1. Introduction
With the rapid expansion of information on the Web, locating relevant information has become a prominent issue. E-commerce has grown significantly in the Internet era, enabling the selling of various products. E-commerce users face difficulties when it comes to selecting a product among millions of options. The recommendation system assists the e-commerce user in making selections among millions of products [
1]. A recommender system (RS) gathers information about the goods a consumer is interested in and makes recommendations about those items or products [
2]. Nowadays, practically every e-commerce website makes use of RS, supporting millions of users. E-commerce sites such as Netflix and MovieLens [
3] for movies, Amazon [
4] for books, CDs, and a variety of other things, Entree for restaurants, and Jester [
5] for jokes all make use of a recommender system to aid their customers. The recommender system’s output is used by both e-commerce organizations and users [
6]. That is, RS not only assists the consumer in obtaining the desired item, but also increases the organization’s revenue by selling more products.
A recommender system’s objective is to give relevant product recommendations to the customer. Algorithms for recommendation systems fall into three broad categories: collaborative, content-based, and hybrid [
2]. Collaborative filtering (CF) is the simplest and most efficient of the three algorithms, having been implemented in a variety of real-world applications, including Netflix and Amazon. According to the prediction approach utilized, CFs can be classified as item-based or user-based. Collaborative filtering identifies individuals who share common interests and generates predictions about them. On the other hand, the item-based approach proposes the most related things to the user. The symmetric relationship of collaborative filtering have been exploited in SRMC [
7] and PCA-SVD transformed K-means++ [
8] approach. Content-based filtering (CBF) [
9,
10] makes a suggestion based on what the same person did before. The CBF is based on the item’s description and the user’s background [
11,
12]. For example, when you use the demographic filtering technique [
13], you look for people who have the same nationality, age, gender, and more. In [
14] hybrid filtering is discussed, which combines both the filtering techniques [
15,
16]. In order to improve the performance of CF, different clustering techniques are used to make better recommendations based on what users like [
17,
18]. Clustering is a way to group people together based on how well they rate the same things. A cluster of users is sent to an active user who likes the same things as the people in that cluster. Clustering methods like k-means and fuzzy c-means are available in user-based CF. The quality of the recommendation system is still an open question.
Several techniques have been devised for the development of recommender systems, including swarm-based algorithms [
19]. These algorithms are nature-inspired and based on the decision-making capabilities of decentralized and self-organized clans of organisms in a community. These organisms obtain local information from the environment as well as other agents. These organisms’ co-evolutionary behavior resembles the iterative nature of swarm algorithms, such as the firefly algorithm (FA), cuckoo search algorithm (CSA), grasshopper algorithm (GA), whale algorithm (WSA), sparrow search algorithm (SSA), etc. [
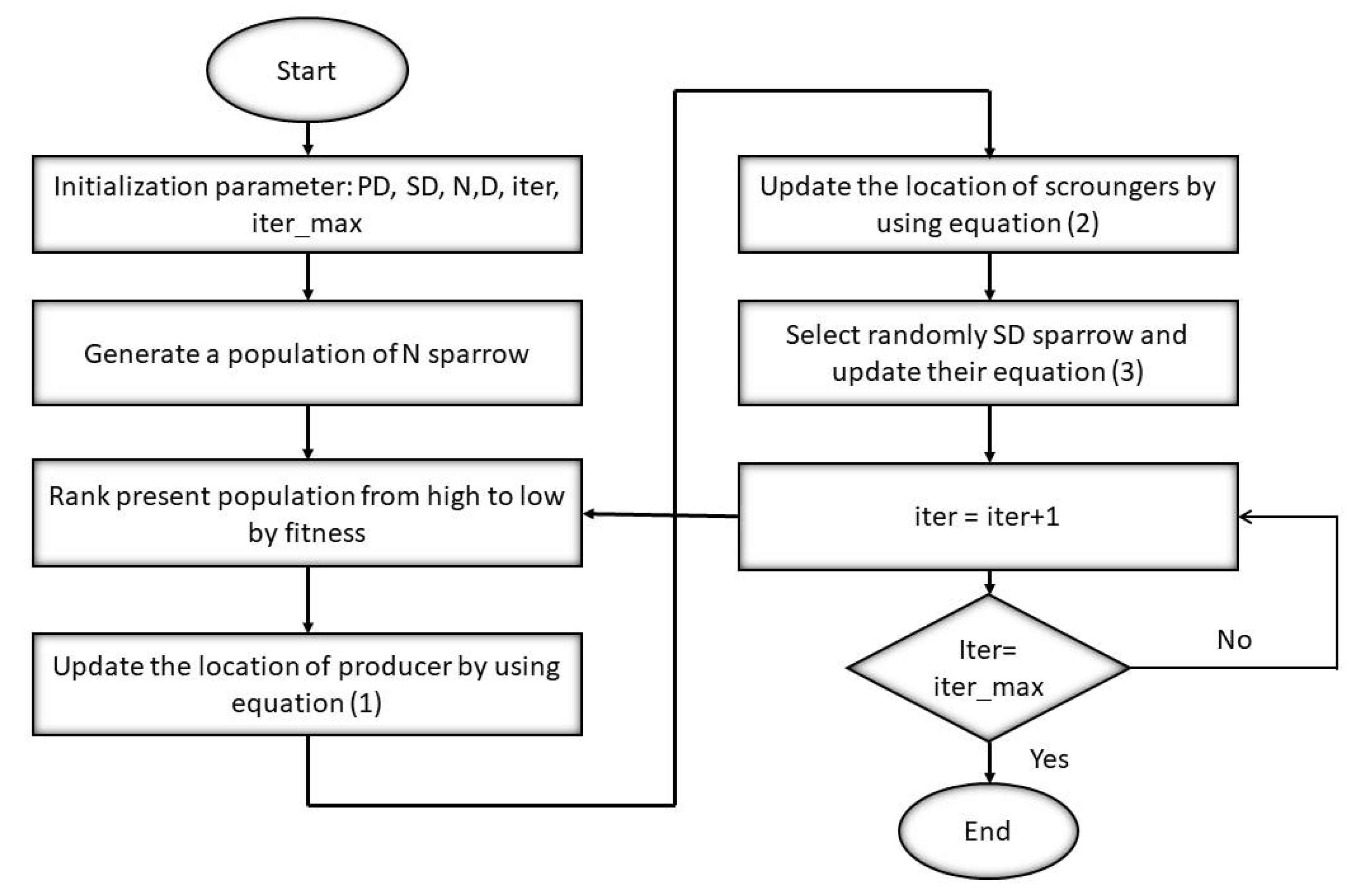
20]. SSA is based on the group wisdom, foraging, and anti-predator behavior of sparrows [
21]. This is why it is used in research to find the best way to improve [
22,
23,
24,
25,
26,
27,
28,
29,
30].
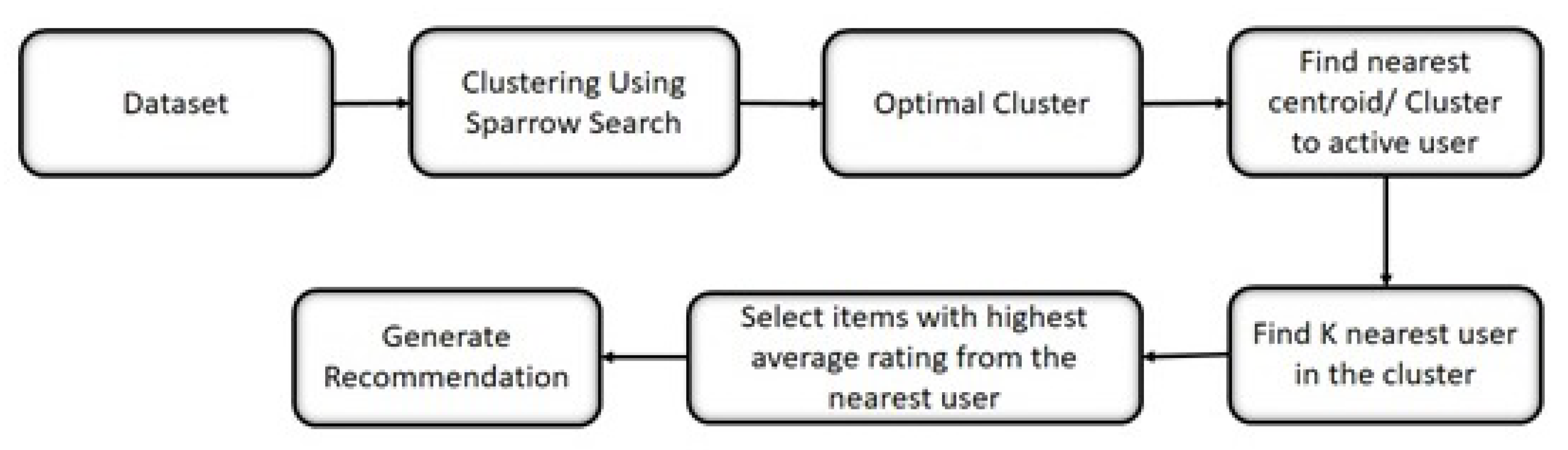
In this paper, we incorporate swarm intelligence-based optimization to generate optimal cluster(s) for a recommendation system by using a sparrow search algorithm. The proposed algorithm exploits the symmetric relationships between the users to generate better recommendations. Swarm-based recommendation systems work in two phases, which include the training phase and recommendation phase. Phase I is an offline process in which a rating matrix is produced from the collected data and clusters are obtained by using a swarm clustering algorithm. Phase II is an online process in which the recommendation for an active user is performed.
The rest of the paper is organized as follows:
Section 2 provides the literature survey related to swarm intelligence and recommender systems,
Section 3 presents the methodology used for generating recommendations,
Section 4 deals with experiments and results, and
Section 5 gives the conclusion and future scope.
2. Related Work
Some important things to ponder when evaluating the CF recommender systems are covered in [
31]. These include the user’s task, the dataset used, and how to judge a recommender system’s accuracy. One way to make a recommendation is to use clustering. The cluster that is formed must have a minimum number of inter- and the maximum number of intra- similarities [
14]. Clustering techniques are used a lot in CF-based recommender systems to make them work better.
According to Feng et al. [
32], co-clustering can increase the performance of top N suggestions. They demonstrate a recommendation system called user–item community detection-based recommendation (UICDR). The primary idea is to create a bipartite network of data about how people and objects interact. Individuals and objects are classified into several categories. When we have clusters of people and things, we may apply its same collaborative filtering algorithms to each cluster. The results demonstrate that the suggested method can greatly improve the performance of the top N suggestions for a variety of well-known collaborative filtering techniques.
In [
33], the clustering method is used to make traditional recommender systems work better with multi-criteria ratings. It used Mahalanobis distance to figure out how similar people in the same cluster are, which made recommendations more accurate. The authors of [
34] came up with a way to improve the quality of recommendations by using a weighted clustering method viz. spherical k-means. If there are a lot of users and a lot of items, this method doesn’t get more complicated (in contrast to existing incremental methods). Therefore, the proposed collaborative filtering system is better for dynamic settings, wherein there are a lot of databases and information changes quickly. In the experiments, real-world datasets were used to see how well and how quickly the method works in terms of scalability and how well it makes recommendations.
Numerous research publications have demonstrated that traditional clustering approaches (such as k-means clustering) can provide local bests. Thus, clustering and algorithms inspired by nature-inspired global optimization can be employed to enhance the performance of recommendations. Reference [
35] developed a hybrid movie recommendation system that incorporated both genetic algorithms (GAs) and k-means clustering. It employs principle component analysis (PCA) to reduce the size of the movie population space, hence speeding up the calculations. The studies (conducted on the MovieLens dataset) demonstrate that the suggested method is capable of being extremely accurate and providing more dependable and tailored movie recommendations than existing methods. The authors of [
36] used the PSO to enhance the performance of a recommender system. They employed a k-means approach to obtain the initial parameters for particle swarm optimization in the suggested method (PSO). PSO begins with a seed and enhances fuzzy c-means (FCM) to do soft grouping of data (users) rather than hard clustering as in k-means.
The author of [
37] devised a method for making a top-N recommendation based on ant behavior. This approach is divided into two sections. Users’ opinions are clustered into categories with a preset number of clusters by using an ant-based clustering technique. The results are then kept in a database for future recommendations and can be used to assist individuals in locating what they’re looking for. The second phase involves making a recommendation to the user who is currently using the app. The new method’s efficiency was evaluated by using the Jester dataset and was compared to a conventional collaborative filtering-based approach. The proposed solution outperforms the usual recommender system, as demonstrated by the findings.
The authors of [
38] create a collaborative recommender system for movies by using a gray wolf optimization algorithm and fuzzy c-means (FCM) clustering. To obtain the initial clusters from the MovieLens dataset, the gray wolf optimizer technique is employed. FCM is used to categorize users in a dataset according to how similar their ratings are. The authors of [
39] made recommendations by using the collaborative filtering technique, k-means clustering, and cuttlefish optimization. The proposed solution begins with the k-means algorithm, which groups people with similar tastes together, and then uses the cuttlefish algorithm to generate the best recommendations based on the k-means algorithm’s results.
In [
40], the authors combine the k-means and cuckoo search algorithms to create recommender systems, whereas in [
41], the k-means clustering technique is combined with an algorithm for optimizing artificial bee colonies. In the first phase of the proposed strategy, k-means is employed to classify people into distinct clusters. The second phase employs the artificial bee colony optimization technique to enhance the k-means procedure’s outcomes [
42]. The proposed method’s results demonstrate significant progress in terms of scalability and performance. Additionally, they provide more accurate personalized movie recommendations by avoiding the cold start issue. In [
43], an urban travel recommendation is made by using a hybrid quantum-induced swarm intelligence clustering. The authors demonstrate a novel method for grouping users in order to create a collaborative filtering-based recommender system that takes advantage of quantum-behaved particle swarm optimization. Because clustering algorithms were combined with collaborative filtering to put individuals with shared characteristics into clusters, the recommendation’s efficiency was boosted.
For dynamic recommendation systems, [
44] discusses an evolutionary clustering method that groups objects based on their time characteristics. The clustering algorithm creates comparable user groups and increases them over time. This graph illustrates how user performance evolves over time in terms of accuracy and relevance. The authors of [
45] demonstrate how to use evolutionary clustering to forecast ratings based on user collaborative filtering. The primary objective of the strategy demonstrated is to put people with similar interests together and to assist them in finding things that best suit their inclinations. Collaborative filtering is used in each cluster following the clustering procedure. The target rating is determined collaboratively by the users in the cluster. The authors of [
46] use hierarchical particle swarm optimization to do clustering (HPSO-clustering). It is based on the PSO method and offers both hierarchical and partitional clustering advantages. The authors of [
47] employ three techniques: visual clustering recommendation, a blend of visual clustering, and user-based methods, and a hybrid of visual clustering and item-based methods. To aggregate user stuff together, a genetic algorithm is applied.
5. Conclusions and Future Scope
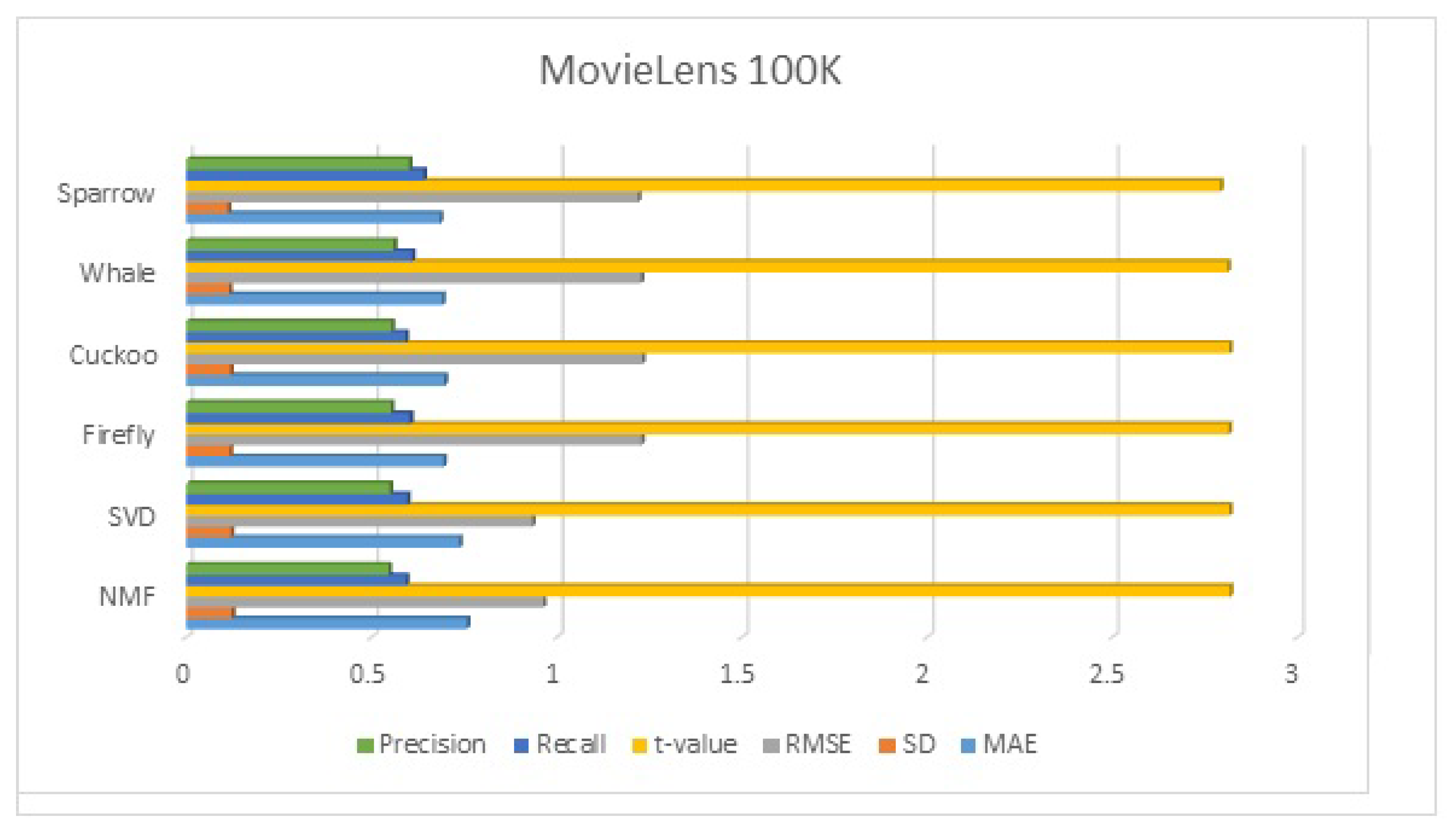
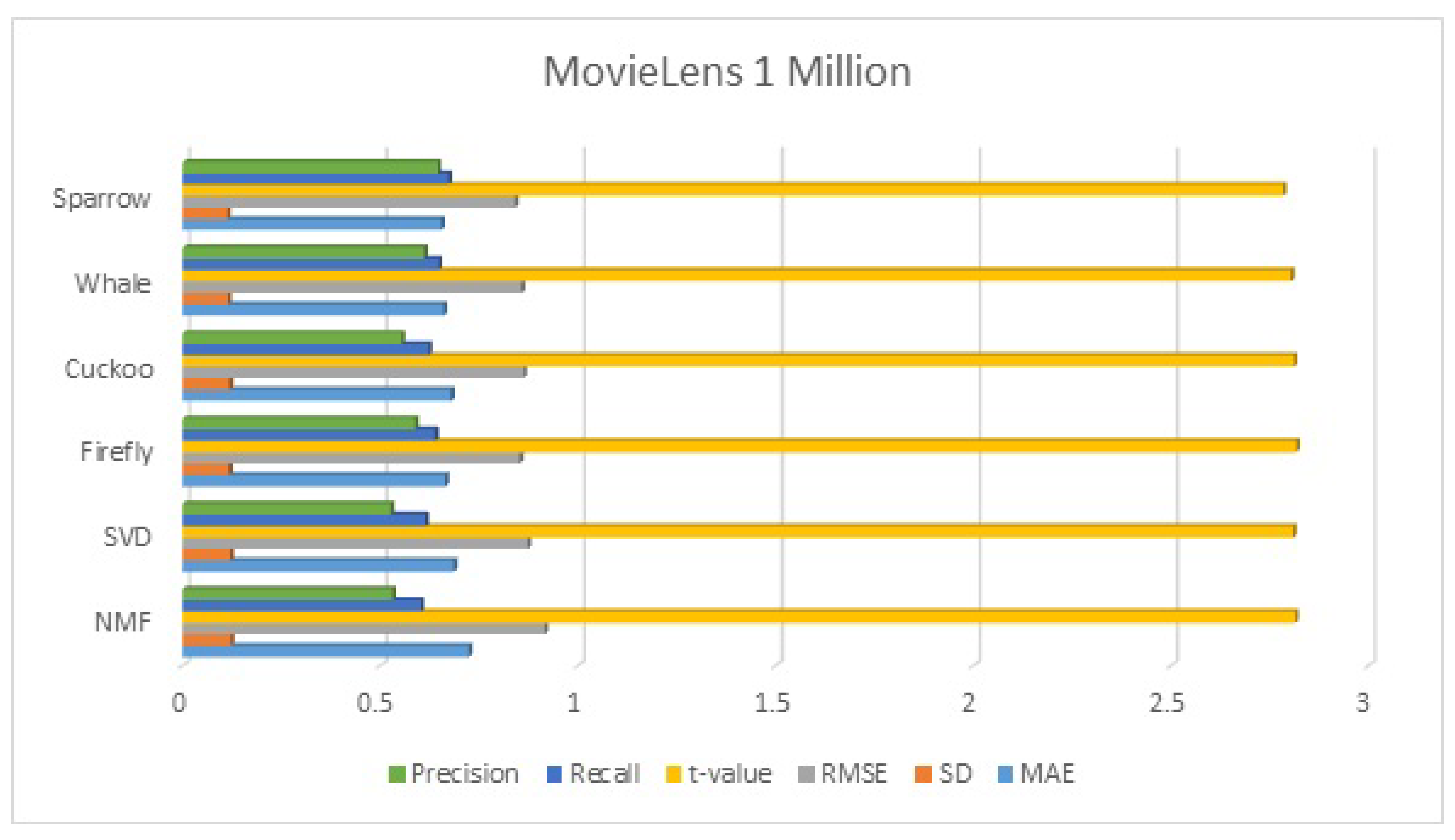
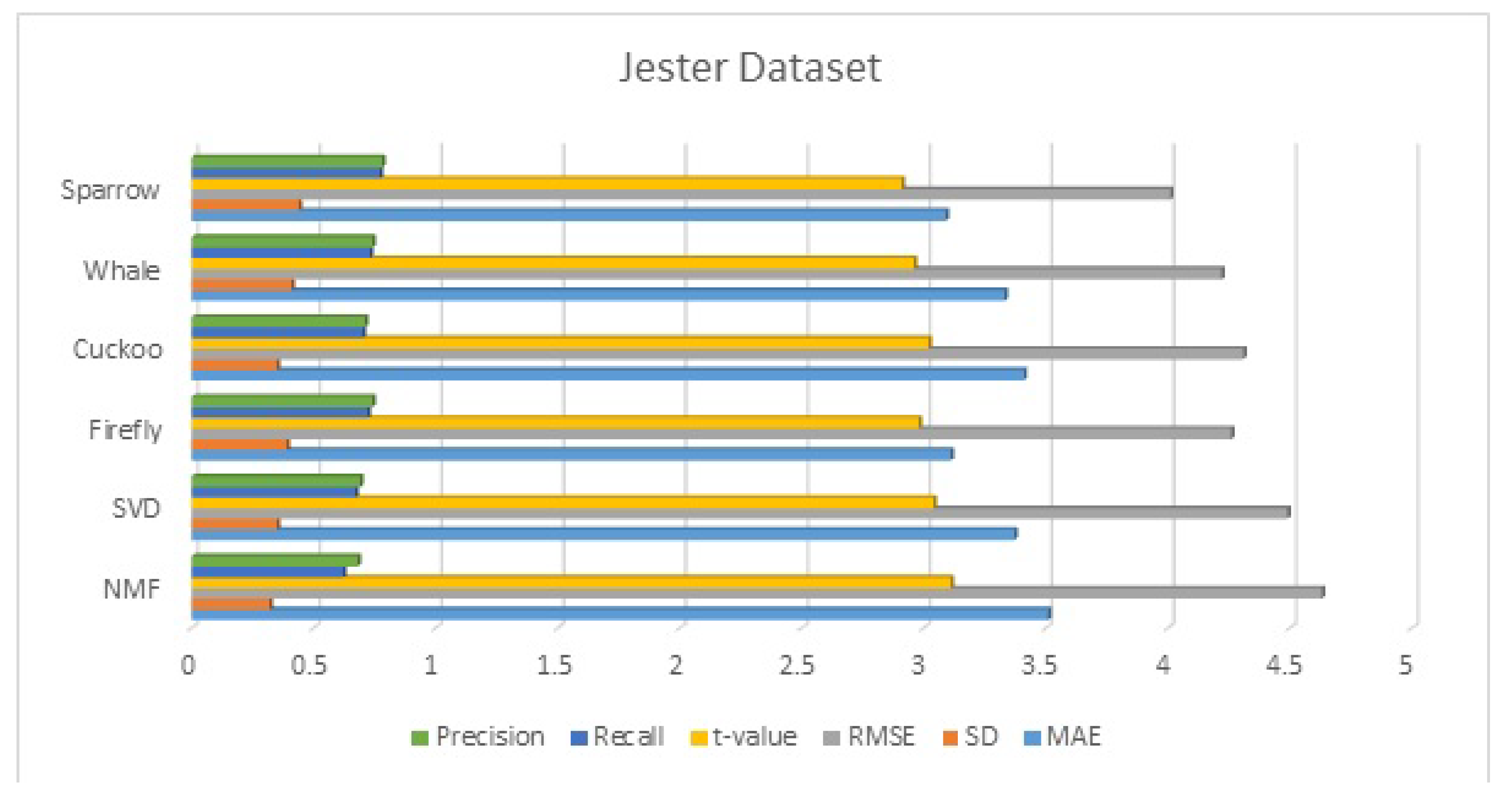
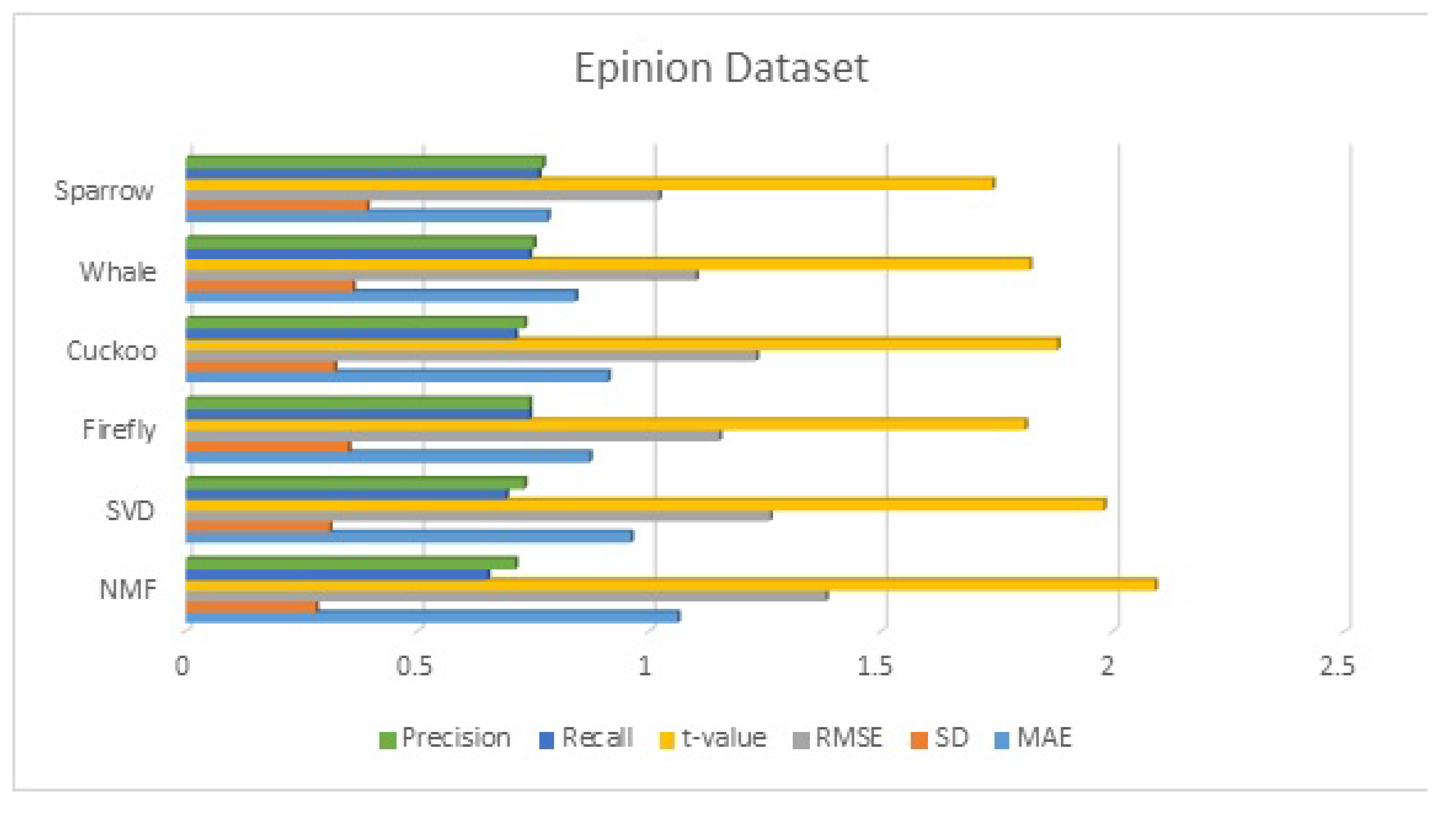
The use of standard clustering algorithms in recommender systems leads to slow results especially when a dataset is large. To speed up the clustering process, swarm intelligence-based clustering is a better option. In this proposed system, we presented a recommender system with four metaheuristic clustered algorithms, namely the firefly clustered algorithm, the cuckoo clustered algorithm, the whale clustered algorithm, and the sparrow clustered algorithm. In the proposed system, the symmetric nature of collaborative filtering is utilized. As far as clustering-based recommendation systems are concerned, getting optimal clusters is imperative in giving good recommendations. To obtain the optimal cluster, we need to minimize the within-cluster sum of squared (WCSS) distance. All algorithms are optimization algorithms and are used for reducing WCSS, which becomes the fitness function to be optimized.
The best clusters are then used to provide relevant and timely recommendations depending on the preferences of other cluster members. After obtaining the optimal cluster, recommendations can be generated by first selecting the right cluster(s) and then selecting the suitable items from the clusters. A straightforward approach is to select the cluster whose cluster head is closest to the active user, average the ratings for each item in the cluster, and then recommend the item with the highest cluster average rating. We evaluated our approach’s performance by using standard statistical measures such as mean absolute error, standard deviation, root mean squared error, and t-value. The results demonstrate that our approach generates highly relevant recommendations. In future work, alternative nature-inspired algorithms, such as multi-objective metaheuristic algorithms, can be utilized in place of the single-objective algorithm.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}