Abstract
It is extremely frequent for systems to fail in their demanding operating environments in many real-world contexts. When systems reach their lowest, highest, or both extreme operating conditions, they usually fail to perform their intended functions, which is something that researchers pay little attention to. The goal of this paper is to develop inference for multi-reliability using unit alpha power exponential distributions for stress–strength variables based on the progressive first failure. As a result, the problem of estimating the stress–strength function R, where X, Y, and Z come from three separate alpha power exponential distributions, is addressed in this paper. The conventional methods, such as maximum likelihood for point estimation, Bayesian and asymptotic confidence, boot-p, and boot-t methods for interval estimation, are also examined. Various confidence intervals have been obtained. Monte Carlo simulations and real-world application examples are used to evaluate and compare the performance of the various proposed estimators.
1. Introduction
Systems failing to perform in their harsh working settings is a common occurrence in real-life scenarios. When crossing their lower, upper, or both extreme operating conditions, systems frequently fail to perform their intended roles. Stress–strength reliability, often known as , has been extensively investigated in the literature. When the applied stress exceeds the system’s strength, a system working under such stress–strength conditions fail to function. Refs. [1,2,3,4,5,6,7,8,9,10,11] are only a few of the significant efforts in this direction. Moreover, the study of stress–strength models has been expanded to multi-component systems, which are systems with several components. Despite the fact that Ref. [12] developed the multi-component stress–strength model decades ago, it has garnered a lot of attention in recent years and has been explored by numerous scholars for both complete and filtered data [13,14,15,16,17]. Stress–strength reliability, , has been extensively investigated as a stress–strength model, and the research has also been extended to multi-component systems. However, an equally important practical scenario in which equipment fails in extreme lower and upper working environments receives significantly less attention. When electrical equipment is placed below or above a specified power supply, for example, it will fail. A person’s systolic and diastolic pressure limits should not be exceeded at the same time. There are a plethora of such applications, many of them are straightforward and natural, reflecting sound correlations between diverse real-world events. It is a valuable relationship in a variety of subfields of genetics and psychology, where strength Y should not only be more than stress X, but also less than stress Z. For numerous statistical models, several scholars have examined the estimation of the stress–strength parameter. Refs. [18,19,20] investigated the estimation of based on independent samples. Ref. [21] obtained the estimation in the stress–strength model with the assumption that a component’s strength lies in an interval and the probability where and are random stress variables and is a random strength variable. When are normal random variables, is another independent normal random variable, and the estimation of is considered. Ref. [22] calculated the reliability of a component that was subjected to two separate stresses that were unrelated to the component’s strength. Ref. [23] used a multi-component series stress–strength model to predict system reliability. Using current U-statistics, Ref. [24] proposed a straightforward computation procedure for and its variance. was used by Ref. [24] to study the cascade system. Nonparametric statistical inference for was studied by Ref. [25]. Ref. [26] achieved inference of for the n-Standby System: a Monte-Carlo simulation approach. Ref. [27] discussed for the progressive first failure of the Kumaraswamy model.
Many articles appeared in the censored sample, including a multi-component stress–strength model with adaptive hybrid progressive censored data. Ref. [28] discussed Bayesian and maximum likelihood estimation methods of reliability. Weibull distribution is a type of probability distribution. Using progressively first-failure censored data, Ref. [29] determined the reliability of a multi-component stress–strength system based on the Burr XII distribution. Under adaptive hybrid progressive censoring, Ref. [30] proposed multi-component stress–strength estimation of a non-identical component strengths system. Ref. [31] used progressive Type-II censoring data to estimate the reliability of multi-component stress–strength with a generalized linear failure rate distribution. Ref. [32] studied the estimation of multi-component reliability based on progressively Type-II censored data from unit Weibull distribution.
When dealing with reliability features in statistical analysis, even when it is known that some efficiency loss may occur, different censoring strategies, or early deletions of active units, are frequently utilized to save time and money. The Type-II censoring scheme, progressive Type-II censoring system, and progressive first failure censoring method, for example, are all well-known censoring schemes. Ref. [33] presented the progressive first failure censoring scheme, which combines progressive Type-II censoring and first failure censoring strategies to create a new life-test plan.
The progressive first failure censoring system can be summarized as follows. Assume that a life test is administered to independent groups, each having items. The units and the group in which the first failure is identified are randomly withdrawn from the experiment once the first failure has occurred. The units and the group in which the second failure is observed are randomly withdrawn from the remaining live groups at the moment of the second failure . When the -th observation fails at the end, the remaining living units are removed from the test. The resultant ordered observations are then referred to as progressive first-failure censored with a progressive censored scheme described by where are failures and the sum of all removals equals , that is, . The progressive first-failure censoring scheme is reduced to a first-failure censoring scheme when . Similarly, first-failure Type-II censoring is a special instance of this censoring technique when and . The progressive first-failure censoring scheme is simplified to the progressive Type-II censoring scheme with the premise that each group contains precisely one unit, . Progressive first-failure censoring is a generalization of progressive censoring.
Letting denote a progressive first-failure Type-II censored population sample with probability density function (PDF) and cumulative distribution function (CDF) and the progressive censoring scheme of R, on the basis of considering progressive first-failure, the likelihood function is based on Ref. [34]. The following is a censored sample:
where .
Ref. [35] constructed the APE distribution from the exponential baseline distribution and explored its essential aspects as well as parameter estimation. Ref. [36] developed the alpha power Weibull distribution and demonstrated that it outperforms certain other variants of the Weibull distribution using two real data sets. Ref. [37] used the generalized exponential baseline distribution and the APE approach to introduce the alpha power generalized exponential (APGE) distribution. Closed-form formulas for the APGE distribution’s moment properties were established by Ref. [38]. Because of APE flexibility, recently, many studies gave been conducted, such as in Refs. [39,40]. The PDF and hazard functions of the APE distribution are similar to the Weibull, gamma, and GE distributions. As a result, it can be used to replace the popular Weibull, gamma, and GE distributions. Because the APE distribution’s CDF may be precisely defined, it can also be used to evaluate censored data. The PDF, CDF, and hazard rate function of the APE with parameters and are described by
and
To the best of our knowledge, statistical inference and optimality on multi-component stress–strength models have been derived for some well-known models using progressively censored sample conditions; this subject has not received much attention under censored data. As a result, we plan to introduce multi-component reliability inference where stress–strength variables follow unit APE based on progressive first-failure. This work addresses the problem of predicting the stress–strength function R, where X, Y, and Z are three independent APE. The moments, skewness, and kurtosis measures of APE are computed. The assessment of likelihood based on increasing first-failure point estimation filtered, asymptotic confidence interval, boot-p, and boot-t approaches are also covered. Using Markov chain Monte Carlo (MCMC), Bayesian estimate methods based on progressive first-failure censoring are produced. A Bayesian estimate has made use of both symmetric and asymmetric loss functions. Based on progressive first-failure censored samples, the balanced and unbalanced loss functions were utilized to assess the reliability of the multi-stress–strength APE distribution. The different optimal schemes of the progressively censored samples are obtained. Monte Carlo simulations and real-world application examples are utilized to assess and compare the performance of the various proposed estimators.
The remainder of the paper is structured as follows: Moments of APE are calculated in Section 2. Section 3 considers the traditional point estimates, maximum likelihood estimation of R, and the parameter model under progressive first failure. Fisher information matrix of the parameter model is obtained in Section 4, while confidence intervals, namely asymptotic intervals, boot-p, and boot-t, are computed in Section 5. In Section 6, the Bayesian approach is considered. Optimization criterion is used to choose the appropriate progressive censoring approach in Section 7. Simulation research is carried out to demonstrate the relative effectiveness of multi-stress–strength reliability under progressive first failure based on different censoring methods in Section 8. Section 9 provides real-world data application examples. Finally, Section 10 has the concluding remarks of this paper.
2. Moments
Let and . Then, we have . Thus, we have
Lemma 1.
We have
where is the incomplete gamma function defined by , and is the Euler-Mascheroni constant given by .
Proof.
First, we derive . The PDF of is given by
Using the change of variable (), we have
Then, it suffices to obtain . It should be noted that . For more details, refer to Identity (6) of Ref. [41]. Thus, we have
Using the integration by parts, we have
Substituting (8) into (7), we have
Substituting (9) into (6), we have
which completes the proof. □
Thus, we have
Lemma 2.
We have
here, is the generalized hypergeometric function [42,43] defined as
where is the Pochhammer symbol for the rising factorial defined as and for.
Proof.
Using the change of variable (), we have
Since and from (8), we have
Now, it suffices to evaluate , which is in the last term in (5). After tedious calculus and algebra along with the help of Mathematica [44], we have
along with . Thus, we have
Substituting the above into (10), we have
which completes the proof. □
Then, using Lemmas 1 and 2, we have
Using and in the above, we can obtain the method-of-moments estimate as follows. We can set
Thus, by solving the above for , we can estimate . We denote this estimate as . Then, the estimate of can be explicitly obtained by setting with (11), which is given by
Figure 1 shows the skewness (SK) and kurtosis (KT) by using moment measures of quartile with different values of parameters. Table 1 discusses the first quartile, median, and third quartile and well as SK and KT of the APE distribution with different values.
Figure 1.
Three-dimensional plot of skewness and kurtosis with different values of parameters.

Table 1.
Different measures of the moment by different values of parameters.
3. Estimation in the Classical Style
In this part, the classical point and interval estimation methods are discussed, namely maximum likelihood estimation for finding point estimates of R and asymptotic, boot-p, and boot-t intervals for R for obtaining interval estimates.
Maximum Likelihood R Estimation
Let and be independent functions.
Assuming is known in this the case, we have
Figure 2 shows the different plot of multi-stress–strength reliability for different values of parameters, which explains that the multi-stress–strength reliability has different ranges.
Figure 2.
Three-dimensional plot of multi-stress–strength reliability with different values of parameters.
To obtain the MLE of R, we must first obtain the MLEs of , and . Let , and be three progressively first-failure censored samples from distribution with censoring schemes Using the formulas from (2) and (3), the likelihood function of
, and is given by
We use instead of to simplify notation. Similarity between and .
The log-likelihood function, can now be written as follows:
Taking the derivative of (14) with respect to β1, β2 and β3, we obtain
It is noted that the MLEs of and can not be found in closed form. Thus, by solving the system of nonlinear Equations (15)–(17), numerical solutions to the nonlinear system in (15)–(17) can be found using an iterative approach, such as Newton–Raphson. Then, the MLEs and can be obtained. To obtain the MLE of R, by replacing and in (5) with and as follows:
4. Fisher Information
The Fisher information matrix of the
is expressed as
where , , , ,
5. Confidence Intervals
In this section, the parameters’ confidence intervals (CIs) are computed. Because our point estimate is the most likely value for the parameter, we should build the confidence intervals on it. CIs are a set of values (intervals) that serve as good approximations of an unknown population parameter. In this investigation, two types of CIs were computed.
5.1. Approximate Confidence Intervals
Because the APE distribution’s PDF is not symmetric, asymptotic CIs based on normality do not perform well. The underlying distribution is assumed to be APE. As a result, we believe that the parametric bootstrap percentile interval is preferable to the nonparametric one. Furthermore, it is well known that the nonparametric bootstrap percentile interval does not perform well in general. See Section 5.3.1 of Ref. [45] for more information. The parametric bootstrap interval with normal approximation or Studentization can be used. However, because this CI is symmetric, it may not be suitable for our asymmetric instance. According to large sample theory, the MLE results are consistent and regularly distributed, subject to certain regularity restrictions. According to large sample theory, the MLE results are consistent and regularly distributed, subject to certain regularity restrictions. Because parameter MLE values are not in closed form, correct CIs cannot be obtained; instead, asymptotic CIs based on the asymptotic normal distribution of MLE values are computed.
Assume that . is known to yield the asymptotic distribution of MLE values of , where is the variance–covariance matrix of the unknown parameters. As previously established, the inverse of the Fisher information matrix is an estimator of the asymptomatic variance–covariance matrix.
The approximate two-sided CIs for are provided by
where is the -th upper percentile of the standard normal distribution.
5.2. Bootstrap Confidence Intervals
In this paragraph, we propose to employ two additional confidence intervals based on parametric bootstrap methods: percentile bootstrap technique (Boot-p) and bootstrap-t method (Boot-t). Obtaining the step-by-step illustrations of the two ways is shown briefly below; for more information, see Ref. [46].
5.2.1. Methods of Boot-p
- Use the sample to compute and .
- Based on censoring technique, a bootstrap progressive first-failure Type-II censored sample indicated by is constructed from the From the , a bootstrap progressive first-failure Type-II censored sample designated by is constructed using censoring scheme. Based on censoring scheme, a bootstrap progressive first-failure Type-II censored sample, indicated by , is constructed from the Based on and , construct the bootstrap sample estimate of R using (5), say .
- Step 2 should be repeated times.
- Assume , where is the cumulative distribution function. For a given , define The approximation of percent confidence interval of is given by
5.2.2. Methods of Boot-t
- Use the sample and to compute and .
- Use to generate a bootstrap sample , to generate a bootstrap sample , and similarly, to generate a bootstrap sample . Based on , and , compute the bootstrap sample estimate of R using (5), say and the following statistic:
- Step 2 should be repeated times.
- After obtaining a number of values, the boundaries of percent confidence interval are determined as follows: Assume has a cumulative distribution function given by Define for a given .
- percent boot-t confidence interval of is calculated as
- To achieve better estimates of parameters or any function of parameters, it is often advantageous to incorporate prior knowledge about the parameters, which could be prior data, expert opinion, or some other medium of knowledge. A Bayesian technique is used to include such prior knowledge into the estimation process. As a result, we now go through the Bayesian approach of estimation in depth, which incorporates previous knowledge in the form of prior distributions.
6. Bayesian Approach
Bayesian inference has gained appeal in a variety of sectors in recent years, including engineering, clinical medicine, biology, and so on. Its capacity to analyze data using prior knowledge makes it valuable in dependability studies, where data availability is a major issue. The model parameters and Bayesian estimates, as well as the corresponding credible intervals, are derived in this section.
6.1. Prior Information and Loss Function
Because the gamma distribution can take on different shapes based on the parameter values, using various gamma priors is simple and can result in more expressive posterior density estimates. As a result, we investigated gamma density priors, which are more adaptable than other challenging prior distributions and APE distribution under progressive first-failure censoring model parameters. As a result, under progressive first-failure censoring model parameters gamma , independent gamma PDFs are assumed for the APE distribution. The joint prior is as follows
where indicate prior knowledge of the unknown parameters and R and are anticipated to be non-negative.
According to the literature, choosing the symmetric loss function (SLF), (squared loss function) (SEL) is a critical issue in Bayesian analysis. The SEL function is the most often utilized SLF in this study for estimating the considered unknown values.
where and are approximations of and . The posterior mean of and is utilized to compute the objective estimate of and . In contrast, any other loss function can be easily incorporated.
6.2. Posterior Analysis by SLF
Observing the APE distribution under progressive first-failure censoring sample data from the likelihood function and the prior knowledge given both yield the joint posterior density function.
The Bayesian estimator of
and such as and , under the SEL function, is the posterior expectation of and . The marginal posterior distributions for each of the parameters ( and ) must be gathered in order to generate these estimates. However, due to the implied mathematical calculations, precise formulations for the marginal PDFs for each unknown parameter are plainly not realistic. As a result, we would like to generate Bayesian estimates and credible intervals utilizing simulation approaches such as MCMC.
The Metropolis–Hastings (MH) algorithm, which is used to generate random samples using the posterior density distribution and an independent proposal distribution to approximate Bayesian estimates and to create the associated Highest Posterior Density (HPD) credible intervals, is one of the most useful MCMC algorithms. In addition, this method provides a chain version of the Bayesian estimate that is simple to use in practice.
7. Optimization Criterion
In recent years, there has been a lot of interest in finding the optimal censoring scheme in the statistical literature; for example, see Refs. [47,48,49,50,51,52,53]. Possible censoring schemes refer to any combinations such that and finding the optimum sampling approach means locating the progressive censoring scheme that offers the most information about the unknown parameters among all conceivable progressive censoring schemes for fixed and . The first difficulty is, of course, how to generate unknown parameter information measures based on specific progressive censoring data, and the second is how to compare two distinct information measures based on two different progressive censoring techniques. The next subsections go through some of the optimality criteria that were employed in this situation. In practice, we want to select the filtering scheme that delivers the most information about the unknown parameters; see Ref. [54] for further information. In our example, Table 2 presents a number of regularly used measures to help us choose the appropriate progressive censoring approach.
Table 2.
Some practical censoring plan optimum criteria.
In terms of , our goal is to maximize the observed Fisher information values. Furthermore, our goal for criterion and is to minimize the determinant and trace of . Comparing multiple criteria is simple when dealing with single-parameter distributions; however, when dealing with unknown multi-parameter distributions, comparing the two Fisher information matrices becomes more difficult because the criterion and are not scale-invariant; see Ref. [55]. However, the optimal censoring scheme of multi-parameter distributions can be chosen using scale-invariant criteria . The criterion , which is dependent on the value of , clearly tends to minimize the variance of logarithmic MLE of the quantile, . As a result, the logarithmic for of the APE distribution is supplied by
The delta approach is applied to (3) to produce the approximated variance for of the APE distribution as
where
The optimal progressive censoring, however, corresponds to a maximum value of the criterion and a minimum value of the criteria
8. Simulation Study
A simulation study is carried out to illustrate the relative efficiency of multi-stress–strength reliability under the progressive first failure based on different censored schemes and to evaluate it as a function of changing factors of a parameter. For a better understanding of this model, we use the following procedure to produce samples from the progressive first failure based on different censored schemes for APE distribution described in Section 3.
A large number N = 1000 of progressively first-failure censored samples for a true value of parameters and different combinations of n (number of groups), m (progressively first-failure-censoring data), and k (number of items within each group) are generated from the APE by using the algorithm described in Balakrishnan and Sandhu (1995). In each case, the MLE and Bayesian of the multi-stress–strength reliability are computed. The asymptotic CIs and two parametric bootstrap CIs are used for MLE computation purposes. The HPD CIs are used for Bayesian computation purposes. The MSE and Bias values are used to compare different estimators. The average lengths are also used to compare the performances of the two-sided 95% asymptotic CI/HPD credible intervals, where the length of asymptotic CI is (LACI), length of bootstrap-p CI is (LBPCI), length of bootstrap-t CI is (LBTCI), and length of credible CI is (LCCI). Comparison between censoring schemes is made with respect to their optimum criteria measures; see Table 1, where we consider the various sampling schemes listed as follows:
- Scheme I: and ,
- Scheme II: and .
The simulation study was conducted with various values of (k, n, m), such as n = 20, 50, and k = 2 and 4 for each group size. When the number of failed participants reaches or exceeds a specified value m, the test is over, where m =12 and 18 when n = 20, and m = 35 and 45 when n = 50. The joint posterior distribution of the unknown four parameters is proportional to the likelihood function based on the non-informative priors of hyper-parameters ai, bi for I = 1, …, 4. As a result, we employed an informative prior of, and using elective hyper-parameters, the values of hyper-parameters are chosen to satisfy the prior mean, resulting in the expected value of the corresponding parameter; see Refs. [56,57]. The Bayesian estimation based on 12,000 MCMC samples and discarding the first 2000 values as “burn-in” are generated using the M-H sampler technique introduced in Section 3.
The progressive first failure of censored samples was generated from APE distribution for four sets of parametric values:
In computational analysis, extensive computations were carried out using the R statistical programming language software, with the “coda” package proposed by Ref. [58], and the “maxLik” package proposed by Henningsen and Toomet (2011), which uses the Newton–Raphson method of maximizing the computations. The average results of MLE and Bayesian for multi-stress–strength reliability are presented in Table 2 and Table 3.
Table 3 and Table 4 show that APE based on the multi-stress–strength model MLE and Bayesian of multi-stress–strength reliability is excellent in terms of MSE, Bias, and CI length (LCI). The MSE, Bias, and LCI drop as n and m rise, as expected. Furthermore, the MSE, Bias, and LCI drop as group size k grows. In terms of MSE, Bias, and LCI, Bayesian estimation utilizing gamma informative prior is also superior to MLE because it includes prior knowledge. In terms of the length of CI values, HPD credible intervals outperform asymptotic CI for interval estimation. As a result, we recommend using the M-H approach to estimate multi-stress–strength reliability using Bayesian point and interval estimates. Furthermore, when comparing Scheme I and Scheme II, it is obvious that the MLE optimum criteria measures for Scheme II are higher than for Scheme I.
Table 4.
MLE and Bayesian point and interval estimations for multi-stress–strength reliability with optimality measures when .
9. Application of Real Data
The analysis of real data is presented in this part for demonstration reasons. We look at data from three distinct voltages of 36, 34, and 32 KV that show times to breakdown of an insulating fluid between electrodes. This information is taken from page 105 of [59].
Data set 1: Times to breakdown of an insulated fluid at 32 KV (Z): 0.27, 0.40, 0.69, 0.79, 0.75, 2.75, 3.91, 9.88, 13.95, 15.93, 27.80, 53.24, 82.85, 89.29, 100.58, 215.10.
Data set 2: Times to breakdown of an insulated fluid at 34 KV (Y): 0.19, 0.78, 0.96, 1.31, 2.78, 3.16, 4.15, 4.67, 4.85, 6.50,7.35, 8.01, 8.27, 12.06, 31.75, 32.52, 33.91, 36.71, 72.89.
Data set 3: Times to breakdown of an insulated fluid at 36 KV (X): 0.35, 0.59, 0.96, 0.99, 1.69, 1.97, 2.07, 2.58, 2.71, 2.90,3.67, 3.99, 5.35, 13.77, 25.50.
Ref. [60] discusses the estimation of R = P[Y < X < Z] of the Weibull distribution. Table 5 discusses parameter estimation with stander error (SE) for this model and R = P[Y < X < Z] by the MLE method.
Table 5.
MLE with SE and R = P[Y < X < Z] for the Weibull model.
First, we check the fitting of APE distribution to this data; see Table 6. Distance of Kolmogorov–Smirnov (DKS) with p values (PVKS) for three distinct voltages data. The values of KSD statistics are found to be 0.2598, 0.1612, and 0.1427 with corresponding PVKS 0.2214, 0.6492, and 0.8786. The p values indicate that the APE distribution with the above-mentioned parameters is a suitable model for modeling these three data sets. The plots of the estimated PDF, CDF, and PP plot of the three data sets in Figure 3, Figure 4 and Figure 5 also confirm the same.
Table 6.
MLE with SE, KSD, and different measures for three distinct voltages data.
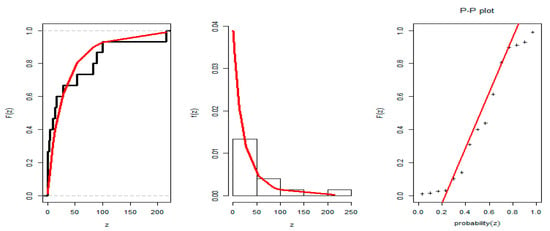
Figure 3.
Plots of the estimated PDF, CDF, and PP of APE distribution in data set I.
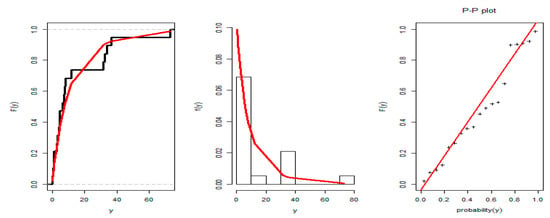
Figure 4.
Plots of the estimated PDF, CDF and PP plot of APE distribution in data set II.
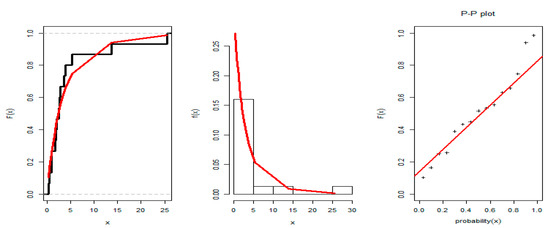
Figure 5.
Plots of the estimated PDF, CDF, and PP plot of APE distribution in data set III.
Based on the complete data, the MLE and Bayesian estimate for the APE model of R = P[Y < X < Z] are found to be 0.4523 and 0.4570, respectively, as shown in Table 7. Here, it is to be noted in the Bayesian estimation of parameters that we use informative priors, as gamma prior is available regarding the model parameters. From the results of Table 7, we show that the Bayesian estimation is the best estimation of this model where the multi-stress–strength reliability R = P[Y < X < Z] is larger than MLE. In addition, the SE of Bayesian is smaller than MLE. Figure 6 shows the contour plot of the log-likelihood function of this model with different values of parameters to check the unique and global values of these parameters. Figure 7 discusses the MCMC trace, convergence, and plot of the posterior distribution of this model.
Table 7.
MLE and Bayesian estimation for the parameters and R = P[Y < X < Z] for the APE model.
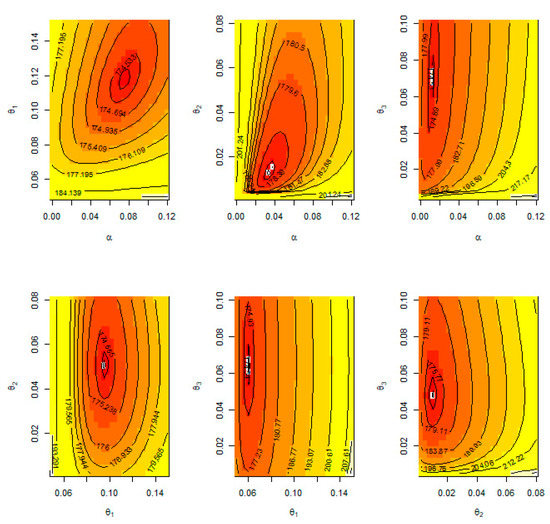
Figure 6.
Contour plot of log-likelihood function with different values of parameters; complete sample.
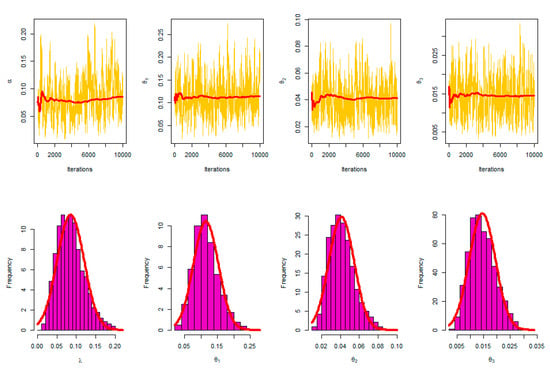
Figure 7.
MCMC trace, convergence and plot of posterior distribution; complete sample.
10. Conclusions
In this paper, inference for multi-reliability using unit alpha power exponential distributions for stress–strength variables based on the progressive first failure is considered. The conventional methods such as maximum likelihood and Bayesian methods for point estimation of the parameter model and R are obtained. The Fisher information and confidence intervals such as asymptotic, boot-p, and boot-t methods are also examined. Various optimal criteria have been found. Monte Carlo simulations and real-world application examples are used to evaluate and compare the performance of the various proposed estimators.
Author Contributions
Investigation, R.A., E.M.A., A.A.M., C.P., and H.R.; methodology, R.A., C.P., and H.R.; software, R.A. and E.M.A.; validation, R.A., A.A.M., E.M.A., C.P., and H.R.; writing, R.A., E.M.A., and H.R.; funding acquisition, R.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R50), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are included within the article.
Acknowledgments
The authors extend their appreciation to Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R50), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Weerahandi, S.; Johnson, R.A. Testing reliability in a stress-strength model when X and Y are normally distributed. Technometrics 1992, 34, 83–91. [Google Scholar] [CrossRef]
- Surles, J.G.; Padgett, W.J. Inference for reliability and stress-strength for a scaled Burr Type X distribution. Lifetime Data Anal. 2001, 7, 187–200. [Google Scholar] [CrossRef] [PubMed]
- Al-Mutairi, D.K.; Ghitany, M.E.; Kundu, D. Inferences on stress-strength reliability from Lindley distributions. Commun. Stat.—Theory Methods 2013, 42, 1443–1463. [Google Scholar] [CrossRef]
- Rao, G.S.; Aslam, M.; Kundu, D. Burr-XII distribution parametric estimation and estimation of reliability of multicomponent stress-strength. Commun. Stat.—Theory Methods 2015, 44, 4953–4961. [Google Scholar] [CrossRef]
- Singh, S.K.; Singh, U.; Yaday, A.; Viswkarma, P.K. On the estimation of stress strength reliability parameter of inverted exponential distribution. Int. J. Sci. World 2015, 3, 98–112. [Google Scholar] [CrossRef][Green Version]
- Abo-Kasem, O.E.; Almetwally, E.M.; Abu El Azm, W.S. Inferential Survival Analysis for Inverted NH Distribution Under Adaptive Progressive Hybrid Censoring with Application of Transformer Insulation. Ann. Data Sci. 2022, 1–48. [Google Scholar] [CrossRef]
- Alshenawy, R.; Sabry, M.A.; Almetwally, E.M.; Almongy, H.M. Product Spacing of Stress-Strength under Progressive Hybrid Censored for Exponentiated-Gumbel Distribution. Comput. Mater. Contin. 2021, 66, 2973–2995. [Google Scholar] [CrossRef]
- Alamri, O.A.; Abd El-Raouf, M.M.; Ismail, E.A.; Almaspoor, Z.; Alsaedi, B.S.; Khosa, S.K.; Yusuf, M. Estimate stress-strength reliability model using Rayleigh and half-normal distribution. Comput. Intell. Neurosci. 2021, 7653581. [Google Scholar] [CrossRef]
- Sabry, M.A.; Almetwally, E.M.; Alamri, O.A.; Yusuf, M.; Almongy, H.M.; Eldeeb, A.S. Inference of fuzzy reliability model for inverse Rayleigh distribution. AIMS Math. 2021, 6, 9770–9785. [Google Scholar] [CrossRef]
- Abu El Azm, W.S.; Almetwally, E.M.; Alghamdi, A.S.; Aljohani, H.M.; Muse, A.H.; Abo-Kasem, O.E. Stress-Strength Reliability for Exponentiated Inverted Weibull Distribution with Application on Breaking of Jute Fiber and Carbon Fibers. Comput. Intell. Neurosci. 2021, 4227346. [Google Scholar] [CrossRef]
- Okabe, T.; Otsuka, Y. Proposal of a Validation Method of Failure Mode Analyses based on the Stress-Strength Model with a Support Vector Machine. Reliab. Eng. Syst. Saf. 2021, 205, 107247. [Google Scholar] [CrossRef]
- Bhattacharyya, G.K.; Johnson, R.A. Estimation of reliability in a multicomponent stress-strength model. J. Am. Stat. Assoc. 1974, 69, 966–970. [Google Scholar] [CrossRef]
- Kotb, M.S.; Raqab, M.Z. Estimation of reliability for multi-component stress–strength model based on modified Weibull distribution. Stat. Pap. 2021, 62, 2763–2797. [Google Scholar] [CrossRef]
- Maurya, R.K.; Tripathi, Y.M. Reliability estimation in a multicomponent stress-strength model for Burr XII distribution under progressive censoring. Braz. J. Probab. Stat. 2020, 34, 345–369. [Google Scholar] [CrossRef]
- Mahto, A.K.; Tripathi, Y.M.; Kızılaslan, F. Estimation of Reliability in a Multicomponent Stress-Strength Model for a General Class of Inverted Exponentiated Distributions Under Progressive Censoring. J. Stat. Theory Pract. 2020, 14, 58. [Google Scholar] [CrossRef]
- Alotaibi, R.M.; Tripathi, Y.M.; Dey, S.; Rezk, H.R. Bayesian and non-Bayesian reliability estimation of multicomponent stress–strength model for unit Weibull distribution. J. Taibah Univ. Sci. 2020, 14, 1164–1181. [Google Scholar] [CrossRef]
- Maurya, R.K.; Tripathi, Y.M.; Kayal, T. Reliability Estimation in a Multicomponent Stress-Strength Model Based on Inverse Weibull Distribution. Sankhya B 2022, 84, 364–401. [Google Scholar] [CrossRef]
- Chandra, S.; Owen, D.B. On estimating the reliability of a component subject to several different stresses (strengths). Nav. Res. Logist. Quart. 1975, 22, 31–39. [Google Scholar]
- Dutta, K.; Sriwastav, G.L. An n-standby system with P(X < Y < Z). IAPQR Trans. 1986, 12, 95–97. [Google Scholar]
- Ivshin, V.V. On the estimation of the probabilities of a double linear inequality in the case of uniform and two-parameter exponential distributions. J. Math. Sci. 1998, 88, 819–827. [Google Scholar] [CrossRef]
- Singh, N. On the estimation of Pr(X1 < Y < X2). Commun. Statist. Theory Meth. 1980, 9, 1551–1561. [Google Scholar]
- Hlawka, P. Estimation of the Parameter p = P(X < Y < Z); No.11, Ser. Stud. i Materiaty No. 10 Problemy Rachunku Prawdopodobienstwa; Prace Nauk. Inst. Mat. Politechn.: Wroclaw, Poland, 1975; pp. 55–65. [Google Scholar]
- Hanagal, D.D. Estimation of system reliability in multicomponent series stress-strength model. J. Indian Statist. Assoc. 2003, 41, 1–7. [Google Scholar]
- Waegeman, W.; De Baets, B.; Boullart, L. On the scalability of ordered multi-class ROC analysis. Comput. Statist. Data Anal. 2008, 52, 33–71. [Google Scholar] [CrossRef]
- Chumchum, D.; Munindra, B.; Jonali, G. Cascade System with Pr(X < Y < Z). J. Inform. Math. Sci. 2013, 5, 37–47. [Google Scholar]
- Patowary, A.N.; Sriwastav, G.L.; Hazarika, J. Inference of R = P(X < Y < Z) for n-Standby System: A Monte-Carlo Simulation Approach. J. Math. 2016, 12, 18–22. [Google Scholar]
- Yousef, M.M.; Almetwally, E.M. Multi stress-strength reliability based on progressive first failure for Kumaraswamy model: Bayesian and non-Bayesian estimation. Symmetry 2021, 13, 2120. [Google Scholar] [CrossRef]
- Kohansal, A.; Shoaee, S. Bayesian and classical estimation of reliability in a multicomponent stress-strength model under adaptive hybrid progressive censored data. Stat. Pap. 2021, 62, 309–359. [Google Scholar] [CrossRef]
- Saini, S.; Tomer, S.; Garg, R. On the reliability estimation of multicomponent stress–strength model for Burr XII distribution using progressively first-failure censored samples. J. Stat. Comput. Simul. 2022, 92, 667–704. [Google Scholar] [CrossRef]
- Kohansal, A.; Fernández, A.J.; Pérez-González, C.J. Multi-component stress–strength parameter estimation of a non-identical component strengths system under the adaptive hybrid progressive censoring samples. Statistics 2021, 55, 925–962. [Google Scholar] [CrossRef]
- Hassan, M.K. On Estimating Standby Redundancy System in a MSS Model with GLFRD Based on Progressive Type II Censoring Data. Reliab. Theory Appl. 2021, 16, 206–219. [Google Scholar]
- Alotaibi, R.; Tripathi, Y.; Dey, S.; Rezk, H. Estimation of multicomponent reliability based on progressively Type II censored data from unit Weibull distribution. WSEAS Trans. Math. 2021, 20, 288–299. [Google Scholar] [CrossRef]
- Wu, S.J.; Kus, C. On estimation based on progressive first-failure-censored sampling. Comput. Stat. Data Anal. 2009, 53, 3659–3670. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Springer Science & Business Media Birkhauser Boston: Cambridge, MA, USA, 2000. [Google Scholar]
- Mahdavi, A.; Kundu, D. A new method for generating distributions with an application to exponential distribution. Commun. Stat. Theory Methods 2017, 46, 6543–6557. [Google Scholar] [CrossRef]
- Nassar, M.; Alzaatreh, A.; Mead, M.; Abo-Kasem, O. Alpha power Weibull distribution: Properties and applications. Commun. Stat.—Theory Methods 2017, 46, 10236–10252. [Google Scholar] [CrossRef]
- Dey, A.; Alzaatreh, A.; Zhang, C.; Kumar, D. A new extension of generalized exponential distribution with application to ozone data. Ozone Sci. Eng. 2017, 39, 273–285. [Google Scholar] [CrossRef]
- Nadarajah, S.; Okorie, I.E. On the moments of the alpha power transformed generalized exponential distribution. Ozone Sci. Eng. 2018, 40, 330–335. [Google Scholar] [CrossRef]
- Alotaibi, R.; Elshahhat, A.; Rezk, H.; Nassar, M. Inferences for Alpha Power Exponential Distribution Using Adaptive Progressively Type-II Hybrid Censored Data with Applications. Symmetry 2022, 14, 651. [Google Scholar] [CrossRef]
- Alotaibi, R.; Al Mutairi, A.; Almetwally, E.M.; Park, C.; Rezk, H. Optimal Design for a Bivariate Step-Stress Accelerated Life Test with Alpha Power Exponential Distribution Based on Type-I Progressive Censored Samples. Symmetry 2022, 14, 830. [Google Scholar] [CrossRef]
- Dence, T.P.; Dence, J.B. A survey of Euler’s constant. Math. Mag. 2009, 82, 255–265. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables; 55 of National Bureau of Standards Applied Mathematics Series; U.S. Government Printing Office: Washington, DC, USA, 1964.
- Seaborn, J.B. Hypergeometric Functions and Their Applications; Springer: New York, NY, USA, 1991. [Google Scholar]
- Wolfram Research, Inc. Mathematica—Wolfram/Alpha; Davison and Hinkley: Champaign, IL, USA, 1997. [Google Scholar]
- Davison, A.C.; Hinkley, D.V. Bootstrap Methods and Their Application; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Tibshirani, R.; Efron, B. An Introduction to the Bootstrap; Chapman & Hall, Inc.: New York, NY, USA, 1993. [Google Scholar]
- Ng, H.K.T.; Chan, C.S.; Balakrishnan, N. Optimal progressive censoring plans for the Weibull distribution. Technometrics 2004, 46, 470–481. [Google Scholar] [CrossRef]
- Balasooriya, U.; Balakrishnan, N. Reliability sampling plans for log-normal distribution, based on progressively-censored samples. IEEE Trans. Reliab. 2000, 49, 199–203. [Google Scholar] [CrossRef]
- Balasooriya, U.; Saw, S.L.C.; Gadag, V. Progressively censored reliability sampling plans for the Weibull distribution. Technometrics 2000, 42, 160–167. [Google Scholar] [CrossRef]
- Burkschat, M.; Cramer, E.; Kamps, U. Optimality criteria and optimal schemes in progressive censoring. Commun. Stat.—Theory Methods 2007, 36, 1419–1431. [Google Scholar] [CrossRef]
- Burkschat, M.; Cramer, E.; Kamps, U. On optimal schemes in progressive censoring. Stat. Probab. Lett. 2006, 76, 1032–1036. [Google Scholar] [CrossRef]
- Burkschat, M. On optimality of extremal schemes in progressive type II censoring. J. Stat. Plan. Inference 2008, 138, 1647–1659. [Google Scholar] [CrossRef]
- Pradhan, B.; Kundu, D. On progressively censored generalized exponential distribution. Test 2009, 18, 497–515. [Google Scholar] [CrossRef]
- Elshahhat, A.; Rastogi, M.K. Estimation of parameters of life for an inverted Nadarajah–Haghighi distribution from Type-II progressively censored samples. J. Indian Soc. Probab. Stat. 2021, 22, 113–154. [Google Scholar] [CrossRef]
- Gupta, R.D.; Kundu, D. On the comparison of Fisher information of the Weibull and GE distributions. J. Stat. Plan. Inference 2006, 136, 3130–3144. [Google Scholar] [CrossRef]
- Almongy, H.M.; Alshenawy, F.Y.; Almetwally, E.M.; Abdo, D.A. Applying transformer insulation using Weibull extended distribution based on progressive censoring scheme. Axioms 2021, 10, 100. [Google Scholar] [CrossRef]
- El-Sherpieny, E.S.A.; Almetwally, E.M.; Muhammed, H.Z. Bayesian and non-bayesian estimation for the parameter of bivariate generalized Rayleigh distribution based on clayton copula under progressive type-II censoring with random removal. Sankhya A 2021, 1–38. [Google Scholar] [CrossRef]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence diagnosis and output analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Nelson, W.B. Applied Life Data Analysis; John Wiley & Sons.: Hoboken, NJ, USA, 2003. [Google Scholar]
- Choudhary, N.; Tyagi, A.; Singh, B. Estimation of R = P[Y < X < Z] under Progressive Type-II Censored Data from Weibull Distribution. Lobachevskii J. Math. 2021, 42, 318–335. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).