
Using XAI for Deep Learning-Based Image Manipulation Detection with Shapley Additive Explanation



Abstract
:1. Introduction
- A unique feature selection strategy is delivered in this paper that is based on Shapley additive explanation (SHAP), which is an XAI approach. The explanation framework for the real deep learning-based model is constructed using the kernelExplainer approach.
- A pretrained ResNet50 architecture is used by initializing the network with ‘imagenet’ weights to retrain the network with forgery detection datasets.
- The proposed approach takes advantage of the difference in compression levels of the image and identifies the possible manipulated regions to be fed to the network.
- The proposed approach uses a local binary pattern that helps in analyzing the manipulations based on the texture of the images.
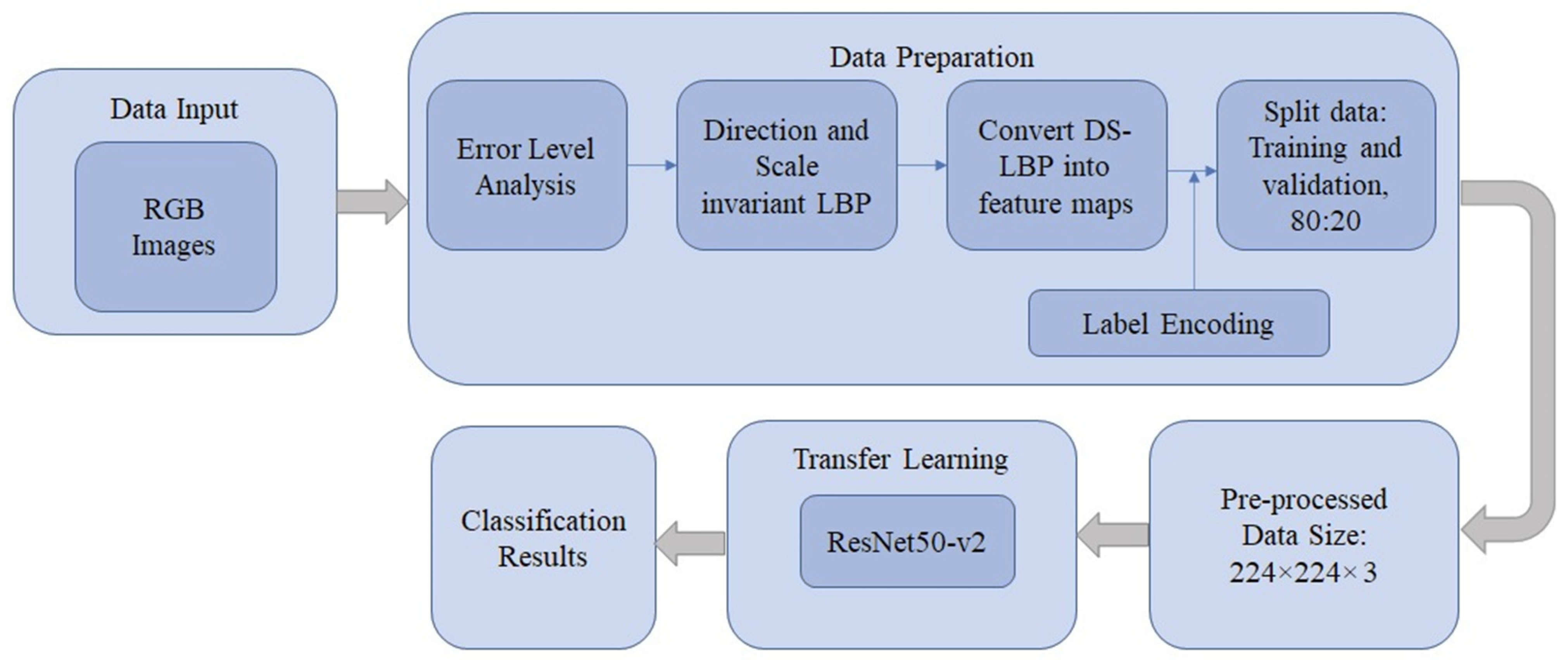
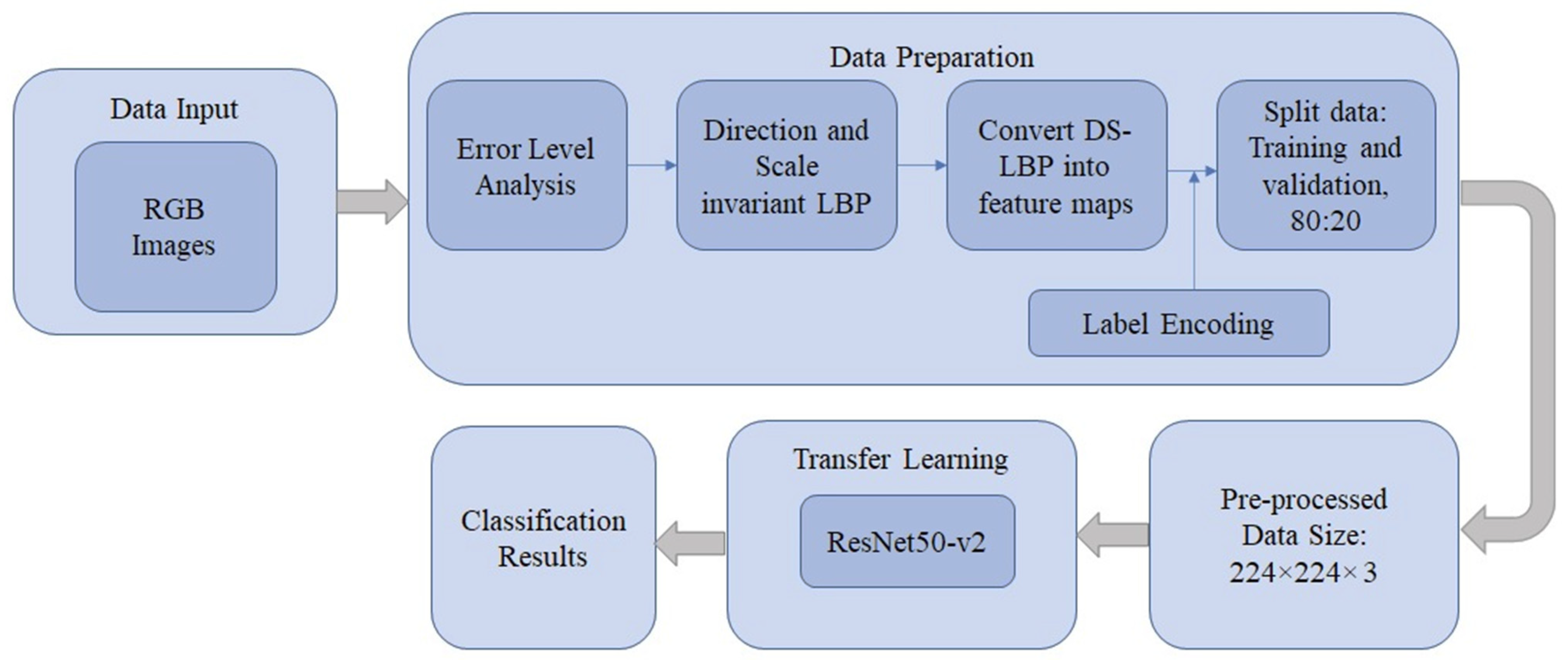
2. Proposed Scheme
2.1. Error Level Analysis
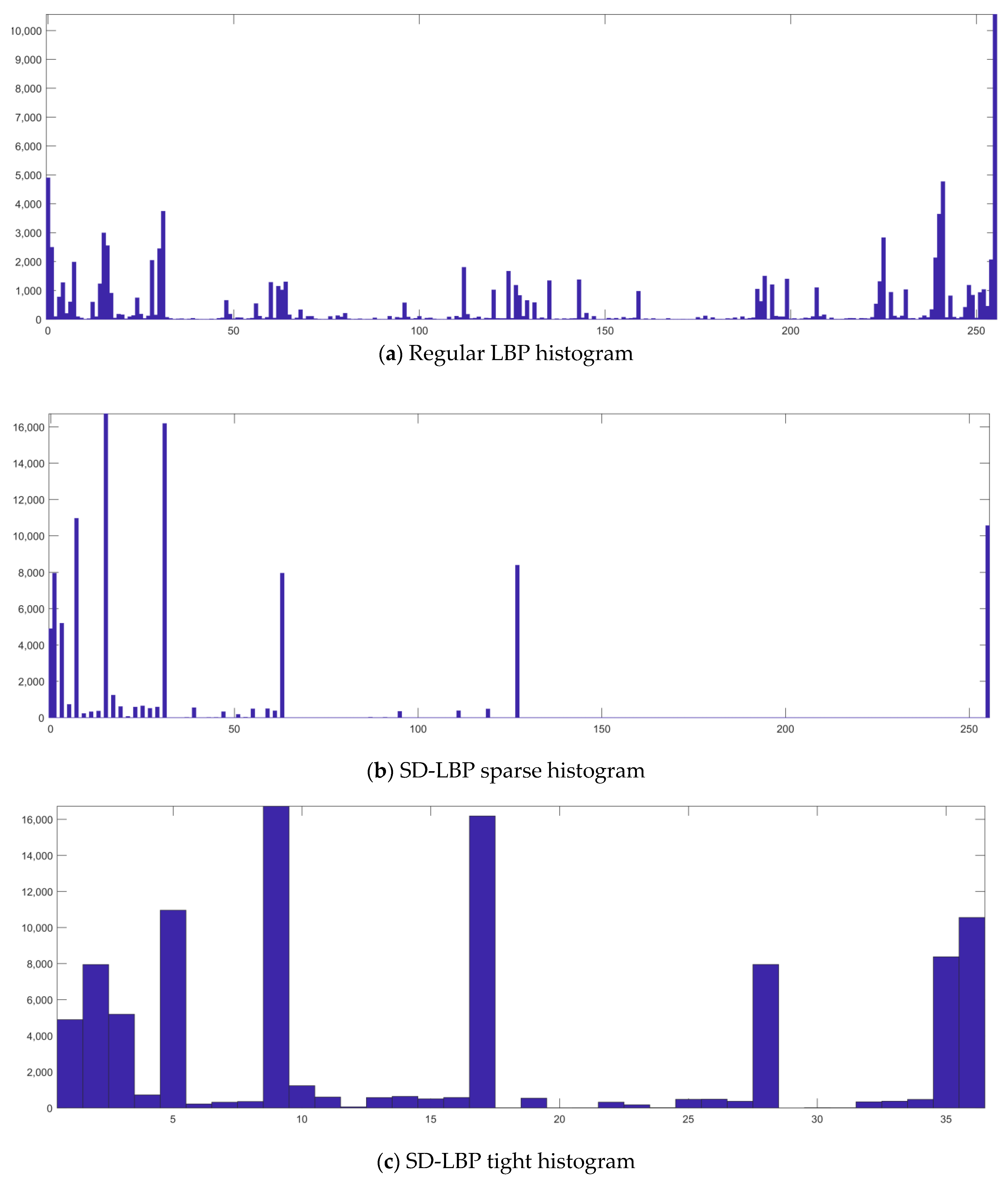
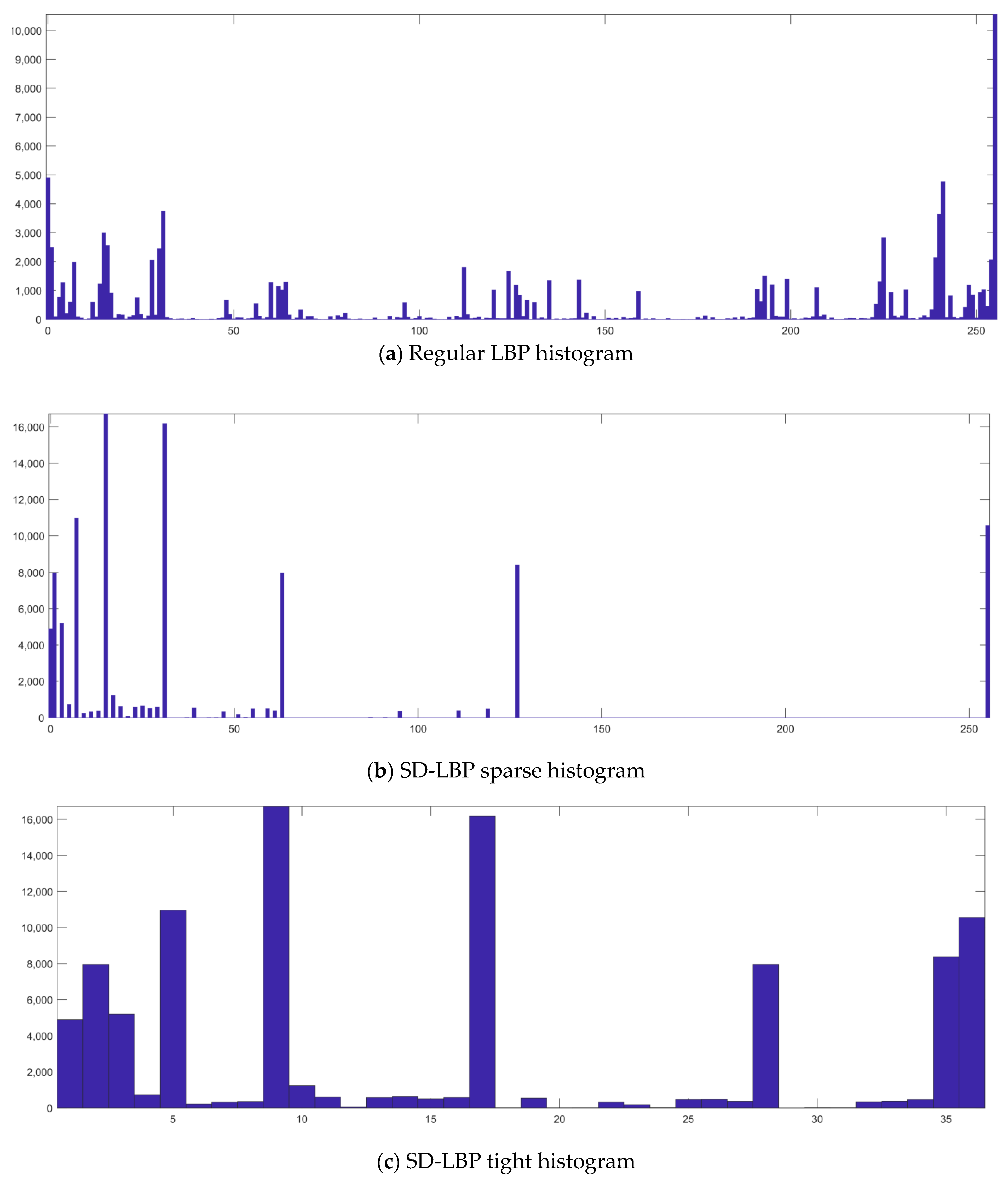
2.2. Direction- and Scale-Invariant Local Binary Patterns
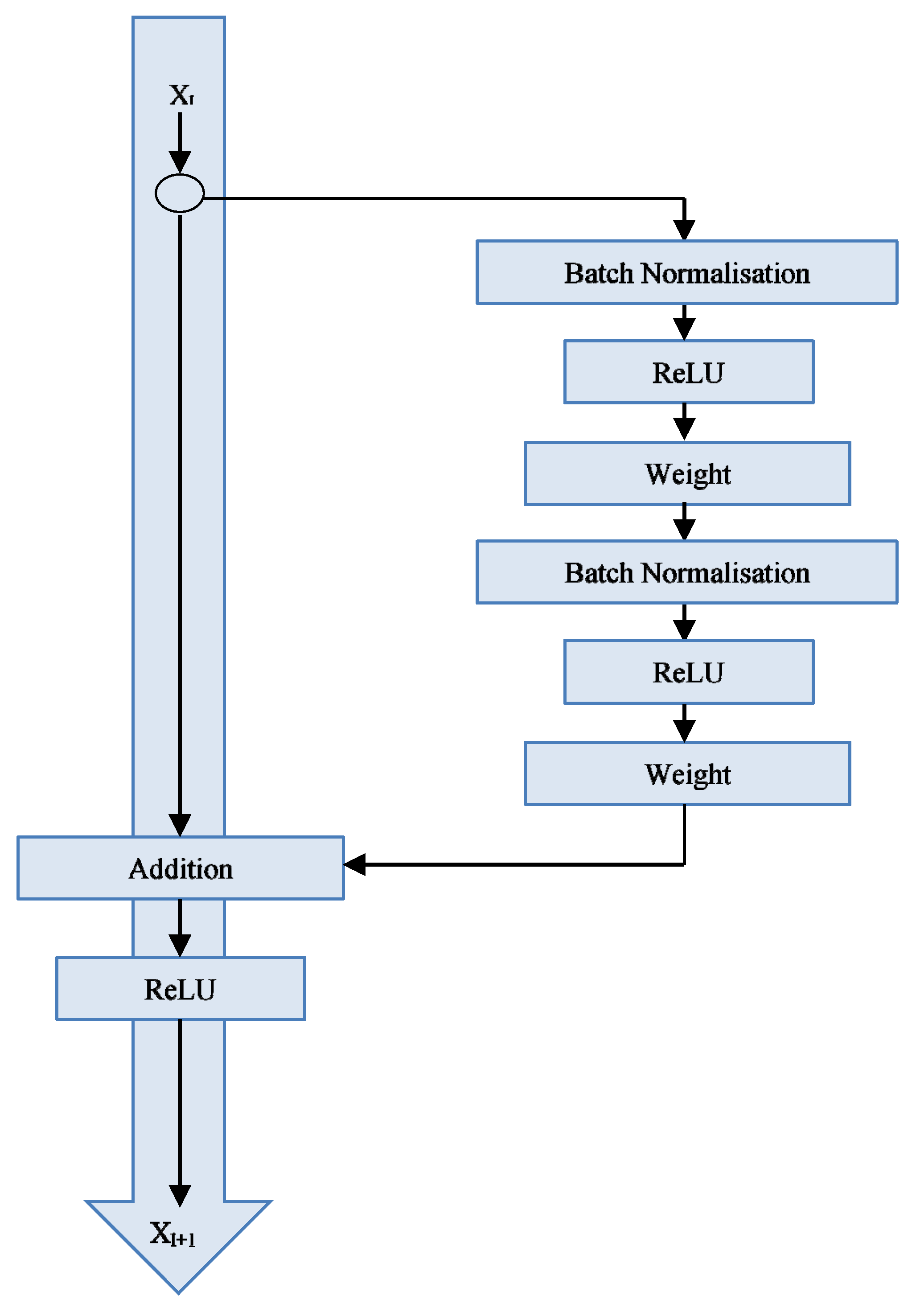
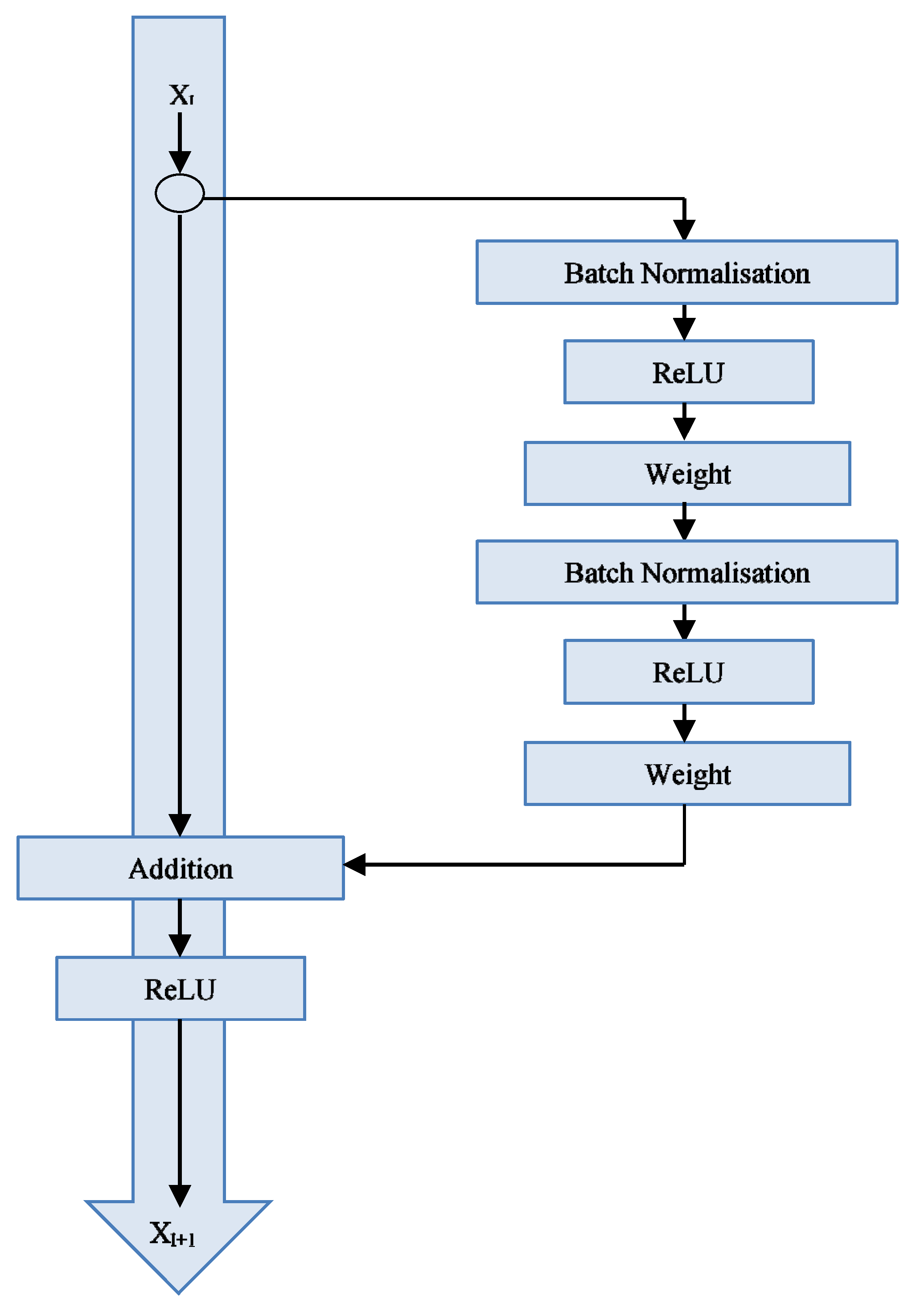
2.3. ResNet50-v2 Architecture
2.4. Shapley Additive Explanation (SHAP)
3. Experimental Setup and Results
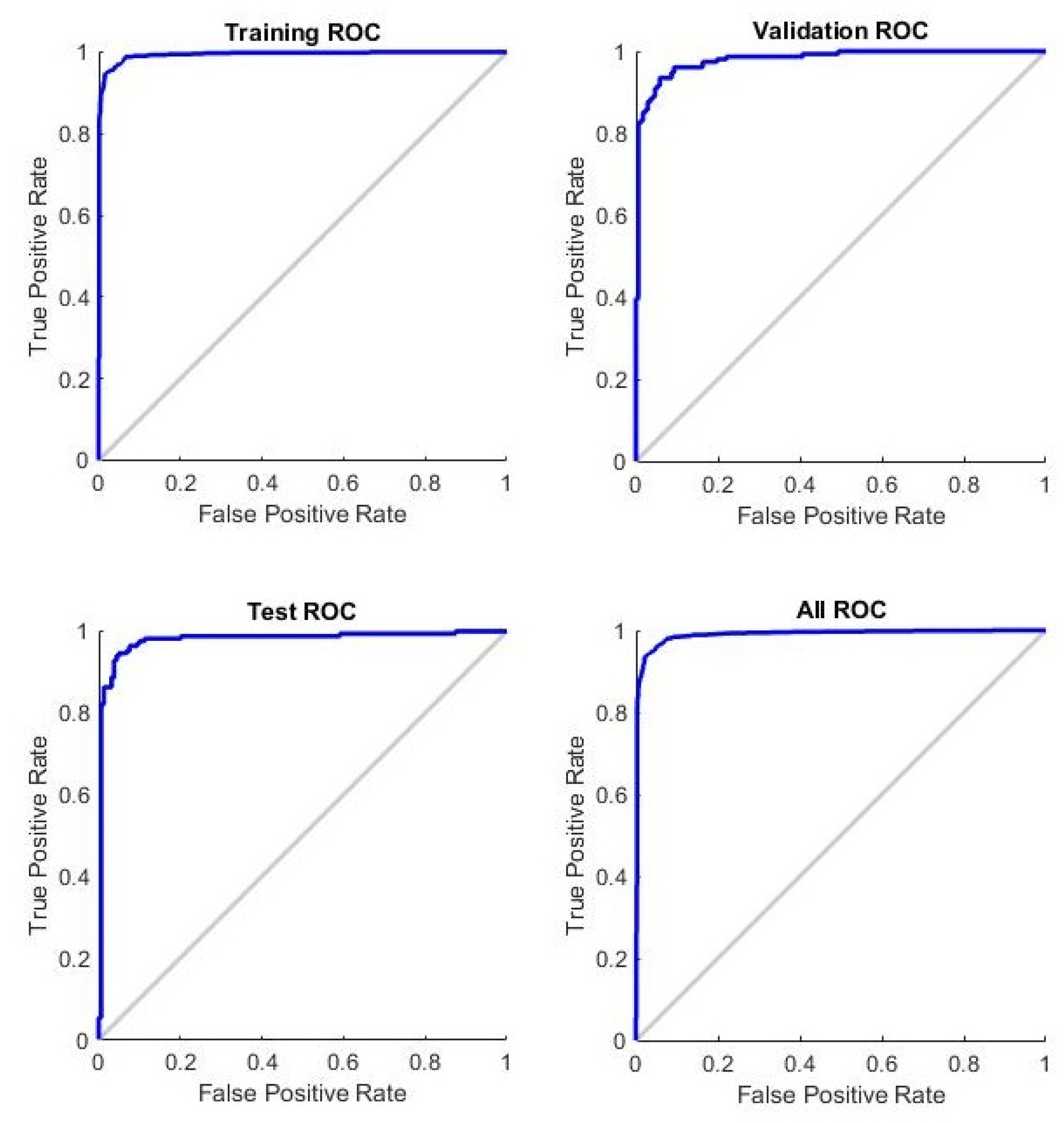
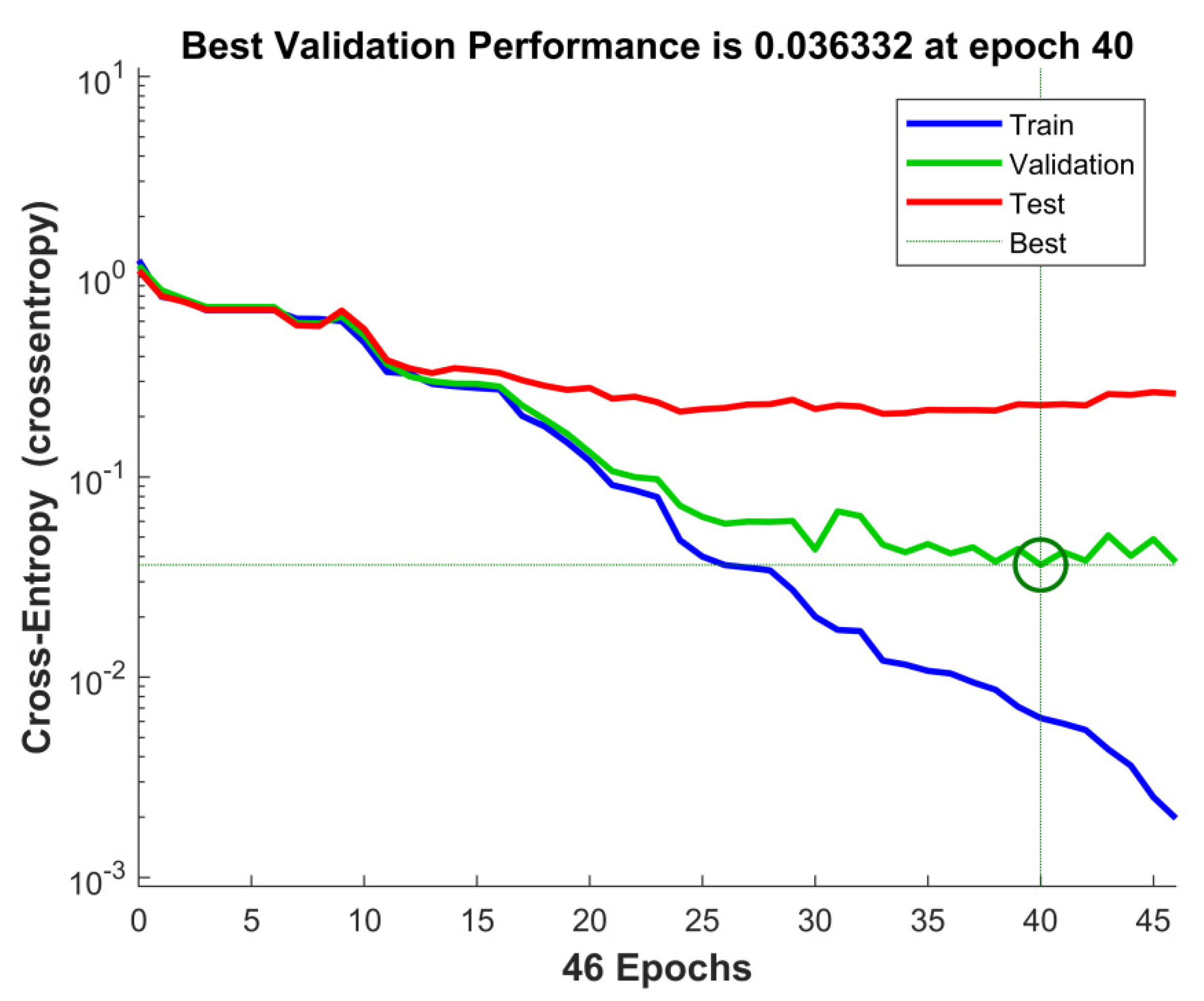
3.1. Effectiveness of the Approach
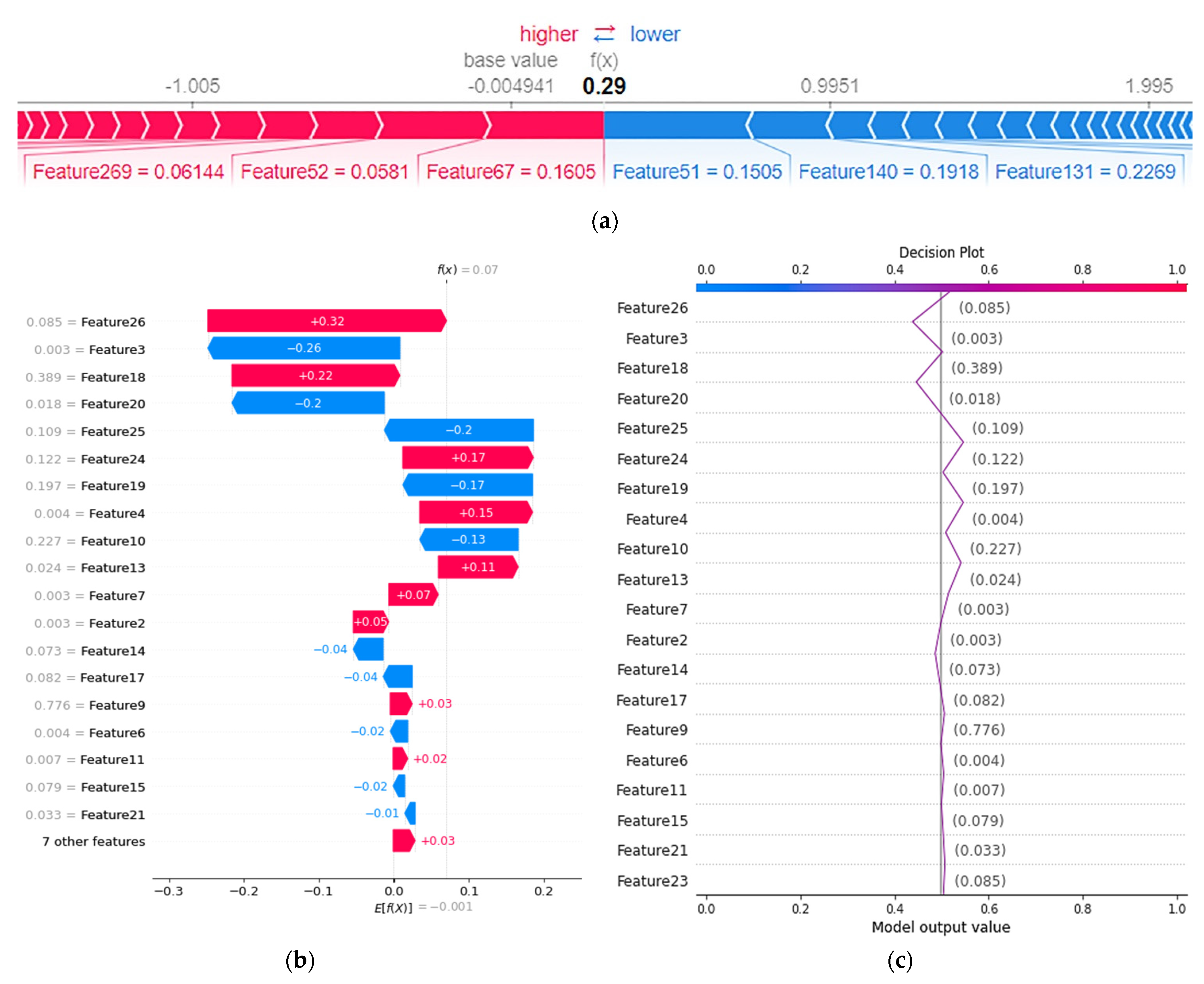
3.2. Results Explaining the Output of the Proposed Approach
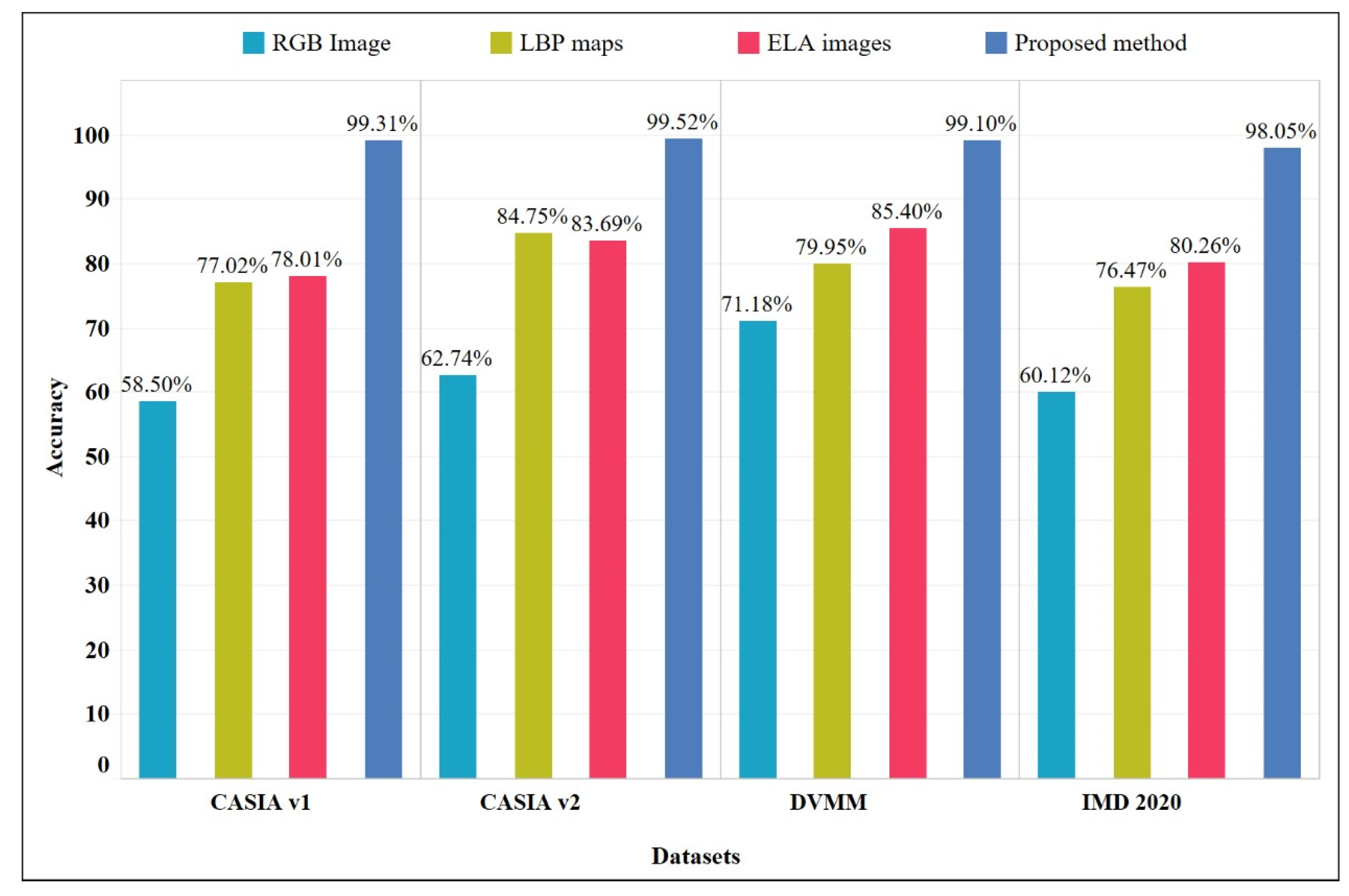
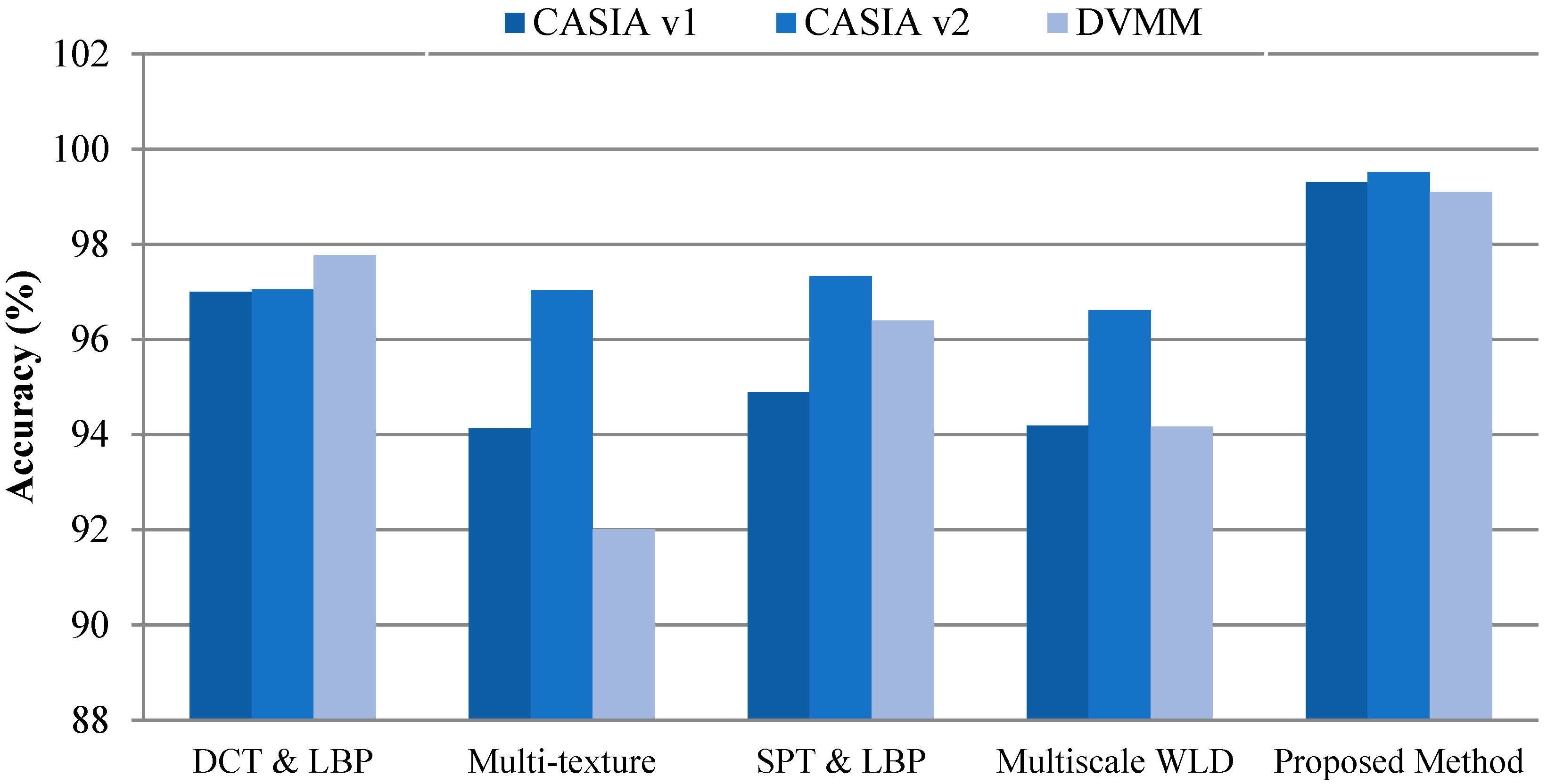
3.3. Comparison with Recent Deep-Learning Methods
3.4. Comparison with Traditional Machine Learning Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Asghar, K.; Hussain, M. Copy-Move and Splicing Image Forgery Detection and Localization Techniques: A Review. Aust. J. Forensic Sci. 2017, 49, 281–307. [Google Scholar] [CrossRef]
- Walia, S.; Kumar, K. Digital Image Forgery Detection: A Systematic Scrutiny. Aust. J. Forensic Sci. 2019, 51, 488–526. [Google Scholar] [CrossRef]
- Nixon, M.S.; Aguado, A.S. Feature Extraction and Image Processing for Computer Vision, 4th ed.; Academic Press, Inc.: Cambridge, MA, USA, 2020; ISBN 978-0-12-814976-8. [Google Scholar]
- Hemanth, D.J.; Vieira Estrela, V. Deep Learning for Image Processing Applications, 31st ed.; Advances in Parallel Computing; IOS Press: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Al-hammadi, M.H.; Muhammad, G. Curvelet Transform and Local Texture Based Image Forgery Detection. In Advances in Visual Computing, ISVC 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 503–512. [Google Scholar]
- Muhammad, G.; Al-Hammadi, M.H.; Hussain, M.; Bebis, G. Image Forgery Detection Using Steerable Pyramid Transform and Local Binary Pattern. Mach. Vis. Appl. 2014, 25, 985–995. [Google Scholar] [CrossRef]
- Hussain, M.; Qasem, S.; Bebis, G.; Muhammad, G.; Aboalsamh, H.; Mathkour, H. Evaluation of Image Forgery Detection Using Multi-Scale Weber Local Descriptors. Int. J. Artif. Intell. Tools 2015, 24, 416–424. [Google Scholar] [CrossRef] [Green Version]
- Alahmadi, A.; Hussain, M.; Aboalsamh, H.; Muhammad, G.; Bebis, G.; Mathkour, H. Passive Detection of Image Forgery Using DCT and Local Binary Pattern. Signal Image Video Process. 2017, 11, 81–88. [Google Scholar] [CrossRef]
- Vidyadharan, D.S.; Thampi, S.M. Digital Image Forgery Detection Using Compact Multi-Texture Representation. J. Intell. Fuzzy Syst. 2017, 32, 3177–3188. [Google Scholar] [CrossRef]
- Walia, S.; Kumar, K.; Kumar, M.; Gao, X.Z. Fusion of Handcrafted and Deep Features for Forgery Detection in Digital Images. IEEE Access 2021, 9, 99742–99755. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A Unified Framework for Multi-Label Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2285–2294. [Google Scholar]
- Lee, H.; Kwon, H. Going Deeper With Contextual CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, D.; Liu, Q.; Fan, W. A New Image Classification Method Using CNN Transfer Learning and Web Data Augmentation. Expert Syst. Appl. 2018, 95, 43–56. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Lv, J. Automatically Designing CNN Architectures Using the Genetic Algorithm for Image Classification. IEEE Trans. Cybern. 2020, 50, 3840–3854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parashar, A.; Upadhyay, A.K.; Gupta, K. A Novel Machine Learning Approach for Forgery Detection and Verification in Digital Image. ECS Trans. 2022, 107, 11791–11798. [Google Scholar] [CrossRef]
- Rao, Y.; Ni, J. A Deep Learning Approach to Detection of Splicing and Copy-Move Forgeries in Images. In Proceedings of the 8th IEEE International Workshop on Information Forensics and Security, WIFS 2016, Abu Dhabi, United Arab Emirates, 4–7 December 2016. [Google Scholar]
- Shi, Z.; Shen, X.; Kang, H.; Lv, Y. Image Manipulation Detection and Localization Based on the Dual-Domain Convolutional Neural Networks. IEEE Access 2018, 6, 76437–76453. [Google Scholar] [CrossRef]
- Qazi, E.U.H.; Zia, T.; Almorjan, A. Deep Learning-Based Digital Image Forgery Detection System. Appl. Sci. 2022, 12, 2851. [Google Scholar] [CrossRef]
- Ali, S.S.; Ganapathi, I.I.; Vu, N.S.; Ali, S.D.; Saxena, N.; Werghi, N. Image Forgery Detection Using Deep Learning by Recompressing Images. Electronics 2022, 11, 403. [Google Scholar] [CrossRef]
- Zhou, J.; Ni, J.; Rao, Y. Block-Based Convolutional Neural Network for Image Forgery Detection. In Digital Forensics and Watermarking IWDW2017; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 65–76. [Google Scholar]
- Farooq, S.; Yousaf, M.H.; Hussain, F. A Generic Passive Image Forgery Detection Scheme Using Local Binary Pattern with Rich Models. Comput. Electr. Eng. 2017, 62, 459–472. [Google Scholar] [CrossRef]
- Muhammad, G.; Al-hammadi, M.H.; Hussain, M.; Mirza, A.M.; Bebis, G. Copy Move Image Forgery Detection Method Using Steerable Pyramid Transform and Texture Descriptor. In Proceedings of the Eurocon 2013, Zagreb, Croatia, 1–4 July 2013; pp. 1586–1592. [Google Scholar]
- Moore, J.D.; Swartout, W.R. Explanation in Expert Systems: A Survey; Technical Report; University of Southern California, Information Sciences Institute: Marina del Rey, CA, USA, 1988. [Google Scholar]
- Van Lent, M.; Fisher, W.; Mancuso, M. An Explainable Artificial Intelligence System for Small-Unit Tactical Behavior. In Proceedings of the 16th Conference on Innovative Applications of Artificial Intelligence (IAAI’04), San Jose, CA, USA, 27–29 July 2004; pp. 900–907. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Takeishi, N.; Lee, S. Shapley Values of Reconstruction Errors of PCA for Explaining Anomaly Detection. In Proceedings of the International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8 September 2019. [Google Scholar]
- Sudiatmika, I.B.K.; Rahman, F.; Trisno, T.; Suyoto, S. Image Forgery Detection Using Error Level Analysis and Deep Learning. TELKOMNIKA Telecommun. Comput. Electron. Control 2019, 17, 653. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Shrikumar, A.; Greenside, P.; Shcherbina, A.; Kundaje, A. Not Just a Black Box: Learning Important Features through Propagating Activation Differences. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3145–3153. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should i Trust You?” Explaining the Predictions of Any Classifier. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Dong, J.; Wang, W.; Tan, T. CASIA image tampering detection evaluation database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013; pp. 422–426. [Google Scholar]
- Novozámský, A.; Mahdian, B.; Saic, S. IMD2020: A Large-Scale Annotated Dataset Tailored for Detecting Manipulated Images. In Proceedings of the 2020 IEEE Winter Applications of Computer Vision Workshops (WACVW), Snowmass, CO, USA, 1–5 March 2020; pp. 71–80. [Google Scholar] [CrossRef]
- Remya Revi, K.; Wilscy, M. Image Forgery Detection Using Deep Textural Features from Local Binary Pattern Map. J. Intell. Fuzzy Syst. 2020, 38, 6391–6401. [Google Scholar] [CrossRef]
- Samir, S.; Emary, E.; El-Sayed, K.; Onsi, H. Optimization of a Pre-Trained AlexNet Model for Detecting and Localizing Image Forgeries. Information 2020, 11, 275. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number_of_Layers | 50 |
|---|---|
| Batch_size | 32 |
| Weights | ‘imagenet’ |
| Input_size | 224, 224, 3 |
| ResNet_50_pooling | ‘max’ |
| Dense_layer_activator | ‘sigmoid’ |
| Objective_function | ‘binary_crossentropy’ |
| Loss_metrics | [‘acc’] |
| Learning_rate | 0.00005 |
| Epochs | 50 |
| Dataset | No. of Original Images | No. of Forged Images | Image Resolution | Image Format |
|---|---|---|---|---|
| Columbia DVMM | 933 | 912 | 128 × 128 | BMP |
| CASIA TIDE v1 | 800 | 925 | 384 × 256 | JPEG |
| CASIA TIDE v2 | 7491 | 5123 | 240 × 160 to 900 × 600 | JPEG, TIFF, BMP |
| IMD 2020 | 35,000 | 35,000 | 384 × 256 to 1200 × 1051 | JPEG |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walia, S.; Kumar, K.; Agarwal, S.; Kim, H. Using XAI for Deep Learning-Based Image Manipulation Detection with Shapley Additive Explanation. Symmetry 2022, 14, 1611. https://doi.org/10.3390/sym14081611
Walia S, Kumar K, Agarwal S, Kim H. Using XAI for Deep Learning-Based Image Manipulation Detection with Shapley Additive Explanation. Symmetry. 2022; 14(8):1611. https://doi.org/10.3390/sym14081611
Chicago/Turabian StyleWalia, Savita, Krishan Kumar, Saurabh Agarwal, and Hyunsung Kim. 2022. "Using XAI for Deep Learning-Based Image Manipulation Detection with Shapley Additive Explanation" Symmetry 14, no. 8: 1611. https://doi.org/10.3390/sym14081611
APA StyleWalia, S., Kumar, K., Agarwal, S., & Kim, H. (2022). Using XAI for Deep Learning-Based Image Manipulation Detection with Shapley Additive Explanation. Symmetry, 14(8), 1611. https://doi.org/10.3390/sym14081611