2. Applications
We start with the typical partial differential equation used in mathematical finance.
where
X(
t) is the value of the financial quantity at time
t,
X(0) is the initial value of
X at time 0,
μ and
σ are constants representing the drift and volatility of
X, respectively, and
BH(
s) is the fractional Brownian motion (fBm) process which has long-range dependence and self-similarity properties. We already covered why the fBm process is used in financial modelling. In summary, it can capture the long-term dependencies in financial data, which are not always captured by traditional Brownian motion processes. This makes it suitable for modelling financial quantities that exhibit long-term trends or memory effects. Unlike crisp partial differential equation, the equation involving uncertainties is modelled using fuzzy processes. In the case of linear coefficients, an explicit solution can be obtained. The fractional fuzzy stochastic differential equation (FFSDE) satisfies the assumptions of Yamada-Watanabe-Kunita theorem and the Kushner-Stratanovich equation. The Yamada-Watanabe-Kunita theorem provides conditions for the existence and uniqueness of solutions to certain types of SDEs [
6]. Statement of the Theorem—consider the following stochastic differential equation:
where:
- -
Xt is the stochastic process to be solved.
- -
b(Xt) is a drift function that depends on Xt.
- -
σ(Xt) is a diffusion function that depends on Xt.
- -
Wt is a standard Wiener process (Brownian motion).
The Yamada-Watanabe-Kunita theorem requires the following assumptions to be satisfied:
1. The functions
b(
X) and
σ(
X) are globally Lipschitz continuous in
X with a Lipschitz constant that is independent of time
t. In other words, there exists a constant
K such that for all
x,
y in the state space of
X, we have:
2. The functions
b(
X) and
σ(
X) satisfy a linear growth condition. That is, there exist constants
M and
L such that for all
x in the state space of
X, we have:
SDE is nondegerate meaning the diffusion(covariance) matrix
σσT is positive definite everywhere. Under these assumptions, the Yamada-Watanabe-Kunita theorem guarantees the existence and uniqueness of a strong solution to the stochastic differential equation:
The theorem is essential because it establishes the conditions under which solutions to certain stochastic differential equations exist and are unique. The key idea behind the Yamada-Watanabe-Kunita theorem is to show that the nonlinearity of the drift and diffusion coefficients can be controlled by the Lipschitz and growth conditions, respectively, so that the SDE admits a unique solution. The theorem has been extended to FFSDEs, which are SDEs with fuzzy coefficients. In this context, the theorem provides conditions for the existence and uniqueness of solutions to FFSDEs and has important applications in the modelling of systems with uncertain or imprecise information.
The second important condition is the FFSDE model must satisfy the Kushner-Stratonovich equation [
7]. It arises in the context of state estimation problems, where the goal is to estimate the unobservable state of a dynamic system based on noisy measurements. The Kushner-Stratonovich equation applies to a class of SDEs that can be written in the following form:
where:
Xt is the unobservable state of the system at time t.
f(Xt, t) is a drift function that describes how the state Xt evolves over time. It depends on both the current state Xt and the time t.
g(Xt, t) is a diffusion function that accounts for the effect of random noise on the system. It also depends on the state Xt and time t.
dWt represents the increment of a Wiener process (Brownian motion), which represents the random noise or uncertainties in the system.
The main challenge in the theory of filtering is to find an optimal estimate of the state
X(
t) given the available measurements up to time t. This estimate is usually denoted by
and is known as the filter. Solving the Kushner-Stratonovich equation involves finding the filter
that minimizes the mean squared error between the true state
X(
t) and the estimated state
. The key idea behind the equation is to express the SDE in a form that separates the drift and diffusion terms, so that it can be solved using standard techniques from the theory of stochastic calculus. The Kushner-Stratonovich equation takes the following form:
where
g′ denotes the derivative of
g with respect to its argument. The equation represents an alternative to the Itô formula, which is commonly used to derive solutions to SDEs with linear drift and diffusion coefficients. In contrast to the Itô formula, which involves a stochastic integral with respect to the Wiener process, the Kushner-Stratonovich equation involves a deterministic integral with respect to the derivative of the diffusion coefficient. We have explained two important theorems that were used in this work’s derivations.
The equation we are deriving is a stochastic differential equation (SDE) describing a system with two state variables, and The SDE has a Wiener process W, which represents the random noise in the system. The SDE can be divided into two cases depending on the value of the drift coefficient μ. When μ ≥ 0, the unique solution to the SDE can be obtained using Feynman-Kac Theorem. The solution for and can be expressed in a matrix form. The solution involves exponentials of μt, α, and the Wiener process W. When μ < 0, the unique solution to the SDE can also be obtained using the same theorem. Again, the solution for and can be expressed in a matrix form. The solution involves hyperbolic functions of μt (cosh and sinh), exponentials of α and the Wiener process W. In both cases, the solution involves an integral over the Wiener process W, which is a stochastic integral. The integral is evaluated using the Itô integral, which is a stochastic calculus tool used to integrate stochastic processes with respect to the Wiener process. The integral is approximated using the Stratonovich integral, which is a different stochastic calculus tool that gives a different result than the Itô integral. The result of the Stratonovich integral is denoted by the symbol 〈 〉 in the equation we derive. The final result is an approximation of the solution to the SDE in terms of X(0), , α, σ, μ, and the Wiener process W. The solution is a fuzzy solution because it involves a stochastic process, and the value of Xε(t) is not deterministic but depends on the realisation of the Wiener process W. Now we will derive it.
FFSDE involves a stochastic process X that maps from R+ × Ω to F(R), where F(R) is the space of fuzzy real numbers. and are functions that map from R+ × Ω to R and define the lower and upper bounds of the fuzzy process and .
To obtain a closed explicit form of the solution for μ ≥ 0, a system of equations is derived. The solution to the system provides a unique solution, and , which is expressed as an explicit formula involving the initial values and . This formula involves the exponential function and the fBm process BH(s). For every α ∈ [0, 1], a similar procedure is applied to obtain a new system of equations, which is similar to the previous system but involves the fBm process instead of dBH(s). The solution to this new system of equations also involves an explicit formula, and which is expressed as an integral involving the initial values and the fBm process .
To obtain an explicit solution, we first express
X(
s) in terms of its initial value
X0 and the fBm process
BH(
s):
and apply Itô’s formula to the function
for some constant a:
Substitute for
dx, we get:
Integrate both sides from 0 to
t, we get:
Solving for X(t) we obtain: .
This is the solution to the crisp SDE with a linear coefficient. We are interested in the fuzzy SDE. Consider the FFSDE which satisfies the theorem we proved in [
8], that there is the existence of a strong and unique solution.
Then, the given equation is:
To obtain a closed form solution for
μ ≥ 0, we obtain the following system of equations for lower and upper bounds.
We add two equations and simplify to get
We will now transition from fBm to standard Brownian motion. To achieve this, we substitute a derivative of
into the above equation. Recall:
where
.
So, taking derivative
Substitute these identities into expression for
will convert this FFSDF into a Wiener process.
this symbol is Stratonovich integral, and this is why we needed the Kushner-Stratonovich theorem so we could go back and fourth between Wiener and fractal processes. The Kushner-Stratonovich equation, which was mentioned earlier in the text, provides a way to relate SDEs driven by a Wiener process to SDEs driven by a fractional Brownian motion process or other fractal processes. This theorem allows for the conversion between the two types of processes, which is necessary in this case to convert the FFSDE involving a fractional Brownian motion into an SDE involving a standard Wiener process. By using the Kushner-Stratonovich theorem and the Stratonovich integral, it becomes possible to work with the more familiar Wiener process while still accounting for the fractal nature of the original process through the appropriate transformations and integrals.
Now, we can use the solution that we used to solve the crisp stochastic differential equation and substitute back fBm expression.
Finally, we apply similar approach for every
a ∈ [0, 1] to get the system of equations.
For
μ ≥ 0, we apply the solution derived above, namely (1) for upper and lower bounds:
In terms of the Wiener process, we again get rid of fBm and replace it with normal Brownian motion. So, we will substitute a derivative of
into above equation same as we did before.
So, to summarise what we have done and give a high-level overview of the steps involved, this is what we did so far. To solve this SDE, we need to find the probability distribution of
X(
t) given its initial condition
X(0). This probability distribution is given by the rough Fokker-Planck equation [
9], which is a partial differential equation that describes the time evolution of the probability density function of
X(
t). However, in the case of our SDE, we can simplify the problem by noticing that
and
are linear combinations of X, which means that their probability distributions can be obtained from the probability distribution of X(t). We can then use Itô’s lemma to transform the SDE into an equivalent SDE for
and
[
2,
10]. Itô’s lemma is a rule that allows us to find the SDE satisfied by a function of a stochastic process. The lemma states that if Y(t) is a function of X(t), then the SDE satisfied by
Y(
t) is given by:
, where (
∂Y/
∂t) is the partial derivative of
Y with respect to time, (
∂Y/
∂X) is the partial derivative of
Y with respect to
X, and (
∂2Y/
∂X2 is the second partial derivative of
Y with respect to
X. Using Itô’s lemma, we can find the SDEs satisfied by
and
. The SDEs have the same form as the original SDE, but with different drift and diffusion coefficients that depend on
α. The final solution involves an integral over the Wiener process
W, which is a stochastic integral. The integral is evaluated using the Itô integral or the Stratonovich integral, depending on the convention used. The solution is a fuzzy solution because it involves a fuzzy stochastic process, and the value of
Xe(
t) is not deterministic but depends on the realisation of the Wiener process
W. We will derive a generic solution for stochastic differential equation of the following form which can be applied to each specific case:
Re-writing in terms of derivatives, we need to solve the stochastic differential equation of the form:
with initial condition
X(0), we will use Itô’s lemma to obtain the solution:
Let
Y(
t,
B(
t)) =
eμtX(
t). Then, using Itô’s lemma, product rule and definition of X to obtain the solution:
Integrating both sides of this equation from 0 to
t, we treat left hand side using fundamental theorem of calculus:
Y(
t,
B(
t)) −
Y(0,
B(0)). The first integral on the right-hand side can be simplified using change of variable.
The second integral on the right-hand side is a stochastic integral of the form:
Substituting both sides back into the original equation, we get:
So, the unique solutions are same as before.
Now, we will revert to fBm by making the same substitution as before. Recall that:
where
.
So, taking derivative
, and in terms of fBm, we get:
Therefore, the generic solution for
μ ≥ 0:
For μ ≤ 0, we start with the following well-known identities:
and
. We will show that
. If we combine {
}, and we replace the first term
with
, our solution becomes:
Therefore, the generic solution for
μ ≤ 0:
The choice of the customised PDE involving hyperbolic and exponential functions rather than a classical PDE is driven by the need to reflect the inherent complexities observed in financial markets more accurately. Classical PDEs, such as the traditional Black-Scholes model, rely heavily on assumptions like independent increments and no memory effect, conditions that are rarely fully satisfied by real-world data.
We proved no arbitrage conditions for fuzzy fractal model when Hurst exponent is greater than ½ [
1,
10]. We will extend this now to FFJDM under the risk-neutral measure
Q which is a theoretical probability measure used to value financial derivatives, such as options, under the assumption that the expected rate of return of the underlying asset is the risk-free rate [
3]. This approach simplifies the valuation process and allows for a relatively easy pricing of derivatives without considering the actual probabilities of different market outcomes. This means that when calculating expected values of future payoffs, we use the risk-free rate as the discount factor. Under this measure, we can calculate the present value of future cash flows associated with financial derivatives. When valuing financial derivatives like options, the risk-neutral measure allows us to use a discounted expected value calculation to determine the fair price of the derivative. This approach assumes that investors are risk-neutral and do not require a risk premium for holding the derivative. The statement implies that even under the risk-neutral measure
Q, the underlying asset price still follows a certain stochastic process. Under the assumption of no arbitrage, the risk-neutral and the real-world (risky) measures are equivalent in the context of option pricing and derivatives valuation. This equivalence is a fundamental concept in mathematical finance and is known as the Fundamental Theorem of Asset Pricing [
3]. In order for risk-neutral and risky measures to be equivalent, we impose a no-arbitrage condition under which
. The result we will derive next using Itô’s lemma shows that there is a unique solution to our FFJDM equation, and that solution does not depend on any particular assumptions or individual preferences about risk. The arbitrage free price of a derivative is uniquely determined because in this model the derivative is superfluous. This means that the derivative’s price is fully determined by the model’s dynamics and parameters, and its price is consistent with the prices of other assets in the market. In essence, the derivative’s price is not subject to arbitrary fluctuations or ambiguous valuation. We will use a well-known Girsanov theorem in the theory of stochastic differential equations, that if we change the measure from real-world P to some other equivalent measure in risk-neutral world
Q, this will change the drift in the SDE, but the diffusion term will be unaffected. This is why we set
. Thus, the drift will play no part in the pricing equations. Using Girsanov’s theorem and re-writing
as
. We get under risk-neutral measure:
This is the process that
follows which we will use in the proof later. The Cheridito (2001) paper, titled “Mixed Fractional Brownian Motion” [
11], presented a framework for modelling and analysing mixed fractional Brownian motion (MFBM), which is a generalisation of fractional Brownian motion (fBm). The paper introduced a class of stochastic differential equations driven by MFBM and established existence and uniqueness results for solutions under certain regularity conditions. It was shown that if the Hurst exponent is greater than ¾, the fractional Brownian motion process satisfies certain regularity conditions, which allow for the existence of a unique solution to the stochastic differential equation. The key point made in [
11] is that when ¾ <
H < 1, the mixed fractional Brownian motion exhibits properties that avoid arbitrage. For
H > ¾, the text makes clear that the mixed model retains a semimartingale structure, allowing for classical arbitrage-free pricing arguments. This is an important result because in this regime, the models are well behaved. For
H < ¾, the paper mentions that arbitrage can emerge because the resulting process is no longer a semimartingale. This means the standard tools like Girsanov’s theorem may break down. Ref. [
11] explicitly proves that adding a standard Brownian motion to fractional Brownian motion making it a mixed model, helps restore arbitrage-free properties under specific conditions on
H. This is equation 6.2 on page 933 in [
11]. In other words, ref. [
11] key contribution is precisely that by adding a standard Brownian motion component to fractional Brownian motion making it “mixed” and keeping
H above ¾, one can restore the possibility of no-arbitrage and standard pricing methods. The mixed process takes the form of equation 6.2 where
is a fractional Brownian motion and
is an independent standard Brownian motion.
The crucial point is Theorem 1.7 from [
11] that shows that for
H > ¾, the process
remains equivalent to a Brownian motion under an equivalent martingale measure
, provided ε is small enough. This implies that arbitrage is avoided when the mixed process is used instead of pure fBm. This result is relevant for our work in the mathematical analysis and modelling of the underlying asset dynamics in option pricing. The discounted expected value of
ZT at time
t ϵ [0,
T] under risk-neutral measure
Q is given by
, so
, otherwise the payoff is zero. We will now substitute expression for
from (6) into the above equation:
We will now use law of iterated expectation within the context of a σ-algebra. The σ-algebra, denoted by represents the conditioning information or the available knowledge up to time T. It includes all the events or outcomes that can be determined based on the random variables Yi up to time T. This sigma algebra essentially captures the information available from the past observations and values of Yi up to time T. The Law of Iterated Expectations allows us to rewrite this as which means we are now taking the inner conditional expectation over the specific sigma algebra . By conditioning on the specific sigma algebra we are essentially using the available information up to time T to compute the conditional expectation of the expression. This simplification is possible because the conditioning restricts the uncertainty to the events in the specified sigma algebra.
In the context of our expression, the conditional expectation represents the expected value of the inner expression (the option payoff) given the information available up to time T, which is encapsulated by the sigma algebra. This conditional expectation accounts for the uncertainty in future events by conditioning on the information from the past.
The sequence of random variables
, where
V is a sequence of independent and identically distributed i.i.d fuzzy random variables, contributes to the information available in the conditioning σ-algebra. These random variables follow a normal distribution with mean μ and variance
σ2. Therefore, we have:
When we condition on the sum of Yi, which is essentially the cumulative log value of the sequence of jumps, we are effectively considering the total logarithmic impact of the jumps up to time T. Since the number jumps are modelled using a fuzzy Poisson process with jump intensity λ, their cumulative effect follows a Poisson distribution.
In other words, the jumps, when summed and transformed by taking the logarithm, have properties that lead to the emergence of a Poisson distribution in the conditional expectation.
consists of three i.i.d. fuzzy normal random variables. From the properties of variances of random variables we know that the variance of the square of the random variables is the sum of their variances. Also, from Itô’s, we know that the square of
Bt and
BH is
T and
T2H. So,
. Mean of
is simply expectation of
because expectation of the stochastic processes is zero. So,
. We plug these values into the above the equations:
where
is the density of the fuzzy normal variable with mean
and variance
So,
, and the whole integral:
The integrand in the integral above vanishes when:
, i.e., when z < z
0, where
The integral can thus be written as:
The integral
B can be written as
and using the symmetry of the Normal distribution, this can be written as
. So, if we denote the cumulative distribution function of
N as is the usual convention:
then we can write
. In the integral
A, we have:
Recall that the fuzzy normal random variable has mean and variance .
So, we are integrating a function with respect to a random variable that follows a given probability distribution. In the field of stochastics, this is often encountered in the form of an expectation. In our case, the expectation of (
), where
is normally distributed can be written as follows:
where
f(
y) is the probability density function (PDF) of the normal distribution:
Plugging this into the original equation, we get:
Simplifying this, we get:
The above expression is the definition of the moment generating function (MGF) of a normally distributed random variable at the point
t = 1. The MGF of a normal distribution with mean
μ and variance
σ2 is given by:
Substituting
t = 1 in the MGF gives us:
This is the expected value of an exponential of a normally distributed random variable. This is different from the indefinite integral of eY with respect to Y, which isn’t typically defined for random variables. Instead, we work with expectations, which are a form of weighted integral where the weights are given by the PDF of the random variable.
So, the above integral is now simplified to:
Next step is to standardise the integral by changing its limit with
and
Again, this is the density of the of the normal distribution. Using symmetry we can write:
Now, we can combine
A and
B and write the whole expression:
Finally, substituting above expression into:
Recall that
. Take t
0 = 0 and substitute
into above expression, we get:
Φ represents the cumulative standard normal distribution function. The terms d1 and d2 are often used to assess the probability of the option expiring in the money or out of the money. d1 represents the standardised distance between the current stock price (S) and the strike price (K), adjusted by other factors such as the risk-free interest rate (r), volatility (σ), and time to expiration (T). Specifically, d1 incorporates the expected return and the expected volatility of the stock. d2 is similar to d1, but it is adjusted by subtracting the volatility component (σ√T). This adjustment reflects the expectation of the stock price being below the strike price at expiration. The probabilities come into play when you consider the cumulative standard normal distribution function (Φ) applied to these d1 and d2 values. The cumulative distribution function gives the probability that a standard normal random variable is less than or equal to a given value. For a call option, d1 represents the probability that the option will finish in the money (stock price above the strike price) and d2 represents the probability that the option will finish out of the money (stock price below the strike price). In summary, while d1 and d2 aren’t direct probabilities, they are closely related to the probabilities of the option being in the money or out of the money.
The techniques developed for fBm with
H < ½ can be effectively applied in financial modelling, particularly in modelling volatility and volatility of volatility (vol-of-vol) which exhibit rough path structure [
8,
9]. These rough volatility models, often characterised by Hurst exponents less than ½, capture the persistent, jagged behaviour of market fluctuations more accurately. By incorporating fuzziness into key parameters such as volatility, drift, and jump intensities, the fuzzy fBm framework enhances the ability to model these irregularities and account for uncertainty in parameter estimation. This is particularly important in environments where precise volatility measurement is challenging due to market noise or incomplete data. The combination of fuzziness with rough fractional paths allows for a more robust representation of the volatility surface, improving option pricing, hedging strategies and risk assessment in volatile markets.
In the context of modelling volatility of volatility, the FFBM can be particularly useful in capturing the stochastic nature in instruments like VIX derivatives and volatility swaps. Traditional models often struggle to account for the irregular, long-memory effects present in vol-of-vol, which is now very documented in empirical finance [
9]. By applying FFBM, empiricists can build a shifting vol-vol dynamic model without assuming an overly smooth process. As we demonstrated earlier, this framework can be integrated with Girsanov’s theorem under a risk-neutral measure, ensuring that the pricing of derivatives reflects real-world irregularities while maintaining theoretical robustness and no-arbitrage conditions.
In non-financial applications, a potential application is in the telecommunications and network traffic modelling. Fractional Brownian motion has already been widely used to model network traffic, but the real-world network conditions often exhibit variations that are best captured through fuzzy logic. In adaptive bandwidth allocation, congestion control, and network anomaly detection, FFBM can be employed to handle imprecise or incomplete traffic data, allowing service providers to develop more resilient protocols for managing data flow, reduce latency, and optimise resource allocation in high-traffic environments such as cloud computing and real-time streaming services.
In classical fBm, the kernel governs the memory and roughness of the process through the Hurst exponent H. When fuzziness is introduced, the kernel becomes a fuzzy function. This means instead of having a single deterministic kernel, the model now handles sets of possible kernels defined by membership functions of fuzzy intervals. The amplitude functions, which influence the drift and diffusion terms in SDEs also become fuzzy variable. This means the diffusion coefficient σ and drift term μ are no longer fixed but represented by fuzzy sets or intervals. While fuzziness increases model complexity, it also introduces robustness in modelling real-world uncertainty. By modelling this uncertainty explicitly through fuzziness, the framework becomes mathematically richer and computationally more intensive, but these challenges are balanced by the model’s ability to capture real-world phenomenon where precise information is often unavailable or delayed.
4. Introducing Fuzzy When H < ½
Under the assumption that the fuzzy aspect lives in the amplitude/kernels and that the underlying driving noise
is actually a crisp fractional Brownian motion. In other words, we are layering fuzziness on the coefficients/functions of the integral but not changing the fundamental measure-theoretic structure of the noise. This assumption ensures we can leverage classical results such as Itô isometry for existence, uniqueness, and bounding integrals which we proved in [
8].
For
H < ½, the kernel
KH(
t,
s) used to construct fBm was derived by [
17].
where
CH is a normalising constant given by:
.
For practical applications, a more convenient representation of the kernel function for
H < ½ can be written as:
This ensures the kernel remains well-defined and integrable. To establish upper and lower bounds for the integrals involving fuzzy fractional Brownian motion when H < ½, we need to adapt the existing techniques to handle the fuzzy nature of the random variables. To establish bounds, we need to represent the fuzzy variables as intervals or use membership functions and then analyse these representations.
An important characteristic of fBm that significantly enhances its applicability in financial modelling is its long memory effect, which is governed by the Hurst exponent H. The Hurst exponent characterises the autocorrelation structure of increments of the process. If H > ½, this indicates positive correlation and persistent behaviour, meaning past increases or decreases tend to be followed by future movements in the same direction. Financial assets exhibit persistent behaviour, and shocks to be positively correlated over long periods, making fBm an ideal model for capturing long-term dependencies observed in bubble dynamics.
If H < ½, this corresponds to anti-persistence, or rough path showing mean-reverting behaviour. Such anti persistence phenomena are frequently observed in short-term trading scenarios. In our context, we focus on the case of H < ½, as indicated above, due to its suitability for modelling frequent reversals.
Fuzzy Gaussian Distribution
At any fixed time t, the value of the fuzzy Brownian motion is a fuzzy Gaussian variable. This means its probability distribution is a Gaussian distribution with fuzzy mean and variance.
Fuzzy Integral Representation:
We denote the kernel
as fuzzy, which means at each
ω ∈
Ω, the kernel belongs to a set and has a membership function describing possible amplitude values.
We assume the underlying noise is crisp, but the fuzzy aspect is in the amplitude of the kernel. We had earlier proven in [
8] that the classical Itô isometry remains perfectly valid for each crisp selection and each scenario in our fuzzy ensemble because the noise is crisp. The fuzziness is layered on top by letting the integrand vary in intervals. Nothing breaks the standard measure-theoretic basis of
.
Our future work would involve defining the fuzzy fractional Brownian motion in the sense of fuzzy measure theory, not just a crisp B with fuzzy amplitude. Then the classical Itô isometry is no longer guaranteed. Indeed, we might not even have a linear–additive expectation E in the sense of Kolmogorov measure theory. Instead, we have fuzzy expectation and fuzzy integrals, which typically do not obey Itô isometry.
The step:
would be wrong as indicated by ≠, because the left side uses a fuzzy integral and fuzzy expectation. Typically, a pure fuzzy measure does not preserve linear additivity, and it uses a non-classical integral Choquet, or Sugeno. The isometry is not guaranteed.
Since both and are fuzzy, we can represent them as intervals for analysis.
The fuzzy labels on does not break linearity or additivity of the expectations and the integrals, because fuzziness is above the measure level.
For uniqueness proofs, we define upper and lower bounds for Fuzzy Gaussian Increments:
Here,
represent the lower and upper bounds of the fuzzy kernel function, and
represent the lower and upper bounds of the fuzzy Gaussian process. The upper and lower bounds for the fuzzy fractional Brownian motion integrals are determined by analysing the bounds of the kernel function and the Gaussian process separately.
By ensuring that these integrals are finite, we will demonstrate the existence of the solution. Uniqueness will be shown by proving that the fuzzy integrals converge uniquely under the given conditions—if that difference of kernels is zero a.s. owing to identical initial data and integrable constraints, we obtain uniqueness.
In other words, we need to show that:
For
:
Both terms inside the integral are finite for H < ½, and the subtraction term also ensures the finiteness of the integral.
Similarly, for the upper bounds:
The same reasoning applies here, both terms inside the integral are finite, and their subtraction ensures the integrals are finite. Therefore, both the upper and lower bounds are finite.
To show uniqueness, we need to prove that the fuzzy integral representation converges uniquely under the given conditions. We assume that there are two fuzzy fractional Brownian motions and with the same initial conditions.
For uniqueness, consider the difference:
Then we can use Itô’s isometry:
If and are solutions, then a.s. Thus, .
This implies that a.s. and . Proof complete. Therefore, the solution is unique.
Membership function:
is called a fuzzy normal variable if for each α ∈ (0, 1], we can select a crisp normal distribution such that μα and come from the α-cuts of the fuzzy numbers and . The nested family is consistent in the sense that if α2 < α1, then μα2 ⊆ μα1 as intervals.
Hence, we represent our fuzzy normal by the entire nested family of classical normal distributions, one for each level of membership
α. Next, we apply the Zadeh extension principle (or an interval-based extension principle) to unify fuzzy parameters
and
into one membership function
μX(
x) for a fuzzy normal distribution. The key idea is once we have fuzzy sets for mean and variance, we want a single fuzzy set in
R describing how likely it is for our fuzzy normal to take each real value
x. This demands a recognised fuzzy extension approach that merges the fuzzy parameters into a single fuzzy set of real outputs. Generally, for each
and
t, the value
has membership function describing the degree to which it belongs to the fuzzy set
.
When we have intervals of means μ ∈ and variances σ ∈ , the pdf can vary accordingly. To find unified pdf we implement the threshold aggregator approach that merges the entire alpha-cut family into one membership function by allowing us to climb up alpha levels as far as possible, subject to the pdf condition. A bigger α indicates a narrower region for μα and , so it is more demanding that we still get bigger threshold in the pdf. The result is a single membership at x ∈ [0, 1]. If we define τ as some threshold then x has membership ≥ α if we can find a parameter pair in α-cuts that yields ≥ τ pdf. So, membership is the supremum of all such α. This is a version of the Zadeh extension principle, adopted to the pdf is above threshold τ condition.
We now formalise these concepts mathematically. Let be a fuzzy mean and be a fuzzy variance. and are fuzzy numbers in R and (0, ∞) respectively. Fix a threshold τ ∈ (0, ∞). For each α ∈ (0, 1], define intervals .
We say x ∈ if:
such that .
Then the membership function for
is:
We call a fuzzy normal variable under threshold τ.
This aggregator is one of many possible. Now we have a robust approach that merges fuzzy and into a single fuzzy set of real values x. It does so by checking the classical normal pdf at each α -cut and picking the supremum over α.
Fuzzy Martingale
A fuzzy martingale
(t) is a generalisation of a standard martingale, where the values are described by fuzzy numbers. For a process to be a fuzzy martingale, it must satisfy the martingale property with respect to fuzzy conditional expectations. So, for
(t) to be a fuzzy martingale, it must satify:
Proof for Fuzzy Fractional Brownian motion when H < ½ with Gaussian membership function
We derive step by step proof for ffBm when H < ½ and Gaussian membership function.
- 1.
Integration by Parts with Fuzzy Variable:
Let
. Then:
- 2.
Define fuzzy Molchan martingale:
where
is a scaled beta kernel.
- 3.
Upper bound for fuzzy using integration by parts. From (15):
Since the integral term is positive, therefore:
- 4.
Now, substitute for :
- 5.
We now apply expectation:
Since
is a fuzzy Molchan martingale, by the Burkholder-Davis-Gundy inequality, there exists a constant
such that:
The next result we take from Norros, Proposition 2.1 in [
16]:
- 6.
We will now combine these results to compute quadratic variation for 1 − H > ½ to obtain:
Use [
16]:
.
Substitute into:
. Continuing with quadratic variation:
- 7.
Apply BDG inequality on quadratic variation of MH, to obtain:
Using (16):
, substitute into (18), we get:
- 8.
If we define then . Proof complete.
The risk-free measure transformation relies on constructing a risk-neutral probability measure under which the discounted asset price processes become martingale. In our fuzzy environment, the validity of this transformation hinges upon the assumption that fuzziness is introduced at the coefficient and amplitude level as opposed to altering the fundamental probability measure structure itself. Since the driving noise remains crisp, the classical construction of the risk-free measure is preserved. Thus, each scenario within our fuzzy environment still respects the standard probabilistic assumptions required by the Girsanov transformation.
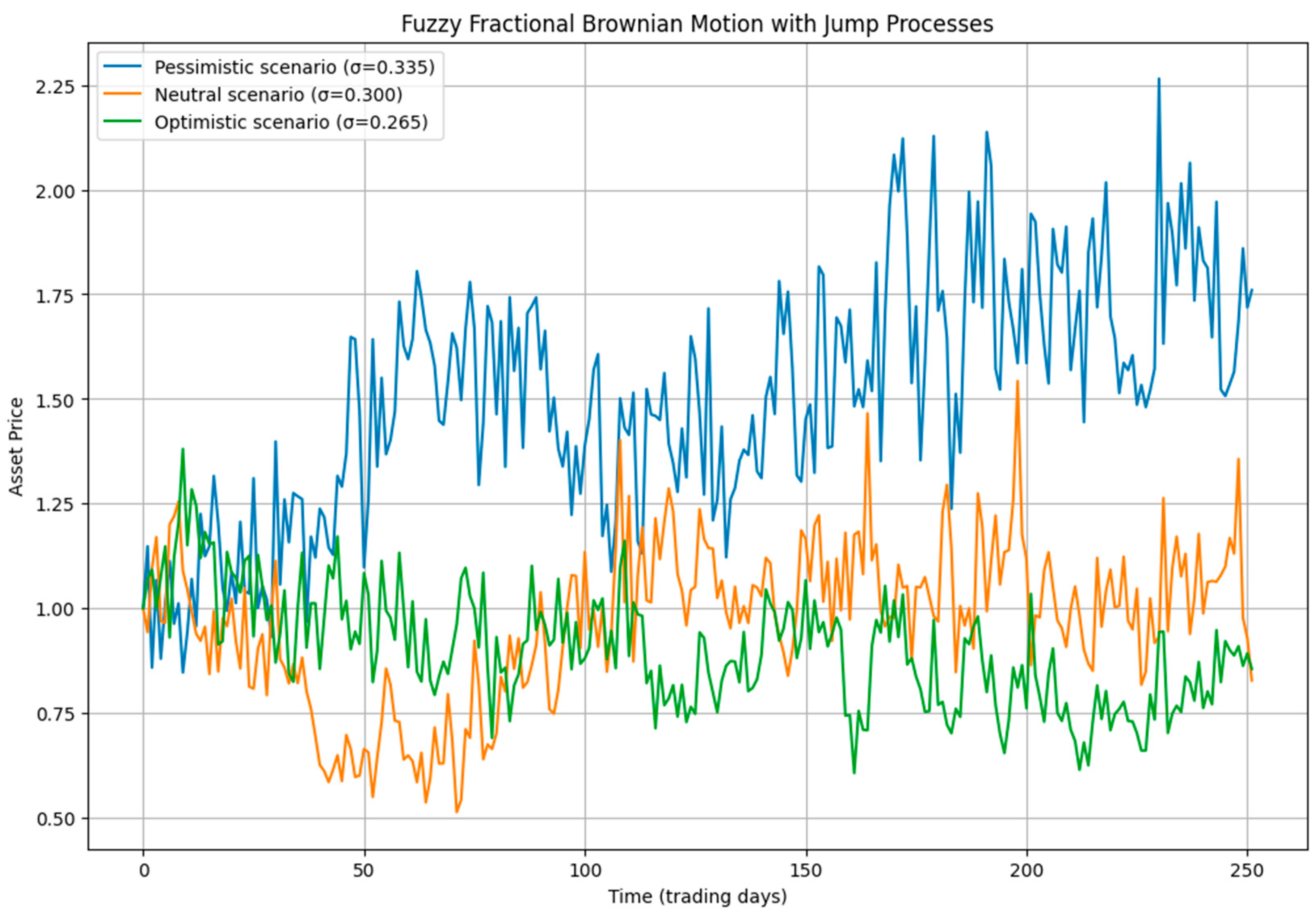
In order to generalise the classical Girsanov transformation to cover fBm by leveraging Molchan-Golosov representation and a suitable martingale constructions. This extension ensures the stochastic integrals driven by fBm can be translated into equivalent martingale measures, allowing us to consistently price financial derivatives under fuzzy fractional dynamics. The generalisation uses fractional kernels and transformations introduced through fuzzy integral bounds. To illustrate the practical implications, consider the following heuristic numerical example involving a European call option.
Assumptions:
Asset Price, S0: 100
Strike Price K: 100
Risk-Free Rate: 0.05
Time to maturity (T): 1.0 year(s)
Hurst Exponent H: 0.4
Adjusted Volatility Interval (fuzzy): [0.1500, 0.2500]
Drift (fuzzy), μ: [0.04, 0.08]
Results under lower bound and upper bound scenarios:
7. Conclusions
We formalised the study of a fuzzy fractional Brownian motion (fBm) for H < ½ by adapting classical results from traditional fBm setting, while layering fuzziness on certain coefficients and amplitude functions. In the crisp scenario, fBm with H < ½ is often represented via the Mandelbrot–Van Ness construction, where BH(t) is expressed as an integral of a kernel KH(t, s) against a standard Brownian motion. This kernel typically takes a difference form that remains integrable near the endpoints s = 0 and s = t, even though the process is not a semimartingale. To extend this into a fuzzy framework, we assumed that the driving fractional Brownian motion is still a classical, measure-theoretic process, but the kernel and other amplitude-related parameters become fuzzy. This framework allowed us to reuse many of the standard measure-theoretic techniques for integrals and isometries, because the underlying noise retained all its crisp characteristics.
We treated the kernel and the parameters as fuzzy sets whose possible values, for each outcome, lie in the intervals or have membership functions describing their degrees of plausibility. Each realisation of these fuzzy parameters can then be viewed as a crisp selection, ensuring the integral with respect to the standard Brownian motion is well-defined in the usual sense. This framework allows the preservation of existence, uniqueness, and boundedness properties. The driving noise is classical, so measure-theoretic arguments like the Young and Skorohod integrals for H < ½ continue to hold, and the presence of fuzziness in the amplitude and kernel does not break the underlying integrability conditions.
A key aspect of analysis focuses on uniqueness. If two processes share the same fuzzy kernel data but happen to differ in how one selects fuzzy values for the integrand, one looks at their difference . Because the underlying noise is a crisp Brownian motion, one applies the standard isometry. If coincide almost surely in the sense that their fuzzy parameters are identical for each scenario, then the difference integral is zero. This shows that no two distinct fuzzy processes can arise from the same fuzzy kernel data, and uniqueness is secured.
To bound the supremum of fuzzy fBm, we employed a form of the Molchan martingale technique and a BDG inequality approach [
19]. In standard fBm with
H < ½, one can define a transform that behaves like a martingale with respect to a certain filtration or at least allows one to control the magnitude of
BH(
t). By retaining a crisp measure for the noise, the same style of arguments holds. We obtained an estimate of
in terms of
, where
is a fuzzy version of the Molchan martingale. Expectation inequalities follow from standard integrability requirements.
Taken together, we showed that working with H < ½ in the fuzzy context does not fundamentally destroy the usual integrability results, as long as the driving noise remains crisp. The main difference is that each amplitude or kernel value now belongs to a fuzzy set, but any specific scenario or selection yields a classical integrand, so integral definitions and uniqueness proofs proceed as in the standard framework. The bounding arguments are similar. We reused the classical measure-theoretic inequalities and simply recognised that the fuzziness entered in the amplitude, not in the measure. In this way, the entire theory remained consistent for H < ½, including existence of the fuzzy fractional Brownian motion, its uniqueness from the integral representation plus the crisp isometry argument, and the ability to label its distribution as fuzzy Gaussian via alpha-cuts and an aggregator principle.
The concept of overlaying a fuzzy structure onto a crisp fractional Brownian motion is not entirely new. Various authors in fuzzy stochastic modelling that we thoroughly reviewed in [
8] have taken a crisp process such as a Brownian motion or a fractional Brownian motion and allowed certain parameters or coefficients to be fuzzy, thus letting each outcome pick a different crisp coefficient from the fuzzy set. This approach makes it possible to reuse all the standard measure-theoretic arguments, because the noise is still treated in a classical Kolmogorov framework.
However, systematically applying this method in the specific case of
H < ½ for fractional Brownian motion, together with an explicitly defined aggregator and Zadeh extension principle for fuzzy normal distributions, has not been formalised in the literature. Mostly, research focuses on a fully crisp version of fractional Brownian motion in the non-semimartingale regime without considering fuzziness, or it addresses fuzzy Brownian motion or fBm in a more informal manner without fully elaborating measure-theoretic integrals or the precise aggregator rules that unify fuzzy parameters into one membership function on the real line [
20,
21,
22]. Some articles instead mention fuzzy parameters in simpler SDE frameworks with Brownian noise but do not carefully handle the fractional exponents and the integration approach required for
H < ½ [
23,
24,
25,
26,
27,
28,
29,
30,
31,
32].
Our research offers a unified formalism for adapting the fractional integral representation when H < ½, how to treat fuzzy kernel and amplitude values while preserving the crisp measure structure of the noise, and demonstrating existence, uniqueness, and boundedness in that environment. We clarified how to use the classical fractional integral machinery in a fuzzy setting, employed the standard uniqueness arguments while acknowledging the fuzziness of the kernel, and explained how to define a fuzzy normal membership function rather than simply stating fuzzy Gaussian without formal details. The originality of our approach lies in its explicit handling of the non-semimartingale regime H < ½ within a fuzzy kernel environment, its maintenance of the validity of measure-theoretic integrals by keeping the noise crisp, and its articulation of a consistent approach to defining the distribution via a recognised aggregator principle for fuzzy normals. Our rigorous treatment of fuzzy fractional Brownian motion and a clear explanation of how fuzziness modifies the usual uniqueness proofs and distribution membership constitute a coherent roadmap that is currently missing in the existing literature.
Our rigorous treatment of fBm and a clear explanation of how fuzziness modifies the usual uniqueness proofs and distribution membership constitutes a coherent roadmap that is currently missing in the existing literature. Furthermore, our model demonstrates superior applicability to financial products where long-term dependency and uncertainty are critical. In particular, it provides improved performance in pricing and hedging options with persistent volatility or mean-reverting characteristics which are common in equity indices and commodity markets, respectively. By incorporating fuzzy fractional dynamics, the model captures both long memory and uncertainty, offering more realistic pricing intervals and enhanced risk assessments compared to classical models. These attributes make the model highly relevant not only for option pricing but also for broader derivative applications and risk management strategies, where accurate quantifications of volatility ambiguity and drift uncertainty is essential.





{kind=link}