Abstract
Aiming at the problems of noise interference and the lack of information on sentence–subject interactions in Chinese matching models, which lead to their low accuracy, a new semantic matching method using fine-grained context features and sentence–subject interaction is designed. Compared with the method that relies on noisy data to improve the noise resistance of the model, we introduce data pollution and imprecise noise processing. We also design a novel context refinement strategy, which uses dot product attention, a gradient reversal layer, the Softmax function, and projection theorem to accurately identify and eliminate noise features to obtain high-quality refined context features, effectively overcoming the above shortcomings. Then, we innovatively use a one-way interaction strategy based on the projection theorem to map the sentence subject to the refined context feature space, which produces effective interaction ability between the features in the model. The refined context and sentence’s main idea are fused in the final prediction stage to compute the matching result. In addition, this study uses Kullback–Leibler divergence scatter to optimize the distance between the distributions of the refined context and the sentence’s main idea so that their distributions are closer to each other. The experimental results show that the accuracy of the method on the PAWS dataset and F1 are 87.65% and 86.51%, respectively; 80.51% on the Ant Financial dataset, and 85.29% on the BQ dataset. The accuracies on the Medic-SM dataset and Macro-F1 are 74.69% and 74% respectively, both of which are superior to those of other methods.
1. Introduction
Text matching [1], fundamental within the field of NLP, has the essential goal of assessing and quantifying the semantic similarity or association between two texts. The technique plays a fundamental and critical role in many advanced language understanding tasks, including, but not limited to, paraphrase recognition [2], natural language reasoning [3], and question-and-answer systems [4]. Therefore, effective text-matching models play a crucial role in NLP development.
However, due to the presence of some redundant information in natural language, the matching model inevitably faces challenges, i.e., the interference due to noise information on sentence focus and comprehension as well as the lack of interaction between the main ideas of the sentence pairs to be matched. There are three solutions commonly used to address the problem of the interference of the redundant content on the comprehension of the main sentence idea. One approach relies on attentional mechanisms to obtain the main idea’s information. It uses a two-stage approach [5,6], where the scores from different sentence tokens are first calculated using the attention mechanism, and then this score is combined to determine the similarity of the statements to be matched. Another approach is adding noise data to the data to train the model to improve its ability to resist noise and identify the main idea of the sentences to be matched. The third method is using an external knowledge base to enhance the matching model’s understanding of the main idea in a sentence and thus improve its performance [7]. One approach to address the lack of interaction between the main ideas of sentence pairs to be matched is to capture the interaction information by integrating an encoder layer, a co-attention layer, and a fusion layer as interaction modules [8]. However, most of the studies [9,10] have usually focused on annotating a selection of critical information on the main idea, while few recent studies have focused on both selecting and rejecting noisy information as well as the interactions among main idea information, which is of significant value for text-matching tasks. Therefore, we propose the idea of both selecting noisy information and considering the interactions among main idea information. In essence, acquiring and removing noisy information enable access to refined contextual features, which help the model obtain better representations. Considering the interaction between sentence themes can help the model understand the core meaning of the sentence more accurately. However, there are two problems here. One is how to effectively acquire and remove the noise information. The second is how to obtain the interaction information of the main idea.
To solve the above problems, there is a need to develop strategies that can better capture and remove noisy information as well as mechanisms that determine the interactions among main idea information. Therefore, this paper proposes a semantic matching method based on a sentence essence and context. The method is inspired by the text-matching models based on keyword and intent decomposition [11] and semantic matching methods oriented towards zero-sample relation extraction [10] in the literature. Specifically, this study first designed the contextual feature refinement strategy method [10,12,13,14] to reduce the negative impact of the noise components on the matched content. This method can obtain and propose the features of noise and thus refine the contextual features from sentences to reduce the influence of interfering factors on the final results, thus improving the accuracy of the matching.
Secondly, in order to obtain better the features of sentence-matching–main idea interactions, this study projected the main sentence features obtained by the unsupervised TextRank method into orthogonal space where finer features are obtained after the distillation layer [10,12,13,14]. This allows the central theme’s features to more accurately express the semantic relationships between sentences, further improving the accuracy and effectiveness of the matching. In the final prediction stage, this study fused the refined matching content with the main post-interaction idea and used feature enhancement to complete the final prediction. By combining the two, more accurate matching results were obtained, and the overall performance of the model wase improved.
In addition, in order to further optimize the model, in the design of the loss function, this study also considered the goal of minimizing the KLD [11] between the distribution of the refined contextual matching features and the distribution of the sentence essence. The KLD (Kullback–Leibler divergence) is a measure of the difference between two probability distributions. This enables the model to better learn the relationship between match content and the core meaning, further improving the matching performance.
Through comprehensive experimental validation on a Chinese dataset, this study demonstrated the effectiveness of the method. The experimental results showed that the method achieved significant performance improvement in various text-matching tasks. The method also has the advantages of easy combination with pre-trained language models and a small number of auxiliary training parameter combinations, which makes it more feasible and flexible in practical applications.
In summary, the core contribution points of this study are as follows:
- Adaptive refined contextual feature distillation technique: Weakly correlated features are filtered using dot product attention and a GRL (gradient reversal layer), and then projection theorem is used to reject noise and obtain refined features.
- The innovative projection of sentence subject features into a fine-grained contextual feature space enhances the interactive matching ability between the sentence subject and contextual information.
- Supervised feature distillation and post-interaction feature combinations are used to understand the subject of the sentence to be matched and improve the performance of the matching model.
- A KLD-based loss function is introduced to optimize the consistency of the distribution of fine-grained contextual features with the interacted sentence main idea, which improves the matching accuracy of the model.
- In this study, a concise and effective training strategy for text semantic matching was developed, which was experimentally verified to significantly improve the performance of text written in Chinese language matching tasks.
2. Related Work
Textual semantic matching, as a cornerstone task of NLP, plays a crucial role in applications such as paraphrase recognition [2], natural language reasoning [3], and question and answer [4]. Early research mostly relied on neural network models with specific inductive biases, such as LSTM [15], CNN [16], and RNN [17], which have achieved some results in text representation and feature extraction.
In the field of text matching, although the previous methods can express the semantic meaning of sentences, the interaction information is insufficient. To overcome this limitation, BiMPM [15] encodes sentence context semantics through bidirectional LSTM, utilizes multiple sets of similarity functions bidirectional to achieve fine-grained interactive matching at the word or phrase level, uses BiLSTM to aggregate matching features into fixed-length vectors, and finally outputs matching probabilities through the full connection layer. Its innovation lies in the combination of two-way interaction and multi-perspective mechanism. Experiments showed that its performance is better than that of traditional single-direction or single-granularity methods in the tasks of interpretation, recognition, reasoning, and answer selection, which verified the effectiveness of complex semantic modeling. However, these models still make insufficient use of the rich semantic information contained in tags. To this end, the R2-Net [18] semantic matching model combines the global representation of BERT and the local features of multi-scale CNN to enhance semantic comprehensiveness through multi-granularity semantic coding. At the same time, the model uses self-supervised relational classification tasks and contrast learning to enhance the discriminability of semantic relationships as well as realizes relational enhancement modeling by jointly optimizing multi-task loss functions. Experiments showed that R2-Net performs well in natural language reasoning and interpretive recognition tasks; its innovation lies in mining the semantic relationship patterns implied by tags, and provides a lightweight and transferable framework.
Large-scale pre-trained language models, especially those based on Transformer and multi-head attention mechanisms, have significantly improved the language semantic understanding and representation of text written in Chinese through self-supervised learning. Representative models such as Mac-BERT [19] and RoBERta-base [20] achieve a deeper understanding of the input text through powerful encoders. In text-matching tasks, these models have been fine-tuned to achieve state-of-the-art performance in several benchmark tests. Meanwhile, new matching approaches have emerged based on these pre-trained language models, such as DC-Match [11], a text-matching model based on keyword and intent decomposition; MCP-SM [21], a general and flexible multi-concept parsing framework for multilingual semantic matching; and STMAP [22], a novel semantic text-matching model incorporating embedding perturbations.
The DC-Match [11] model improves text semantic matching performance through a divide-and-conquer strategy. Its decomposes sentence content into keywords and intentions for decoupling processing as well as uses remote supervision to automatically label keywords. In the training stage, the model learns independent keyword matching and intention matching with auxiliary targets and designs KL divergence targets to align the joint distribution of the global matching distribution and the decouple subproblem to meet the matching requirements with different granularities. The method requires only a few additional training parameters and maintains efficiency consistency with the original pre-trained language model (PLM) in the inference phase. Experiments showed that DC-Match provided improved performance compared with BERT and other models on multiple benchmarks, verifying the effectiveness of its dive-and-conquer strategy. MCP-SM [21] flexibly parses text into multiple concepts for multi-language semantic matching through a framework based on pre-trained language models. This method does not rely on external named entity recognition (NER) technology to identify keywords in sentences but directly extracts various concepts from the text and integrates these conceptual information into classification tags to optimize semantic matching performance. Through experiments on English, Chinese, and Arabic datasets, MCP-SM demonstrated its applicability and superior performance in low-resource languages. The STMAP [22] model introduces Gaussian noise and noise mask signals in the embedding layer to generate diversified semantic representations while avoiding the semantic biases that may be caused by traditional data enhancement. In addition, the model uses an adaptive optimization network to dynamically adjust multiple sets of data to enhance the generated target loss weight, achieve training balance under different disturbance modes, and improve the robustness of the model. Experiments showed that the model achieved excellent performance on multiple English and Chinese datasets, especially in a small-sample scenario, which provided a new idea for small-sample semantic matching.
In this study, we reduced the interference caused by noisy information using a context-specific refinement strategy and projecting the main sentence idea’s features into a refined contextual feature space to enhance the interaction matching capability. In the prediction stage, the refined matching content and sentence main idea are fused, and the enhanced feature set is utilized for prediction. At the same time, the KLD loss function is introduced to optimize distributional consistency and enhance model-matching accuracy and robustness. These strategies and techniques provide new ways to enhance text semantic matching performance.
3. Semantic Matching Model Design Using Refined Contextual Features and Sentence–Subject Interaction
The overall architecture of the model is shown in Figure 1. In this study, dot multiplication attention, GRL, Softmax function, and projection theorem were used to find weakly correlated features in the sentence pairs to be matched; projection theorem was used to obtain noise features in the feature direction; projection theorem was used to identify and discard the noise in the hidden layer information; and then the refined context features were obtained. Among them, the GRL is a special layer used in neural networks, whose main role is to reverse the direction of the gradient during backpropagation.
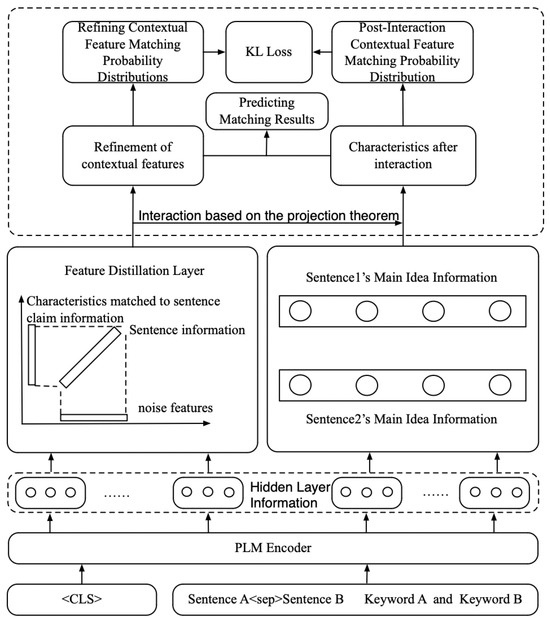
Figure 1.
Model architecture diagram.
Then, the sentence’s main idea is projected into the orthogonal space of this feature to obtain better interaction information. In the final prediction stage, the refined context and sentence subject are fused to compute the matching result. In addition, this study calculated the KLD between the refined context and sentence’s main idea distributions to make their distributions closer. The model includes four training objectives. Among them, the first objective is the classification loss of refined context features, which is used to determine the semantic relationship between sentences via distillation layers. The second objective is to optimize the loss of weakly relevant contextual features, which aims to filter out features that are weakly relevant to the sentence’s main idea. The third objective is the loss of the sentence’s main idea matching classification, which improves the model’s ability to understand the main idea in a sentence and thus more accurately determine the degree of semantic matching between sentences. The fourth objective is using KL scatter to ensure that the global matching distribution resembles the sentence’s main idea distribution, thus enhancing the performance of the matching model.
3.1. Contextual Feature Refinement Strategies in Global Matching
Firstly, this paper defines the task of textual semantic matching and describes a generic approach to this task. Given two text sequences, and , the goal of textual semantic matching is to learn a classifier for predicting whether and are semantically equivalent or not, where and denote the ith and jth words in the sequence, respectively; and la and lb denote the length of the text sequence. This classifier y can be used for binary classification goals to determine whether two sequences match or not or, for multiple classification goals, to determine different degrees of matching. Learning the classifier by training the model can improve the accuracy of the text semantic matching task results.
Recently, pre-trained language models have achieved breakthroughs in text parsing and expression learning capabilities, providing more powerful support tools for NLP tasks. For the global text-matching task, this study connected and as a continuous sequence where is the separator. This sequence was then fed into the pre-trained language model encoder [20]. The expression is shown below:
During the fine-tuning process, each sequence is preceded by a special marker . , in turn, signifies the aggregated outcome of the sequence after the final hidden layer processing. This hidden-layer-like representation contains a summary of the entire sequence. PLM denotes a pre-trained language model.
3.1.1. Filter Out Noise Features
The dot product attention mechanism has the ability to select selection to filter out specific feature attributes. This study argued that the properties of this mechanism are particularly beneficial for capturing weakly correlated features. The gradient inversion layer can generate feature representations that are inverse to the gradient of the objective function in a given scenario, a property that makes it suitable for extracting specific features. This study concluded that this unique feature helps to identify and analyze weakly correlated features. Therefore, to reduce the interference caused by noisy information on the accuracy of sentence matching, this study designed a feature aggregation mechanism [10] specifically for extracting features that are weakly relevant to the matching task. The first step in the mechanism is to feed the sentences to be matched into an encoder, thus obtaining a coded representation of the sentences, denoted as . Next, these codes are weighted and aggregated using a trainable query vector q to filter out features that are weakly relevant to the sentence-matching task. This process effectively focuses on features that do not contribute substantially to the matching result while filtering those with noisy information. The specific results are shown below:
In the aforementioned formula, denotes the aggregation of weakly relevant features for the ith sentence matching task. denotes the weight of the nth weakly relevant feature. Softmax(·) converts a set of arbitrary real numbers into real numbers representing a probability distribution, which is essentially a normalization function.
Then, this study employed GRL [23] to identify those features that were weakly relevant to the matching task from the semantic representation of the sentence. The role of GRL is to guide the optimization process of the query vector q to locate and emphasize those features that are weakly relevant to the matching result more accurately. Its expression is shown below:
where W and b represent the weight and bias of the relational classifier, respectively. After being processed by the GRL layer, is fed into the classifier for prediction. yi denotes the ith sentence pair to be matched with the true labels. is the ith gradient inversion loss, which is used to optimize the training process of query q. The classifier can be optimized by minimizing these losses. By minimizing these losses, the model can better learn the features that are weakly correlated with the matching relation and improve the performance on the sentence-matching task.
Projection theorem is often applied of dimensionality reduction processing due to its ability to decompose features. This paper argues that this property helps to separate noisy features from sentence semantic information. Therefore, to reduce the detrimental effect of noisy information on sentence matching accuracy, a feature distillation layer was designed in this study [10]. The core role of this layer is to map the final hidden layer aggregation representation of the sentence to the orthogonal complementary space of the weakly correlated feature vectors with the matching task. The operation steps are summarized as follows: First, the final hidden layer aggregation representation vector of the sentence is projected to the space defined by as a way of identifying and separating those with noise feature components. Through this processing, the model can more clearly identify the features that are substantially helpful for sentence matching and, at the same time, effectively suppress those noise features that may cause errors, thus optimizing the matching effect. The expression is shown below:
In the feature distillation layer, the method uses the projection operator Proj(·,·) for the input vectors a and b. Specifically, the final hidden layer aggregation representation is computed by projecting the final hidden layer aggregation representation with the matching weakly correlated features under the projection operator. , which denotes the noise feature. |b| denotes the modulus of vector b.
3.1.2. Obtaining Key Matching Features
By implementing the projection transformation, this method successfully excludes the noise feature and thus obtains a more refined representation of the final hidden layer aggregation sequence of the sentence to be matched, . The use of this technique significantly reduces the potential interference caused by noisy information on the matching accuracy and, at the same time, enhances the performance of the model on performing the sentence-matching task. The expression is shown as follows:
Finally, this method introduces a standard classification loss for fine-tuning for training, which is calculated as shown below:
In this paper, and indicate a more accurate representation of the final hidden-layer-aggregated sequence of sentences a and b to be matched. For model training, is introduced as a classification loss function for refining the contextual features. This loss function is used to measure the performance of the model on the sentence-matching task and to optimize the model parameters by minimizing the error.
3.2. Sentence–Subject-Interaction-Based Matching Strategy
This study, inspired by the text-matching model based on keyword and intent decomposition [10], introduced a task-specific assumption for text semantic matching. This assumption is that each sentence can extract several keywords and use them as the main idea of the sentence. These keywords extracted from the sentence contain the main meaning of the sentence. This main idea information is fed into the pre-trained model with the following formula:
where denotes the sequence of the main idea of the sentence pair to be matched. is a special token of the sequence of the main idea of the sentence pair to be matched. denotes the state of the hidden layer of the main idea of the sentence pair to be matched. denotes the representation of the aggregated sequence of the final hidden layer states of the main idea of the sentence pair to be matched.
To improve the correlation between the sentence’s main idea features and the matching features, this method employs a projection technique [24] to map the main idea features from the initial space to the orthogonal space of the finer features obtained after distillation-layer processing. This can effectively better extract the matching features of the sentence’s main idea’s interactions. The expression is shown below:
where denotes the aggregated sequence representation of the final hidden-layer state of the ith sentence to be matched against the main idea. denotes the better sentence matching of the main idea’s feature. Proj(·,·) denotes the projection operator. Trainable weights are , where K denotes the number of labels, and H denotes the hidden layer size.
In order to further improve the performance of the model on the semantic text-matching task, this study defined a loss function for main idea classification. By minimizing this loss function, this study expected the model to better understand the semantic relationships between sentences and accurately determine their semantic relationships. The model was trained to enhance its performance in text semantic matching. Its expression is shown below:
where and denote the trainable weight matrix. denotes the sentence’s main idea’s classification loss. y denotes the label. and denote the sentence main idea’s interaction among the matching features of sentences a and b to be matched, respectively.
3.3. Training and Reasoning Using KLD to Ensure That Contextual Matches Are Similar to the Main Idea’s Distribution
The symmetry of this study is mainly reflected in the use of a bidirectional KLD to measure two probability distributions. KLD is used to measure the distance between two distributions, and its properties help to make the distributions between contextual distillation matching and the matching of the main sentence idea more similar. Therefore, in order to ensure that these two distributions of a sentence are similar, this study introduced a bidirectional KLD [11] to measure the distance between them. Specifically, this study compared two conditional probability distributions, and . By minimizing the bi-directional KLD, it is possible to minimize the distance between the contextually distilled matching of the sentence and the main idea matching of the sentence after the interaction. The expression is as follows:
where denotes the KL loss function. In this way, this study expected the effective contextual matching distribution to be closer to the main sentence idea’s matching distribution. is the KLD function measuring the closeness of the two distributions. denotes the distilled sentence matching distribution by context. denotes the sentence’s main idea’s matching distribution.
3.4. Matching Result Prediction
Generic models may have some problems in performing the matching task, such as giving high matching scores conditionally only to the matched keywords and ignoring the effect of context. This situation may be due to the fact that the model tends to learn the statistical biases in the training data [25,26]. To address this issue, this study adopts an approach that fuses contextual features and main idea features to compute the final match results. By fusing a sentence’s context features with the main idea features, this method considers the semantic relationships between sentences more comprehensively and does not rely only on keywords. This approach enables the model to more accurately determine whether the sentences are semantically similar as a whole, which improves the performance and robustness of the model in the matching task. By taking contextual and main idea features into account, this method can obtain more reliable and accurate matching results. The expression is as follows:
where denotes the predicted label. The true label y denotes the semantic relation between the input sentence pairs. For a three-classified sentence matching relation, Y = {no match, partial match, complete match}. For a bi-categorical sentence matching relation, Y = {mismatch, perfect match}. In order to enhance features, this method fuses sentence context features with main idea features, i.e., .
3.5. Training and Inference
In the training phase, four loss functions (, , , and ) were used in this study to jointly train the model. The purpose of these loss functions was to optimize the performance of the model through different perspectives. is a classification loss function for refining contextual features, which is used to determine the semantic relationship between sentences through the distillation layer. is optimized for the loss of weakly relevant features and is designed to filter out features that are weakly relevant to the main idea in the sentence. is a loss for classifying the matching of the main idea of the sentence, which can improve the model’s comprehension and thus more accurately determine the degree of semantic matching between sentences. is the use of KL scatter to ensure that the global matching distribution is similar to the main sentence idea’s distribution, thus enhancing the performance of the matching model. By jointly optimizing these four loss functions, this study aimed to improve the performance of the model in the matching task and provide more accurate and reliable matching results. The expressions are as follows:
where L denotes the total loss. denotes the classification loss function for refined contextual features. denotes the gradient reversal loss. is the main sentence idea’s matching loss. denotes the KL loss.
In the inference stage, using the keywords extracted by the unsupervised text rank method as the main idea of the sentence, the model obtains the main idea information in the sentence. Then, based on the features distilled by contextual features and the conditional probability of the sentence’s main idea, this method can directly infer the matching category of sentence pairs. With the above training and inference strategies, this study aimed to improve the performance of the model in the matching task and obtain more accurate and reliable matching results.
The pseudo-code strictly corresponds to the mathematical model in the text, and the PyTorch 2.0.1 implementation and completely reproduces the gradient inversion layer, attention mechanism, projection theorem, encoder structure, GRL, and loss function in the training stage. Overleaf software (TeX Live 2024) was used to compile the pseudo-code.
| Algorithm 1 A Chinese text matching algorithm |
| Require: Input sequence X, labels Y, model name M, number of classes K |
| Ensure: Predicted probability distribution P, total loss L |
| 1: Component Definitions: |
| 2: ▷ Gradient Reversal Layer GRL(⋅; ) ▷ Identity forward, reverses gradients scaled by backward |
| 3: ▷ Dot-Product Attention Attn(Q,K,V,Mask). ▷ Compute |
| 4: ▷ Embedding Projection Proj(v,B) ▷ Compute |
| 5: Model Initialization: |
| 6: Load pretrained encoder Enc(⋅) ▷ e.g., DeBERTa/Funnel architecture |
| 7: Initialize concept embedding |
| 8: Build classifier Clf(⋅): |
| 9: Build adversarial classifier AdvClf(⋅): |
| 10: Set GRL hyperparameter |
| 11: procedure FORWARDPASS(X,Y) |
| 12: Generate attention mask , keyword mask |
| 13: Segment input |
| 14: Encoding Process: |
| 15: ▷ Full sequence encoding |
| 16: ▷ Keyword-focused encoding |
| 17: Domain-Invariant Feature Extraction: |
| 18: ▷ Common feature extraction |
| 19: ▷ Domain-invariant projection |
| 20: |
| 21: Adversarial Training: |
| 22: |
| 23: |
| 24: |
| 25: Multi-View Consistency: |
| 26: ▷ Keyword view projection |
| 27: |
| 28: |
| 29: |
| 30: KL-Divergence Constraint: |
| 31: |
| 32: |
| 33: |
| 34: Loss Integration: |
| 35: |
| 36: |
| 37: return |
| 38: end procedure |
| 39: Training Phase: |
| 40: Jointly optimize |
| 41: Inference Phase: Use fused probabilities |
4. Experimental Settings and Datasets
4.1. Datasets
Experiments were carried out on four Chinese data sets. These data sets include PAWS, Anthem, Bank Question Corpus (BQ), and Medical-SM [11], as shown in Table 1.

Table 1.
Experimental dataset statistics.
This study evaluated this method and other reference models using four texts written in Chinese as language semantic matching benchmarks. These datasets included PAWS, Anthem, BQ, and Medical-SM [11]. The PAWS dataset focuses on the text-matching task, aiming at determining semantic equivalence between sentences or identifying paraphrase relations. It covers 51,401 sentence pairs, each of which is explicitly categorized as either an exact match or a mismatch. The data are provided by Anthem, and some of the data from this dataset were extracted in this study. The dataset consists of 37,334 Q&A pairs, each of which can be categorized as either an exact match or a mismatch. The BQ dataset is derived from online banking customer service logs and contains up to 120,000 sample question pairs. Medical-SM consists of 48,008 query pairs in the field of medical advice. Each query pair can be categorized as an exact match, partial match, or no match. In the table, the “-” symbol indicates that the corresponding dataset was not available. The reason for this is that when we downloaded the PAWS dataset from the Hugging Face platform, we found that its test set did not contain real labels. Therefore, the validation set of PAWS was considered a test set. By evaluating these benchmark datasets, it was possible to comprehensively assess the performance of the method in this paper for different languages and domains and to compare it with other reference models.
4.2. Automatic Keyword Annotation
To achieve the goal of main sentence idea matching, this study drew on the idea of a text-matching model based on keyword and intent decomposition [11]. Sentence subject matter refers to the set of keywords or phrases determined after the weight evaluation and ranking of the words in the sentence by the TextRank algorithm. This is a set of words or phrases that summarizes and highly focuses on the core content or key points of the sentence. In this study, the TextRank algorithm was used to extract keywords as the main idea in a sentence from the PAWS, Anthem, BQ, and Medical-SM datasets. Previous studies have shown that sentence pairs with a high degree of matching usually contain keywords with a higher degree of relevance [11]. By extracting keywords and composing them into the main sentence ideas, the semantic relationships between sentences can be better captured. This approach allows the model to focus on important information and more accurately determine whether semantic equivalence exists between sentence pairs. By considering the importance of sentence subject matter in the matching task, this was expected to improve the performance of the model on different datasets and optimize the prediction result.
4.3. Parameter Settings
For fair comparison, this study fine-tuned each pre-trained model of the original version and its paper model using the same hyperparameters. This paper systematically explains the basis of setting the key hyperparameters to ensure the accuracy and reproducibility of this study. The AdamW [27] optimizer was used, and we set β1 = 0.9 and β2 = 0.999. This combination effectively decouples weight decay from gradient updates, avoids overfitting, and is widely used for fine-tuning pre-trained models. The weight decay rate was set to 0.01 to maintain consistent parameter settings among the comparison models to ensure the fairness of the experiment. The learning rate was selected as 2 × 10−5, which is within the typical range used for pre-trained model fine-tuning, which can avoid destroying the semantic knowledge in pre-trained weights and ensure the stability of the fine-tuning process. Batch sizes were adjusted for different datasets and comparison models to maintain consistency in the experimental conditions. PAWS, Medic-SM, and Ant Gold datasets used a batch size of 64. The batch size of the BQ dataset was set to 16. Finally, for PAWS, Ant Financial, BQ, and Medical-SM data, this study set a fine-tuning process of 50,000 steps and evaluated the model every 2000 steps to monitor its performance changes using the Chinese checkpoints published in previous studies [28]. The selection of these parameter settings was based on the need for extensive validation and practical applications to ensure the validity and reliability of this method.
The experiment was carried out based on a high-performance computing platform with hardware configuration including a NVIDIA TITAN RTX graphics card (24GB graphics memory, CUDA 10.1.243 architecture acceleration), 11th-generation Intel® Core™ i7-11700 processor (8 cores, 16 threads, 2.50 GHz), 125.7 GiB DDR4 memory, and 1 TB NVMe SSD (read/write bandwidth 3500 MB/s), running on the Ubuntu 18.04.6 LTS operating system (64-bit kernel 5.4.0-150-generic). The software environment was the PyTorch 2.0.1 deep learning framework, integrating HuggingFace Transformers 4.36.2 and the Datasets 2.0.0 toolkits, and the programming language was Python 3.9.7. All experiments were accelerated by CUDA to achieve efficient parallel computation.
5. Discussion
5.1. Results of the Experiment
- (1)
- Experimental results and analysis on PAWS dataset
Evaluation of the binary classification PAWS dataset showed that the method proposed in this study achieved performance improvements of 6.45%, 2.7%, and 0.65% compared to STMAP [22], Mac-BERT [19], and RoBERta-base [20], respectively, as shown in Table 2. This was mainly due to the efficacy of information extraction by the contextual refinement strategy, the projection of the main sentence idea’s features to the fine contextual feature space to enhance the interaction matching capability, the combination of supervised feature distillation and interaction features to enhance the understanding of the main sentence idea and the matching model performance, as well as the optimization of the consistency of the feature distribution by the KLD-based loss function, which together led to a significant enhancement in model performance.
Table 2.
Accuracy experiment results for PAWS text-matching dataset.
In addition to accuracy, this study further evaluated the model performance using F1, as shown in Table 3. In terms of accuracy, this paper’s method achieved a performance improvement of 0.6% and 0.65% compared to Mac-BERT [19] and RoBERta-base [20], respectively. In terms of F1 value, the proposed method had an increased value of 0.3% and 1.2% compared with Mac-BERT [19] and RoBERta-base [20]. This indicated that this study successfully achieved model performance improvement on the binary PAWS dataset through a series of innovative strategies, including contextual refinement, one-way interaction of features, and KLD-based loss function optimization.
Table 3.
Experimental results of accuracy and F1 metrics for pre-trained models on the PAWS dataset and application of this paper’s approach.
- (2)
- Experimental results on Ant Gold Service data
To comprehensively evaluate the model’s performance, this study conducted experiments on the Chinese binary classification Ant Gold Service dataset, using the accuracy rate as the main evaluation index. The experimental results showed that compared with Mac-BERT [19] and RoBERta-base [20], the method proposed in this study improved the accuracy by 1.37% and 0.9%, respectively, as shown in Table 4, indicating that the method is significantly effective on the Chinese binary classification financial Q&A task.
Table 4.
Accuracy experimental results on Ant Gold Service dataset.
To verify the broad applicability of this paper’s method, this study applied it to two different pre-trained language models and evaluated its performance on the Chinese binary classification Anthem dataset. As shown in Table 5, compared with Mac-BERT [19] and RoBERta-base [20], the accuracy of this paper’s method was higher by 0.25% and 0.9%, respectively. These results indicate that this paper’s method is applicable and effectiveness under both pre-trained language models, showing its potential for wide application in Chinese binary financial question-and-answer tasks.
Table 5.
Experimental results of accuracy and F1 metrics of the pre-trained model and application of this paper’s method on the Anthem dataset.
- (3)
- BQ data experiment results
In order to comprehensively evaluate the model’s efficacy, this study implemented experiments for the Chinese dichotomous BQ dataset, using accuracy as the core evaluation index. The experimental results are shown in Table 6. Compared with SRoBERTbase-NLI [29], RoBERTabase-CoSENT-NLI [29], SRoBERTabase (MSE) [29], SRoBERTabase (Softmax) [29], and RoBERTabase-CoSENT [29], the method in this paper achieved accuracy improvements of 39.69%, 38.64%, 13.15%, 14.23%, and 12.69%, respectively. Compared with the SBERTbase family of models (covering SBERTbase-NLI [29], SBERTbase (MSE) [29], SBERTbase (softmax) [29], BERTbase-CoSENT-NLI [29], and BERTabase-CoSENT [29]), the method in this paper also demonstrated significant advantages with accuracy improvements of 42.56%, 14.55%, 14.32%, 43.45%, and 13.76%, respectively. In addition, compared with Mac-BERT [19] and RoBERta-base [20], the method in this paper showed slight increase sin accuracy of 0.26% and 0.18%, respectively. These results indicate that the method in this paper has outstanding effectiveness on the task of Chinese binary classification financial problems.
Table 6.
Accuracy experimental results on BQ dataset.
To verify the generality of this paper’s method, we applied it to two different pre-trained language models and evaluated its performance on the Chinese binary classification BQ dataset. As shown in Table 7, compared with Mac-BERT [19] and RoBERta-base [20], this paper’s method was improved in accuracy by 0.09% and 0.18%, respectively. These results show that this paper’s method exhibits good applicability and effectiveness in the context of these two different pre-trained language models, which predicts its promise for applications on the task of Chinese binary classification for financial problems.
Table 7.
Experimental results of accuracy and F1 metrics of pre-trained models and application of this paper’s method on BQ dataset.
- (4)
- Experimental results on the Medical dataset
To comprehensively evaluate the performance of the model on multi-classification problem, this study conducted experiments on the Chinese three-classified Medical text-matching dataset, and the accuracy rate was chosen as the main evaluation index. As shown in Table 8, compared with Mac-BERT [19], DC-Match (Mac-BERT) [11], RoBERta-base [20], DC-Match (RoBERta-base) [11], and MCP-SM (RoBERta-base) [21], the proposed method in this paper achieved improvements in accuracy by 1.23%, 0.86%, 0.6%, 0.96%, and 1.21%, respectively. This result shows that the method in this paper demonstrates significant effectiveness on the Chinese three-classification dataset.
Table 8.
Accuracy experimental results on Medical text-matching dataset.
To verify the broad applicability of this paper’s method, this study applied it to a variety of pre-trained language models and evaluated its performance on the Chinese triple-classified Medical text matching dataset. As shown in Table 9, compared with Mac-BERT [19] and RoBERta-base [20], this paper’s method achieved 0.44% and 0.6% higher accuracy and 0.47% and 0.72% higher Macro-F1 metrics, respectively. These enhancements demonstrate the applicability and effectiveness of this paper’s method in the context of different pre-trained language models, thus enhancing its potential for wide application in Chinese triple classification tasks.
Table 9.
Experimental results of accuracy and Macro-F1 metrics for pre-trained models and application of this paper’s method on Medical dataset.
5.2. Ablation Experiment
To verify the effectiveness of each component of the proposed method, an ablation experiment was conducted in this study, and the results are shown in Table 10 and Table 11. The experimental results show that the performance of the model based on the pre-trained model and the introduction of refined context features and gradient reversal loss is not significantly different from that of the original pre-trained model RoBERta-base on each dataset. Then, by adding the supervision loss of sentence subject matter, compared with the classification loss function and gradient inversion loss of the refined context features, the accuracy of the model was improved. Then, by adding the supervision loss of the sentence’s subject matter, compared with the classification loss function and gradient inversion loss of the refined context features, the accuracy of the model was improved. Specifically, compared with the method that introduced the classification loss function and gradient reversal loss of the refined context features, the method with the supervisory loss of the sentence’s subject matter increased the accuracy on the PAWS dataset by 0.5%, on the Ant Financial dataset by 0.05%, and the F1 value on the PAWS data set by 0.53%. The accuracy was increased by 0.16% on BQ and 0.48% on the Medical datasets, and the value of the Macro-F1 on the Medical dataset was increased by 0.67%. The results show that the sentence–subject interaction method can effectively enhance the model’s ability to understand the key information and thus improve the performance of the matching model.
Table 10.
Experimental results of PAWS and Ant Financial Services ablation on Chinese dataset.
Table 11.
Chinese BQ and Medical dataset ablation experiment results.
Finally, the final method in this paper utilizes the LJ, LGRL, LG, and LKL loss functions. Specifically, based on the above (LJ, LGRL, and LG), the further introduction of the LKL method increased the accuracy on the PAWS dataset by 0.1% and on the Ant Financial dataset by 0.63% compared with the method of adding sentence subject matter supervision loss LG in the previous step. The F1 value on the PAWS dataset also increased by 0.62%, the accuracy on the BQ dataset increased by 0.13%, the accuracy on the Medical dataset increased by 0.14%, and the Macro-F1 value on the Medical dataset increased by 0.2%. This result shows that the introduction of KLD effectively promotes the convergence between the context-matching distribution and the sentence’s subject matter matching distribution after the interaction, thus further enhancing the performance of the model.
5.3. Time and Memory Complexity Analysis
In this study, we analyzed the time and memory complexity of this paper’s method based on MacBERT-base, original MacBERT-base, this paper’s method based on RoBERT-base, original RoBERT-base, and DC-Match (RoBERTa-base, as shown in Table 12.
Table 12.
Time and memory complexity analysis.
The MacBERT-base-based method in this paper presents a significant performance trade-off with the original MacBERT-base in terms of time and memory complexity due to differences in structural design. In terms of time complexity, the core part of this paper’s method is two forward propagations of the encoder (2L(n2d + nd2)), whereas the original version retains the lightness of the base architecture with only a single forward computation (L(n2d + nd2)); furthermore, the addition of the 2bhd(n2 + d) term in this paper highlights the use of the dot product attention and projection theorems, whereas the original model only retains the bd magnitude of the classifier computation. The difference in memory complexity is even more significant: the additional 2L(nd) and 2bhn2 terms introduced i this paper’s approach reflect the double -caching requirement for intermediate activation values and attention matrices, whereas the original model only needs to store a single layer of activation and optimizer states (AdamW’s momentum and gradient). Although both share 110M base parameters, the approach in this paper improves model representation through the design of the attention mechanism, projection theorem, and computational paths for KL dispersion, at the cost of exponentially increasing time and memory overheads, while the original model achieves more efficient resource use by streamlining computational flows. This discrepancy essentially reflects the trade-off between representation capability and computational efficiency in model design, with the former favoring complex computation in exchange for performance enhancement and the latter maintaining utility through structural compression.
This paper’s method based on RoBERT-base shows significant differences from the original RoBERT-base at the complexity level, reflecting the trade-off between model architecture design and computational efficiency. In terms of time complexity, the core term 2L(n2d + nd2) in this paper’s method indicates that its encoder needs to perform two forward propagations, which increases the computational effort compared to the single forward (L(n2d + nd2)) of the original model; the additional bhn2d term corresponds to the extended design of the dot product attention, and the 4bd2 term reveals the four projection operations, which further amplifies the computational scale. In contrast, the original model retains only the base encoder and classifier without introducing such complex operations. In terms of memory consumption, the method in this paper significantly boosts the memory footprint by storing intermediate activation values with 2L(n2 + nd) and caching the attention matrix with 2bhn2, while the original model only needs to maintain a single layer of activation with the base optimizer state (momentum and gradient of AdamW). Although both share the 125 M parameter size, this paper’s approach trades an exponentially increasing consumption of spatial and temporal resources for improved model representation capabilities by enhancing the attention mechanism and increasing the complexity of the projection paths and loss functions, while the original model maintains the efficiency-first design philosophy by streamlining the computational flow.
The RoBERT-base-based approach in this paper and DC-Match (RoBERTa-base) exhibit very different architectural design strategies at the time and memory complexity levels. In terms of time complexity, DC-Match’s core term 3L(n2d + nd2) indicates that the encoding phase is 1.5 times more computationally intensive than that of this paper’s method (2L(n2d + nd2)) due to the use of triple-encoder-independent forward computation, whereas the additionally introduced 4bn2d term is further amplified by pooling as compared to the bhn2d in this paper’s method, even though both of them are related to the square term of the sequence length, n2. This amplifies the computational effort, while the latter spreads the computational pressure through the parallelization of the attention head (h = 12). The difference in memory consumption is even more significant: the triple encoder parameters of DC-Match (375 M) directly inflate the number of base parameters to triple that of this paper’s method (125 M), and the intermediate activation storage of 3L(n2 + nd) together with the attention matrix cache of 3Lhn2 constitute a memory bottleneck, whereas this paper’s method, with the strategy of using single-encoder parameter sharing and 2L(n2 + nd) activation storage, retains the dual forward propagation capability while retaining the dual forward propagation capability of DC-Match, which compresses the memory footprint while preserving the dual forward propagation capability (e.g., bidirectional gradient computation with KL scatter loss). The method in this paper also achieves more compact spatiotemporal efficiency by optimizing the attention mechanism (e.g., projection operation compression) and gradient accumulation strategy (four accumulations correspond to gradient storage optimization), while maintaining the underlying expressive power.
5.4. Case Studies
The core intention of the case presentation is to intuitively reflect the practical application effect of the method proposed in this paper. With the help of the established theoretical model and the control, through experiments carried out on two datasets, Ant Financial and Medical-SM, we verified that the proposed method showed better performance than the RoBERTa-base model. In addition, we further demonstrated the effectiveness of the subject interaction strategy and KLD in ablation experiments. It should be emphasized that these cases were only used as auxiliary means to visually illustrate the characteristics of the method presented in this paper rather than to directly prove the validity of the method, which was fully verified i the aforementioned experiments.
Table 13 presents the results of four sets of test cases based on the RoBERTa-base model on the Ant Financial dataset. Specifically, among the four sentence pairs, the results obtained with the method proposed in this paper and the sentence–subject interaction strategy were all 0, indicating that they were not similar to the real labels. However, when relying solely on the RoBERTa-base model for prediction, the resulting label was one, indicating dissimilarity. These cases fully demonstrate the advantages of the proposed method and sentence–subject interaction strategy in forecasting accuracy.
Table 13.
RoBERta-base model test cases on Anthem dataset.
Table 14 shows the results of four groups of test cases based on the RoBERTa-base model in the Medical-SM dataset. Specifically: In the first set of sentence pairs, the results obtained by the method proposed in this paper and the sentence subject interaction strategy are both 2 and real labels, indicating high similarity. However, when relying solely on the RoBERTa-base model for prediction, the resulting label is 1, which is contrary to the real situation. Similarly, in the second set of sentence pairs, the interaction between the method and the sentence topic agreed with the real label as 0, indicating dissimilarity, while RoBERTa-base gave the opposite prediction (labeled as 1). In the third and fourth sentence pairs, the interaction between our method and the sentence subject matter is again consistent with the true label (both 1), and RoBERTa-base’s prediction is again wrong (label 0). These cases fully demonstrate the advantages of the proposed method and sentence-subject interaction strategy in forecasting accuracy.
Table 14.
RoBERta-base model in Chinese dataset Medical-SM test cases.
6. Conclusions
This paper proposes a new Chinese semantic matching method, which obtains key features through a context-refining strategy, uses a one-way interaction strategy to improve the model’s interaction ability, fuses features to calculate the matching results, and uses KLD to optimize the distribution to improve the performance on Chinese text matching. Experiments on four Chinese datasets and ablation experiments validated the validity of these contribution points. Future research will focus on technology improvement and application expansion. At the technical level, in view of the high complexity of dot multiplication attention in processing long text, we will optimize the sparse attention mechanism in long text scenes as well as balance the computational efficiency and feature capture ability by constructing a multi-modal dynamic fusion mechanism and hierarchical adaptive compression strategy. At the application level, aiming at the bottleneck of professional knowledge sparsity in the application of intelligent question-answering systems in the vertical field, we will breakthrough the knowledge enhancement problem of intelligent question-answering systems in the vertical field, develop dynamic knowledge association technology and context-aware reordering mechanisms, and improve the interpretation and reliability of professional question-answering systems. These studies will promote the innovative application of attention mechanism and knowledge enhancement technology as well as provide core support for professional intelligent question-answering systems.
Author Contributions
Conceptualization, P.J. and X.C.; methodology, P.J. investigation, P.J.; resources, X.C.; data curation, P.J.; writing—original draft preparation, P.J.; writing—review and editing, P.J.; visualization, X.C.; supervision, X.C.; project administration, X.C.; funding acquisition, X.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Intelligent Integrated Media Platform R&D and Application Demonstration Project (PM21014X).
Data Availability Statement
The URL for the BQ dataset is https://aistudio.baidu.com/aistudio/competition/detail/45/0/datasets (accessed on 25 December 2024). The URL for the PAWS dataset is https://huggingface.co/datasets/google-research-datasets/paws-x/tree/main/zh (accessed on 25 December 2024). The URL for the Anthem dataset is https://tianchi.aliyun.com/dataset/106411 (accessed on 25 December 2024). The URL for the Medical-SM dataset is https://drive.google.com/file/d/1OugsTLxqdoxAWaC93hn8xAoiMzjdxjXg/view (accessed on 25 December 2024).
Acknowledgments
We would like to thank the above funders for their technical and financial support.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wu, L.S.; Hu, J.; Teng, F.; Li, T.R.; Du, S.D. Text Semantic Matching with an Enhanced Sample Building Method Based on Contrastive Learning. Int. J. Mach. Learn. Cybern. 2023, 14, 3105–3112. [Google Scholar] [CrossRef]
- Jin, Z.L.; Hong, Y.; Peng, R.; Yao, J.M.; Zhou, G.D. Intention-Aware Neural Networks for Question Paraphrase Identification. In Proceedings of the 45th European Conference on Information Retrieval, Dublin, Ireland, 2–6 April 2023; Volume 13980, pp. 474–488. [Google Scholar]
- Lai, P.C.; Ye, F.Y.; Fu, Y.G.; Chen, Z.W.; Wu, Y.J.; Wang, Y.L. M-Sim: Multi-Level Semantic Inference Model for Chinese Short Answer Scoring in Low-Resource Scenarios. Comput. Speech Lang. 2024, 84, 101575. [Google Scholar] [CrossRef]
- Neeman, E.; Aharoni, R.; Honovich, O.; Choshen, L.; Szpektor, I.; Abend, O. Disentqa: Disentangling Parametric and Contextual Knowledge with Counterfactual Question Answering. arXiv 2022, arXiv:2211.05655. [Google Scholar]
- Tang, X.; Luo, Y.; Xiong, D.; Yang, J.; Li, R.; Peng, D. Short Text Matching Model with Multiway Semantic Interaction Based on Multi-Granularity Semantic Embedding. Appl. Intell. 2022, 52, 15632–15642. [Google Scholar] [CrossRef]
- Lu, G.; Liu, Y.; Wang, J.; Wu, H. CNN-BiLSTM-Attention: A Multi-Label Neural Classifier for Short Texts with a Small Set of Labels. Inf. Process. Manag. 2023, 60, 103320. [Google Scholar] [CrossRef]
- Jiang, K.; Zhao, Y.; Jin, G.; Zhang, Z.; Cui, R. KETM: A Knowledge-Enhanced Text Matching Method; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Yu, C.; Xue, H.; Jiang, Y.; An, L.; Li, G. A Simple and Efficient Text Matching Model Based on Deep Interaction. Inf. Process. Manag. 2021, 58, 102738. [Google Scholar] [CrossRef]
- Li, Y. Unlocking Context Constraints of Llms: Enhancing Context Efficiency of Llms with Self-Information-Based Content Filtering. arXiv 2023, arXiv:2304.12102. [Google Scholar]
- Zhao, J.; Zhan, W.; Zhao, X.; Zhang, Q.; Gui, T.; Wei, Z.; Wang, J.; Peng, M.; Sun, M. RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction. arXiv 2023, arXiv:2306.04954. [Google Scholar]
- Zou, Y.; Liu, H.; Gui, T.; Wang, J.; Zhang, Q.; Tang, M.; Li, H.; Wang, D.; Assoc Computa, L. Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents. arXiv 2022, arXiv:2203.02898. [Google Scholar]
- Chen, Y.; Wang, S.; Liu, J.; Xu, X.; de Hoog, F.; Huang, Z. Improved Feature Distillation via Projector Ensemble. Adv. Neural Inf. Process. Syst. 2022, 35, 12084–12095. [Google Scholar]
- Snell, C.; Klein, D.; Zhong, R. Learning by Distilling Context. arXiv 2022, arXiv:2209.15189. [Google Scholar]
- Heo, B.; Kim, J.; Yun, S.; Park, H.; Kwak, N.; Choi, J.Y. A Comprehensive Overhaul of Feature Distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1921–1930. [Google Scholar]
- Wang, Z.; Hamza, W.; Florian, R. Bilateral Multi-Perspective Matching for Natural Language Sentences. arXiv 2017, arXiv:1702.03814. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Bulsari, A.B.; Saxen, H. A RECURRENT NEURAL NETWORK MODEL. In Proceedings of the 1992 International Conference (ICANN-92), Brighton, UK, 4–7 September 1992; pp. 1091–1094. [Google Scholar]
- Zhang, K.; Wu, L.; Lv, G.Y.; Wang, M.; Chen, E.H.; Ruan, S.L. Making the Relation Matters: Relation of Relation Learning Network for Sentence Semantic Matching. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 14411–14419. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yao, D.; Alghamdi, A.; Xia, Q.; Qu, X.; Duan, X.; Wang, Z.; Zheng, Y.; Huai, B.; Cheng, P.; Zhao, Z. A General and Flexible Multi-Concept Parsing Framework for Multilingual Semantic Matching. arXiv 2024, arXiv:2403.02975. [Google Scholar]
- Wang, Y.; Zhang, B.; Liu, W.; Cai, J.; Zhang, H. STMAP: A Novel Semantic Text Matching Model Augmented with Embedding Perturbations. Inf. Process. Manag. 2024, 61, 103576. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Sarath, B.; Varadarajan, K. Fundamental Theorem of Projective Geometry. Commun. Algebra 1984, 12, 937–952. [Google Scholar] [CrossRef]
- Lin, J.; Zou, J.; Ding, N. Using Adversarial Attacks to Reveal the Statistical Bias in Machine Reading Comprehension Models. arXiv 2021, arXiv:2105.11136. [Google Scholar]
- Manjunatha, V.; Saini, N.; Davis, L.S. Explicit Bias Discovery in Visual Question Answering Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9562–9571. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-Training with Whole Word Masking for Chinese Bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Huang, X.; Peng, H.; Zou, D.; Liu, Z.; Li, J.; Liu, K.; Wu, J.; Su, J.; Philip, S.Y. CoSENT: Consistent Sentence Embedding via Similarity Ranking. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 2800–2813. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).