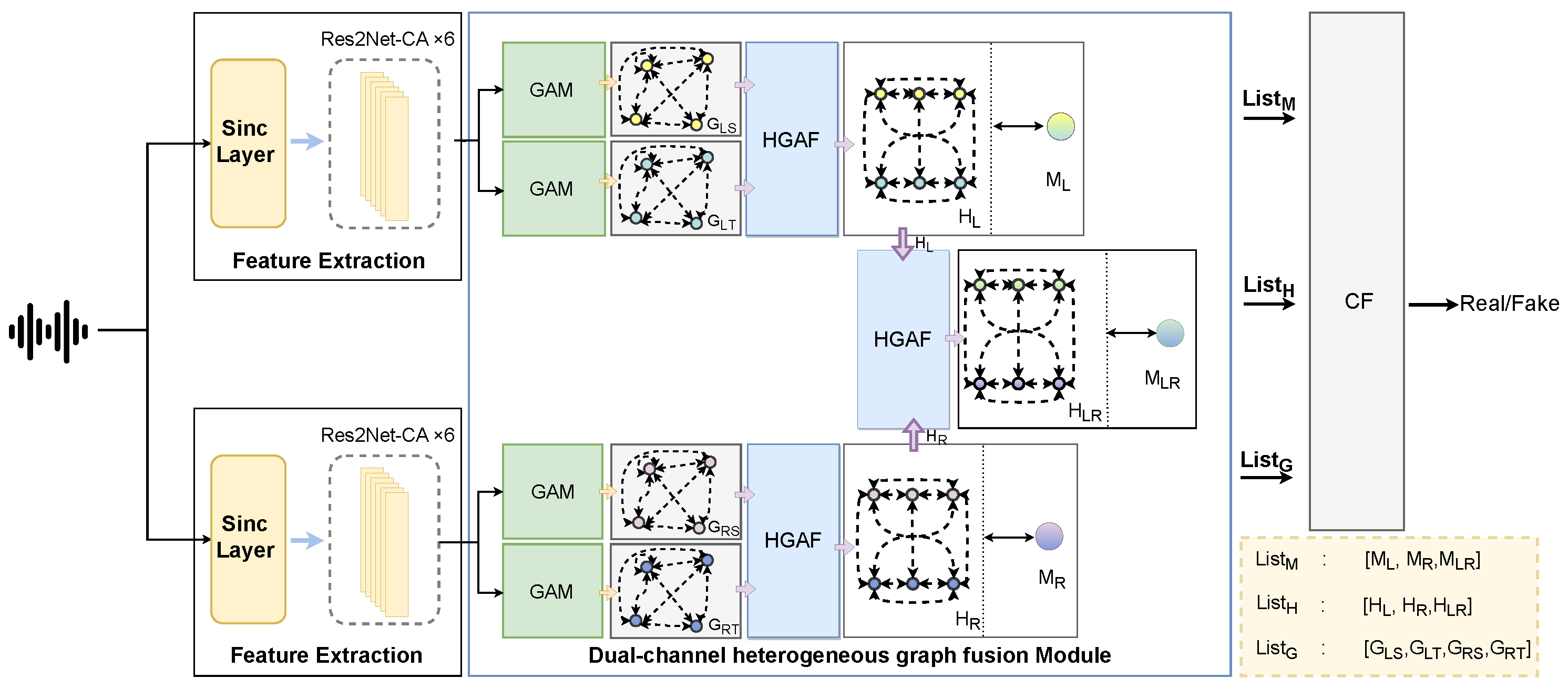
3.3.1. Graph Attention Module
For each vocal tract’s time–frequency representation, the time-domain and frequency-domain views are constructed, resulting in four views: the time-domain and frequency-domain views of the left and right vocal tracts. Because GAT can learn the relationship between artifacts in different subbands or time intervals [
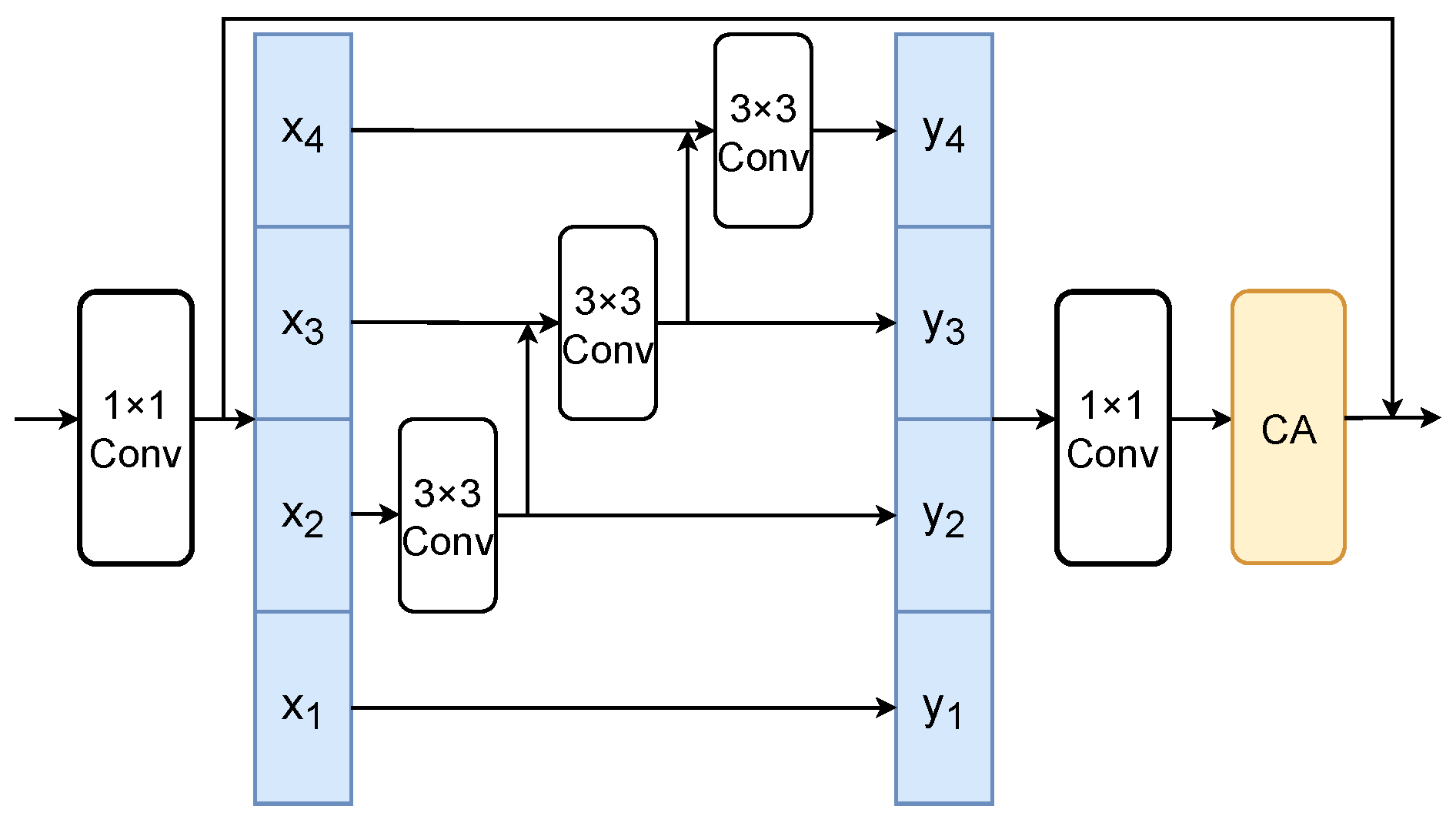
17], the GAT layer in the graph attention module (GAM) is used to aggregate relevant information by using self-attention weights between information pairs, and the graph pooling layer is used to discard useless and repetitive information, as illustrated in
Figure 3. Taking a single vocal tract as an example, in the time–frequency representation, the frequency feature corresponding to the time’s maximum value and the time feature corresponding to the frequency’s maximum value are used as inputs in two separate graph attention modules, each designed to capture different aspects of the features.
In the following text, the attention generation process of the GAT layer in the GAM is introduced.
- (1)
Schematic of attention generation in the GAT layer based on frequency domain features
In the input time–frequency representation, the frequency features corresponding to the maximum values in the time domain capture local dependencies in the frequency dimension. These local relationships are directly modeled by the standard graph attention network, avoiding the need for mean calculation and excessive smoothing, which helps preserve the sensitivity of forgery audio detection.
The frequency domain attention mechanism consists of the following parts. First, the pairwise relationship between nodes is calculated by element-wise multiplication and linear transformation. This allows adjacent frequency bands to interact directly, preserving fine-grained spectral artifacts. Secondly, the attention weight is normalized to focus on the most discriminative frequency component.
To compute the similarity or interaction strength between nodes
and nodes
within its neighborhood
, we first define an attention weight.
denotes the strength of the relationship from the u-th node
to the n-th node
, as show in Equation (
1):
Here, is a learnable map that adjusts the strength of the relationship between the nodes using the dot product, where ⊙ denotes element-wise multiplication. The element-wise multiplication (⊙) explicitly models local frequency interactions by amplifying co-activated patterns between node and its neighbor . The learnable matrix then projects these interactions into a relation space, where forged audio typically exhibits a weaker consistency compared to genuine speech.
Then, softmax is used to normalize the attention weights, resulting in
:
This coefficient determines the relative importance of node in updating the node representation.
- (2)
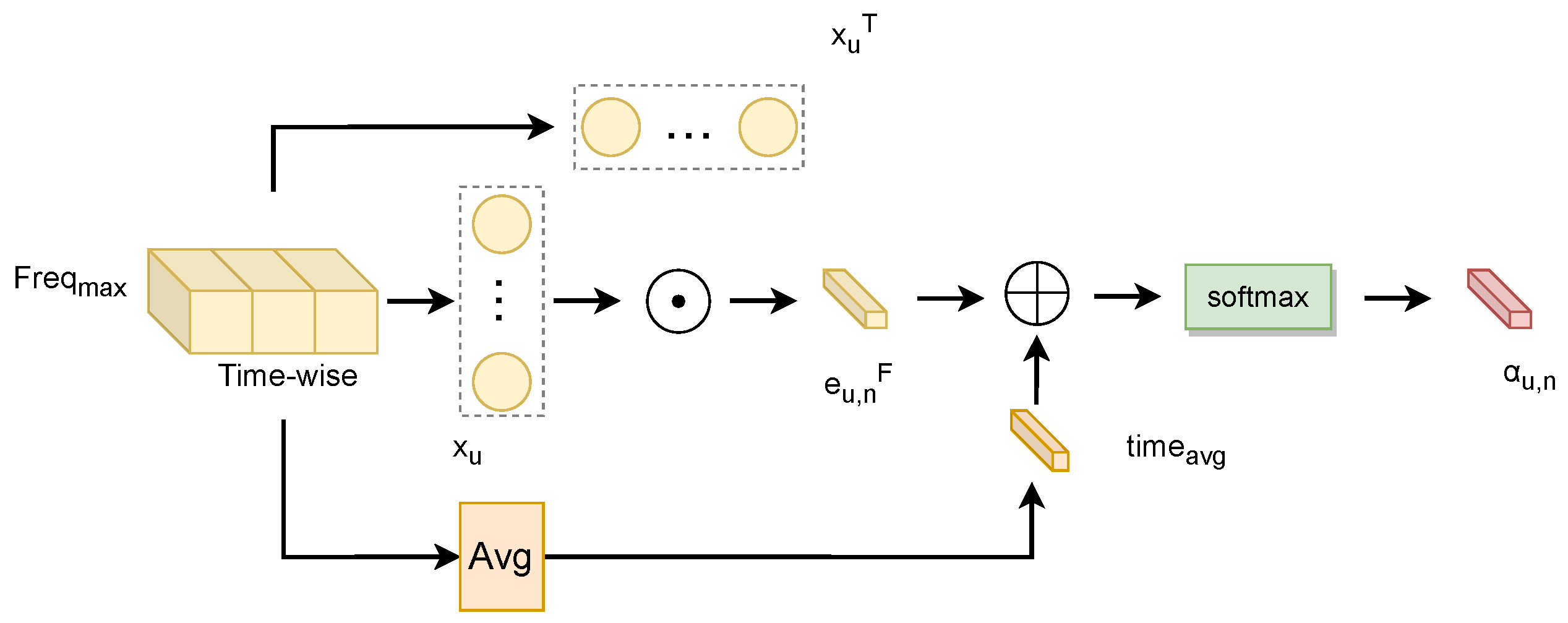
Schematic of attention generation in the GAT layer based on time domain features
This module takes as input the time-domain features corresponding to the maximum frequency magnitude in the time–frequency representation, focusing on modeling the time dimension. It introduces a mean matrix to enhance global statistical information and capture global patterns in the time domain, as shown in
Figure 4.
The mean value is computed using Equation (
3):
Equation (
4) represents the relationship strength between node
and node
in its domain:
To integrate the global context, we modify the attention score normalization by incorporating
as an additive bias:
This coefficient determines the relative importance of node in updating the node representation.
By introducing the mean matrix, the model can capture global relationships in temporal data during attention calculation, rather than being limited to local adjacency. Thus, temporal features may encompass broader global patterns and long-term trends. This enhancement improves the module’s ability to recognize long-term changes and global patterns, thereby strengthening the model’s representation of temporal data.
Except the above attention generation part is not the same, the other operations in the GAM are the same in time domain features as in frequency domain features.
For the GAT layer in the GAM based on time domain features, the updated node representation
is computed by aggregating its neighboring features weighted by the attention coefficient. Equation (
6) represents the node aggregation process in the GAT layer:
and
represent the projection of the aggregated and original nodes, respectively:
P denotes the projection operation, SELU denotes the scaled exponential linear unit activation function, BN denotes the batch normalization, and the final output of the GAM is . In the same way, the final output of the GAM based on frequency domain features is .
3.3.2. Heterogeneous Graph Attention Fusion Module
Previously, GAM had four views, each of which was represented as follows:
where
and
represent the time-domain and frequency-domain views of the left and right vocal tracts, respectively. Although each view contains useful information individually, these views are intrinsically complementary and mutually dependent. The time-domain and frequency-domain features of the same vocal tract describe the same signal from different perspectives. If their mutual relationships are ignored, the representations learned by the model may not be ideal.
- (1)
Heterogeneous graph construction
To better exploit the relationships both within and across views, we model them as a heterogeneous graph, where nodes from different views are treated as distinct node types. We adopt a heterogeneous graph attention fusion module (HGAFM) to learn view-specific patterns while simultaneously capturing cross-view dependencies.
Taking the left vocal tract as an example, the heterogeneous graph node aggregation process is introduced. For two views,
and
, where B is the batch size,
and
represent the number of nodes, and D is the feature dimension. To process the feature information from different views, we project the features from each view into a shared space before treating them as nodes in a heterogeneous graph, as shown in Equation (
9):
where
and
represent the node sets of the graph structure data
and
, respectively.
- (2)
Node aggregation
In the heterogeneous graph
, the relationship strength
between node
and node
within its domain is modeled using an attention mechanism, as given by Equation (
10).
The inter-graph attention mechanism adopts a two-node aggregation operation, and the specific operation is shown in Equation (
11):
Here, the learnable weights
are applied to nodes
and
, which are derived from the same set of nodes in
or
, respectively. When the nodes
and
belong to different node sets,
is applied to node
and
, which are derived from different node sets. Equation (
12) computes the attention weights between node
and all nodes in its neighborhood
. Then, softmax is used to normalize the attention weights, resulting in
:
where
is the set of neighboring nodes of node
, and
is the attention strength between nodes. Finally, the node features are updated as an aggregate of weighted neighbor node features. Equation (
13) represents the node aggregation process in the heterogeneous graph attention fusion network:
Equation (
14) indicates that node
is updated by applying a double projection operation on
and
:
The final output of the heterogeneous graph attention fusion module is the heterogeneous graph .
- (3)
Master node information augmentation
In order to enhance the model’s understanding of global information, the heterogeneous graph attention fusion module introduces a master node
to capture global information through interaction with all other nodes in the heterogeneous graph, thereby improving the representation of global features. The initial master node is computed as the mean value of
, as shown in Equation (
15):
where
N is the total number of nodes in the graph. The master node aggregation process is realized through the self-attention mechanism, where the learnable mapping
is used to measure the importance of the master node to other heterogeneous nodes, resulting in the normalized
, as shown in Equation (
16):
Here,
represents the aggregated information enhanced by the master node. Finally, the master node s is obtained by performing a double projection operation on s and
, and the calculation process is consistent with Equation (
14).
The heterogeneous graph fusion module operates on the left and right vocal channels separately to obtain the left vocal channel fusion view , master node , and attention map , as well as the right vocal channel fusion view , master node , and attention map . Then, the two vocal channel fusion views , master node , and attention map are obtained by taking and as inputs.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}