

SDSM: Secure Data Sharing for Multilevel Partnerships in IoT Based Supply Chain


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
3. System Model and Problem Description
3.1. System Model
3.2. Design Goals
- Data privacy: The most basic design requirement is to prevent unauthorized participants from viewing any important information about the shared data submitted by the data owner.
- Fine-grained access control: Each data owner involved in a product transaction is able to specify an access policy for his shared data related to product transactions. The policy should be granular enough to help the data owner define an access policy based on the system’s predefined set of attributes and his own personalized attributes to accurately describe his authorized partners.
- Resistant to collusion attacks: Two or more data requesters with different attributes cannot combine their attributes to access and decrypt data for which they are not authorized by a data owner.
3.3. Security Model
4. The Proposed SDSM Scheme
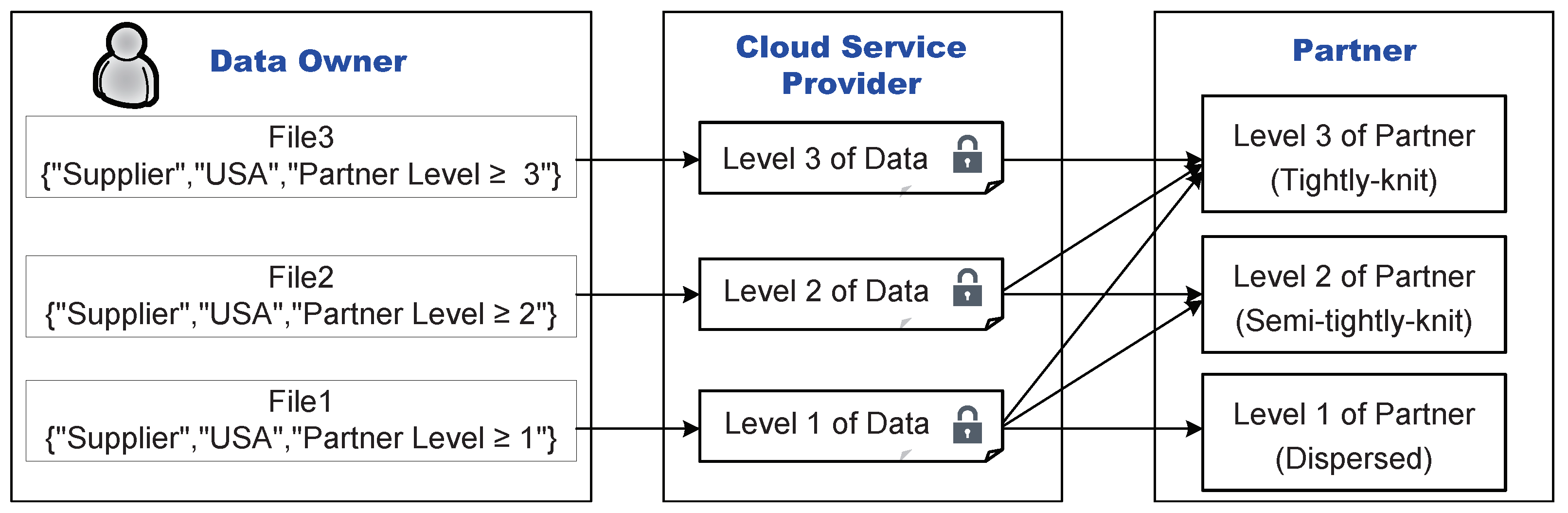
4.1. Definition of Multilevel Partnership
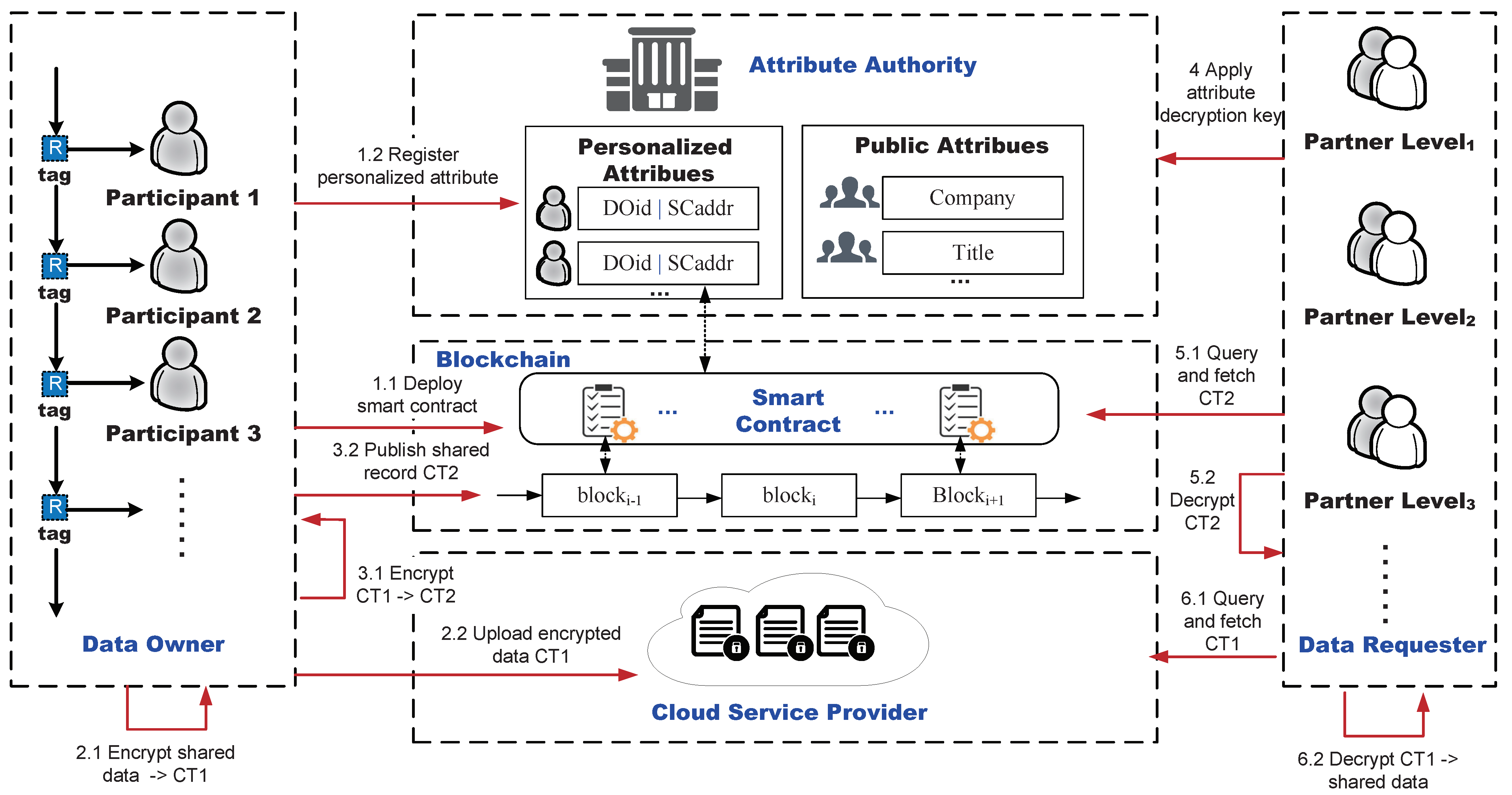
4.2. The SDSM Construction
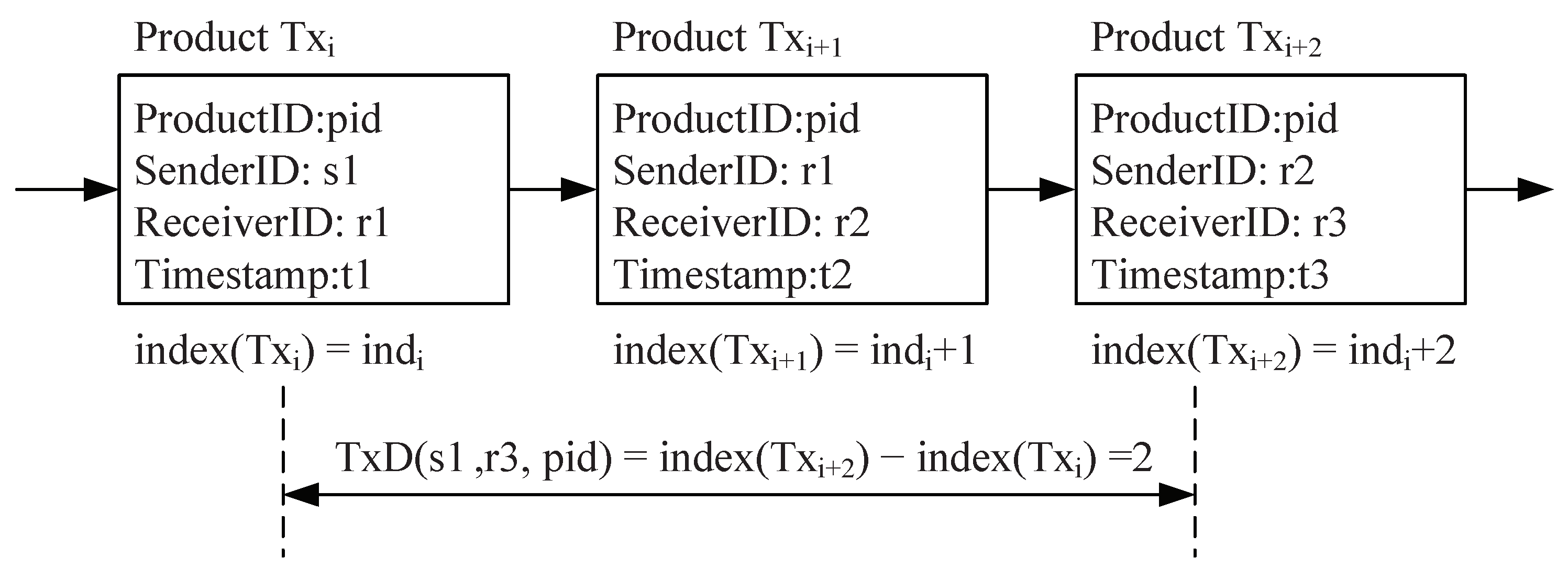
4.3. Smart Contracts
| Algorithm 1: ComputeTxD |
|
| Algorithm 2: Evaluate Level of Partnership |
|
4.4. PA-CP-ABE Algorithm Description
5. Security Analysis
5.1. Security Analysis of the PA-CP-ABE Algorithm
5.2. Security Analysis of Our SDSM Scheme
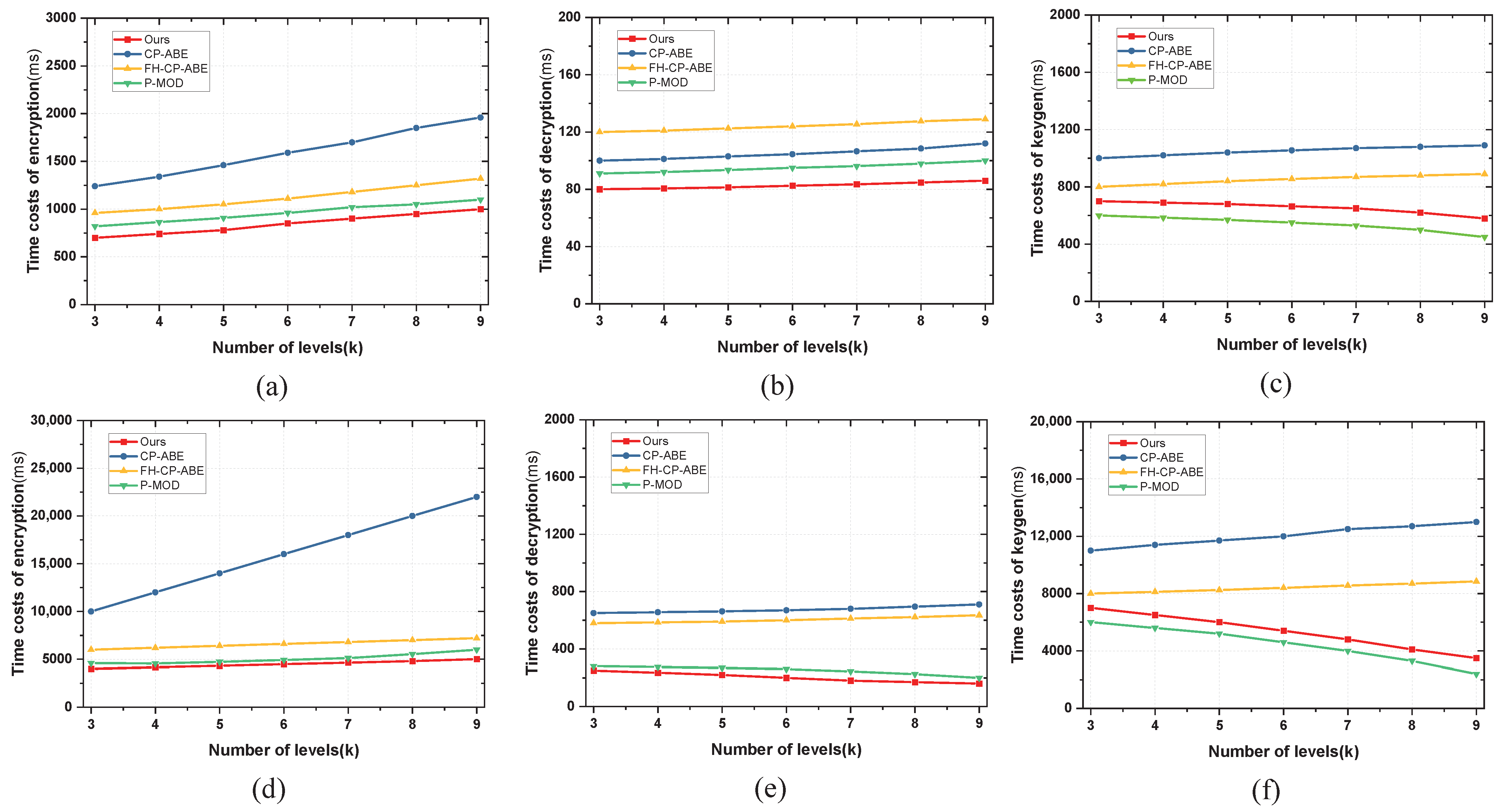
6. Performance Evaluation
6.1. Comparison of Encryption Schemes
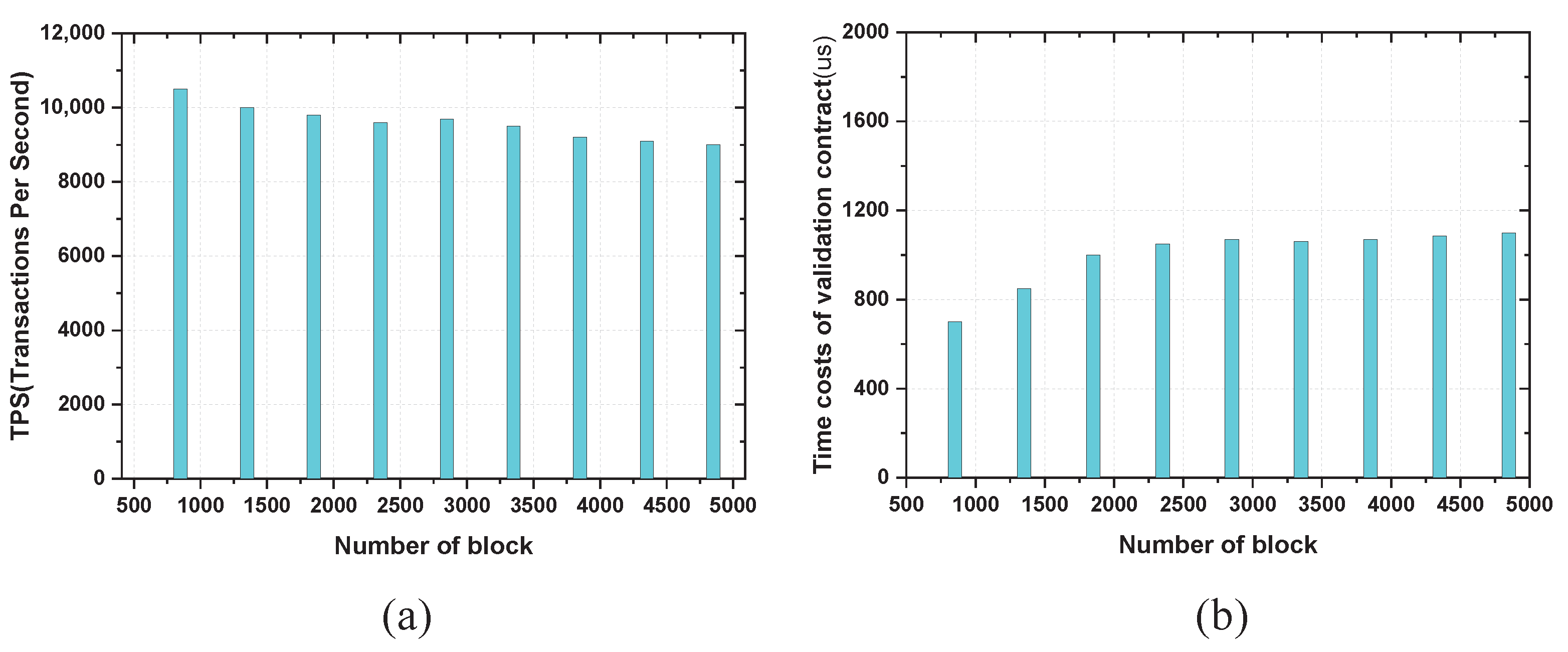
6.2. On-Chain Overhead of Our System
- The experimental network is built on a private cloud platform formed by four computing servers and one storage array.
- The experimental network is a local area network with a data transfer speed of 1000 Mbps.
- Each computing server is configured with two E5-2650v4 processors (12 cores and 24 threads each) and 128G of RAM, and the storage array is configured with 54 TB of enterprise-class SATA hard disks.
- Through virtualization technology, forty virtual servers are configured with two cores and 8 G of RAM assigned to each virtual server.
- Thirty virtual servers act as Hyperledger Fabric nodes, five virtual servers act as cloud storage servers, and the remaining five virtual servers act as attribute authority servers.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Lin, B. Accessing information sharing and information quality in supply chain management. Decis. Support Syst. 2006, 42, 1641–1656. [Google Scholar] [CrossRef]
- Lotfi, Z.; Mukhtar, M.; Sahran, S.; Zadeh, A.T. Information Sharing in Supply Chain Management. Procedia Technol. 2013, 11, 298–304. [Google Scholar] [CrossRef]
- Tao, F.; Cheng, Y.; Xu, L.; Zhang, L.; Li, B. CCIoT-CMfg: Cloud Computing and Internet of Things-Based Cloud Manufacturing Service System. IEEE Trans. Ind. Inform. 2014, 10, 1435–1442. [Google Scholar] [CrossRef]
- Novais, L.; Maqueira, J.M.; Ortiz-Bas, A. A systematic literature review of cloud computing use in supply chain integration. Comput. Ind. Eng. 2019, 129, 296–314. [Google Scholar] [CrossRef]
- Arbit, A.; Oren, Y.; Wool, A. A Secure Supply-Chain RFID System that Respects Your Privacy. IEEE Pervasive Comput. 2014, 13, 52–60. [Google Scholar] [CrossRef]
- Qi, S.; Zheng, Y.; Li, M.; Lu, L.; Liu, Y. Secure and Private RFID-Enabled Third-Party Supply Chain Systems. IEEE Trans. Comput. 2016, 65, 3413–3426. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Gupta, V.; Jain, S.; Guizani, N. A Survey on Supply Chain Security: Application Areas, Security Threats, and Solution Architectures. IEEE Internet Things J. 2021, 8, 6222–6246. [Google Scholar] [CrossRef]
- Cao, Y.; Jia, F.; Manogaran, G. Efficient Traceability Systems of Steel Products Using Blockchain-Based Industrial Internet of Things. IEEE Trans. Ind. Inform. 2020, 16, 6004–6012. [Google Scholar] [CrossRef]
- Wang, X.; Yu, G.; Liu, R.; Zhang, J.; Wu, Q.; Su, S.W.; He, Y.; Zhang, Z.; Yu, L.; Liu, T.; et al. Blockchain-Enabled Fish Provenance and Quality Tracking System. IEEE Internet Things J. 2022, 9, 8130–8142. [Google Scholar] [CrossRef]
- Sun, Z.; Chen, Z.; Cao, S.; Ming, X. Potential Requirements and Opportunities of Blockchain-Based Industrial IoT in Supply Chain: A Survey. IEEE Trans. Comput. Soc. Syst. 2022, 9, 1469–1483. [Google Scholar] [CrossRef]
- Wen, Q.; Gao, Y.; Chen, Z.; Wu, D. A Blockchain-based Data Sharing Scheme in The Supply Chain by IIoT. In Proceedings of the IEEE International Conference on Industrial Cyber Physical Systems (ICPS), Taipei, Taiwan, 6–9 May 2019; pp. 695–700. [Google Scholar]
- Manogaran, G.; Alazab, M.; Shakeel, P.M.; Hsu, C.H. Blockchain Assisted Secure Data Sharing Model for Internet of Things Based Smart Industries. IEEE Trans. Reliab. 2022, 71, 348–358. [Google Scholar] [CrossRef]
- Waters, B. Ciphertext-Policy Attribute-Based Encryption: An Expressive, Efficient, and Provably Secure Realization. In Proceedings of the 14th International Conference on Practice and Theory in Public Key Cryptography, Taormina, Italy, 6–9 March 2011; pp. 53–70. [Google Scholar]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the 2007 IEEE symposium on security and privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Liu, C.; Xiang, F.; Sun, Z. Multiauthority Attribute-Based Access Control for Supply Chain Information Sharing in Blockchain. Secur. Commun. Netw. 2022, 2022, 8497628. [Google Scholar] [CrossRef]
- Jiang, Y.; Xu, X.; Xiao, F. Attribute-based Encryption with Blockchain Protection Scheme for Electronic Health Records. IEEE Trans. Netw. Serv. Manag. 2022, 1. [Google Scholar] [CrossRef]
- Ma, H.; Zhang, R.; Yang, G.; Song, Z.; He, K.; Xiao, Y. Efficient Fine-Grained Data Sharing Mechanism for Electronic Medical Record Systems with Mobile Devices. IEEE Trans. Dependable Secur. Comput. 2020, 17, 1026–1038. [Google Scholar] [CrossRef]
- Niederman, F.; Mathieu, R.G.; Morley, R.; Kwon, I.W. Examining RFID applications in supply chain management. Commun. ACM 2007, 50, 92–101. [Google Scholar] [CrossRef]
- Yang, K.; Forte, D.; Tehranipoor, M.M. CDTA: A Comprehensive Solution for Counterfeit Detection, Traceability, and Authentication in the IoT Supply Chain. ACM Transact. Des. Automat. Electron. Syst. 2017, 22, 42. [Google Scholar] [CrossRef]
- Misra, N.N.; Dixit, Y.; Al-Mallahi, A.; Bhullar, M.S.; Upadhyay, R.; Martynenko, A. IoT, Big Data, and Artificial Intelligence in Agriculture and Food Industry. IEEE Internet Things J. 2022, 9, 6305–6324. [Google Scholar] [CrossRef]
- Piltan, M.; Sowlati, T. Multi-criteria assessment of partnership components. Expert Syst. Appl. 2016, 64, 605–617. [Google Scholar] [CrossRef]
- Rezaei, S.; Behnamian, J. A survey on competitive supply networks focusing on partnership structures and virtual alliance: New trends. J. Clean. Prod. 2021, 287, 125031. [Google Scholar] [CrossRef]
- Kim, J.S.; Shin, N. The Impact of Blockchain Technology Application on Supply Chain Partnership and Performance. Sustainability 2019, 11, 6181. [Google Scholar] [CrossRef]
- Putra, F.A.; Ramli, K.; Hayati, N.; Gunawan, T.S. PURA-SCIS Protocol: A Novel Solution for Cloud-Based Information Sharing Protection for Sectoral Organizations. Symmetry 2021, 13, 2347. [Google Scholar] [CrossRef]
- Qi, S.; Zheng, Y.; Li, M.; Liu, Y.; Qiu, J. Scalable Industry Data Access Control in RFID-Enabled Supply Chain. IEEE-ACM Trans. Netw. 2016, 24, 3551–3564. [Google Scholar] [CrossRef]
- Qi, S.; Lu, Y.; Wei, W.; Chen, X. Efficient Data Access Control With Fine-Grained Data Protection in Cloud-Assisted IIoT. IEEE Internet Things J. 2021, 8, 2886–2899. [Google Scholar] [CrossRef]
- Wei, X.; Yan, Y.; Guo, S.; Qiu, X.; Qi, F. Secure Data Sharing: Blockchain-Enabled Data Access Control Framework for IoT. IEEE Internet Things J. 2022, 9, 8143–8153. [Google Scholar] [CrossRef]
- Almagrabi, A.O.; Bashir, A.K. A classification-based privacy-preserving decision-making for secure data sharing in Internet of Things assisted applications. Digit. Commun. Netw. 2022, 8, 436–445. [Google Scholar] [CrossRef]
- Miao, Q.; Lin, H.; Hu, J.; Wang, X. An intelligent and privacy-enhanced data sharing strategy for blockchain-empowered Internet of Things. Digit. Commun. Netw. 2022, 8, 636–643. [Google Scholar] [CrossRef]
- Jia, X.; Song, X.; Sohail, M. Effective Consensus-Based Distributed Auction Scheme for Secure Data Sharing in Internet of Things. Symmetry 2022, 14, 1664. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, J.; Liu, J.K.; Yu, J.; Chen, J.; Xie, W. An Efficient File Hierarchy Attribute-Based Encryption Scheme in Cloud Computing. IEEE Trans. Inf. Forensic Secur. 2016, 11, 1265–1277. [Google Scholar] [CrossRef]
- Zaghloul, E.; Zhou, K.; Ren, J. P-MOD: Secure Privilege-Based Multilevel Organizational Data-Sharing in Cloud Computing. IEEE Trans. Big Data 2020, 6, 804–815. [Google Scholar] [CrossRef]
- Zaghloul, E.; Li, T.; Mutka, M.; Ren, J. d-MABE: Distributed Multilevel Attribute-Based EMR Management and Applications. IEEE Trans. Serv. Comput. 2022, 15, 1592–1605. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, C.; Zhan, Y.; Sohail, M. SDSM: Secure Data Sharing for Multilevel Partnerships in IoT Based Supply Chain. Symmetry 2022, 14, 2656. https://doi.org/10.3390/sym14122656
Yu C, Zhan Y, Sohail M. SDSM: Secure Data Sharing for Multilevel Partnerships in IoT Based Supply Chain. Symmetry. 2022; 14(12):2656. https://doi.org/10.3390/sym14122656
Chicago/Turabian StyleYu, Chuntang, Yongzhao Zhan, and Muhammad Sohail. 2022. "SDSM: Secure Data Sharing for Multilevel Partnerships in IoT Based Supply Chain" Symmetry 14, no. 12: 2656. https://doi.org/10.3390/sym14122656
APA StyleYu, C., Zhan, Y., & Sohail, M. (2022). SDSM: Secure Data Sharing for Multilevel Partnerships in IoT Based Supply Chain. Symmetry, 14(12), 2656. https://doi.org/10.3390/sym14122656