Abstract
Privacy security and property rights protection have gradually attracted the attention of people. Users not only hope that the images edited by themselves will not be forensically investigated, but also hope that the images they share will not be tampered with. Aiming at the problem that inpainted images can be located by forensics, this paper proposes a general anti-forensics framework for image inpainting with copyright protection. Specifically, we employ a hierarchical attention model to symmetrically reconstruct the inpainting results based on existing deep inpainting methods. The hierarchical attention model consists of a structural attention stream and a texture attention stream in parallel, which can fuse hierarchical features to generate high-quality reconstruction results. In addition, the user’s identity information can be symmetrically embedded and extracted to protect copyright. The experimental results not only had high-quality structural texture information, but also had homologous features with the original region, which could mislead the detection of forensics analysis. At the same time, the protection of users’ privacy and property rights is also achieved.
1. Introduction
Digital images have become an important vehicle for accessing information. due to their direct visual impact and easy dissemination. With the development of technology, digital image editing software and APPs have endlessly emerged, allowing users to easily modify images. In order to distinguish the authenticity of images, the research of image forensics technology has attracted the attention of many researchers. Its purpose is to detect and locate image forgery through the traces of in-camera and out-camera processes left on the acquired image [1,2,3,4]. On the other hand, users have improved their privacy security and manufacturers’ have improved their awareness of copyright. Anti-forensics technology has also attracted extensive research interest, which aims to hide traces of tampering in order to evade detection by the human eye and forensic algorithms [5].
Image inpainting [6,7,8], as a fundamental image manipulation technique, has been a research hotspot in the field of image processing. It can be divided into the following three main categories: diffusion-based image inpainting, patch match-based image inpainting, and deep learning-based image inpainting. Among these, the first two categories belong to traditional inpainting methods. The former carries out pixel diffusion to the interior of the damaged area along the direction of the illumination isoline according to the pixel information around the damaged area. According to the inherent attributes of its inpainting, Li et al. [9] first proposed a forensics algorithm for diffusion-based image inpainting. Later, Zhang et al. [10] also proposed a forensics algorithm, enhanced by weighted least squares filtering, based on Li et al.’s method. Based on the inpainting algorithm of patch matching, this method was similar to Copy-move. Researchers mainly used block features [11], with similarity between different regions [12], and adaptive attention and residual network [13] to obtain evidence. At the same time, image inpainting algorithm forensics, based on deep learning [14], have also been studied.
Anti-forensic techniques for digital images [15,16] not only hide traces of manipulation for the purpose of privacy and property rights protection, but also reveal the shortcomings of image operation itself and image forensic techniques, which has further promoted their development. Currently, anti-forensic algorithms can be divided into three main categories: trace hiding of tampering operations, forgery of inherent features of imaging devices and feature learning forgery based on deep learning.
Firstly, in regard to tampering trace hiding, the main focus is currently on eliminating JPEG compression traces [17], masking median filtering traces [18] and so on, to disguise regular image processing operations. Stamm et al. [19] proposed adding dithered noise, similar to the DCT distribution to the DCT histogram of compressed images, to deceive quantization estimation forensics, which can disable most JPEG compression forensics algorithms based on quantization traces, but cannot resist detection based on block traces [20]. Fan et al. [21] proposed an image variational deconvolution, based on an optimization framework to hide the traces left by median filtering. This work achieved state-of-the-art performance at the time of its proposal, not only in the area of median filtering operations but also in the area of anti-forensics, as it did not damage the image quality. In addition, for image copy-move operations, Amerini et al. [22], applied a global smoothing operation to the image after the copy-move operation, where Gaussian smoothing smoothed out the pixels around key points in the full image, thus rendering forensics ineffective. Analyzing and hiding the traces left by a particular operation is the easiest and most effective way to achieve anti-forensic purposes.
Secondly, forgery of inherent features of imaging devices, the main features inherent to the imaging device, include photo response non-uniformity (PRNU) and the colour filter array (CFA). Among these, Gloe et al. [23] proposed to use a flat field to compress the pattern noise in an image and, later, inserted decompressed pattern noise into the image by inverse flat field, and the results showed that the method achieved an obstructive, or misleading, effect on the pattern noise forensic algorithm. Goljan et al. [24] selected a large number of images taken by the same camera for training beforehand to extract the pattern noise of that type of camera. The resulting pattern noise could later be added to other images to falsify their sources, prompting the resultant source misclassification in source recognition. Karaküçük and Dirik [25] suppressed PRNU noise as much as possible by subtracting sensor noise from the images through noise evaluation, and experimentally showed that it could successfully hinder image source recognition. Huang [26] performed secondary CFA interpolation on the tampered image with quadratic CFA interpolation to maintain a certain linear relationship between the overall image pixels; thus, achieving anti-forensic purposes. Kirchner and Böhme [27] proposed a distortion estimation of the tampered image, using matrix equations to model this distortion and, finally, recovered the tampered image by a least squares algorithm. Stamm and Liu [28] used the CFA interpolation to destroy the inter-pixel correlation introduced by the CFA interpolation by, for example, resizing the image or non-linear filtering of the image, etc., to confuse CFA correlation-based forensic techniques.
Lastly, with the development of deep learning networks, the technology of using deep features to tamper with images has become increasingly mature. Zhang et al. [29] improved the robustness of detection by extracting and analyzing the common traces left by the GAN network. In addition, Du et al. [30] proposed a locally sensitive automatic encoder, which ensured the tampered area was more concerned in the detection process. A lot of works have been conducted with a view to making deep generated images resistant to forensic analysis. Fake images generated from different GANs still exhibit the same fingerprint features. To avoid forensics relying on fingerprint features, data is post-processed before training in order to get rid of consistent fingerprint features [31]. Neves et al. [32] proposed an automatic encoder to remove fingerprints and other information from the synthetically forged image, which could also disable the forensic network relying on generated features. Cozzolino et al. [33] proposed the SpoC method. In the process of generating images based on GAN, camera fingerprints were introduced into forged images to confuse the detector. Wu and Sun [34] proposed an anti-forensics method of covering multiple operations. This method applied appropriate loss function in the training process to automatically learn the visual and statistical characteristics of the original image in the generated image.
In order to address the issue of anti-forensics technologies for image inpainting, Dou et al. [5] proposed an anti-forensics of diffusion-based image inpainting. By analyzing the pattern noise distribution of the original image, this method added a random noise that satisfied the distribution to the diffusion pixels during the painting process, causing the forensic methods based on diffusion [9] to fail. Presently, general image inpainting forensics technology has emerged. However, its counter operation a general anti-forensics of image inpainting technology has not yet been studied. In order to make up for the lack of this technology, this paper proposes a general anti-forensics framework for deep image inpainting. In particular, our framework consists of a pre-trained deep inpainting network, the proposed hierarchical reconstruction network, and a watermark decoder. The pre-trained inpainting network could be any existing deep inpainting network. Our hierarchical reconstruction network adopts the structural attention stream and the texture attention stream parallel reconstruction to those inpainted features, avoiding the entanglement of structure and texture. In addition, the watermark decoder is used to recover the identity information of the user. The inpainted result generated by the proposed general anti-forensics framework is not only resistant to detection by forensic methods, but also copyright is protected. Figure 1 gives the example of image inpainting and anti-forensics. The main contribution is two-fold.

Figure 1.
An example of image inpainting and anti-forensics.(a) Original image, and the red mask in (a) are ground truth of the inpainting region, (b) Inpainted image using DFNet. (c) The forensics result of IID-Net on (b), (d) Result using the proposed method. (e) The forensics result of IID-Net on (d).
- We reconstruct inpainting results hierarchically-based on the deep image inpainting technology, which destroys differences between different regions, and, therefore, damaged regions are not forensically recovered. In addition, our network can also hide the user’s identity information.
- We propose a new hierarchical attention model based on parallel streams of structural attention and texture attention, which can be used to reconstruct the content and texture of images.
2. Related Works
In this section, we introduce works related to the proposed method, including image inpainting and image forensics.
2.1. Image Inpainting
Image inpainting [35,36,37], as a basic image processing method, is often used to fill in missing areas in an image. The technique has been developed over two decades and is a relatively mature image processing technique. In recent years, many DL- and GAN-based inpainting algorithms have been proposed, all of which possess advanced results. They can be divided into two categories [6]: content-based inpainting and structure-based inpainting(SI). By using effective loss functions or attention models, the SI method fills in missing regions and improves realism. For instance, the attention mechanism in [38] was used to construct the correlation of missing regions and background regions, and to fill those regions with background information. Typically, the SI method adopts edge-based context priors to ensure image structure continuity. As one example, ref. [39] developed an edge linking strategy to solve inconsistencies in image semantic structure.
Numerous inpainting algorithms aim to achieve more consistency with human eye vision. Among them, edge articulation has been a difficult challenge for inpainting. Hong et al. [37] proposed a deep fusion image inpainting network (DFNet) with the addition of a fusion block on the U-net network. In this, the fusion block was designed to act as an adaptive module that combined the inpainted part of an image with the original image. In addition to providing smooth transitions, the fusion block avoids learning unnecessary identity mapping of pixels in unknown regions and provides attention mapping to allow the network to focus more on missing pixels. Using the fusion block, structural and texture information can be naturally propagated from known regions to unknown regions.
The DL-based image inpainting algorithms achieve high visual quality, but artefacts always appear in areas with more complex textures and at boundaries. To solve this problem, Wu et al. [35] proposed a deep generative model for image inpainting (DGM), which is a typical DL-based image inpainting network. DGM combines a Local Binary Pattern learning network with an actual inpainting network to propose a new end-to-end, two-stage (coarse to fine) generative model. The network achieves better global and local consistency inpainting results. In addition, Suin et al. [40] designed a new deep image inpainting approach, based on distillation, where cross-distillation and self-distillation were used to produce more accurate hole encoding.
GAN-based image inpainting algorithms usually only output an inpainting result that tends to be factual. However, there may be multiple results that match the semantic information for filling the broken areas. Based on this, Zheng et al. [36] proposed a pluralistic Image inpainting (PLI) network, based on GAN. The network is a framework with two parallel paths, one for reconstruction and the other for generation, both of which are supported by GAN. The method not only generates higher quality inpainting results, but also has a wide variety of plausible outputs. Ref. [41] adopted a cascade generated model to progressively fill in the damaged image, which attempted to solve the inpainting task by introducing multi-scale structural information.
From the above analysis, the existing deep image inpainting algorithms focus more on improving visual quality, and they usually use structural loss and adversarial loss to constrain their operations. Consequently, with the continuous advancement of technology, the repair of damaged images with advanced image inpainting technology has become more in line with the vision of the human eye. In this process, the previous inpainting technology failed to consider the global deep image features of the image, and forensic technology could effectively locate the tampered area by using these non-uniform deep features.
The training data for the anti-forensic image inpainting network in this paper is generated by the inpainting algorithms DFNet [37], DGM [35] and PLI [36] presented in this subsection. In addition, refs. [35,36,37] are also used as comparison algorithms for the results in this paper.
2.2. Image Forensics
Currently, a large number of image forensics algorithms have emerged to identify the authenticity of images. Among these, references [42,43,44] are advanced general image forensics methods. These methods can forensically identify a variety of tampering methods and are able to forensically locate a number of manipulation methods, such as stitching, copy-move [45,46,47], etc. Current deep learning-based image inpainting is an operational technique that generates content in broken areas. Generic forensic algorithms are able to forensically locate part of the tampered regions in image inpainting. In this paper, we used the most common generic forensic algorithm, MT-Net [42], to forensically analyze the results of our experiments. MT-Net is a simple and effective full convolutional network, which is capable of learning the manipulation trace of images based on self-supervised training. In particular, MT-Net treats tamper localization as an anomaly detection problem and designs a comprehensive long and short-memory strategy to evaluate local anomalies.
In addition, Wu et al. [14] proposed an image inpainting detection network (IID-Net) for forensics methods of image inpainting to detect the inpainted regions at pixel accuracy. IID-Net is trained on a large amount of data for 10 typical inpainting algorithms, which allows the network to accurately detect and locate inpainting operations for a variety of invisible inpainting methods. Extensive experimental results demonstrated the superiority of the proposed IID-Net, compared to its state-of-the-art competitors.
In this paper, two different forensic algorithms, the aforementioned generic forensic algorithm MT-Net and the image inpainting detection network (IID-Net), are used to forensically analyze our experimental results.
3. Proposed Method
In this paper, we constructed an image anti-forensics framework that resists deep inpainting forensics, given in Figure 2. In particular, the masked image is fed to the existing deep inpainting networks (DFNet [37], DGM [35], PLI [36].) to produce the inpainted image. In most cases, these inpainted images can be detected by the deep forensics method IID-Net (see the binary map A in Figure 2). Hence, we proposed a Hierarchical Reconstruction Network (HR-Net) for reshaping the inpainted images to resist IID-Net detection (see the binary map B in Figure 2). In addition, we embedded the user’s identity information (ID) in the image reconstruction process, and recovered ID by the watermark decoder (WD). By employing this strategy, the copyright of the reconstructed image could be protected from being tampered with in the future. Next, we discuss HR-Net, as well as the loss functions, in detail.
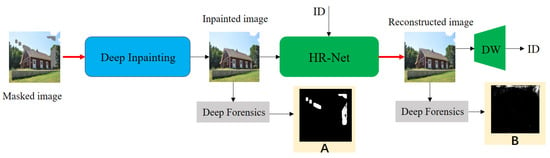
Figure 2.
Overview of our image anti-forensics architecture.
3.1. Hierarchical Reconstruction Network
The following three issues needed to be tackled for our HR-Net: (1) the reconstructed image had to be consistent in quality with the inpainted image; (2) the reconstructed image was resistant to analysis by forensic strategies; (3) the reconstructed image was protected by copyright. In view of this, the proposed RH-Net contained an encoder, an identity embedding (IE) module, a residual block, a hierarchical attention (HA) module, and a decoder. The overview of our proposed RH-Net is shown in Figure 3. Specifically, we first adopted the encoder to map the inpainted image to a latent space, which was then sent to the residual block to produce the deep feature . Where the residual block consisted of five standard residual layers, c, h, and w represented the number of channels, weight, and height. Meanwhile, our IE module inputted the ID information m of the user and fused it with the deep feature to produce , which was formulated as below:
where the IE module executes the cryptographic operation and the replicate operation sequentially. is used to transform m to the binary bits . l denotes the length of the binary bits . is adopt to make the spatial of equal to [3]. ⊕ is the concatenate operation. Next, the most conceivable solution was to employ a decoder to decode the fused feature into image space. Unfortunately, due to the entanglement of structure and texture in , the reconstructed image still contained the inpainted traces. Hence, we employed the proposed hierarchical attention (HA) module to distill the fused feature to remove the inpainted trace. The HA module contained the structure attention (SA) stream and the texture attention (TA) stream, which are given in Figure 4. We explain, in detail, the SA and TA streams below.
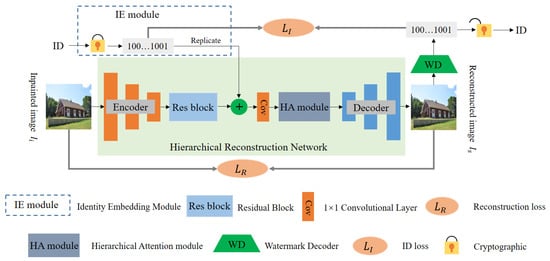
Figure 3.
Framework of the proposed HR-Net.
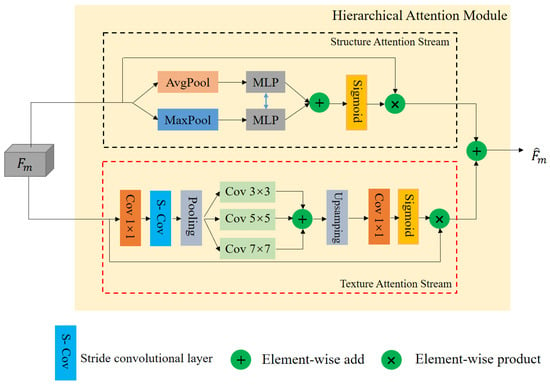
Figure 4.
Structure of the HA module.
3.2. Structure Attention Stream
We adopted the SA stream to distill the adaptive semantic feature on , shown in the black dotted box of Figure 4. Referring to [48], we introduced the channel-wise attention mechanism [49] to perform this process. In particular, was simultaneously fed to the AvgPool (global avg-pooling) layer and the MaxPool (global max-pooling) layer to obtain the channel features, and . Then, we adopted the shared MLP networks and Sigmoid operation to generate the channel feature map , which is given below:
where the MLP network consists of multi-layer perceptron. represent the Sigmoid operation. As a final step, and are multiplied to produce the structure feature by the dot product operation ⨂.
3.3. Texture Attention Stream
The TA stream wasused to purify the texture feature on , which is given in the red dotted box of Figure 4. In light of the fact that spatial attention was more effective at capturing texture features [49], we proposed a novel texture attention model, based on an existing approach [50]. Specifically, to reduce channel dimensions, our TA stream began with a 1 × 1 convolutional layer, which mace the whole stream extremely lightweight. Afterwards, we added a 2-stride convolution layer and a max-pooling layer to increase the receptive field, which is widely used in the image generation task [36]. After the pooling layer, we added a convolutional group with multi-layer convolutions to distill multi-scale texture features. According to [51], the proposed convolution group consisted of three parallel convolutional layers, each of which had a kernel size of 3 × 3, 5 × 5, and 7 × 7. To recover the spatial and channel dimensions, an upsampling layer and a 1 × 1 convolutional layer were added on top of the convolutional group. Lastly, the spatial feature map was obtained via the Sigmoid operation . As with the structure stream, and were multiplied to produce the textural feature by the dot product operation ⨂.
We refused the results of the structure stream and the texture stream to produce , which was then passed to the decoder for the final reconstructed image . Next, we describe the loss function according to the proposed HR-Net.
3.4. Loss Function
For joint supervision of our HR-Net, we adopted the ID loss and reconstruction loss t.
ID loss. The ID loss ensures that the embedded identity information of a user is correct extracted. We introduced the watermark decoder of [52] to recover the ID information. Our ID loss is formulated below:
where denotes the decoded ID information. is converted to the final ID information by the cryptographic operation.
Reconstruction loss. The reconstruction loss is commonly adopted in video and image conversion (image/video inpainting [36], image/video style transfer [53], etc.), which is used to ensure that the generated image is visually consistent with the original image. In this paper, we applied the reconstruction loss to constrain the visual differences between the reconstructed image and the inpainted image . consisted of image loss and deep feature loss, which is given below:
where represents the normal form. denotes the pre-trained VGG16 (excluding the fully connected layer).
Total loss. Our total loss is formulated by
where and denotes the coefficients of ID and reconstruction, respectively.
3.5. Implementation Details
In the hardware, four NVIDIA Tesla P100 GPUs and a CPU with Intel(R) Xeon(R) Silver 4110 (2.10 GHz) were used to implement the proposed anti-forensics framework. To train the HR-Net, we adopted Adam with the default parameters for optimizing. The size of the batch was set to 4. The length of ID was 10 bit. The hyper-parameters were set as and . In addition, as part of HR-Net, the encoder consisted of three down-sampling convolutional layers. Among these, each convolutional layer was followed by a Batch Normalization (BN) layer. Corresponding to the encoder, the decoder contained three up-sampling convolutional layers and three BN layers. Furthermore, the structure of the WD was derived from [3], which provided more details.
4. Experimental Results
We conducted many experiments to evaluate the proposed method. First, we clarified the experimental settings, including the dataset and the detailed network implementation. Then, we provided a comprehensive performance analysis on HR-Net against state-of-the-art image forensics schemes.
4.1. Experimental Setup
Datasets. We adopted the Places2 [54] and Mask [38] as the training datasets, commonly used for image inpainting. The Places2 dataset [54] is published by MIT and contains over 8,000,000 images from over 365 scenes and the model can learn from a large number of different natural scenes from this dataset, making the model extremely suitable for the field of image inpainting. We split the datasets into training data and testing data in a ratio of 9:1. During training, all video frames were resized to 256 × 256.
Evaluation Metrics. To verify the anti-forensic performance of HR-Net, the TP and F1 scores of the experimental results were calculated. Where True Position (TP) indicated a correct prediction of positive samples. This metric could directly demonstrate the ability of the anti-forensic algorithm results to hide tampered regions. In addition, the F1 score could report overall accuracy of previous forensics schemes on the images produced by HR-Net. The definition of F1 score is:
where TP stands for True Positive rate, FN stands for False Negative rate, and FP stands for False Positive rate. The smaller F1 value represents a better anti-forensics capability.
Benchmark. We compared the proposed HR-Net with the image inpainting algorithm to show the effectiveness in resisting forensics. We adopted PLI [36], DFM [35], DFNet [37] as the image inpainting schemes, which can manipulate high quality image.
Additionally, two forensic algorithms [14,42], were used to verify the ability of our HR-Net to resist forensics. Image Inpainting Detection Network (IID-Net) [14] is a forensic algorithm proposed specifically for image inpainting, with strong tampering detection capabilities for any image inpainting algorithm. MT-Net [42] is a general and common forensic algorithm. We used two different classes of forensic algorithms, IID-Net and MT-Net, to verify that the forensic resistance of the inpainting results was comprehensive and adequate.
The inpainting results of [35,36,37] and the forensic results of [14,42] were implemented via source codes provided by the authors.
4.2. Quality Analysis
We first evaluated the visual quality of generated image. Figure 5 shows two sets of examples, each containing the inpainting results of the three inpainting algorithms (PLI [36], DGM [35], DFNet [37]) and the results of HR-Net network. The results showed that the results generated by the HR-Net network were very similar to the direct inpainting results, and it was difficult to distinguish the authenticity of the inpainting results. In short, when users shared the HR-Net-generated images, it was difficult for the recipients to visually detect the difference between them and the real images.

Figure 5.
Visual quality comparison. (a) denotes masked image, (b,d,f) represent the inpainted result of PLI, DGM and DFNet respectively, (c,e,g) indicate the result of reconstruction of (b,d,f) through HR-Net.
4.3. Forensics Analysis
In addition to an intuitive visual anti-forensic analysis of the generated results, this subsection presents a forensic analysis of the inpainting results of the three inpainting algorithms (PLI [36], DGM [35], DFNet [37]) and the corresponding HR-Net generated results by two forensic algorithms (MT-Net [42] and IID-Net [14]). The results are presented in Figure 6, Figure 7 and Figure 8, respectively.

Figure 6.
Forensic results of PLI and HR-Net(Ours). (a) are the original images with damage regions (see the red masks). (b) are the inpainted results of PLI, (c,d) denote the forensics results of MT-Net and IID-Net on (b), respectively. (e) are the results of HR-Net, (f,g) denote the forensics results of MT-Net and IID-Net on (e), respectively.

Figure 7.
Forensic results of DGM and HR-Net (Ours). (a) are the original images with damage regions (see the red masks). (b) are the inpainted results of DGM, (c,d) denote the forensics results of MT-Net and IID-Net on (b), respectively. (e) are the results of HR-Net, (f,g) denote the forensics results of MT-Net and IID-Net on (e), respectively.

Figure 8.
Forensic results of DFNet and HR-Net(Ours). (a) are the original images with damage regions (see the red masks). (b) are the inpainted results of DFNet, (c,d) denote the forensics results of MT-Net and IID-Net on (b), respectively. (e) are the results of HR-Net, (f,g) denote the forensics results of MT-Net and IID-Net on (e), respectively.
Figure 6b, Figure 7b and Figure 8b show the forensic analysis of the broken images inpainted directly by PLI [36], DGM [35], and DFNet [37], respectively. Figure 6c, Figure 7c and Figure 8c show the MT-Net forensic results for Figure 6b, Figure 7b and Figure 8b, in which the entire broken area was basically successfully forensically analyzed, except for the inpainted edge area, which was not very clearly localized. In addition, as seen in Figure 6c, Figure 7c and Figure 8c, the inpainting results of the three inpainting algorithms could hardly circumvent the forensics of IID-Net, and their forensic regions almost overlapped with the ground truth.
The inpainting results reconstructed via HR-Net in this paper are shown in Figure 6e, Figure 7e and Figure 8e, where visually they do not differ much from the direct inpainting results. For the forensic analysis of Figure 6e, Figure 7e and Figure 8e, Figure 6f, Figure 7f and Figure 8f are the MT-Net forensic result of Figure 6e, Figure 7e and Figure 8e, where the white part indicates the suspected tampering areas detected by this forensic network. Figure 6f, Figure 7f and Figure 8f show a large number of mislocated areas, some of which even circumvented the correct tampering areas, such as the first row of Figure 6f and the first row of Figure 7f. We considered such forensic localisation to be invalid and the results showed that the results obtained by HR-Net could circumvent the forensics of the generic forensic algorithm MT-Net. In addition, IID-Net, a forensic network designed specifically for inpainting, had forensic results that were almost close to all-black. This indicated that IID-Net considered that Figure 6e, Figure 7e and Figure 8e did not exist for inpainting operations.
In addition, we also performed a quantitative analysis of the forensic results, and Figure 9 shows a comparison of the F1 and TP scores. Where the left column Figure 9a–c indicates the F1 scores of the three inpainting algorithms for different forensic algorithms, the horizontal coordinates indicate the number of images computed and the vertical coordinates indicate the F1 scores. The yellow and blue dashes indicate the F1 scores of the MT-Net for PLI inpainting results and HR-Net generated results, respectively. The grey and orange dashes indicate the F1 scores of the IID-Net for PLI inpainting results and HR-Net generation results, respectively. The right column Figure 9d–f indicates the probability of the forensic algorithm correctly locating the tampered region (TP), with its vertical coordinate indicating the TP score, and the rest similar to the left.
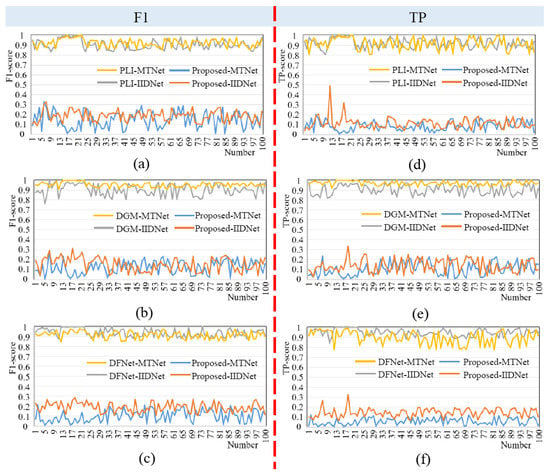
Figure 9.
F1 and TP score comparison. (a–c) represents the F1 scores of PLI, DGM and DFNet respectively, (d–f) are represents the TP scores of PLI, DGM and DFNet respectively.
As can be seen from the quantitative analysis in Figure 9, the results inpainted directly by the inpainting algorithm were highly susceptible to forensic localization and lacked security. The existing deep image inpainting algorithms focus more on improving visual quality, and they usually use structural loss and adversarial loss to constrain their operations. Consequently, with the continuous advancement of technology, the repair of damaged images with advanced image restoration technology has become more in line with the vision of the human eye. In this process, the previous inpainting technology did not consider the global deep image features of the image, and forensic technology could effectively locate the tampered area by using these non-uniform deep features. The probability of being correctly located was generally greater than 80%, and in some cases even reached 100%. The results generated by HR-Net significantly reduced the probability of the results being forensically located to less than 20%. The results showed that the method proposed in this paper was forensically resistant and improved the security of the inpainting results.
5. Privacy Protection
In this Subsection, we show that our privacy protection method was effective during communication or sharing. To this end, we gave six sets of comparisons between the reconstructed images (see (b) in the Figure 10) and the original inpainted images (see (a) in the Figure 10). The original inpainted images were embedded with 10bit identity information to obtain the reconstructed images by the proposed HR-Net. As can be seen from the comparison results, the reconstruction results were very similar to the original inpainted images in visual appearance. At the same time, the user could use the watermark decoder to correctly extract the identity information. This showed that, compared with the traditional inpainted image, the copyright of our generated image was protected.

Figure 10.
Examples for privacy protection. (a) Original inpainted images; (b) Reconstructed images.
The identity information of the operator was embedded in the anti-forensic process for the purpose of privacy protection. The inpainted image after the anti-forensic operation was difficult to locate forensically by relevant forensic techniques and could easily be considered as the original image and be widely distributed. In addition to alerting the sharer to the fact that the image had been tampered with twice, the embedding of identity information could also serve as a side warning to the user of the fact that the image was a forgery.
6. Conclusions
In this paper, we proposed a general anti-forensics framework, based on deep image inpainting. Our method not only generated high-quality inpainting results, but also resisted detection by forensic algorithms. In addition, the generated images were also copyrighted because they included a watermark. For this reason, we designed HR-Net to reconstruct arbitrary deep inpainted images. Specifically, in the codec structure of HR-Net, we constructed two parallel attention streams: SA and TA. The SA stream was used to distill the semantic feature. We employed the TA stream to purify the texture feature. The aforementioned hierarchical features were fused to generate more robust inpainting results, in which the regions that had been tampered with could avoid detection. Furthermore, we embedded the identity information of users during image reconstruction to protect the copyright of the generated images. Rigorous experimental analysis and comparison with contrasting methods demonstrated the effectiveness of the proposed method. The limitation of our work was that it did not consider the robustness of anti-forensics, and we will address this issue in the future.
Author Contributions
Writing—original draft, L.D.; Supervision, G.F.; Funding acquisition, Z.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Natural Science Foundation of China under Grant U20B2051 and 61572308.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Itier, V.; Strauss, O.; Morel, L.; Puech, W. Color noise correlation-based splicing detection for image forensics. Multim. Tools Appl. 2021, 80, 13215–13233. [Google Scholar] [CrossRef]
- Jaiswal, A.K.; Srivastava, R. Forensic image analysis using inconsistent noise pattern. Pattern Anal. Appl. 2021, 24, 655–667. [Google Scholar] [CrossRef]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-Based Camera Model Fingerprint. IEEE Trans. Inf. Forensics Secur. 2020, 15, 144–159. [Google Scholar] [CrossRef]
- Lin, X.; Li, C. On Constructing A Better Correlation Predictor For Prnu-Based Image Forgery Localization. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo, ICME 2021, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Dou, L.; Qian, Z.; Qin, C.; Feng, G.; Zhang, X. Anti-forensics of diffusion-based image inpainting. J. Electron. Imaging 2020, 29, 043026. [Google Scholar] [CrossRef]
- Bertalmío, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 2000, New Orleans, LA, USA, 23–28 July 2000; Brown, J.R., Akeley, K., Eds.; 2000; pp. 417–424. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. EdgeConnect: Structure Guided Image Inpainting using Edge Prediction. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops, ICCV Workshops 2019, Seoul, Republic of Korea, 27–28 October 2019; pp. 3265–3274. [Google Scholar]
- Wang, N.; Zhang, Y.; Zhang, L. Dynamic Selection Network for Image Inpainting. IEEE Trans. Image Process. 2021, 30, 1784–1798. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Luo, W.; Huang, J. Localization of Diffusion-Based Inpainting in Digital Images. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3050–3064. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, T.; Cattani, C.; Cui, Q.; Liu, S. Diffusion-based image inpainting forensics via weighted least squares filtering enhancement. Multim. Tools Appl. 2021, 80, 30725–30739. [Google Scholar] [CrossRef]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Image Copy-Move Forgery Detection via an End-to-End Deep Neural Network. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, WACV 2018, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1907–1915. [Google Scholar]
- Mayer, O.; Stamm, M.C. Forensic Similarity for Digital Images. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1331–1346. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, C.; Yan, G.; Guo, Y.; Dong, Y. AR-Net: Adaptive Attention and Residual Refinement Network for Copy-Move Forgery Detection. IEEE Trans. Ind. Inform. 2020, 16, 6714–6723. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J. IID-Net: Image Inpainting Detection Network via Neural Architecture Search and Attention. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1172–1185. [Google Scholar] [CrossRef]
- Böhme, R.; Kirchner, M. Counter-Forensics: Attacking Image Forensics. In Digital Image Forensics; Springer: Berlin/Heidelberg, Germany, 2012; pp. 327–366. [Google Scholar]
- Barni, M.; Stamm, M.C.; Tondi, B. Adversarial Multimedia Forensics: Overview and Challenges Ahead. In Proceedings of the 26th European Signal Processing Conference, EUSIPCO 2018, Roma, Italy, 3–7 September 2018; pp. 962–966. [Google Scholar]
- Qian, Z.; Zhang, X. Improved anti-forensics of JPEG compression. J. Syst. Softw. 2014, 91, 100–108. [Google Scholar] [CrossRef]
- Wu, Z.; Stamm, M.C.; Liu, K.J.R. Anti-forensics of median filtering. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2013, Vancouver, BC, Canada, 26–31 May 2013; pp. 3043–3047. [Google Scholar]
- Stamm, M.C.; Tjoa, S.K.; Lin, W.S.; Liu, K.J.R. Anti-forensics of JPEG compression. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2010, Dallas, TX, USA, 14–19 March 2010; pp. 1694–1697. [Google Scholar]
- Fan, Z.; de Queiroz, R.L. Identification of bitmap compression history: JPEG detection and quantizer estimation. IEEE Trans. Image Process. 2003, 12, 230–235. [Google Scholar] [PubMed]
- Fan, W.; Wang, K.; Cayre, F.; Xiong, Z. Median Filtered Image Quality Enhancement and Anti-Forensics via Variational Deconvolution. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1076–1091. [Google Scholar] [CrossRef]
- Amerini, I.; Barni, M.; Caldelli, R.; Costanzo, A. Counter-forensics of SIFT-based copy-move detection by means of keypoint classification. EURASIP J. Image Video Process. 2013, 2013, 18. [Google Scholar] [CrossRef]
- Gloe, T.; Kirchner, M.; Winkler, A.; Böhme, R. Can we trust digital image forensics? In Proceedings of the 15th International Conference on Multimedia 2007, Augsburg, Germany, 24–29 September 2007; Lienhart, R., Prasad, A.R., Hanjalic, A., Choi, S., Bailey, B.P., Sebe, N., Eds.; 2007; pp. 78–86. [Google Scholar]
- Goljan, M.; Fridrich, J.J.; Chen, M. Sensor noise camera identification: Countering counter-forensics. In Proceedings of the Media Forensics and Security II, Part of the IS&T-SPIE Electronic Imaging Symposium, San Jose, CA, USA, 18–20 January 2010; Memon, N.D., Dittmann, J., Alattar, A.M., Delp, E.J., Eds.; 2010; Volume 7541, p. 75410S. [Google Scholar]
- Karaküçük, A.; Dirik, A.E. Adaptive photo-response non-uniformity noise removal against image source attribution. Digit. Investig. 2015, 12, 66–76. [Google Scholar] [CrossRef]
- Huang, Y. Can digital image forgery detection be unevadable? A case study: Color filter array interpolation statistical feature recovery. In Proceedings of the Visual Communications and Image Processing, Beijing, China, 12–15 July 2005; Volume 5960, pp. 980–991. [Google Scholar]
- Kirchner, M.; Böhme, R. Synthesis of color filter array pattern in digital images. In Proceedings of the Media Forensics and Security I, Part of the IS&T-SPIE Electronic Imaging Symposium, San Jose, CA, USA, 19–21 January 2009; Delp, E.J., Dittmann, J., Memon, N.D., Wong, P.W., Eds.; Volume 7254, p. 72540K. [Google Scholar]
- Stamm, M.C.; Liu, K.J.R. Protection against reverse engineering in digital cameras. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2013, Vancouver, BC, Canada, 26–31 May 2013; pp. 8702–8706. [Google Scholar]
- Zhang, X.; Karaman, S.; Chang, S. Detecting and Simulating Artifacts in GAN Fake Images. In Proceedings of the IEEE International Workshop on Information Forensics and Security, WIFS 2019, Delft, The Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar]
- Du, M.; Pentyala, S.K.; Li, Y.; Hu, X. Towards Generalizable Deepfake Detection with Locality-aware AutoEncoder. In Proceedings of the CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, 19–23 October 2020; d’Aquin, M., Dietze, S., Hauff, C., Curry, E., Cudré-Mauroux, P., Eds.; pp. 325–334. [Google Scholar]
- Wang, S.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-Generated Images Are Surprisingly Easy to Spot…for Now. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 8692–8701. [Google Scholar]
- Neves, J.C.; Tolosana, R.; Vera-Rodríguez, R.; Lopes, V.; Proença, H.; Fiérrez, J. GANprintR: Improved Fakes and Evaluation of the State of the Art in Face Manipulation Detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1038–1048. [Google Scholar] [CrossRef]
- Cozzolino, D.; Thies, J.; Rössler, A.; Nießner, M.; Verdoliva, L. SpoC: Spoofing Camera Fingerprints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2021, Virtual, 19–25 June 2021; pp. 990–1000. [Google Scholar]
- Wu, J.; Sun, W. Towards multi-operation image anti-forensics with generative adversarial networks. Comput. Secur. 2021, 100, 102083. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J.; Li, Y. Deep Generative Model for Image Inpainting With Local Binary Pattern Learning and Spatial Attention. IEEE Trans. Multim. 2022, 24, 4016–4027. [Google Scholar] [CrossRef]
- Zheng, C.; Cham, T.; Cai, J. Pluralistic Image Completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 1438–1447. [Google Scholar]
- Hong, X.; Xiong, P.; Ji, R.; Fan, H. Deep Fusion Network for Image Completion. In Proceedings of the 27th ACM International Conference on Multimedia, MM 2019, Nice, France, 21–25 October 2019; Amsaleg, L., Huet, B., Larson, M.A., Gravier, G., Hung, H., Ngo, C., Ooi, W.T., Eds.; pp. 2033–2042. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.; Tao, A.; Catanzaro, B. Image Inpainting for Irregular Holes Using Partial Convolutions. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11215, pp. 89–105. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Suin, M.; Purohit, K.; Rajagopalan, A.N. Distillation-guided Image Inpainting. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 2461–2470. [Google Scholar]
- Zhang, H.; Hu, Z.; Luo, C.; Zuo, W.; Wang, M. Semantic Image Inpainting with Progressive Generative Networks. In Proceedings of the 2018 ACM Multimedia Conference on Multimedia Conference, MM 2018, Seoul, Republic of Korea, 22–26 October 2018; pp. 1939–1947. [Google Scholar]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries With Anomalous Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 9543–9552. [Google Scholar]
- Dong, C.; Chen, X.; Hu, R.; Cao, J.; Li, X. MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection. arXiv 2021, arXiv:2112.08935. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J.; Tian, J.; Liu, J. Robust Image Forgery Detection over Online Social Network Shared Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 13430–13439. [Google Scholar]
- Rodríguez-Ortega, Y.; Ballesteros, D.M.; Renza, D. Copy-Move Forgery Detection (CMFD) Using Deep Learning for Image and Video Forensics. J. Imaging 2021, 7, 59. [Google Scholar] [CrossRef]
- Zhong, J.; Pun, C. An End-to-End Dense-InceptionNet for Image Copy-Move Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2134–2146. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, J. Fast and Effective Image Copy-Move Forgery Detection via Hierarchical Feature Point Matching. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1307–1322. [Google Scholar] [CrossRef]
- Qiao, Y.; Liu, Y.; Yang, X.; Zhou, D.; Xu, M.; Zhang, Q.; Wei, X. Attention-Guided Hierarchical Structure Aggregation for Image Matting. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 13673–13682. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual Feature Aggregation Network for Image Super-Resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 2356–2365. [Google Scholar]
- Wang, Y.; Tao, X.; Qi, X.; Shen, X.; Jia, J. Image Inpainting via Generative Multi-column Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; pp. 329–338. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. HiDDeN: Hiding Data With Deep Networks. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11219, pp. 682–697. [Google Scholar]
- Wang, Q.; Li, S.; Zhang, X.; Feng, G. Multi-granularity Brushstrokes Network for Universal Style Transfer. ACM Trans. Multim. Comput. Commun. Appl. 2022, 18, 107:1–107:17. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, À.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).