
Semantic Matching for Chinese Language Approach Using Refined Contextual Features and Sentence–Subject Interaction

Abstract
1. Introduction
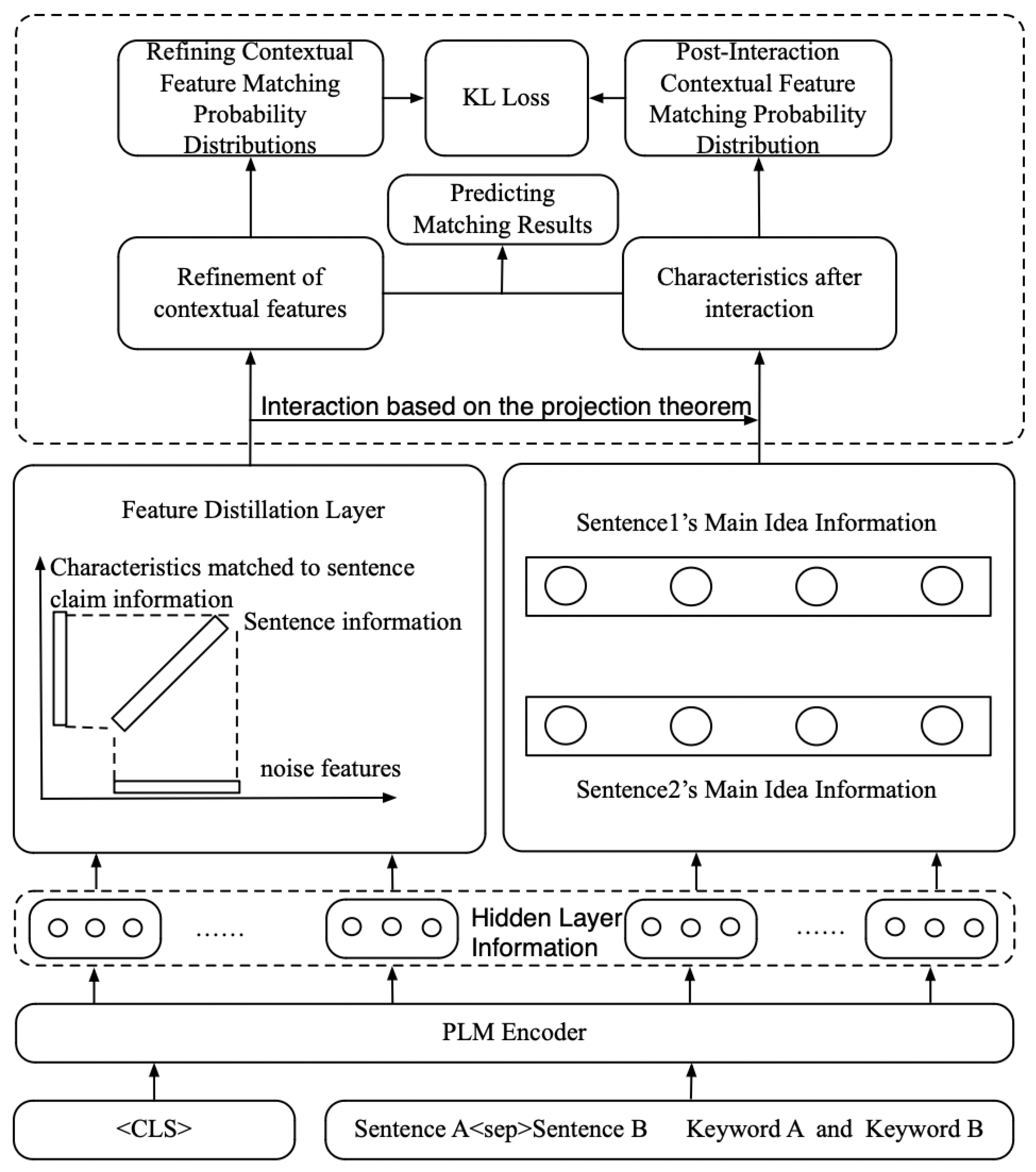
- Adaptive refined contextual feature distillation technique: Weakly correlated features are filtered using dot product attention and a GRL (gradient reversal layer), and then projection theorem is used to reject noise and obtain refined features.
- The innovative projection of sentence subject features into a fine-grained contextual feature space enhances the interactive matching ability between the sentence subject and contextual information.
- Supervised feature distillation and post-interaction feature combinations are used to understand the subject of the sentence to be matched and improve the performance of the matching model.
- A KLD-based loss function is introduced to optimize the consistency of the distribution of fine-grained contextual features with the interacted sentence main idea, which improves the matching accuracy of the model.
- In this study, a concise and effective training strategy for text semantic matching was developed, which was experimentally verified to significantly improve the performance of text written in Chinese language matching tasks.
2. Related Work
3. Semantic Matching Model Design Using Refined Contextual Features and Sentence–Subject Interaction
3.1. Contextual Feature Refinement Strategies in Global Matching
3.1.1. Filter Out Noise Features
3.1.2. Obtaining Key Matching Features
3.2. Sentence–Subject-Interaction-Based Matching Strategy
3.3. Training and Reasoning Using KLD to Ensure That Contextual Matches Are Similar to the Main Idea’s Distribution
3.4. Matching Result Prediction
3.5. Training and Inference
| Algorithm 1 A Chinese text matching algorithm |
| Require: Input sequence X, labels Y, model name M, number of classes K |
| Ensure: Predicted probability distribution P, total loss L |
| 1: Component Definitions: |
| 2: ▷ Gradient Reversal Layer GRL(⋅; ) ▷ Identity forward, reverses gradients scaled by backward |
| 3: ▷ Dot-Product Attention Attn(Q,K,V,Mask). ▷ Compute |
| 4: ▷ Embedding Projection Proj(v,B) ▷ Compute |
| 5: Model Initialization: |
| 6: Load pretrained encoder Enc(⋅) ▷ e.g., DeBERTa/Funnel architecture |
| 7: Initialize concept embedding |
| 8: Build classifier Clf(⋅): |
| 9: Build adversarial classifier AdvClf(⋅): |
| 10: Set GRL hyperparameter |
| 11: procedure FORWARDPASS(X,Y) |
| 12: Generate attention mask , keyword mask |
| 13: Segment input |
| 14: Encoding Process: |
| 15: ▷ Full sequence encoding |
| 16: ▷ Keyword-focused encoding |
| 17: Domain-Invariant Feature Extraction: |
| 18: ▷ Common feature extraction |
| 19: ▷ Domain-invariant projection |
| 20: |
| 21: Adversarial Training: |
| 22: |
| 23: |
| 24: |
| 25: Multi-View Consistency: |
| 26: ▷ Keyword view projection |
| 27: |
| 28: |
| 29: |
| 30: KL-Divergence Constraint: |
| 31: |
| 32: |
| 33: |
| 34: Loss Integration: |
| 35: |
| 36: |
| 37: return |
| 38: end procedure |
| 39: Training Phase: |
| 40: Jointly optimize |
| 41: Inference Phase: Use fused probabilities |
4. Experimental Settings and Datasets
4.1. Datasets
4.2. Automatic Keyword Annotation
4.3. Parameter Settings
5. Discussion
5.1. Results of the Experiment
- (1)
- Experimental results and analysis on PAWS dataset
- (2)
- Experimental results on Ant Gold Service data
- (3)
- BQ data experiment results
- (4)
- Experimental results on the Medical dataset
5.2. Ablation Experiment
5.3. Time and Memory Complexity Analysis
5.4. Case Studies
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, L.S.; Hu, J.; Teng, F.; Li, T.R.; Du, S.D. Text Semantic Matching with an Enhanced Sample Building Method Based on Contrastive Learning. Int. J. Mach. Learn. Cybern. 2023, 14, 3105–3112. [Google Scholar] [CrossRef]
- Jin, Z.L.; Hong, Y.; Peng, R.; Yao, J.M.; Zhou, G.D. Intention-Aware Neural Networks for Question Paraphrase Identification. In Proceedings of the 45th European Conference on Information Retrieval, Dublin, Ireland, 2–6 April 2023; Volume 13980, pp. 474–488. [Google Scholar]
- Lai, P.C.; Ye, F.Y.; Fu, Y.G.; Chen, Z.W.; Wu, Y.J.; Wang, Y.L. M-Sim: Multi-Level Semantic Inference Model for Chinese Short Answer Scoring in Low-Resource Scenarios. Comput. Speech Lang. 2024, 84, 101575. [Google Scholar] [CrossRef]
- Neeman, E.; Aharoni, R.; Honovich, O.; Choshen, L.; Szpektor, I.; Abend, O. Disentqa: Disentangling Parametric and Contextual Knowledge with Counterfactual Question Answering. arXiv 2022, arXiv:2211.05655. [Google Scholar]
- Tang, X.; Luo, Y.; Xiong, D.; Yang, J.; Li, R.; Peng, D. Short Text Matching Model with Multiway Semantic Interaction Based on Multi-Granularity Semantic Embedding. Appl. Intell. 2022, 52, 15632–15642. [Google Scholar] [CrossRef]
- Lu, G.; Liu, Y.; Wang, J.; Wu, H. CNN-BiLSTM-Attention: A Multi-Label Neural Classifier for Short Texts with a Small Set of Labels. Inf. Process. Manag. 2023, 60, 103320. [Google Scholar] [CrossRef]
- Jiang, K.; Zhao, Y.; Jin, G.; Zhang, Z.; Cui, R. KETM: A Knowledge-Enhanced Text Matching Method; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Yu, C.; Xue, H.; Jiang, Y.; An, L.; Li, G. A Simple and Efficient Text Matching Model Based on Deep Interaction. Inf. Process. Manag. 2021, 58, 102738. [Google Scholar] [CrossRef]
- Li, Y. Unlocking Context Constraints of Llms: Enhancing Context Efficiency of Llms with Self-Information-Based Content Filtering. arXiv 2023, arXiv:2304.12102. [Google Scholar]
- Zhao, J.; Zhan, W.; Zhao, X.; Zhang, Q.; Gui, T.; Wei, Z.; Wang, J.; Peng, M.; Sun, M. RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction. arXiv 2023, arXiv:2306.04954. [Google Scholar]
- Zou, Y.; Liu, H.; Gui, T.; Wang, J.; Zhang, Q.; Tang, M.; Li, H.; Wang, D.; Assoc Computa, L. Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents. arXiv 2022, arXiv:2203.02898. [Google Scholar]
- Chen, Y.; Wang, S.; Liu, J.; Xu, X.; de Hoog, F.; Huang, Z. Improved Feature Distillation via Projector Ensemble. Adv. Neural Inf. Process. Syst. 2022, 35, 12084–12095. [Google Scholar]
- Snell, C.; Klein, D.; Zhong, R. Learning by Distilling Context. arXiv 2022, arXiv:2209.15189. [Google Scholar]
- Heo, B.; Kim, J.; Yun, S.; Park, H.; Kwak, N.; Choi, J.Y. A Comprehensive Overhaul of Feature Distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1921–1930. [Google Scholar]
- Wang, Z.; Hamza, W.; Florian, R. Bilateral Multi-Perspective Matching for Natural Language Sentences. arXiv 2017, arXiv:1702.03814. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Bulsari, A.B.; Saxen, H. A RECURRENT NEURAL NETWORK MODEL. In Proceedings of the 1992 International Conference (ICANN-92), Brighton, UK, 4–7 September 1992; pp. 1091–1094. [Google Scholar]
- Zhang, K.; Wu, L.; Lv, G.Y.; Wang, M.; Chen, E.H.; Ruan, S.L. Making the Relation Matters: Relation of Relation Learning Network for Sentence Semantic Matching. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 14411–14419. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yao, D.; Alghamdi, A.; Xia, Q.; Qu, X.; Duan, X.; Wang, Z.; Zheng, Y.; Huai, B.; Cheng, P.; Zhao, Z. A General and Flexible Multi-Concept Parsing Framework for Multilingual Semantic Matching. arXiv 2024, arXiv:2403.02975. [Google Scholar]
- Wang, Y.; Zhang, B.; Liu, W.; Cai, J.; Zhang, H. STMAP: A Novel Semantic Text Matching Model Augmented with Embedding Perturbations. Inf. Process. Manag. 2024, 61, 103576. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Sarath, B.; Varadarajan, K. Fundamental Theorem of Projective Geometry. Commun. Algebra 1984, 12, 937–952. [Google Scholar] [CrossRef]
- Lin, J.; Zou, J.; Ding, N. Using Adversarial Attacks to Reveal the Statistical Bias in Machine Reading Comprehension Models. arXiv 2021, arXiv:2105.11136. [Google Scholar]
- Manjunatha, V.; Saini, N.; Davis, L.S. Explicit Bias Discovery in Visual Question Answering Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9562–9571. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-Training with Whole Word Masking for Chinese Bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Huang, X.; Peng, H.; Zou, D.; Liu, Z.; Li, J.; Liu, K.; Wu, J.; Su, J.; Philip, S.Y. CoSENT: Consistent Sentence Embedding via Similarity Ranking. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 2800–2813. [Google Scholar] [CrossRef]

{kind=link}
| Dataset | Task | Train | Dev | Test | Language | Class |
|---|---|---|---|---|---|---|
| PAWS | Semantic Equivalence Identification/Paraphrase Identification | 49,401 | - | 2000 | Chinese | 2 |
| Ant Financial Services | QA | 29,998 | 3668 | 3668 | Chinese | 2 |
| BQ | QA | 100,000 | 10,000 | 10,000 | Chinese | 2 |
| Medical | Medical Consultation Query Matching | 38,406 | 4801 | 4801 | Chinese | 3 |
| Model | Accuracy |
|---|---|
| STMAP [22] | 81.2% |
| Mac-BERT [19] | 84.95% |
| RoBERta-base [20] | 87% |
| Ours (RoBERta-base) | 87.65% |
| Model | Accuracy (Ori → Ours) | F1 (Ori → Ours) |
|---|---|---|
| Mac-BERT [19] | 84.95% → 85.55% | 82.69% → 82.99% |
| RoBERta-base [20] | 87% → 87.65% | 85.31% → 86.51% |
| Model | Accuracy |
|---|---|
| Mac-BERT [19] | 79.14% |
| RoBERta-base [20] | 79.61% |
| Ours (RoBERta-base) | 80.51% |
| Model | Accuracy (Ori → Ours) |
|---|---|
| Mac-BERT [19] | 79.14% → 79.39% |
| RoBERta-base [20] | 79.61% → 80.51% |
| Model | Accuracy |
|---|---|
| SBERTbase-NLI [29] | 42.73% |
| SRoBERTbase-NLI [29] | 45.60% |
| BERTbase-CoSENT-NLI [29] | 41.84% |
| RoBERTabase-CoSENT-NLI [29] | 46.65% |
| SBERTbase(MSE) [29] | 70.74% |
| SRoBERTabase (MSE) [29] | 72.14% |
| SBERTbase(Softmax) [29] | 70.97% |
| SRoBERTabase (Softmax) [29] | 71.06% |
| BERTabase-CoSENT [29] | 71.53% |
| RoBERTabase-CoSENT [29] | 72.60% |
| Mac-BERT [19] | 85.03% |
| RoBERta-base [20] | 85.11% |
| Ours (RoBERta-base) | 85.29% |
| Model | Accuracy (Ori → Ours) |
|---|---|
| Mac-BERT [19] | 85.03% → 85.12% |
| RoBERta-base [20] | 85.11% → 85.29% |
| Model | Accuracy |
|---|---|
| Mac-BERT [19] | 73.46% |
| DC-Match (Mac-BERT) [11] | 73.83% |
| RoBERta-based [20] | 74.09% |
| DC-Match (RoBERta-bas) [11] | 73.73% |
| MCP-SM (RoBERta-base) [21] | 73.48% |
| Ours (RoBERta-base) | 74.69% |
| Model | Accuracy (Ori → Ours) | Macro-F1 (Ori → Ours) |
|---|---|---|
| Mac-BERT [19] | 73.46% → 73.90% | 72.67% → 73.14% |
| RoBERta-base [20] | 74.09% → 74.69% | 73.28% → 74% |
| Model | PAWS (acc.) | PAWS (F1) | Ant (acc.) |
|---|---|---|---|
| RoBERTa-base | 87% | 85.31% | 79.61% |
| + LJ + LGRL | 87.05% | 85.36% | 79.83% |
| + LJ + LGRL + LG | 87.55% | 85.89% | 79.88% |
| Ours (LJ + LGRL + LG + LKL) | 87.65% | 86.51% | 80.51% |
| Model | BQ (acc.) | Medical (acc.) | Medical (Macro-F1) |
|---|---|---|---|
| RoBERTa-base | 85.11% | 74.09% | 73.28% |
| + LJ + LGRL | 85% | 74.07% | 73.13% |
| + LJ + LGRL + LG | 85.16% | 74.55% | 73.80% |
| Ours (LJ + LGRL + LG + LKL) | 85.29% | 74.69% | 74% |
| Model | Complexity Type | Component/Operation | Main Influencing Factors | Calculation Formulae |
|---|---|---|---|---|
| Methodology of this paper (MacBERT-base) | time complexity | (1) MacBERTa-base encoder (2) Dot product attention (3) Projection operation (4) KL scattering loss | (1) Sequence length n, hidden layer dimension d = 768, number of layers L = 12, and two forward propagations; (2) batch size batch size b = 16/64, number of attention heads h = 12, and sequence length n = 512; (3) four projection operations (b × d2 each); (4) number of labels k = 2/3 | O(2L(n2d + nd2) + 2bhd(n2 + d)) |
| memory complexity | (1) MacBERTa-base parameters (2) Attention matrix (3) Intermediate activation values (4) Gradient storage | (1) Number of references 110M; (2) batch size b = 16/64, number of attention heads h = 12, and sequence length n = 512; (3) hidden-layer dimension d = 768, sequence length n = 512, and number of layers L = 12; (4) number of references 110M, and number of gradient accumulations 4 | O(2L(n2 + nd) + 2bhn2 + 110M) | |
| MacBERT-base | time complexity | (1) MacBERTa-base encoder (2) Classifier | (1) Sequence length n = 512, hidden-layer dimension d = 768, and number of layers L = 12; (2) batch size b = 16/64, and hidden layer dimension d = 768 | O(L(n2d + nd2) + bd) |
| memory complexity | (1) MacBERTa-base parameters (2) Attention matrix (3) Intermediate activation values (4) Optimizer state (AdamW) | (1) Number of parameters 110M; (2) batch size b = 16/64, number of attention heads h = 12, and sequence length n (3) hidden layer dimension d = 768, sequence length n = 512, and number of layers L = 12; (4) number of parameters 110M, momentum and gradient storage | O(L(n2 + nd) + 110M) | |
| DC-Match(RoBERTa-base) | time complexity | (1) Triple encoder forward computation (2) Mean pooling operation (3) Classifier computation (4) KL scatter loss computation | (1) L = 12 layers, n = 512 sequence length, d = 768 hidden dimensions; (2) batch size b = 16/64, and sequence length n = 512; (3) number of labels k = 2/3; (4) joint probability distribution dimension k × k | O(3L(n2d + nd2) + 4bn2d) |
| memory complexity | (1) Triple encoder parameters (2) Attention matrix storage (3) Intermediate activation values (4) Optimizer state (AdamW) | (1) RoBERTa-base parameter count of 125M (three independent encoders); (2) number of layers L = 12, number of attention heads h = 12, and length of sequence n = 512; (3) hidden states and pooled intermediate results of three-time encoder; (4) parameters, gradients, momentum and second-order momentum | O(3L(n2 + nd) + 375M + 3Lhn2) | |
| Methodology of this paper (RoBERTa-base) | time complexity | (1) RoBERTa encoder (2) dot product attention (3) projection operation (4) KL scatter loss | (1) L = 12 layers, n = 512 sequence length, d = 768 hidden dimensions; (2) b = 16/64 batches, h = 12 attention heads; (3) four projection operations (b×d2 each) (4) Number of labels k = 2/3 | O(2L(n2d + nd2) + bhn2d + 4bd2) |
| memory complexity | (1) RoBERTa-base parameters (2) Attention matrix (3) Intermediate activation values (4) Gradient storage | (1) Number of references 125M; (2) batch size b = 16/64, number of attention heads h = 12, and sequence length n; (3) hidden-layer dimension d = 768, sequence length n = 512, and number of layers L = 12; (4) number of references 125M, and number of gradient accumulations 4 | O(2L(n2 + nd) + 125M + 2bhn2) | |
| RoBERTa-base | time complexity | (1) RoBERT-base encoder (2) Classifier | (1) Sequence length n = 512, hidden-layer dimension d = 768, and number of layers L = 12; (2) batch size b, and hidden layer dimension d = 768 | O(L(n2d + nd2)) |
| memory complexity | (1) MacBERTa-base parameters (2) Attention matrix (3) Intermediate activation values (4) Optimizer state (AdamW) | (1) Number of parameters 125M; (2) batch size b = 16/64, number of attention heads h = 12, and sequence length n = 512; (3) hidden-layer dimension d = 768, sequence length n = 512, and number of layers L = 12; (4) number of parameters 125M, momentum and gradient storage | O(L(n2 + nd) + 125M) |
| Sentence Pair | Label | RoBERta-Base | Main Sentence Idea Interaction | Methodology in This Paper |
|---|---|---|---|---|
| S1: 超市支付宝可以使用花呗吗 S1: Supermarket paypal can use the Huabei? | 0 | 1 | 0 | 0 |
| S2: 在商场购物可以使用花呗吗 S2: Can I use the Huabei to shop at the mall? | ||||
| S1: 借呗会涨额度吗 S1: Borrowing will increase the limit? | 0 | 1 | 0 | 0 |
| S2: 我想借呗额度提升 S2: I want to increase my borrowing limit. | ||||
| S1: 借呗现在只能分六期和十二期吗 S1: Borrowing can only be divided into six and twelve instalments now? | 0 | 1 | 0 | 0 |
| S2: 蚂蚁借呗怎么只能分六期了 S2: How come I can only do six instalments? | ||||
| S1: 新注册的用户要多久才能有花呗 S1: How long does it take for a newly registered user to have a Huabei? | 0 | 1 | 0 | 0 |
| S2: 要多久能用花呗 S2: How long does it take to use the Huabei? |
| Sentence Pair | Label | RoBERta-Base | Sentence Main Idea Interaction | Our |
|---|---|---|---|---|
| S1: 在医院怎么做真菌检查 S1: How to get a fungal test at the hospital? | 2 | 1 | 2 | 2 |
| S2: 真菌检查怎么做 S2: How to do a fungal test? | ||||
| S1: 牙齿摔断会疼多久 S1: How long does a broken tooth hurt? | 0 | 1 | 0 | 0 |
| S2: 我是摔跤把牙齿摔断了现在很痛呢大 S2: I broke my tooth in a fall and it’s hurting me. | ||||
| S1: 止痛片又叫 S1: Painkillers are also called. | 1 | 0 | 1 | 1 |
| S2: 止痛片 S2: painkiller | ||||
| S1: 刘绪英主任还在宁阳妇幼保健院吗 S1: Is Director Liu Xuying still at Ningyang Maternal and Child Health Centre? | 1 | 0 | 1 | 1 |
| S2: 刘绪英大夫出诊时间 S2: Dr Liu Xueying’s consultation time |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, P.; Cai, X. Semantic Matching for Chinese Language Approach Using Refined Contextual Features and Sentence–Subject Interaction. Symmetry 2025, 17, 585. https://doi.org/10.3390/sym17040585
Jiang P, Cai X. Semantic Matching for Chinese Language Approach Using Refined Contextual Features and Sentence–Subject Interaction. Symmetry. 2025; 17(4):585. https://doi.org/10.3390/sym17040585
Chicago/Turabian StyleJiang, Peng, and Xiaodong Cai. 2025. "Semantic Matching for Chinese Language Approach Using Refined Contextual Features and Sentence–Subject Interaction" Symmetry 17, no. 4: 585. https://doi.org/10.3390/sym17040585
APA StyleJiang, P., & Cai, X. (2025). Semantic Matching for Chinese Language Approach Using Refined Contextual Features and Sentence–Subject Interaction. Symmetry, 17(4), 585. https://doi.org/10.3390/sym17040585