

A Novel Hybrid MSA-CSA Algorithm for Cloud Computing Task Scheduling Problems



Abstract
:1. Introduction
- A novel adaptive approach for optimal task transfer in CC is proposed to minimize the transfer of task time across available resources.
- A hybrid model-based scheduling framework is designed to achieve efficient task scheduling in CC while ensuring data security.
- This work proposes a novel scheduling model to enhance the efficiency of task scheduling while ensuring data security in the CC model. The framework is based on hybrid MSA-CSA models.
- The scheduling of tasks in the cloud incorporates P-AES to ensure data security.
- A scheduling algorithm that uses a hybrid meta-heuristic technique with low complexity has been developed and shows significant improvements in makespan, cost, degree of imbalance, resource utilization, average waiting time, response time, throughput, latency, execution time, speed, and bandwidth utilization.
2. Literature Review
3. Problem Statement and Formulation
3.1. Decision Variables
3.2. Objective Function
3.2.1. Minimize the Maximum Execution Time
3.2.2. Maximize the Throughput
3.2.3. Minimize the Average Execution Time
3.2.4. Maximize the Total Bandwidth Usage
3.2.5. Minimize the Total Cost
3.2.6. Minimize the Total Execution Time
3.3. Constraints
3.3.1. Security Constraints
- a
- Confidentiality constraint: All data must be encrypted during transmission and storage.
- b
- Integrity constraint: Data must not be modified during transmission or storage.
- c
- Availability constraint: The cloud system must be available for task scheduling at all times.
3.3.2. Resource Availability Constraints
- CPU constraints
- Memory constraint
- Storage constraint
- Network bandwidth constraint
3.3.3. Deadline Constraint
3.3.4. Makespan Constraint
3.3.5. Throughput Constraint
3.3.6. Latency Constraint
3.3.7. Bandwidth Constraint
3.3.8. Cost Constraint
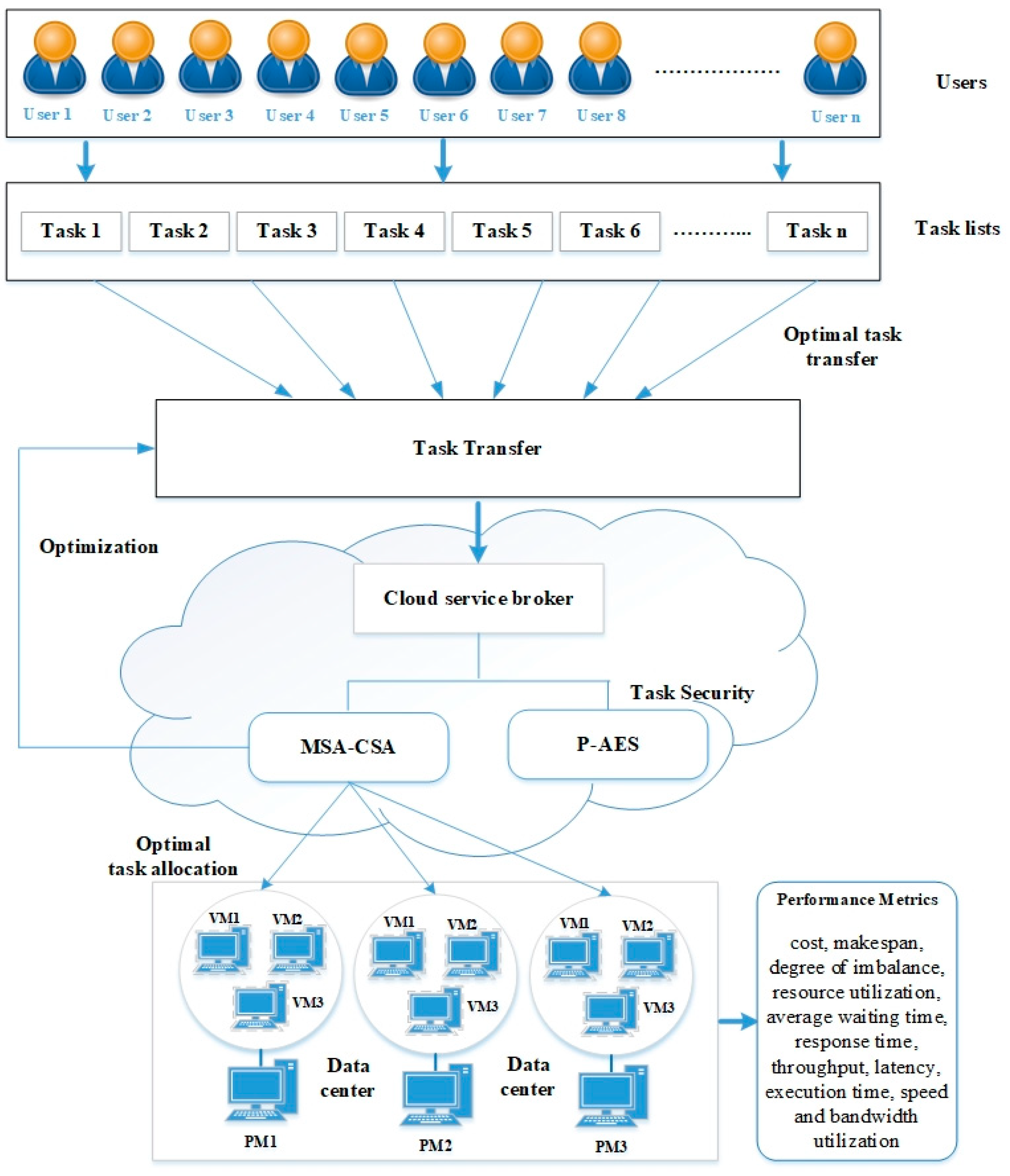
4. Scheduling of Tasks in the Cloud
4.1. Security Strategy
Polymorphic Advances Encryption Standard (P-AES)
4.2. MSA
4.2.1. Pathfinder Phase
4.2.2. Choice of Crossover Points
4.2.3. Lévy Mutation
4.2.4. Position Update
4.2.5. Prospector Phase
4.2.6. Onlooker Phase
4.2.7. Gaussian Walks
4.2.8. Associative Learning Mechanism with Immediate Memory
4.3. CSA
4.3.1. Evaluation of Initialization and Function
4.3.2. Searching for a Target
4.3.3. Eyes Rotation of Chameleon
- The initial location or starting point of the chameleon is the center of gravity or focal point.
- The location of the prey can be identified by computing the rotation matrix.
- The location of the chameleon at the focal point is updated using the rotation matrix.
- Finally, they are brought back to their initial position.
4.3.4. Hunt of Target
4.4. Optimized Task Scheduling Using Hybrid MSA-CSA
| Algorithm 1: Pseudo code for MSA-CSA |
| function hybridMSACSA(taskList, VMList, PMList): // Initialize MSA parameters MSA_maxIterations = 100 MSA_populationSize = 50 MSA_c1 = 1.5 MSA_c2 = 1.5 MSA_w = 0.8 // Initialize CSA parameters CSA_maxGenerations = 50 CSA_populationSize = 30 CSA_mutationRate = 0.01 // Initialize hybrid algorithm parameters hybrid_iterations = 10 hybrid_populationSize = 20 // Initialize global best solution globalBestSolution = null globalBestFitness = INF // Run hybrid algorithm for a fixed number of iterations for i = 1 to hybrid_iterations: // Run MSA to optimize task assignment to VMs MSA_solutions = initializeMSA(MSA_populationSize) MSA_globalBestSolution = null MSA_globalBestFitness = INF for j = 1 to MSA_maxIterations: for each solution in MSA_solutions: fitness = evaluateFitness(solution, taskList, VMList) if fitness < MSA_globalBestFitness: MSA_globalBestSolution = solution MSA_globalBestFitness = fitness updateMSAPositions(MSA_solutions, MSA_globalBestSolution, MSA_c1, MSA_c2, MSA_w) // Run CSA to optimize allocation of VMs to PMs CSA_population = initializeCSA(CSA_populationSize) CSA_globalBestSolution = null CSA_globalBestFitness = INF for k = 1 to CSA_maxGenerations: for each chameleon in CSA_population: fitness = evaluateFitness(chameleon, VMList, PMList) if fitness < CSA_globalBestFitness: CSA_globalBestSolution = chameleon CSA_globalBestFitness = fitness mutateCSA(CSA_population, CSA_globalBestSolution, CSA_mutationRate) // Combine MSA and CSA solutions to create hybrid solution hybridSolution = combineSolutions(MSA_globalBestSolution, CSA_globalBestSolution) hybridFitness = evaluateHybridFitness(hybridSolution, taskList, VMList, PMList) // Update global best solution for the hybrid algorithm if hybridFitness < globalBestFitness: globalBestSolution = hybridSolution globalBestFitness = hybridFitness return globalBestSolution |
5. Experimental Results and Analysis
5.1. Experimental Environment
5.2. Parameter Setting
5.3. Evaluation Parameters
5.4. Discussion on the Comparison
5.4.1. Makespan Result
5.4.2. Degree of Imbalance Result
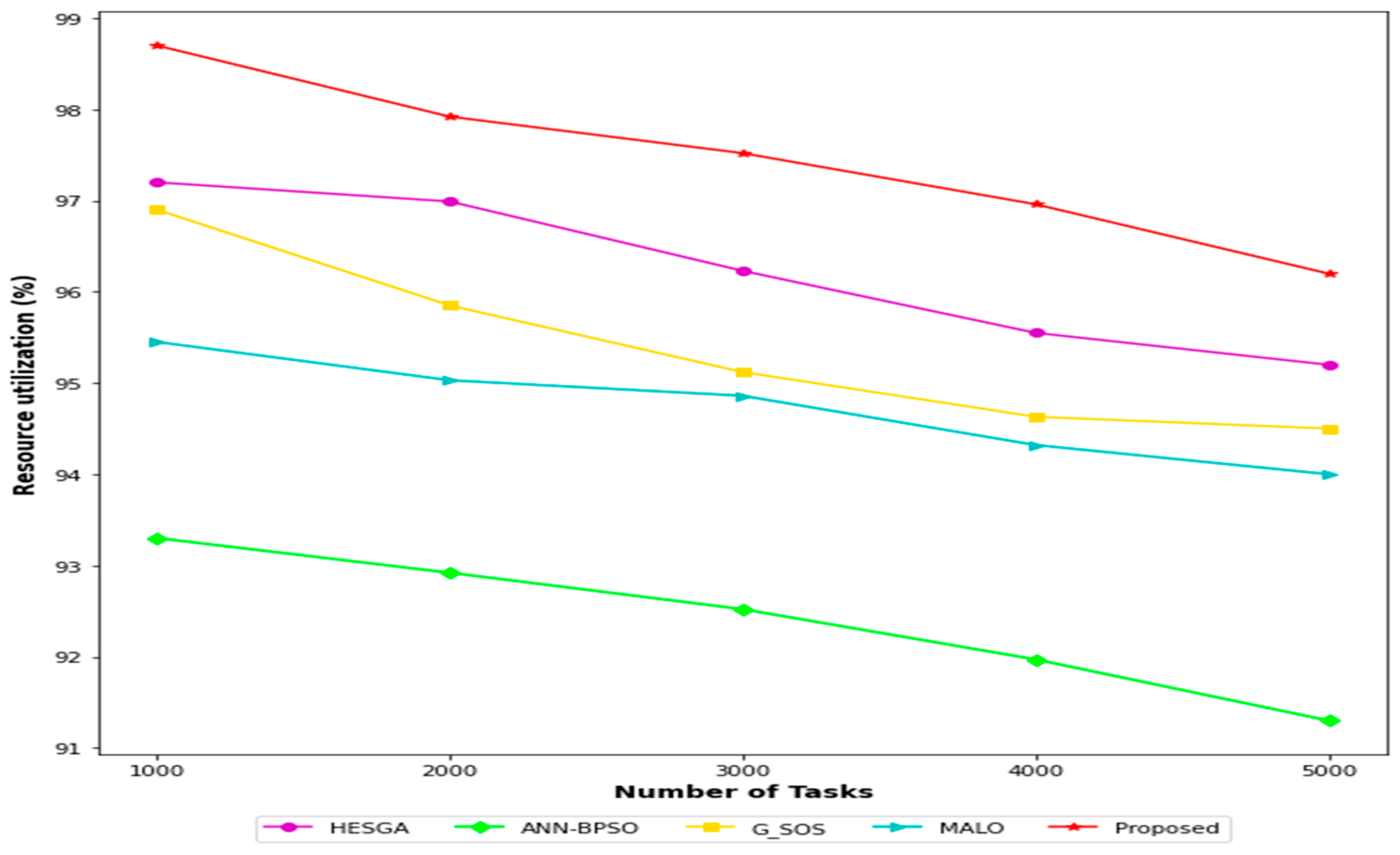
5.4.3. Resource Utilization Result
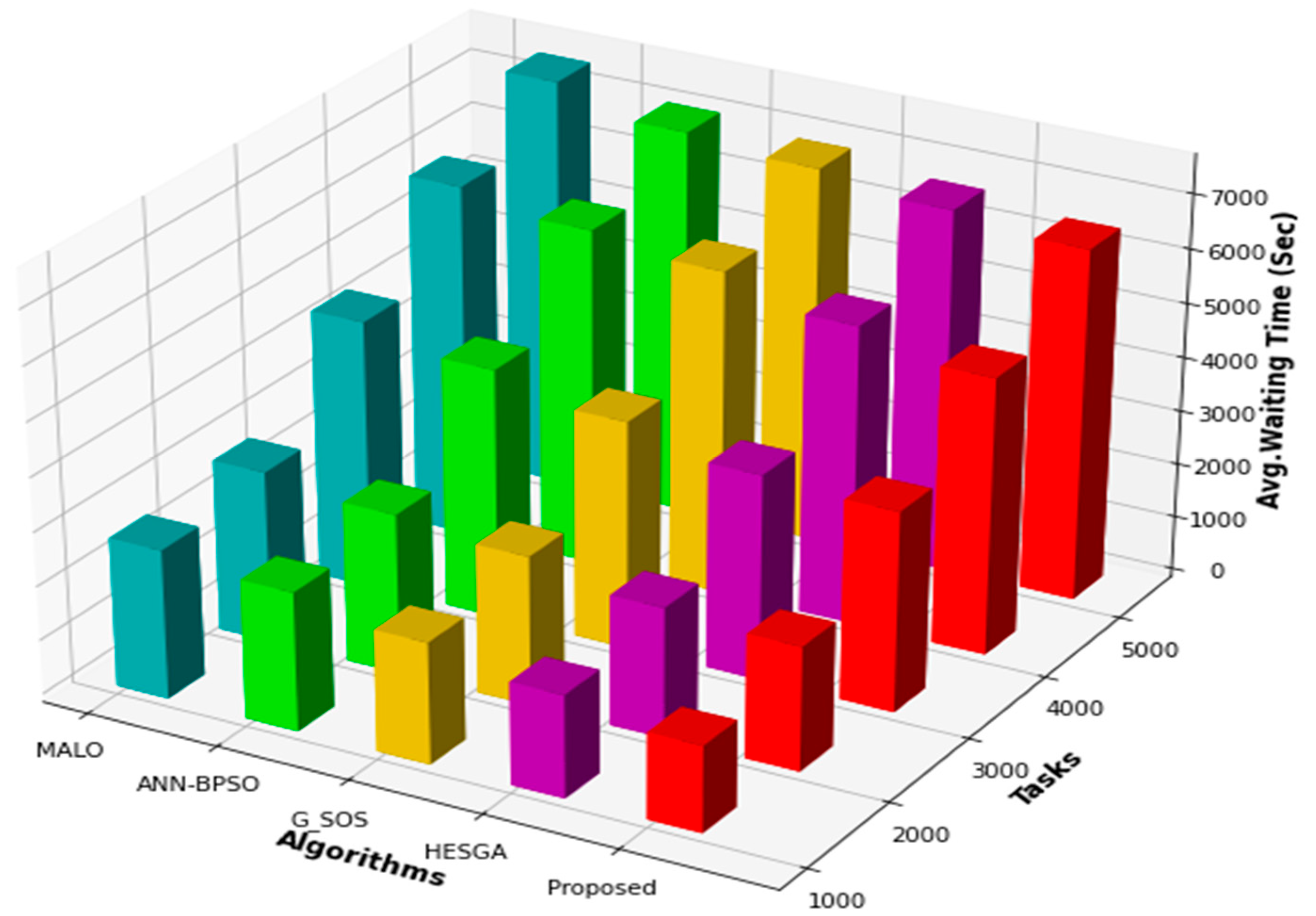
5.4.4. Average Waiting Time
5.4.5. Cost Result
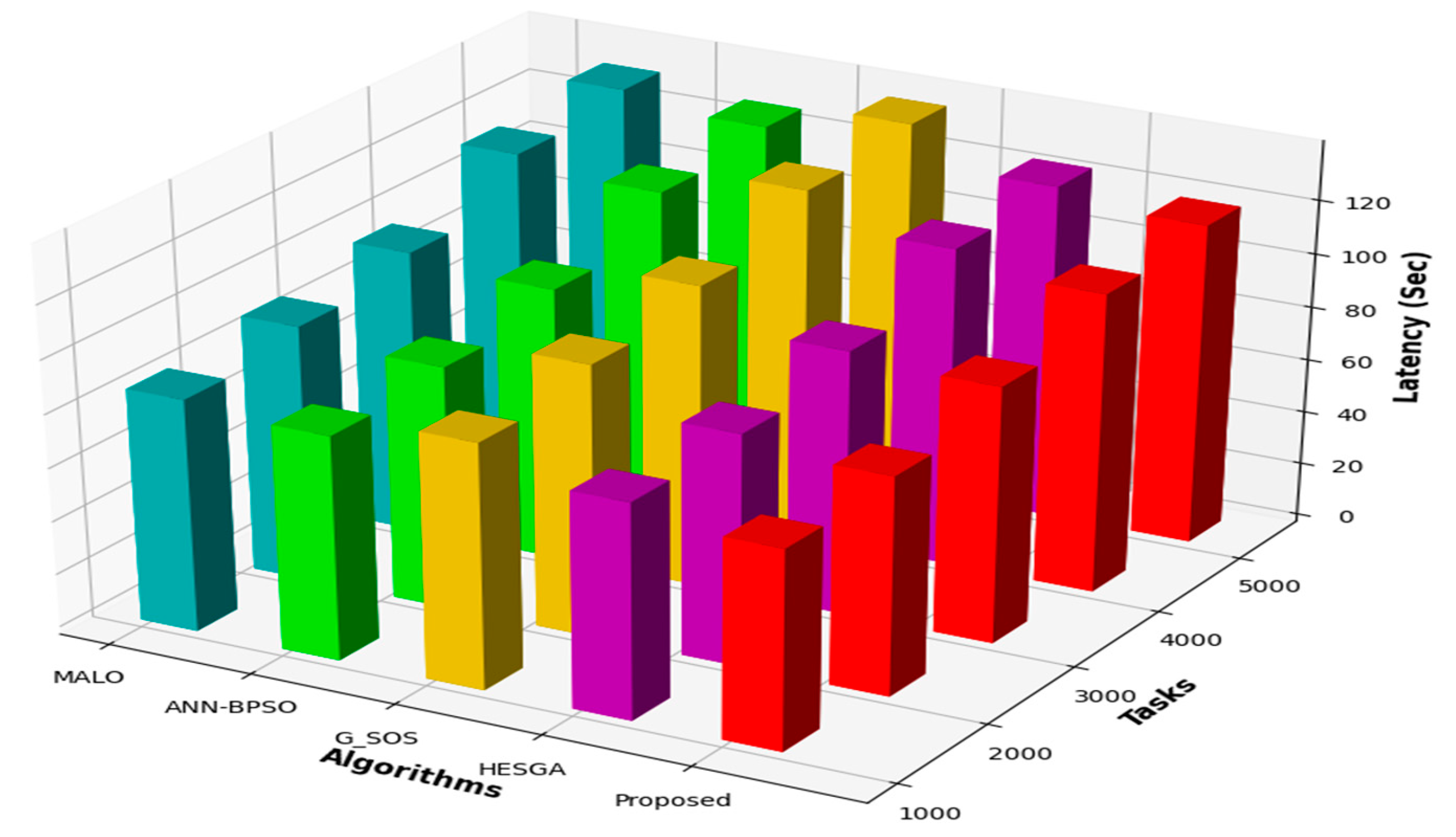
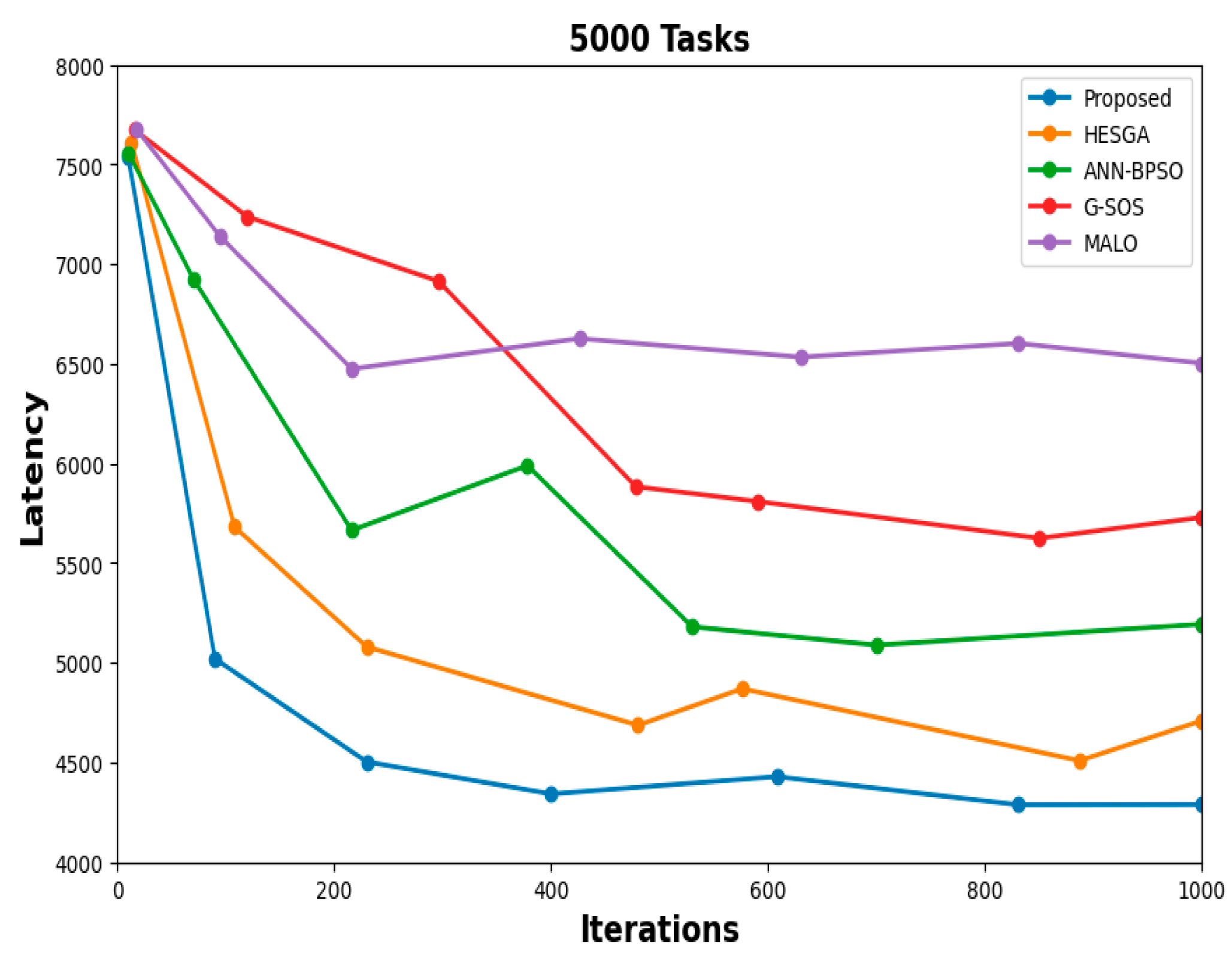
5.4.6. Latency Result
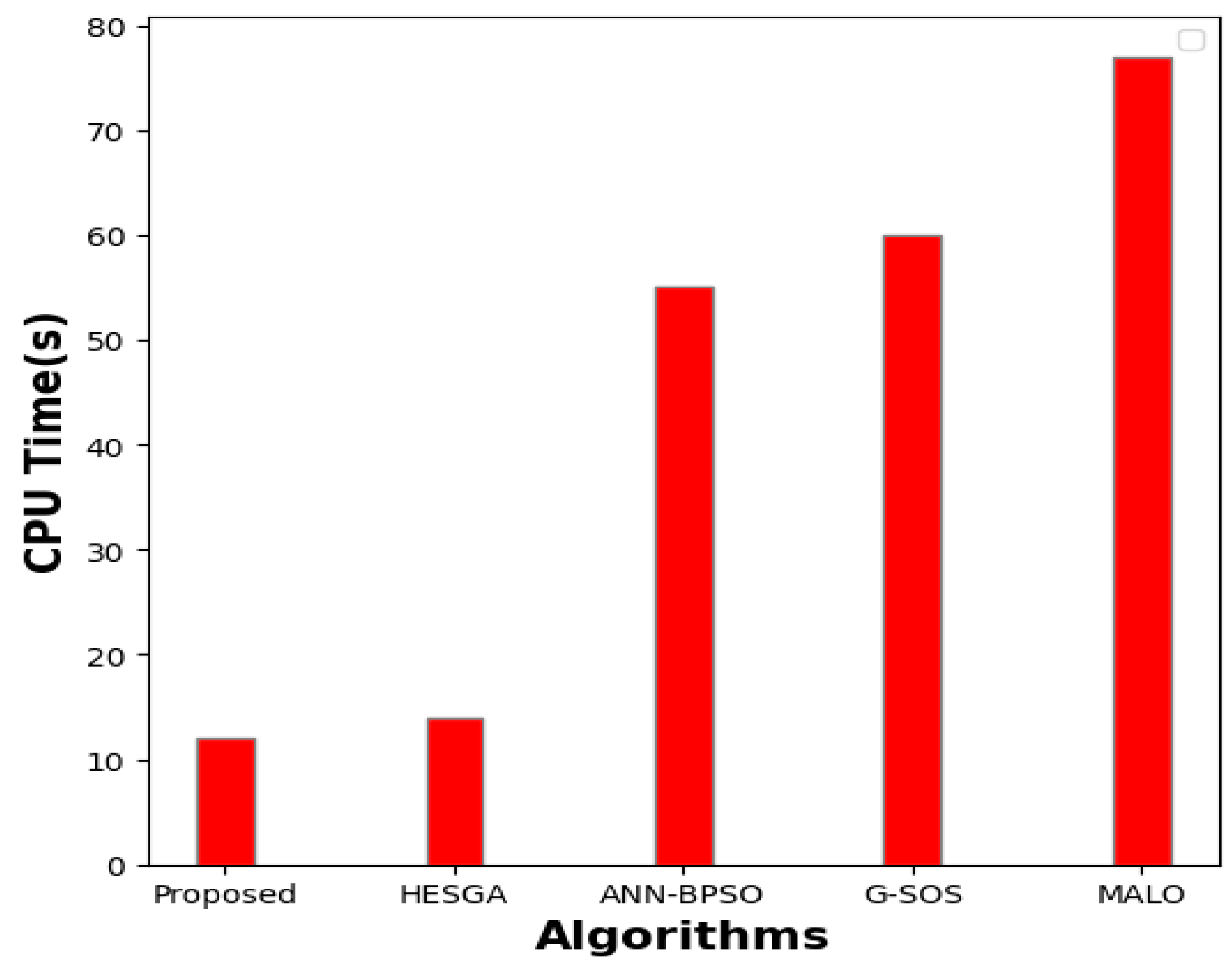
5.4.7. Execution Time
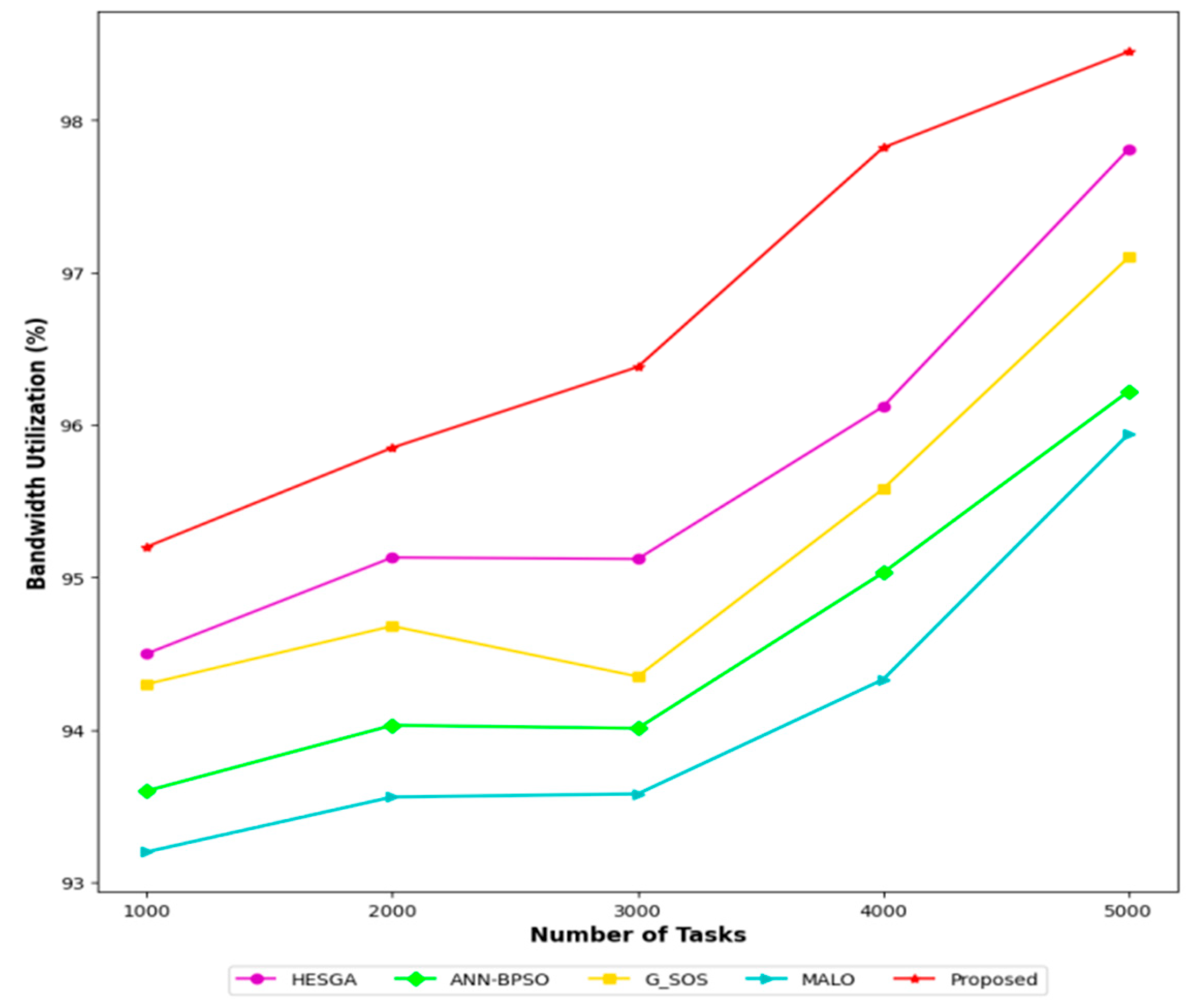
5.4.8. Bandwidth Utilization
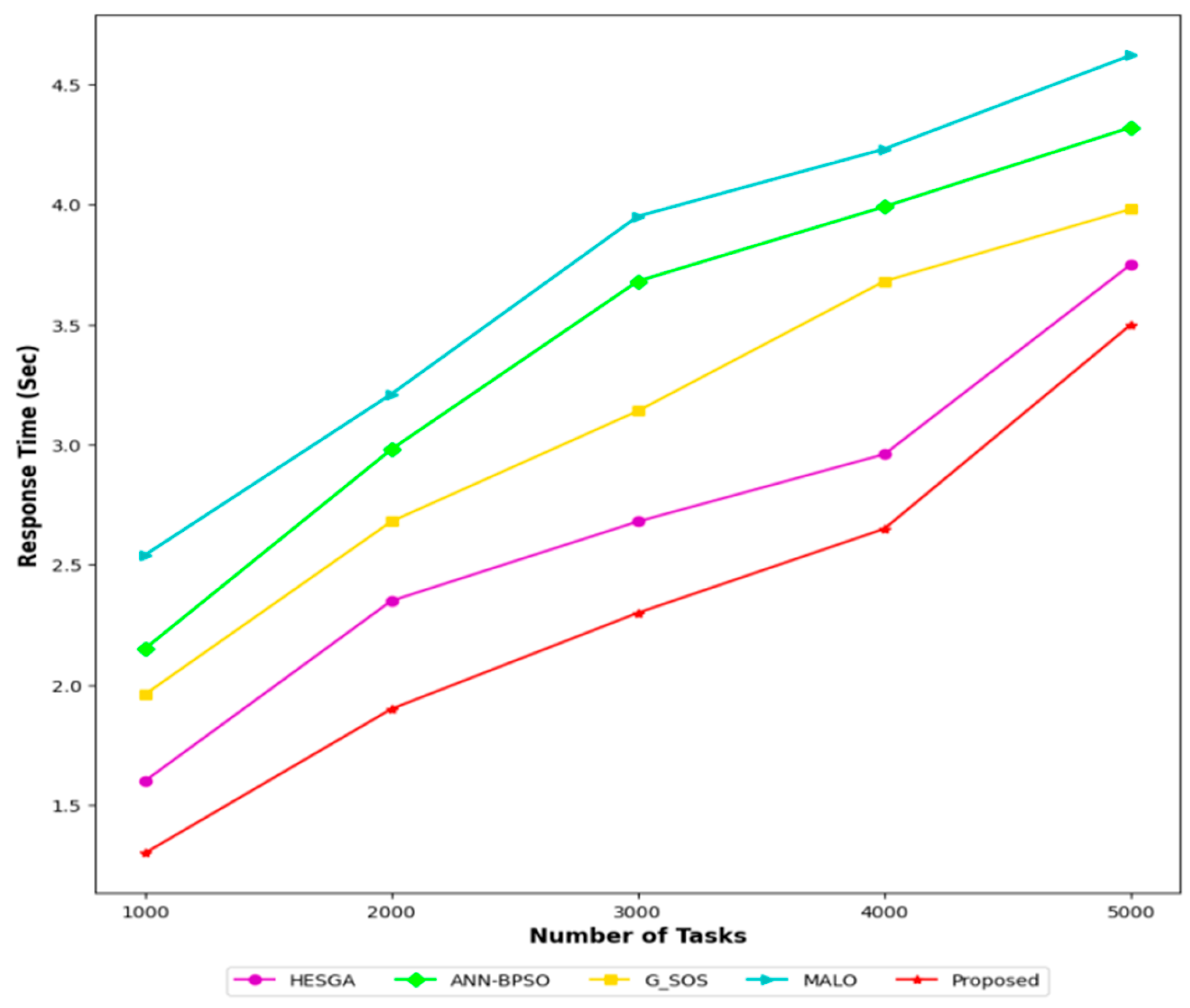
5.4.9. Response Time Result
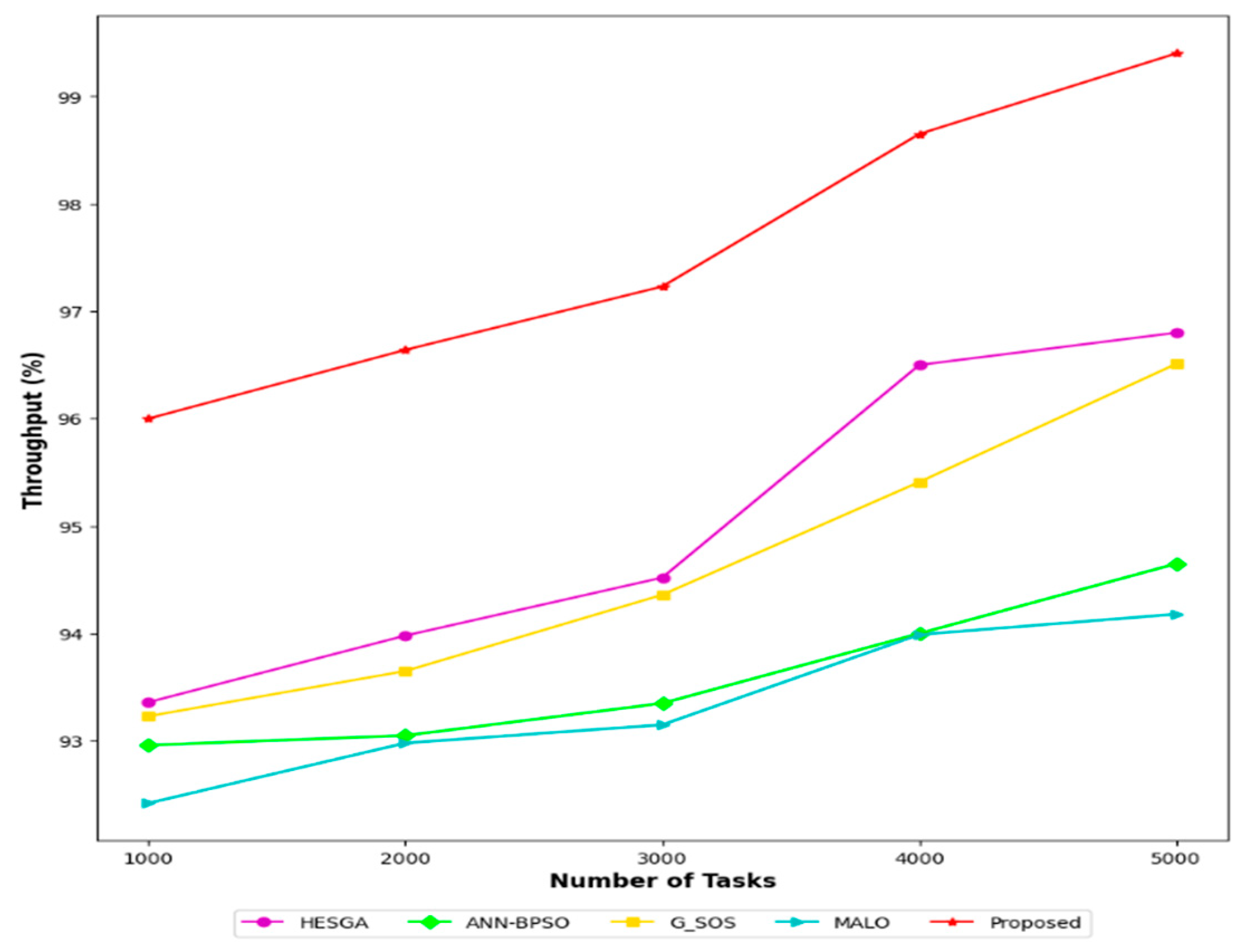
5.4.10. Throughput Result
5.4.11. Speed
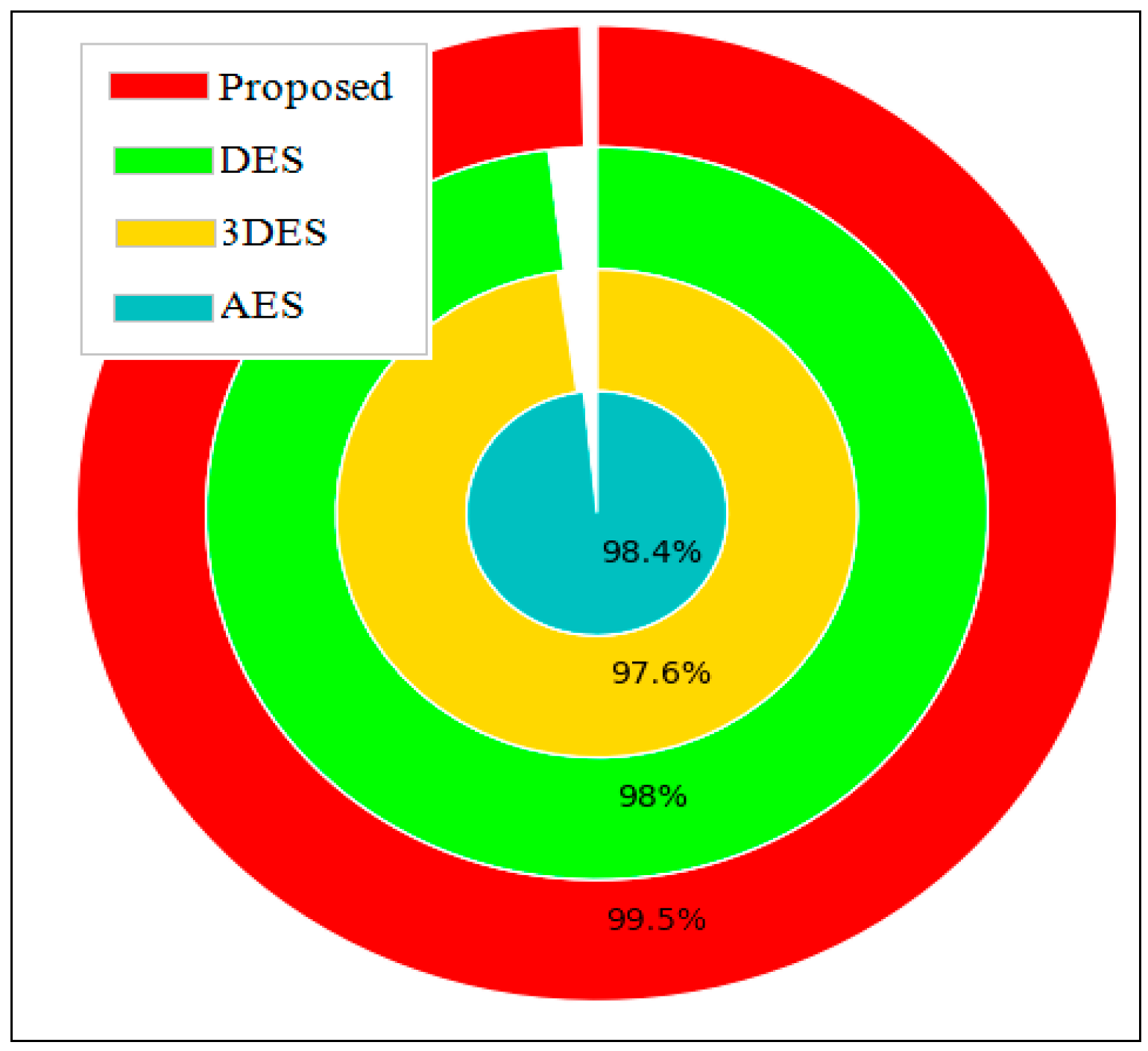
5.4.12. Security
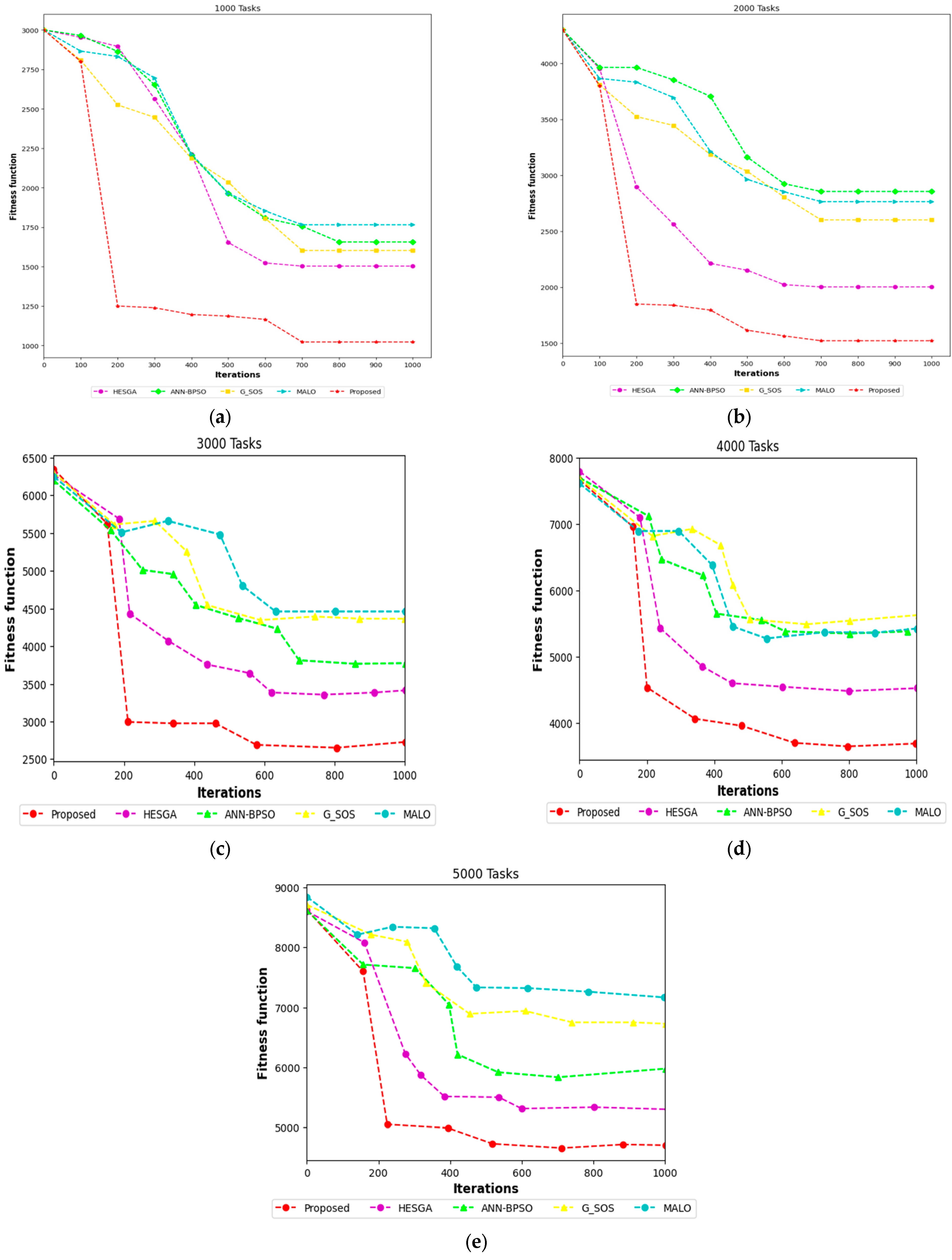
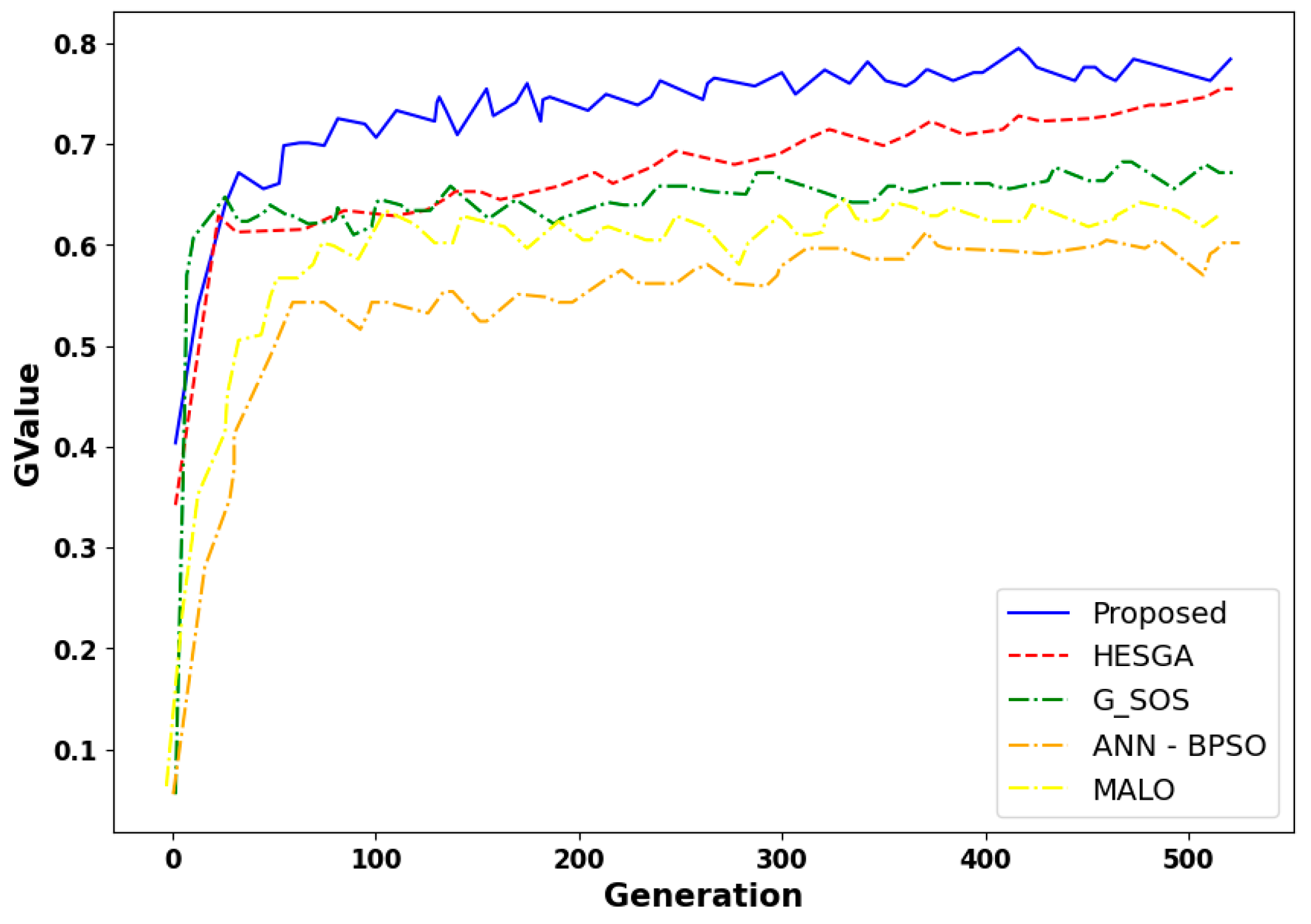
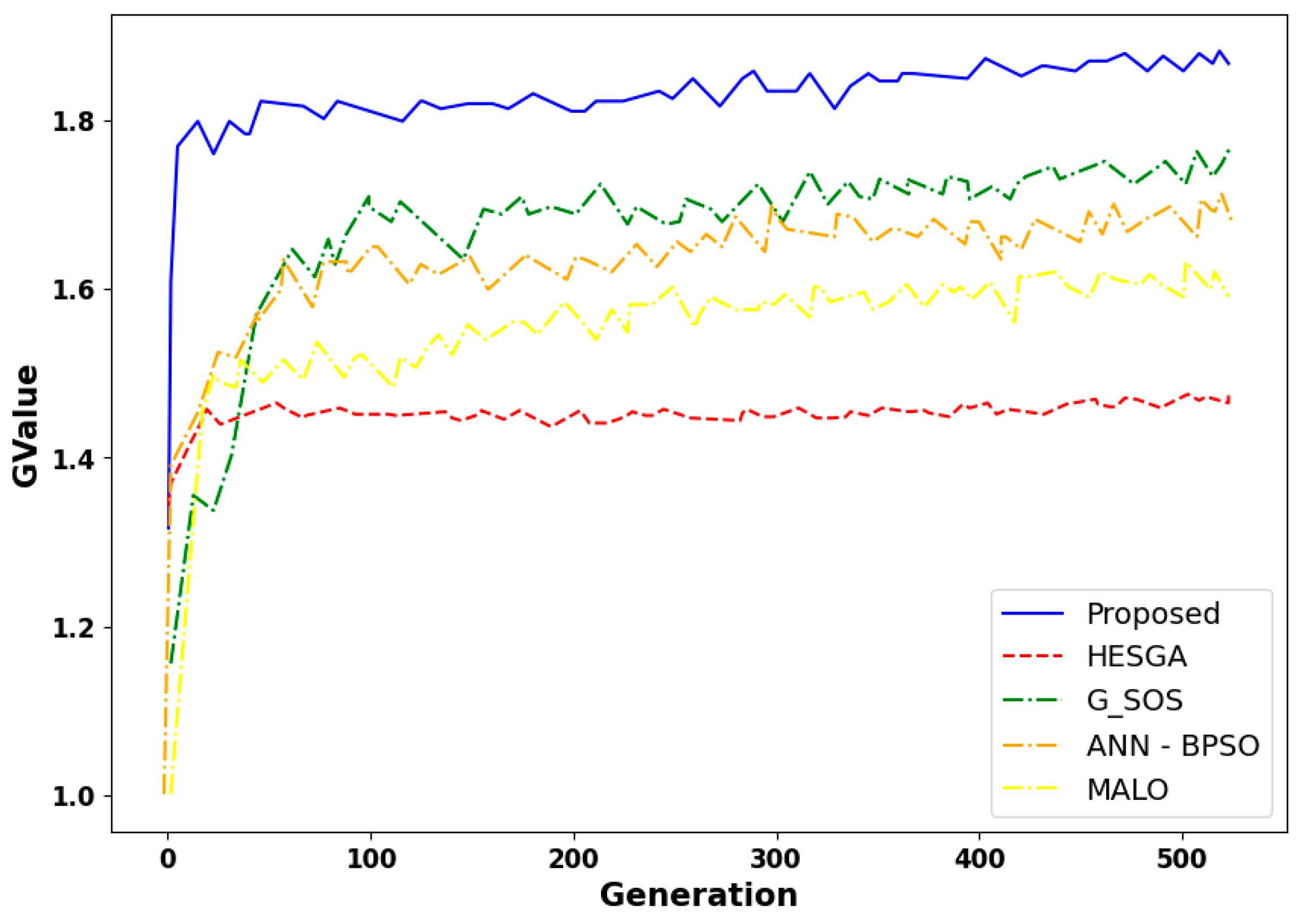
5.4.13. Result Based on the Fitness Function
- Convergence trends for Makespan
- 2.
- Convergence trends for Throughput
- 3.
- Convergence trends for Latency
- 4.
- Result analysis based on different types of tasks
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Badri, S.; Alghazzawi, D.M.; Hasan, S.H.; Alfayez, F.; Hasan, S.H.; Rahman, M.; Bhatia, S. An Efficient and Secure Model Using Adaptive Optimal Deep Learning for Task Scheduling in Cloud Computing. Electronics 2023, 12, 1441. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Santhosh, R. Task scheduling in cloud computing using hybrid optimization algorithm. Soft Comput. 2022, 26, 13069–13079. [Google Scholar] [CrossRef]
- Najafizadeh, A.; Salajegheh, A.; Rahmani, A.M.; Sahafi, A. Multi-objective Task Scheduling in cloud-fog computing using goal programming approach. Clust. Comput. 2022, 25, 141–165. [Google Scholar] [CrossRef]
- Mangalampalli, S.; Karri, G.R.; Elngar, A.A. An Efficient Trust-Aware Task Scheduling Algorithm in Cloud Computing Using Firefly Optimization. Sensors 2023, 23, 1384. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Qiu, H.; Xu, X.; Zhang, Y. Multi-objective workflow scheduling based on genetic algorithm in cloud environment. Inf. Sci. 2022, 606, 38–59. [Google Scholar] [CrossRef]
- Wang, X.; Yao, W. A Discrete Particle Swarm Optimization Algorithm for Dynamic Scheduling of Transmission Tasks. Appl. Sci. 2023, 13, 4353. [Google Scholar] [CrossRef]
- Shao, K.; Song, Y.; Wang, B. PGA: A New Hybrid PSO and GA Method for Task Scheduling with Deadline Constraints in Distributed Computing. Mathematics 2023, 11, 1548. [Google Scholar] [CrossRef]
- Bal, P.K.; Mohapatra, S.K.; Das, T.K.; Srinivasan, K.; Hu, Y.C. A joint resource allocation, security with efficient task scheduling in cloud computing using hybrid machine learning techniques. Sensors 2022, 22, 1242. [Google Scholar] [CrossRef]
- Fu, X.; Sun, Y.; Wang, H.; Li, H. Task scheduling of cloud computing based on hybrid particle swarm algorithm and genetic algorithm. Clust. Comput. 2021, 26, 2479–2488. [Google Scholar] [CrossRef]
- Rana, N.; Abd Latiff, M.S.; Abdulhamid, S.I.M.; Misra, S. A hybrid whale optimization algorithm with differential evolution optimization for multi-objective virtual machine scheduling in cloud computing. Eng. Optim. 2022, 54, 1999–2016. [Google Scholar] [CrossRef]
- Pirozmand, P.; Jalalinejad, H.; Hosseinabadi, A.A.R.; Mirkamali, S.; Li, Y. An improved particle swarm optimization algorithm for task scheduling in cloud computing. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 4313–4327. [Google Scholar] [CrossRef]
- Naik, B.B.; Singh, D.; Samaddar, A.B. FHCS: Hybridised optimisation for virtual machine migration and task scheduling in cloud data center. IET Commun. 2020, 14, 1942–1948. [Google Scholar] [CrossRef]
- Kakkottakath Valappil Thekkepuryil, J.; Suseelan, D.P.; Keerikkattil, P.M. An effective meta-heuristic based multi-objective hybrid optimization method for workflow scheduling in cloud computing environment. Clust. Comput. 2021, 24, 2367–2384. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, S.; Wang, B. An Improved Genetic Algorithm with Swarm Intelligence for Security-Aware Task Scheduling in Hybrid Clouds. Electronics 2023, 12, 2064. [Google Scholar] [CrossRef]
- Iranmanesh, A.; Naji, H.R. DCHG-TS: A deadline-constrained and cost-effective hybrid genetic algorithm for scientific workflow scheduling in cloud computing. Clust. Comput. 2021, 24, 667–681. [Google Scholar] [CrossRef]
- Masadeh, R.; Alsharman, N.; Sharieh, A.; Mahafzah, B.A.; Abdulrahman, A. Task scheduling on cloud computing based on sea lion optimization algorithm. Int. J. Web Inf. Syst. 2021, 17, 99–116. [Google Scholar] [CrossRef]
- Natesan, G.; Chokkalingam, A. An improved grey wolf optimization algorithm based task scheduling in cloud computing environment. Int. Arab J. Inf. Technol. 2020, 17, 73–81. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Cuan, X.; Chen, Z.; Zhang, L.; Chen, H. A Multiregional Agricultural Machinery Scheduling Method Based on Hybrid Particle Swarm Optimization Algorithm. Agriculture 2023, 13, 1042. [Google Scholar] [CrossRef]
- Mohammadzadeh, A.; Masdari, M.; Gharehchopogh, F.S.; Jafarian, A. A hybrid multi-objective metaheuristic optimization algorithm for scientific workflow scheduling. Clust. Comput. 2021, 24, 1479–1503. [Google Scholar] [CrossRef]
- Dubey, K.; Sharma, S.C. A novel multi-objective CR-PSO task scheduling algorithm with deadline constraint in cloud computing. Sustain. Comput. Inform. Syst. 2021, 32, 100605. [Google Scholar] [CrossRef]
- Kaur, A.; Kumar, S.; Gupta, D.; Hamid, Y.; Hamdi, M.; Ksibi, A.; Elmannai, H.; Saini, S. Algorithmic Approach to Virtual Machine Migration in Cloud Computing with Updated SESA Algorithm. Sensors 2023, 23, 6117. [Google Scholar] [CrossRef] [PubMed]
- Rajakumari, K.; Kumar, M.V.; Verma, G.; Balu, S.; Sharma, D.K.; Sengan, S. Fuzzy Based Ant Colony Optimization Scheduling in Cloud Computing. Comput. Syst. Sci. Eng. 2022, 40, 581–592. [Google Scholar] [CrossRef]
- Attiya, I.; Abualigah, L.; Alshathri, S.; Elsadek, D.; Abd Elaziz, M. Dynamic jellyfish search algorithm based on simulated annealing and disruption operators for global optimization with applications to cloud task scheduling. Mathematics 2022, 10, 1894. [Google Scholar] [CrossRef]
- Sharma, M.; Garg, R. HIGA: Harmony-inspired genetic algorithm for rack-aware energy-efficient task scheduling in cloud data centers. Eng. Sci. Technol. Int. J. 2020, 23, 211–224. [Google Scholar] [CrossRef]
- Noorian Talouki, R.; Hosseini Shirvani, M.; Motameni, H. A hybrid meta-heuristic scheduler algorithm for optimization of workflow scheduling in cloud heterogeneous computing environment. J. Eng. Des. Technol. 2022, 20, 1581–1605. [Google Scholar] [CrossRef]
- Nabi, S.; Ahmad, M.; Ibrahim, M.; Hamam, H. AdPSO: Adaptive PSO-based task scheduling approach for cloud computing. Sensors 2022, 22, 920. [Google Scholar] [CrossRef] [PubMed]
- Zubair, A.A.; Razak, S.A.; Ngadi, M.A.; Al-Dhaqm, A.; Yafooz, W.M.; Emara, A.H.M.; Saad, A.; Al-Aqrabi, H. A Cloud Computing-Based Modified Symbiotic Organisms Search Algorithm (AI) for Optimal Task Scheduling. Sensors 2022, 22, 1674. [Google Scholar] [CrossRef]
- Gupta, S.; Iyer, S.; Agarwal, G.; Manoharan, P.; Algarni, A.D.; Aldehim, G.; Raahemifar, K. Efficient prioritization and processor selection schemes for heft algorithm: A makespan optimizer for task scheduling in cloud environment. Electronics 2022, 11, 2557. [Google Scholar] [CrossRef]
- Amer, D.A.; Attiya, G.; Zeidan, I.; Nasr, A.A. Elite learning Harris hawks optimizer for multi-objective task scheduling in cloud computing. J. Supercomput. 2022, 78, 2793–2818. [Google Scholar] [CrossRef]
- Alboaneen, D.; Tianfield, H.; Zhang, Y.; Pranggono, B. A metaheuristic method for joint task scheduling and virtual machine placement in cloud data centers. Future Gener. Comput. Syst. 2021, 115, 201–212. [Google Scholar] [CrossRef]
- Albert, P.; Nanjappan, M. WHOA: Hybrid based task scheduling in cloud computing environment. Wirel. Pers. Commun. 2021, 121, 2327–2345. [Google Scholar] [CrossRef]
- Alsadie, D. A metaheuristic framework for dynamic virtual machine allocation with optimized task scheduling in cloud data centers. IEEE Access 2021, 9, 74218–74233. [Google Scholar] [CrossRef]
- Agarwal, M.; Srivastava, G.M.S. Opposition-based learning inspired particle swarm optimization (OPSO) scheme for task scheduling problem in cloud computing. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9855–9875. [Google Scholar] [CrossRef]
- Wei, X. Task scheduling optimization strategy using improved ant colony optimization algorithm in cloud computing. J. Ambient. Intell. Humaniz. Comput. 2020, 1–12. [Google Scholar] [CrossRef]
- Ramasamy, V.; Thalavai Pillai, S. An effective HPSO-MGA optimization algorithm for dynamic resource allocation in cloud environment. Clust. Comput. 2020, 23, 1711–1724. [Google Scholar] [CrossRef]
- Altigani, A.; Hasan, S.; Barry, B.; Naserelden, S.; Elsadig, M.A.; Elshoush, H.T. A polymorphic advanced encryption standard–A novel approach. IEEE Access 2021, 9, 20191–20207. [Google Scholar] [CrossRef]
- Luo, Q.; Yang, X.; Zhou, Y. Nature-inspired approach: An enhanced moth swarm algorithm for global optimization. Math. Comput. Simul. 2019, 159, 57–92. [Google Scholar] [CrossRef]
- Braik, M.S. Chameleon Swarm Algorithm: A bio-inspired optimizer for solving engineering design problems. Expert Syst. Appl. 2021, 174, 114685. [Google Scholar] [CrossRef]
- Velliangiri, S.; Karthikeyan, P.; Xavier, V.A.; Baswaraj, D. Hybrid electro search with genetic algorithm for task scheduling in cloud computing. Ain Shams Eng. J. 2021, 12, 631–639. [Google Scholar] [CrossRef]
- Alghamdi, M.I. Optimization of Load Balancing and Task Scheduling in Cloud Computing Environments Using Artificial Neural Networks-Based Binary Particle Swarm Optimization (BPSO). Sustainability 2022, 14, 11982. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A. A novel hybrid antlion optimization algorithm for multi-objective task scheduling problems in cloud computing environments. Clust. Comput. 2021, 24, 205–223. [Google Scholar] [CrossRef]
- Li, B.; Tan, Y.; Wu, A.; Duan, G. A distributionally robust optimization based method for stochastic model predictive control. IEEE Trans. Autom. Control 2021, 67, 5762–5776. [Google Scholar] [CrossRef]
- Zheng, Y.; Lv, X.; Qian, L.; Liu, X. An Optimal BP Neural Network Track Prediction Method Based on a GA and ACO Hybrid Algorithm. J. Mar. Sci. Eng. 2022, 10, 1399. [Google Scholar] [CrossRef]
- Qian, L.; Zheng, Y.; Li, L.; Ma, Y.; Zhou, C.; Zhang, D. A New Method of Inland Water Ship Trajectory Prediction Based on Long Short-Term Memory Network Optimized by Genetic Algorithm. Appl. Sci. 2022, 12, 4073. [Google Scholar] [CrossRef]
- Ma, K.; Li, Z.; Liu, P.; Yang, J.; Geng, Y.; Yang, B.; Guan, X. Reliability-Constrained Throughput Optimization of Industrial Wireless Sensor Networks With Energy Harvesting Relay. IEEE Internet Things J. 2021, 8, 13343–13354. [Google Scholar] [CrossRef]
- Cao, B.; Sun, Z.; Zhang, J.; Gu, Y. Resource Allocation in 5G IoV Architecture Based on SDN and Fog-Cloud Computing. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3832–3840. [Google Scholar] [CrossRef]
- Xiao, Z.; Shu, J.; Jiang, H.; Lui, J.C.S.; Min, G.; Liu, J.; Dustdar, S. Multi-Objective Parallel Task Offloading and Content Caching in D2D-aided MEC Networks. IEEE Trans. Mob. Comput. 2022, 22, 6599–6615. [Google Scholar] [CrossRef]
- Rashid, M.; Abed, W. IoT Sensor network data processing using the TWLGA scheduling algorithm and the Hadoop cloud platform. Wasit J. Comp. Math.Sci. 2023, 2, 135–145. [Google Scholar] [CrossRef]
- Ma, J.; Hu, J. Safe consensus control of cooperative-competitive multi-agent systems via differential privacy. Kybernetika 2022, 58, 426–439. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| Npm | Number of physical machines |
| Nvm | Number of virtual machines |
| VMk | kth VM device |
| processing acceleration of VMs by millions-of-instructions-per second | |
| Ntsk | Number of tasks |
| Taski | ith task |
| SIDTi | ith task identity number |
| lengthi | task length |
| ECTi | ith task execution time |
| LIi | task preference |
| ETCi,j | ECT for the lth task on the jth VM |
| d | dimensions |
| n | number of moths |
| Di | distance between the ith moth and the jth flame |
| l | current repetition number |
| T | Total number of flames |
| N | Maximum number of flames |
| chameleon’s position | |
| t and (t + 1) | iteration step |
| current position | |
| new position | |
| best position | |
| global best position | |
| ith chameleon’s new velocity | |
| ith chameleon’s current velocity |
| Task | Required Resources | Moth Swarm Algorithm | Chameleon Swarm Algorithm | Assigned Resource |
|---|---|---|---|---|
| T1 | CPU, 2 GB RAM | V1, V2 | V2, V3 | V2 |
| T2 | GPU, 4 GB RAM | V2, V3 | V3, V4 | V3 |
| T3 | CPU, 1 GB RAM | V3, V4 | V4, V5 | V4 |
| T4 | GPU, 2 GB RAM | V1, V4 | V4, V5 | V4 |
| T5 | CPU, 2 GB RAM | V2, V5 | V5, V1 | V5 |
| Entity | Parameter | Values of Settings |
|---|---|---|
| Hosts | Bandwidth | 2 Gb/s |
| Storage | 500 GB | |
| RAM | 1 GB | |
| No. of hosts | 1 | |
| Virtual Machine | Bandwidth | 2 Gb/s |
| Size | 20,000 | |
| MIPS | 100–1000 | |
| No. of CPU | 1 | |
| Operation system | Windows | |
| RAM | 2 GB | |
| Datacenter | No. of data center | 1 |
| Cloudlets | Number of cloudlets | 1000–5000 |
| Length | 1000–2000 |
| Algorithm | Parameter Name | Parameter Value |
|---|---|---|
| Moth Swarm | Swarm size | 50 |
| Number of iterations | 50 | |
| Light absorption | 0.5 | |
| Step size | 0.1 | |
| Attraction exponent | 1 | |
| Chameleon Swarm Algorithm | Swarm size | 50 |
| Number of iterations | 50 | |
| Mutation rate | 0.1 | |
| Crossover probability | 0.8 | |
| Mutation probability | 0.1 | |
| Local search | 10% |
| Parameter | Description |
|---|---|
| Makespan | The time is taken to complete all tasks in the cloud environment |
| Throughput | The amount of work completed per unit of time in the cloud environment |
| Latency | The time is taken for data to travel from source to destination in the cloud environment |
| Bandwidth | The amount of data that can be transferred in a unit of time in the cloud environment |
| Cost | The total cost incurred in the cloud environment |
| Execution time | The total time taken for all tasks to complete in the cloud environment |
| Degree of imbalance | The difference between the highest and lowest loads across all nodes in the system |
| Resource utilization | The proportion of available resources that are being used by the system |
| Average waiting time | The average time that a request spends in the queue before being serviced by a node |
| Response time | The time it takes for a request to be processed by a node and receive a response |
| Speed | The rate at which a node can process requests |
| Bandwidth utilization | The proportion of available network bandwidth that is being used by the system |
| Tasks | Proposed | HESGA | G_SOS | ANN—BPSO | MALO |
|---|---|---|---|---|---|
| 1000 | 55% | 42% | 38% | 36% | 31% |
| 2000 | 65% | 59% | 53% | 49% | 42% |
| 3000 | 78% | 68% | 64% | 59% | 51% |
| 4000 | 85% | 79% | 71% | 67% | 64% |
| 5000 | 92% | 82% | 74% | 69% | 66% |
| Task Type | No. of Tasks | Memory Requirement | CPU Requirement | Makespan (ms) | Throughput (tasks/ms) | Latency (ms) |
|---|---|---|---|---|---|---|
| Memory-Intensive | 1000 | High | Low | 500 | 0.002 | 110 |
| Memory-Intensive | 2000 | High | Low | 480 | 0.003 | 120 |
| Memory-Intensive | 3000 | High | Low | 490 | 0.0025 | 125 |
| Memory-Intensive | 4000 | High | Low | 470 | 0.003 | 145 |
| Memory-Intensive | 5000 | High | Low | 480 | 0.002 | 155 |
| CPU-Intensive | 1000 | Low | High | 550 | 0.001 | 120 |
| CPU-Intensive | 2000 | Low | High | 530 | 0.002 | 125 |
| CPU-Intensive | 3000 | Low | High | 540 | 0.0018 | 135 |
| CPU-Intensive | 4000 | Low | High | 520 | 0.0015 | 140 |
| CPU-Intensive | 5000 | Low | High | 510 | 0.0012 | 150 |
| Tasks | Proposed | HESGA | G_SOS | ANN—BPSO | MALO |
|---|---|---|---|---|---|
| 6000 | 2700 | 3054 | 3595 | 3215 | 3725 |
| 7000 | 3426 | 3561 | 4025 | 3965 | 4553 |
| 8000 | 5623 | 5789 | 6264 | 6214 | 7254 |
| 9000 | 7964 | 8331 | 8236 | 9254 | 9362 |
| 10,000 | 9900 | 10,275 | 10,562 | 12,523 | 12,598 |
| Tasks | Proposed | HESGA | G_SOS | ANN—BPSO | MALO |
|---|---|---|---|---|---|
| 6000 | 1.5 | 2.45 | 2.87 | 3.58 | 5.75 |
| 7000 | 2.5 | 3.78 | 3.58 | 4.75 | 6.85 |
| 8000 | 3.2 | 4.57 | 4.97 | 6.45 | 8.54 |
| 9000 | 4.2 | 6.8 | 8.7 | 8.65 | 10.22 |
| 10,000 | 5.1 | 8.9 | 10.7 | 11.54 | 13.54 |
| Tasks | Proposed | HESGA | G_SOS | ANN—BPSO | MALO |
|---|---|---|---|---|---|
| 6000 | 52% | 40% | 37% | 34% | 29% |
| 7000 | 62% | 55% | 52% | 47% | 39% |
| 8000 | 75% | 65% | 60% | 57% | 49% |
| 9000 | 84% | 77% | 69% | 66% | 62% |
| 10,000 | 93% | 79% | 72% | 62% | 55% |
| VM Serial Number | Proposed | HESGA | G_SOS | ANN—BPSO | MALO |
|---|---|---|---|---|---|
| 10 | 2.5 | 3.7 | 4.5 | 4.2 | 3.4 |
| 35 | 2.7 | 4.5 | 4.8 | 4.6 | 4.5 |
| 47 | 3.2 | 4.9 | 5.78 | 5.4 | 5.34 |
| 60 | 3.75 | 5.2 | 6.43 | 5.78 | 6.72 |
| 72 | 4.23 | 5.9 | 6.75 | 6.95 | 7.23 |
| 85 | 4.75 | 6.3 | 7.25 | 7.8 | 7.89 |
| 93 | 4.9 | 6.9 | 7.5 | 8.45 | 8.45 |
| 100 | 5.24 | 7.4 | 8.54 | 9.25 | 9.43 |
| 120 | 5.62 | 7.8 | 9.12 | 10.15 | 10.76 |
| 150 | 5.8 | 8.4 | 10.2 | 12.4 | 13.54 |
| VM Serial Number | Proposed | HESGA | G_SOS | ANN—BPSO | MALO |
|---|---|---|---|---|---|
| 10 | 1.2 | 2.75 | 2.5 | 3.5 | 4.5 |
| 35 | 1.5 | 3.5 | 3.12 | 4.12 | 4.87 |
| 47 | 1.7 | 4.9 | 4.5 | 4.67 | 5.4 |
| 60 | 2.5 | 5.43 | 5.25 | 5.8 | 5.75 |
| 72 | 2.75 | 6.8 | 6.78 | 6.45 | 6.75 |
| 85 | 3.2 | 7.43 | 7.34 | 6.9 | 8.23 |
| 93 | 3.5 | 9.5 | 7.98 | 7.23 | 12.45 |
| 100 | 3.9 | 12.54 | 8.45 | 9.12 | 15.67 |
| 120 | 4.5 | 15.3 | 10.5 | 10.34 | 16.25 |
| 150 | 4.75 | 16.32 | 11.25 | 13.5 | 17 |
| VM Serial Number | Proposed | HESGA | G_SOS | ANN—BPSO | MALO |
|---|---|---|---|---|---|
| 10 | 55% | 45% | 34% | 38% | 31% |
| 35 | 62% | 54% | 36% | 42% | 38% |
| 47 | 68% | 59% | 39% | 48% | 49% |
| 60 | 72% | 62% | 45% | 52% | 65% |
| 72 | 76% | 69% | 49% | 57% | 69% |
| 85 | 85% | 72% | 55% | 63% | 73% |
| 93 | 89% | 78% | 59% | 69% | 78% |
| 100 | 92% | 81% | 62% | 72% | 82% |
| 120 | 94% | 85% | 68% | 79% | 85% |
| 150 | 96% | 88% | 72% | 82% | 87% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsubai, S.; Garg, H.; Alqahtani, A. A Novel Hybrid MSA-CSA Algorithm for Cloud Computing Task Scheduling Problems. Symmetry 2023, 15, 1931. https://doi.org/10.3390/sym15101931
Alsubai S, Garg H, Alqahtani A. A Novel Hybrid MSA-CSA Algorithm for Cloud Computing Task Scheduling Problems. Symmetry. 2023; 15(10):1931. https://doi.org/10.3390/sym15101931
Chicago/Turabian StyleAlsubai, Shtwai, Harish Garg, and Abdullah Alqahtani. 2023. "A Novel Hybrid MSA-CSA Algorithm for Cloud Computing Task Scheduling Problems" Symmetry 15, no. 10: 1931. https://doi.org/10.3390/sym15101931
APA StyleAlsubai, S., Garg, H., & Alqahtani, A. (2023). A Novel Hybrid MSA-CSA Algorithm for Cloud Computing Task Scheduling Problems. Symmetry, 15(10), 1931. https://doi.org/10.3390/sym15101931