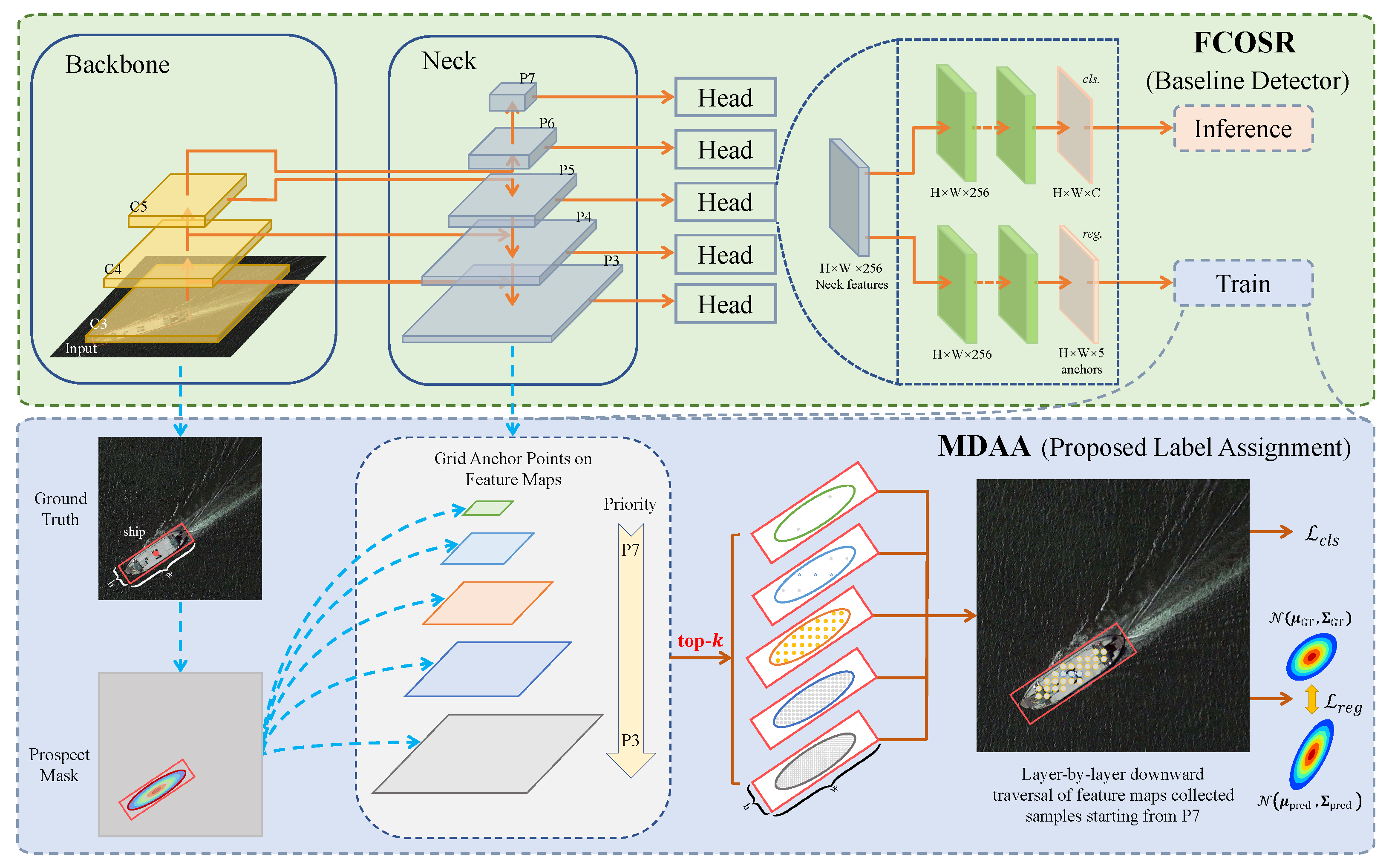
5.3. Ablation Studies
All experiments in this section were conducted using FCOSR as the baseline model, with as the default regression loss function and FCOS LA strategy. Component-wise ablation studies were performed on the UCAS-AOD and HRSC2016 datasets to evaluate the individual effectiveness and joint performance of the proposed MDAA strategy and GEIoU regression loss.
Ablation Studies on the Effectiveness of the Proposed Components. The results in
Table 1 and
Table 2 demonstrate that both the proposed MDAA strategy and GEIoU loss consistently contribute to performance improvements on both datasets. On the UCAS-AOD dataset, the baseline model achieves an mAP(07) of 87.57%, which is partly due to the limited coverage of traditional assignment strategies, leading to the inclusion of low-quality samples during training. The introduction of the MDAA strategy improves mAP(07) by 0.67% to 88.24%, indicating that this strategy effectively performs adaptive sample selection based on object scale, shape, and orientation, thereby enhancing the modeling of key features.
On the HRSC2016 dataset, where ship objects typically exhibit high aspect ratios, the baseline achieves an mAP(07) and mAP(12) of 87.92% and 91.87%, respectively. With MDAA, these metrics increase to 88.75% and 92.34%, respectively, demonstrating the adaptability of MDAA in handling high-aspect-ratio OD tasks.
Furthermore, the experiments confirm the advantages of GEIoU loss in improving regression accuracy. Compared with loss, GEIoU brings mAP(07) improvements of 1.25% and 1.34% on the UCAS-AOD and HRSC2016 datasets, respectively. This improvement is attributed to GEIoU’s ability to jointly model position, scale, and orientation through covariance representation, thereby enhancing regression consistency and mitigating error accumulation caused by parameter decoupling.
When both MDAA and GEIoU loss are applied simultaneously, detection performance is further improved. On UCAS-AOD, the mAP reaches 89.29%, while on HRSC2016, mAP(07) and mAP(12) improve to 89.81% and 94.75%, respectively. These results suggest that the proposed modules exhibit strong complementarity in sample selection and geometric alignment, significantly enhancing the model’s capacity for complex object structure modeling and detection robustness.
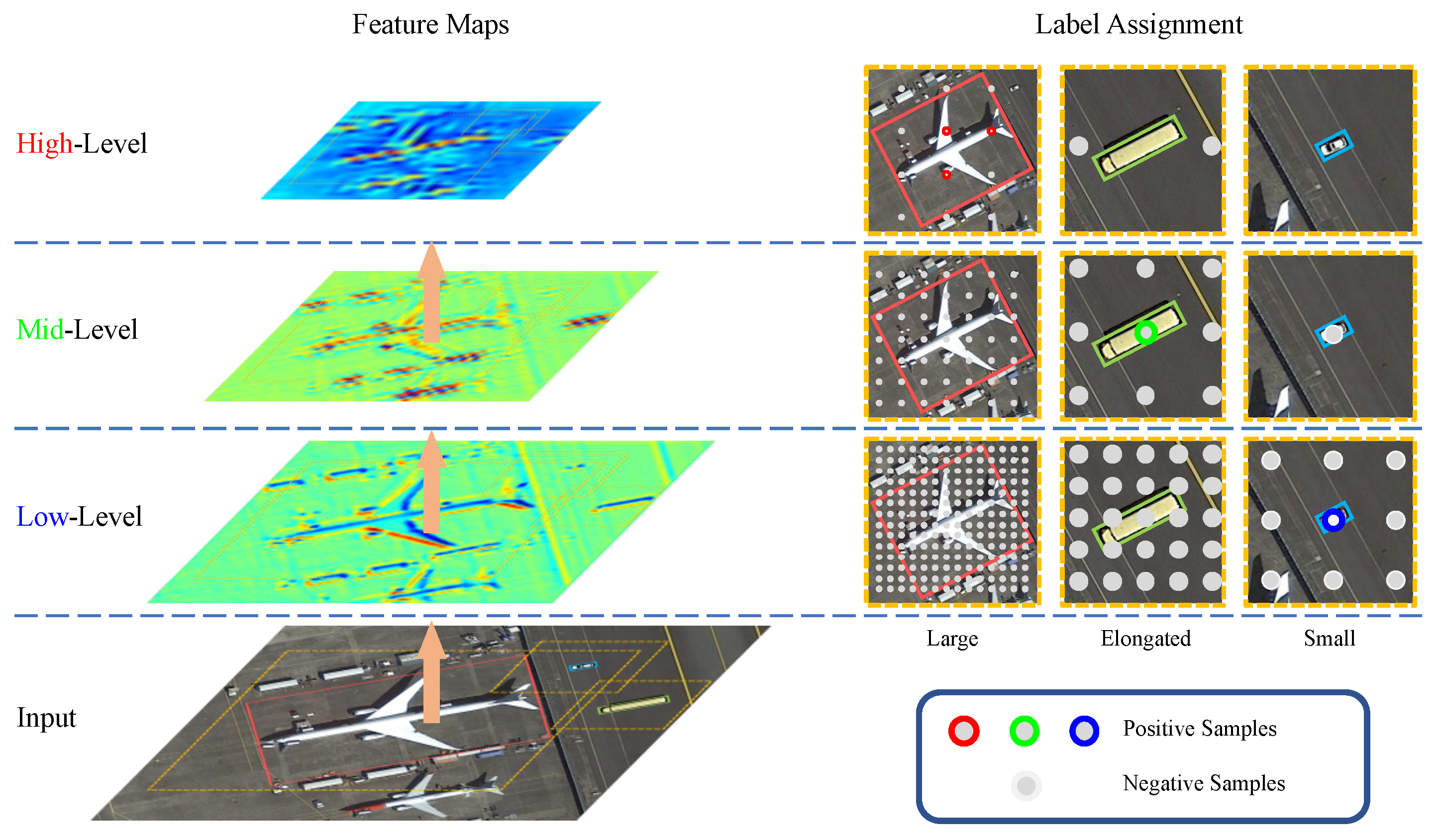
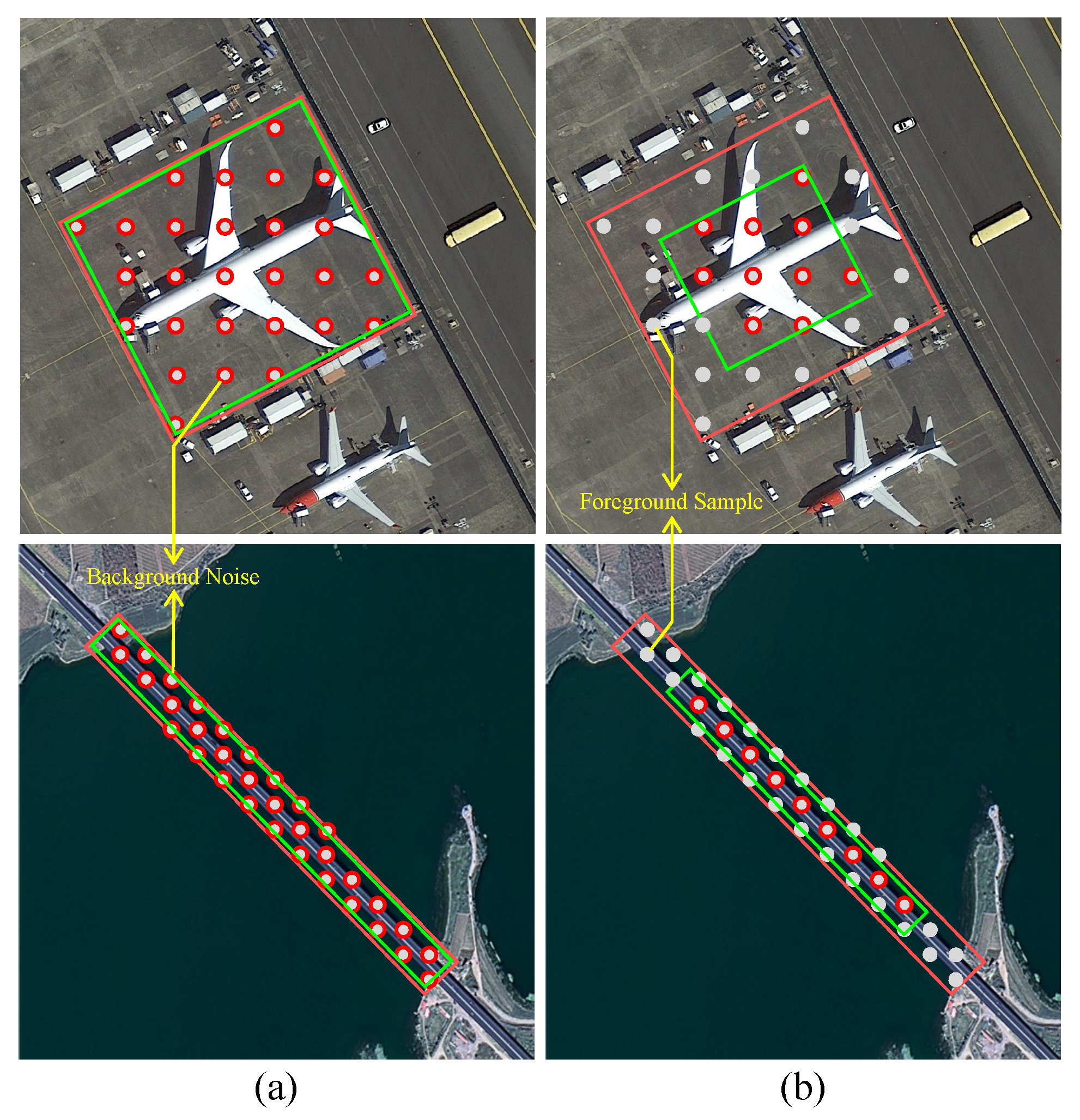
Ablation Studies on the Effectiveness of the Proposed MDAA Strategy. As shown in
Table 3 and
Table 4, the experimental results demonstrate that the MSAA strategy effectively addresses the common challenges of insufficient sampling and imbalanced sample distribution in extreme-scale and high-aspect-ratio object detection (OD) tasks. Compared with the baseline, incorporating MSAA alone yields a 0.25% improvement in mAP on the UCAS-AOD dataset, and increases mAP(07) and mAP(12) by 0.29% and 0.09%, respectively, on the HRSC2016 dataset. These results suggest that MSAA demonstrates strong adaptability and generalization in sample-scale assignment.
Taking the car and airplane categories as examples, the baseline model suffers from limited sample coverage on specific feature levels, making it difficult to capture multi-scale object features effectively. With MSAA, the sample distribution becomes more balanced across feature levels, thereby enhancing the model’s ability to learn objects with varying scales.
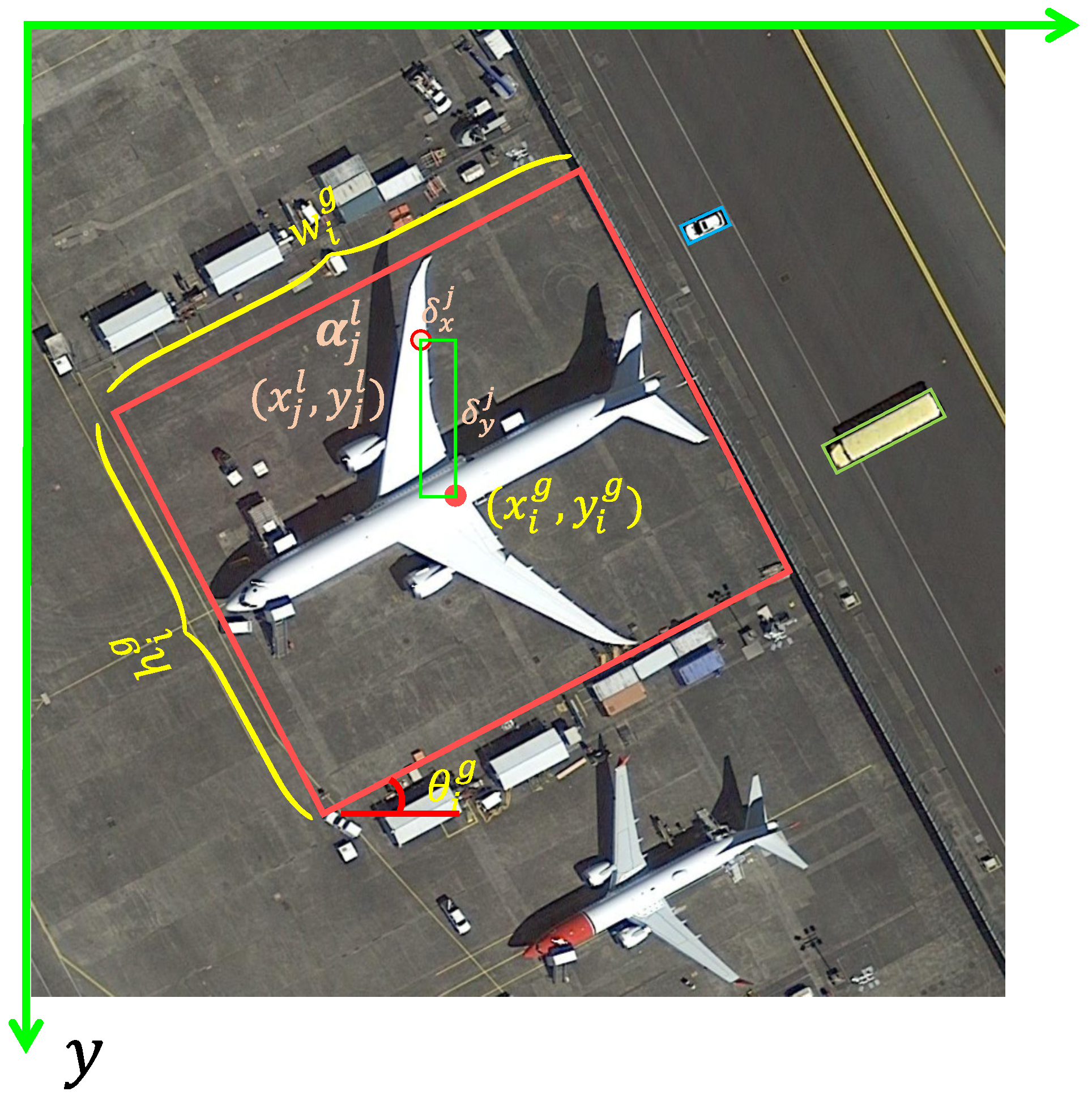
An ablation analysis was conducted on the effectiveness of the proposed SGS strategy. The SGS strategy enhances the structural adaptability of sample selection by constructing a geometry-aware spatial sampling region. Results show that applying SGS alone improves mAP by 0.44% on UCAS-AOD, and increases mAP(07) and mAP(12) by 0.56% and 0.28%, respectively, on HRSC2016. These improvements demonstrate that SGS effectively enhances the model’s capacity to handle variations in object orientation and shape, thereby improving recognition performance on high-aspect-ratio objects.
Furthermore, when MSAA and SGS are used in combination, detection performance is further improved. On the UCAS-AOD dataset, mAP reaches 88.24%, representing a 0.67% gain over the baseline; on HRSC2016, mAP(07) and mAP(12) are improved to 88.75% and 92.34%, respectively. This indicates that SGS reinforces the scale adaptation ability of MSAA at the spatial distribution level, and the joint design of the two modules exhibits strong complementarity, contributing to enhanced detection performance and robustness in complex RS scenarios.
Effectiveness analysis of the GEIoU loss function.
Table 5 and
Table 6 present the performance impact of different regression loss functions on the UCAS-AOD and HRSC2016 datasets, respectively. In the baseline model,
is used for BBox regression. Due to the independent regression of each geometric parameter, this method suffers from offset errors caused by parameter decoupling, resulting in an mAP of 87.57% on the UCAS-AOD dataset and 87.92% (mAP(07)) / 91.87% (mAP(12)) on HRSC2016.
To enhance regression consistency, two distribution-based loss functions—GWD and KLD—were introduced. Both optimize the shape and positional alignment between the predicted and ground-truth boxes through distribution similarity. KLD, with its scale-invariant property, performs slightly better than GWD overall. However, both methods rely on hyperparameters embedded in nonlinear functions, and their sensitivity to dataset-specific parameter tuning limits generalization in cross-dataset scenarios.
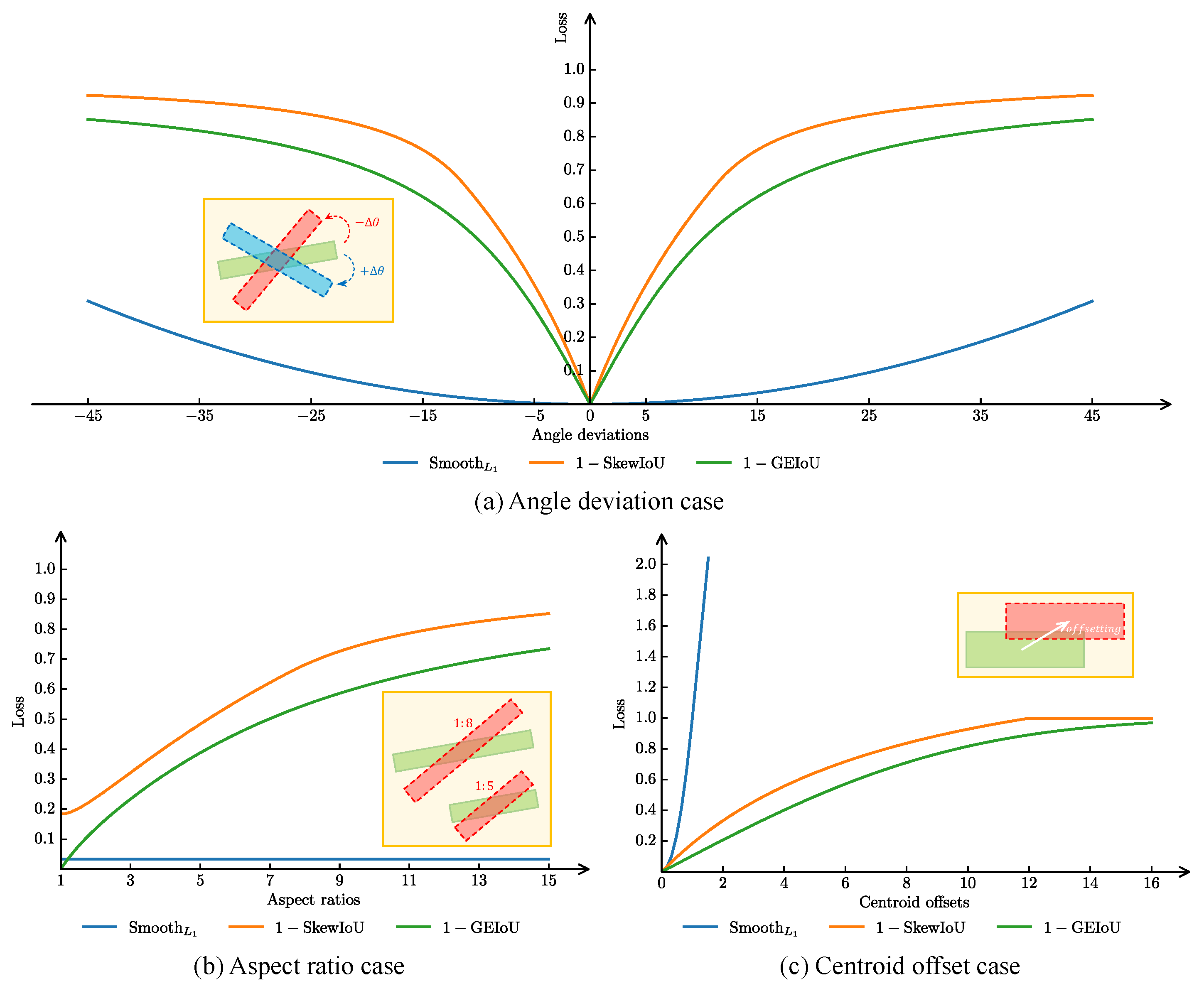
In contrast, the proposed GEIoU loss is designed without reliance on additional hyperparameters, while offering both scale invariance and strong structural alignment. On the UCAS-AOD dataset, GEIoU achieves a 1.25% mAP improvement over the baseline; on HRSC2016, it improves mAP(07) and mAP(12) by 1.34% and 2.04%, respectively. These results demonstrate that GEIoU exhibits strong generalization and robustness across datasets, and effectively aligns the optimization direction of the regression loss with that of the evaluation metric.
Effectiveness analysis of different LA strategies. To evaluate the impact of LA strategies in RSOD, comparative experiments were conducted on the UCAS-AOD and HRSC2016 datasets using FCOSR as the baseline. Apart from the LA strategies, all other settings were kept identical. FCOS’s original strategy, ATSS, SimOTA, and the proposed MDAA were, respectively, substituted. Performance results are shown in
Table 7 and
Table 8.
On the UCAS-AOD dataset, FCOS, ATSS, and SimOTA achieve mAPs of 87.57%, 87.66%, and 88.01%, respectively, while MDAA achieves 88.24%, yielding superior performance across all categories. A similar trend is observed on the HRSC2016 dataset: FCOS achieves 87.92% (mAP(07)) and 91.87% (mAP(12)); ATSS achieves 88.28% and 92.04%; SimOTA reaches 88.67% and 92.26%; all are surpassed by MDAA, which attains 88.75% and 92.34%. These results indicate that MDAA exhibits superior adaptability and LA efficiency in RSOD scenarios.
From the perspective of assignment mechanisms, FCOS treats all pixels within the GT region as positive samples without considering object scale or geometric structure, leading to lower positive sample quality. SimOTA performs reliably in horizontal box detection, but lacks directional modeling in OOD, which limits convergence. ATSS introduces a center-based assignment mechanism, but was originally designed for natural images and is less suited for RS scenes with large-scale variation and dense objects.
In contrast, MDAA incorporates object scale, shape, and orientation, offering enhanced geometric adaptability and positive sample selection during assignment. Its superior performance highlights the importance of geometry-aware assignment mechanisms in RSI, contributing to improved detection accuracy and model robustness.
Rationality analysis of the hyperparameter
k setting. To enhance the structure-aware capability of the sample assignment strategy, a top-
k candidate selection mechanism was introduced during the positive sample screening phase. To investigate the impact of this hyperparameter, a systematic evaluation was conducted on both the UCAS-AOD and HRSC2016 datasets. The results are shown in
Table 9.
On the UCAS-AOD dataset, the model achieved the best performance when , with an mAP of 88.24%. On HRSC2016, the optimal result was obtained when , reaching an mAP(07) of 88.75%. These findings indicate that the proposed mechanism exhibits good adaptability across different RS data structures.
The performance differences can be attributed to variations in object distribution and scale characteristics between the two datasets. In UCAS-AOD, where small objects are densely distributed, a smaller k helps to balance noise control and sample diversity. In contrast, HRSC2016 predominantly features objects with high aspect ratios, where increasing k improves feature coverage near object boundaries.
In general, a small k results in insufficient positive samples, limiting the model’s ability to learn from diverse structures; a large k, on the other hand, introduces more edge or noisy samples, thereby degrading detection accuracy. For example, on UCAS-AOD, mAP increases from 87.68% at to a peak of 88.24% at , but then drops to 87.49% when k increases to 18. A similar trend is observed in HRSC2016, where the best performance is achieved at a moderate k.
In summary, the selection of k should balance “high-quality sample density” and “spatial coverage range.” A well-chosen value improves detection performance, reduces noise interference, and enhances the model’s generalization ability across various object structures, reflecting the practical value and robustness of this selection mechanism in RSOD tasks.
5.4. Comparative Experiments
To further evaluate the overall performance of the proposed method, a comparative study was conducted on the HRSC2016 dataset against several representative OOD methods, with all approaches implemented under a unified RTMDet-R detection framework.
Experimental results (
Table 10) show that the proposed method achieves an mAP(07) of 90.53% and an mAP(12) of 96.24% on the HRSC2016 dataset, outperforming all compared approaches. As illustrated in the visualization results in
Figure 11, object boundaries are accurately regressed with no significant center drift or angular deviation. This performance is attributed to the GEIoU loss function, which uniformly models the geometric parameters of objects, thereby improving the consistency and stability of regression.
In addition, examples indexed 1–5 in the figure demonstrate the accurate detection of objects with various scales and aspect ratios, indicating the effectiveness of the MDAA strategy in adapting to both multi-scale and geometric spatial variations. Notably, in region 8, despite severe occlusion, the detection results remain highly accurate, suggesting that the proposed method maintains robust performance in complex scenes.
In summary, the proposed MDAA-based positive sample selection mechanism and GEIoU loss function collaboratively optimize the two critical components of structural modeling and LA, demonstrating strong competitiveness and generalization capability across multiple benchmark models and high-precision detection scenarios.
As shown in
Table 11, the proposed method achieves an mAP(07) of 90.36% on the UCAS-AOD dataset, outperforming most existing OOD algorithms. This result validates the adaptability of the geometry-aware mechanisms built upon MDAA and GEIoU in multi-object RSI.
Furthermore, the visualized results in
Figure 12 demonstrate strong localization and orientation prediction across diverse scenes:
In curved-road scenes (results 1 and 2), all vehicles exhibit orientations consistent with the lane curvature, indicating the model’s high capacity for orientation alignment.
In dense small-object scenarios (results 3 and 4), such as with clustered vehicles, detection boxes are uniformly distributed without omissions or false positives, reflecting good robustness to scale variation.
In complex background scenes (results 5 and 6), certain aircraft exhibit distinct aerodynamic structures and background texture overlap, yet the model still accurately identifies their boundaries and angles, demonstrating strong generalization in geometric modeling.
In conclusion, the proposed method exhibits reliable detection performance and environmental adaptability across various RSI scenarios. The synergistic effect between the high-quality sample assignment mechanism (MDAA) and the unified regression loss (GEIoU) significantly enhances the model’s stability and detection accuracy in multi-scale, multi-pose object environments.
5.5. Supplementary Experimental Analysis and Extended Validation
Performance of Transformer-based architectures in OOD. In recent years, Transformer-based detection frameworks have demonstrated strong end-to-end modeling capabilities in general OD tasks, with self-attention mechanisms providing enhanced global contextual modeling. To further investigate their applicability in RSOD, the representative Transformer-based method Adaptive Object Detection with Two-stage DETR (AO2-DETR) [
59], which incorporates rotation modeling, was selected for replication and comparison on the HRSC2016 and UCAS-AOD datasets. AO2-DETR is built upon the DEtection TRansformer (DETR) framework [
60] and introduces an angular regression branch to handle arbitrarily OOD.
In the experimental setup, a unified input size of
was used, with consistent training parameters across methods. The evaluation metrics included mAP(07) and mAP(12). The results are presented in
Table 12 and
Table 13.
On the HRSC2016 dataset, AO2-DETR achieves an mAP(12) of 97.47%, demonstrating strong global modeling capability and regression accuracy. However, its mAP(07) is 88.12%, which is lower than that of the proposed method (90.53%), suggesting room for improvement in boundary fitting and angle alignment.
On the UCAS-AOD dataset, AO2-DETR achieves an mAP(07) of 87.79%, with relatively balanced performance on both car and airplane categories, outperforming some traditional CNN-based approaches. Nevertheless, its overall detection performance remains inferior to that of GaussianDet (90.36%), indicating that its end-to-end mechanism has certain limitations in regression accuracy and sample selection, particularly in scenarios with small-scale objects and high-density distributions.
In summary, AO2-DETR demonstrates good structural adaptability and benefits from the end-to-end characteristics of Transformer architectures in RS scenes. However, in terms of the directional perception, structural consistency modeling, and fine-grained detection of densely distributed objects, it still falls short of the overall performance advantages offered by the proposed flexible boundary representation and symmetry-aware optimization mechanisms.
Impact of backbone replacement on model performance. To systematically evaluate the robustness and generalization ability of the proposed method under different backbone architectures, three representative networks—ResNet50, ResNet101, and the lightweight CSPNeXt-L—were selected for comparative experiments on the UCAS-AOD and HRSC2016 RS datasets. All experiments were conducted under identical training configurations, with the ODAA LA mechanism and GEIoU regression loss consistently applied to ensure result comparability.
As shown in
Table 14, the proposed method demonstrates strong performance stability across different backbone architectures. Compared with ResNet50, ResNet101 yields slightly improved results on both datasets, suggesting that enhanced feature extraction contributes positively to detection accuracy. The lightweight CSPNeXt-L backbone, while maintaining computational efficiency, further boosts overall performance, achieving an mAP(12) of 95.28% on the HRSC2016 dataset—the highest among all tested settings.
Despite differences in parameter scale and architectural complexity among the three backbones, the core components of GaussianDet—including FBBox modeling, the GEIoU loss function, and the ODAA assignment strategy—exhibit strong structural adaptability. These components effectively support high-precision OOD tasks across varied network architectures, further validating the method’s practicality, generalization capability, and robustness in real-world applications.
Impact of resolution variation on detection performance. To assess the adaptability of the proposed method under varying input image scales, experiments were conducted on the UCAS-AOD and HRSC2016 datasets using test samples at a low resolution (), the original resolution (), and a high resolution (). All experiments were conducted under a consistent RTMDet-R detection framework, with identical training configurations and model parameters to ensure result comparability.
As shown in
Table 15, detection performance drops significantly under the low-resolution setting (
), primarily due to the loss of image detail, particularly the degradation in boundary feature representation for small objects, resulting in reduced localization accuracy. Under high-resolution conditions (
), mAP improves on both datasets, reflecting enhanced boundary fitting capability—especially notable for large-scale objects. However, the increase in resolution leads to a considerable rise in computational cost, with inference speed dropping from the default 13.3 FPS to 7.6 FPS, indicating that the performance gains come at the expense of significant efficiency loss.
In summary, under the default resolution setting (), the proposed method achieves a well-balanced trade-off between accuracy and inference speed. These results confirm the robustness and stability of the FBBox representation and GEIoU loss function across multi-scale scenarios, demonstrating high practical value for deployment.
Theoretical and visual comparison with existing Gaussian-based loss functions. To further validate the effectiveness of the GEIoU loss in OOD tasks, a comprehensive comparison was conducted with two mainstream Gaussian-based loss functions—GWD and KLD—from both theoretical and visual perspectives.
At the theoretical level, GEIoU is constructed based on the Bhattacharyya coefficient and Hellinger distance, inherently providing scale invariance and independence from additional hyperparameters. In contrast, GWD—based on the Gaussian Wasserstein distance between covariance matrices—is relatively sensitive to scale variations and struggles to maintain consistent loss trends across varying object sizes. Although KLD improves stability through modeling distributional differences via the Kullback–Leibler Divergence, it relies on exponential scaling factors, with parameter tuning dependent on empirical heuristics, thus limiting its generalization in convergence behavior.
In terms of numerical stability, GEIoU adopts a closed-form expression, ensuring stable gradient output even under significant variations in object shape or scale. This characteristic is especially critical in OOD, helping to improve both training efficiency and regression accuracy.
At the visual level, as shown in
Figure 13, GEIoU outperforms GWD and KLD in terms of rotation alignment, boundary consistency, and detection capability for dense small objects. Specifically, in ship detection tasks on the HRSC2016 dataset, GEIoU more accurately fits object orientations and boundaries. In the UCAS-AOD dataset, it also exhibits superior object separation and pose-awareness capabilities.
Model limitations and bad-case analysis. Although GaussianDet demonstrates excellent performance across various RSOD tasks, certain limitations remain in complex scenarios. Typical issues include degraded detection performance in low-contrast maritime backgrounds, and missed or false detections in small-object remote scenes.
Specifically, as shown in
Figure 14, under conditions with low visibility or minimal contrast between objects and background textures, weakened boundary features may lead to localization shifts and angular deviations. In small OD, the limited size and inconspicuous texture of objects make it difficult for the model to extract discriminative features, resulting in missed detections or false alarms. These observations suggest that the current model still has room for improvement under extreme conditions such as low signal-to-noise perception and ultra-small object modeling. Future work may consider integrating multi-scale feature fusion and local fine-grained enhancement mechanisms to further improve the robustness and generalization capacity of the model in complex RS environments.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}