
Vehicle Distance Estimation from a Monocular Camera for Advanced Driver Assistance Systems


Abstract
1. Introduction
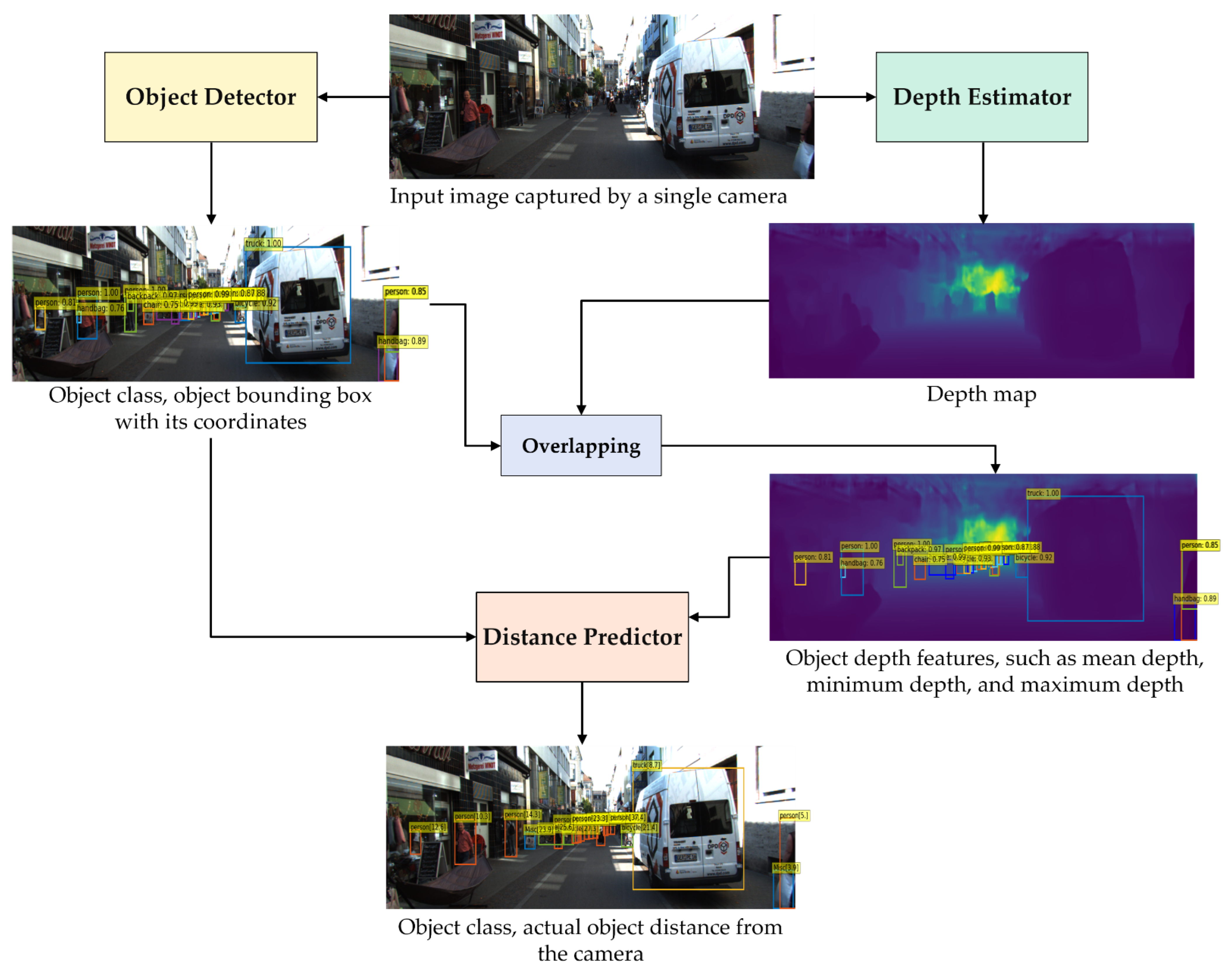
2. Materials and Methods
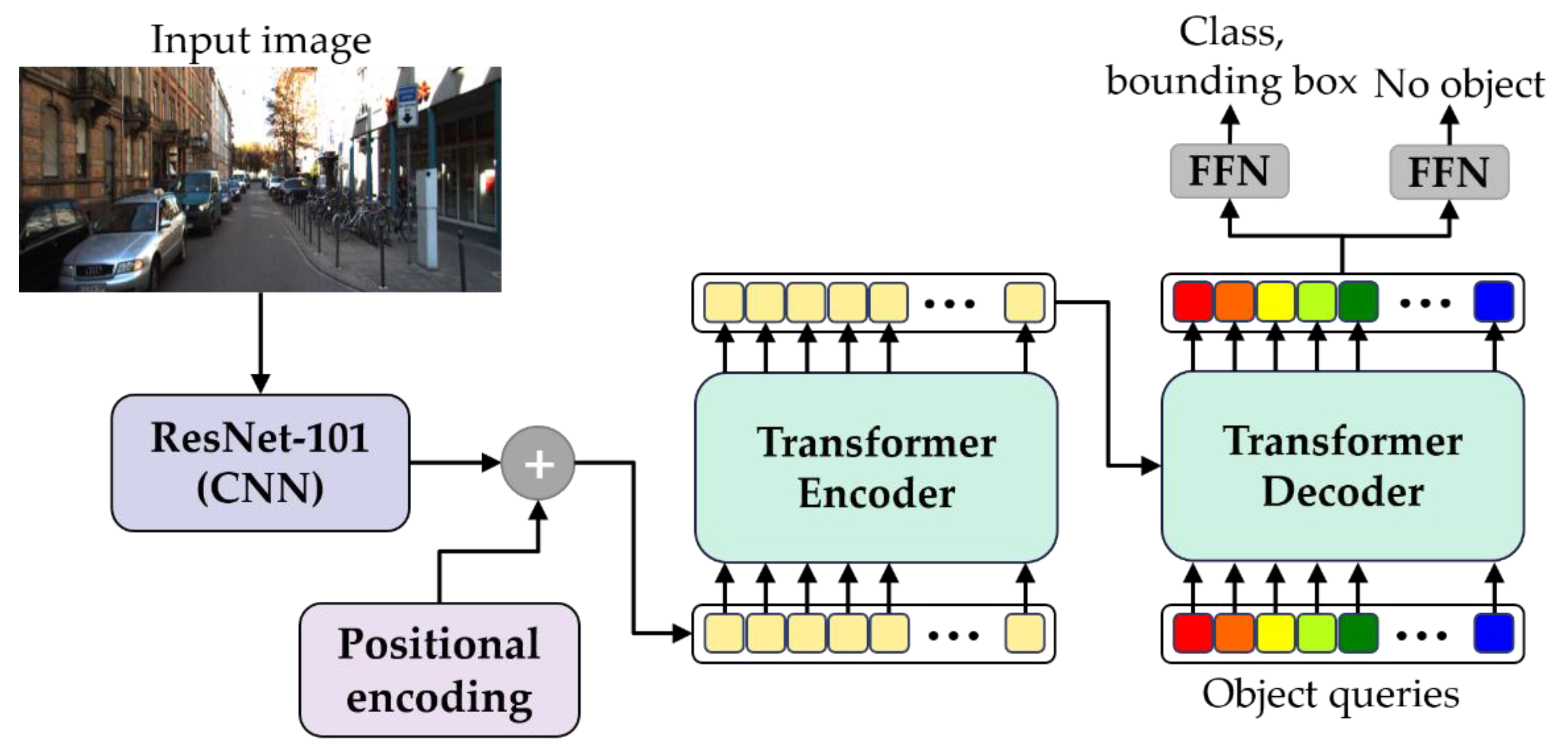
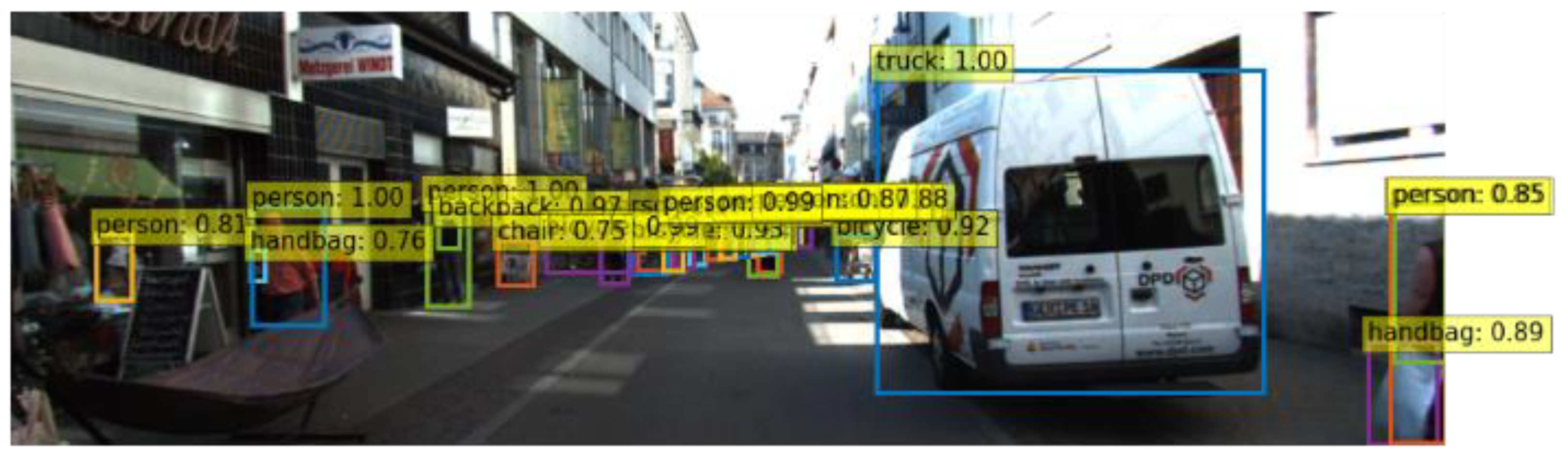
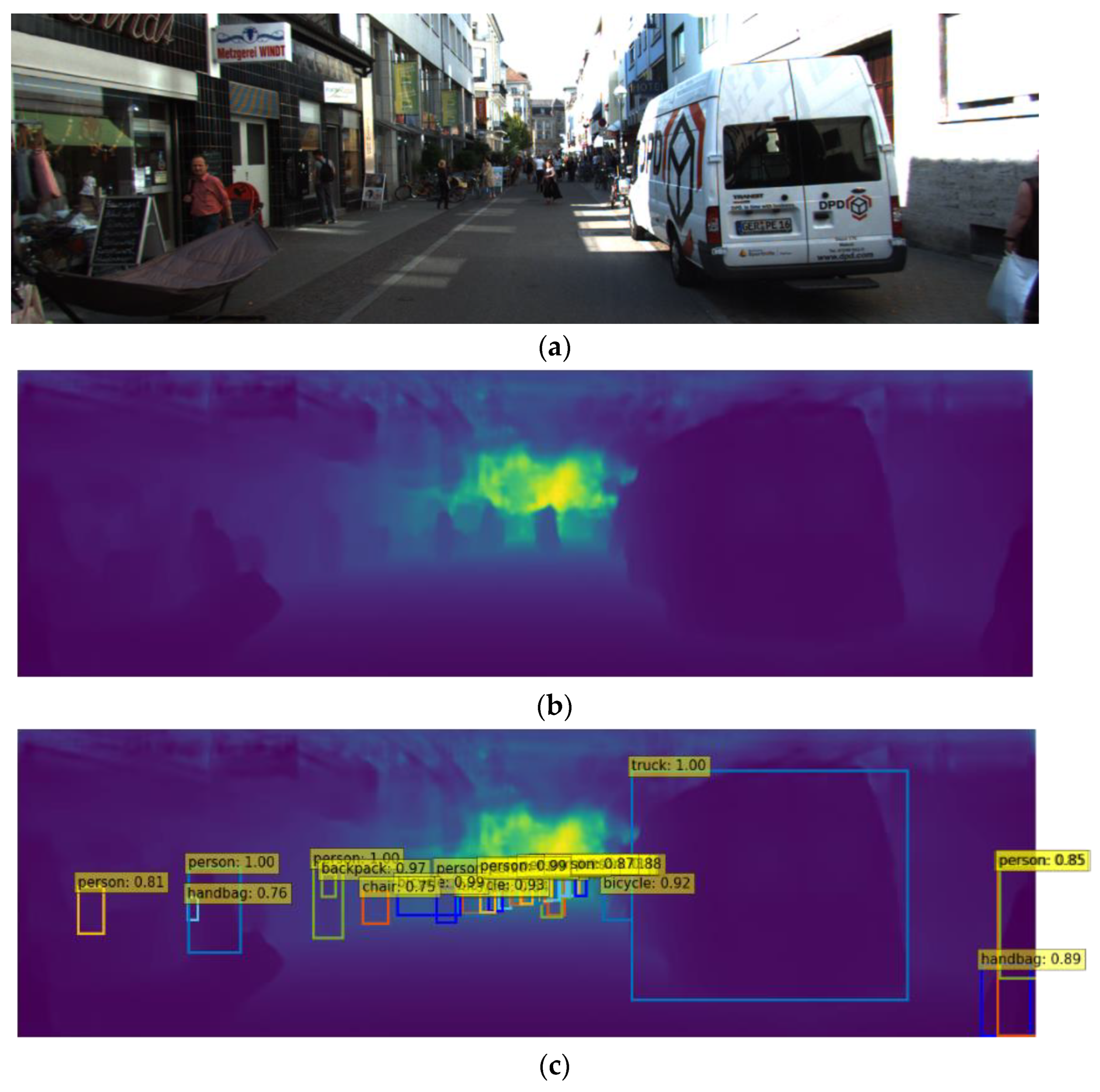
2.1. Object Detector
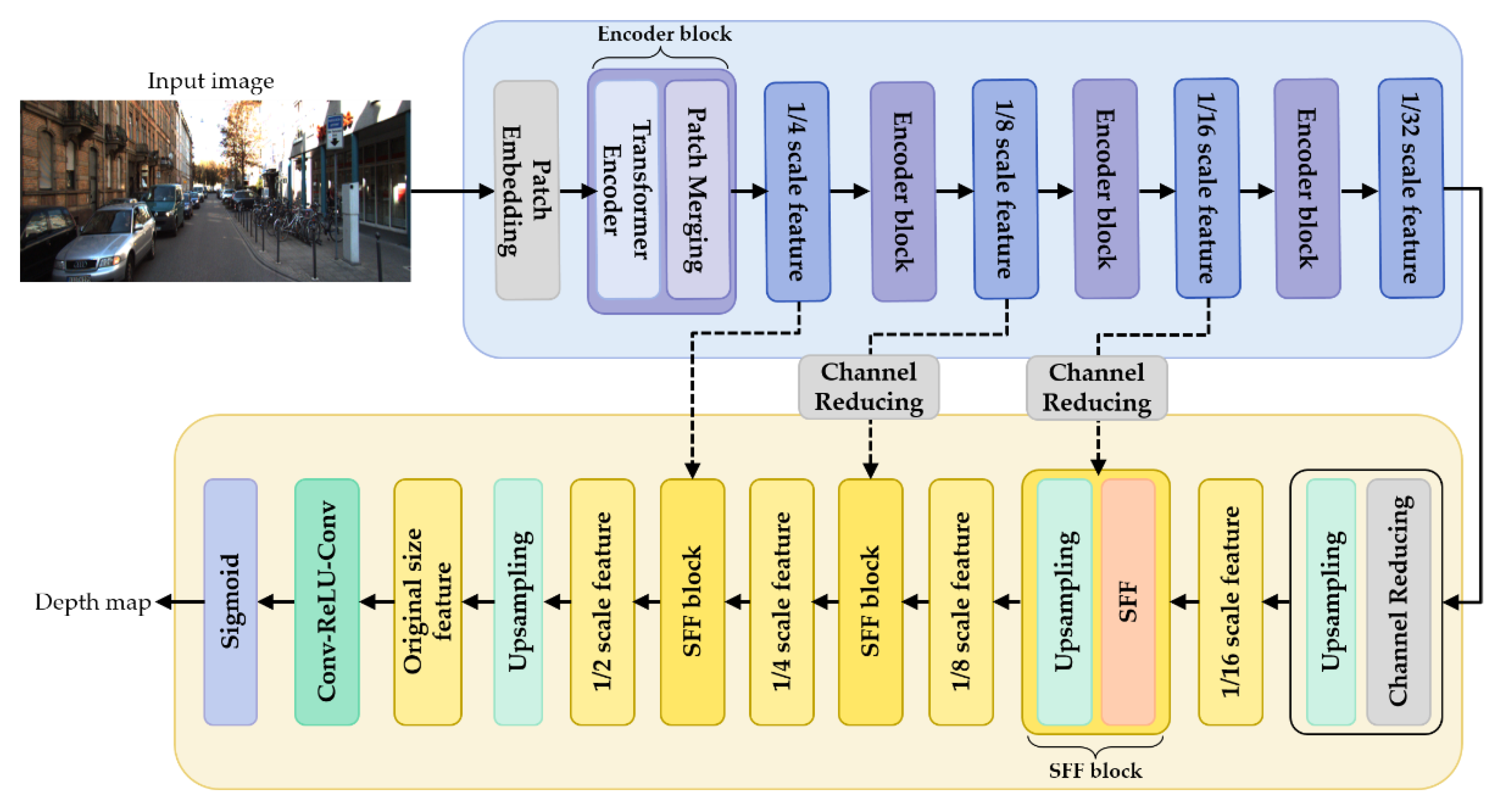
2.2. Depth Estimator
2.3. Distance Predictor
2.3.1. XGBoost
2.3.2. RF
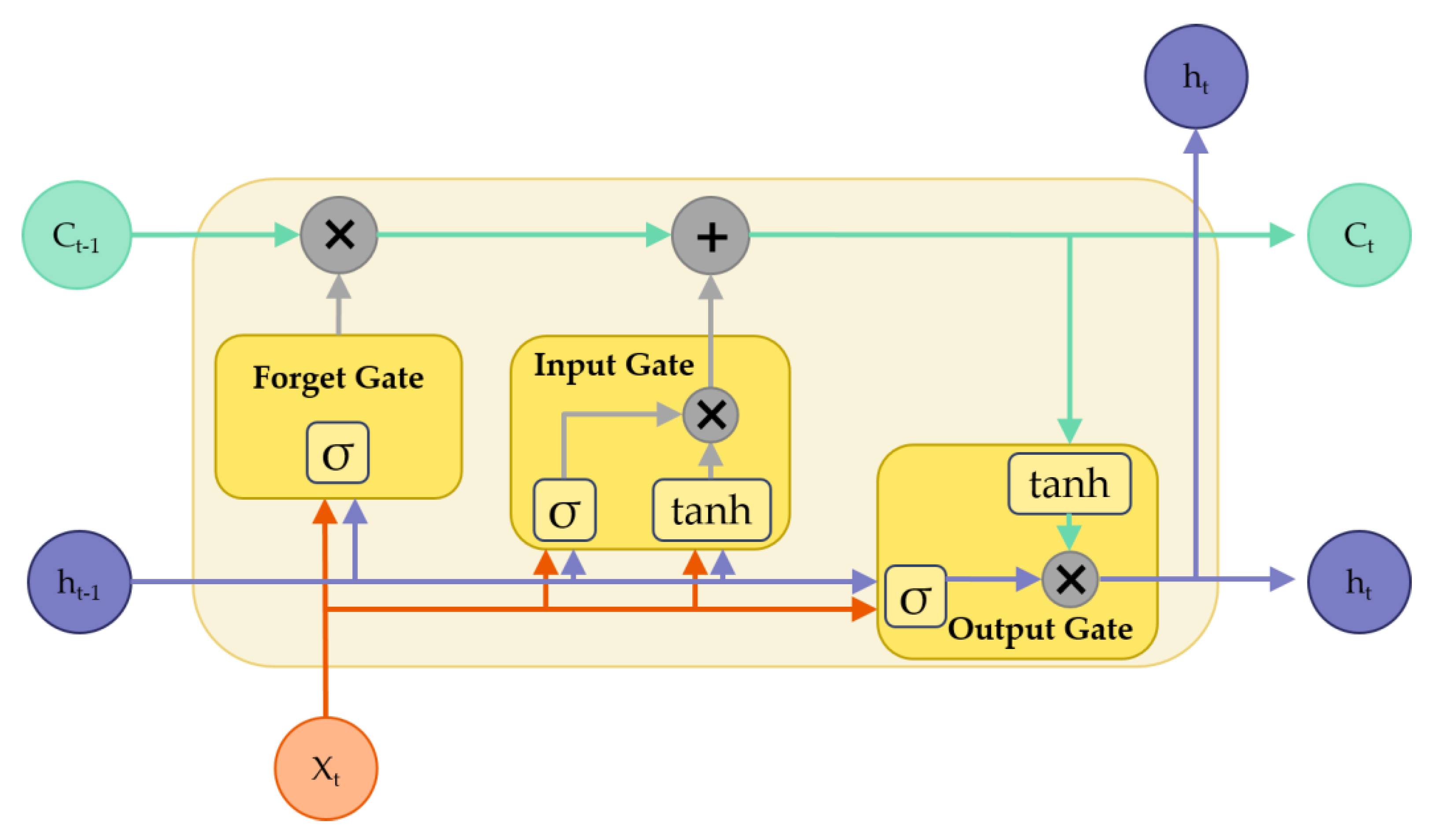
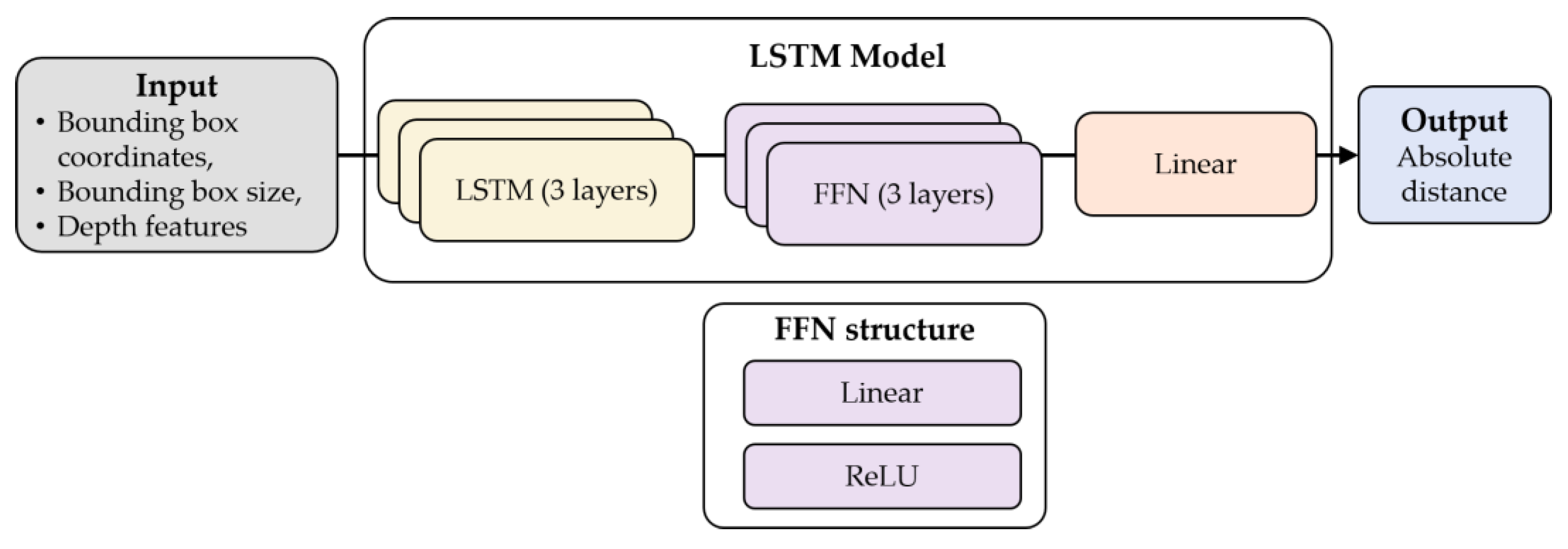
2.3.3. LSTM
3. Experiments
3.1. Data Preprocessing
3.2. Model Training
3.3. Evaluation
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oberhammer, J.; Somjit, N.; Shah, U.; Baghchehsaraei, Z. RF MEMS for automotive radar. In Handbook of Mems for Wireless and Mobile Applications; Uttamchandani, D., Ed.; Woodhead Publishing Ltd.: Cambridge, UK, 2013; pp. 518–549. [Google Scholar]
- Ali, A.; Hassan, A.; Ali, A.R.; Khan, H.U.; Kazmi, W.; Zaheer, A. Real-Time Vehicle Distance Estimation Using Single View Geometry. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1111–1120. [Google Scholar]
- Khader, M.; Cherian, S. An Introduction to Automotive LIDAR; Technical Report; Taxes Instruments Incorporated: Dallas, TX, USA, 2018. [Google Scholar]
- Raj, T.; Hashim, F.H.; Huddin, A.B.; Ibrahim, M.F.; Hussain, A. A survey on LiDAR scanning mechanisms. Electronics 2020, 9, 741. [Google Scholar] [CrossRef]
- Ding, M.; Zhang, Z.; Jiang, X.; Cao, Y. Vision-based distance measurement in advanced driving assistance systems. Appl. Sci. 2020, 10, 7276. [Google Scholar] [CrossRef]
- Liang, H.; Ma, Z.; Zhang, Q. Self-supervised object distance estimation using a monocular camera. Sensors 2022, 22, 2936. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.B. Efficient vehicle detection and distance estimation based on aggregated channel features and inverse perspective mapping from a single camera. Symmetry 2019, 11, 1205. [Google Scholar] [CrossRef]
- Tram, V.T.B.; Yoo, M. Vehicle-to-vehicle distance estimation using a low-resolution camera based on visible light communications. IEEE Access 2018, 6, 4521–4527. [Google Scholar] [CrossRef]
- Kim, G.; Cho, J.S. Vision-Based Vehicle Detection and Inter-Vehicle Distance Estimation. In Proceedings of the International Conference on Control, Automation and Systems, Jeju, Republic of Korea, 17–21 October 2012. [Google Scholar]
- Liu, L.C.; Fang, C.Y.; Chen, S.W. A novel distance estimation method leading a forward collision avoidance assist system for vehicles on highways. IEEE Trans. Intell. Transp. Syst. 2017, 18, 937–949. [Google Scholar] [CrossRef]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Song, Z.; Lu, J.; Zhang, T.; Li, H. End-to-end Learning for Inter-Vehicle Distance and Relative Velocity Estimation in ADAS with a Monocular Camera. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 1–17 June 2020. [Google Scholar]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3D Packing for Self-Supervised Monocular Depth Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2485–2494. [Google Scholar]
- Shu, C.; Yu, K.; Duan, Z.; Yang, K. Feature-metric Loss for Self-supervised Learning of Depth and Egomotion. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhang, Y.; Ding, L.; Li, Y.; Lin, W.; Zhao, M.; Yu, X.; Zhan, Y. A regional distance regression network for monocular object distance estimation. J. Vis. Commun. Image Represent. 2021, 79, 103224. [Google Scholar] [CrossRef]
- Zhu, J.; Fang, Y. Learning Object-Specific Distance from a Monocular Image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3839–3848. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-Scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5354–5362. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Kreuzig, R.; Ochs, M.; Mester, R. DistanceNet: Estimating Traveled Distance from Monocular Images using a Recurrent Convolutional Neural Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A Discriminatively Trained, Multiscale, Deformable Part Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 840–849. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Zhang, G.; Luo, Z.; Cui, K.; Lu, S. Meta-DETR: Few-Shot Object Detection via Unified Image-Level Meta-Learning. arXiv 2021, arXiv:2103.11731. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 2017 Conference on Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kim, D.; Ka, W.; Ahn, P.; Joo, D.; Chun, S.; Kim, J. Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth. arXiv 2022, arXiv:2201.07436. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Kumar, G.A.; Lee, J.H.; Hwang, J.; Park, J.; Youn, S.H.; Kwon, S. LiDAR and camera fusion approach for object distance estimation in self-driving vehicles. Symmetry 2020, 12, 324. [Google Scholar] [CrossRef]
- ADAS Statistics: BSW, LDW, ACC & LKA. Available online: https://caradas.com/adas-statistics/ (accessed on 17 November 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Hyperparameter | Value |
|---|---|---|
| XGBoost | colsample_bytree | 0.9 |
| gamma | 0.3 | |
| learning_rate | 0.01 | |
| max_depth | 9 | |
| min_child_weight | 3 | |
| n_estimators | 1000 | |
| reg_alpha | 1 | |
| reg_lambda | 0.9 | |
| subsample | 0.7 | |
| objective | squared_error | |
| RF | n_estimators | 500 |
| learning_rate | 0.01 | |
| max_depth | 20 | |
| max_features | 2 | |
| min_samples_split | 2 | |
| min_samples_leaf | 1 | |
| criterion | squared_error | |
| LSTM | Input_dim | 15 |
| Hidden_dim(LSTM) | 612 | |
| Layer_dim(LSTM) | 3 | |
| Hidden_dim(Linear) | 612, 306, 154, 76 | |
| Output_dim(Linear) | 1 | |
| Bidirectional | False | |
| Optimizer | Adam | |
| Activation function | ReLU | |
| Max epoch | 1000 | |
| Batch size | 24 |
| Category | Variable | Description |
|---|---|---|
| Input variables | x_min | Minimum x coordinate of a bounding box |
| y_min | Minimum y coordinate of a bounding box | |
| x_max | Maximum x coordinate of a bounding box | |
| y_max | Maximum y coordinate of a bounding box | |
| width | Width of a bounding box | |
| height | Height of a bounding box | |
| depth_mean | Mean depth of an object | |
| depth mean_trim | 20% trimmed mean depth of an object | |
| depth_max | Maximum depth of an object | |
| depth_median | Median depth of an object | |
| class | Type of an object | |
| Output variable | d | Ground truth distance of an object |
| Model | MAE (m) | ||||||
|---|---|---|---|---|---|---|---|
| Car | Person | Bicycle | Train | Truck | Others | Overall | |
| XGBoost | 0.2159 | 0.7366 | 1.3290 | 1.8476 | 2.4005 | 1.9559 | 1.2194 |
| LSTM | 1.2131 | 0.6178 | 1.6292 | 1.2472 | 1.9459 | 1.1650 | 1.1658 |
| RF | 1.3258 | 0.7664 | 1.6695 | 2.1551 | 2.6382 | 2.5058 | 1.3134 |
| Model | MAE (m) | |||||||
|---|---|---|---|---|---|---|---|---|
| 0–9 m | 10–19 m | 20–29 m | 30–39 m | 40–49 m | 50–59 m | 60–69 m | 70–80 m | |
| XGBoost | 0.3786 | 0.6032 | 0.9749 | 1.5372 | 1.9183 | 2.7571 | 3.6277 | 4.1768 |
| LSTM | 0.4154 | 0.5248 | 0.8868 | 1.5052 | 1.9079 | 2.5899 | 3.7846 | 3.3255 |
| RF | 0.4079 | 0.6287 | 1.0588 | 1.6363 | 2.0780 | 3.0674 | 3.5624 | 4.7060 |
| Model | MAE (m) | ||
|---|---|---|---|
| 10% Trimmed | 20% Trimmed | 30% Trimmed | |
| XGBoost | 1.2279 | 1.2194 | 1.2258 |
| LSTM | 1.1909 | 1.1658 | 1.1895 |
| RF | 1.2665 | 1.3134 | 1.2657 |
| Model | MAE (m) | |
|---|---|---|
| Trained Using Ground Truth Bounding Boxes | Trained Using Identified Bounding Boxes | |
| XGBoost | 1.5130 | 1.2194 |
| LSTM | 1.6205 | 1.1658 |
| RF | 1.5295 | 1.3134 |
| Studies | Camera Type | Error Metric | Accuracy Metric | |||||
|---|---|---|---|---|---|---|---|---|
| AbsRel | SquaRel | RMSE | RMSE log | |||||
| Zhou et al. [19] | Monocular | 0.183 | 1.595 | 6.709 | 0.270 | 0.734 | 0.902 | 0.959 |
| Yin and Shi [11] | Monocular | 0.147 | 0.936 | 4.348 | 0.218 | 0.810 | 0.941 | 0.977 |
| Liang et al. [6] | Monocular | 0.101 | 0.715 | NA | 0.178 | 0.899 | 0.981 | 0.990 |
| Shu et al. [14] | Monocular | 0.088 | 0.712 | 4.137 | 0.169 | 0.915 | 0.965 | 0.982 |
| Guizilini et al. [13] | Monocular | 0.078 | 0.420 | 3.485 | 0.121 | 0.931 | 0.986 | 0.996 |
| Ding et al. [5] | Stereo | 0.071 | NA * | 3.740 | NA | 0.934 | 0.979 | 0.992 |
| Ours | Monocular | 0.047 | 0.116 | 2.091 | 0.076 | 0.982 | 0.996 | 1.000 |
| Distance (m) | Accuracy (%) | ||
|---|---|---|---|
| Proposed Framework | Kim [7] | Kumar et al. [42] | |
| 10 | 98.33 | 98.0 | NA |
| 20 | 98.67 | 92.2 | NA |
| 30 | 98.44 | 91.7 | 98.02 |
| 40 | 99.50 | 91.3 | NA |
| 50 | 97.52 | 91.2 | 96.32 |
| 60 | 97.47 | NA * | NA |
| 70 | 93.19 | NA | NA |
| 80 | 96.33 | NA | 95.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Han, K.; Park, S.; Yang, X. Vehicle Distance Estimation from a Monocular Camera for Advanced Driver Assistance Systems. Symmetry 2022, 14, 2657. https://doi.org/10.3390/sym14122657
Lee S, Han K, Park S, Yang X. Vehicle Distance Estimation from a Monocular Camera for Advanced Driver Assistance Systems. Symmetry. 2022; 14(12):2657. https://doi.org/10.3390/sym14122657
Chicago/Turabian StyleLee, Seungyoo, Kyujin Han, Seonyeong Park, and Xiaopeng Yang. 2022. "Vehicle Distance Estimation from a Monocular Camera for Advanced Driver Assistance Systems" Symmetry 14, no. 12: 2657. https://doi.org/10.3390/sym14122657
APA StyleLee, S., Han, K., Park, S., & Yang, X. (2022). Vehicle Distance Estimation from a Monocular Camera for Advanced Driver Assistance Systems. Symmetry, 14(12), 2657. https://doi.org/10.3390/sym14122657