1. Introduction
The blade shape in an aero-engine compressor is usually either symmetric or asymmetric, and the traditional symmetric blade shapes include the NACA series. As shown in
Figure 1, the plane cascade consists of either a symmetrical shape or an asymmetrical blade shape. In order to obtain the advantages and disadvantages of symmetric or asymmetric blade shapes, plane cascades are usually used for testing. The aerodynamic coefficients of the plane cascade can reflect the pros and cons of symmetric and asymmetric blade shapes in a compressor, which in turn determines the performance of the compressor. As the core component of the aero-engine, the compressor can directly affect the aero-engine parameters, such as thrust-to-weight ratio, air flow rate, and efficiency. The geometry structure and test method of the plane cascade test piece determine the importance of the axial velocity density ratio (AVDR) parameter in determining the duality of the flow field and the validity of the data at the early stage of the test, and the value of AVDR is generally maintained at about 1 [
1]. In subsonic and transonic tests, AVDR has a greater influence on the cascade loss coefficient (measurement of pressure, energy losses) and airflow turning angle [
2].
The aerodynamic performance of traditional plane cascades can be obtained by theoretical analysis, computational fluid dynamics (CFD), and wind tunnel tests. Theoretical analysis is based on the laws of physics and deduced through the control equations, which will encounter great difficulties in dealing with complex problems, whereas wind tunnel tests have the problems of long test periods and high costs. CFD uses computer and the laws of physics to solve equations and has achieved excellent results in flow field prediction, control optimization, and turbulence modeling [
3,
4], but it consumes a lot of computing resources and takes a long time when performing complex calculations. In order to speed up the CFD time, machine learning and its combination have achieved good results in grid solving, geometric modeling, flow field prediction, and pressure distribution prediction [
5,
6,
7,
8,
9]. However, limited by the computing resources required by CFD itself, the computing time and resource consumption of problems are still a major difficulty.
As artificial intelligence has matured, data-driven machine learning methods have been widely used in aerospace and other fields, such as target detection [
10]. In research on aerodynamic performance prediction, commonly used machine learning methods include support vector regression (SVR) [
11,
12], Gaussian process regression (GPR) [
13], Kriging [
14,
15], and neural networks [
16,
17,
18,
19,
20,
21,
22]. For classical machine learning methods, Andrés-Pérez et al. [
11] and Peng et al. [
12] used SVR for airfoil and rocket aerodynamic performance prediction, respectively. Experimental results show that SVR has a stronger ability to fit nonlinear data. For GPR, the kernel has a decisive influence. Different kernels have different fitting abilities for data. Hu et al. [
13] proposed a GPR based on automatic kernel construction, selecting different kernels according to the set construction rules and combining kernels, avoiding the empirical error caused by manual selection. Kriging, which is essentially similar to GPR, also has the same advantages in the task. Han et al. [
14] and Zhao et al. [
15] proposed a Kriging based on gradient and second-order forms, respectively.
The neural network methods studied in the field of aerodynamic coefficient prediction are BPNN [
17,
20,
23], CNN [
16,
18,
21,
24,
25,
26], PINN, and MTLNN. BPNN is generally used for pure numerical data, and CNN is used for image data. Due to the multi-dimensional output characteristics of aerodynamic coefficients, Lin et al. [
19] and Zhang et al. [
27] utilized MTLNN to expand different aerodynamic coefficients and data forms into different tasks for the purpose of parameter sharing between different outputs and data forms and embedded physical knowledge to form PIMTLNN.
For the methods described above, the neural network and GPR have better prediction accuracy than the other methods, but the neural network model requires a large number of datasets to obtain excellent prediction results, and the plane cascade data collection has the problems of a long test period, high input cost, and low efficiency. GPR has great advantages over neural networks for small samples. However, the traditional single-output Gaussian process regression is limited by its own functional characteristics [
28] and can only model each output dimension separately in the aerodynamic coefficient prediction task. For plane cascade data with the correlation between output dimensions, single-output Gaussian process regression not only takes a long time to model, but also cannot fit the correlation between multi-dimensional outputs. Multi-output Gaussian process regression can consider the correlation between multi-dimensional outputs, but there are two different types of input parameters in the plane cascade data, geometry and working conditions, and the traditional Euclidean distance-based sample similarity measure is difficult to improve the prediction accuracy and generalization performance of the model in the case of small samples.
For this problem, metric learning for multi-output Gaussian process regression is proposed. ML_MOGPR combines metric learning to learn a new embedding space of sample features, which can better distinguish different samples in the task of predicting the aerodynamic coefficients of plane cascade with fewer samples. In the new metric space, the input features corresponding to each output target can have better weight ratios.
The experimental results of the aerodynamic coefficient prediction of the plane cascade show that the multi-output model is better than the single-output model in overall prediction accuracy. ML_MOGPR further outperforms the rest of the multi-output models, backpropagation neural network (BPNN), multi-task neural network (MTLNN), and traditional MOGPR, in terms of overall prediction accuracy, which verifies the effectiveness of ML_MOGPR in the prediction of aerodynamic performance of a plane cascade, and it can provide an important reference for the preliminary estimation of aerodynamic coefficients of the plane cascade. The main symbols and abbreviations used in this paper are shown in
Table 1.
2. Gaussian Process Regression (GPR)
2.1. Single-Output Gaussian Process Regression (SOGPR)
GPR is a non-parametric model that uses GP prior for regression analysis. According to the prior assumption and likelihood distribution, the posterior probability distribution of the predicted sample is obtained by the Bayesian rule.
Assuming a latent function
with a Gaussian prior, its mean
and covariance
are as follows:
In a regression task, suppose the training dataset
,
is the input matrix of
, and
is the output vector of
;
is the
d-dimensional vector, and
is the output scalar corresponding to
. There is generally noise in real datasets, i.e.,
, where
is assumed to follow an independent and identically distributed Gaussian distribution with mean 0 and variance
:
. A GP is defined as a collection of random variables, for convenience of computation, assuming
, then
, where
I is the unit matrix,
is the covariance matrix of
with
. If the test set input is
, the expected prediction value is
, and since any finite number in a GP has a joint Gaussian distribution, the joint prior Gaussian distribution under the independent assumption is as follows:
The joint posterior distribution can be obtained:
The simplified expression , , where and are the predicted value and covariance matrix of , respectively, and the covariance represents the uncertainty in the prediction results. If is a sample in test set , then the predicted value , . As can be seen, GPR is mainly determined by the covariance, which is also called a kernel function. This kernel controls the covariance and similarity between any two samples.
Based on the SOGPR definition, the model itself is compatible with multiple inputs, but it is not capable of achieving multi-output target prediction, and it is not possible to jointly consider the aerodynamic performance coefficients of a multi-output plane cascade. The lack of correlation between the multiple output dimensions of the model affects the overall accuracy. Therefore, the multi-output Gaussian process regression model has advantages in this respect and can more accurately predict the aerodynamic performance coefficient of the multi-dimensional cascade.
2.2. Multi-Output Gaussian Process Regression (MOGPR)
The crucial aspect of Gaussian process regression is the kernel function selection and design. Earlier MOGPR considered each output individually as a Gaussian process with a Gaussian prior latent function and computed the covariance between different output dimensions by linearly combining the latent GP of each output dimension [
29,
30]. Assume
is a
p-dimension output vector.
where
Q is the number of components, and
is a
positive semi-definite matrix of the multi-output kernel product, which represents the correlation between the outputs, also called the coregionalization matrix. The operator ⊗ is a Kronecker product, and
represents the covariance of the
ith and
jth outputs.
The limited cross-covariance leads to a conflict with the
ℓ of the SOGPR kernel, and there is no explanation for the correlation of multiple outputs. The kernel Fourier transform-based spectral mixture kernel (SM) [
31] generates phase shifts through a linearly weighted combination of spectral Gaussian kernels (SG), which can give explicit covariance relations and solve the conflict problem.
where
,
is the kernel parameter,
is the peak frequency,
is the scale parameter, and
is the relative contribution of each SG. The combination of SM and linear model of coregionalization (LMC) forms the basic spectral mixture multi-output model (SM_LMC), which can represent any combination of stationary kernels and better explain the relationship between different channels.
In addition, the SM-based extended multi-output kernels are cross-spectral mixture kernel (CSM) [
32], multi-output spectral mixture kernel (MOSM) [
33], and multi-output harmonizable spectral mixture (MOHSM) [
34] proposed based on MOSM.
where
and
are amplitude and displacement parameters;
is the number of subcomponents;
are the delay parameters;
,
P is the input displacement number,
is the input component, and
l represents the length scale parameter. The SM extension-based method makes MOGPR smoother and is able to do joint consideration of the multidimensional aerodynamic coefficients of the plane cascade, which makes the model more generalizable.
3. Metric Learning for MOGPR
Metric learning has been shown to have significant benefits in areas such as image classification [
35,
36,
37] and regression prediction, as it is able to measure sample similarity from different perspectives in a new embedding space and shows great benefits with fewer samples. In the traditional multi-output Gaussian process regression, the sample similarity calculation form is
, which gives the same weight to the input features. The input features of plane cascade data include two different types of parameters, geometry and working conditions, and the degree of influence on the aerodynamic coefficient has non-point-to-point characteristics.
As shown in
Figure 2, the correlation strength between the plane cascade data features and coefficients is different. For example, the correlation between the geometrical parameter raster distance (t) and the aerodynamic coefficient
is −0.07, whereas the correlation between the working condition parameter inlet airflow angle (
) and
is −0.85. It is evident that there is a large difference between the influence of geometric and working condition parameters on the aerodynamic coefficients.
In the case of small samples, the generalization ability of the model will be reduced. Inspired by [
38,
39], the input features are embedded into a new space, denoted as:
, where
, then
. The new distance metric formula is as follows:
The model learns this new matrix by which to linearly project the original sample space. This new matrix is able to assign different weight ratios to the sample features based on the output coefficients, reducing the influence of uncorrelated features on the resulting predicted coefficients. In addition, different output coefficients have different focused features (i.e., the same input features of different output coefficients have different weights in single output modeling) in order to maintain different ratios of feature weights while further fitting the correlation between multiple output coefficients. Reference [
40] has an embedding matrix
A with the following form in the multi-output Gaussian kernel:
where
is the matrix matmul product, and
denote the output dimensions. Equivalent to
is the subembedding matrix about the
ith and
jth dimensional output coefficients, and
is the joint matrix.
As MOSM and MOHSM are the better multi-output Gaussian kernel functions in the current study, these two kernel functions are explored in this paper, and their functional forms based on metric learning are as follows:
where
. ML_MOSM and ML_MOHSM introduce new embedding matrices and learn new feature weight ratios while inheriting the multi-output form of the original kernel function. They not only consider the differences between the output targets, but also make the parameters of the measurement matrices of different output targets shared, which make them more generalizable. In plane cascade data with smaller samples, the model can be enhanced to assign weights to parameters with large differences, and similarity measures between different samples can be implemented in a more reasonable space.
4. Experiments and Analysis
The plane cascade test data used were obtained from real wind tunnel test data from a research institute. The data included plane cascades with symmetric and asymmetric blade compositions, which have varying degrees of difficulty in predicting aerodynamic coefficients. In addition, the complexity and high cost of the experimental process resulted in a complex and sparse dataset. Finally, after data cleaning, five groups of plane cascades totaling 310 samples were selected for the experiment. The input features include four geometric and three working condition parameters, and the output coefficients are cascade loss coefficient (
) and AVDR (
). The main geometric differences between the five datasets are shown in
Table 2.
To explore the performance of ML_MOGPR compared with other models in the case of small plane cascade samples, 200, 250, and 300 samples were randomly selected for the experiment. In addition, to make up for the differences caused by the random division of data and ensure the stability of the model as much as possible, each model performs ten experiments in each set of data to take the average value. The training, verification, and test set are randomly divided into 8:1:1. The regression evaluation metrics are RMSE and MAE, and the optimal values are marked in bold black.
Since ML_MOGPR is an innovation based on MOSM and MOHSM, in the field of data-driven prediction of aerodynamic coefficients, the neural networks mainly used for pure numerical data are backpropagation neural network (BPNN) and multi-task learning neural network (MTLNN), and the other single-output models are mainly SOGPR and SVR. Therefore, the comparative models are MOSM, MOHSM, BPNN, MTLNN, SOGPR, and SVR.
Neural networks have different network structures based on the data and loss function. Specific neural networks are described below:
(1) The form of the data in this paper is similar to [
19]. The MTLNN model adopts its network structure, but the physical knowledge of the plane cascade data is implicit, the embedded physical knowledge module is not used, and only the multi-task network part is used. The task layer is changed to two layers according to the two-dimensional output characteristics of the data in this paper.
(2) BPNN has different numbers of network layers and nodes according to the amount of data. In order to ensure the relative fairness of the comparison results, the BPNN network structure will be explored under three sets of data.
(3) Since the prediction of the aerodynamic coefficient of the plane cascade is a regression task, BPNN and MTLNN train the network under the two loss functions of mean square error (MSE) and mean square absolute error (MAE). Each neural network is trained with a mini_batch size of 30 and a network output dimension of 2.
The neural network uses the pytorch, and MOGPR, ML_MOGPR uses the MOGPTK [
41]. The experiments were performed on a computer configured with an Intel(R) Core(TM) i7-8700 CPU @ 3.20 GHz, 3.19 GHz.
4.1. Neural Network Structure and Loss Function Exploration
4.1.1. BPNN Experiments
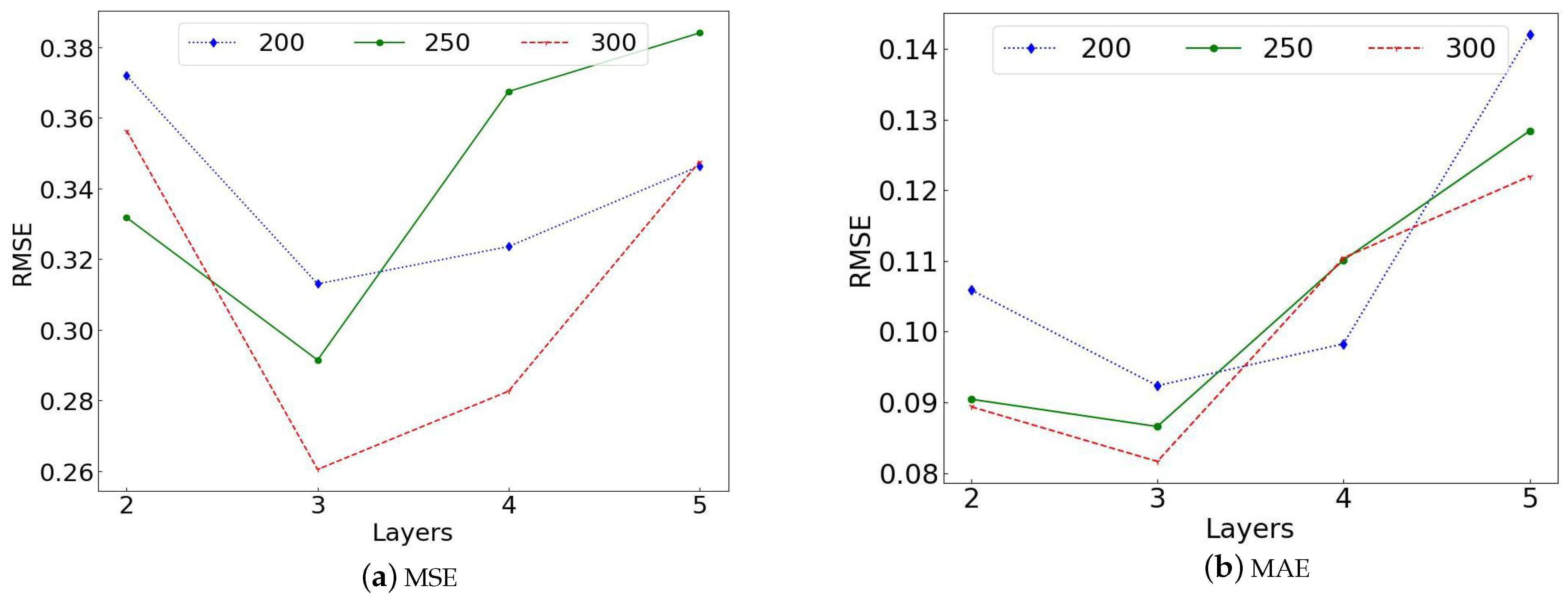
For the network structure exploration of BPNN, due to the small plane cascade data, in order to avoid network overfitting and underfitting, we first start with a network structure with two hidden layers and the number of nodes (8,4). Then, the number of network layers and the number of nodes in each layer are increased sequentially, and the loss functions are, respectively, chosen as MSE and MAE. Specific experiments were performed with MSE loss function and MAE loss function and sample sizes of 200, 250, and 300.
The experimental results shown in
Figure 3 and
Figure 4a,b represent the experimental results of BPNN trained under the MSE and MAE loss functions, respectively. The vertical coordinates in
Figure 3 and
Figure 4 indicate the RMSE prediction value, and the horizontal coordinates in
Figure 3 denote the number of network layers (e.g., 2 indicates 2 hidden layers (8,4), 3 indicates 3 hidden layers (16,8,4), and incremented accordingly). The horizontal coordinates in
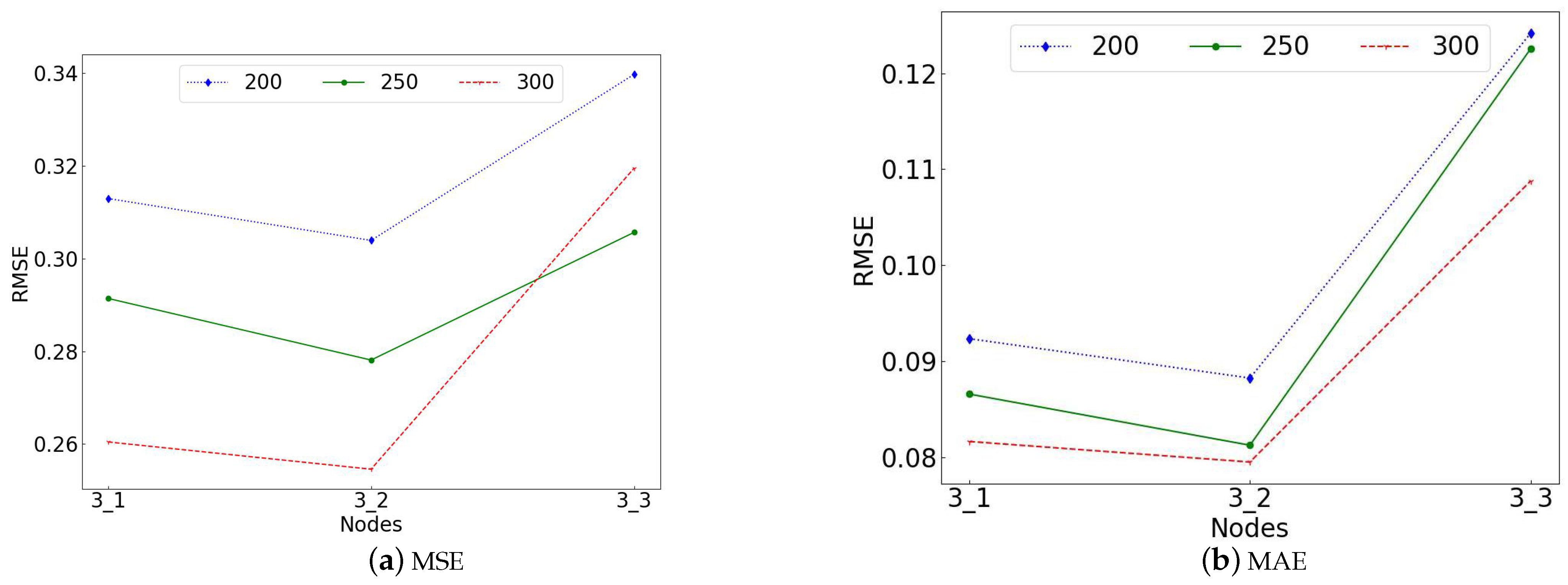
Figure 4 indicate the number of nodes compared to the product of the initial three-layer nodes (16,8,4) in the three-layer hidden layer (e.g., 3_1 means (16,8,4) is the initial three-layer node number, 3_2 means multiplying the number of nodes in 1 by 2, and the number of nodes is (32,16,8)).
It can be seen from
Figure 3 that, under the MSE and MAE, the number of hidden layers of the optimal BPNN network for the three groups of training samples is three and the network structure is (16,8,4); as shown in
Figure 4, the optimal number of network nodes is (32,16,8). Refer to
Table 3 for the specific values in
Figure 3 and
Figure 4. It can be seen that, under the three sets of training data, the optimal values for the MSE are 0.30392, 0.27811, and 0.25457, respectively, and the optimal values for the MAE are 0.08824, 0.0814, and 0.07949. As the number of samples increases, the RMSE value is gradually decreasing regardless of the MSE or MAE. The overall prediction accuracy of MAE-guided BPNN training is far better than that of the MSE. Overall, for BPNN, the optimal network structure is (32,16,8) and the optimal loss function is MAE in the few-sample plane cascade dataset.
4.1.2. MTLNN Experiments
The output aerodynamic coefficients of the plane cascade data have a dimension of two and do not fit into the four task layers of the MTLNN network in [
19]. The shared layer of the network structure remains unchanged, and the number of task layers is changed to two. The specific MTLNN process structure is shown in
Figure 5, and the detailed number of network nodes is referred to in [
19]. The experimental results under the MAE and MSE loss functions are shown in
Table 4. Under MSE and MAE, the RMSE value gradually decreases as the number of samples increases, and the prediction value of MAE training MTLNN is better than MSE.
From the training results of BPNN and MTLNN guided by MAE and MSE loss functions, the three training datasets show that for the plane cascade dataset, the MAE loss function outperforms the MSE loss function with a fewer number of samples. The reason may be that the loss coefficient of the cascade is small, usually around 0.05, while the value of the axial velocity density ratio is usually large, around 1. MSE will square the overall calculation, widening the gap between the two outputs, whereas MAE takes the absolute value directly, so under the MSE loss function, the training results of BPNN and MTLNN are inferior to the results from the MAE loss function.
4.2. Analysis of MOGPR Parameters
MOSM and MOHSM kernels have component combinations (Equations (11) and (12)), and different numbers of component combinations will affect the final prediction results. According to the properties of MOSM and MOHSM kernel functions and their corresponding literature, it can be known that the number of components and the output dimension are generally consistent with better experimental results.
Because the number of components Q determines the count of kernels and hyperparameters, the higher the number of parameters, the more difficult it is to optimize. From [
33], Q is also called the rank of the decomposition, and the number of Q is usually less than or equal to the number of output dimensions, so the value of Q cannot be large. In this paper, the data output dimension is 2, and the number of components Q may be around 2 to make the model have an optimal value. The following will explore the specific influence of the number of components on the experimental results. The number of core components is selected as
. The P parameter (Equation (
16)) in MOHSM refers to [
34], which has little influence on the final result and is fixed as
.
The experimental results of the specific number of MOGPR components are shown in
Figure 6, where (a–d) represent the MOSM, MOHSM, ML_MOSM, and ML_MOHSM models, respectively, the ordinate represents the RMSE value, and the abscissa represents the number of components Q. Under the three groups of sample numbers, it can be seen from the subgraphs (a) and (c) that, for the MOSM and ML_MOSM models, the overall prediction progress shows an upward trend with the increase of Q, and the optimal value is around Q = 2. It can be seen from the sub-figures (b) and (d) that for the MOHSM and ML_MOHSM models, with the increase of Q, the overall RMSE value shows a downward trend. The optimal value of MOHSM is around Q = 4, and the value of ML_MOHSM is around Q = 3. ML_MOGPR has some volatility with Q on the MOHSM model, but the Q of ML_MOHSM is smaller, indicating that it has fewer parameters and is easier to optimize compared to the original MOHSM model. The specific experimental results of
Figure 6 are shown in
Table 5.
From
Table 5, it can be seen that the experimental results of ML_MOSM and ML_MOHSM are better than their respective original models. The experimental results also illustrate that multi-output Gaussian process regression based on metric learning can learn a metric matrix that is more suitable for the input features of plane cascade data, avoiding the effect of large differences (As shown in
Figure 2) in the features.
4.3. Analysis of Results
In the above
Section 4.1 and
Section 4.2, BPNN, MTLNN, and MOGPR have been analyzed under the RMSE evaluation metrics, respectively. For the prediction of the aerodynamic coefficient of the plane cascade, the optimal guidance function of BPNN and MTLNN networks is MAE, and the optimal network structure of BPNN is (32,16,8).
In the final comparison experiment, under three groups of sample sizes, MAE is used for the training loss function of BPNN and MTLNN, and (32,16,8) is used for the BPNN network structure. The number of MOSM, ML_MOSM, MOHSM, and ML_MOHSM components are, respectively, set to the component counts corresponding to the optimal RMSE values in
Table 5.
Table 6 and
Table 7 show the comparison of the best RMSE and MAE values of SOGPR (SOGPR uses a radial basis function kernel (RBF)), SVR, BPNN, MTLNN, MOSM, ML_MOSM, MOHSM, and ML_MOHSM, respectively.
As can be seen from
Table 6 and
Table 7, the multi-output model outperforms the single-output prediction of SOGPR and SVR in overall prediction, with SVR showing an overall higher RMSE value. The probable reason for this is that SVR’s prediction of nonlinear data has extremely noisy points and it is poorly adapted to the plane cascade data. In addition, RMSE is the root mean square error, which goes through the sum of squares, so it exhibits a larger RMSE value. It is known that the single-output model does not fit the relationship between the output dimensions well in multi-output tasks. As can be seen in
Figure 2, there is some correlation between features and outputs. The single-output model lacks some ability to fit this multi-output regression prediction of aerodynamic coefficients.
In the case of fewer samples, MTLNN performs worse and BPNN predicts better. Traditional MOSM and MOHSM have slightly worse RMSE values than BPNN with fewer samples, but better MAE values than BPNN. ML_MOSM and ML_MOHSM are better than BPNN in terms of RMSE value and MAE value. The shortcomings of traditional multi-output Gaussian process regression based on the Euclidean distance measure of sample similarity make it difficult to accurately measure the relationship between different samples when there are large differences in the input features of plane cascade data.
Multi-output Gaussian process regression based on metric learning should learn a new sample embedding space. In addition, according to different output dimensions with joint embedding, ML_MOGPR is able to combine multi-dimensional embedding space based on the joint consideration of the relationship between multi-output coefficients and to assign different weights to each feature according to the relationship between the outputs, thus improving the generalization ability of the model under smaller samples. In addition, ML_MOGPR performs better in the task of predicting the aerodynamic coefficients of symmetric and asymmetric blades of plane cascade in the case of small samples compared to other models.
5. Conclusions
For the shortcomings of multi-output Gaussian process regression based on the Euclidean distance measure of sample similarity in the task of predicting the aerodynamic coefficients of the small-sample plane cascade, metric learning for multi-output Gaussian process regression is proposed.
There are experimental results that show that the single-output model is worse than the multi-output model. When ML_MOGPR is compared with its original MOSM and MOHSM models, ML_MOGPR experimental results are better. This indicates that ML_MOGPR should learn a new metric space in which to distinguish large difference features and assign different weight ratios and effectively improve the accuracy of MOGPR. Additionally, ML_MOGPR outperforms BPNN and MTLNN, which shows that the proposed method can be used for a few samples of plane cascade data.
ML_MOGPR can be applied to the preliminary estimation of plane cascade coefficients, provide a reference for the design of plane cascades, and speed up its design and test process. Further work in the future will incorporate more input features and output coefficients.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}