1. Introduction
We consider the nonlinear equation
where
is a continuously differentiable mapping. We denote
as the Jacobian matrix of
at
x and pay attention to the case
having sparse or special structures. Specifically, one has
and
Nonlinear equations arise from many scientific and engineering problems and have various applications in the fields such as physics, biology, and many other fields [
1].
The linearization of nonlinear Equation (
1) at an iterative point
is
when
is nonsingular, we obtain the Newton–Raphson method
Newton’s method is theoretically efficient because it is locally quadratically convergent when the Jacobian matrix is nonsigular and Lipschitz continuous at the solution of
[
2]. However, at each iteration, Newton’s method must compute the exact Jacobian matrix to keep the quadratic convergence rate. The idea of quasi-Newton methods is to approximate the Jacobian matrix
by a quasi-Newtonian matrix
with an acceptable reduction of convergence rate. However, at each iteration, Newton’s method must compute the exact Jacobian matrix. To avoid computing the derivatives directly, quasi-Newton methods have been proposed, where
is approximated by a quasi-Newton matrix
. Thus, quasi-Newton methods generate an iteration as follows:
where the step length
is determined by some line search strategies, and
is the quasi-Newton direction obtained by solving the subproblem
Usually, as an approximation to the Jacobian matrix
, matrix
usually satisfies the so-called quasi-Newton condition
where
The quasi-Newton matrix
can be updated by kinds of quasi-Newton update formulae, such as Broyden’s method, Powell’s symmetric Broyden method, BFGS method, and DFP methods [
3,
4].
Quasi-Newton methods are popular among small and medium-scale problems, since they possess local and superlinear convergence without computing the Jacobian [
5,
6,
7]. However, when the dimension of nonlinear equations is large, the matrix
will be dense. Then, the computation and time complexity will be high. There are two considerations to motivate us to consider the sparse quasi-Newton methods for solving sparse nonlinear equations in this paper. One is the fact that there are lots of nonlinear equations with sparse or special Jacobian. Moreover, quasi-Newton methods for solving (
1) have a good property that they can maintain the sparse structure of Jacobian matrices. Thus, in this paper, we are interested in constructing a sparse quasi-Newton method for solving sparse nonlinear equations, where the Jacobian matrix
has sparse or special structure. Earlier work on sparse quasi-Newton methods was carried out by Schubert [
8] and Toint [
9], where Schubert modified Broyden’s method by updating
row by row so that the sparsity can be maintained and Toint studied sparse and symmetric quasi-Newton methods. There also have been many kinds of methods for solving large-scale nonlinear systems, such as limited-memory quasi-Newton methods [
10,
11], partitioned quasi-Newton methods [
12,
13,
14], diagonal quasi-Newton method [
15,
16], and column updating method [
17].
However, the global convergence of quasi-Newton methods for nonlinear equations is a relatively difficult topic, not to mention the dense case. This mainly results from the fact that the quasi-Newton direction may not be a descent direction of the merit function
Griewank [
18] and Li and Fukushima [
19] have proposed some line search techniques to establish the global convergence of the quasi-Newton method.
The purpose of our paper is to develop a sparse quasi-Newton method and study its local and global convergence. We consider Broyden’s method
If we replace
with
, we can obtain the following update
which fulfills the direct tangent condition [
20,
21]
We call the corresponding method the direct Broyden method. Then, we will develop a sparse direct Broyden method, which enjoys the following nice properties: (a) the new sparse quasi-Newton method is a least change update satisfying the direct tangent condition; (b) the proposed method can preserve the sparsity property of the original Jacobian matrix
exactly; and (c) the sparse direct Broyden method is globally and superlinearly convergent. Presented limited numerical results demonstrate that our algorithm has better performance than Schubert’s method and the direct Broyden method in iteration counts, function evaluation counts, and Broyden’s mean convergence rate.
The paper is organized as follows: in
Section 2, we propose a sparse direct Broyden method and list its nice property. For the full step sparse direct Broyden method, local and superlinear convergence is also given. By adopting a nonmonotone line search, we prove the global and superlinear convergence of the method proposed in
Section 2. Moreover, after finitely many iterations, the unit step length will always be accepted. In
Section 4, we do some preliminary numerical experiments to test the efficiency of the proposed method. In the last section, we give the conclusion.
2. A New Sparse Quasi-Newton Update and Local Convergence
We pay attention to nonlinear Equation (
1), whose Jacobian matrix is sparse or has a special structure. Firstly, we introduce some notations to describe the sparsity structure of the Jacobian as that in [
22]. Define the sparsity features of the
ith row of
where
is the
jth column of identity matrix. Then, we can obtain the set of matrices
V that preserve the sparsity pattern of
:
Define a projection operator
,
, which maps
onto
:
Similar to the derivation of Schubert’s method [
8], we consider the sparse extension of direct Broyden update [
2]
which fulfills the direct tangent condition
Then, we can obtain a compact representation of the new sparse quasi-Newton update as
where the pseudo-inverse of
is defined by
The new sparse quasi-Newton method (
3) updates the quasi-Newton matrix row by row to preserve the zero and nonzero structure of the Jacobian.
Then, we can obtain a quasi-Newton method as
where
can be obtained by solving the following subproblem
and
is updated by sparse direct Broyden update
We call the corresponding method the sparse direct Broyden method. When
, we refer to it as a full step sparse direct Broyden method.
Lemma 1. The defined by (3) is the unique solution to the following minimization problem:where . Proof. Firstly, we will prove that
. For
, multiply both sides of (
3) by
, to obtain
Since
and
, then we have
, which implies
.
If
, one has
According to the definition of the operator
, we have
Then, (
5) can be written as
If
, we have
thus
, which implies
. Therefore,
.
Then, we will prove the uniqueness. Suppose that
. Since
and
, one has
Taking the Frobenius norm,
where the first inequality follows from the triangle inequality. Since the function
is strictly convex and the constraint condition (
4) is convex, we can obtain the uniqueness. □
To analyze the local convergence of the full step sparse direct Broyden method, first we show that the bounded deterioration property
is satisfied with some constants
, where
.
Lemma 2. Suppose that is continuously differentiable in , which is an open and convex set. Let be a solution of (1) at which is nonsingular. Suppose that there exists with , for , such thatThen, one has the estimationwhere . Proof. For the case
, then it is obvious that
and
. For the case
, subtracting
from both sides of the update formula
and multiplying by
,
, one has
Taking norms yields
If
, then we have
. It is obvious that
If
, it follows that
Thus, (
7) reduces to
Make a summation to obtain
□
Based on the classical framework of Dennis and Moré, we give the following local convergence, which can be proved similar to the case of Broyden’s method [
6,
7].
Theorem 1. Let the conditions in Lemma 2 hold. Then, there exist constants such that, if and , the sequence is well defined and converges to . Furthermore, the convergence rate is superlinear.
Proof. According to Lemma 2, one has
which means that the estimation (
6) is satisfied with
and
. Then, we obtain the local and linear convergence of
.
Next, we will show the Dennis–Moré condition [
7]
is satisfied. According to (
8), one has
then, the result can be proved similar to that in [
7]. □
4. Numerical Experiments
In this section, we compare the SDBroyden method with Schubert’s method [
8]. We also compare the SDBroyden method with a direct Broyden method and Newton’s method. All the methods are written in MATLAB R2018a and run in an iMac with 16G. The product
is computed by the automatic differentiation tool TOLMAB [
24].
The testing problems are listed in
Appendix A. The Jacobian matrices of the tested problems have different structures such as: diagonal (Problem 1, 2), tridiagonal (Problems 3, 4, 5, 6, 7, 8), block-diagonal (Problems 9, 10, 11), and special structure (Problem 12). The parameters in Algorithm 1 are specified as [
19]
For all the methods, we also stop the iteration if the number of iterations exceeds 200. We report the numerical performance of the above four methods in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 and
Figure 1 and
Figure 2, where the meaning of each column is as follows:
| Schubert: | Schubert’s method; |
| SDBroyden: | sparse direct Broyden method with LF condition; |
| Pro | the number of the test problem; |
| Dim: | the dimension of the problem; |
| Ite | the total number of iterations; |
| Nfun: | the total number of function evaluations; |
| R: | Broyden’s mean convergence rate; |
| Time(s): | CPU time in second; |
| Fail: | the stopping criterion was not satisfied. |
(1) In the first set of our numerical experiments, we test the performance of the SDBroyden method and Schubert’s method. When
is chosen as unit matrix
I, the results are listed in
Table 1 and
Table 2, respectively. For SDBroyden method and Schubert’s method, we compute the problems with dimensions (
10, 20, 50, 100, 200, 500, 1000, 2000, 5000, 10,000, 20,000, 50,000), but we select a subset of the dimensions (
10, 100, 1000, 2000, 10,000, 20,000, 50,000) to improve the readability of the corresponding tables. The two methods fail on two problems (3, 8). Considering the iteration counts, the SDBroyden method is more efficient than Schubert’s method on seven problems (1, 2, 4, 5, 10, 11, 12), equivalent to Schubert’s method on three problems (6, 7, 9). For the total number of function evaluations, the SDBroyden method has better performance on seven problems (1, 2, 4, 9, 10, 11, 12), while Schubert’s method needs less function evaluations on one problem (5), and both methods are equivalent on two problems (6, 7). As for the Broyden’s mean convergence rate, SDBroyden works well on seven problems (1, 2, 4, 6, 10, 11, 12), equal to Schubert’s method on three problems (5, 7, 9). It can be seen that the SDBroyden method outperforms Schubert’s method in iteration counts, function evaluation counts, and Broyden’s mean convergence rate.
When
is chosen as the exact Jacobian matrix
, the results are given in
Table 3 and
Table 4, respectively. The two methods solve the 12 problems successfully. The SDBroyden method needs fewer iterations than Schubert’s method on seven problems (1, 2, 4, 5, 8, 10, 11), equal iterations with Schubert’s method on five problems (3, 6, 7, 9, 12). For the total number of function evaluations, the SDBroyden method is more efficient than Schubert’s method on six problems (1, 2, 4, 5, 8, 11) and equivalent to Schubert’s method on six problems (3, 6, 7, 9, 10, 12). As for the Broyden’s mean convergence rate, SDBroyden has better performance on nine problems (1, 2, 3, 4, 5, 8, 10, 11, 12) and equals Schubert’s method on two problems (7, 9). The two methods are competitive on one problem (6). It also can be seen that the SDBroyden method outperforms Schubert’s method in terms of number of iterations, number of function evaluations, and Broyden’s mean convergence rate. Meanwhile, the CPU time of SDBroyden method is mostly more than that of Schubert’s method.
Performance ration [
25] is used to compare the numerical performance. For given solvers set
S and problems set
P, let
be the number of iterations, the number of function evaluations or others, required to solve problem
p by solver
s. Then, define the performance ration as
whose distribution function is defined as
where
is the number of problems in the set
P. Thus,
was the probability for solver
that a performance ratio
was within a factor
of the best possible ratio. According to the definition of performance profiles, we can see that the top curve corresponds to the best solver.
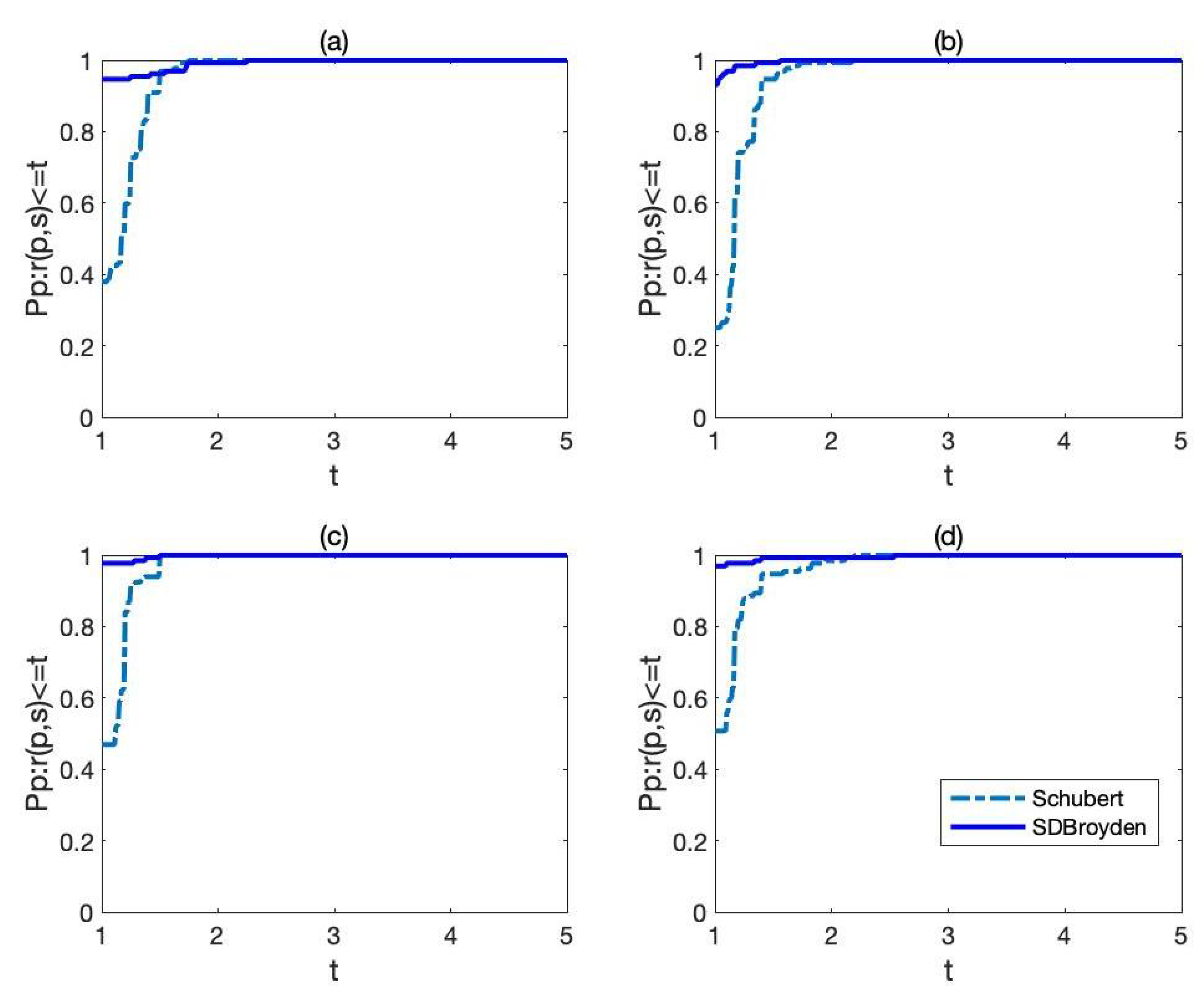
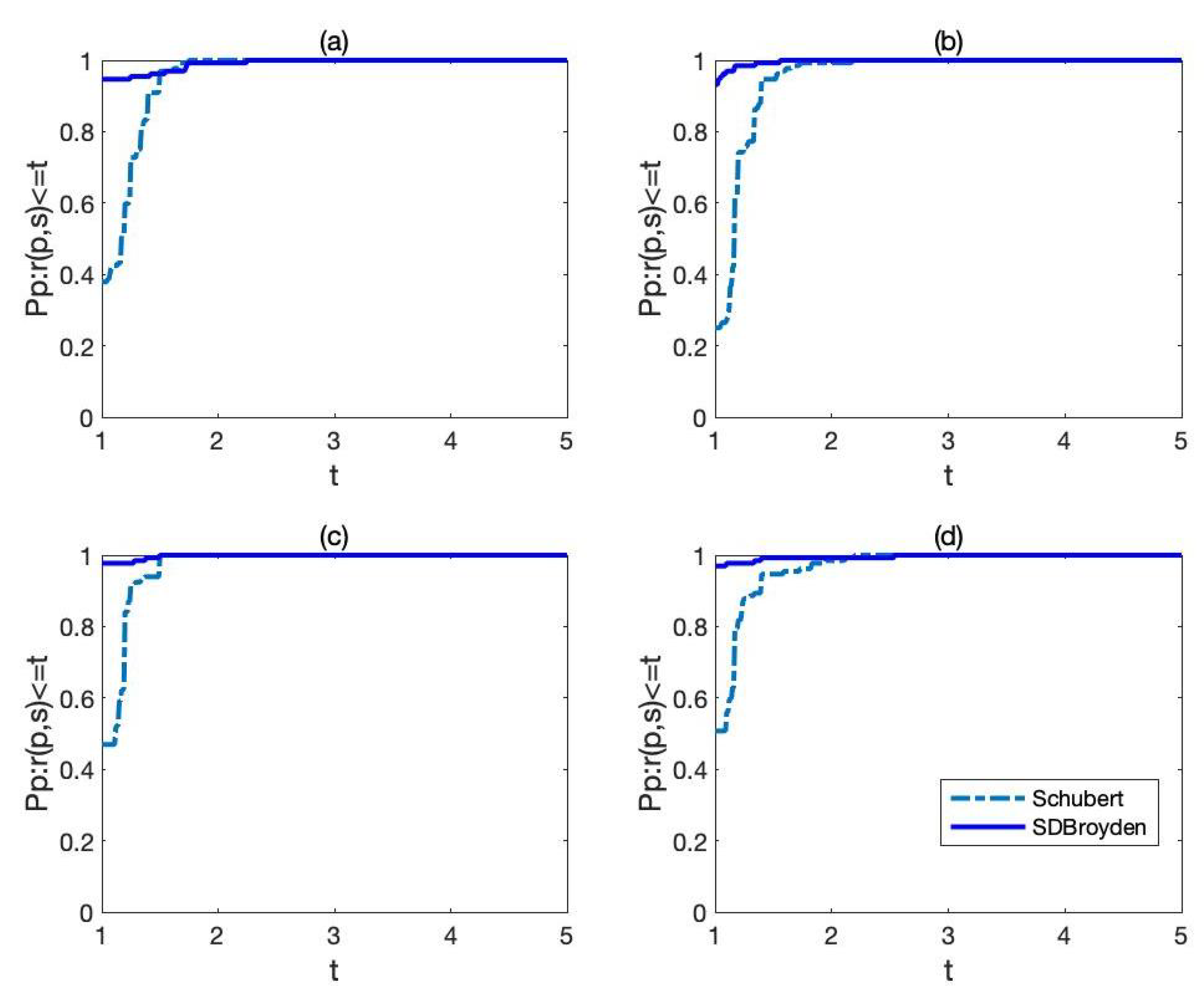
In
Figure 1, the performance of the two methods: the SDBroyden method and Schubert’s method, relative to the number of iterations, and the number of function evaluations are evaluated.
Figure 1 indicates that SDBroyden has better performance than Schubert’s method on the number of iterations and number of function evaluations.
(2) In the second set of numerical experiments, we compare the SDBroyden method with the direct Broyden quasi-Newton method (DBQN). We give the results of the DBQN method with
in
Table 5. The DBQN method fails on four problems (3, 5, 8, 9). For the number of iterations and number of function evaluations, the SDBroyden method needs less iterations on five problems (2, 4, 6, 7, 11) and equals DBQN on three problems (1, 10, 12). For the Broyden’s mean convergence rate, the SDBroyden method performs better on five problems (2, 4, 6, 7, 11), equals DBQN on two problems (1, 10), and works badly on one problem (12).
The results of the DBQN method with
are listed in
Table 6. The DBQN method fails on one problem (5). For the number of iterations, SDBroyden is better than the DBQN method on seven problems (2, 4, 6, 8, 10, 11, 12), equivalent to the DBQN method on three problems (1, 3, 9). At the same time, DBQN performs well on one problem (7). For the number of function evaluations and Broyden’s mean convergence rate, SDBroyden is excellent on six problems (2, 4, 6, 8, 11, 12), while the DBQN method works well on one problem (10). The two methods coincide with each other on three problems (3, 9, 10).
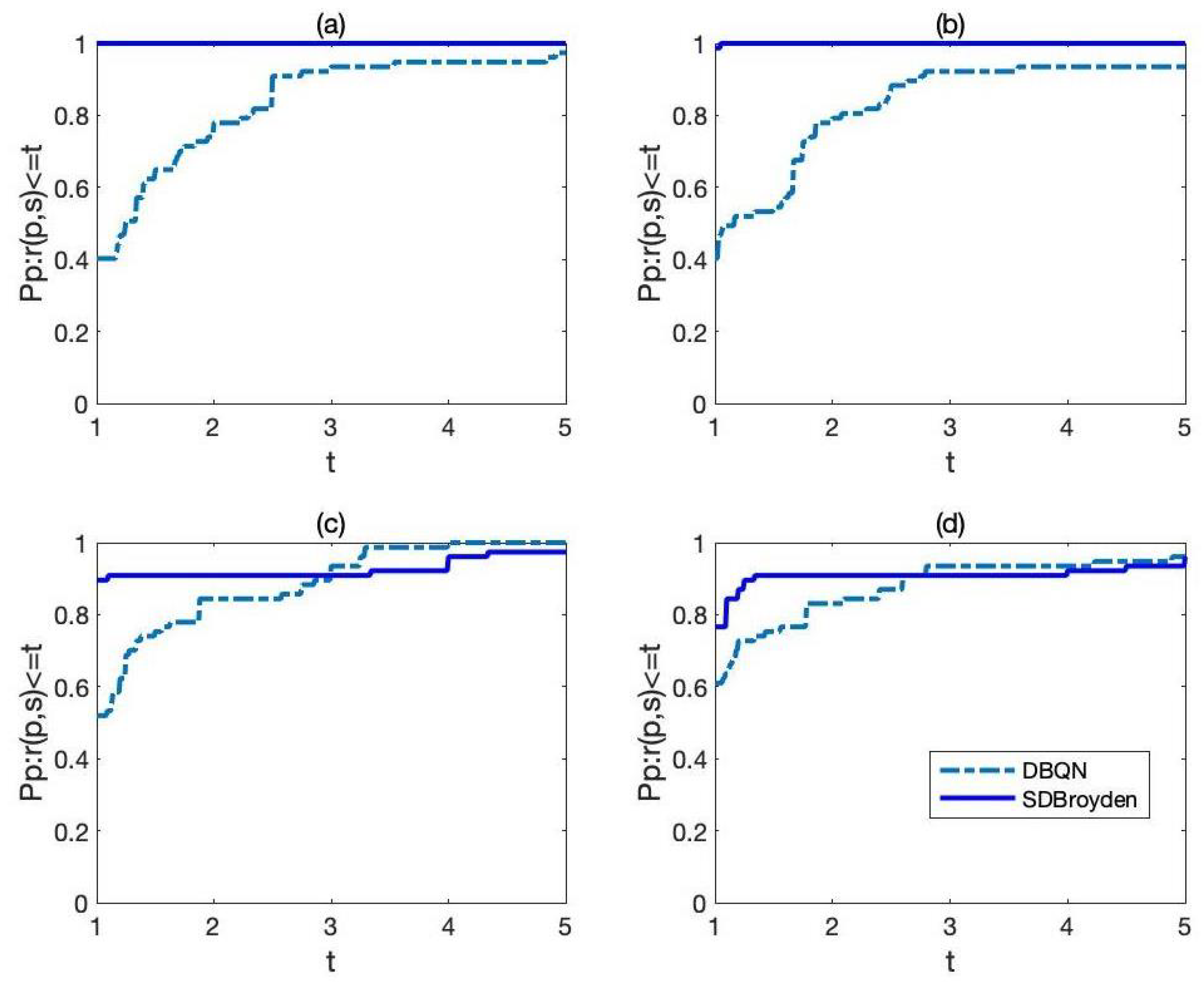
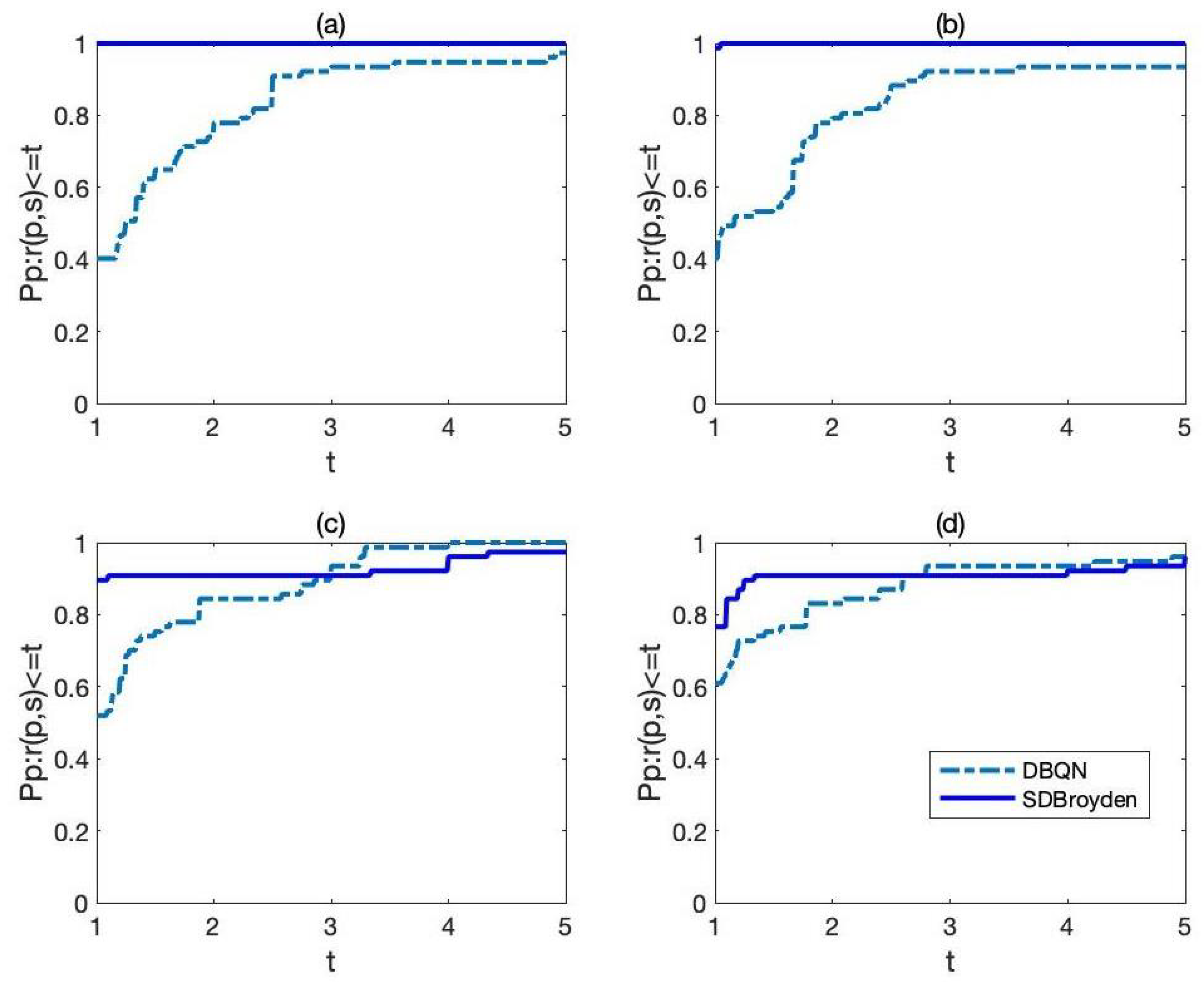
In
Figure 2, we also give the comparison of the SDBroyden method and DBQN method relative to the number of iterations and number of function evaluations. It can be seen that the top curve corresponds to the SDBroyden method. This means that the SDBroyden method has satisfactory performance in terms of number of iterations and number of function evaluations when compared with its dense version.
(3) In the third set of our numerical experiments, we compare the SDBroyden method with Newton’s method, where the results are listed in
Table 7. Newton’s method fails on three problems (5, 8, 10). One can see that the SDBroyden method requires slightly more iterations than Newton’s method in most tests and has no significant advantages in the number of iterations, number of function evaluations, and Broyden’s mean convergence rate. However, the CPU time for Newton’s method is much higher than that of the SDBroyden method. Moreover, the CPU time of Newton’s method increases significantly faster than that of the quasi-Newton methods. Thus, the SDBroyden method can be applied to solve large-scale nonlinear equations.




{kind=link}
{kind=link}