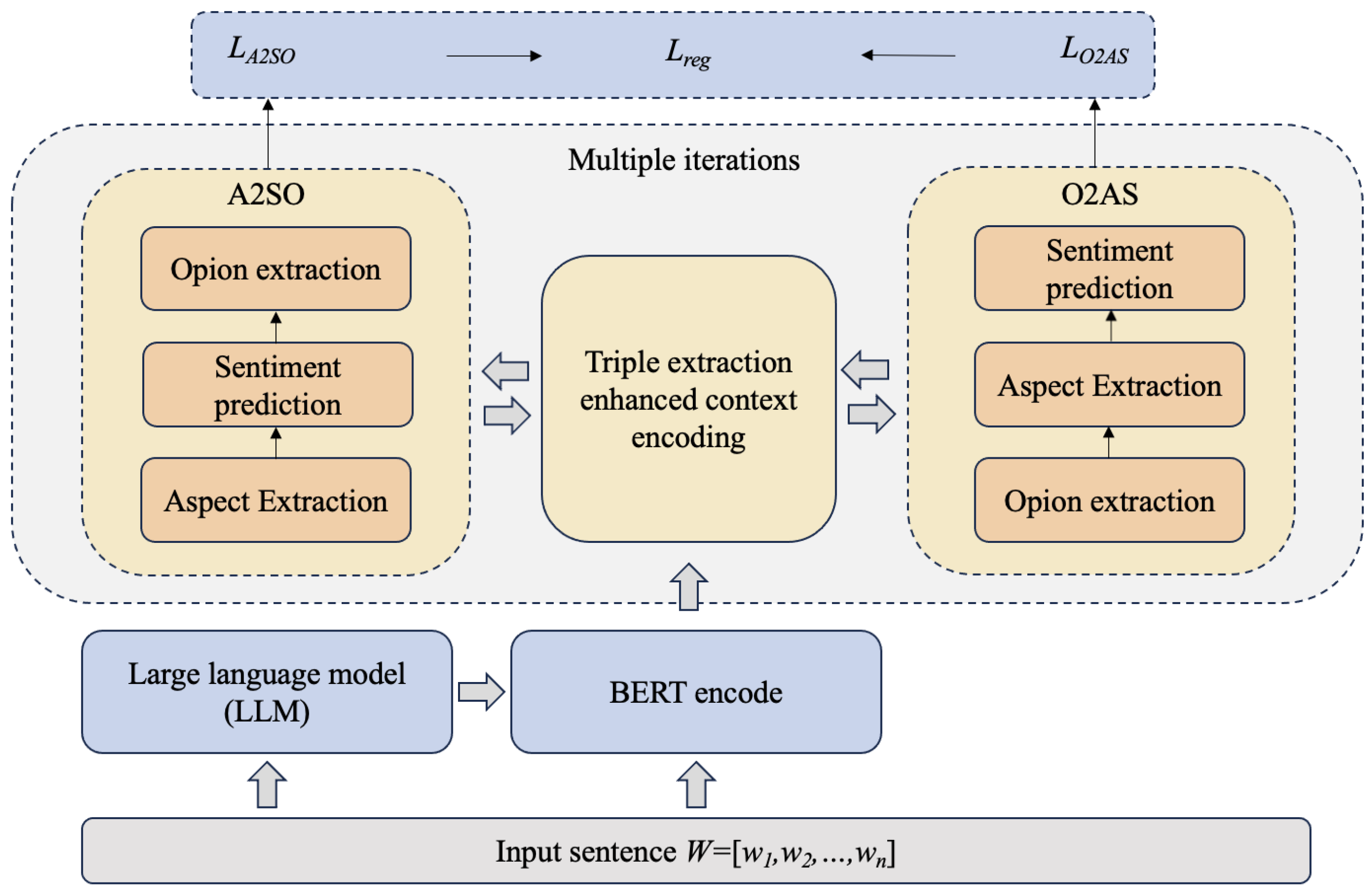
In this section, we present a comprehensive evaluation of the performance improvements achieved by our proposed framework for ASTE across multiple datasets. To demonstrate the efficacy of our approach, we first provide an extensive overview of the datasets used and detail our experimental settings. Building on this foundation, we then conduct an in-depth analysis of the results to elucidate the key factors driving the observed performance enhancements.
4.1. Datasets
To evaluate the performance of our proposed model, we employ three widely used datasets: ASTE-DATA-V1 [
5], ASTE-DATA-V2 [
6], and TOWE [
30].
ASTE-DATA-V1: The dataset was refined by Peng et al. [
5], based on the datasets originally proposed in the SemEval Challenges by Pontiki et al. [
31], with opinion annotations sourced from Fan et al. [
30]. It comprises four subsets: 14 res, 14 lap, 15 res, and 16 res. The dataset covers real-world reviews in the domains of laptops and restaurants. Each sample includes the original sentence, a sequence labeled with unified aspect tags, and a sequence labeled with opinion tags. A single sentence may contain multiple aspects and corresponding opinions.
ASTE-DATA-V2: The dataset employed in this study builds upon the ASTE-DATA-V1 and was further refined by Xu et al. [
6]. It comprises four benchmark subsets: 14 res, 14 lap, 15 res, and 16 res. In contrast to the original ASTE-DATA-V1, the revised version explicitly accommodates cases where a single opinion span is linked to multiple aspect terms. This enhancement better captures the intricacies of real-world sentiment expression and the many-to-one relationships commonly observed between opinions and targets in natural language.
TOWE: The datasets are derived from the SemEval Challenge series Task 4 of SemEval 2014, Task 12 of SemEval 2015, and Task 5 of SemEval 2016 by Pontiki et al. [
31]. These benchmark datasets span the restaurant and laptop domains and are widely adopted in various sub-tasks of ABSA, including aspect category detection, opinion term extraction, and opinion-dependent sentiment classification.
These datasets, spanning diverse domains, provide a comprehensive benchmark for assessing the generalization ability and accuracy of the model in ASTE. Each dataset comprises a rich collection of textual samples annotated with aspect terms, opinion words, and sentiment polarity, thereby serving as a reliable standard for evaluating practical performance. By testing our approach across these datasets, we gain a deeper understanding of the strengths and weaknesses of the model, which in turn guides further optimization and refinement.
Table 1 details the basic characteristics of these datasets, including the sizes of the training and test sets and the number of aspect terms, among other key metrics. No.sen represents the number of sentences and No.Asp represents the number of aspects.
4.2. Experiment Setting
During training, we employ the AdamW optimizer with a learning rate of 5 × 10
−5 and train the model for 20 epochs [
32]. A warm-up strategy is applied during the first 10% of training to accelerate convergence and enhance stability [
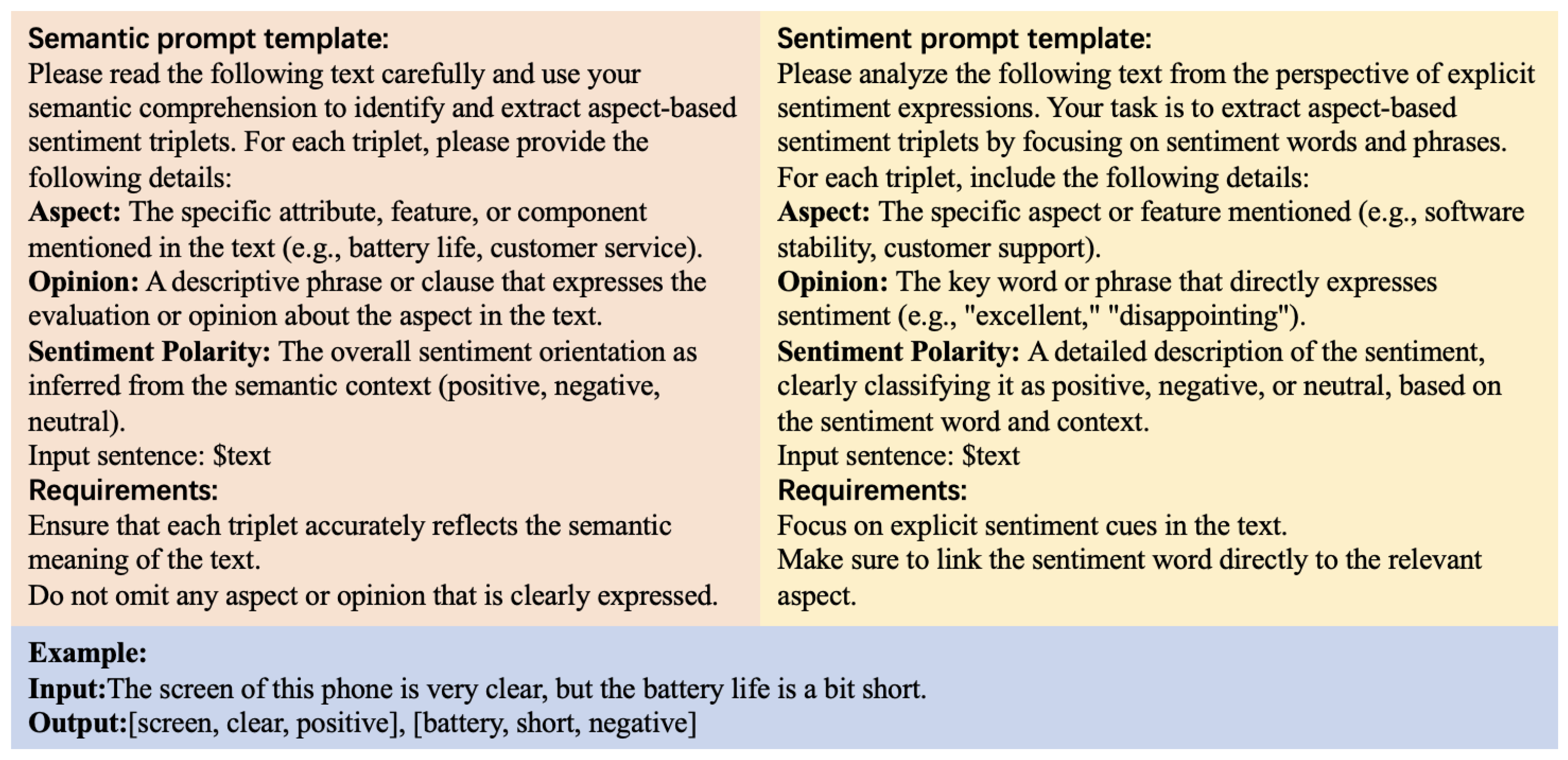
29], and a batch size of 12 is used to balance training efficiency with comprehensive feature extraction. To ensure the robustness and statistical reliability of our experimental results, we repeat each experiment five times using different random seeds and report the mean values. In the LLM generation phase, the DeepSeek-R1 (DeepSeek:
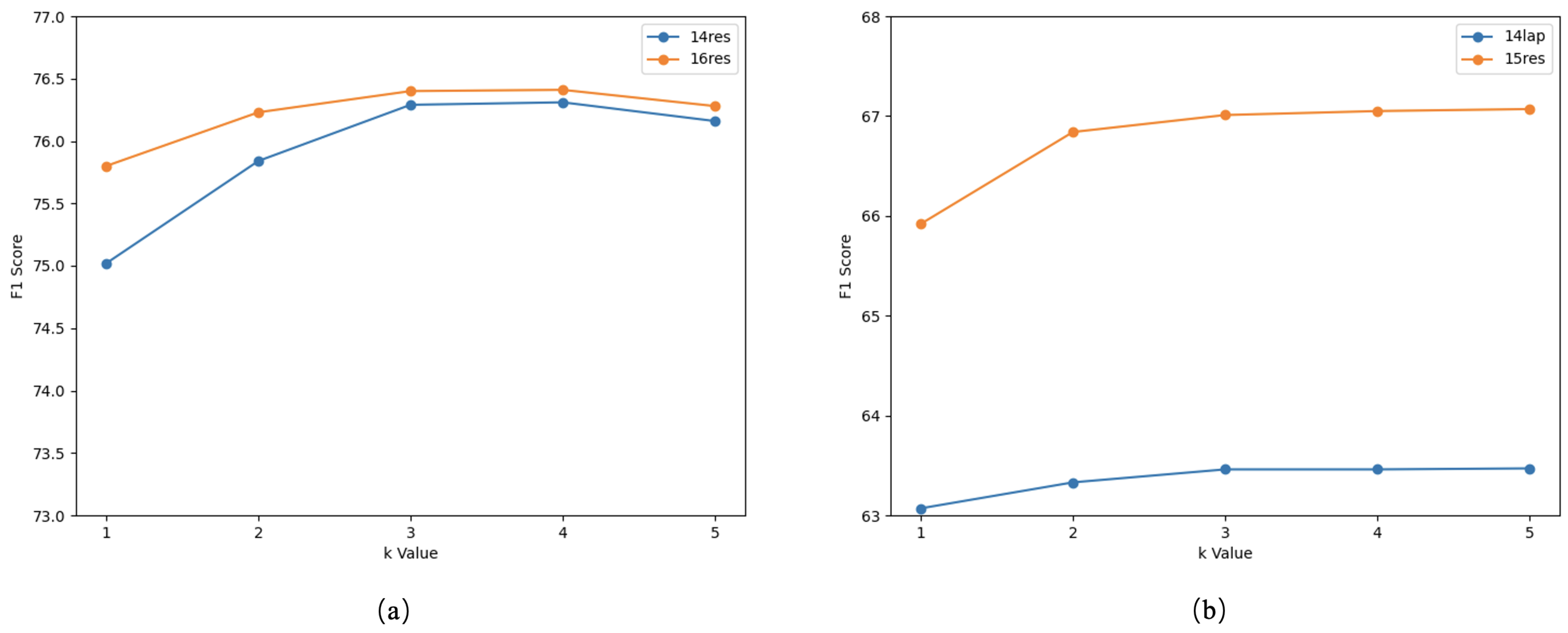
https://api.deepseek.com, accessed on 25 January 2025) model is utilized to generate aspect sentiment triplets. DeepSeek-R1 was selected as the backbone LLM for this study due to its strong performance, open-source availability, and cost-effectiveness. For the multi-round iterative process, the maximum number of iterations
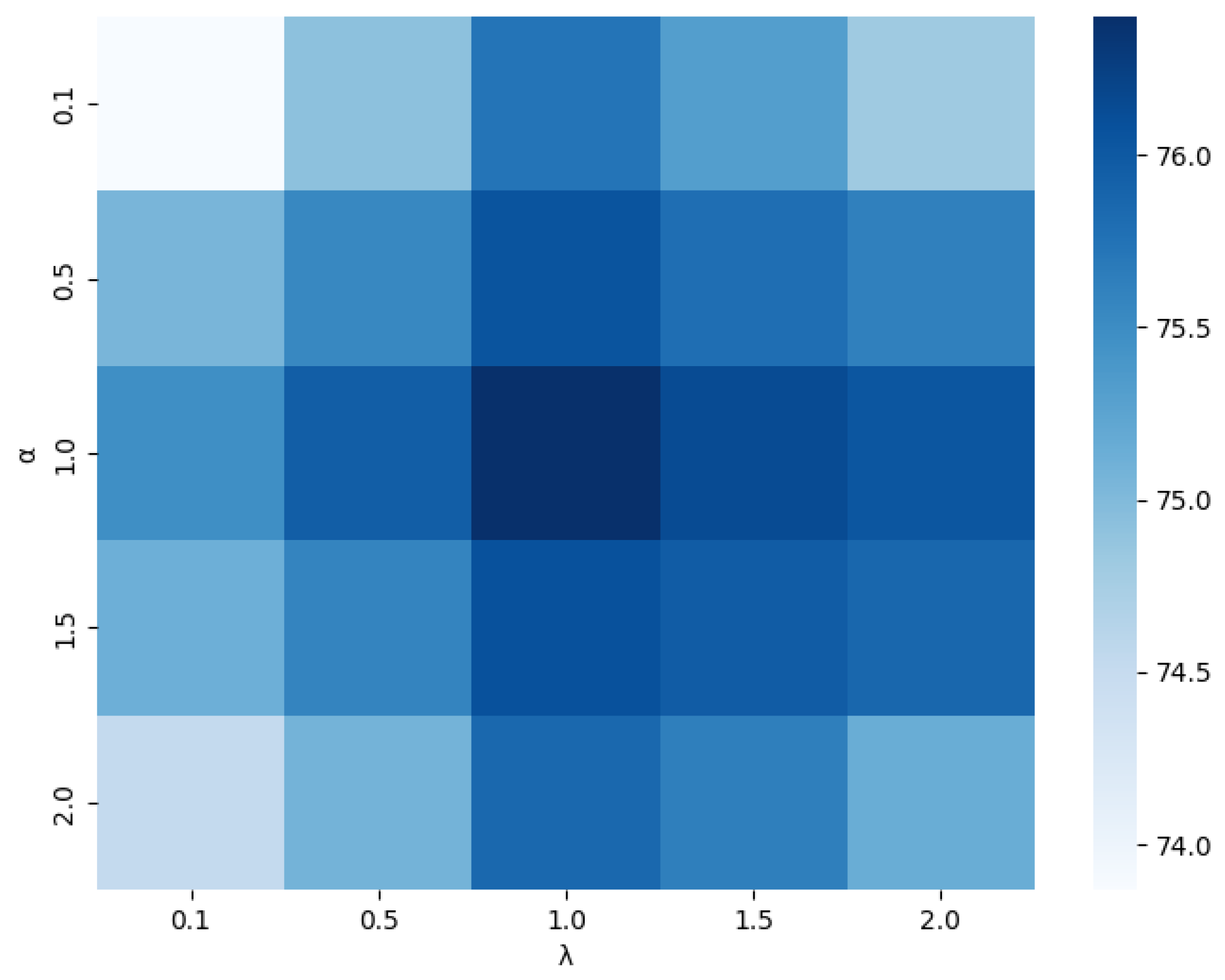
K is set to 3, and the confidence threshold is fixed at 0.80. The coefficients
.
In line with [
9,
11,
33], our evaluation framework encompasses not only the triplet extraction task but also three additional tasks to thoroughly assess model performance. To evaluate the effectiveness of our proposed model and ensure a fair comparison with state-of-the-art methods, we adopt three widely recognized evaluation metrics: precision (P), recall (R), and F1-score (F1). These metrics are particularly suited for the ASTE task, where correct identification of all three elements, aspect term, opinion term, and sentiment polarity, is required. Precision reflects the ability of model to produce only correct triplets, thereby quantifying its strictness in prediction. Recall measures the capacity of model to retrieve all relevant triplets, highlighting its coverage. F1-score, as the harmonic mean of precision and recall, offers a balanced view and is especially important when dealing with imbalanced data distributions common in real-world ABSA datasets.
A triplet is considered correct only if the aspect term, opinion term, and sentiment polarity all match the ground truth exactly, making these metrics both rigorous and appropriate for evaluating fine-grained sentiment extraction performance. Following previous works [
11,
15,
34], we report these metrics to maintain consistency and comparability across benchmarks. All experimental evaluations are executed on a GPU (Geforce RTX 3090, 24 GB).
4.3. Baselines
While an exhaustive comparison with every existing ASTE method exceeds the scope of this paper, we have selected representative and widely cited models from two major categories:
For two-stage extraction methods in aspect-based sentiment triplet extraction, baselines include CMLA+, RINANTE+, and Li-unified-R [
5], which are enhanced variants of CMLA [
35], RINANTE [
36], and Li-unified [
37], respectively. In addition, the methods proposed by Peng-TG [
5] and TGCN [
38] are also notable. The Peng-TG model first extracts aspects and opinions, subsequently pairing them, with sentiment being identified in the initial stage; in contrast, TGCN predicts sentiment based on the paired outputs. DAST [
11] introduces two distinct directional triplet extraction strategies that derive triplets from different combinations. These approaches often suffer from cascading errors due to their sequential design, where inaccuracies in one stage propagate to the next.
Regarding joint extraction approaches, OTE-MTL [
17] and Span ASTE [
13] employ multi-task learning to jointly extract all three elements of ASTE. Moreover, specialized tagging frameworks for triplet prediction have been proposed by GTS [
7], JET [
6], and Jing-SC [
8]. In addition, Dual-MRC [
9] and Bi-MRC [
10] leverage MRC-based designs for triplet prediction, while generative frameworks with pointer indexing have been developed by Yan-UG [
14] and SentiPrompt [
4]. Furthermore, GAS [
15] and PARAPHRAS [
34] model the ASTE task as a text generation problem, thereby generating all relevant elements from a sentence. While these avoid cascading errors, they tend to struggle with long-range dependencies and complex multi-sentiment targets.
These methods reflect the current state-of-the-art and predominant approaches used in the literature and demonstrate distinct advantages and performance characteristics across diverse application scenarios and datasets, providing a rich array of solutions for the ASTE task. Our comprehensive comparative analysis against these representative baselines effectively demonstrates the robustness and superior performance of our proposed DASTER framework.
4.4. Experimental Results
In this section, we present a detailed analysis of the experimental results on the AV2 dataset, the results shown in
Table 2. Our proposed model is compared against multiple state-of-the-art methods across four datasets. We employ precision (P), recall (R), and F1-score (F1) as evaluation metrics to ensure a comprehensive and accurate assessment of the effectiveness of the model.
The experimental results demonstrate the outstanding performance of our proposed method across all datasets, achieving the highest F1-scores on each dataset. Specifically, on the 14res dataset, the F1-score reaches 76.29%; on the 14 lab dataset, it is 63.46%; on the 15 res dataset, it attains 67.01%; and on the 16 res dataset, it even reaches 76.40%. These results consistently surpass all baseline models, underscoring the efficiency of our method in the ASTE task. In addition, to rigorously assess the significance of performance gains of our approach over DAST, we conduct two-tailed t-test on the 14 res, 14 lab, 15 res, and 16 res datasets. The resulting p-values, , and (), demonstrating that the improvements in F1-score are statistically significant. These findings substantiate the robustness of our approach relative to DAST.
For the 14 res dataset, our model achieves a precision of 79.32%, a recall of 73.57%, and an F1-score of 76.29%, which are 2.45% and 4.44% higher than those of DAST and Span ASTE, respectively. On the 14lab dataset, although our model does not attain the highest recall, it achieves the best precision and F1-score. In the 15res dataset, the recall of our model is slightly lower than that of the Span-ASTE model by 1.17%, yet it significantly outperforms Span-ASTE in terms of precision and F1-score, with improvements of 9.69% and 3.74%, respectively. In the 16res dataset, the performance gap is particularly pronounced; our method consistently outperforms baselines, achieving an F1-score of 76.40%, which is 2.36% higher than that of DAST, which achieved 74.04%.
Notably, recent methods such as DAST, SentiPrompt, PARAPHRASE, and GAS have demonstrated strong performance on the AV2 dataset; however, our method consistently outperforms them across all metrics. For example, compared to ASTE, our model achieves a 2.45% improvement in the F1-score on the 14res dataset, indicating that our framework effectively captures contextual dependencies and structured information to enable more accurate sentiment triplet extraction. Moreover, although prompt-based approaches such as SentiPrompt and PARAPHRASE exhibit commendable performance, they remain inferior to our model. Specifically, on the 16res dataset, our model improves the F1-score by 4.66% and 4.59% compared to SentiPrompt and PARAPHRASE, respectively. These results provide strong evidence for the effectiveness of integrating LLM with bidirectional methods, which better model syntactic structure and capture fine-grained aspect–opinion relationships.
Further analysis of precision, recall, and F1-score reveals that our model achieves a well balanced between high recall and high precision. In contrast, several baseline models exhibit a pronounced trade-off between these metrics. For instance, the Li-unified-R model and Peng-TG obtain high recall at the cost of low precision, resulting in modest F1-scores, whereas the JET-T and JET-O models favor precision at the expense of recall, which undermines overall performance. We attribute the superior performance of our proposed model to two key factors. First, our approach leverages a LLM as prior knowledge within a bidirectional extraction framework, effectively mitigating cascading errors. Second, a confidence-based iterative optimization strategy not only enhances classification accuracy but also incorporates high-confidence samples into training, thereby compensating for the limitations inherent in two-stage methods for triplet extraction.


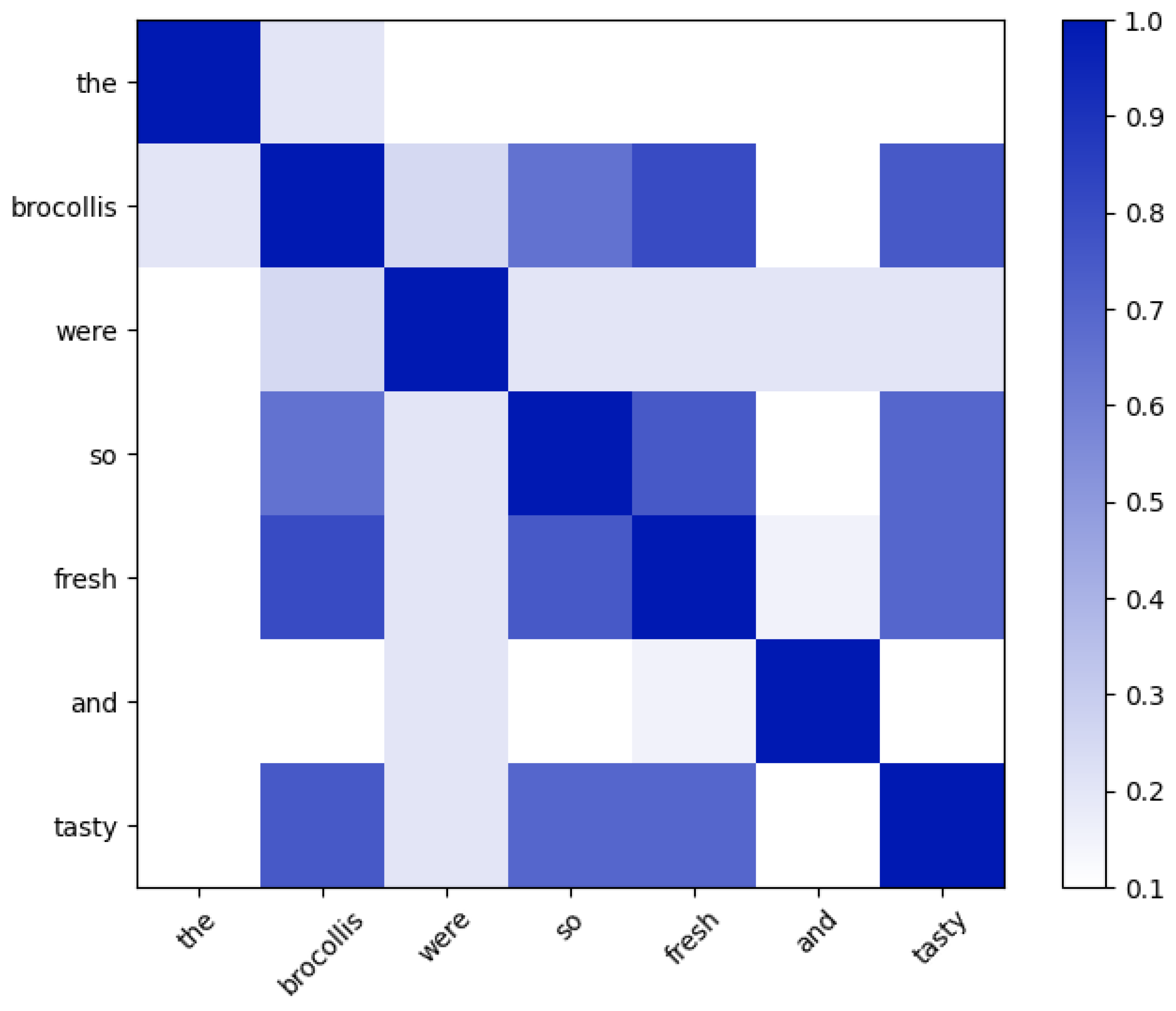


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}