Abstract
In this paper, a five-parameter distribution, Khalil’s new generalized Weibull distribution, is defined and studied in detail. Some mathematical and statistical functions are studied. The effects of shape parameters on skewness and kurtosis are studied. Extensions for density and distribution functions are provided. Estimation of the intended model parameters based on ranked samples is investigated. The behavior of the maximum likelihood estimators is examined using a Monte Carlo simulation. In order to predict unique symmetric and asymmetric patterns and illustrate the applicability and potential of the intended distribution, a COVID-19 dataset is analyzed. The goodness-of-fit results of the new generalized Weibull model of Khalil are compared with some other models. Finally, we make some concluding remarks.
1. Introduction
In order to achieve the goals that the researcher has set for his or her research, the researcher must collect data and information about that research. Since some data may be difficult to obtain or unacceptable due to cost, labor, and time constraints, he must choose the sampling method that will guarantee that he will achieve the research objectives with the least amount of time and expense—or, in many practical cases, it is not possible to obtain true measurements of the variables of interest, which is expensive and therefore a waste of time. To solve these problems, it is necessary to use a sampling method that ensures that time, effort, and cost are reduced in obtaining data.
The Ranked Set Sampling (RSS) method was proposed by McIntyre [1] as an inexpensive and effective method for estimating pasture yield. Although the RSS method is not parametric, many authors have used it to estimate parameters for many distributions and have demonstrated that its estimates are more effective than estimates based on simple random sampling and the same sample size. More detailed information can be found in [2,3,4,5]. Therefore, the aim of this work was to estimate the parameters of the Khalil new generalized Family-Weibull Distribution (KHGWD) considering ordered groups.
We now briefly introduce the RSS strategy used in the supplements. Consider an absolutely continuous random variable with the cumulative distribution function (CDF) and the probability density function (PDF). Then, a simple random sample of size n derived from the random variable is denoted by . Suppose further that a random sample of size is selected and randomly divided into n groups of equal size. Then, RSS is observed according to the following pattern:
The RSS vector of observations is given by , where is the statistic of order ith in the group jth based on a given simple random sample of size n. Then, as is well known, the PDF of is
For more details, see Arnold et al. [6].
| (1) | … | → | ||||
| (2) | … | → | ||||
| . | ||||||
| . | ||||||
| . | ||||||
| (n) | … | → |
Next, Najma et al. [7] proposes a new method to extend the family of lifetime distributions. The method is called Khalil new generalized family of distributions. For any baseline CDF and a PDF , the CDF and the PDF of the new generalized family of Khalil distributions are respectively given by
and
where and are the scale and shape parameters, respectively.
In 1939, Swedish scientist Waloddi Weibull established the Weibull distribution in a study of the breaking strength of instruments. The Weibull distribution is one of the most commonly used failure models. The Weibull distribution is used to simulate many probabilistic applications; this is due to its unique symmetric and asymmetric patterns. The distribution has several desirable properties, acceptable physical interpretations, and the ability to fit the failure rates of various systems, whether those rates are high, low, or constant.
Let X be a random variable (R.V.) that follows the Weibull distribution with three parameters , then its CDF, denoted by is given by
Here, is the location parameter, , , and are the shape and the scale parameter, respectively. The corresponding PDF, denoted by is given by
2. The Khalil New Generalized Family-Weibull Distribution (KHGWD)
Take and in Equations (2) and (3) as of Equation (4) and of Equation (5), respectively. The CDF and the PDF of KHGWD are respectively given by
and
where , , and are two scale parameters, and are two shape parameters, and is a location parameter.
The survival function and hazard rate function of time t via KHGWD are, respectively, given be
and
In what follows, an R.V. X with the KHGWD (7) is denoted by . Figure 1, Figure 2 and Figure 3 show various survival functions (SF), PDF, and hazard rate functions (HRF) for the . The right panel for KHGWD(1.10, 2.80, 0.50, 1.40, 0.20), KHGWD(0.30, 0.80, 0.60, 2.90, 0.12), KHGWD(9.02, 6.90, 0.50, 1.90, 0.20), KHGWD(1.2, 3.90, 0.65, 0.90, 0.20), and KHGWD(0.20, 3.90, 0.30, 1.10, 0.01), while the left panel for KHGWD(5.10, 0.50, 6.50, 1.40, 1.20) and KHGWD(0.10, 0.50, 6.50, 1.40, 1.20), KHGWD(5.10, 0.80, 6.50, 1.40, 1.20), KHGWD(5.10, 0.50, 2.80, 1.40, 1.20), and KHGWD(5.10, 0.50, 6.50, 2.40, 1.20).
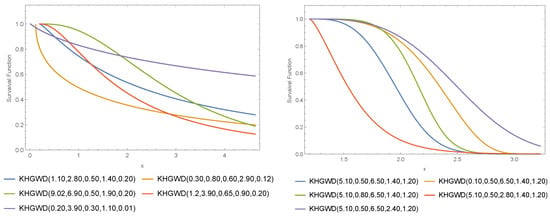
Figure 1.
Different SF for the .
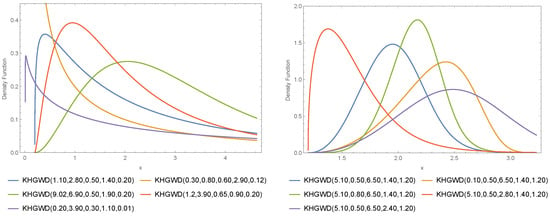
Figure 2.
Different PDF for the .
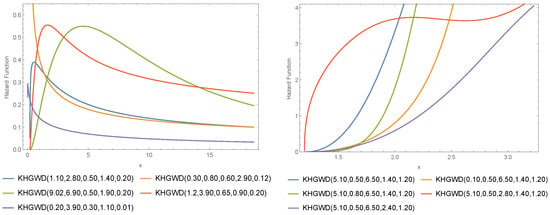
Figure 3.
Different HRF for the .
The model is sometimes very flexible. It seems to approach the bell curve with some torsion, as seen in the right panel of Figure 2. At other times, it seems to have strong tails, as seen in the left panel of Figure 2, which depends on the particular values of the parameters. The left panel of Figure 2 also shows that the proposed model has heavy tails when the parameters are increased. Based on the behavior of the proposed model shown in Figure 2, it is a good candidate for modeling semi-normal data (right part) and data with heavy tails (left part) in various financial, industrial, medical, and global epidemiological applications which have the same behavior. However, from the plots in Figure 3, it is clear that the KHGWD has unimodal and increasing failure rate functions. The unimodal and increasing failure rate functions are another superiority of the proposed model along with the heavy-tailed behavior. Therefore, the proposed model is suitable for modeling COVID-19.
3. Mathematical Properties
This section is devoted to deriving some mathematical properties of the .
3.1. Quantile Function
To generate random variables by Monte Carlo simulation, the quantile function of the distribution is required. Assuming , we solved the following equation for the quantile function :
Letting , we have
By solving for y, we have
Thus,
where is the quantile of the baseline distribution . Inverting in (6), we can write
By setting x as a uniform R.V. in the unit interval (0, 1), we can also use (14) for simulating R.V.s. Figure 4 plots different quantile functions for the , and particularly for (1) (2) , (3) . (4) (5) , respectively. Some numerical values of the quantile measure are provided in Table 1.
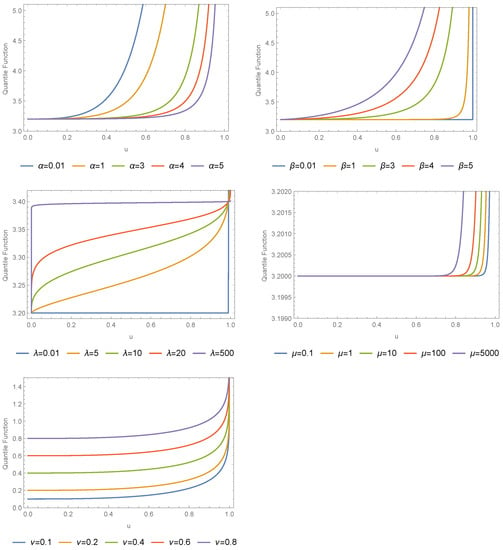
Figure 4.
Different quantile functions for the .

Table 1.
Some quantile values for and .
In addition, the effects of shape parameters on skewness and kurtosis can be determined using quantile measures. We obtain skewness and kurtosis measures of . The skewness (SK) (see Bowley [8]) of X is given by
and the Kurtosis (K) (see Moor [9]) is given by
Figure 5 shows and for different values of and . Figure 6, on the other hand, shows and for different values of and .
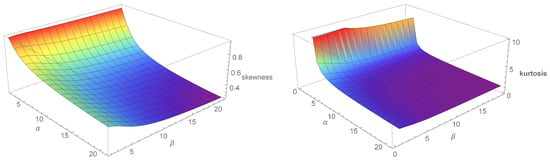
Figure 5.
Plots for the and .
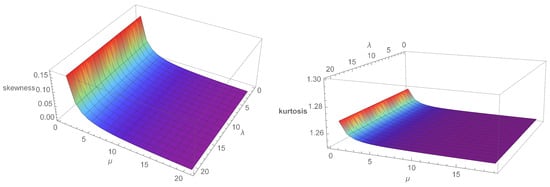
Figure 6.
Plots for the and .
3.2. The Expansion for KHGWD Density Function
3.3. The Expansion for the KHGWD Distribution Function
4. Estimation of the Parameters Based on the Ranked Set Samples
Let be the observed sample, where is the ith order statistic in the jth group. The likelihood function based on the , is given by
where and are the baseline CDF (6) and PDF (7), respectively. The corresponding log-likelihood function is given by
where is constant. The first partial derivatives of log-likelihood (20) with respect to , respectively, are given by
and
where
and
5. Monte Carlo Simulation Study
This section is concerned with evaluating the performance of the maximum likelihood estimators of through a Monte Carlo simulation study. The R program through the optimum function can used to compute the simulation and application results. The Weibull location parameter was set to zero to simplify the calculations.
The simulation of the KHGWD model is performed for two parameter sets:
- Set 1:
- Set 2:
The simulation study is performed as follows.
- Random samples of sizes are generated from KHGWD and are randomly divided into r groups of equal size m, where and 30, respectively.
- The model parameters have been estimated via the maximum likelihood method.
- Five-thousand repetitions are made to calculate these estimators’ biases, absolute biases, and mean square errors (MSEs).
- The formulas for obtaining the estimate, biases, and MSEs are given respectively, byandrespectively.
- Step (4) is also repeated for the parameters and .
The simulation results of the KHGWD for Set 1 and Set 2 are presented in Table 2 and Table 3, respectively. Figure 7 and Figure 8 displays graphically the results provided in Table 2 and Table 3, respectively.
Table 2.
Simulation results of the KHGWD for Set 1.
Table 3.
Simulation results of the KHGWD for Set 2.
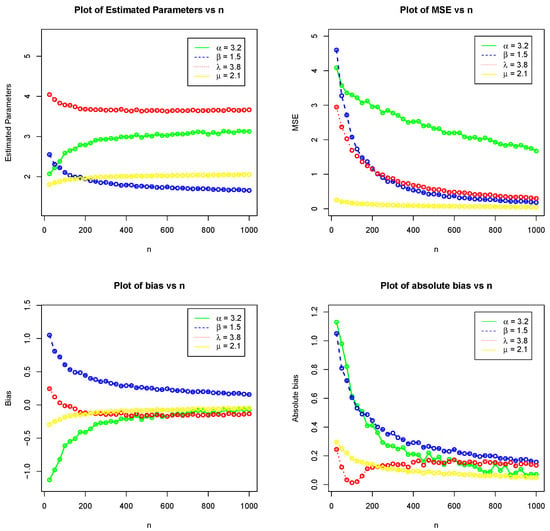
Figure 7.
Plot of the simulation results of the KHGWD for Set 1.
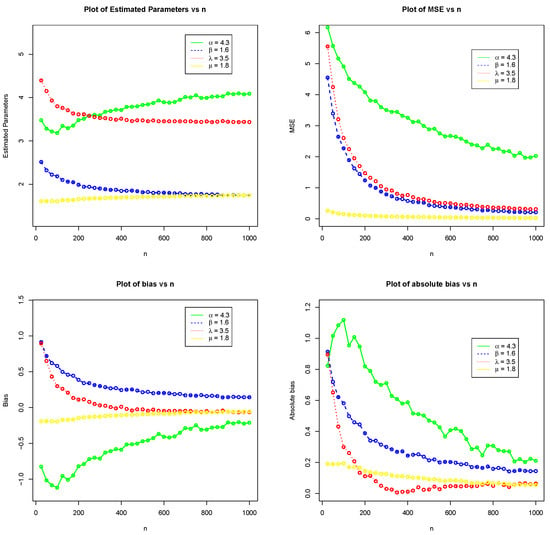
Figure 8.
Plot of the simulation results of the KHGWD for Set 2.
Figure 7 and Figure 8 illustrate the simulation results for the above measures. These plots show that increasing the sample size n leads to a reduction in the estimated biases. In addition, increasing the sample size n leads to a decrease in the estimated MSEs, which approaches zero as n increases. These results demonstrate both the efficiency and consistency properties of the MLEs.
6. COVID-19 Data
The COVID-19 dataset of Hong and Li [10] is considered an application of the KHGWD model and is randomly divided into seven groups of similar seven observations. Table 4 shows the descriptive statistics of the proposed COVID-19 data. The boxplot and Q-Q plot are shown in Figure 9. By performing the maximum likelihood estimators of by Monte Carlo simulation study for , the estimated parameters are , , and . Figure 10: Plots of the fitted PDF of KHGWD and CDF. Figure 11: PP plot and Kaplan–Meier survival function of KHGWD.
Table 4.
Descriptive statistics of the COVID-19 data.
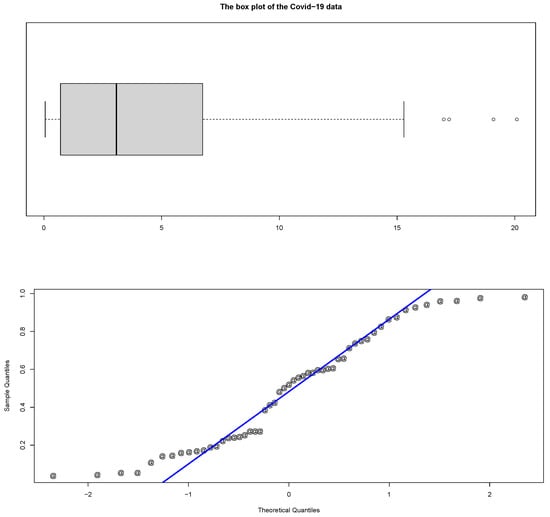
Figure 9.
The boxplot and Q-Q plot of the COVID-19 data.
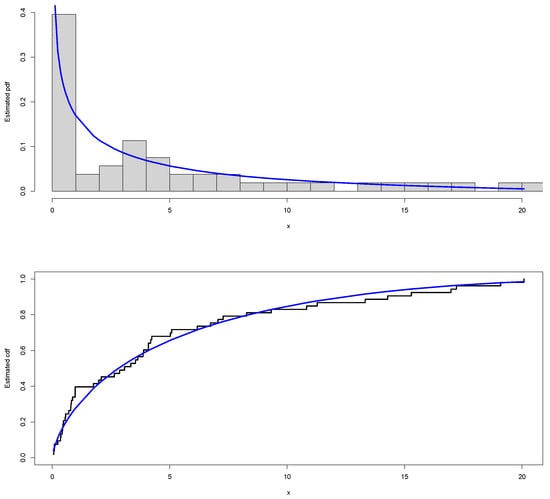
Figure 10.
The fitted PDF and CDF of the KHGWD.
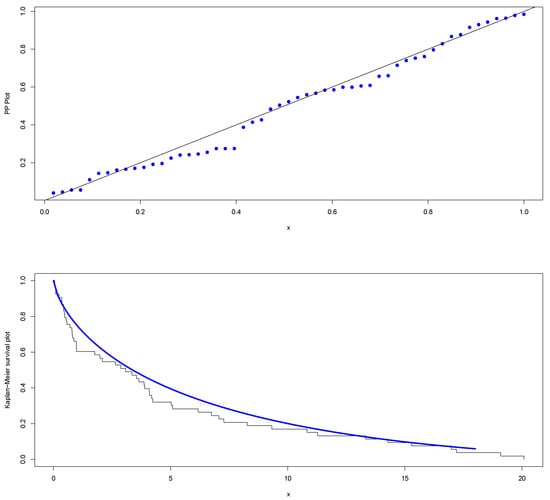
Figure 11.
The PP plot and the Kaplan–Meier survival function of the KHGWD.
Table 5 compares the KHGWD based on one-sample Kolmogorov–Smirnov test. The goodness-of-fit results of the KHGWD model are compared with some other models, including the Khalil generalized exponential distribution (KHGEXP), the Khalil generalized gamma distribution (KHGGamma), and Weibull distribution. The distribution functions of these competitive distributions are given by
Table 5.
Relative quality of the KHGWD vs. competing models.
(1) KHGEXP distribution:
(2) KHGGamma distribution:
where is the lower incomplete gamma function.
(3) Weibull distribution:
Based on the results presented in Table 5, we see that KHGWD is a good competitor among the competing models for modeling the COVID-19 data.
7. Conclusions
We introduced the new generalized Weibull distribution of Khalil with five parameters. The model has a high degree of flexibility to fit the appropriate data. The model is unimodal, has a strong tail-heavy behavior, and exhibits increasing failure rate functions. We have studied some mathematical and statistical functions and the effects of shape parameters on skewness and kurtosis. We have provided density and distribution functions in an extended form. Based on ranked samples, the maximum likelihood estimators for the intended model parameters and a Monte Carlo simulation study are provided. A COVID-19 dataset is analyzed to illustrate the applicability and potential of the intended distribution. The biases and mean square errors decrease as the sample size increases. It is clear that the proposed model fits the estimated PDF and CDF plots well. The COVID-19 dataset has a strong deflection that is skewed to the right in the boxplot. The proposed model fits the Kaplan–Meier survival plot very well. The new generalized Weibull distribution of Khalil, based on the Kolmogorov–Smirnov one-sample test, provides a better fit than other competing models. The results show that the model is considered ideal for modeling COVID-19.
Author Contributions
Formal analysis, W.E.; Funding acquisition, Y.A.T.; Methodology, W.E.; Software, W.E.; Supervision, W.E.; Writing—original draft, W.E.; Writing—review and editing, Y.A.T. All authors have read and agreed to the published version of the manuscript.
Funding
The study was funded by Researchers Supporting Project number (RSP2022R488), King Saud University, Riyadh, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are available on request (wemam.c@KSU.EDU.SA).
Conflicts of Interest
The authors declare no conflict of interest.
References
- McIntyre, G.A. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 1952, 3, 385–390. [Google Scholar] [CrossRef]
- Frey, J. A note on Fisher information and imperfect ranked-set sampling. Commun. Stat.-Theory Methods 2014, 43, 2726–2733. [Google Scholar] [CrossRef]
- Park, S.; Lim, J. On the effect of imperfect ranking on the amount of Fisher information in ranked set samples. Commun. Stat.-Theory Methods 2012, 413, 3608–3620. [Google Scholar] [CrossRef]
- Chen, Z.; Bai, Z.; Sinha, B. Ranked Set Sampling: Theory and Applications; Springer: New York, NY, USA, 2013. [Google Scholar]
- Tahmasebi, S.; Longobardi, M.; Kazemi, M.R.; Alizadeh, M. Cumulative Tsallis entropy for maximum ranked set sampling with unequal samples. Phys. A Stat. Mech. Appl. 2020, 556, 124763. [Google Scholar] [CrossRef]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. A First Course in Order Statistics; John Wiley & Sons: New York, NY, USA, 1992. [Google Scholar]
- Najma, S.; Alamgir, K.; Wali, K.; Habib, S.; Pijitra, J.; Thammarat, P. A Novel Generalized Family of Distributions for Engineering and Life Sciences Data Applications. Math. Probl. Eng. 2021, 2021, 9949999. [Google Scholar]
- Bowley, A.L. Elements of Statistics, 4th ed.; Charles Scribner’s Sons: New York, NY, USA, 1920. [Google Scholar]
- Moors, J.J.A. The meaning of kurtosis: Darlington re-examined. Am. Stat. 1986, 40, 283–284. [Google Scholar]
- Hong, H.G.; Li, Y. Estimation of time-varying reproduction numbers underlying epidemiological processes: A new statistical tool for the COVID-19 pandemic. PLoS ONE 2020, 15, e0236464. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).