
Third-Order Tensor Decorrelation Based on 3D FO-HKLT with Adaptive Directional Vectorization




Abstract
:
1. Introduction
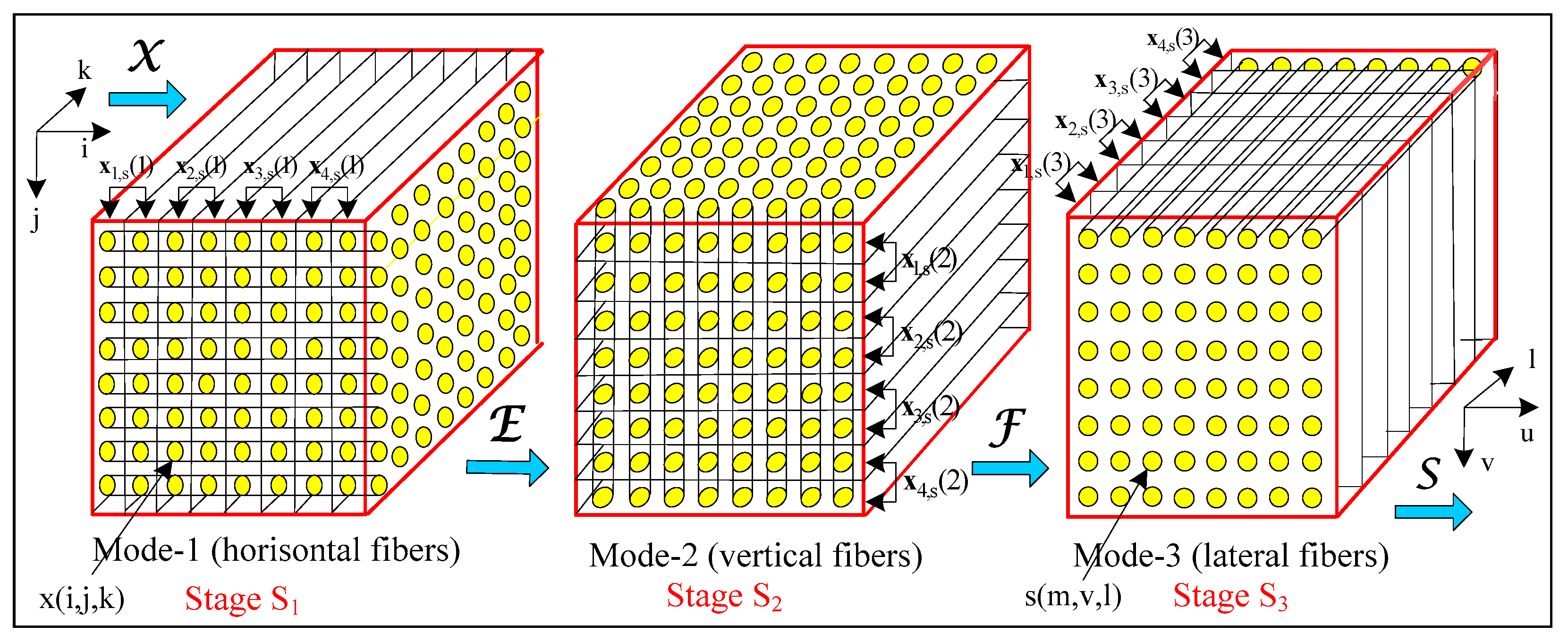
2. Method for 3D Adaptive Frequency-Ordered Hierarchical KLT of a Cubical Tensor
- The binary code of the sequential decimal number k = 0, 1, …, 2n−1 of the component Yn,k is arranged inversely (i.e., ), as for 0 ≤ i ≤ n − 1;
- The so-obtained code is transformed from Gray code into the binary code , in accordance with the operations for 0 ≤ i ≤ n − 2. Here, “⊕” denotes the operation “exclusive OR”.
3. Enhancement of the 3D FO-HKLT Efficiency, Based on Correlation Analysis
3.1. Analysis of the Covariance Matrices
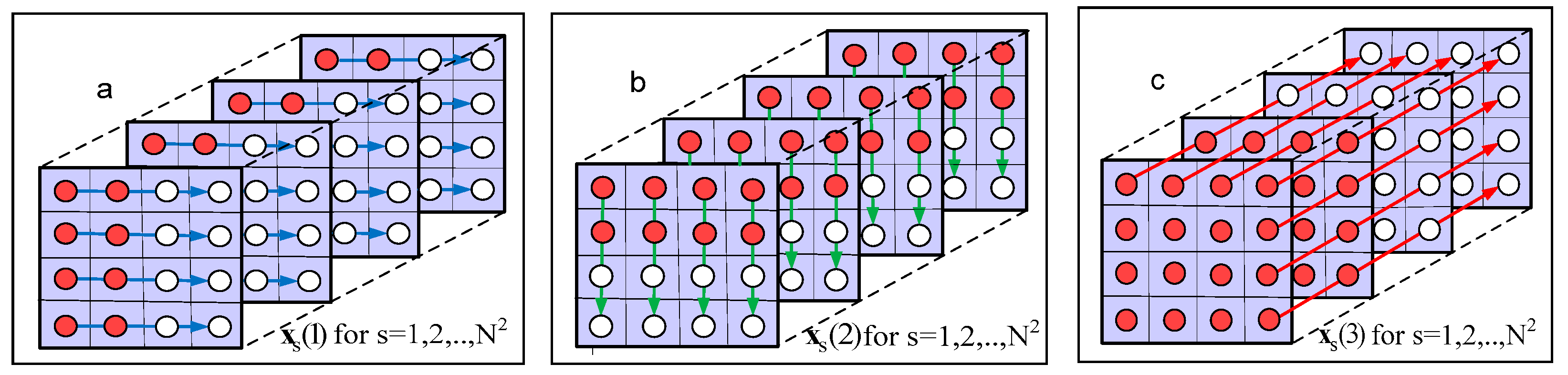
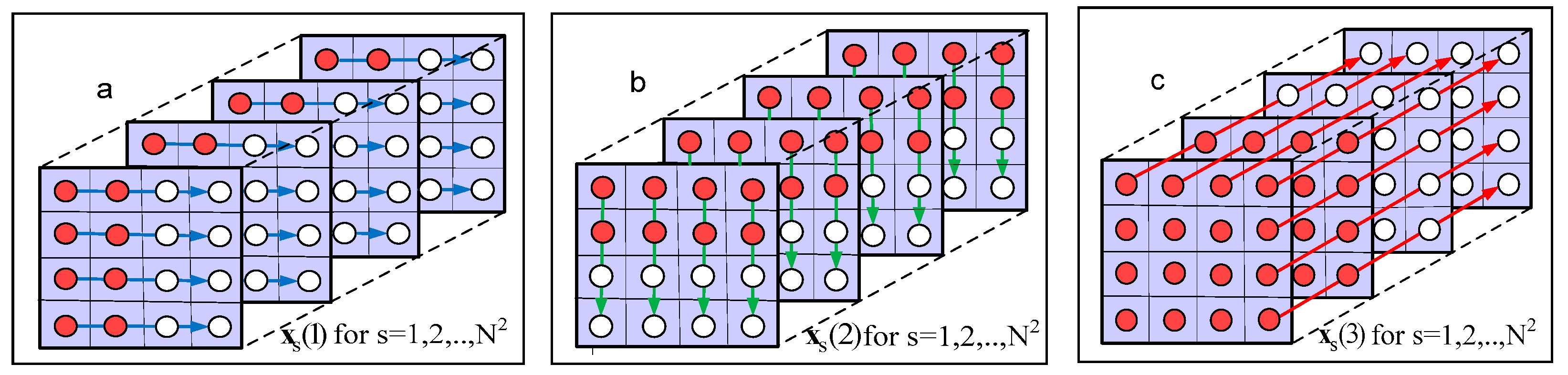
3.2. Choice of Vectors’ Orientation for Adaptive Directional Tensor Vectorization
3.3. Evaluation of the Decorrelation Properties of FO-AHKLT
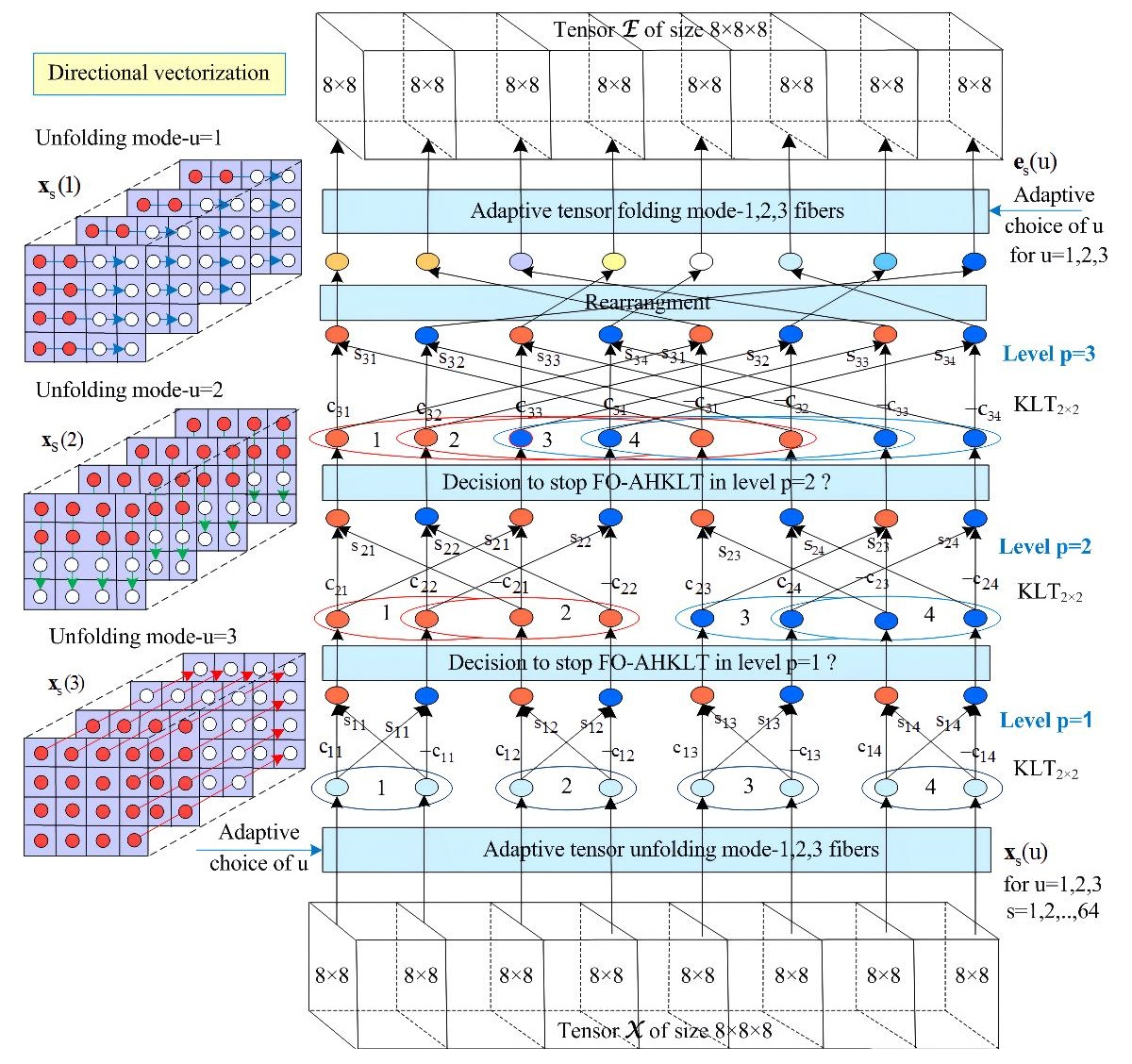
4. Adaptive Control for Each Level of FO-AHKLT
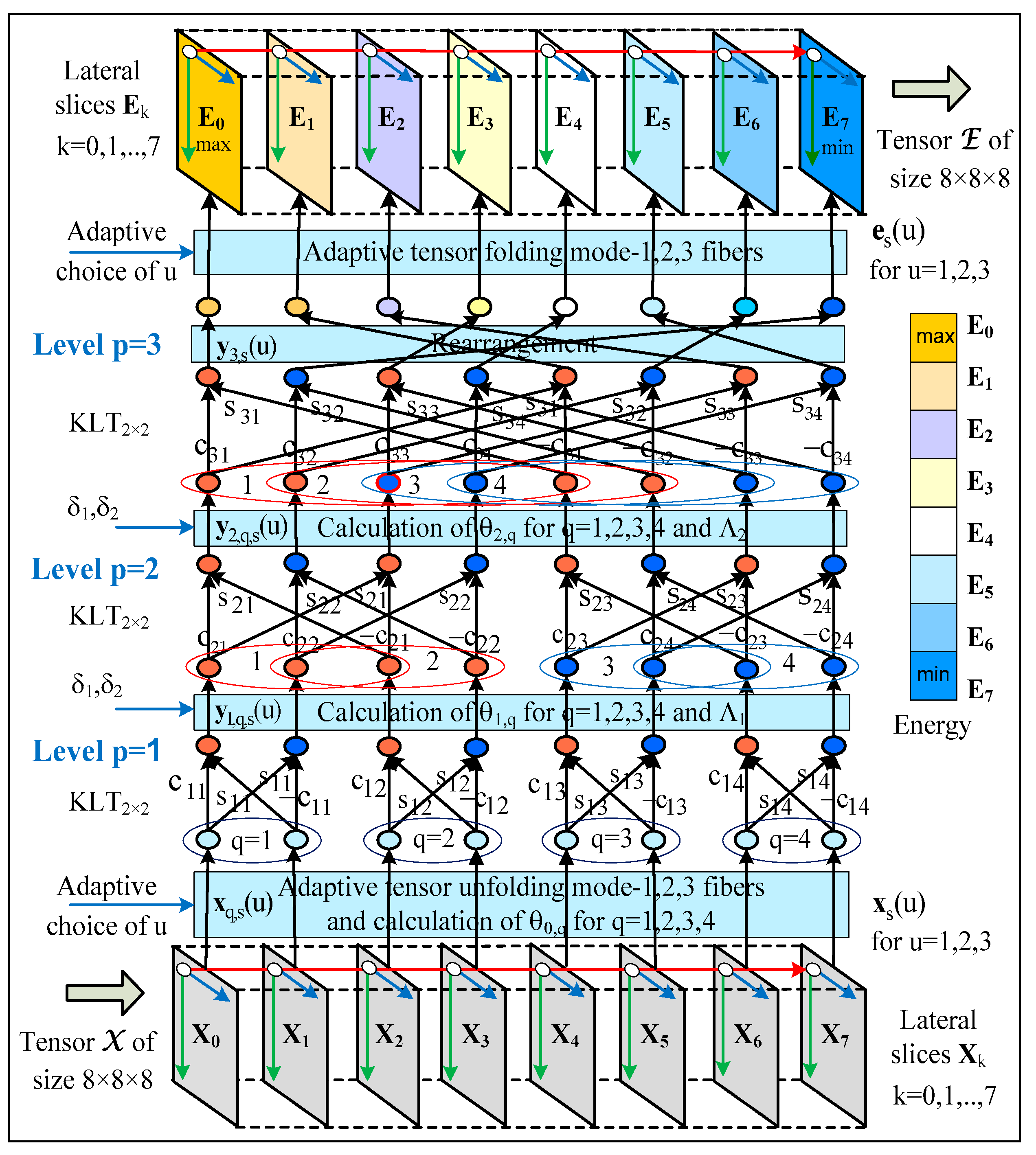
5. Algorithm 3D FO-AHKLT
| Algorithm1 |
| Input: Third-order tensor of size N × N × N (N = 2n) with elements x(i, j, k), and threshold values, δ1, δ2; |
| The steps of the algorithm are given below: |
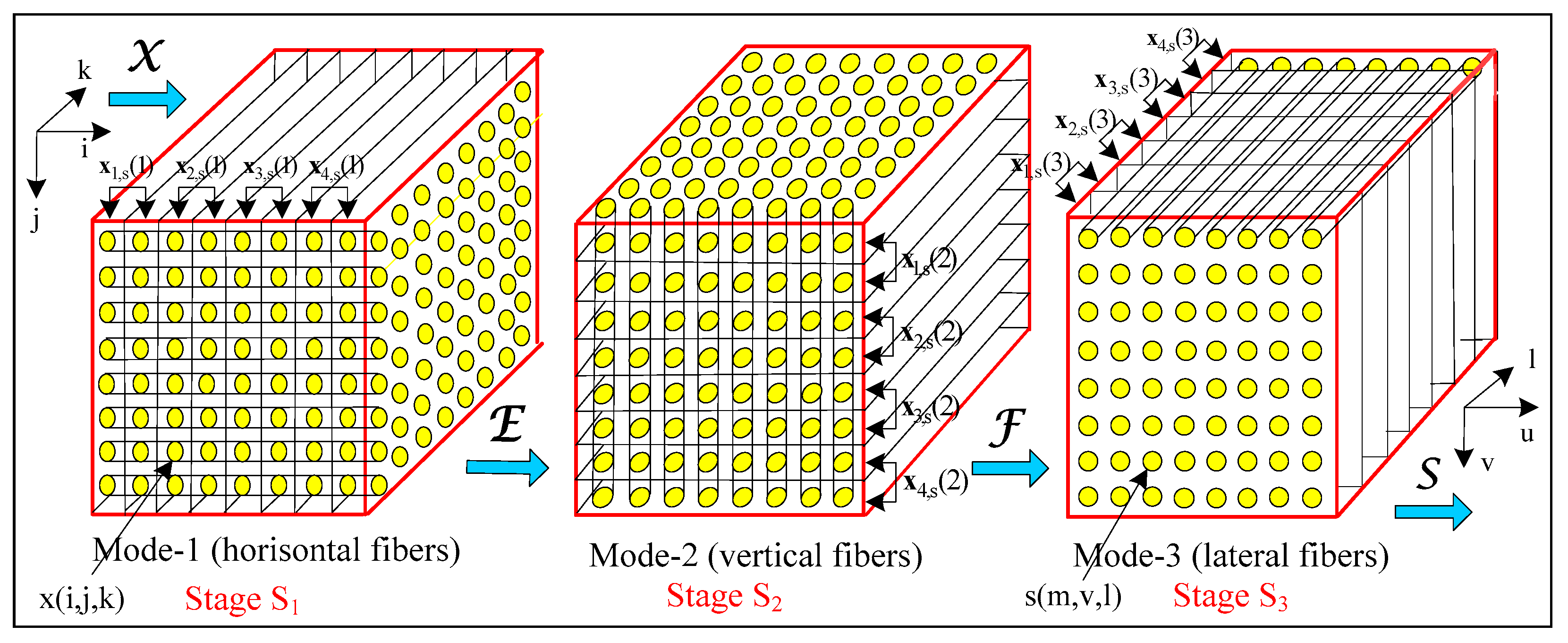
| 1. Unfolding of the tensor (mode u = 1, 2, 3), thereby obtaining the corresponding groups of vectors, . |
| 2. Calculation of the covariance matrices of the vectors , for u = 1, 2, 3. |
| 3. Calculation of the coefficients for u = 1, 2, 3, using the matrices . |
| 4. Setting the sequence of stages Su1, Su2, Su3 for the execution of 3D FO-AHKLT, chosen in accordance with the relations between coefficients . |
| 5. Start of stage Su1, which comprises: |
| 5.1. Execution of FO-AHKLT for the vectors with orientation u1 (for ), in correspondence with the calculation graph of n hierarchical levels and with a kernel—the adaptive KLT2×2, thereby obtaining the vectors . In each level p = 1, 2, …, n is checked if the condition to stop the FO-AHKLT calculations is satisfied; |
| 5.2. Folding of the tensor E of size N × N × N, by using the vectors ; |
| 5.3. Unfolding of the tensor E (mode u2), thereby obtaining the vectors with orientation u2, for . |
| 6. Start of stage Su2, which comprises: |
| 6.1. Execution of FO-AHKLT for the vectors in correspondence with the computational graph of n hierarchical levels and with a kernel—the adaptive KLT2 × 2, thereby obtaining the vectors . In each level p = 1, 2, …, n is checked if the condition to stop the FO-AHKLT calculations is satisfied; |
| 6.2. Folding the tensor F of size N × N × N, by using the vectors ; |
| 6.3. Unfolding the tensor F (mode u3), thereby obtaining the vectors , with orientation u3, for ; |
| 7. Start of stage Su3, which comprises: |
| 7.1. Execution of FO-AHKLT for the vectors in correspondence with the computational graph of n hierarchical levels and with a kernel—the adaptive KLT2 × 2, thereby obtaining the vectors . In each level p = 1, 2, …, n is checked if the condition to stop the FO-AHKLT calculations is satisfied; |
| 7.2. Folding of the tensor S of size N × N × N (N = 2n) by using the vectors . The elements of the tensor S are the spectrum coefficients s (m, v, l). |
| 8. Calculation of the transform matrices for each stage t = 1, 2, 3 of the 3D FO-AHKLT in accordance with the relations below:
|
| 9. Determination of the basic vectors for m, v, l = 0, 1, 2, …, N − 1, which are the rows of the matrices . With this, the decomposition of the tensor in correspondence with Equation (1), is finished. |
| Output: Spectral tensor S, whose elements s(m, v, l) are the coefficients of the 3D FO-AHKLT. |
- The main part of the tensor energy is concentrated into a small number of coefficients s(m, v, l) of the spectrum tensor S, for m, v, l = 0, 1, 2;
- The decomposition components of the tensor are uncorrelated.
6. Comparative Evaluation of the Computational Complexity
- The new hierarchical decomposition has low Complexity, which decreases together with the growth of n faster than those of the H-Tucker and TT decompositions;
- Significant reduction in the decomposition Complexity could be achieved through replacement of the kernel KLT2×2 by WHT2×2. In this particular case, the decrease in the decomposition Complexity results in a lower decorrelation degree;
- For the case n = 8, the Complexity of the algorithm 3D-AFWHT is approximately 6 times lower than that of the 3D FO-AHKLT;
- The Complexity of algorithms 3D FO-AHKLT and 3D-AFWHT was evaluated without taking into consideration the use of the adaptive KLT2×2 and the possibility to stop the execution prior to the maximum level n. Equations (35) and (40) give the maximum values of Complexity used for the evaluation of the compared algorithms.
7. Conclusions
- Efficient decorrelation of the calculated components;
- Concentration of the tensor energy into a small number of decomposition components;
- Lack of iterations;
- Low Complexity;
- The capacity for parallel recursive implementation, which reduces the needed memory volume;
- The capacity for additional significant Complexity reduction through the use of the algorithm 3D-AFWHT, depending on the needs of the implemented application.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Liu, J.; Long, Z.; Zhu, C. Tensor Decomposition. In Tensor Computation for Data Analysis; Springer: Cham, Switzerland, 2021; pp. 19–57. [Google Scholar]
- Ji, Y.; Wang, Q.; Li, X.; Liu, J. A Survey on Tensor Techniques and Applications in Machine Learning. IEEE Access 2019, 7, 162950–162990. [Google Scholar] [CrossRef]
- Cichocki, A.; Mandic, D.; Phan, A.; Caiafa, C.; Zhou, G.; Zhao, Q.; De Lathauwer, L. Tensor Decompositions for Signal Processing Applications: From Two-Way to Multiway Component Analysis. IEEE Signal Process. Mag. 2015, 32, 145–163. [Google Scholar] [CrossRef] [Green Version]
- Sidiropoulos, N.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.; Faloutsos, C. Tensor Decomposition for Signal Processing and Machine Learning. IEEE Trans. Signal Proc. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Oseledets, I. Tensor-train decomposition. Siam J. Sci. Comput. 2011, 33, 2295–2317. [Google Scholar] [CrossRef]
- Grasedyck, L. Hierarchical Singular Value Decomposition of Tensors. Siam J. Matrix Anal. Appl. 2010, 31, 2029–2054. [Google Scholar] [CrossRef] [Green Version]
- Ozdemir, A.; Zare, A.; Iwen, M.; Aviyente, S. Extension of PCA to Higher Order Data Structures: An Introduction to Tensors, Tensor Decompositions, and Tensor PCA. Proc. IEEE 2018, 106, 1341–1358. [Google Scholar]
- Vasilescu, M.; Kim, E. Compositional Hierarchical Tensor Factorization: Representing Hierarchical Intrinsic and Extrinsic Causal Factors. In Proceedings of the 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD): Tensor Methods for Emerging Data Science Challenges, Anchorage, NY, USA, 2–4 August 2019; p. 9. [Google Scholar]
- Wang, P.; Lu, C. Tensor Decomposition via Simultaneous Power Iteration. In Proceedings of the 34th International Conference on Machine Learning (PMLR), Sydney, Australia, 6–9 August 2017; Volume 70, pp. 3665–3673. [Google Scholar]
- Ishteva, M.; Absil, P.; Van Dooken, P. Jacoby Algorithm for the Best Low Multi-linear Rank Approximation of Symmetric Tensors. SIAM J. Matrix Anal. Appl. 2013, 34, 651–672. [Google Scholar] [CrossRef]
- Zniyed, Y.; Boyer, R.; Almeida, A.; Favier, G. A TT-based Hierarchical Framework for Decomposing High-Order Tensors. SIAM J. Sci. Comput. 2020, 42, A822–A848. [Google Scholar] [CrossRef] [Green Version]
- Kernfeld, E.; Kilmer, M.; Aeron, S. Tensor–tensor products with invertible linear transforms. Linear Algebra Appl. 2015, 485, 545–570. [Google Scholar]
- Keegany, K.; Vishwanathz, T.; Xu, Y. A Tensor SVD-based Classification Algorithm Applied to fMRI Data. arXiv 2021, arXiv:2111.00587v1. [Google Scholar]
- Rao, K.; Kim, D.; Hwang, J. Fast Fourier Transform: Algorithms and Applications; Springer: Dordrecht, The Netherlands, 2010; pp. 166–170. [Google Scholar]
- Ahmed, N.; Rao, K. Orthogonal Transforms for Digital Signal Processing; Springer: Berlin/Heidelberg, Germany, 1975; pp. 86–91. [Google Scholar]
- Kountchev, R.; Kountcheva, R. Adaptive Hierarchical KL-based Transform: Algorithms and Applications. In Computer Vision in Advanced Control Systems: Mathematical Theory; Favorskaya, M., Jain, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 1, pp. 91–136. [Google Scholar]
- Kountchev, R.; Mironov, R.; Kountcheva, R. Complexity Estimation of Cubical Tensor Represented through 3D Frequency-Ordered Hierarchical KLT. Symmetry 2020, 12, 1605. [Google Scholar] [CrossRef]
- Lu, H.; Kpalma, K.; Ronsin, J. Motion descriptors for micro-expression recognition. In Signal Processing: Image Communication; Elsevier: Amsterdam, The Netherlands, 2018; Volume 67, pp. 108–117. [Google Scholar]
- Kountchev, R.; Mironov, R.; Kountcheva, R. Hierarchical Cubical Tensor Decomposition through Low Complexity Orthogonal Transforms. Symmetry 2020, 12, 864. [Google Scholar] [CrossRef]
- Cichocki, A.; Phan, H.; Zhao, Q.; Lee, N.; Oseledets, I.; Sugiyama, M.; Mandic, D. Tensor networks for dimensionality reduction and large-scale optimizations: Part 2 Applications and future perspectives. Found. Trends Mach. Learn. 2017, 9, 431–673. [Google Scholar] [CrossRef]
- Abhyankar, S.S.; Christensen, C.; Sundaram, G.; Sathaye, A.M. Algebra, Arithmetic and Geometry with Applications: Papers from Shreeram S. Abhyankar's 70th Birthday Conference; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2004; pp. 457–472. [Google Scholar]
- Peters, J. Computational Geometry, Topology and Physics of Digital Images with Applications: Shape Complexes, Optical Vortex Nerves and Proximities; Springer Nature: Cham, Switzerland, 2019; pp. 1–115. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Relations for Δ(1), Δ(2), Δ(3) | Sequence of Stages Su in the 3D FO-AHKLT Execution (for u = 1, 2, 3) |
|---|---|---|
| 1 | Δ(1) > Δ(2) > Δ(3) Δ(1) = Δ(2) = Δ(3) Δ(1) > Δ(2) = Δ(3) Δ(1) = Δ(2) > Δ(3) | S1 → S2 → S3 |
| 2 | Δ(1) > Δ(3) > Δ(2) Δ(1) > Δ(3) = Δ(2) Δ(1) = Δ(3) > Δ(2) | S1 → S3 → S2 |
| 3 | Δ(2) > Δ(1) > Δ(3) Δ(2) > Δ(1) = Δ(3) Δ(2) = Δ(1) > Δ(3) | S2 → S1 → S3 |
| 4 | Δ(2) > Δ(3) > Δ(1) Δ(2) > Δ(3) = Δ(1) Δ(2) = Δ(3) > Δ(1) | S2 → S3 → S1 |
| 5 | Δ(3) > Δ(2) > Δ(1) Δ(3) > Δ(2) = Δ(1) Δ(3) = Δ(2) > Δ(1) | S3 → S2 → S1 |
| 6 | Δ(3) > Δ(1) > Δ(2) Δ(3) > Δ(1) = Δ(2) Δ(3) = Δ(1) > Δ(2) | S3 → S1 → S2 |
| n | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| 0.28 | 0.34 | 0.48 | 0.74 | 1.21 | 2.05 | 3.57 | 6.34 | 11.39 | |
| 0.30 | 0.42 | 0.66 | 1.06 | 1.77 | 3.04 | 5.33 | 9.47 | 17.06 | |
| 4.16 | 5.00 | 5.46 | 5.74 | 5.87 | 5.94 | 5.97 | 5.98 | 5.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kountchev, R.K.; Mironov, R.P.; Kountcheva, R.A. Third-Order Tensor Decorrelation Based on 3D FO-HKLT with Adaptive Directional Vectorization. Symmetry 2022, 14, 854. https://doi.org/10.3390/sym14050854
Kountchev RK, Mironov RP, Kountcheva RA. Third-Order Tensor Decorrelation Based on 3D FO-HKLT with Adaptive Directional Vectorization. Symmetry. 2022; 14(5):854. https://doi.org/10.3390/sym14050854
Chicago/Turabian StyleKountchev, Roumen K., Rumen P. Mironov, and Roumiana A. Kountcheva. 2022. "Third-Order Tensor Decorrelation Based on 3D FO-HKLT with Adaptive Directional Vectorization" Symmetry 14, no. 5: 854. https://doi.org/10.3390/sym14050854
APA StyleKountchev, R. K., Mironov, R. P., & Kountcheva, R. A. (2022). Third-Order Tensor Decorrelation Based on 3D FO-HKLT with Adaptive Directional Vectorization. Symmetry, 14(5), 854. https://doi.org/10.3390/sym14050854