a dotted horizontal line.
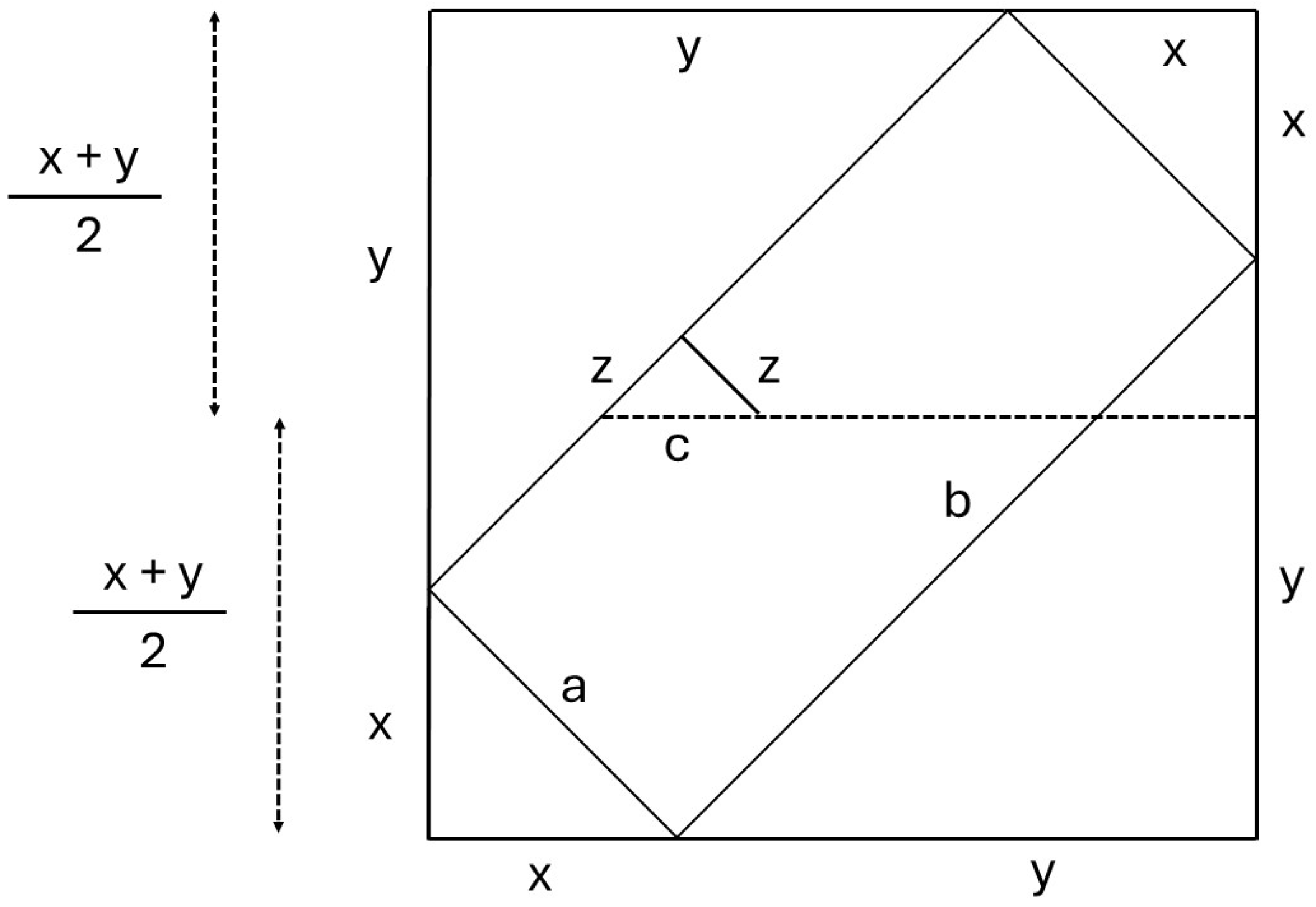
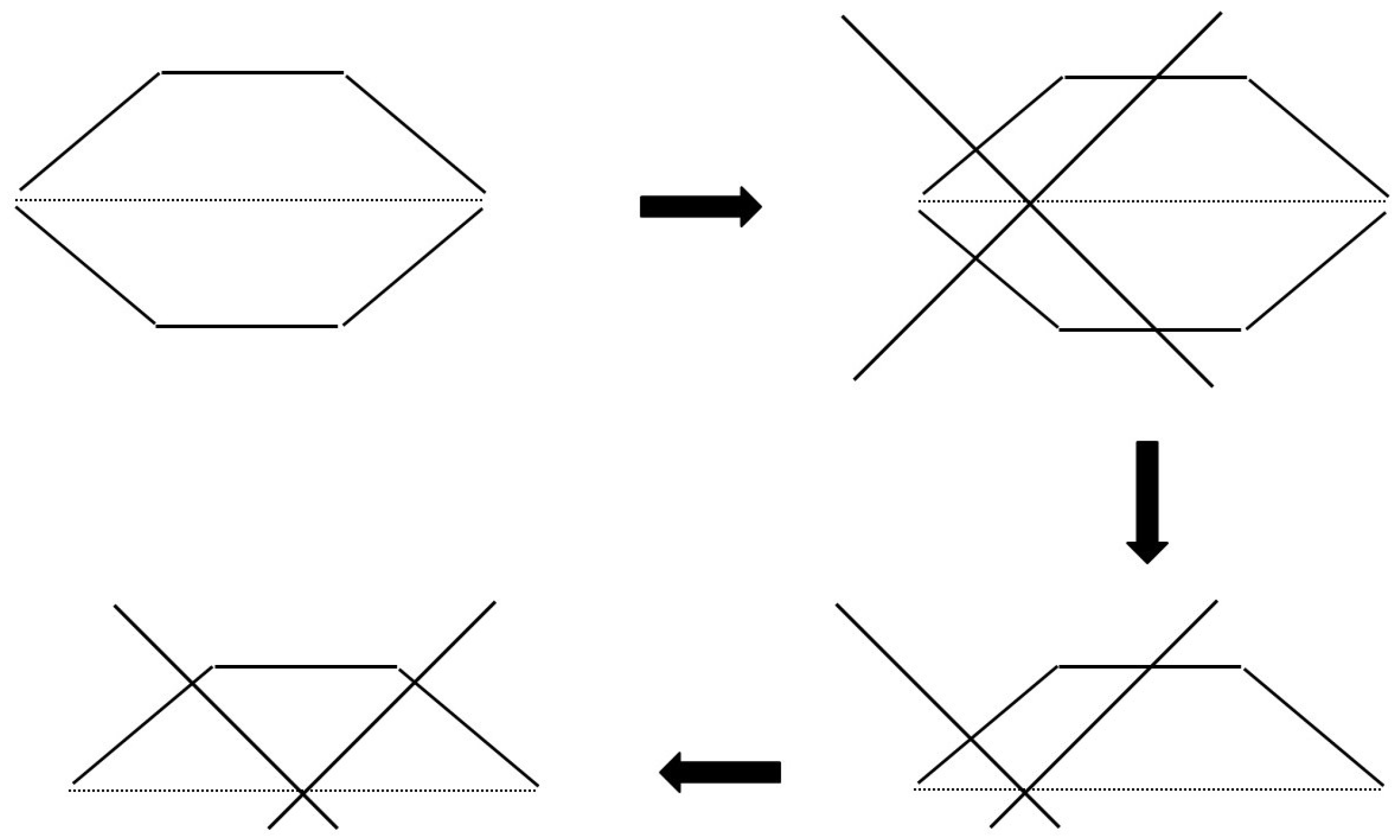
4.3. Reasoning with Symmetry
We continue with the top-right part of
Figure 2. The external user selects the center row of the tableau, which is the longest row in the polygon
, and then chooses an arbitrary cell in that row to place the center of the cutting cross, effectively injecting an arbitrary state symbol, such as
. Two illustrations are provided in
Table 13 and
Table 14, with the center row indexed as 9. Later, in rows 5 and 13, the user’s interventions will amount to even smaller polygons within the two depicted polygons.
It is unnecessary to treat each of the two smaller polygons inside polygon
separately. Indeed, given the symmetry of our geometric problem, we may transition from the top-right part to the bottom-right part of
Figure 2.
We are now prepared to formally introduce the geometric claims related to a tableau with holes. After performing m cross-cuts in the top half of the original tableau, let represent one of the resulting polygons. Now, consider , a smaller polygon contained within formed by introducing an additional cut, bringing the total number of cross-cuts to . If at most two rows in lack a state symbol, the problem becomes trivial to solve. The analysis in this section focuses on , assuming it contains at least three rows.
Specifically, we aim to establish the following three claims regarding and , where the relevant measurements are expressed in terms of the number of cells.
Claim 1. The center row of is the longest, yet other rows within may be as long.
Remark 9. We use the symbols H and D to denote, respectively, the length of a horizontal row and the dotted area of a polygon (see, for example, Table 15). Claim 2. The length of the center row of is at most times the length of the center row of , where . That is, .
Claim 3. We distinguish between a strong Claim 3 and a weak Claim 3:
- 1.
The total area of is at most times the area of , where . That is, .
- 2.
Filling any hole in the center row of the convex polygon of holes scales the space for binary choices within by a factor Δ, where .
Remark 10. The strong claim (1). implies the weak claim (2). as follows:We shall only rely on the weak claim in Section 5 and simply call this “Claim 3”. To establish Claims 1–3, we conduct a case analysis in the remainder of this section. We begin with the most symmetric case (
Section 4.3.1), proceed to a slightly less symmetric case (
Section 4.3.2), and conclude with the least symmetric case (
Section 4.3.3). Throughout, we rely on lemmas proved in
Appendix B.
In the final case (
Section 4.3.3), which encompasses the previous two cases, we are unable to prove the strong version of Claim 3. However, we establish the weak version via a geometric proof in
Appendix C, where we take a broader perspective on
. We therefore encourage the reader to view this section as an intuitive buildup to the final case, which naturally leads to the comprehensive proof presented in
Appendix C.
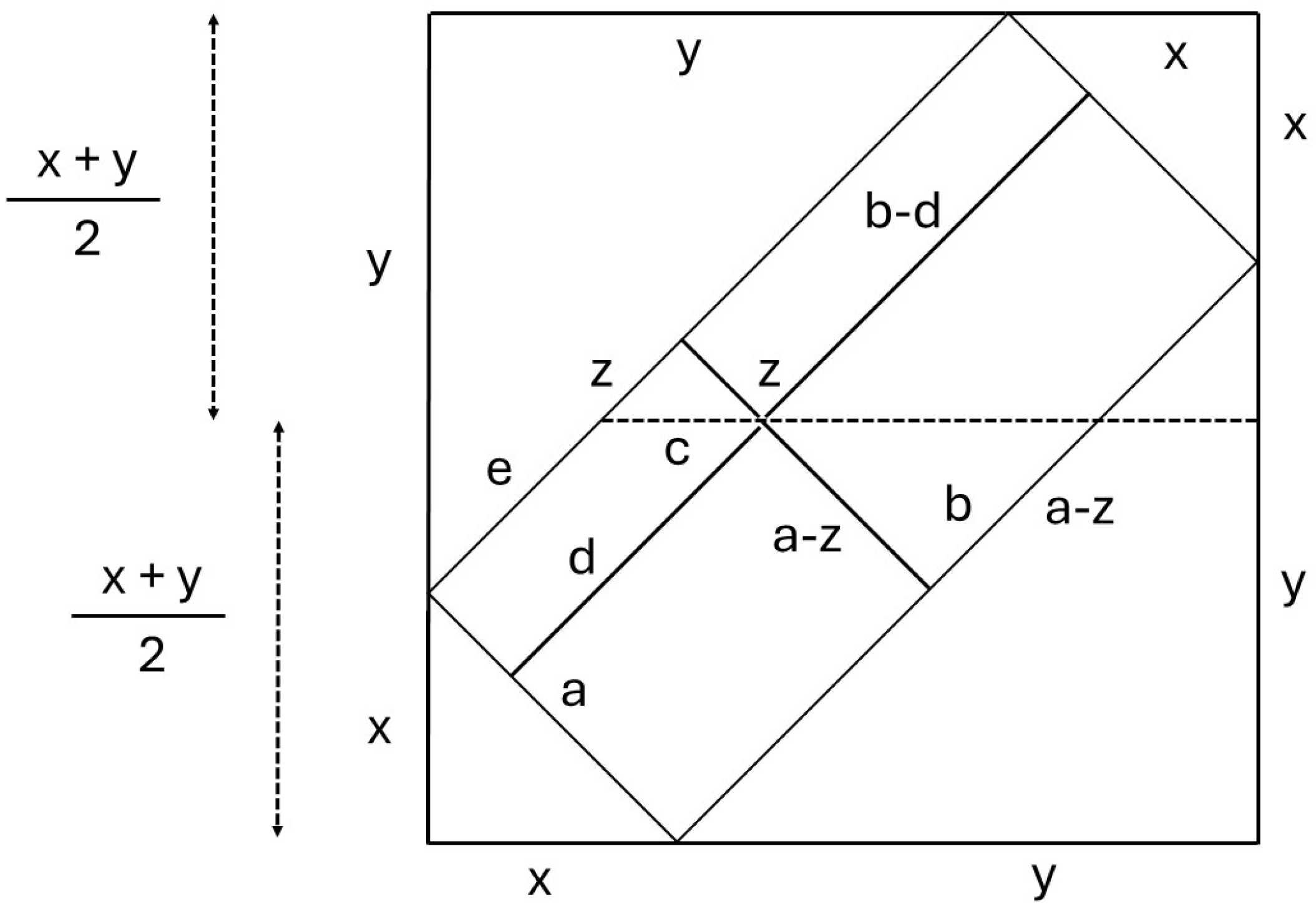
4.3.1. The Symmetry-to-Symmetry Transition Case
Rather than immediately analyzing the bottom-right portion of
Figure 2, we shift the cut to the middle of the center line, as depicted in the bottom-left portion of
Figure 2. Hereby, we examine the most symmetric scenario, specifically when the two state symbols are located in the same column. Readers are encouraged to compare the sketch in the lower left part in
Figure 2 with the first nine rows of
Table 14.
Transitioning from the top half of
Table 14 to
Table 15, we observe that the crosses have been removed, with the holes now represented by dots. Collectively, these dots form the convex polygon
.
We define
H, the length of the center row of
, as:
when
H is odd, and as:
when
H is even. For example, in
Table 12, we have
and
. Similarly, in
Table 15, we have
and
.
The symmetry of the current case implies that the center row is the longest and that
Therefore, Claim 1 is automatically confirmed.
Turning to the second claim, we differentiate between the cases where
is even and where it is odd. In the even case, we would have:
which would imply
. In the odd case, we begin with the following:
From these, we derive the equation:
Solving for
, we find:
As
, it follows that
. More significantly, as
,
. This establishes Claim 2.
Next, we define
D, the number of cells constituting the polygon, in terms of
N and
H:
For example, in
Table 12, we have
Similarly, in
Table 15, we have
We want to calculate the ratio,
, given that
On the one hand, we have:
On the other hand, we can express
fully in terms of
, as follows:
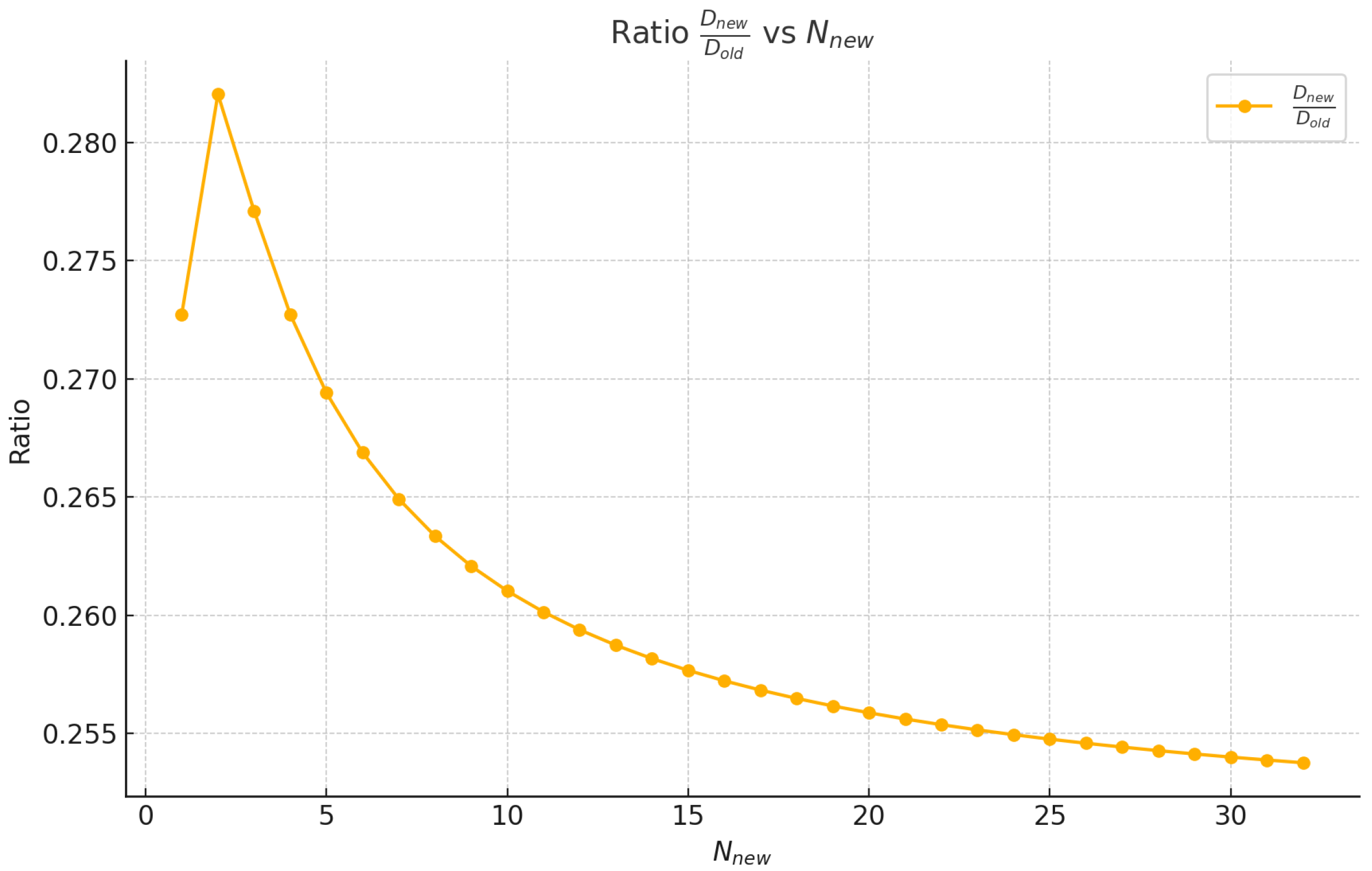
Based on some elementary algebra, we can prove the following two lemmas:
Lemma 2. .
Lemma 3. .
By applying Lemmas 2 and 3, we obtain
This ratio serves two purposes. First, readers can substitute small values of
to verify the data points presented in
Figure 3. Second, by evaluating the limit of the ratio as
, one finds that it is
.
Coming now to an actual confirmation of the third claim, we start thus:
and we note that as
,
. Also, as
, we have
. More significantly,
holds for all nonzero values of
. This establishes the strong version of Claim 3.
4.3.2. The Symmetry-to-Skew Transition Case
We now consider the transition from an outer, symmetric polygon
to a smaller, skewed polygon
, as shown in the bottom-right portion of
Figure 2. This transition is further illustrated in the shift from
Table 12 to the top half of
Table 13.
The three claims can be readily established, as follows:
Since the larger polygon is being cut with two straight lines, each of which is either orthogonal or parallel to ’s longest sides, the longest rows of must be situated at the center. The row lengths remain the same or decrease as one moves away from the center toward either the top or the bottom of . This confirms Claim 1.
The length of the center row of is even shorter than that of the center row in the polygon examined in the previous section (the Symmetry-to-Symmetry Transition Case). Thus, Claim 2 is readily established.
The total area of is even smaller than that of the polygon considered in the previous section. Consequently, Claim 3 is also confirmed.
4.3.3. The Skew-to-Skew Transition Case
We now examine the transition from an outer, skewed polygon
to a smaller, skewed polygon
. An example of
is shown in
Table 16, while an example of
appears, again as a collection of dots, in the top nine rows of
Table 17.
Regarding
Table 17, note that if symbol
is placed in the same column as symbol
—specifically, in
—rather than in column 12, no crosses will appear in row 5, the center row of
. However, in this stringent case, we do have a diamond-shaped polygon
again. This situation is depicted in
Table 18.
The straight lines of the cutting cross are either parallel or orthogonal to the two longest edges of the skewed polygon . As a result, the longest rows of must be positioned at the center. The row lengths either remain constant or decrease as one moves away from the center toward the top or bottom of , thereby confirming Claim 1.
Regarding the length of the center row in
, as shown in row 5 in
Table 17, we only need to consider the most stringent case, as shown in row 5 in
Table 18. We have
, thereby confirming Claim 2.
Concerning the third claim, we begin by noting that
where
denotes all the dots in rows
of
Table 18 and
represents all the crosses depicted in those same rows.
refers to all the dots in
Table 16.
To understand the ratio
in the general case, we express it as follows:
Lemma 4. .
Lemma 5. From Lemmas 2 and 4, we obtain From Lemmas 2 and 5, we obtain
As
, the ratio
Some more results are presented in
Table 19. In our running example, this yields:
Alas, these results do not validate the strong version of Claim 3. However,
Table 18 does suggest a compensation of crossed-out cells in the lower half of
. This observation, which brings us to the weak version of Claim 3, requires a more comprehensive geometric proof, which is presented in
Appendix C.
5. Filling Holes with Backtracking (FHB)
On the one hand, we have assumed the existence of the compact Horn formula
. On the other hand, we have validated (the weak version of) Claim 3, which asserts that filling any hole in the center row of a convex polygon scales the space for binary choices within the polygon by a factor
, where
. With these specifics established, we now turn our attention to filling holes with backtracking (
FHB)—an automatable process. Efficiency is achieved by relying on a refined version of the
FHB algorithm, as outlined in
Section 6.
Conceptually, the
FHB algorithm hinges upon the
solver
and integrates the actions of the external user, automating her interventions and incorporating backtracking as a built-in feature. We stipulate that
operates in polynomial time. While this polynomial can be replaced by a nearly linear function [
9], such details are irrelevant here.
Recall that
n is the length of input
w. The initial formula
,
is
literals long for some constant
. For example, if
is the longest formula of all three conjuncts, it follows that
, as explained in
Section 3.4.
Furthermore, we will have at most
extra stipulations of the form
, namely, one per row. Hence, an upper bound on the total cost of our
instance,
can be expressed as
for some constants
and
.
The FHB algorithm begins with , an instance of size , and thus , and runs the solver on it, resulting in a trivial “satisfiable” as a tentative outcome. (If N’s computation on w is deterministic, then the outcome is permanent and either satisfiable or unsatisfiable.) Next, the algorithm selects the center row of the tableau and injects the first state symbol q in into the leftmost hole in that row. If backtracking is required, subsequent iterations will use different state symbols, and if this does not suffice, the next hole (from left to right) in the row will be filled instead, starting again with the first symbol in Q, and so on.
For a row containing holes, there are at most ways to inject some specific into that row. This leads to our key observation:
There are at most ways to inject any into a row, where denotes the cardinality of Q.
The first user intervention results in scaling the space of binary choices by , shrinking from size to size . In the next two interventions, our algorithm selects the middle row of the first and second convex polygons of holes, read from top to bottom in the tableau. In the next four interventions, our algorithm selects the middle row of each of the four smaller convex polygons of holes, moving sequentially from top to bottom. This pattern continues in subsequent steps.
Immediately after each intervention, the FHB algorithm directs the solver to check the entire tableau for unsatisfiability and, in the process, simplify the underlying Horn clauses as much as possible, taking into account all constraints specified by , where the dots refer to the cumulative intervention stipulations made up to that point.
After each stage of interventions—one intervention in stage 1, two interventions in stage 2, four interventions in stage 3, eight interventions in stage 4, and so on—the solver
runs on an instance that has been shrunk in size by
. To be technically precise, the solver
continues operating on the entire instance, but the space of binary choices has been shrunk by a factor of
after each stage. As a result, we are
intrinsically dealing with an instance of size
after
m stages, where
. Hence,
m is bounded from above by
. Additionally, the bookkeeping for backtracking itself incurs at most a polynomial cost. A runtime stack with a constant overhead per recursive call is sufficient in practice [
11].
Remark 11. In future work, the engineer could reduce the exponent inby considering the on-the-fly generation of the Horn constraints associated with either in Section 3 and/or the constraints associated with in Section 2.3. For instance, the tailored constraints related to would be added only when a guess is made, causing the formula to grow incrementally with each additional guess and shrinking during backtracking. Similarly, the formula could expand and contract based on the placement of the q symbols in the tableau, rather than conservatively accounting for all possibilities in advance.
5.1. Recurrence Relation
To analyze the running cost of the
FHB algorithm, we set
in conformity with the result proved in
Appendix C. We begin by considering the following recurrence relation:
where
denotes the smaller of the two lengths,
a and
b. This relationship is illustrated in
Figure 4, a simplified version adapted from
Appendix C, specifically for the case
.
The recurrence relation expresses that there are
possible positions to place the crossing cut along the dashed horizontal line in
Figure 4. When
, the parameter
c ranges from 0 to
, which is equivalent to
. Similarly, when
, the parameter
c ranges from 0 to
, again spanning from 0 to
. In total, there are
possible ways to fill a hole in the middle dashed row, where the constant
represents the cardinality of the set
Q.
The recurrence relation also specifies that the original search space, consisting of
cells, is reduced to two smaller, equally sized search spaces of
each. This formulation explicitly excludes scenarios like the following one:
This exclusion may seem problematic at first. After all, the only requirement we know for certain is that the sum of the two smaller search spaces must equal half of the original search space, since we set
in this discussion. Specifically,
Despite this, the exclusion is justified, as we will now explain. In fact, the definition of can be further simplified without loss of generality.
5.2. The Devil’s Advocate
A recurrence relation for the
FHB algorithm, regardless of its specific form, must begin with
, as depicted by the diamond shape in
Table 12. During the first user intervention involving the center row of the tableau, the most favorable scenario occurs when the crossing cut is positioned at the leftmost or rightmost edge of the diamond. In either of these two extreme cases, only a single computation path remains, with all other paths discarded from further consideration: the search space is immediately reduced to a single computation path, starting from the top center, passing through either the leftmost or rightmost cell in the middle row, and ending at the bottom center. Conversely, the worst-case scenario arises when the crossing cut is placed exactly halfway along the center row. This results in the formation of two smaller diamond shapes, as illustrated in
Table 14.
The devil’s advocate naturally assumes the worst-case scenario at every user intervention. This assumption leads to
at each stage of the worst-case run of the
FHB algorithm, as illustrated by the transition from
Table 12,
Table 13 and
Table 14. With the invariant
, the devil’s advocate proposes the following simplified recurrence relation:
Consequently, we change variables with
, as follows:
Lemma 6. The dominant behavior of is exponential in . Specifically,where constant denotes the size of the state set Q and the constant depends on the size of the tape alphabet Φ.
Corollary 1. with constant . Remark 12. Corollary 1 is unsurprising, as dividing by 2
instead of 4
(in the recurrence relation) would lead to an exhaustive exploration, as follows:for some constant . A standard derivation is omitted from this paper. Before running the
FHB algorithm, as illustrated by the diamond shape in
Table 12, we have the following equation:
Again, the scalar 2 arises from
.
Now, let
denote the asymptotic runtime cost of the
FHB algorithm. Then, we can express it as:
Theorem 1. The runtime of the
FHB
algorithm satisfies the upper boundwhere is a constant and . Proof. The bound follows from the analysis in the preceding discussion. □
Theorem 1 suggests a prohibitive asymptotic runtime (with in practice). Fortunately, a refinement of the method yields a tighter upper bound.
6. Refining the FHB Algorithm
Even the devil’s advocate will concede that the previous analysis takes an overly pessimistic view by assuming that every cell in the tableau has the potential to contain a (binary) nondeterministic guess. In reality, the situation is far more favorable. Only a small part of the tableau involves binary choices, and more importantly, the outcome of each guess (i.e., the transition to either state or ) also determines the presence of a specific state symbol (e.g., ) in a particular cell elsewhere—typically further down—in the tableau.
To see this, let us analyze a 3-SAT solver . Notably, because any nondeterministic polynomial time Turing machine N (running on some input) can be reformulated in terms of the input for with only polynomial overhead, our discussion remains fully general.
Suppose the machine runs on an input word w of length n, where w encodes a 3-SAT formula with l propositional variables () and a number of clauses. Each clause consists of three literals—for example, .
Remark 13. We may assume that every variable appears in at least two literals across the formula ϕ; otherwise, such a variable (appearing only once) can be eliminated through preprocessing.
6.1. Coin Tossing
The machine
stores the encoded formula
w on its tape, following the conditions outlined in
Section 4.2. During an initial sequence of moves, the tape head shifts to the right, stopping at the first blank symbol immediately following
w. The machine then generates
l bits, proceeding from left to right and writing each bit—either 0 or 1—into a separate tape cell. This sequence, which is supposed to represent the outcome of
l independent coin tosses, is enclosed at both ends by a special marker #.
One outcome of any coin toss must correspond to a rightward movement (+) and the other to a leftward movement (−). To enforce this constraint—consistent with the previous sections in this paper—we implement the following behavior, starting in the tossing state:
If a coin toss yields bit 1, the machine moves its head one cell to the right and re-enters the state.
If a coin toss yields bit 0, the machine first moves its head one cell to the left and enters state , and then it performs two deterministic moves to the right, ending up in state again.
Upon completing this process, the machine will have generated l bits, where the j-th bit () represents the truth assignment for propositional variable . All remaining operations performed by the machine are deterministic.
Assigning the truth value 1 to the variable entails that, later on, the machine will set each encoded occurrence of in the word w to 1 and each encoded occurrence of to 0. (A similar remark holds for the truth value 0.) By implementing the proper FHB-procedures, filling holes with state symbols in the coin-tossing section of the tableau will automatically propagate to filling corresponding holes with state symbols in lower sections of the tableau. Moreover, once all l coins have been tossed, the remaining tableau—and therefore the entire tableau—is fully determined. Even the devil’s advocate would expect this property to be reflected in a worst-case analysis of the FHB algorithm or a refinement thereof.
6.2. Four Coin Tosses
Table 20 illustrates the structure of a coin-tossing process for
. The hyphens and dots in the figure represent potential positions of the tape head (i.e., state symbols), with the distinction between the two serving only for visual clarity. The two extreme computation runs are depicted solely with hyphens: the diagonal run at the top (consisting of five hyphens) produces all four bits as 1, while the zigzagging run takes longer to complete and results in all four bits being 0.
Specifically, the hyphen in
means that the cell contains the symbol pair
. Elsewhere in this paper, we represent this pair as
which occupies two cells instead of one. These notational variations are inconsequential and can be regarded as equivalent.
As
Table 20 illustrates, the coin-tossing process is represented by a table with
rows and
columns. This table can be embedded within a
mini tableau—and more generally, within a
mini tableau, for some constant
. The recurrence relation and Theorem 1 in
Section 5.2 apply to this
mini tableau.
Now, if the 3-SAT solver were solely responsible for tossing l coins, no further improvement in the worst-case runtime of the FHB algorithm would be possible. In reality, however, the tossed coins are made to correlate through the word w, which encodes the 3-SAT formula . For not all sequences of l coin tosses are valid—if any at all.
6.3. Properties of Computation
Appreciating that there is a correlation between the tosses amounts to recognizing the following two properties regarding the computation runs of on w:
6.4. A Conservative but Insightful Theorem
Our thought experiment—initiated by the hypothesis that the compact Horn formula exists—combined with Theorem 1 from our initial cost analysis leads to a refined version of the FHB algorithm. This improved algorithm (rFHB) relies on the two properties discussed above. We introduce rFHB in the proof of the following theorem:
Theorem 2. The runtime of rFHB, a refined version of the FHB algorithm, is bounded from above:where K is a constant and Suppose runs in time. (Typically, for an unsophisticated 3-SAT solver, and otherwise.) Consider the corresponding tableau. Based on the above discussion, we can refine the original algorithm as follows:
Guess a row
such that
holds, where
is the index of the rightmost column in the
mini tableau—with
in
Table 20.
The guess results in crossing out many cells in the remainder of the tableau, as described previously in item .
The associated cell crossings are revoked when backtracking from the guess.
Let the original algorithm operate in the mini tableau, yet in adherence to guess , starting with the center row of that mini tableau. (Take one of the two center rows when is even).
For each state symbol injected by the algorithm within the mini tableau, now also inject the corresponding state symbols outside the mini tableau (within the tableau).
Backtracking in the algorithm triggers backtracking of the corresponding state symbols injected outside the mini tableau.
The inferences from state symbols inside to outside the mini tableau must be pre-programmed. For example, if coin has been tossed to 1 early in the tableau, then—due to the preprogramming—the propagation’s state symbol (used when updating ’s truth value in w) is already known, deep down in the tableau. (Recall Remark 13 to grasp the underlying structure at work. After the coin-tossing stage—mostly beyond the confines of the mini tableau—the machine propagates the truth value of each propositional variable to the encoded 3-SAT formula w on the tape’s left side.)
A minor caveat is that, for any coin index
j (where
), there are
ways to specify that coin
was tossed to 1 (or alternatively, to 0). For instance, coin
in
Table 20 can land on 1 in two ways:
Each such case requires the symbol
to be activated in a predetermined cell
further down in the tableau:
where the contents of cell
encode the state of
after scanning the first clause containing the literal
.
Remark 15. If multiple clauses in ϕ contain the literal , analogous Horn implications apply to each such clause. The total number of Horn constraints scales polynomially with l and the number of clauses in ϕ. Note: and are distinct state symbols.
For a conservative cost analysis of the
algorithm, it is important to note that the free hole-filling outside the
mini tableau occurs in an area at least as large as the
mini tableau. This implies that, at the very least,
rather than
. Consequently, we solve the following recurrence relation:
for some constant
K. Finally, by substituting
for
m, we obtain the result:
with
Remark 16. While overly conservative, Theorem 2 with the exponent already demonstrates genuine compression compared to Theorem 1. Furthermore, if we set —a choice the devil’s advocate might readily accept—the exponent of m decreases further from to , which leads to the improved definition of in Remark 14. The iterative application of the rFHB algorithm will be discussed in a forthcoming article.
7. Conclusions
In this paper, we depart from the classical top-down interpretation of a nondeterministic computation of N on an input w of length n, which runs in at most steps. In the worst case, this classical approach requires making a binary choice at each step, resulting in a deterministic time complexity of essentially . Instead, we abstract away the complexity of enforcing N’s step-by-step behavior, hypothesizing that it can be succinctly represented by a Horn formula .
As a result, our focus shifts to a timeless tableau (with approximately rows and columns), in which the contents of each cell must be guessed. Now, we have increased the deterministic time complexity to . However, by leveraging a compression result related to the tableau and the behavior of the Turing machine’s head within it (recall formula , which leads to in Claim 3), we significantly reduce the search space. This ultimately results in a deterministic time complexity that is only slightly worse than the classical result (see Theorem 1).
Next, we distinguish between a pure coin-tossing machine, to which the previously discussed time complexities apply, and an actual 3-SAT solver—a nondeterministic polynomial time Turing machine that generates not truly random bits but rather correlated bits. In other words, the computational behavior of within a tableau can be further compressed, achieving a reduction factor of at least instead of , leading to a strong compression result (Theorem 2). In future work, we will apply this result iteratively.
The core idea behind can be summarized as follows. Consider an tableau, initially empty. By selecting two specific cells, above and multiple rows below, where N’s head should be located, we can force a binary choice to collapse into a deterministic move. This contrasts with the scenario where only one of these cells is filled with a state symbol, or where two nearby cells are each filled with a state symbol, allowing for greater nondeterminism. Specifically, if only the top cell, , is filled with a state symbol, the machine can move both left and right. However, if a second cell, , is filled at an extreme relative position later in time, various movements earlier in time become restricted—only several rightward moves, for instance, remain feasible for the machine to go from cell to the lower cell .
To further improve the reduction factor from to , we leverage the fact that the nondeterministic Turing machines involved in computations are not pure coin-tossing machines. Instead, their state transitions exhibit structured dependencies across the tableau. For instance, if the state symbol in cell indicates that the machine has just tossed the second coin to 1 (in one of multiple ways) and is about to toss the third coin, this constrains the state symbol in a later cell . Due to several dependencies—embedded in the tableau’s deterministic substructure—the machine may then be forced to toss the next coin to 1 rather than 0. This long-range interaction preserves the computation’s satisfiability, though the underlying mechanism is very subtle. Crucially, ’s computation on w does not develop top-down but grows in an interleaved fashion across the tableau’s rows.
To recapitulate, an accepting tableau provides a framework for demonstrating the satisfiability of , confirming that the nondeterministic polynomial time Turing machine N accepts the input word w. The propositional formula consists of two components: and , both in 3cnf. Since appears more challenging for satisfiability, this raises the question of whether distinguishing between 3cnf and 2cnf for is consequential. In this paper, we have proven that if can be compactly represented as a Horn formula, the gap between 3cnf and 2cnf for becomes small: can be satisfied efficiently in steps, with , where N operates in steps and both k and K are constants.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}