1. Introduction
The purpose of the present work is to further develop the analysis carried out in [
1], which considered a description in the framework of kinetic theory of the evolution of an economic system, or, more precisely, a market system. We mean by this a system of mutually interacting individuals—who could be called “economic agents”—whose states are characterized by the amount of money at their disposal and whose mutual interactions are simply money exchanges that occur due to the sales and purchases of goods and/or services. As is well known, in a statistical framework, the changes in state due to interactions between economic agents cannot be deterministically predicted: all that can be accomplished is to attribute a probability linked to the state before the interaction to each possible state after the interaction. This is what is called “transition probability”, and this probability also depends on the state of the subject interacting with an individual. Usually, the law that associates to any triple
of states, the probability that any individual goes from state
s to
after an interaction with an economic agent whose state is
is assigned more or less arbitrarily, according to a statistical projection from a sufficiently large number of previous experiences. And, of course, the instantaneous variation of the probability of each state also depends on the interaction rate, which, in an economic context, is the frequency of money exchanges per unit time. Thus, this variation is a function of two sets of terms: (1) the “assigned” terms, which are independent of the evolution of the system (interaction rates and probability transitions), and (2) the unknown terms, which are the states of interacting individuals before the interaction.
The assigned terms that determine the variation in the probability distribution over the set of states are usually considered as characterizing the particular system under examination. Accordingly, they are prescribed once and for all on the basis of a sufficiently large number of prior experiments. The correctness of the prescription is checked based on the greater or lesser agreement of the solutions to the equations with the observed evolution of the system. In this connection, a question spontaneously arises: can we improve this procedure by taking into account a priori any possibility of error in the prescription or uncertainty? The main purpose of this paper is to give this question an affirmative answer. As a matter of fact, if the interaction frequencies and transition probabilities, rather than constants uniquely associated with the model, are assumed to be “random variables” or, more precisely, values affected by randomly distributed errors, one obtains at least two important results:
on the one hand, as we shall see in details in
Section 2 and
Section 3, one finds convincing evidence of the validity of the continuous dependence of solutions on the data (where the word “data” also refers to coefficients, when these latter are interpreted as parameters);
on the other hand, with particular regard to the economic context, it allows us to outline an explanation of the fluctuations that affect the overall economic state of a collectivity. These results will be illustrated in this paper through the outputs of some numerical simulations, in which the errors and uncertainties are assumed to be distributed according to the standard normal distribution and the extraction of their random values is performed at each time step.
To put the article in context, we point out that, especially over the last fifteen years or so, several works have been published studying markets and economic exchanges from a kinetic theory perspective. To mention just a few of these works, without any claim to completeness, we recall here [
2,
3,
4,
5,
6], referring to their bibliographies as well. It is worthwhile to stress that, despite the common basis that rests on the analogy between individuals exchanging money and molecules undergoing collisions, these papers and those they quote in fact have developed different approaches. In particular, their approaches and methods are significantly different from those presented here. Very briefly, in [
2], various “gas-like” models are reviewed, which rely on a simple framework in which two (out of
N) randomly selected agents exchange money according to a predefined rule. Specific focus is placed on the effect of different saving propensity attitudes of the traders on the resulting long-time wealth distribution. In [
4], similar asset exchange models are considered in conjunction with a utility maximization principle for the pairs of trading agents. Monte Carlo simulation methods are then employed to analyze the distributional features. The approach in [
3] differs from those just mentioned, because it treats the agents as a continuum and defines the dynamics as governed by a spatially homogeneous Boltzmann equation in which the term containing the “collisional operator” (in this context, collisions correspond to trades) is expressed by an integral. In this paper, the analysis focuses on the thickness of the Pareto tail. An analog of the Boltzmann equation is also considered in [
6], which leads, in a suitable (small transaction) limiting case, to a partial integrodifferential equation. Features such as inflation, production, and taxation are also added to the model. Finally, the survey [
5] provides an extensive description of the historical development of several statistical models of money, wealth, and income distributions, and includes in this overview both gas-like models that involve
N agents and models described by integrodifferential equations.
Unlike ours, none of the mentioned papers take into account the distinction of different income classes. Furthermore, the uncertainty that affects the encounter rates and is incorporated into the present work by means of random variables, has (to the best of our knowledge) never been dealt with as here. Regarding this aspect of stochasticity, a final caveat is also necessary. The explicit incorporation of a noise term in a model of the dynamics of income distribution in the presence of monetary exchanges was the subject of the article [
7] and resulted in a Langevin-type kinetic equation somehow similar to the one below. We emphasize, however, that the type of noise and uncertainty, as well as the aims pursued in the investigation, are very different in [
7] and here. Whereas in [
7], a term expressing a multiplicative noise, unrelated to interaction rates, is added to the deterministic part of the evolution equation, in the present paper it is the coefficients themselves that express the interaction probabilities between individuals that are considered randomly changing over time.
We underline that the stochastic frame formulated in this paper should essentially be understood as a basis building block for future investigations in which we plan to address specific topics of economic interest in a more targeted way. Additionally, we think and hope that it can be a stimulus for in-depth analytical studies and for the establishment of well-posedness results. Indeed, we do not provide here formal proofs of the global existence and uniqueness of solutions of the proposed nonlinear stochastic differential equations. Rather, we pursue a heuristic approach by developing and discussing numerical simulations. We emphasize, however, that all the numerical simulations we have carried out (actually, a large number; those reported here are only a sample) suggest that the proposed model is reasonable and deserves attention and further investigation.
The contents of the paper are distributed as follows:
Section 2 is devoted to the statement of the problem, to the explanation of the mathematical language used to treat it, and to the formulation of the system of stochastic equations describing the evolution of an economic system under our hypotheses; in
Section 3, we comment on simulations and show a sample of numerical solutions to the system considered in
Section 2, also discussing their connection with the problem of the continuous dependence of solutions on parameters.
Section 4 is devoted to outlining some conclusions and possible developments of the present research towards the construction of models that are increasingly faithful to the behavior of real economic societies. Finally, an appendix (
Appendix A) is added containing the proof of the fact that a certain quantity is conserved during the evolution of the system.
2. The Model
We consider here a closed market society, characterized by the fact that the frequencies with which the individuals exchange money vary stochastically over time. We describe the problem in the context of a complex system approach, considering a population of interacting individuals divided into a finite number n of classes characterized by the average income of their members. To fix the notations, we first take numbers , where is large enough to represent an upper bound for the maximal conceivable income of each individual in the society. In particular, we suppose that with , for . Consequently, one can consider n intervals of increasing length, identifying n income classes. Even if n is not very large, we can obtain, by suitably choosing , that the income of individuals belonging to the n-th class is orders of magnitude larger than that of the individuals of the first class (as happens in real societies). We denote by for the average income of the i-th class and, assuming for simplicity that all individuals with income actually have the same average income , we denote by for the “fraction” (portion) of these individuals at time t.
Our aim is to study the variation over time of the number of individuals belonging to each class, due to the whole of economic exchanges that take place between the individuals themselves.
We deal with a case in which the global income is constant. Namely, we assume that only many transfers of money from one individual to another occur. The elementary model of society we have in mind is one in which payments from one individual to another are motivated by the provision of a service, good or job. The effect of these economic transfers is that of a continuous displacement of individuals from one class to another. Of course, in correspondence with a single transaction, this displacement is “small”: we can interpret it as the displacement of portions of individuals, an interpretation that is justified in the context of a collective picture. At the “macroscopic level”, the conservation of global income can be interpreted as the fact that production and consumption in the society are balanced.
To set up a mathematical formulation of the economic exchanges process described, we introduce n matrices with , of dimension , with the following property: the elements of satisfy and expresses the probability that an individual of the h-th class belongs to the i-th class after a direct interaction with an individual of the k-th class. Of course, the requirement that the coefficients express probabilities implies that for any fixed h and k they satisfy .
A suitable expression for these coefficients has been derived in [
1] (note only that in [
1] the case of income intervals of the same length was considered, i.e., the case where
). To reproduce and then adapt it to the new framework, we introduce an
matrix
P, whose elements
for
denote the probability that, in an encounter between an individual of the
h-th class and one of the
k-th class, the one who pays is the former (also called a
h-individual). We denote by
S the amount paid in a transaction. As mentioned above, any single interaction may cause a slight decrease or increase in the income of the individuals involved and, in turn, a slight variation in the class populations. In fact, these variations only affect the original class and the neighboring classes of the individuals involved, and the only possibly nonzero elements among the
are easily found (see [
1] for these details) to take the form
where the only nonzero elements
—elements of
n matrices
—are
whereas the nonzero elements
—elements of
n matrices
—are given by
Note that the expression for
in (
3) holds true for
and
, the first addendum of the expression for
is actually only present for
and
, while the second addendum is present only under the condition that
and
; and the expression for
holds true for
and
. These constraints are functional to the meaningfulness of the indices and reflect the fact that in this model individuals of the first class never pay and individuals of the
n-th class never receive money (there are neither classes poorer than the first nor classes richer than the
n-th).
There is an element of symmetry in the Formula (
3) since in each trade the variation in the fraction of
i-individuals for
, regardless of whether they pay an individual of a poorer or richer class, is inversely proportional to the difference in the average incomes of the classes involved in the exchange. Perfect symmetry, however, cannot be achieved in this case, because the average income
of the
i-th class increases as
i increases.
We emphasize that there are some degrees of freedom in the choice of the coefficients
. It is reasonable, in this respect, to adjust the coefficients based on the fact that poorer individuals usually earn and spend less than richer ones. An even more realistic option is to also take into account the effects of some unavoidable uncertainties and randomness. In view of this, we consider each
for
as the sum of a “deterministic” and a “stochastic” part,
or, in matrix notation,
To this aim, we start by defining a
matrix
where the variable
c is a positive number and the variable
is a
matrix, as the matrix with elements
given by
We then define
and
(with the dependence of
on
explicitly underlined) where
is the
matrix having all elements equal to 1,
W is a
matrix whose elements are Brownian motions and
and
are positive constants, chosen in such a way that the inequalities
hold for all
with a probability very close to 1. In particular, in
Section 3, a numerical approximation is proposed, according to which the (
6) are satisfied; and this in turn guarantees that the
remain non-negative during the evolution of the system. These latter conditions are compatible with the meaning of the
, which express the probabilities of payment in a case in which encounters without any payment can also occur.
The overall dynamics corresponding to the variation of the fraction of individuals in the various income classes is described by a vectorial stochastic differential equation (see, e.g., [
8,
9,
10] for SDE, [
11] for a nice presentation of SDE and their numerical treatment and [
12]). Before writing it down, let us point out that in the following we denote
(respectively,
) the matrix
having elements
as in the Formula (
3), with the difference, however, that the elements
are replaced by
(respectively,
).
The announced stochastic differential equation, whose unknown is the vector function
with components
denoting the number of individuals in the
i-th income class for
, is given by
By taking the sum over
of the left(-hand) and of the right(-hand) side of (
7), one can easily see that (the size of) the total population,
, remains constant in time. This is in agreement with the fact that births, deaths and other variations in the total number of individuals are not significant for the problem under investigation and over the period of interest here.
By choosing the normalization
we observe that, since (as can easily be verified)
one has
The differential Equation (
7) can then be written in a more compact and elegant form as
and in the numerical simulations we employ the usual approximation ([
10,
11,
12])
where
is a
matrix, whose elements are independent standard normal random variables. We emphasize that the extraction of the random variables
occurs at each time step during the evolution of the system. Furthermore, we stress that the elements of the matrices
depend linearly on the elements of the matrices
and, in turn, these depend linearly on the elements of the matrices
X. Yet, the Equation (
10) is nonlinear.
In conclusion, the system of equations described above reflects the classical philosophy underlying the kinetic-theoretical treatment of the behavior of many-particles systems, but with one very important difference. The total probability variation of each possible state of the “particles” in the system results from the sum of a gain term and a loss term; but in the standard model, these are—in an appropriate sense of the term—deterministic: once the transition probabilities and interaction rates have been assigned, the time derivative of the probability of each state and the probability itself become—provided the equation can be solved—known functions of time. This is a peculiar feature of probability: although the events to which it applies are uncertain by definition, within the framework of a given theory, its values are certain. Accordingly, the interaction rates and the transition probabilities that appear in all kinetic-theoretical equations are in a sense the weak point of all models that use them. In any case, these parameters cannot be assigned exactly a priori or “by nose” if the models are to be applied to real problems. At most, their values can be proposed as working hypotheses and must be verified a posteriori.
The difference introduced in this paper lies in the additional term in the right-hand side of Equation (
11). Containing a random variable distributed according to the standard Gauss normal curve of errors, this term takes into account the unavoidable uncertainty of the interactions rates and the parameters, or data, of the theory. The rigidity of precise assumptions about the prescription of conditional probabilities is mitigated and, as will be shown in
Section 3 through a series of simulations, this approach can offer a broader class of solutions that exhibit more natural fluctuating behavior.
3. Numerical Results
Before moving to a discussion on the results of the numerical simulations, we point out that the specific structure of the coefficients (
3) guarantees that the total income
remains constant during the time evolution of the system described by both Equations (
10) and (
11). We refer the proof of this to the Appendix and we continue with the presentation here.
To investigate the processes generated by Equation (
11), we have to fix some of the parameters of the model. As an example, we chose
(but then, as also mentioned below, we also dealt with the cases
and
) and
. The values of the
for
were assumed to be approximately equal to
with average incomes
for
approximately equal to
The logic is to have the average income of the richest class two orders of magnitude larger than that of the poorest class. Also, we chose
. As for the parameters
defined in (
5), we chose
and
, whereas for any
h and any
k in
a (different) value
of the standard normal random variable was taken at each time step. To be precise, in order to guarantee the validity of the inequalities (
6), we took a truncated version of the standard normal random variable, restricting the values domain to the interval
(which contains, by the way, approximately
of all possible values).
At this point, the following observation is in order: a quantity of simulations for the construction of numerical solutions of the “deterministic” problem, namely the problem described by Equation (
11) in which
, gives evidence of the fact that—once the parameters
n,
,
for
and
for
,
S and
are fixed—all solutions evolving from initial data
with
for any
, which satisfy
and
for some
, tend to the same stationary solution as
(actually, as
t becomes large). In other words, when the parameters defining the “deterministic” model are fixed, in correspondence to any conceivable value
of the total income, there exists a unique asymptotic stationary solution.
We have therefore fixed a value of the total income, chosen initial conditions compatible with this value, performed 33 realizations of the Equation (
11) and calculated the mean and the variance of the sample realizations. Moreover, we repeated this procedure several times.
Some results which exhibit features typical of all performed simulations are shown in the
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6. Precisely, the figures from
Figure 1,
Figure 2,
Figure 3 and
Figure 4 are relative to the case when
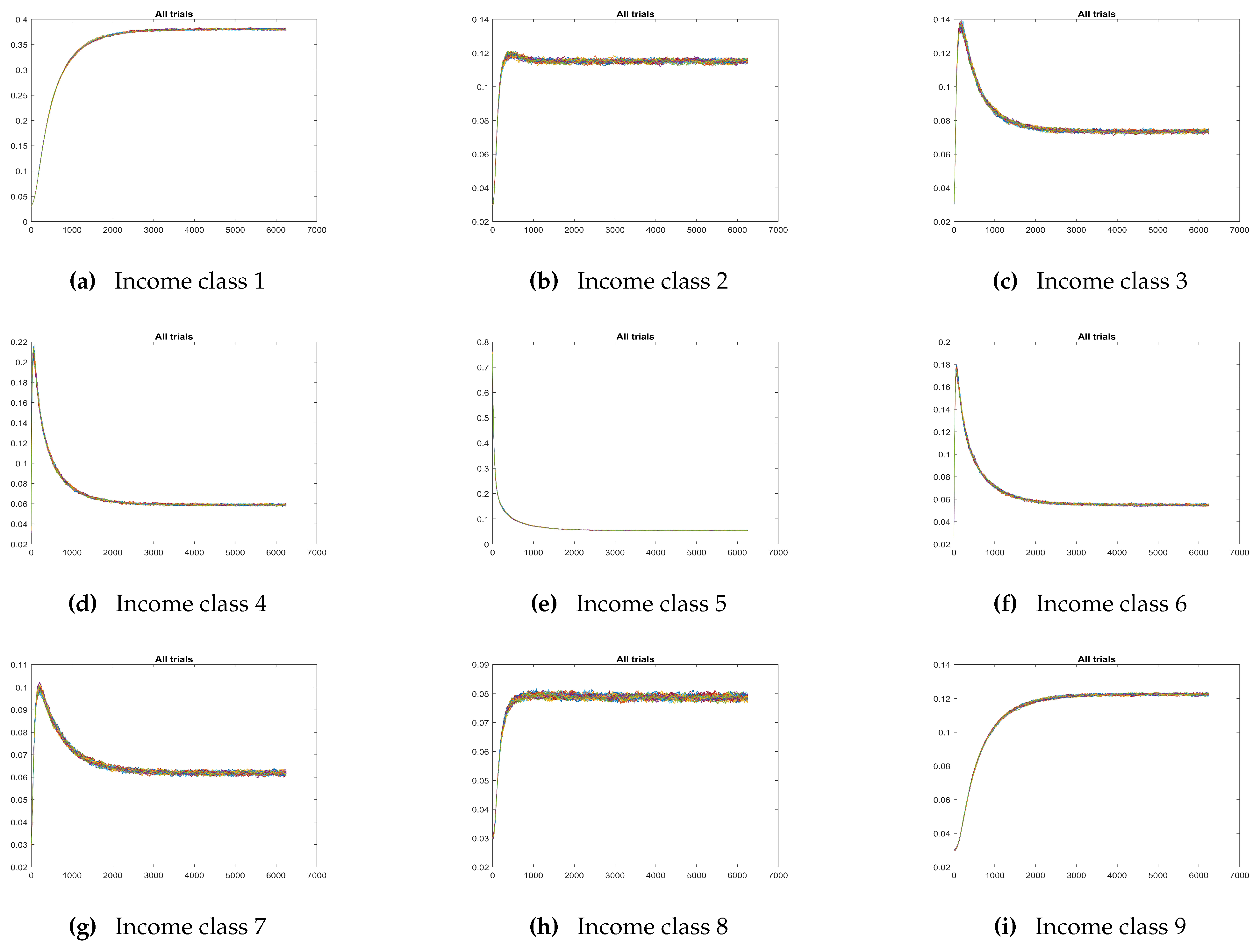
. Each of the panels in
Figure 1 refers to one of the income classes and displays five curves corresponding to the mean over 33 realisations, to the curve obtained adding [respectively, subtracting] at at any time step the standard deviation to [respectively, from] the mean value, and to the curve constructed by taking at any time step the minimum [respectively, the maximum] among the values of the realisations. The panels in
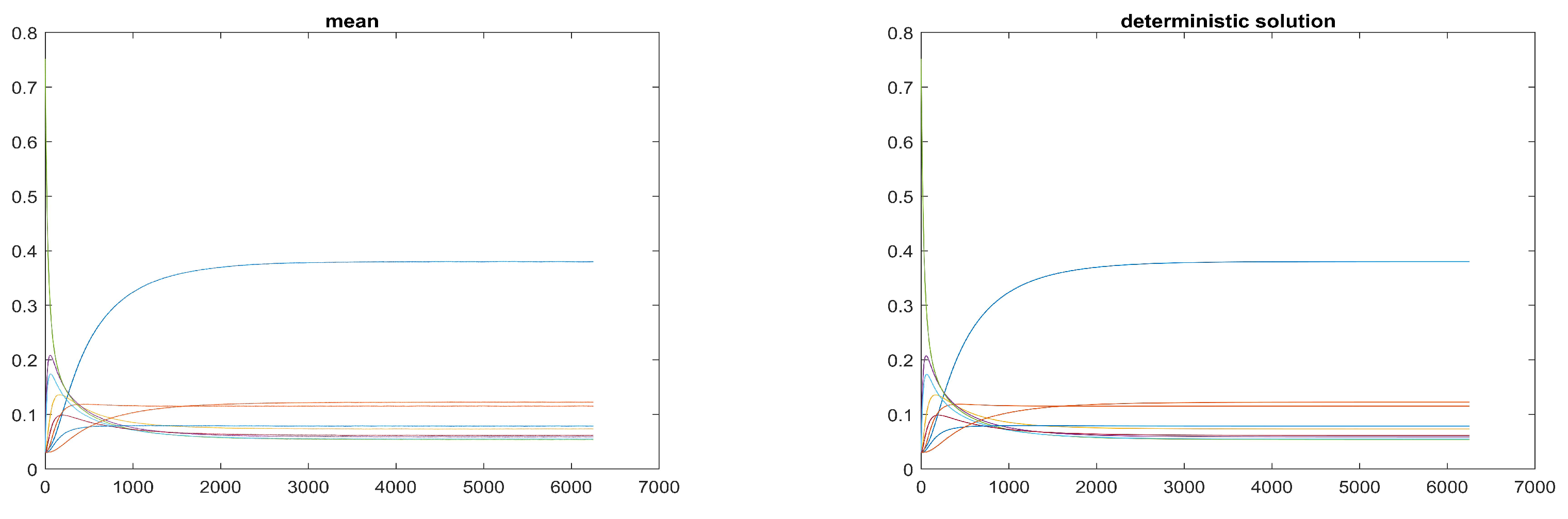
Figure 2 refer to the same experiment, and show for each income class the set of all realisations. The top panel in
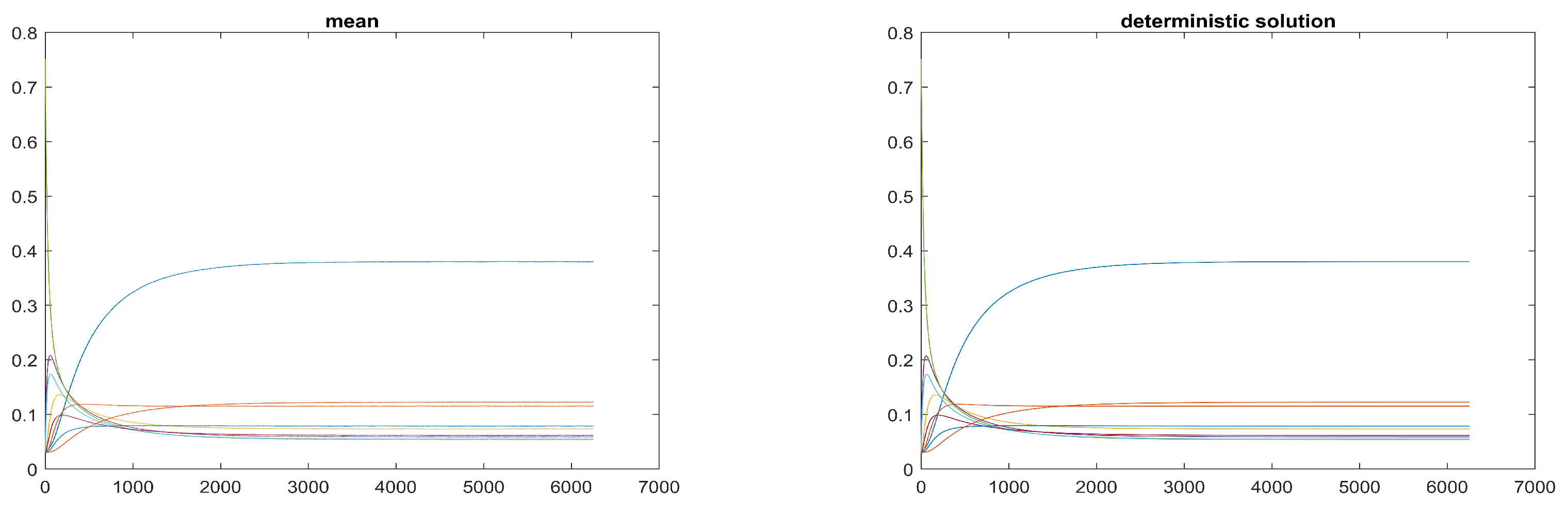
Figure 3 displays the nine curves respectively obtained by considering at each time step the mean of the values over the 33 realisations, whereas in the bottom panel in the same figure one finds the nine curves corresponding to the components of the solution of the corresponding deterministic problem. The high similarity (possibly, the equality) of the curves in the two panels gives indication of the validity of the model. The
Figure 4 displays the nine curves obtained by considering at each time step the standard deviation of the values over the 33 realisations. The two panels in
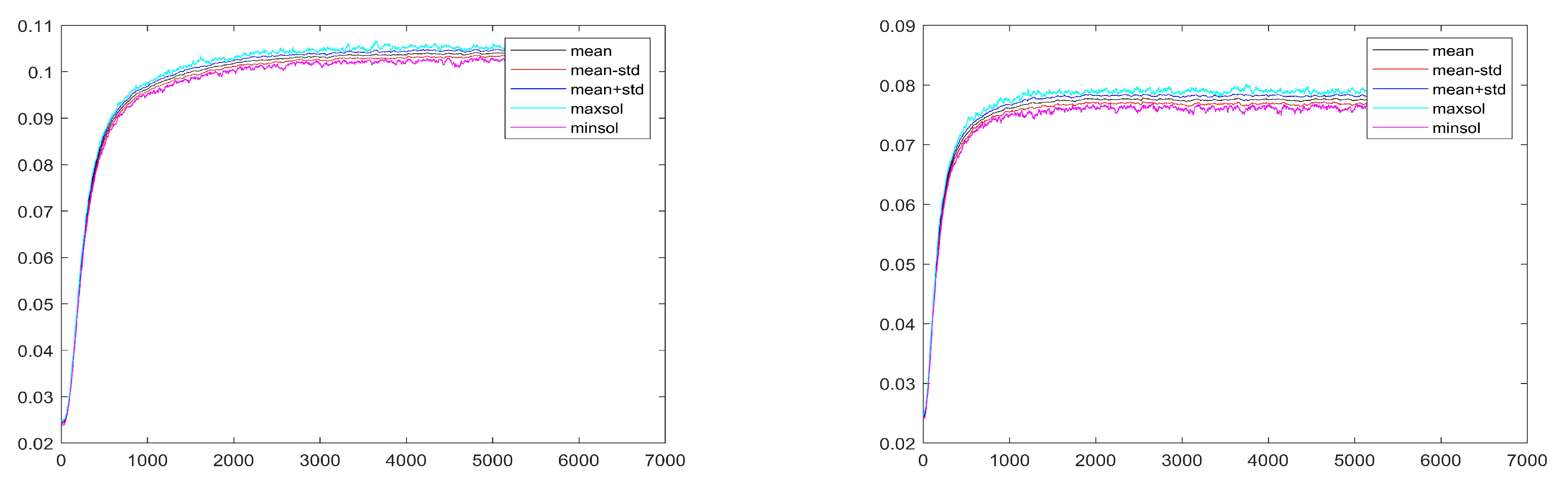
Figure 5 display the five curves mentioned in the
Figure 1 for a case with the same value of the total income, but with
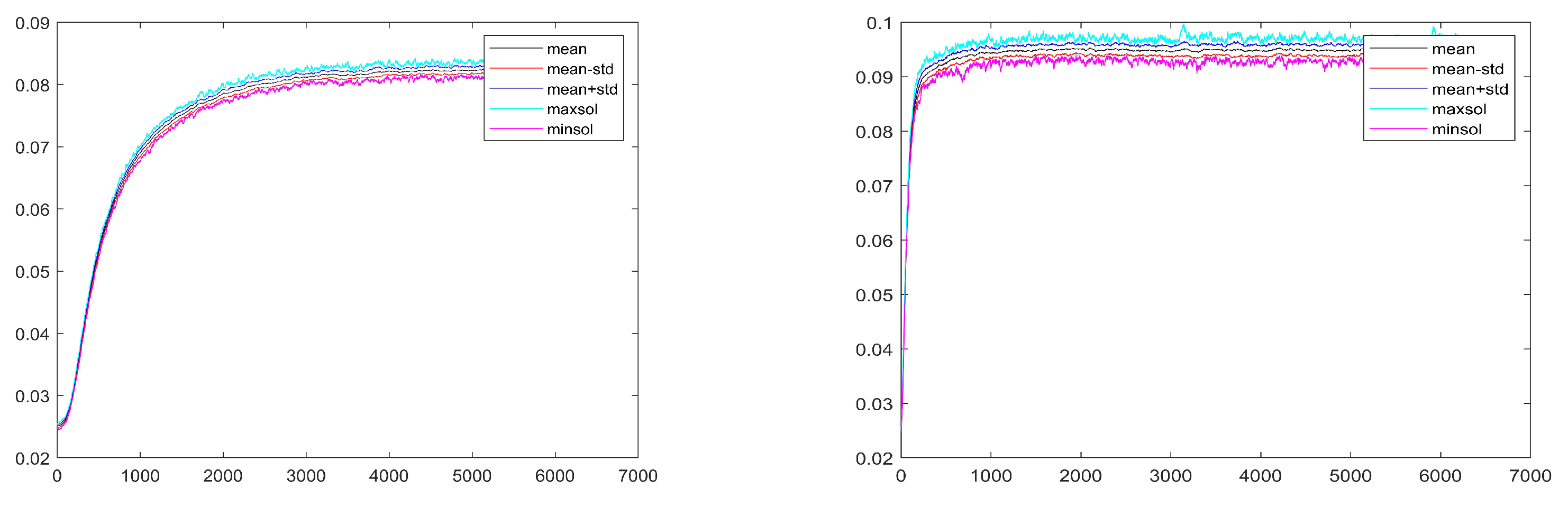
in the classes 2 and 10; the same holds for the two panels in
Figure 6 with the only difference that they refer to the case in which
and the income classes there represented are class 2 and 12 (the second one and the penultimate), those where the fluctuations appear to be the largest one.
By looking at these figures one notices that in the long run the stochastic process modelled by Equation (
11), while not leading to an equilibrium, displays fluctuations which do not deviate much from an equilibrium. Such a picture seems to correspond to the appropriate representation of an economic phenomenon.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}