
Uncertainly Analysis of Prior Distribution in Accelerated Degradation Testing Bayesian Evaluation Method Based on Deviance Information Criterion

Abstract
1. Introduction
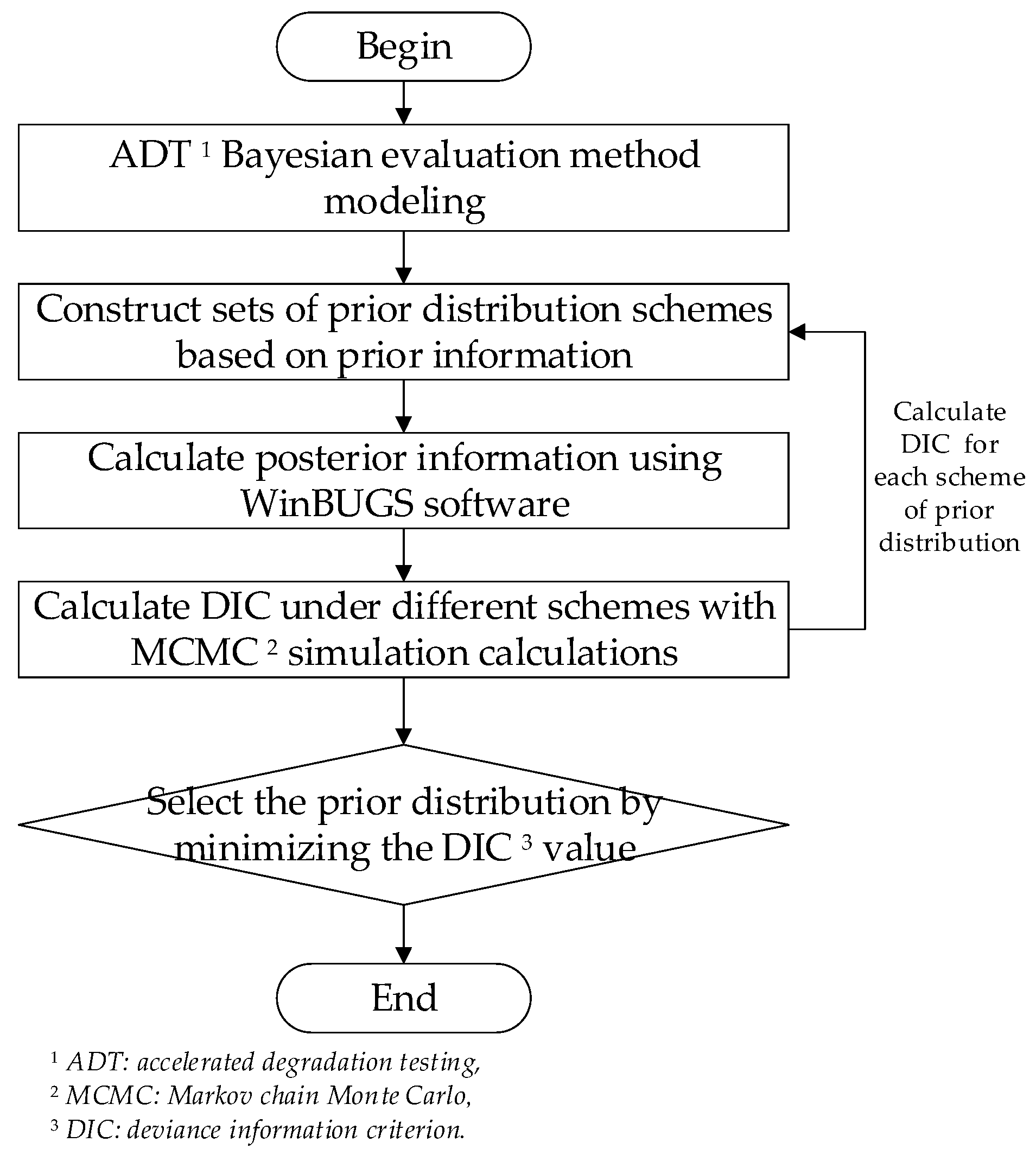
2. Modeling of ADT Bayesian Evaluation
2.1. Modeling of Accelerated Degradation Processes
2.2. ADT Bayesian Evaluation Model
3. Uncertainty Analysis of Prior Distributions
3.1. Principles for Constructing Prior Distributions
3.2. Robustness Analysis of Prior Distributions for the ADT Bayesian Method
3.3. Criteria for Prior Distribution Selection Based on DIC
4. An Illustrative Simulation Case
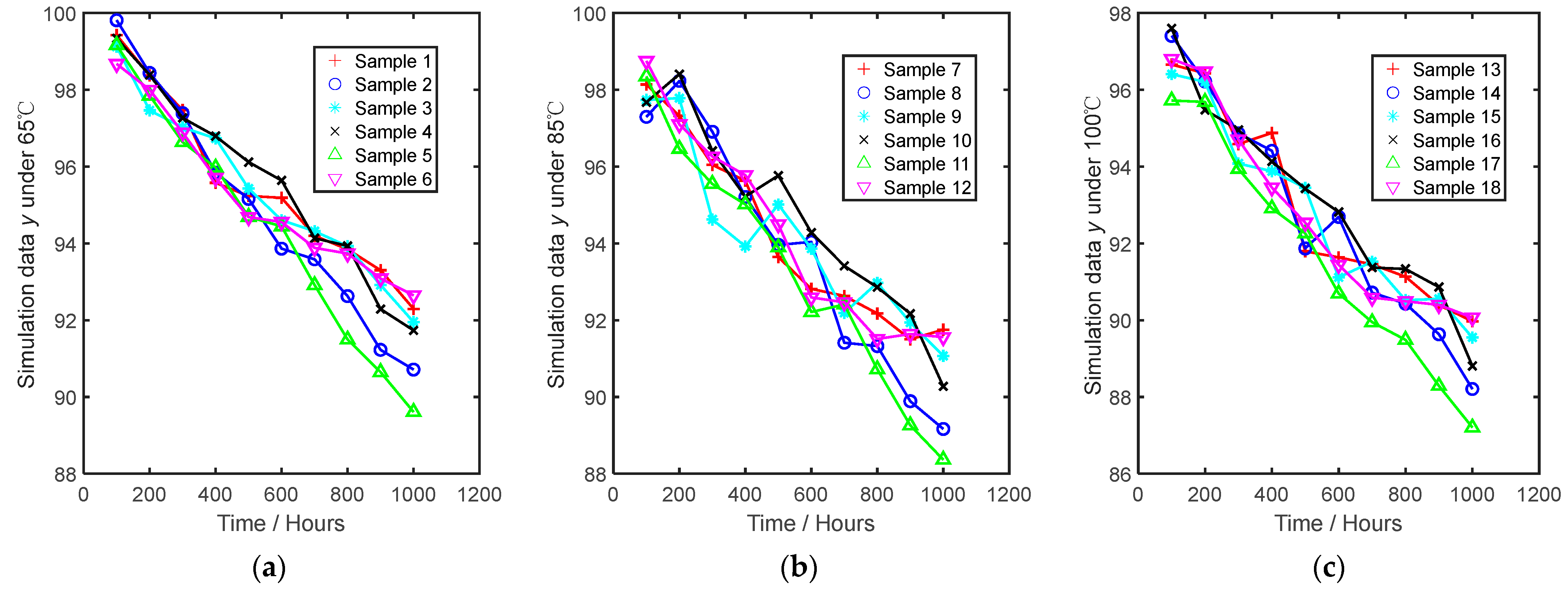
4.1. Simulation Data Declaration
4.2. Construct Sets of Prior Distributions
4.3. Comparison of Prior and Posterior Distributions
- (1)
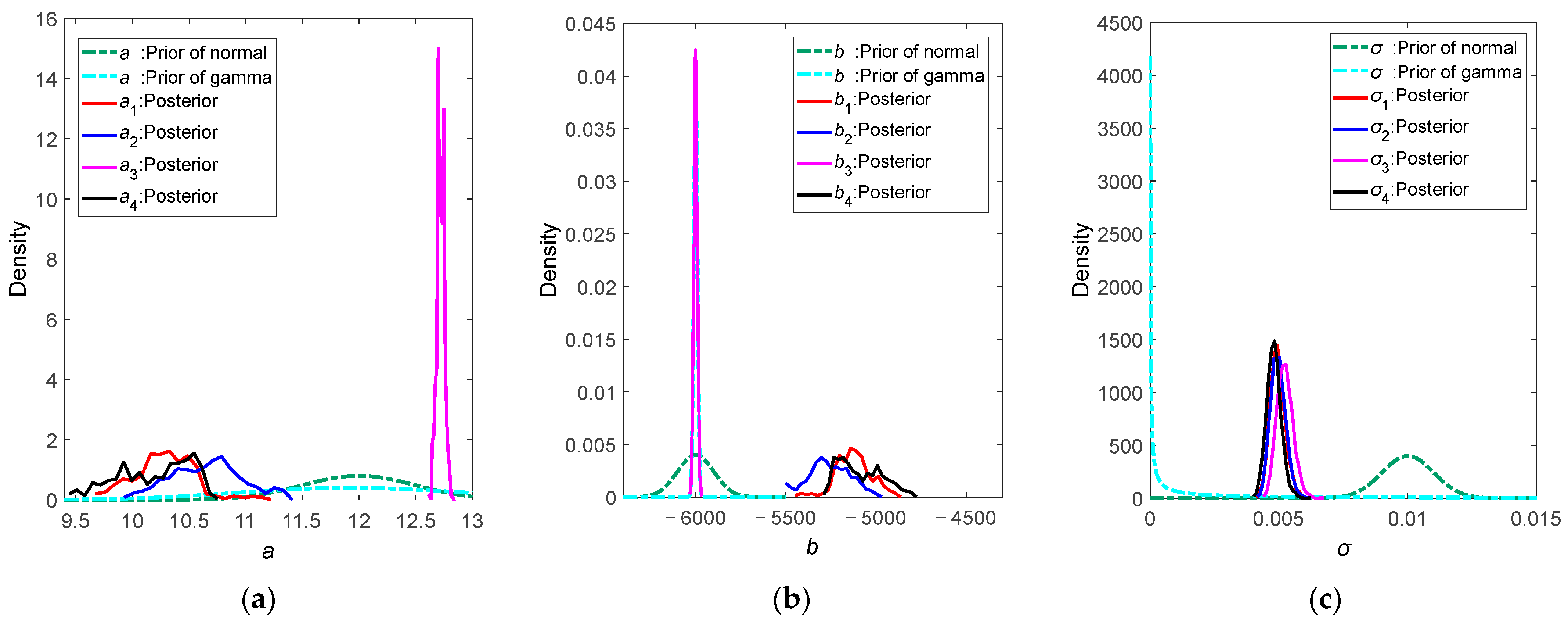
- From the comparison graphs, it is obvious that there is a difference between the prior distribution and the posterior distribution. This result is consistent with Bayesian theory, which means that by adjusting the prior distribution based on the sample data, a posterior distribution can be obtained. However, the form of posterior distributions is different from each other, which also indicates that the prior distribution settings do have an impact on ADT Bayesian evaluation results.
- (2)
- Under Π1, the posterior distributions of a and b are divided into two categories: for πi(θ), i = 1, 2, 4, the posterior distributions of a and b are adjusted by the sample information normally, but posterior distributions do not exhibit obvious distribution characteristics; for π3(θ), when prior parameter b follows a gamma distribution, the prior and posterior distributions of b are almost identical, without the expected adjustment in the posterior distribution, which in turn leads to an unexpected posterior distribution of a.
- (3)
- Under Π2, both posterior distributions of a and b fluctuate around the original simulated hypothetical values. Compared to Π1, setting non-informative prior distributions has a significant impact on the posterior distributions of a and b. Additionally, whether non-informative prior distributions are chosen between a and b will affect the posterior distribution of the other parameter.
- (4)
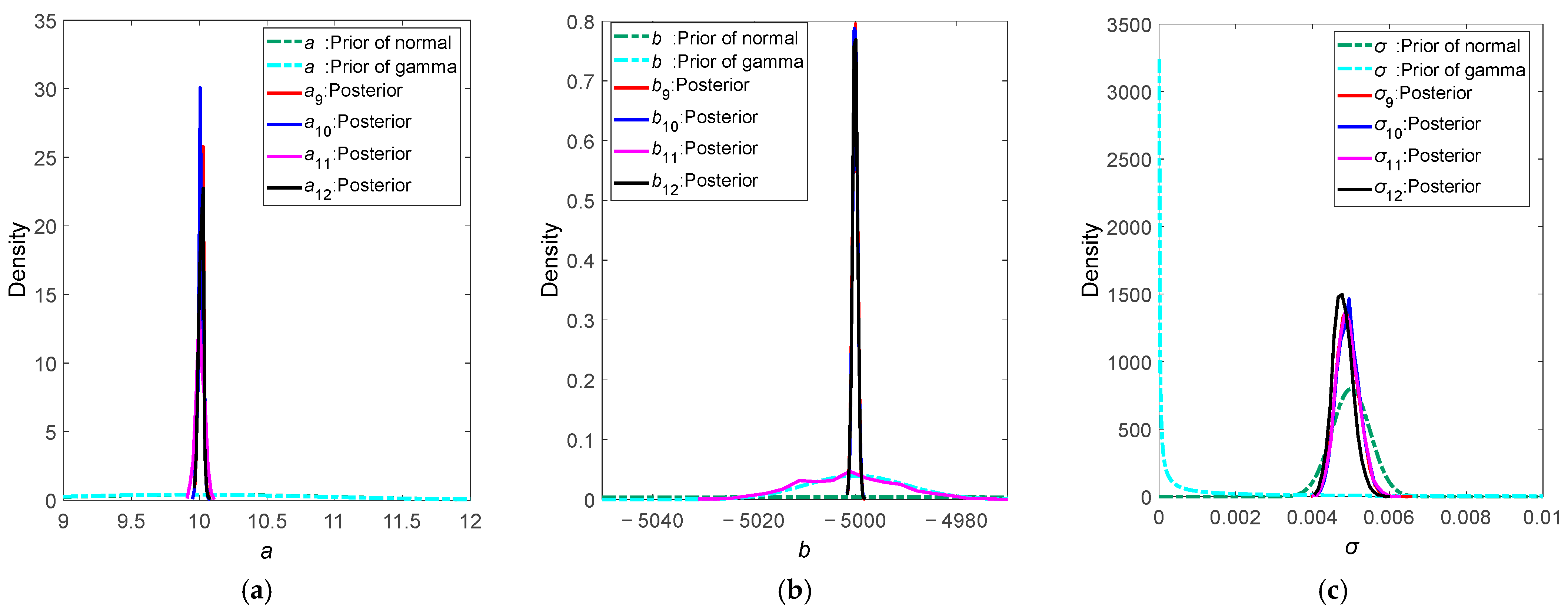
- Under Π3, the posterior distributions of a and b exhibit more noticeable distribution characteristics, with less fluctuation. However, similar to π3(θ), the prior and posterior distributions of parameter b under π11(θ) are almost identical.
- (5)
- The common feature of π3(θ) and π11(θ) is that the prior parameter b is assigned a gamma distribution. It can be seen from the figure that under the gamma prior distribution, the prior data for parameter b is highly concentrated. But the construction of prior distributions should have sufficient support for prior information. An overconcentrated prior distribution may not be conducive to posterior estimation [8]. Since parameter b represents the coefficient of stress level in the Arrhenius acceleration model, when the prior distribution of b is highly concentrated, it may lead to insufficient adjustment capability of small sample data, thereby affecting the calculation of the posterior distribution for a.
- (6)
- Under all prior distributions πi(θ), σ exhibits noticeable distribution characteristics with high consistency, indicating that the choice of different prior distributions has little impact on the posterior distribution of σ.
- (7)
- According to the posterior data points, Table 3 lists the mean, standard deviation (std), 2.5th percentile, and 97.5th percentile of the posterior parameters under different prior distributions in Π1, Π2, and Π3 after convergence of the iterations, for the purpose of comparative analysis. Combining comparison graphs of prior and posterior distributions, it can be concluded as follows:
- (1)
- Under Π1, for πi(θ|y), i = 1, 2, 4, mean(a) ≈ 10 and mean(b) ≈ −5000, which are close to the values of simulation assumptions. However, for π3(θ|y), mean(a) ≈ 12.7 and mean(b) ≈ −6000, showing a significant deviation from the simulated values.
- (2)
- In Π2, the posterior means of a and b are close to the simulated values, and std(a) is in the range of 0.3 to 0.6, and std(b) is in the range of 100 to 250, which shows a clear trend of larger standard deviations compared to those of the posterior distribution in Π1. It can be concluded that under non-informative prior distributions, the posterior parameters are not easily converging and exhibit greater fluctuations in this simulation case.
- (3)
- For the posterior means under Π3, mean(a) ≈ 10 and mean(b) ≈ −5000, with a standard deviation significantly smaller than the posterior parameter standard deviations under Π1 and Π2, making the results more accurate and closer to the simulated hypothesis values.
- (4)
- Under all prior distributions, the mean of the parameter σ is around 0.005, with a standard deviation of around 0.0003. The 2.5th and 97.5th percentile values are also very close. It can be seen that the different settings of prior distributions have a minor impact on the parameter σ, which is mainly adjusted through the sample data.
- (5)
- The choice of prior distribution for b has a noticeable impact on the posterior distribution. In π3(θ) and π11(θ), due to the setting of the gamma distribution for b, the posterior distribution’s mean and variance of b are almost identical to the set prior distribution. In the case of π11(θ), although the posterior mean of b is very close to the simulated hypothesis value, its variance still differs significantly from the variances of other posterior distributions under Π3.
- (6)
- Under Π2, when all three parameters a, b, and σ are assigned non-informative prior distributions, the posterior distribution’s mean achieves results close to the simulated hypothesis condition. This indicates that under non-informative prior distributions, the Bayesian model can effectively find posterior parameters that better match the sample data, but the downside is that the posterior data fluctuates significantly.
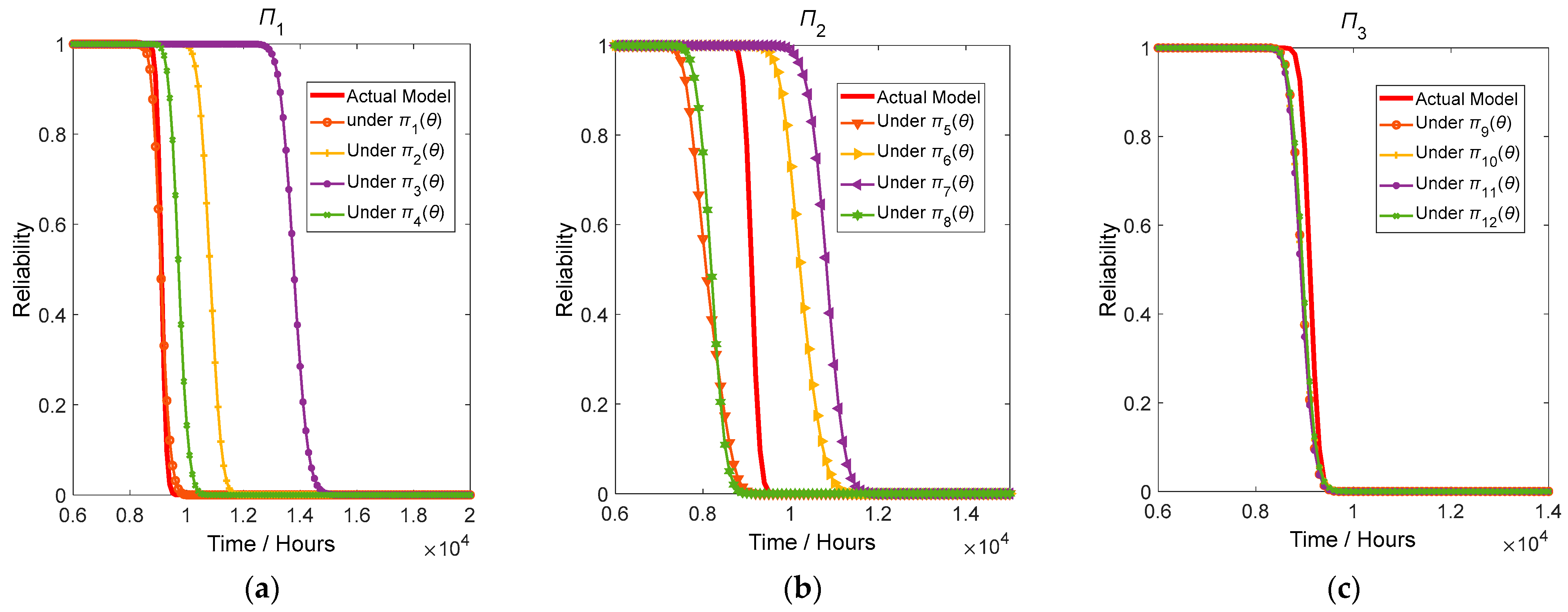
4.4. Robustness Analysis of Evaluation Results
- (1)
- Reliability curves under different prior distributions in Π1 and Π2 have certain differences, even significant disparities, while under different prior distributions in Π3, they are relatively consistent.
- (2)
- The reliability curve under π1(θ) is quite close to the correct reliability curve. In π1(θ), a and b both use a normal prior distribution, while σ uses a non-negative gamma distribution, which corresponds well to the nature of σ representing the diffusion coefficient of the degradation process. In this setting of prior distribution combination, the reliability curve obtained through the posterior distribution adjusted from the sample data are very accurate. However, the reliability curves under other prior distributions in Π1 deviate from the correct reliability curve.
- (3)
- In Π2, reliability curves under different prior distributions lie on both sides of the correct reliability curve, showing a certain deviation from each other. Although using non-informative prior distributions, compared to Π1, it still produces results that are close to the correct reliability curve. Therefore, in the absence of explicit prior information, using non-informative prior distributions is not a terribly bad choice for constructing a prior distribution.
- (4)
- Comparing the reliability curves under π1(θ) with other distributions under Π2, it indicates that when conducting ADT Bayesian evaluation with the correct prior distribution model, prior distributions with biased information will still yield better assessment results than non-informative prior distributions.
- (5)
- Under Π3, the reliability curves of all prior distributions are highly consistent and very close to the true curve. This is mainly due to the fact that the posterior distribution of a, b, and σ under Π3 is quite consistent and close to the simulated values, with very little fluctuation. This means that when using prior distributions with precise information, the sample data reinforces the prior information, resulting in a smaller variance of the posterior distribution and obtaining a fairly accurate reliability evaluation result.
4.5. Prior Distribution Analysis Based on DIC Value
- (1)
- Different prior distribution sets exhibit similarity in DIC values: under Π1, the DIC values are in the range of 200 to 400; under Π2, the DIC values show significant fluctuations, ranging from 300 to 900; under Π3, the DIC values are highly concentrated, ranging from 120 to 150.
- (2)
- According to the principle of selecting prior distributions based on DIC, which states that a smaller DIC value indicates better model fitting [35]. The performance of DIC values under prior distribution sets allows us to conclude the following ranking: accurate prior information distribution > biased prior information distribution > non-informative prior distribution. Similar conclusions can be found in reference [38]. This indicates that DIC can effectively screen the quality of prior distributions.
- (3)
- The DIC value of π1(θ) is the smallest in Π1, and the reliability result of π1(θ) is also the best in Π1, correspondingly. Additionally, the issue of significant posterior distribution bias caused by the selection of gamma distribution as the prior distribution for b is also reflected in the DIC values, with the DIC value of π3(θ) being larger than that of other prior distributions.
- (4)
- The DIC values under Π2 are generally large and exhibit significant fluctuations, indicating that non-informative prior distributions generally yield larger DIC values and are not the optimal choice for prior distributions.
- (5)
- The relatively smaller DIC values under Π3 indicate that having accurate prior information is significantly beneficial in selecting prior distributions for ADT Bayesian evaluation.
- (6)
- It is worth noting that the DIC can serve as a guideline for selecting prior distributions, but it is not an absolute rule. This is because in conducting ADT Bayesian evaluation, there may not always be prior information available, or it may not be certain that the prior information obtained matches the true models. Therefore, when using the DIC as a guideline for selecting prior distributions, judgment based on the actual situation is still necessary.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, F.; Liu, L.; Li, X.; Liao, H. Stochastic modeling and analysis of multiple nonlinear accelerated degradation processes through information fusion. Sensors 2016, 16, 1242. [Google Scholar] [CrossRef]
- Wang, L.; Pan, R.; Li, X.; Jiang, T. A Bayesian reliability evaluation method with integrated accelerated degradation testing and field information. Reliab. Eng. Syst. Saf. 2013, 112, 38–47. [Google Scholar] [CrossRef]
- Prakash, G. A Bayesian approach to degradation modeling and reliability assessment of rolling element bearing. Commun. Stat.-Theory Methods 2021, 50, 5453–5474. [Google Scholar] [CrossRef]
- Guo, J.; Li, Y.F.; Peng, W.; Huang, H.Z. Bayesian information fusion method for reliability analysis with failure-time data and degradation data. Qual. Reliab. Eng. Int. 2022, 38, 1944–1956. [Google Scholar] [CrossRef]
- Fan, T.-H.; Dong, Y.-S.; Peng, C.-Y. A Complete Bayesian Degradation Analysis Based on Inverse Gaussian Processes. IEEE Trans. Reliab. 2023, 1–13. [Google Scholar] [CrossRef]
- Kass, R.E.; Wasserman, L. The selection of prior distributions by formal rules. J. Am. Stat. Assoc. 1996, 91, 1343–1370. [Google Scholar] [CrossRef]
- Zou, T.; Dang, W.; Zhang, G.; Liu, K.; Li, P. Prior Distribution Selection Criterion in Accelerated Degradation Testing Bayesian Optimization Design Based on Bayes Factors. In Proceedings of the 2017 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Shanghai, China, 16–18 August 2017; pp. 694–698. [Google Scholar]
- Ferguson, T.S. A Bayesian analysis of some nonparametric problems. Ann. Stat. 1973, 1, 209–230. [Google Scholar] [CrossRef]
- Jeffreys, H. The Theory of Probability; OuP Oxford: Oxford, UK, 1998. [Google Scholar]
- Sun, D.; Berger, J.O. Reference priors with partial information. Biometrika 1998, 85, 55–71. [Google Scholar] [CrossRef]
- Tibshirani, R. Noninformative priors for one parameter of many. Biometrika 1989, 76, 604–608. [Google Scholar] [CrossRef]
- Sinha, P.; Bansal, A.K. Bayesian optimization analysis with ML-II ϵ-contaminated prior. J. Appl. Stat. 2008, 35, 203–211. [Google Scholar] [CrossRef]
- Handley, W.; Millea, M. Maximum-entropy priors with derived parameters in a specified distribution. Entropy 2019, 21, 272. [Google Scholar] [CrossRef]
- Soofi, E.S. Capturing the intangible concept of information. J. Am. Stat. Assoc. 1994, 89, 1243–1254. [Google Scholar] [CrossRef]
- Lindley, D.V.; Smith, A.F. Bayes estimates for the linear model. J. R. Stat. Soc. Ser. B Stat. Methodol. 1972, 34, 1–18. [Google Scholar] [CrossRef]
- Zou, T.-J.; Li, X.-Y.; Li, M.-J. Impact analysis of prior distributions on ADT Bayesian optimization design based on DIC. In Proceedings of the 2015 Annual Reliability and Maintainability Symposium (RAMS), Palm Harbor, FL, USA, 26–29 January 2015; pp. 1–6. [Google Scholar]
- Chipman, H. Prior distributions for Bayesian analysis of screening experiments. In Screening: Methods for Experimentation in Industry, Drug Discovery, and Genetics; Springer: Berlin/Heidelberg, Germany, 2006; pp. 236–267. [Google Scholar]
- Bayarri, M.; Berger, J.O.; Jang, W.; Ray, S.; Pericchi, L.R.; Visser, I. Prior-based Bayesian information criterion. Stat. Theory Relat. Fields 2019, 3, 2–13. [Google Scholar] [CrossRef]
- Villa, C.; Walker, S. An objective Bayesian criterion to determine model prior probabilities. Scand. J. Stat. 2015, 42, 947–966. [Google Scholar] [CrossRef]
- Liu, C.C.; Aitkin, M. Bayes factors: Prior sensitivity and model generalizability. J. Math. Psychol. 2008, 52, 362–375. [Google Scholar] [CrossRef]
- Liu, L.; Li, X.; Sun, F.; Wang, N. A general accelerated degradation model based on the Wiener process. Materials 2016, 9, 981. [Google Scholar] [CrossRef] [PubMed]
- Tsai, C.-C.; Tseng, S.-T.; Balakrishnan, N. Mis-specification analyses of gamma and Wiener degradation processes. J. Stat. Plan. Inference 2011, 141, 3725–3735. [Google Scholar] [CrossRef]
- Park, C.; Padgett, W. Accelerated degradation models for failure based on geometric Brownian motion and gamma processes. Lifetime Data Anal. 2005, 11, 511–527. [Google Scholar] [CrossRef] [PubMed]
- Pan, Z.; Balakrishnan*, N. Multiple-steps step-stress accelerated degradation modeling based on Wiener and gamma processes. Commun. Stat.-Simul. Comput. 2010, 39, 1384–1402. [Google Scholar] [CrossRef]
- Nelson, W. Analysis of accelerated life test data-part I: The arrhenius model and graphical methods. IEEE Trans. Electr. Insul. 1971, EI-6, 165–181. [Google Scholar] [CrossRef]
- Box, G.E.; Tiao, G.C. Bayesian Inference in Statistical Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Li, X.; Hu, Y.; Sun, F.; Kang, R. A Bayesian optimal design for sequential accelerated degradation testing. Entropy 2017, 19, 325. [Google Scholar] [CrossRef]
- Ntzoufras, I. Bayesian Modeling Using WinBUGS; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 698. [Google Scholar]
- Lykou, A.; Ntzoufras, I. WinBUGS: A tutorial. Wiley Interdiscip. Rev. Comput. Stat. 2011, 3, 385–396. [Google Scholar] [CrossRef]
- Wang, X.; Wang, B.X.; Wu, W.; Hong, Y. Reliability analysis for accelerated degradation data based on the Wiener process with random effects. Qual. Reliab. Eng. Int. 2020, 36, 1969–1981. [Google Scholar] [CrossRef]
- Ye, Z.-S.; Chen, N. The inverse Gaussian process as a degradation model. Technometrics 2014, 56, 302–311. [Google Scholar] [CrossRef]
- Nguyen-Trang, T.; Vo-Van, T. A new approach for determining the prior probabilities in the classification problem by Bayesian method. Adv. Data Anal. Classif. 2017, 11, 629–643. [Google Scholar] [CrossRef]
- Parkinson, A.; Sorensen, C.; Pourhassan, N. A General Approach for Robust Optimal Design. J. Mech. Des. 1993, 115, 74–80. [Google Scholar] [CrossRef]
- Hafez, E.H.; Riad, F.H.; Mubarak, S.A.; Mohamed, M.S. Study on Lindley distribution accelerated life tests: Application and numerical simulation. Symmetry 2020, 12, 2080. [Google Scholar] [CrossRef]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; Van Der Linde, A. Bayesian measures of model complexity and fit. J. R. Stat. Soc. Ser. B Stat. Methodol. 2002, 64, 583–639. [Google Scholar] [CrossRef]
- Ward, E.J. A review and comparison of four commonly used Bayesian and maximum likelihood model selection tools. Ecol. Model. 2008, 211, 1–10. [Google Scholar] [CrossRef]
- Berg, A.; Meyer, R.; Yu, J. Deviance information criterion for comparing stochastic volatility models. J. Bus. Econ. Stat. 2004, 22, 107–120. [Google Scholar] [CrossRef]
- Grzenda, W. Informative Versus Non-Informative Prior Distributions and their Impact on the Accuracy of Bayesian Inference. Stat. Transition. New Ser. 2016, 17, 763–780. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Values |
|---|---|
| Degradation process | Wiener |
| Accelerated model | Arrhenius |
| Simulation parameter θ | a = 10, b = −5000, σ = 0.005 |
| Stress levels (Temperature/°C) | 65, 85, 100 |
| Normal stress level (Temperature/°C) | 45 |
| Sample size under each stress level | 6, 6, 6 |
| Monitor times | 10, 10, 10 |
| Failure threshold | 30 |
| Πk | πi(θ) | a | b | σ |
|---|---|---|---|---|
| Π1 | π1(θ) | N(12,1) 1 | N(−6000,100) | Γ(0.1,10) |
| π2(θ) | Γ (144,12) | N(−6000,100) | Γ(0.1,10) | |
| π3(θ) | N(12,1) | −b~Γ(360,000,60) 2 | Γ(0.1,10) | |
| π4(θ) | N(12,1) | N(−6000,100) | N(0.01,0.001) | |
| Π2 | π5(θ) | U(−100,100) 3 | N(6000,100) | Γ(0.1,10) |
| π6(θ) | N(12,1) | U(−10,000,0) | Γ(0.1,10) | |
| π7(θ) | N(12,1) | N(6000,100) | U(0,10) | |
| π8(θ) | U(−100,100) | U(−10,000,0) | U(0,1) | |
| Π3 | π9(θ) | N(10,1) | N(−5000,100) | Γ(0.05,10) |
| π10(θ) | Γ(100,10) | N(−5000,100) | Γ(0.05,10) | |
| π11(θ) | N(10,1) | −b~Γ(250,000,50) | Γ(0.05,10) | |
| π12(θ) | N(10,1) | N(−5000,100) | N(0.005,0.0005) |
| Πk | πi(θ|y) | a | b | σ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std 1 | 2.5% | 97.5% | Mean | Std | 2.5% | 97.5% | Mean | Std | 2.5% | 97.5% | ||
| Π1 | π1(θ|y) | 10.32 | 0.2662 | 9.787 | 10.93 | −5110 | 98.04 | −5336 | −4913 | 0.005 | 0.00029 | 0.0045 | 0.0056 |
| π2(θ|y) | 10.69 | 0.3141 | 10.09 | 11.33 | −5247 | 115.7 | −5483 | −5026 | 0.005 | 0.00029 | 0.0045 | 0.0056 | |
| π3(θ|y) | 12.73 | 0.0326 | 12.66 | 12.79 | −5999 | 9.981 | −6018 | −5979 | 0.0053 | 0.00031 | 0.0047 | 0.0059 | |
| π4(θ|y) | 10.22 | 0.3272 | 9.557 | 10.67 | −5073 | 120.4 | −5243 | −4828 | 0.0049 | 0.00028 | 0.0043 | 0.0054 | |
| Π2 | π5(θ|y) | 9.833 | 0.5913 | 8.899 | 10.93 | −4931 | 217.4 | −5335 | −4587 | 0.005 | 0.00028 | 0.0045 | 0.0056 |
| π6(θ|y) | 10.51 | 0.3716 | 9.899 | 11.05 | −5179 | 137 | −5382 | −4952 | 0.005 | 0.00029 | 0.0045 | 0.0056 | |
| π7(θ|y) | 10.91 | 0.3424 | 10.19 | 11.37 | −5329 | 126 | −5496 | −5060 | 0.0049 | 0.00027 | 0.0044 | 0.0055 | |
| π8(θ|y) | 9.749 | 0.5756 | 8.649 | 10.61 | −4901 | 211.5 | −5216 | −4497 | 0.0048 | 0.00027 | 0.0044 | 0.0054 | |
| Π3 | π9(θ|y) | 10.02 | 0.01714 | 9.985 | 10.05 | −5000 | 0.5054 | −5001 | −4999 | 0.005 | 0.00029 | 0.0044 | 0.0056 |
| π10(θ|y) | 10.02 | 0.01751 | 9.985 | 10.05 | −5000 | 0.5019 | −5001 | −4999 | 0.005 | 0.00029 | 0.0044 | 0.0056 | |
| π11(θ|y) | 10.02 | 0.03202 | 9.954 | 10.08 | −5000 | 9.906 | −5019 | −4980 | 0.005 | 0.0003 | 0.0044 | 0.0056 | |
| π12(θ|y) | 10.02 | 0.01692 | 9.985 | 10.05 | −5000 | 0.4979 | −5001 | −4999 | 0.0048 | 0.00027 | 0.0044 | 0.0054 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, T.; Liu, K.; Wu, W.; Wang, K.; Lv, C. Uncertainly Analysis of Prior Distribution in Accelerated Degradation Testing Bayesian Evaluation Method Based on Deviance Information Criterion. Symmetry 2024, 16, 160. https://doi.org/10.3390/sym16020160
Zou T, Liu K, Wu W, Wang K, Lv C. Uncertainly Analysis of Prior Distribution in Accelerated Degradation Testing Bayesian Evaluation Method Based on Deviance Information Criterion. Symmetry. 2024; 16(2):160. https://doi.org/10.3390/sym16020160
Chicago/Turabian StyleZou, Tianji, Kai Liu, Wenbo Wu, Ke Wang, and Congmin Lv. 2024. "Uncertainly Analysis of Prior Distribution in Accelerated Degradation Testing Bayesian Evaluation Method Based on Deviance Information Criterion" Symmetry 16, no. 2: 160. https://doi.org/10.3390/sym16020160
APA StyleZou, T., Liu, K., Wu, W., Wang, K., & Lv, C. (2024). Uncertainly Analysis of Prior Distribution in Accelerated Degradation Testing Bayesian Evaluation Method Based on Deviance Information Criterion. Symmetry, 16(2), 160. https://doi.org/10.3390/sym16020160