Remote sensing image change detection is an important research topic in remote sensing technology and is widely used in the fields of environmental monitoring, urban planning, disaster assessment, and agricultural management. Its main goal is to automatically identify and quantify land cover changes by comparing remote sensing images acquired at different times. With the continuous progress of remote sensing technology and imaging equipment, it is becoming more and more convenient to acquire high-resolution multi-temporal remote sensing images. However, the complex surface environment, diverse types of changes, and subtle change characteristics make change detection face many challenges.
In recent years, with the continuous development of deep learning, deep learning technology has been gradually applied to object detection [
1,
2], change detection [
3], and other tasks. Studies in the field of change detection have made various achievements. The Fully Convolutional Early Fusion (FC-EF) network proposed by Daudt et al. [
4] (subsequent iterations are based on the same principle) adopts the early fusion strategy, and the dual-temporal images are directly stitched in the input layer. Its overall structure is simple, and its computational efficiency is high. However, its ability to detect complex changes is limited, and it cannot fully extract and utilize deep features. The DTCDSCN proposed by Liu et al. [
5] uses densely connected Siamese networks, which can enhance feature transfer and multiplexing to capture richer change information. However, the high complexity of the network leads to its long training time and high demand for computing resources. The SNUNet proposed by Fang et al. [
6] adopts a symmetrical nested U-Net structure, and the nested structure can capture multi-scale features and improve the detection accuracy. However, this symmetrical nested structure makes the network structure complex, with large parameters and a long training time. The MFPNet proposed by Xu et al. [
7] uses a multi-feature pyramid structure in the architecture and combines multi-scale features for change detection. The multi-scale feature extraction can adapt to change regions of different sizes, and the pyramid structure can enhance the detail in the expression of features. However, it has a high computational complexity and long training time, which is sensitive to the feature fusion strategy and parameter settings. The BiT network proposed by Chen et al. [
8] uses large-scale training to continue transfer learning and enhance the change detection ability. This allows the model to obtain rich features and improves the performance in small sample scenarios. However, this makes the model bulky, requiring a large amount of training data, and the training is complex. The ChangeFormer proposed by Bandara et al. [
9] adopts the Transformer structure to deal with the remote sensing image change detection task. The Transformer architecture captures long-distance dependencies and better captures large regions of change. However, it has high computational resource requirements and a long training time. Recently, the MSCANet proposed by Liu et al. [
10] effectively improves the accuracy and robustness of change detection in high-resolution remote sensing images through multi-scale context aggregation and feature fusion. However, its high computational resource requirements, model complexity, and dependence on high-quality data also bring corresponding challenges. Later, the AMTNet network proposed by Liu et al. [
11] introduces an attention mechanism and Transformer structure. It significantly improves the accuracy and robustness of remote sensing image change detection. However, its high demand for computing resources, long training time, and complex parameter tuning process also bring certain challenges. The DATNet proposed by Zhang et al. [
12] combines a Transformer with a dual-attention mechanism and introduces a difference enhancement module to greatly improve the detection effect of different buildings, roads, and vegetation changes. However, its difference enhancement module branch is not fully combined with the Transformer module branch.
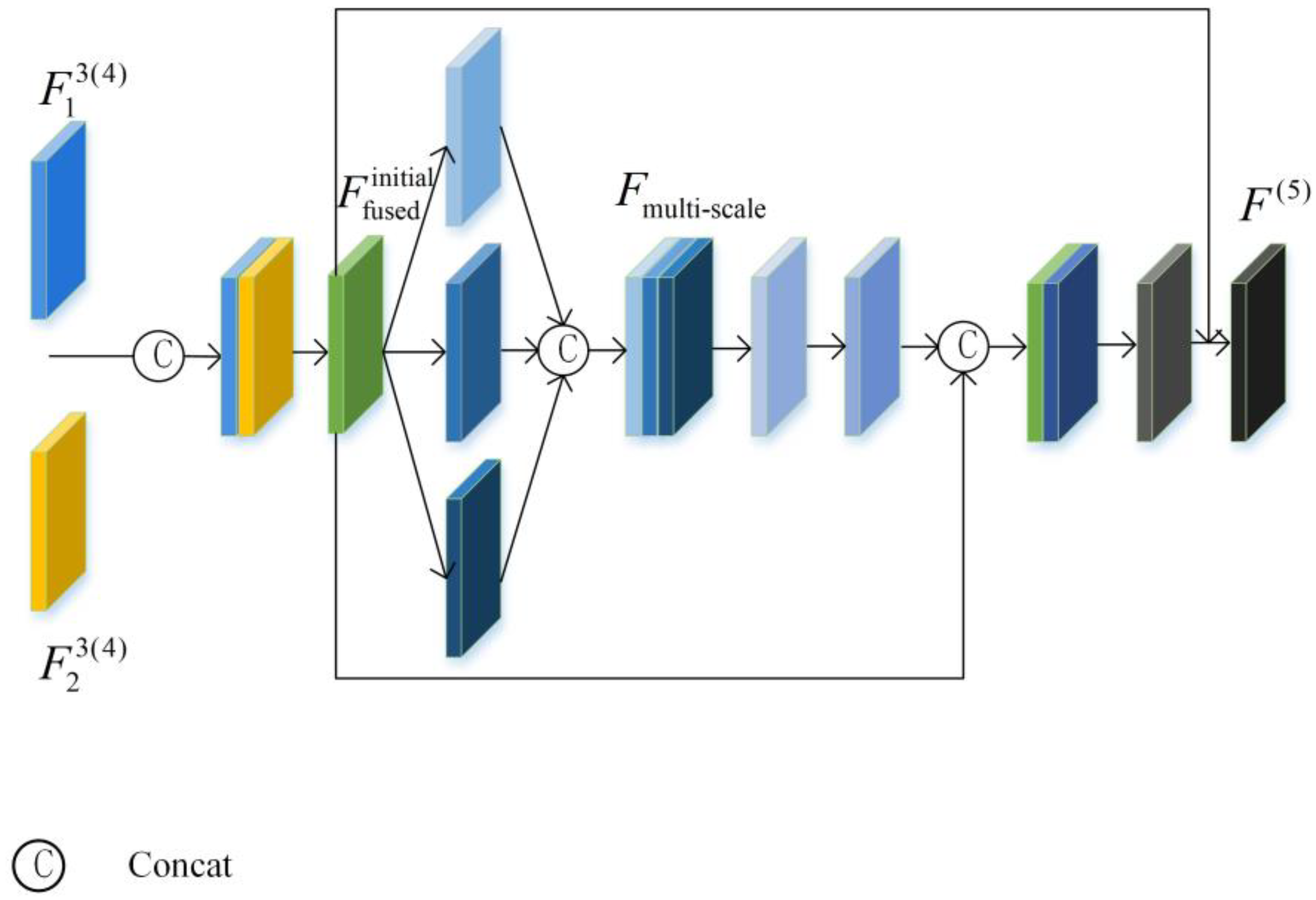
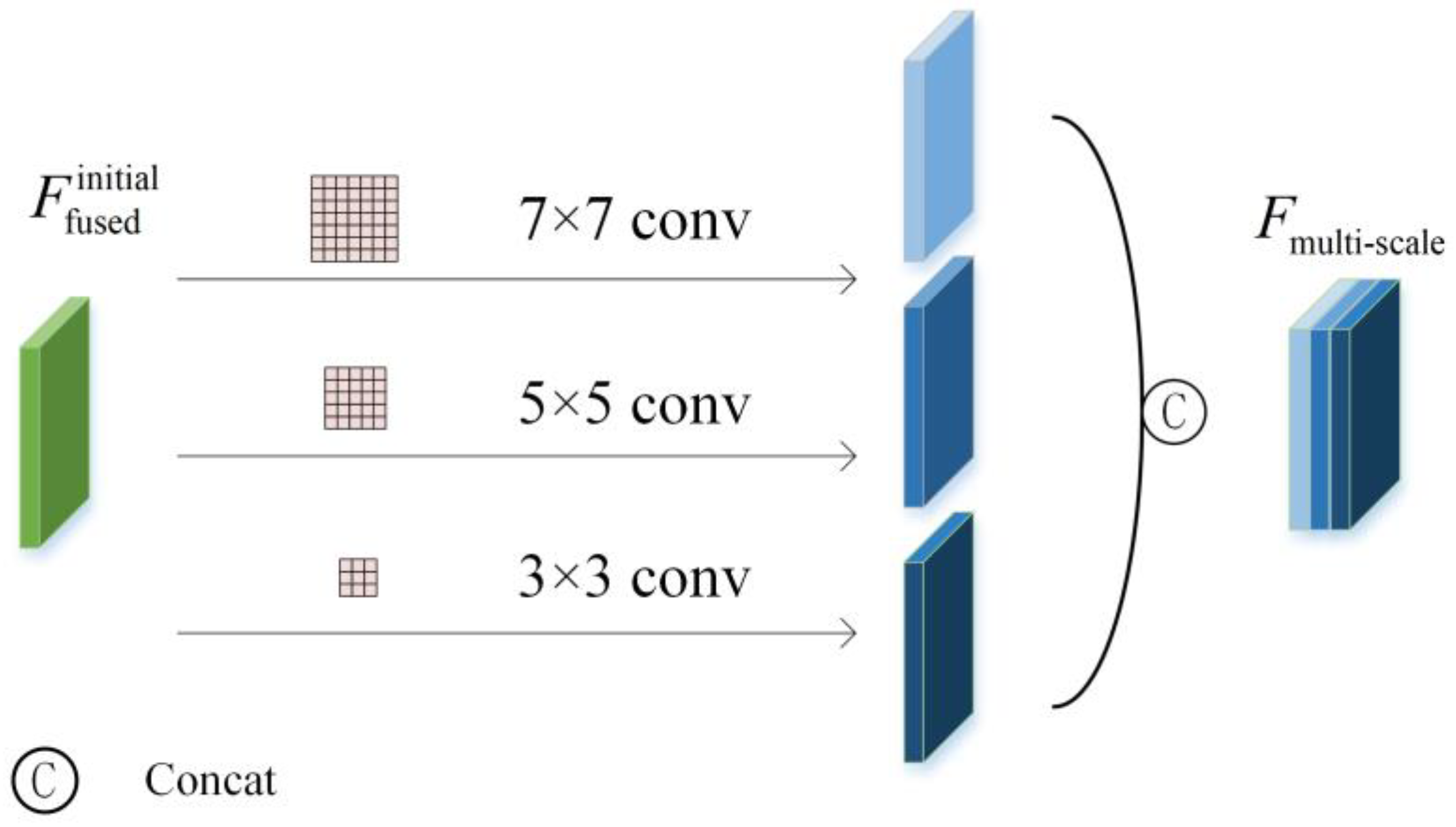
To address the aforementioned issues, this paper proposes a multi-scale feature fusion network based on difference enhancement (FEDNet) for remote sensing image change detection. The FEDNet incorporates an efficient ResNet-50 [
13] backbone in the feature extraction stage of the Siamese network, improving the detection accuracy without increasing the parameter complexity. By combining feature exchange with a channel attention module, the FEDNet enhances contextual representation and bridges domain gaps between bi-temporal images. Finally, a classifier analyzes the fused feature maps to accurately locate and quantify change regions. The experimental results demonstrate that the FEDNet achieves outstanding performance on various remote sensing datasets, particularly in detecting complex environments and subtle changes. The main contributions of this paper can be summarized as follows:
This research presents a multi-scale feature fusion method based on difference enhancement for remote sensing image change detection. The approach achieves high-precision change region identification by fully leveraging multi-level features. To further enhance the system’s performance, we will explore physics-based deep learning solutions. Yan et al. [
14] demonstrated the powerful potential of integrating physical information with neural networks, successfully applying this approach in pantograph–catenary system modeling. The algorithm unrolling technique proposed by Monga et al. [
15] provides us with a new research direction, systematically connecting iterative signal processing algorithms with neural networks while improving the model’s interpretability and data efficiency. The DIVA network developed by Dutta et al. [
16] further proves the excellence of quantum physics-based unfolded architectures in processing non-local image structures, with its adaptive patch-level adjustment mechanism showing outstanding performance across various image restoration tasks. In future work, we plan to integrate algorithm unrolling techniques with our difference enhancement framework to develop change detection systems with better physical interpretability and computational efficiency, further improving the model’s generalization ability based on limited training data and complex scenarios, while exploring semi-supervised learning strategies to reduce the dependence on labeled data.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}