


Semi-Proximal ADMM for Primal and Dual Robust Low-Rank Matrix Restoration from Corrupted Observations

Abstract
1. Introduction
2. Preliminaries
2.1. Notation
2.2. Basic Concepts
2.3. Review of Some Types of ADMM
3. Algorithm and Convergence Analysis
3.1. Semi-Proximal ADMM for Primal Problem (6)
| Algorithm 1: sPADMM |
Initialization: Input , , and . Given constants , , , . Set . While “not converge” Do 1. Compute via (17) for fixed and ; 2. Compute via (18) for fixed and ; 3. Update via (19) for fixed and ; 4. Let . End While Output: Solution of the problem (14). |
3.2. Semi-Proximal ADMM for Dual Problem of (14)
| Algorithm 2: sPDADMM |
Initialization: Input , and . Given constants , , , . Set . While “not converge” Do (1) Compute via (28) for fixed and ; (2) Compute via (29) for fixed and ; (3) Update via (30) for fixed and ; (4) Let . End While Output: Solution of the problem (25). |
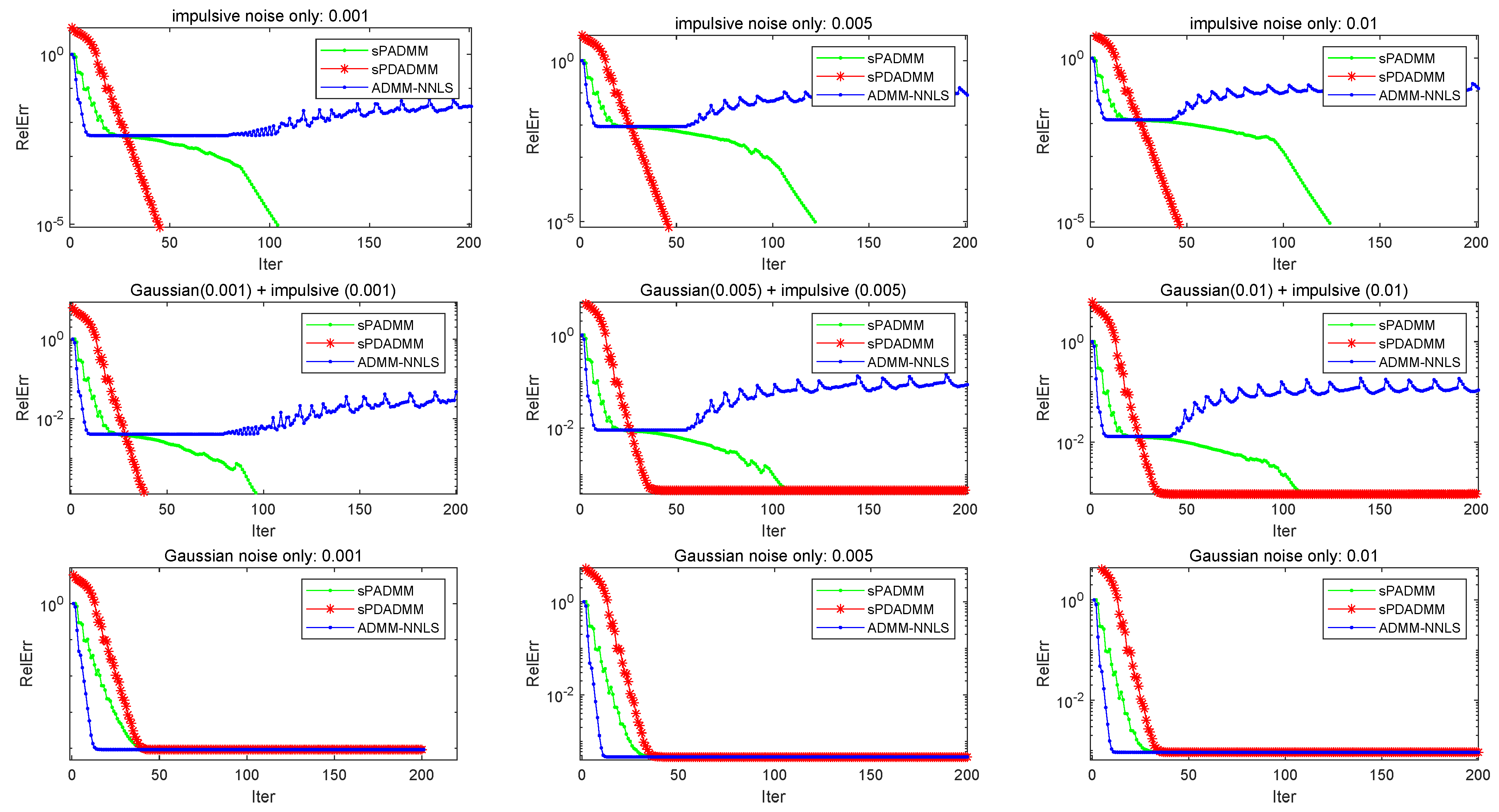
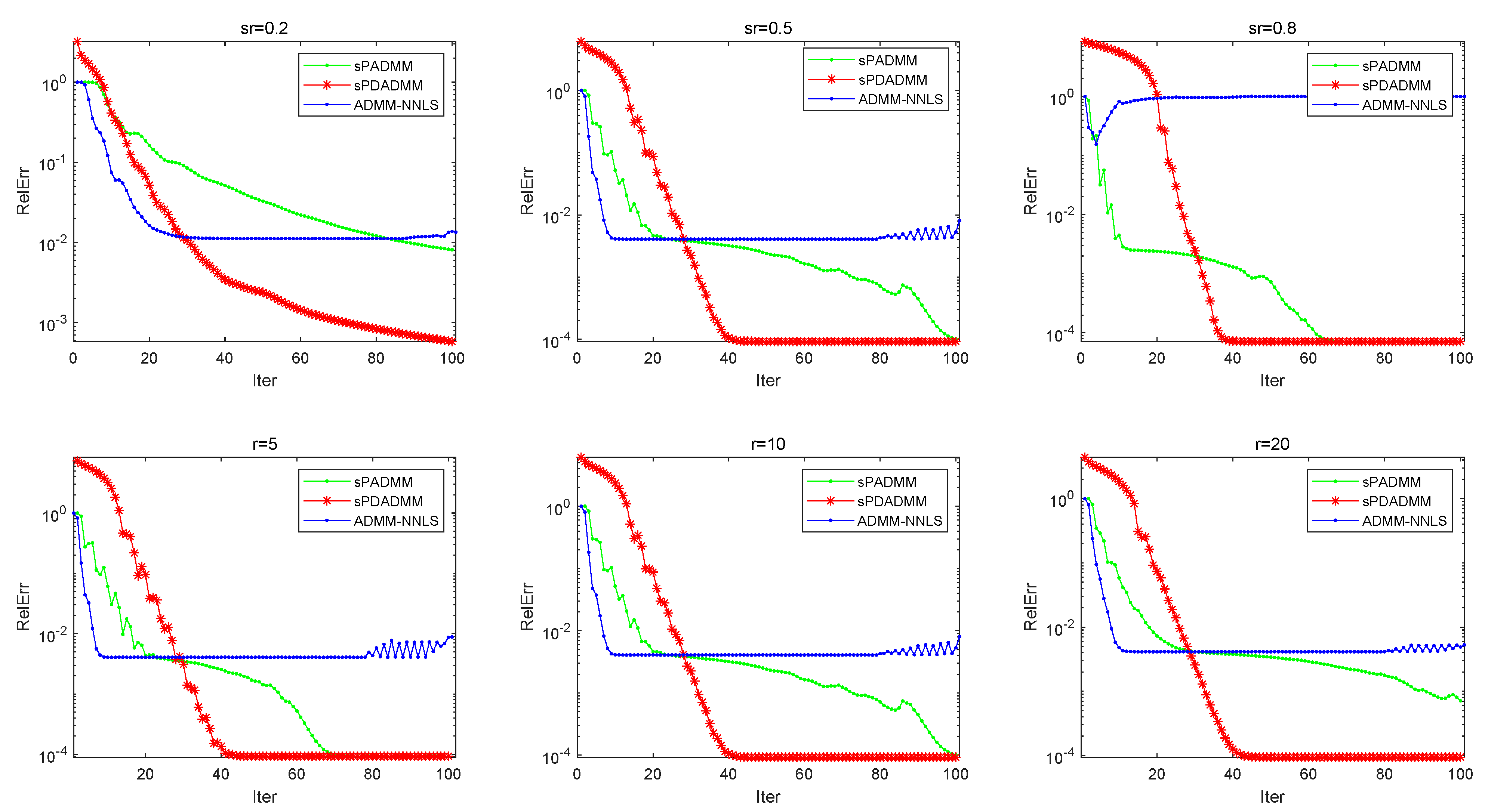
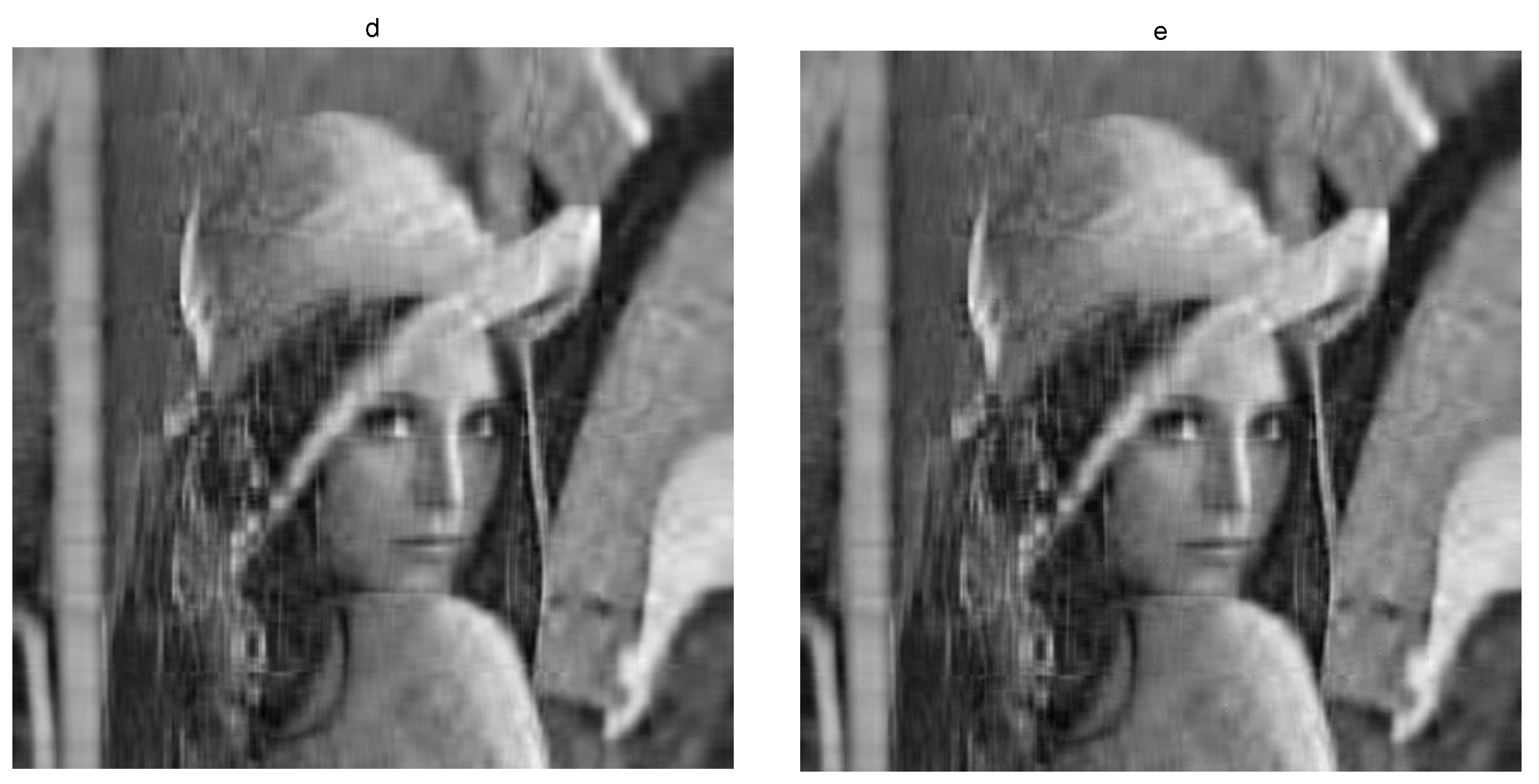
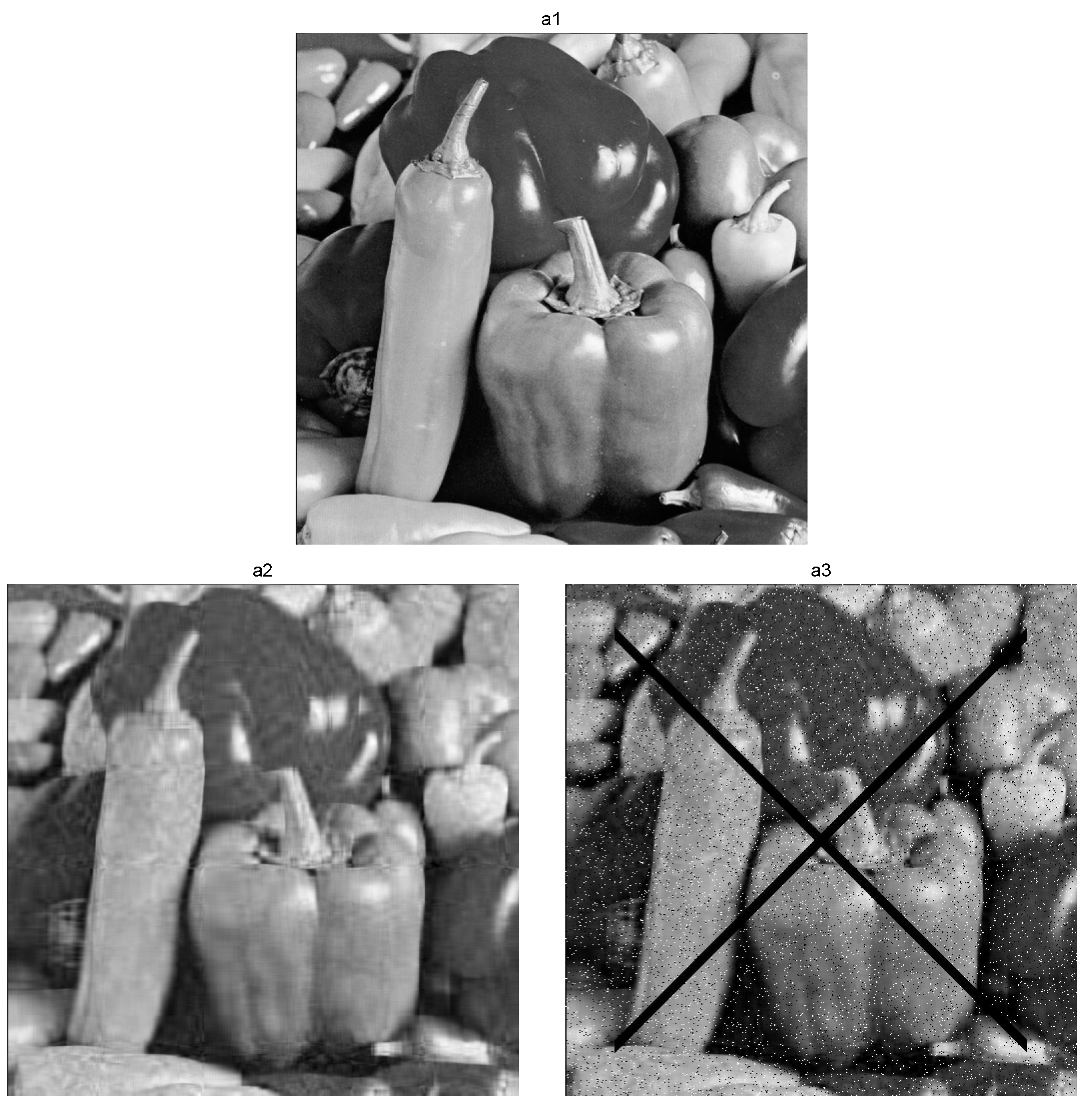
4. Numerical Experiments
4.1. Matrix Completion Problems
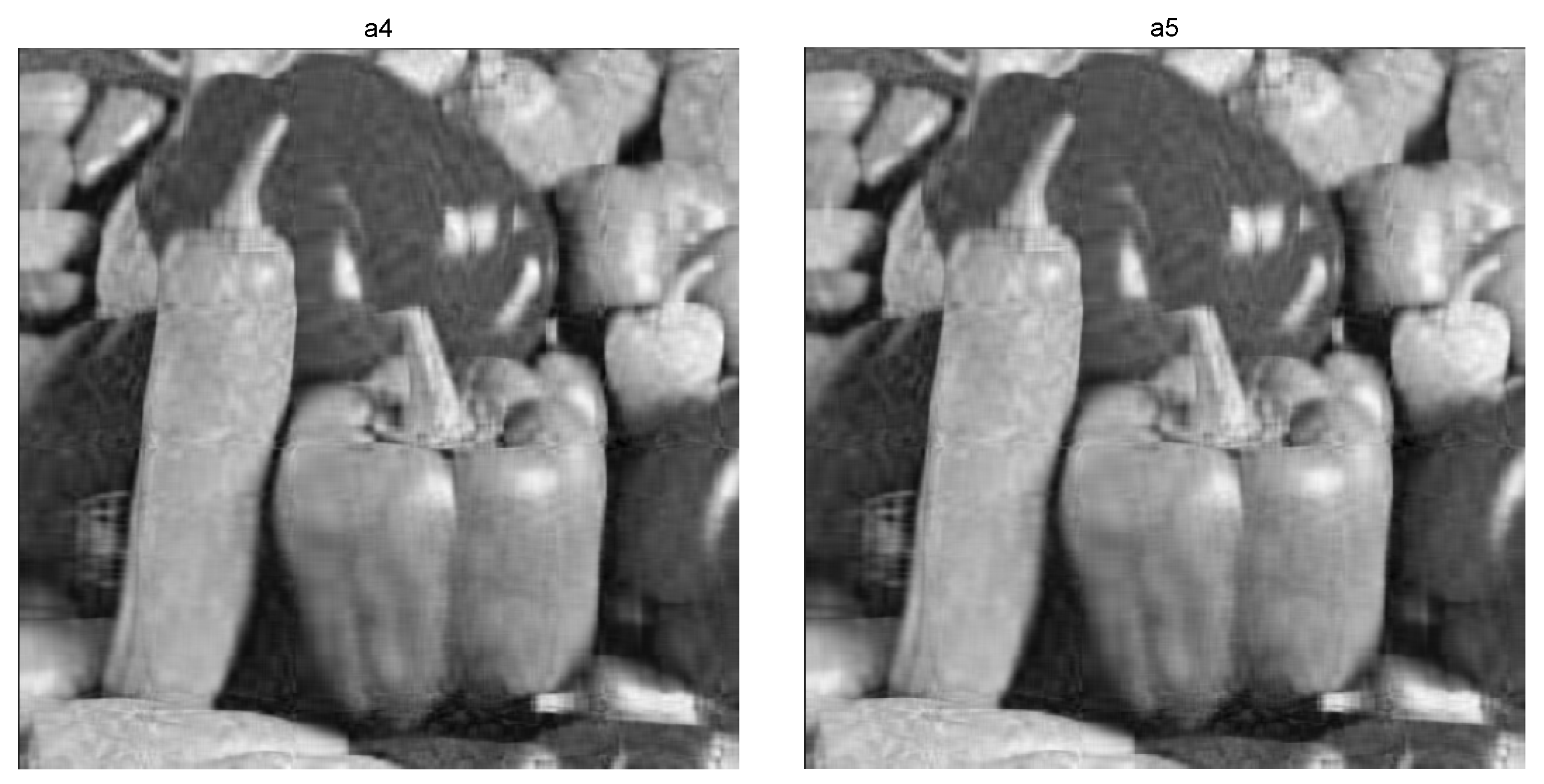
4.2. Nuclear Norm Minimization with Fidelity Term
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Srebro, N. Learning with Matrix Factorizations. Ph.D. Thesis, MIT Computer Science & Artificial Intelligence Laboratory, Cambridge, MA, USA, 2004. [Google Scholar]
- Mohan, K.; Fazel, M. Reweighted nuclear norm minimization with application to system identification. In Proceedings of the American Control Conference (ACC), Baltimore, MD, USA, 30 June–2 July 2010; pp. 2953–2959. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM (JACM) 2011, 58, 11. [Google Scholar] [CrossRef]
- Elsener, A.; van de Geer, S. Robust low-rank matrix estimation. Ann. Stat. 2018, 46, 3481–3509. [Google Scholar] [CrossRef]
- Fazel, M.; Hindi, H.; Boyd, S. Rank minimization and applications in system theory. In Proceedings of the American Control Conference, Boston, MA, USA, 30 June–2 July 2004; Volume 4, pp. 3273–3278. [Google Scholar]
- Jiang, W.; Wu, D.; Dong, W.; Ding, J.; Ye, Z.; Zeng, P.; Gao, Y. Design and validation of a non-parasitic 2R1T parallel hand-held prostate biopsy robot with remote center of motion. J. Mech. Robot. 2024, 16, 051009. [Google Scholar] [CrossRef]
- Ma, S.; Goldfarb, D.; Chen, L. Fixed point and Bregman iterative methods for matrix rank minimization. Math. Program. 2011, 128, 321–353. [Google Scholar] [CrossRef]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef]
- Candès, E.J.; Tao, T. The power of convex relaxation: Near-optimal matrix completion. IEEE Trans. Inf. Theory 2010, 56, 2053–2080. [Google Scholar] [CrossRef]
- Keshavan, R.H.; Montanari, A.; Oh, S. Matrix completion from a few entries. IEEE Trans. Inf. Theory 2010, 56, 2980–2998. [Google Scholar] [CrossRef]
- Sturm, J.F. Using SeDuMi 1.02, a MATLAB toolbox for optimization over symmetric cones. Optim. Methods Softw. 1999, 11, 625–653. [Google Scholar] [CrossRef]
- Tütüncü, R.H.; Toh, K.C.; Todd, M.J. Solving semidefinite-quadratic-linear programs using SDPT3. Math. Program. 2003, 95, 189–217. [Google Scholar] [CrossRef]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Toh, K.C.; Yun, S. An accelerated proximal gradient algorithm for nuclear norm regularized linear least squares problems. Pac. J. Optim. 2010, 6, 615–640. [Google Scholar]
- Liu, Y.J.; Sun, D.; Toh, K.C. An implementable proximal point algorithmic framework for nuclear norm minimization. Math. Program. 2012, 133, 399–436. [Google Scholar] [CrossRef]
- Xiao, Y.H.; Jin, Z.F. An alternating direction method for linear-constrained matrix nuclear norm minimization. Numer. Linear Algebra Appl. 2012, 19, 541–554. [Google Scholar] [CrossRef]
- Yang, J.; Yuan, X. Linearized augmented Lagrangian and alternating direction methods for nuclear norm minimization. Math. Comput. 2013, 82, 301–329. [Google Scholar] [CrossRef]
- Ding, Y.; Xiao, Y. Symmetric Gauss–Seidel technique-based alternating direction methods of multipliers for transform invariant low-rank textures problem. J. Math. Imaging Vis. 2018, 60, 1220–1230. [Google Scholar] [CrossRef]
- Micchelli, C.A.; Shen, L.; Xu, Y.; Zeng, X. Proximity algorithms for the L1/TV image denoising model. Adv. Comput. Math. 2013, 38, 401–426. [Google Scholar] [CrossRef]
- Alliney, S. A property of the minimum vectors of a regularizing functional defined by means of the absolute norm. IEEE Trans. Signal Process. 1997, 45, 913–917. [Google Scholar] [CrossRef]
- Udell, M.; Horn, C.; Zadeh, R.; Boyd, S. Generalized low rank models. Found. Trends® Mach. Learn. 2016, 9, 1–118. [Google Scholar] [CrossRef]
- Zhao, L.; Babu, P.; Palomar, D.P. Efficient algorithms on robust low-rank matrix completion against outliers. IEEE Trans. Signal Process. 2016, 64, 4767–4780. [Google Scholar] [CrossRef]
- Jiang, X.; Zhong, Z.; Liu, X.; So, H.C. Robust matrix completion via alternating projection. IEEE Signal Process. Lett. 2017, 24, 579–583. [Google Scholar] [CrossRef]
- Guennec, A.; Aujol, J.; Traonmilin, Y. Adaptive Parameter Selection for Gradient-Sparse + Low Patch-Rank Recovery: Application to Image Decomposition. HAL Id: Hal-04207313. 2024. Available online: https://hal.science/hal-04207313/document (accessed on 17 March 2023).
- Liang, W. Alternating Direction Method of Multipliers for Robust Low Rank Matrix Completion. Ph.D. Thesis, Beijing Jiaotong University, Beijing, China, 2020. [Google Scholar]
- Wong, R.K.W.; Lee, T.C.M. Matrix completion with noisy entries and outliers. J. Mach. Learn. Res. 2017, 18, 5404–5428. [Google Scholar]
- Abreu, E.; Lightstone, M.; Mitra, S.K.; Arakawa, K. A new efficient approach for the removal of impulse noise from highly corrupted images. IEEE Trans. Image Process. 1996, 5, 1012–1025. [Google Scholar] [CrossRef] [PubMed]
- Ji, H.; Liu, C.; Shen, Z.; Xu, Y. Robust video denoising using low rank matrix completion. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1791–1798. [Google Scholar]
- Wang, D.; Jin, Z.F.; Shang, Y. A penalty decomposition method for nuclear norm minimization with l1 norm fidelity term. Evol. Equ. Control Theory 2019, 8, 695–708. [Google Scholar] [CrossRef]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 1970. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends® Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhu, H.; Wu, S.Y. Primal and dual alternating direction algorithms for l1-l1-norm minimization problems in compressive sensing. Comput. Optim. Appl. 2013, 54, 441–459. [Google Scholar] [CrossRef]
- Jiang, K.; Sun, D.; Toh, K.C. A partial proximal point algorithm for nuclear norm regularized matrix least squares problems. Math. Program. Comput. 2014, 6, 281–325. [Google Scholar] [CrossRef]
- Glowinski, R.; Marroco, A. Sur l’approximation, paréléments finis d’ordre un, et la résolution, par pénalisation-dualité d’une classe de problémes de Dirichlet non linéaires. ESAIM Math. Model. Numer.-Anal.-Modél. Math. Anal. Numér. 1975, 9, 41–76. [Google Scholar]
- Gabay, D.; Mercier, B. A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 1976, 2, 17–40. [Google Scholar] [CrossRef]
- Eckstein, J. Some Saddle-function splitting methods for convex programming. Optim. Methods Softw. 1994, 4, 75–83. [Google Scholar] [CrossRef]
- Fazel, M.; Pong, T.K.; Sun, D.; Tseng, P. Hankel matrix rank minimization with applications to system identification and realization. SIAM J. Matrix Anal. Appl. 2013, 34, 946–977. [Google Scholar] [CrossRef]
- Jin, Z.F.; Wan, Z.; Zhao, X.; Xiao, Y. A Penalty Decomposition Method for Rank Minimization Problem with Affine Constraints. Appl. Math. Model. 2015, 39, 4859–4870. [Google Scholar] [CrossRef]
- Larsen, R.M. PROPACK-Software for Large and Sparse SVD Calculations. 2004. Available online: http://sun.stanford.edu/~rmunk/PROPACK/ (accessed on 17 March 2004).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| sPADMM | sPDADMM | ||||||
|---|---|---|---|---|---|---|---|
| p/dr | Iter | Time | RelErr | Iter | Time | RelErr | |
| (100, 5) | 5.13 | 117 | 0.77 | 85 | 0.20 | ||
| (200, 5) | 10.13 | 85 | 0.77 | 43 | 0.39 | ||
| (400, 5) | 20.13 | 91 | 3.19 | 50 | 2.22 | ||
| (600, 5) | 30.13 | 91 | 7.88 | 50 | 7.18 | ||
| (800, 5) | 40.13 | 88 | 16.41 | 52 | 16.06 | ||
| (1000, 5) | 50.13 | 90 | 34.09 | 54 | 31.68 | ||
| (1200, 10) | 30.13 | 35 | 39.91 | 74 | 112.76 | ||
| (1400, 10) | 35.13 | 34 | 61.55 | 41 | 62.03 | ||
| (1600, 10) | 45.13 | 34 | 67.11 | 41 | 150.57 | ||
| (1800, 10) | 50.13 | 34 | 100.97 | 40 | 235.03 | ||
| (2000, 10) | 50.13 | 34 | 135.99 | 41 | 316.22 | ||
| sPADMM | sPDADMM | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| p/dr | q | Iter | Time | RelErr | Iter | Time | RelErr | ||
| (500, 10) | 15.15 | 0.1 | 0.00 | 200 | 55.28 | 67 | 13.33 | ||
| (500, 10) | 15.15 | 0.05 | 0.00 | 200 | 87.26 | 62 | 11.90 | ||
| (500, 10) | 15.15 | 0.01 | 0.00 | 122 | 13.02 | 56 | 10.04 | ||
| (500, 10) | 15.15 | 0.005 | 0.00 | 111 | 13.01 | 55 | 9.57 | ||
| (500, 10) | 15.15 | 0.001 | 0.00 | 104 | 11.41 | 55 | 9.64 | ||
| (500, 10) | 15.15 | 0.001 | 0.001 | 200 | 23.85 | 200 | 42.50 | ||
| (500, 10) | 15.15 | 0.005 | 0.005 | 200 | 26.52 | 200 | 35.01 | ||
| (500, 10) | 15.15 | 0.01 | 0.01 | 200 | 21.54 | 200 | 37.50 | ||
| (500, 10) | 15.15 | 0.00 | 0.01 | 200 | 45.33 | 200 | 69.90 | ||
| (500, 10) | 15.15 | 0.00 | 0.00 | 54 | 5.03 | 55 | 11.12 | ||
| sPADMM | sPDADMM | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| sr | q | Iter | Time | RelErr | Iter | Time | RelErr | ||
| (500, 5) | 0.3 | 0.1 | 0.00 | 200 | 96.72 | 200 | 56.37 | ||
| (500, 5) | 0.5 | 0.1 | 0.00 | 200 | 94.05 | 56 | 13.05 | ||
| (500, 5) | 0.8 | 0.1 | 0.00 | 101 | 17.14 | 25 | 5.11 | ||
| (500, 10) | 0.3 | 0.1 | 0.00 | 200 | 72.28 | 200 | 45.17 | ||
| (500, 10) | 0.5 | 0.1 | 0.00 | 200 | 55.28 | 67 | 13.33 | ||
| (500, 10) | 0.8 | 0.1 | 0.00 | 156 | 121.12 | 27 | 6.29 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, W.; Shang, Y.; Jin, Z.; Fan, Y. Semi-Proximal ADMM for Primal and Dual Robust Low-Rank Matrix Restoration from Corrupted Observations. Symmetry 2024, 16, 303. https://doi.org/10.3390/sym16030303
Ding W, Shang Y, Jin Z, Fan Y. Semi-Proximal ADMM for Primal and Dual Robust Low-Rank Matrix Restoration from Corrupted Observations. Symmetry. 2024; 16(3):303. https://doi.org/10.3390/sym16030303
Chicago/Turabian StyleDing, Weiwei, Youlin Shang, Zhengfen Jin, and Yibao Fan. 2024. "Semi-Proximal ADMM for Primal and Dual Robust Low-Rank Matrix Restoration from Corrupted Observations" Symmetry 16, no. 3: 303. https://doi.org/10.3390/sym16030303
APA StyleDing, W., Shang, Y., Jin, Z., & Fan, Y. (2024). Semi-Proximal ADMM for Primal and Dual Robust Low-Rank Matrix Restoration from Corrupted Observations. Symmetry, 16(3), 303. https://doi.org/10.3390/sym16030303