
A VVC Video Steganography Based on Coding Units in Chroma Components with a Deep Learning Network

Abstract
1. Introduction
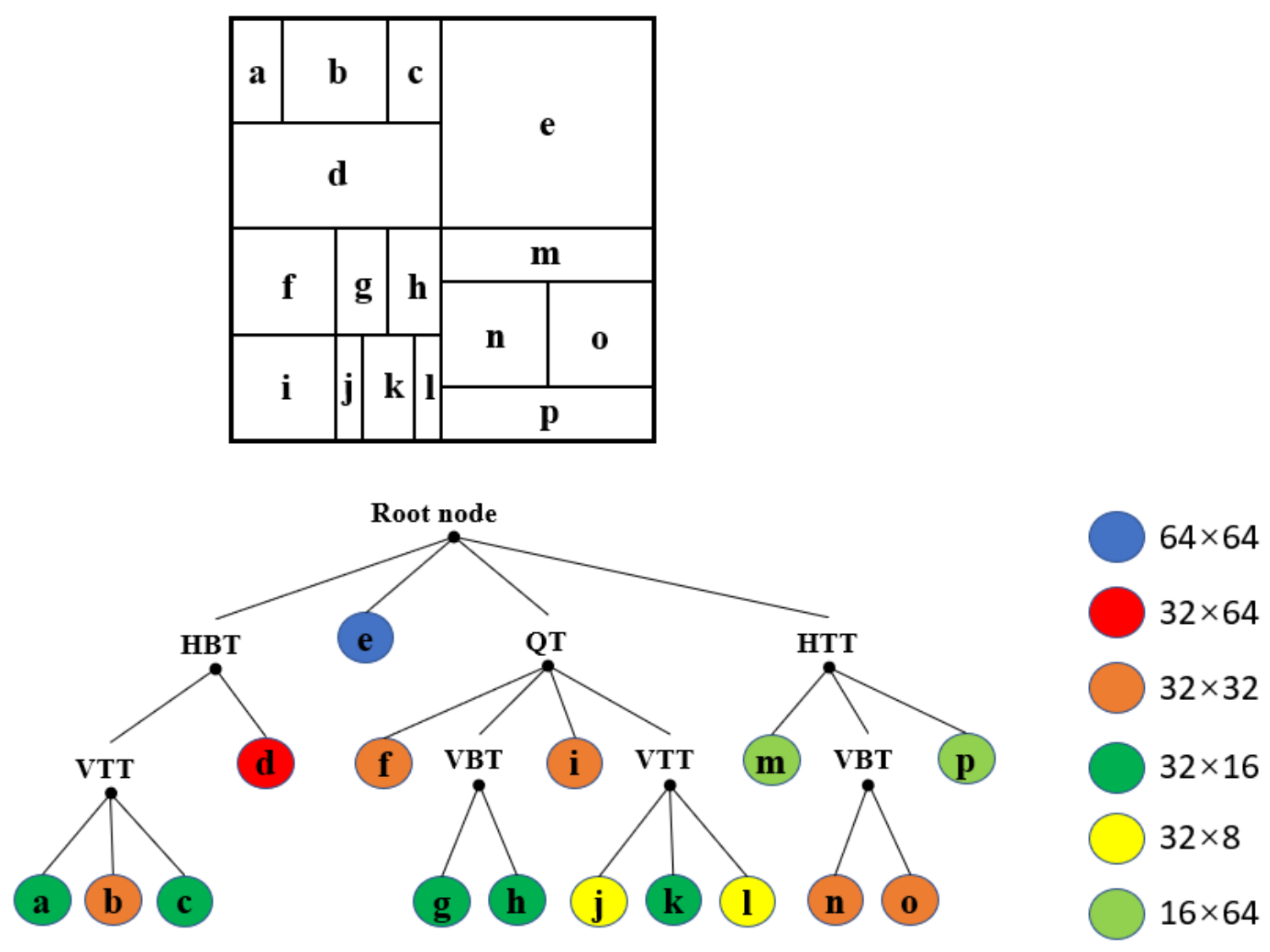
2. Block Partitioning Structure
2.1. Quadtree Plus Multi-Type Tree Structure
| Algorithm 1: Partition process. |
 |
2.2. Chroma Separate Tree
3. The Proposed Algorithm
3.1. The Chroma CU MTT Depth-Based Hierarchical Coding
| Algorithm 2: 4-bits Mapping Rule. |
 |
3.2. Four Embedding Schemes
3.3. The Additional In-Loop Filter MSRNN
4. Experimental Results
4.1. Setup
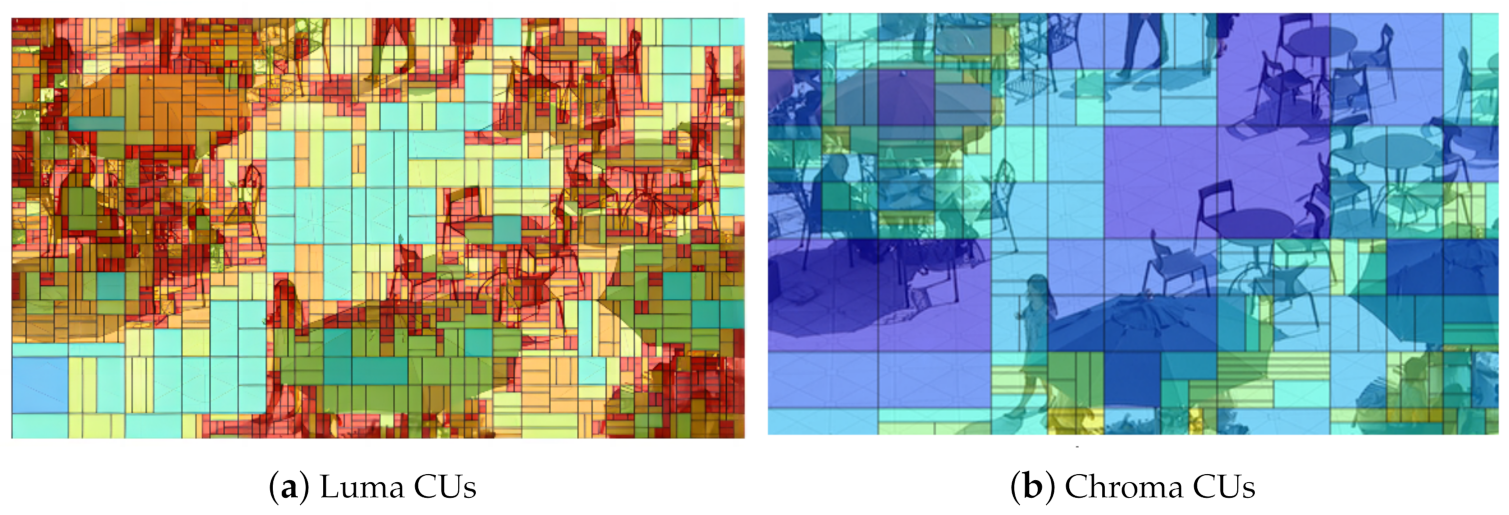
4.2. Subjective Performance
4.3. Objective Performance
4.4. Comparative Analysis
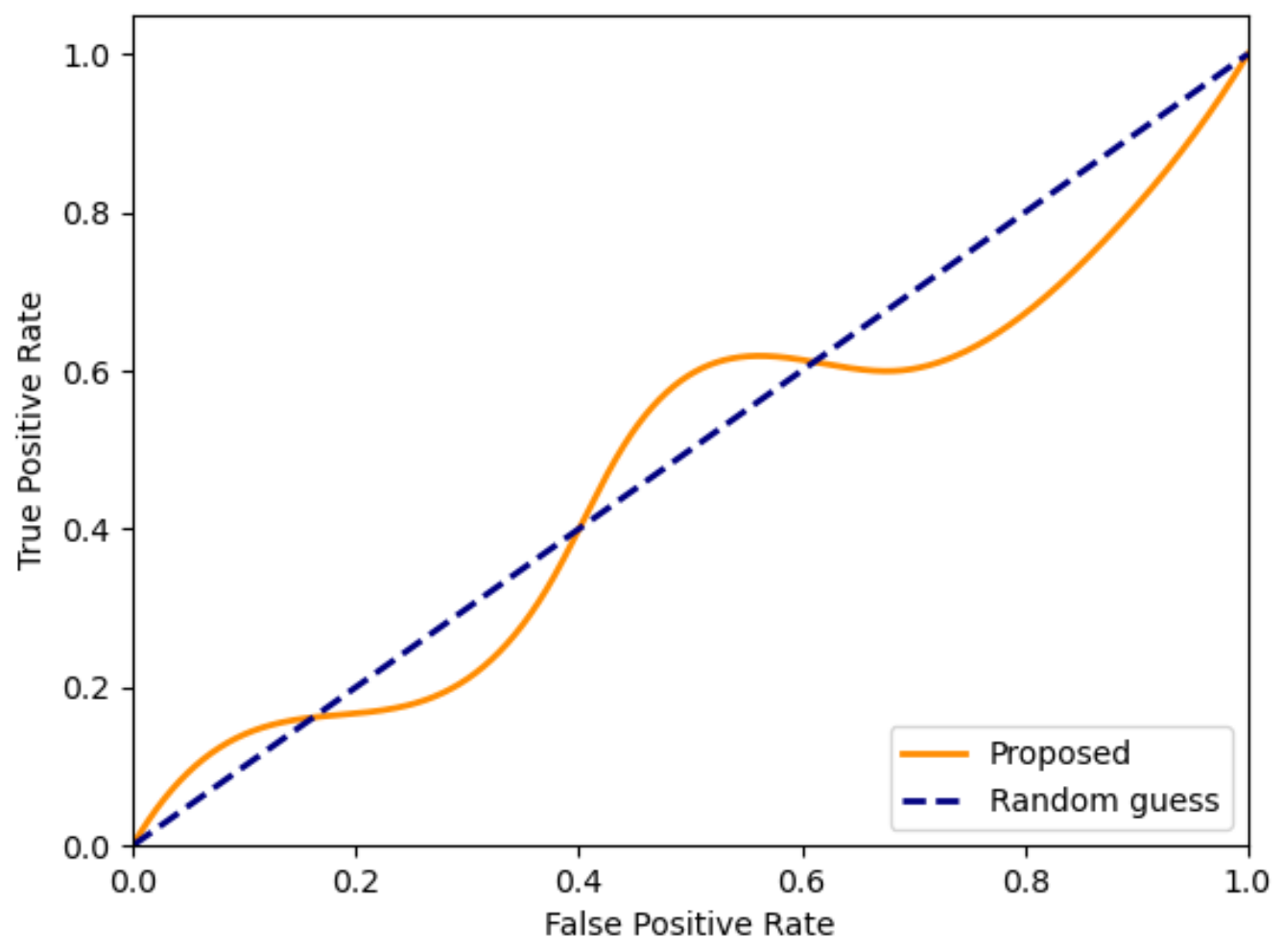
4.5. Security Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, Y.; Liao, X. Improved CMD Adaptive Image Steganography Method. In International Conference on Cloud Computing and Security; Springer: Cham, Switzerland, 2017; pp. 74–84. [Google Scholar]
- Al-Shatnawi, A.M. A new method in image steganography with improved image quality. Appl. Math. Sci. 2012, 6, 3907–3915. [Google Scholar]
- Asad, M.; Gilani, J.; Khalid, A. An enhanced least significant bit modification technique for audio steganography. In Proceedings of the International Conference on Computer Networks and Information Technology, Abbottabad, Pakistan, 11–13 July 2011; pp. 143–147. [Google Scholar]
- Mandal, K.K.; Jana, A.; Agarwal, V. A new approach of text Steganography based on mathematical model of number system. In Proceedings of the 2014 International Conference on Circuits, Power and Computing Technologies [ICCPCT-2014], Nagercoil, India, 20–21 March 2014; pp. 1737–1741. [Google Scholar]
- Chang, P.C.; Chung, K.L.; Chen, J.J.; Lin, C.H.; Lin, T.J. A DCT/DST-based error propagation-free data hiding algorithm for HEVC intra-coded frames. J. Vis. Commun. Image Represent. 2014, 25, 239–253. [Google Scholar] [CrossRef]
- Rana, S.; Kamra, R.; Sur, A. Motion vector based video steganography using homogeneous block selection. Multimed. Tools Appl. 2020, 79, 1–16. [Google Scholar] [CrossRef]
- Yang, Y.; Li, Z.; Xie, W.; Zhang, Z. High capacity and multilevel information hiding algorithm based on pu partition modes for HEVC videos. Multimed. Tools Appl. 2019, 78, 8423–8446. [Google Scholar] [CrossRef]
- Li, Z.; Meng, L.; Jiang, X.; Li, Z. High Capacity HEVC Video Hiding Algorithm Based on EMD Coded PU Partition Modes. Symmetry 2019, 11, 1015. [Google Scholar] [CrossRef]
- Wang, J.; Jia, X.; Kang, X.; Shi, Y.Q. A Cover Selection HEVC Video Steganography Based on Intra Prediction Mode. IEEE Access 2019, 7, 119393–119402. [Google Scholar] [CrossRef]
- Tew, Y.; Wong, K. Information hiding in HEVC standard using adaptive coding block size decision. In Proceedings of the 2014 IEEE international conference on image processing (ICIP), Paris, France, 27–30 October 2014; pp. 5502–5506. [Google Scholar]
- Shanableh, T. Data embedding in high efficiency video coding (HEVC) videos by modifying the partitioning of coding units. Image Process. IET 2019, 13, 1909–1913. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.R. Overview of the Versatile Video Coding VVC Standard and its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Huang, L.; Jiang, B. Fast CU Partition and Intra Mode Decision Method for H.266/VVC. IEEE Access 2020, 8, 117539–117550. [Google Scholar] [CrossRef]
- Huang, Y.W.; An, J.; Huang, H.; Li, X.; Hsiang, S.T.; Zhang, K.; Gao, H.; Ma, J.; Chubach, O. Block Partitioning Structure in the VVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3818–3833. [Google Scholar] [CrossRef]
- Huang, Z.; Sun, J.; Guo, X.; Shang, M. One-for-All: An Efficient Variable Convolution Neural Network for In-Loop Filter of VVC. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2342–2355. [Google Scholar] [CrossRef]
- Chen, S.; Chen, Z.; Wang, Y.; Liu, S. In-Loop Filter with Dense Residual Convolutional Neural Network for VVC. In Proceedings of the 2020 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzhen, China, 6–8 August 2020; pp. 149–152. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Wiegand, T. Rate-distortion optimization for video compression. IEEE Signal Process. Mag. 1998, 15, 74–90. [Google Scholar] [CrossRef]
- IENT. YUView. 2021. Available online: https://github.com/IENT/YUView (accessed on 26 October 2021).
- Starosolski, R. New simple and efficient color space transformations for lossless image compression. J. Vis. Commun. Image Represent. 2014, 25, 1056–1063. [Google Scholar] [CrossRef]
- Chung, K.L.; Huang, C.C.; Hsu, T.C. Adaptive chroma subsampling-binding and luma-guided chroma reconstruction method for screen content images. IEEE Trans. Image Process. 2017, 26, 6034–6045. [Google Scholar] [CrossRef] [PubMed]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. NTIRE 2017 Challenge on Single Image Super-Resolution: Methods and Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, J.; Li, Z.; Jiang, X.; Zhang, Z. A High-Performance CNN-Applied HEVC Steganography Based on Diamond-Coded PU Partition Modes. IEEE Trans. Multimed. 2022, 24, 2084–2097. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Boehm, B. StegExpose—A Tool for Detecting LSB Steganography. arXiv 2014, arXiv:1410.6656. [Google Scholar]
- Liu, P.; Li, S. Steganalysis of Intra Prediction Mode and Motion Vector-based Steganography by Noise Residual Convolutional Neural Network. IOP Conf. Ser. Mater. Sci. Eng. 2020, 719, 012068. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| modes | VBT | VTT | HBT | HTT |
| Binary bits | 00 | 01 | 10 | 11 |
| modes | VBT | VTT | HBT | HTT |
| modes | HBT | HBT | VBT | VBT |
| modes | VBT | HBT |
| Binary bits | 0 | 1 |
| Schemes | Mapping Rules | Embedding Method |
|---|---|---|
| Level 1 | 4-bits | Method 1 |
| Level 2 | 4-bits | Method 2 |
| Level 3 | 2-bits | Method 1 |
| Level 4 | 2-bits | Method 2 |
| Layer | Filter Size | Filter Number |
|---|---|---|
| Conv1 | 3 × 3 | 64 |
| Conv2 | 3 × 3 | 32 |
| Conv3 | 3 × 3 | 16 |
| Conv4 | 3 × 3 | 16 |
| Conv5 | 5 × 5 | 16 |
| Conv6 | 5 × 5 | 16 |
| Conv7 | 3 × 3 | 1 |
| Class | Improved VRCNN [22] | Proposed |
|---|---|---|
| ClassA | −1.73% | −1.73% |
| ClassB | −0.63% | −0.72% |
| ClassC | −3.18% | −3.38% |
| ClassD | −3.60% | −3.76% |
| ClassE | −2.54% | −2.77% |
| Class | Sequence Name | Resolution | Encoded Frames Numbers |
|---|---|---|---|
| ClassA | PeopleOnStreet Traffic | 2560 × 1600 | 18 |
| ClassB | BasketballDrive BQTerrace Cactus Kimono1 ParkScene | 1920 × 1080 | 20 |
| ClassC | BasketballDrill BQMall PartyScene RaceHorses | 832 × 480 | 20 |
| ClassD | BasketballPass BlowingBubbles BQSquare RaceHorses | 416 × 240 | 20 |
| ClassE | FourPeople Johnny KristenAndSara | 1280 × 720 | 20 |
| Class | QP | (Level 2_MSRNN) | (Level 2_MSRNN) | (Level 2_MSRNN) | (Level 2_MSRNN) | (Default) | (Level 2_MSRNN) | Capacity (Level 2_MSRNN) |
|---|---|---|---|---|---|---|---|---|
| ClassA | 26 32 38 | 41.7852 38.1119 34.6532 | 41.2967 39.5137 37.7330 | 42.4510 40.8508 39.1266 | 41.7297 38.6314 35.5459 | 42.1655 38.7845 35.5106 | 2.68% 1.24% 0.74% | 8768.00 3068.00 1096.00 |
| ClassB | 26 32 38 | 40.1954 37.5342 34.6550 | 40.8220 39.2428 37.9042 | 42.7717 40.9064 38.9339 | 40.6005 38.1727 35.5435 | 40.9229 38.3461 35.5857 | 2.27% 1.72% 1.36% | 3540.80 1595.20 774.40 |
| ClassC | 26 32 38 | 39.8219 35.7351 31.7524 | 38.8454 35.8652 34.0027 | 39.6275 36.5972 34.5614 | 39.6237 35.8856 32.4303 | 40.2379 36.3046 32.7169 | 5.48% 4.30% 4.04% | 1294.00 1000.00 640.00 |
| ClassD | 26 32 38 | 39.9070 35.3895 30.3488 | 38.7649 35.8083 33.9349 | 39.4814 36.1828 34.2280 | 39.5875 35.4840 31.9570 | 40.2220 35.9306 32.2150 | 6.55% 4.55% 4.04% | 322.00 218.00 170.00 |
| ClassE | 26 32 38 | 43.3082 40.5442 36.3138 | 45.2538 42.6368 40.8980 | 45.9940 43.3097 41.6887 | 43.9427 41.2098 38.2767 | 44.1721 41.3639 38.2435 | 3.72% 2.33% 1.06% | 1029.33 528.00 213.33 |
| Mean | 37.9081 | 38.1815 | 3.07% | 1617.14 |
| Class | Schemes | Capacity | |||||
|---|---|---|---|---|---|---|---|
| ClassA | Default Level 1 Level 2 Level 3 Level 4 Level 1_MSRNN Level 2_MSRNN Level 3_MSRNN Level 4_MSRNN | 41.6335 41.7114 41.7161 41.7120 41.7030 41.7797 41.7815 41.7725 | 42.9328 41.1107 41.1457 41.2661 41.2729 41.2967 41.4306 | 44.0051 42.3614 42.3382 42.5203 42.4788 42.4510 42.6278 | 42.3597 41.6399 41.6434 41.6900 41.7284 41.7297 41.7783 | 3.53% 2.62% 2.36% 3.55% 2.68% 2.39% | 16,000.00 8768.00 9576.00 5160.00 16,000.00 8768.00 9576.00 5160.00 |
| ClassB | Default Level 1 Level 2 Level 3 Level 4 Level 1_MSRNN Level 2_MSRNN Level 3_MSRNN Level 4_MSRNN | 39.8567 40.1845 40.1832 40.1834 40.1950 40.1950 40.1949 | 42.0612 40.6023 40.7686 40.6950 40.6290 40.8220 40.7774 | 44.0721 42.4676 42.6871 42.6181 42.1957 42.7717 42.7470 | 40.6242 40.5311 40.5781 40.5605 40.4964 40.6005 40.5926 | 3.37% 2.24% 2.15% 3.36% 2.26% 2.20% | 3540.80 4624.40 2018.40 3540.80 4624.40 2018.40 |
| ClassC | Default Level 1 Level 2 Level 3 Level 4 Level 1_MSRNN Level 2_MSRNN Level 3_MSRNN Level 4_MSRNN | 39.5904 39.7120 39.6998 39.7108 39.8250 39.8219 39.8343 | 41.2428 38.8564 38.6593 38.9120 39.0794 38.8454 39.1326 | 42.1792 39.7711 39.5338 39.8661 40.0634 39.8077 40.1578 | 40.1519 39.5500 39.4646 39.5727 39.7172 39.6237 39.7413 | 5.57% 5.56% 5.44% 5.42% 5.48% 5.38% | 1294.00 1099.50 800.00 1294.00 1099.50 800.00 |
| ClassD | Default Level 1 Level 2 Level 3 Level 4 Level 1_MSRNN Level 2_MSRNN Level 3_MSRNN Level 4_MSRNN | 39.5789 39.6644 39.6768 39.6627 39.8883 39.9036 39.8926 | 41.4094 38.8616 38.6192 38.9773 39.0062 38.7649 39.0993 | 42.1426 39.4872 39.1996 39.6032 39.7214 39.4814 39.8522 | 40.1426 39.4482 39.3675 39.4957 39.6604 39.5875 39.7160 | 5.98% 6.76% 6.37% 5.62% 6.55% 6.05% | 322.00 260.00 187.00 322.00 260.00 187.00 |
| ClassE | Default Level 1 Level 2 Level 3 Level 4 Level 1_MSRNN Level 2_MSRNN Level 3_MSRNN Level 4_MSRNN | 43.1490 43.2241 43.2204 43.2099 43.3082 43.3091 43.2946 | 46.6232 44.5351 45.0728 44.7645 44.7835 44.2538 44.9987 | 47.5673 45.4497 45.7937 45.6570 45.6571 45.8640 45.1864 | 44.1049 43.7308 43.8349 43.7776 43.8513 43.9427 43.8974 | 7.49% 3.72% 5.16% 7.40% 3.72% 5.02% | 1029.33 1945.33 582.67 1029.33 1945.33 582.67 |
| BasketballPass | BasketBallDrill | FourPeople | |||||
|---|---|---|---|---|---|---|---|
| Method | QP | PSNR | Capacity | PSNR | Capacity | PSNR | Capacity |
| Shanableh’s [11] | 26 32 38 | −0.25 −0.33 −0.86 | 138.20 133.60 116.80 | −0.22 −0.43 −0.65 | 548.20 454.20 404.60 | −0.08 −0.30 −0.59 | 877.17 |
| Level2 | 26 32 38 | −1.00 −0.80 −0.70 | −0.61 −0.43 −0.64 | −0.36 −0.36 −0.14 | 544.00 208.00 | ||
| Level2 _MSRNN | 26 32 38 | −0.74 −0.58 | −0.38 −0.22 −0.48 | −0.22 −0.13 | 544.00 208.00 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Li, Z.; Zhang, Z. A VVC Video Steganography Based on Coding Units in Chroma Components with a Deep Learning Network. Symmetry 2023, 15, 116. https://doi.org/10.3390/sym15010116
Li M, Li Z, Zhang Z. A VVC Video Steganography Based on Coding Units in Chroma Components with a Deep Learning Network. Symmetry. 2023; 15(1):116. https://doi.org/10.3390/sym15010116
Chicago/Turabian StyleLi, Minghui, Zhaohong Li, and Zhenzhen Zhang. 2023. "A VVC Video Steganography Based on Coding Units in Chroma Components with a Deep Learning Network" Symmetry 15, no. 1: 116. https://doi.org/10.3390/sym15010116
APA StyleLi, M., Li, Z., & Zhang, Z. (2023). A VVC Video Steganography Based on Coding Units in Chroma Components with a Deep Learning Network. Symmetry, 15(1), 116. https://doi.org/10.3390/sym15010116