1. Introduction
The diversity and complexity of cyber-attacks have increased significantly in recent years, which presents significant challenges to network security. Modern cyber-attacks are no longer limited to traditional viruses and worms but also encompass advanced persistent threats (APT), ransomware, phishing, distributed denial of service attacks (DDoS), and zero-day exploit attacks, each characterized by unique tactics, high sophistication, and targeted [
1].
In this complex environment, accurately detecting anomalous network traffic presents a critical challenge to network security. Currently, popular network anomaly detection methods include statistical methods, clustering-based methods, and deep-learning-based methods. Statistical methods, such as traditional network anomaly-detection techniques, detect anomalies by evaluating statistical network traffic characteristics. A representative approach is the multivariate statistical network monitoring method based on principal component analysis (PCA) proposed by N. M. Fuentes Garca [
2]. This method applies MSPC theory, developed for industrial monitoring, to network monitoring, addressing issues in earlier PCA-based methods, including sensitivity to calibration data and contamination of the normal subspace by large-scale anomalies. However, this method requires extensive data normalization, preprocessing, and alignment depending on the data source and task objectives while exhibiting limited generalization capability.
Cluster-based approaches treat traffic that deviates from known clusters as anomalies. Common clustering algorithms include k-means, DBSCAN, among others. The strengths of clustering methods lie in their ability to identify unknown anomaly patterns and exhibit robust modeling capabilities. However, these methods are often inefficient in high-dimensional and large-scale data scenarios, with sensitivity to parameter selection and initial conditions [
3].
In contrast, deep-learning methods can automatically extract intricate features from raw data using multi-layer neural networks, eliminating the need for manual feature engineering. This enables models to effectively handle nonlinear and high-dimensional data, thereby adapting more effectively to complex network traffic patterns and enhancing anomaly detection accuracy [
4,
5]. For example, Q. P. Nguyen et al. [
6] employ variational autoencoders (VAE) combined with gradient-based fingerprinting to construct the GEE network anomaly detection model. It uses VAE to detect anomalies in the dataset and construct a cyber-attack fingerprint based on the gradient change characteristics of the anomalous data. GEE achieves superior overall performance in anomaly detection through the application of fingerprinting techniques. Therefore, a key principle of anomaly detection emerges: compared to normal data points, specific alterations in certain features of anomalous data points result in pronounced variations in the objective function. Consequently, anomaly detection performance can be improved by reducing the noise caused by changes in irrelevant features and highlighting changes in key features.
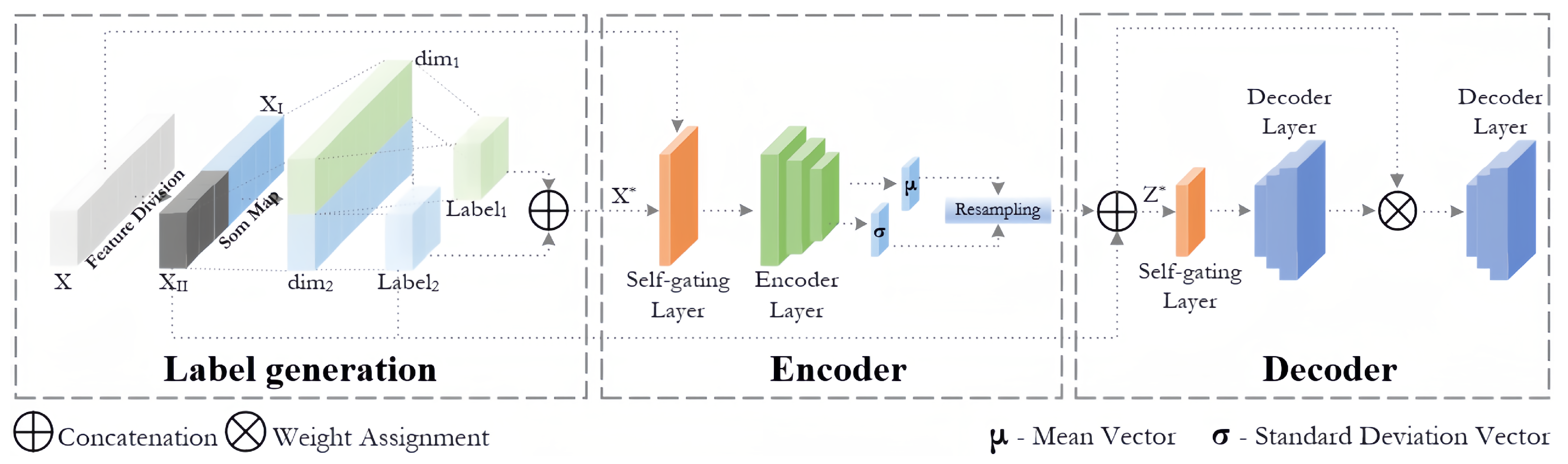
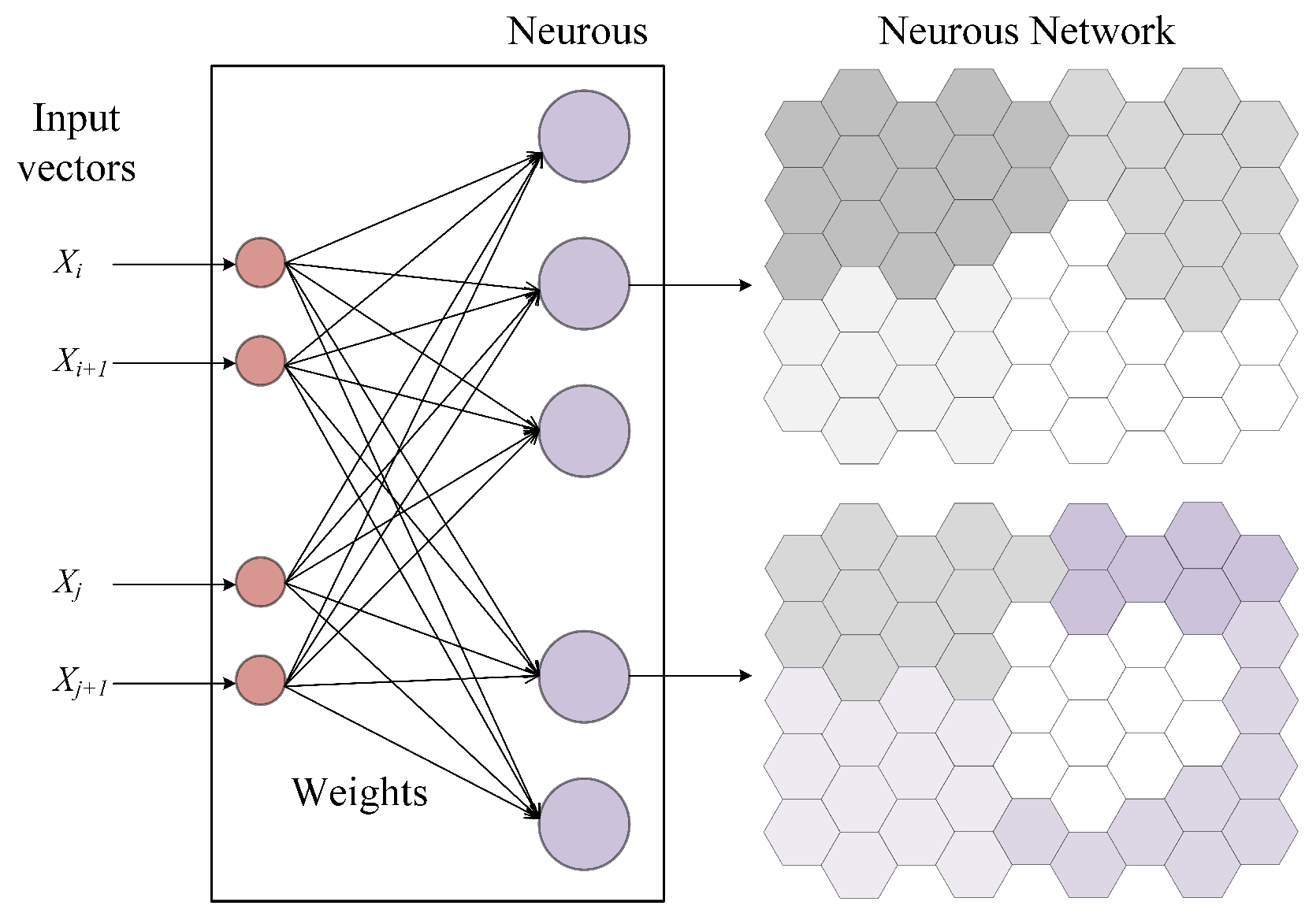
Based on the above ideas, we have constructed a novel unsupervised hybrid model, SOVAE. SOVAE is an unsupervised network anomaly detection model that integrates SOM and VAE. The model partitions data features via a feature correlation graph to reduce feature sparsity. It introduces clustering labels from the SOM into the symmetric “encoder-decoder” network architecture of the VAE to achieve data reconstruction, and incorporates clustering distance to increase the dimensionality of variations in the objective function. The symmetry of the model architecture aids in optimizing the distribution of the latent space, thereby enhancing the robustness of normal pattern reconstruction while amplifying feature deviations in anomalous data. In summary, the main contributions of the research in this paper include:
The remainder of this paper is organized as follows:
Section 2 reviews related work.
Section 3 details the design and implementation of the SOVAE model.
Section 4 presents experimental results and performance evaluations.
Section 5 concludes the paper and discusses potential directions for future research.
2. Related Work
Deep-learning-based network anomaly-detection methods are typically classified as supervised, semi-supervised, or unsupervised. Supervised methods have significantly addressed data imbalance and enhanced detection accuracy and efficiency. For example, the TMG-GAN model described by H. Ding et al. [
9] addresses data imbalance through a multi-generator architecture, classifier design, and cosine similarity loss, outperforming existing algorithms in terms of precision, recall, and F1 score. Semi-supervised methods demand fewer labeled data points compared to their supervised counterparts. A. Hannan et al. [
10] introduce a semi-supervised method based on CVAE. This method innovatively encodes normal traffic and malicious traffic into a bimodal distribution in the latent space and optimizes the bimodal representation of the encoder through semi-supervised learning, thereby improving the detection ability of unknown threats.
Unsupervised methods identify patterns and structures by analyzing unlabeled data, offering stronger generalization capabilities and higher practical applicability compared to the other two categories of methods [
11]. Current unsupervised anomaly detection methods can be primarily categorized into statistical model-based methods, clustering-based methods, and reconstruction-based methods.
In statistical model-based methods, L. Dinh et al. [
12] proposed the RealNVP model, a generative model that employs real-valued non-volume-preserving transformations for density estimation. This model efficiently performs inverse transformations and evaluates the fit of samples to the data distribution by exactly computing the log-likelihood of data points. While RealNVP exhibits strong modeling capabilities, it suffers from complex architecture, high sensitivity to data distributions, and significant computational costs. Zong et al. [
13] developed the DAGMM deep-learning model for anomaly detection, which combines deep autoencoders with Gaussian mixture models (GMM). The model first compresses high-dimensional input data into a low-dimensional latent space and then uses GMM to model the data in this latent space. DAGMM demonstrates significant advantages in nonlinear feature learning and multi-modal distribution modeling, making it particularly suitable for unsupervised anomaly detection in high-dimensional and complex data. However, its performance is influenced by reconstruction errors and GMM hyperparameter settings, requiring continuous adjustment based on data feature distributions in practical applications.
In clustering-based methods, G. Pu et al. [
14] proposed an unsupervised anomaly detection framework combining subspace clustering (SSC) and one-class support vector machine (OCSVM). This framework reduces data complexity through subspace partitioning and leverages the advantages of OCSVM in one-class classification to enhance the detection of anomalous samples. However, the number of subspaces explodes exponentially with increasing feature dimensions, making computational efficiency a key focus for future optimization. Y. Chen [
15] integrated the K-means clustering algorithm with particle swarm optimization (PSO), iteratively optimizing cluster centers and thereby improving the accuracy of data partitioning. This approach outperforms traditional methods in terms of detection accuracy and robustness. Nevertheless, its parameter sensitivity and adaptability to complex scenarios remain primary limitations. Introducing deep-learning methods to strengthen feature representation could enhance the approach’s practical application value.
In reconstruction-based methods, D. Yang et al. [
16] proposed a novel anomaly scoring mechanism that combines the reconstruction loss of autoencoders with the Mahalanobis distance of layer outputs, fully utilizing the feature information from the model’s intermediate layers to capture anomalies. On the UNSW-NB15 dataset, this approach significantly outperforms single-method baselines; however, its generalization capability remains insufficiently validated across diverse datasets. Liao et al. [
17] developed a hybrid unsupervised framework that integrates multiple deep-learning models and employs Mahalanobis distance to compute reconstruction errors, achieving high anomaly detection accuracy. Nevertheless, its computational overhead and redundancy in certain model components require further optimization. Y. Jiang et al. [
18] introduced an anomaly detection method combining VAE and improved K-means clustering. By conducting cluster analysis on samples at the reconstruction threshold boundary, this approach significantly reduces the model’s false alarm rate. However, the manual setting of reconstruction error thresholds and clustering parameters relies on empirical experience, potentially affecting detection performance.
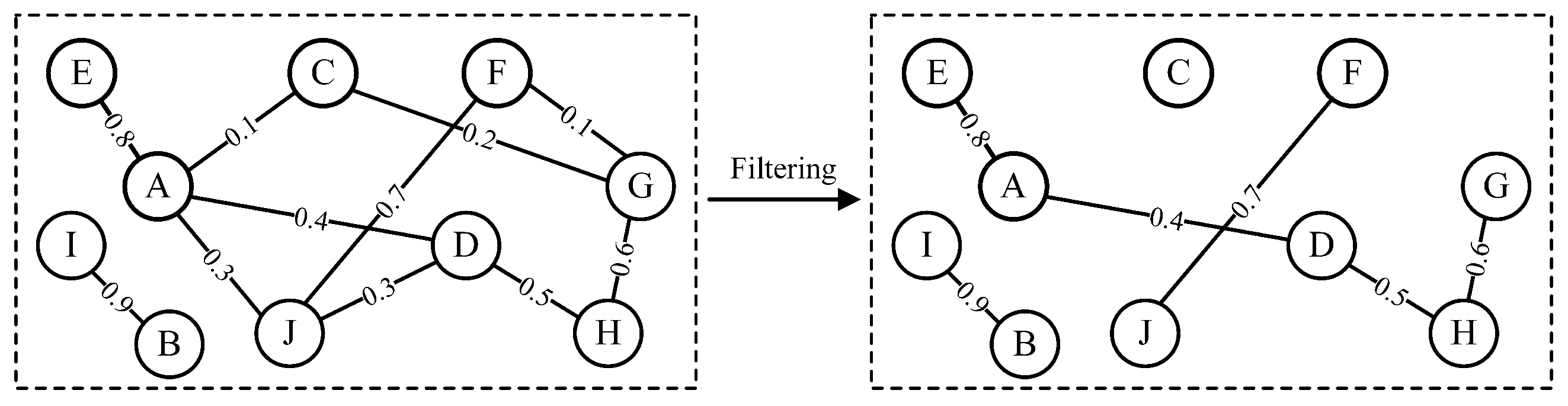
To address the issues of manual setting of cluster numbers and insufficient handling of boundary samples in the above methods, SOVAE automatically generates cluster labels by integrating SOM and incorporates them into the VAE learning process, reducing reliance on manual expertise and strengthening the constraints of the VAE latent space on normal patterns. Furthermore, SOVAE’s dual discriminative metric (reconstruction error and mapping error) offers greater flexibility than a single reconstruction threshold, enhancing robustness in processing boundary samples. Additionally, SOVAE optimizes the input feature space using a feature correlation graph and Louvain algorithm, further improving adaptability to high-dimensional data.
5. Discussion
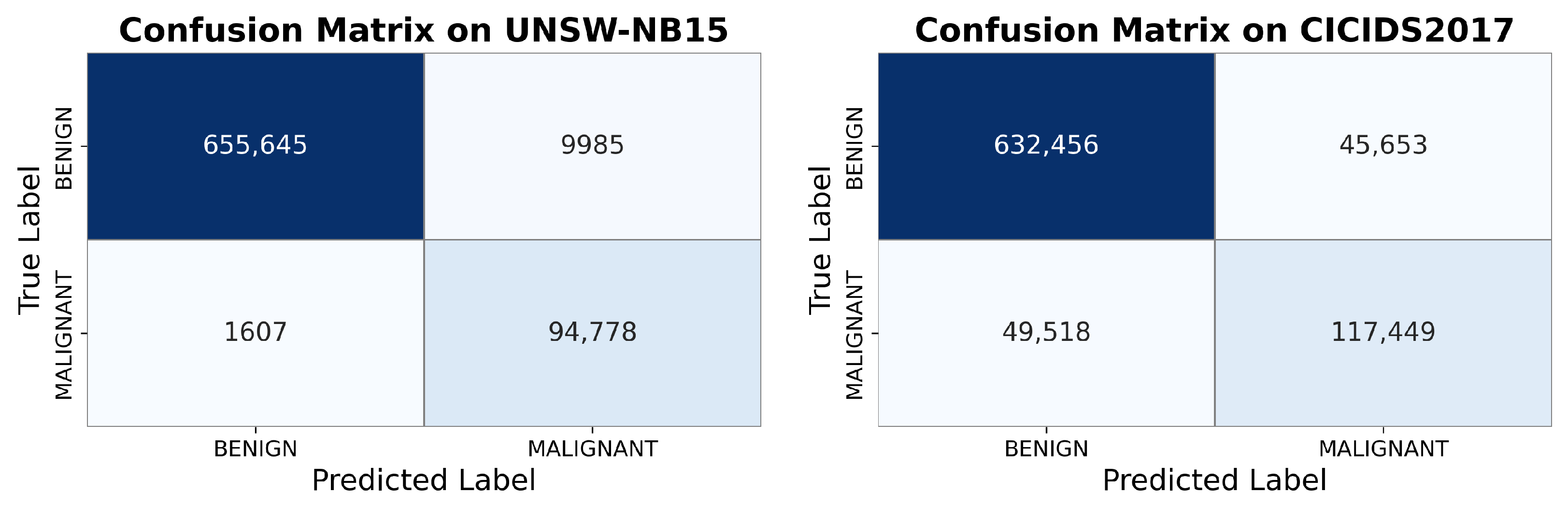
This study proposes an unsupervised network anomaly detection model named SOVAE, based on self-organizing maps (SOM) and variational autoencoders (VAE). The model distinguishes normal and anomalous samples by leveraging the reconstruction error of VAE and the mapping distance of SOM. Experimental results demonstrate that SOVAE achieves F1 scores of 0.983 and 0.875 on the UNSW-NB15 and CICIDS2017 datasets, respectively, outperforming current mainstream unsupervised methods.
The core innovation of SOVAE lies in its feature processing method and model architecture design. Feature selection based on a feature correlation graph significantly improves the clustering quality of SOM; the symmetric encoder-decoder architecture and bidirectional information flow enhance the reconstruction accuracy of normal features and the sensitivity of anomaly discrimination. Ablation experiments further validate the contribution of each component to the overall performance, with results showing that the introduction of feature selection and soft labels significantly enhances the model’s detection capability. However, this study still has the following limitations:
Insufficient adaptability to complex attack patterns: On the CICIDS2017 dataset, due to the high feature overlap between attack traffic and normal traffic and the inclusion of more novel attack patterns, the model’s misdetection rate increased significantly (e.g., the false negative rate reached 29.66%), indicating that its generalization capability to unknown attack types requires improvement.
Sensitivity to data contamination: Experimental results demonstrate that when the proportion of anomalous samples in the training data increases, the model’s performance significantly degrades, indicating that its robustness requires further optimization.
In future research, generative models such as GANs could be introduced to perform data augmentation on overlapping traffic, improving the model’s discriminative ability for complex attack patterns. Additionally, the development of dynamic threshold adjustment mechanisms or ensemble learning frameworks could enhance the model’s robustness in scenarios with data contamination. Overall, SOVAE demonstrates significant potential in the field of unsupervised network anomaly detection. By addressing existing limitations and integrating emerging technologies, this model is poised to play a broader role in dynamic and complex network environments.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}