
Optimal Design of Convolutional Neural Network Architectures Using Teaching–Learning-Based Optimization for Image Classification

 ,
,  ,
,  ,
,  ,
, 
 , and
, and 
Abstract
1. Introduction
2. Related Works
2.1. Teaching–Learning-Based Optimization (TLBO)
2.2. Convolutional Neural Networks (CNNs)
2.3. Existing Metaheuristic-Search-Based Methods in Optimizing Neural Networks
2.4. Technical Contributions of Current Works
- A new network architecture design method known as TLBOCNN is proposed to automatically discover the optimal network architecture of CNNs (i.e., number of layers, type of layers, kernel sizes, number of filters, and number of neurons) for image classification without requiring rich expert domain knowledge. To the best of the authors’ knowledge, no existing studies or only limited works have employed TLBO for the optimization of CNN network architectures.
- TLBOCNN can accommodate the searching of CNN network architectures with flexible size by incorporating the appropriate solution-encoding strategy and design constraints for TLBO learners with variable lengths. These modifications not only prevent the construction of CNNs with invalid network architectures but also preserve the ability of TLBOCNN in discovering novel network architectures. A computationally efficient fitness evaluation process is also incorporated into TLBOCNN to ensure the practicability of the proposed network architecture design method.
- A new mainstream architecture computation scheme is introduced in the teacher phase of TLBOCNN to determine the population mean by referring to all TLBO learners encoded as CNNs with different network architectures. In order to maintain the simplicity of TLBO, a new difference operator is first introduced in both the teacher phase and the learner phase to compare the differences between existing learners with unique network architectures, followed by the design of a new position update operator used to search for the new TLBO learners.
- Extensive simulation studies are conducted to evaluate the feasibility of proposed TLBOCNN in discovering the optimal network architectures of CNN automatically for nine popular datasets. The optimal CNN network architectures constructed by TLBOCNN are proven to have better classification performances than state-of-the-art works when solving majority datasets.
3. Details of Proposed TLBOCNN
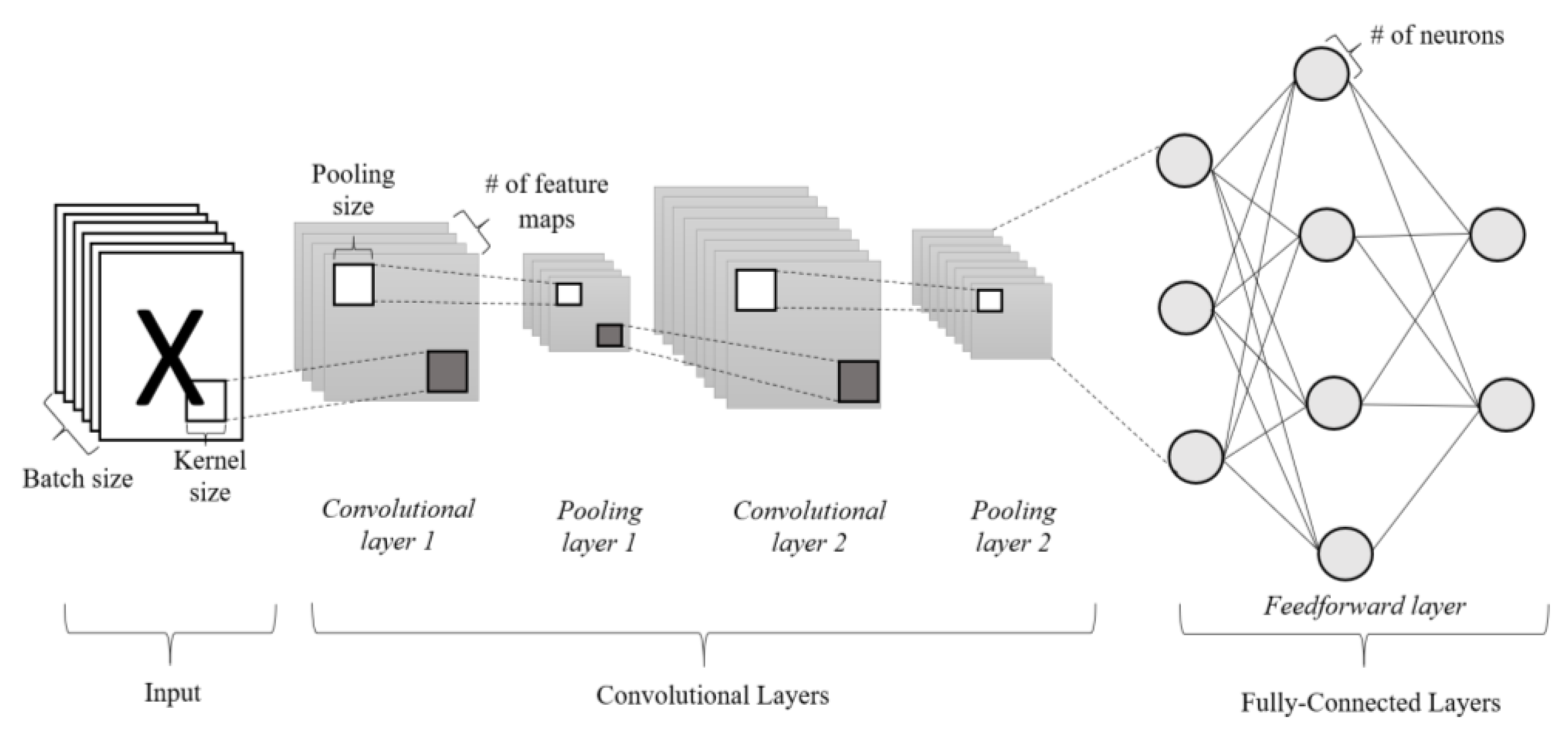
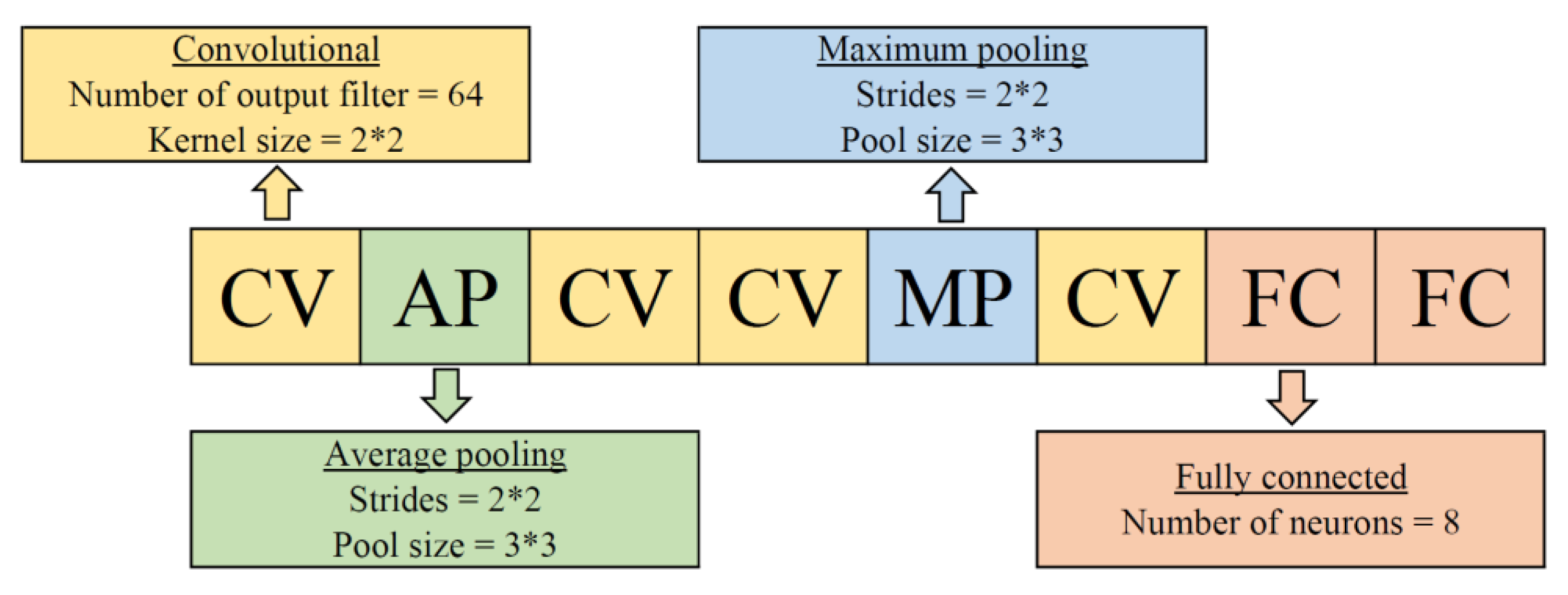
3.1. Functional Blocks Encoding Scheme
3.2. Population Initialization of TLBOCNN
| Algorithm 1: Population Initialization | ||||||
| Input:N,,,,,, numOut | ||||||
| 01: | Initialize and ; | |||||
| 02: | forn = 1 to N do | |||||
| 03: | and for n-th learner; | |||||
| 04: | Reset the ; | |||||
| 05: | forjdo | |||||
| 06: | ifj = 1 then | |||||
| 07: | Assign with a between ; | |||||
| 08: | else ifthen | |||||
| 09: | Assign with a as numOut; | |||||
| 10: | else ifthen | |||||
| 11: | Assign with a between and ; | |||||
| 12: | else | |||||
| 13: | Randomly generate ; | |||||
| 14: | ifthen | |||||
| 15: | Assign with a between ; | |||||
| 16: | else ifthen | |||||
| 17: | Randomly generate the ; | |||||
| 18: | ifthen | |||||
| 19: | Assign with an and , respectively; | |||||
| 20: | else | |||||
| 21: | Assign with a and , respectively. | |||||
| 22: | end if | |||||
| 23: | end if | |||||
| 24: | end if | |||||
| 25: | end for | |||||
| 26: | ; | |||||
| 27: | with Algorithm 2; | |||||
| 28: | if then /*Compare the accuracy of n-th learner and teacher */ | |||||
| 29: | , ; /*Update teacher */ | |||||
| 30: | end if | |||||
| 31: | end for | |||||
| Output: | ||||||
3.3. Fitness Evaluation of TLBOCNN
| Algorithm 2: Fitness Evaluation | |||
| Input:, , ℓ | |||
| 01: | Compile to a full-fledged CNN; | ||
| 02: | Calculate and using Equations (4) and (6), respectively; | ||
| 03: | of complied CNN model with He Normal initializer; | ||
| 04: | for /* Train the compiled CNN model forepoch*/ | ||
| 05: | fordo | ||
| 06: | ; | ||
| 07: | Update the new weights based on using Equation (5); | ||
| 08: | end for | ||
| 09: | end for | ||
| 10: | Initialize with the size of ; | ||
| 11: | fordo /* Evaluate the compiled CNN model using validation dataset */ | ||
| 12: | ; | ||
| 13: | Store the classification accuracy of complied CNN model on the into ; | ||
| 14: | end for | ||
| 15: | Calculate of using Equation (7); | ||
| Output: | |||
3.4. Teacher Phase of TLBOCNN
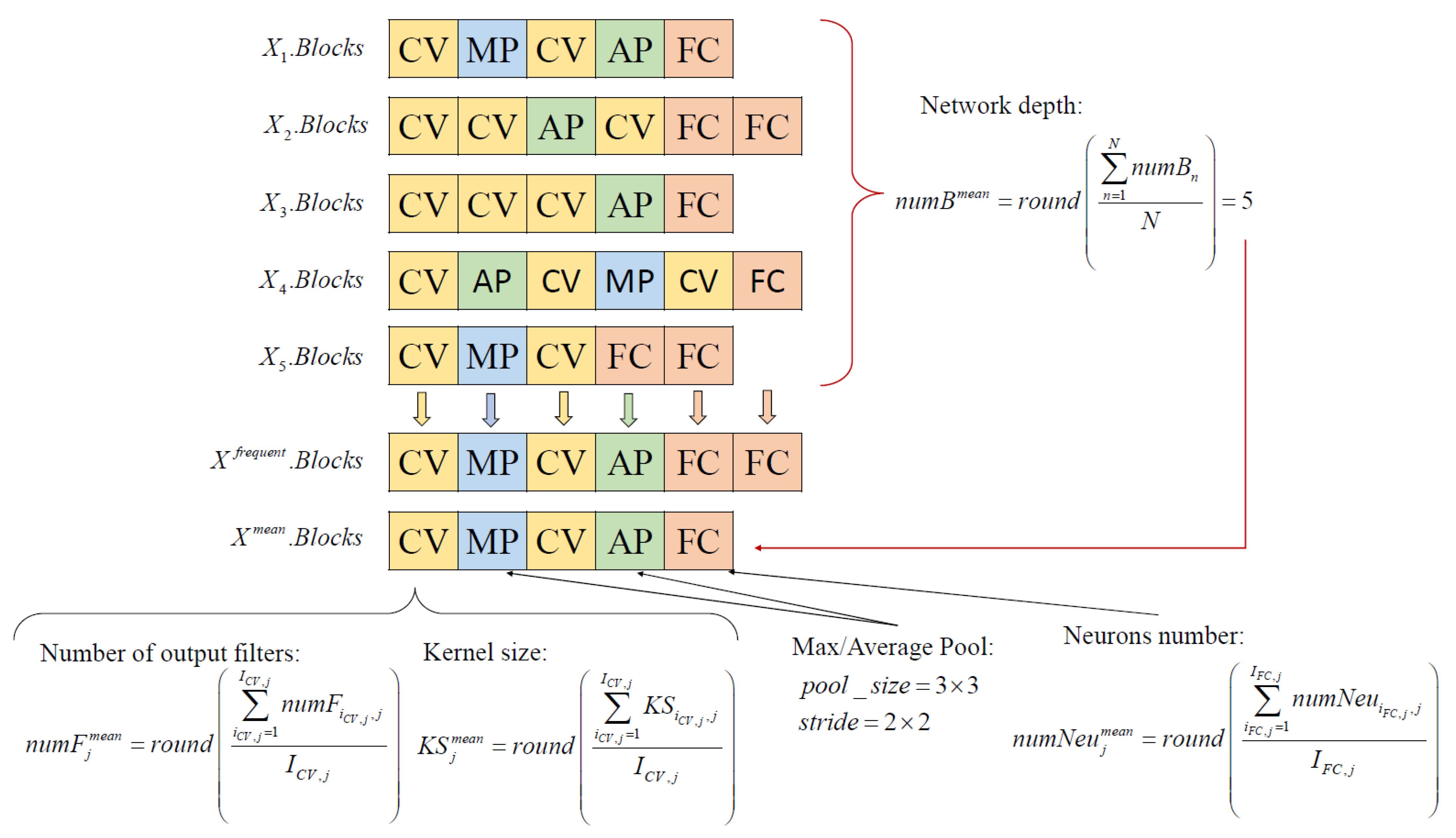
3.4.1. Computation of Mainstream CNN Architecture
| Algorithm 3: Computation of Mainstream CNN Architecture | ||||
| Input:, N, numOut | ||||
| 01: | ; | |||
| 02: | forjdo | |||
| 03: | ; | |||
| 04: | if more than one functional block has highest frequency of occurrence do | |||
| 05: | ; | |||
| 06: | else | |||
| 07: | ; | |||
| 08: | end if | |||
| 09: | end for | |||
| 10: | ; | |||
| 11: | forjdo | |||
| 12: | ifj = 1 then | |||
| 13: | with convolutional block (CV); | |||
| 14: | using Equations (11) and (12), respectively; | |||
| 15: | else ifj =do | |||
| 16: | with fully-connected block (FC); | |||
| 17: | Assign as numOut; | |||
| 18: | else ifjthen | |||
| 19: | if has the highest count then | |||
| 20: | with convolutional block (CV); | |||
| 21: | using Equations (11) and (12), respectively; | |||
| 22: | else if has the highest count then | |||
| 23: | with maximum pooling block (MP); | |||
| 24: | Set the , respectively; | |||
| 25: | else if has the highest count then | |||
| 26: | with average pooling block (AP); | |||
| 27: | Set the , respectively; | |||
| 28: | else if has the highest count then | |||
| 29: | with fully-connected block (FC); | |||
| 30: | using Equation (13); | |||
| 31: | end if | |||
| 32: | end if | |||
| 33: | end for | |||
| Output: | ||||
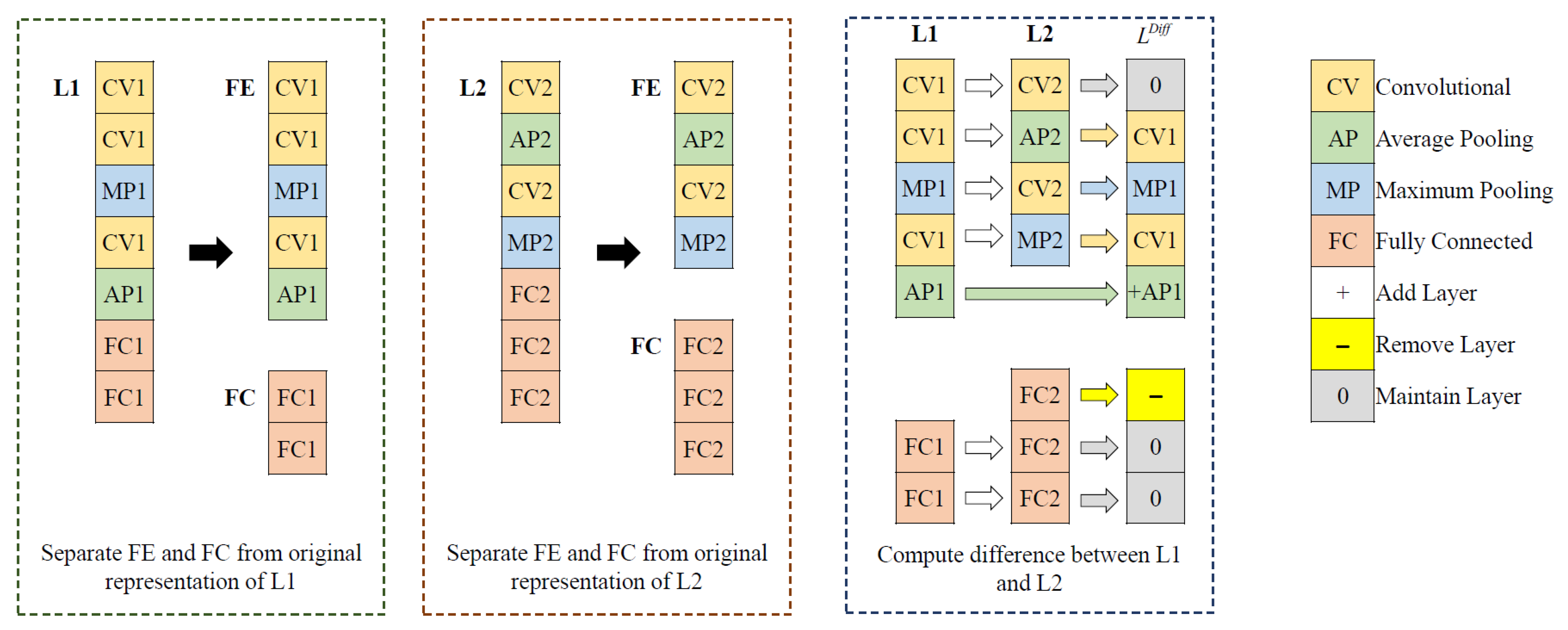
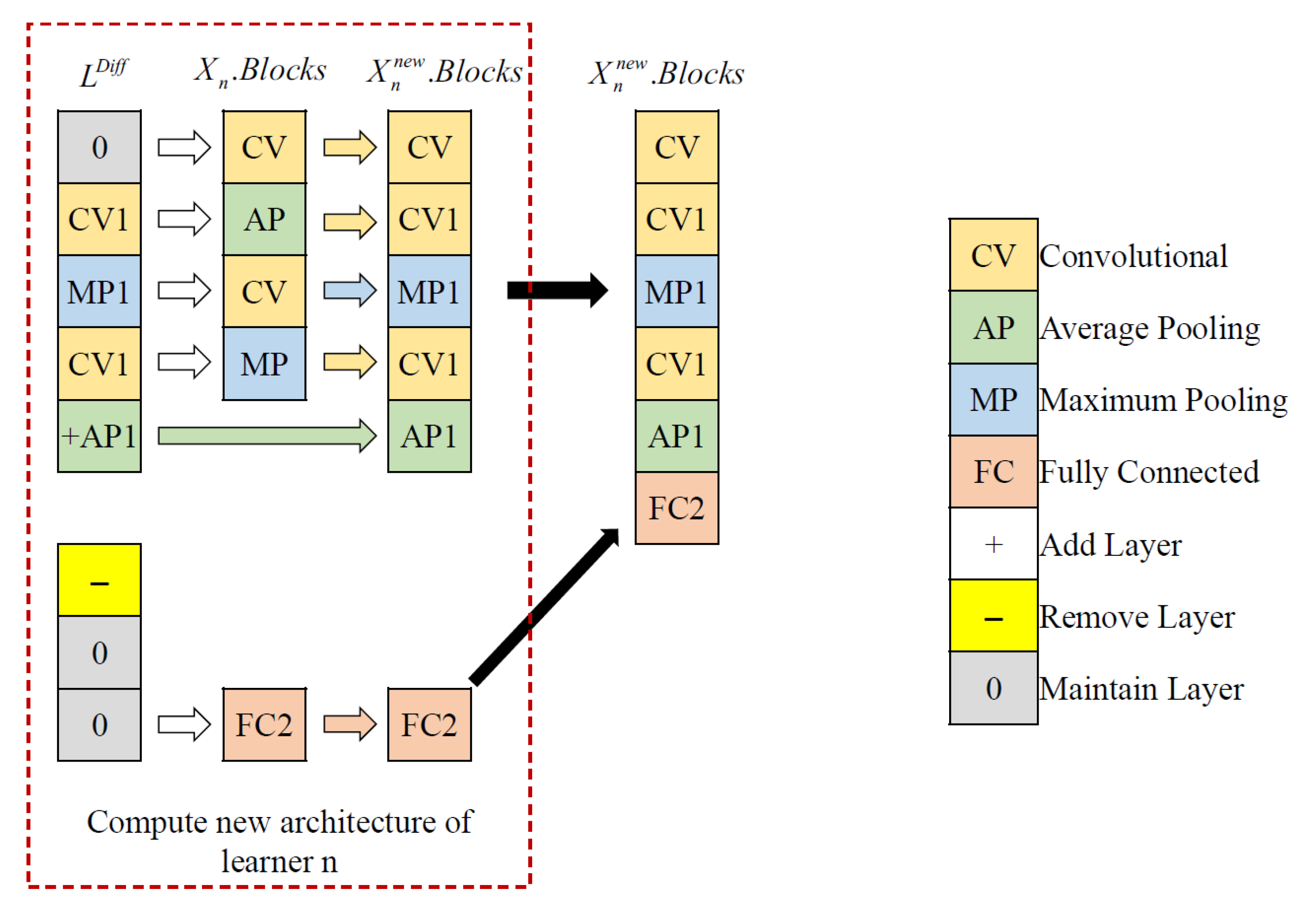
3.4.2. Computation of Differences between Two Learners
| Algorithm 4: Calculate Differences Between L1 and L2 | |||
| Input:L1, L2 | |||
| 01: | Separate the FC layers encoded in L1 and L2 from the FE module as shown in Figure 4. | ||
| 02: | from L2; | ||
| 03: | ;; | ||
| 04: | forjdo | ||
| 05: | ifthen | ||
| 06: | ; | ||
| 07: | else ifthen | ||
| 08: | with ‘0’ to indicate no changes of functional block; | ||
| 09: | else if has no functional block then | ||
| 10: | ; | ||
| 11: | else if has functional block then | ||
| 12: | with ‘-’ to indicate the removal of functional block; | ||
| 13: | end if | ||
| 14: | end for | ||
| Output: | |||
3.4.3. Computation of New Learner
| Algorithm 5: | |||
| Input: Functional block information encoded in | |||
| 01: | from the FE module as shown in Figure 5. | ||
| 02: | ; | ||
| 03: | ; | ||
| 04: | forjdo | ||
| 05: | if has a functional block then | ||
| 06: | ; | ||
| 07: | else if has no functional block then | ||
| 08: | with an empty value; | ||
| 09: | else ifthen | ||
| 10: | with an empty value; | ||
| 11: | else ifthen | ||
| 12: | with the functional block information of B; | ||
| 13: | else if has a functional block then | ||
| 14: | ; | ||
| 15: | else if has a functional block then | ||
| 16: | ; | ||
| 17: | end if | ||
| 18: | end for | ||
| 19: | assigned with an empty value; | ||
| 20: | one by one starting from last layers if it is found to have more pooling layers than that allowed by the sizes of input datasets. | ||
| Output:; | |||
| Algorithm 6: Teacher Phase of TLBOCNN | |||
| Input:, , , , , | |||
| 01: | with Algorithm 3; | ||
| 02: | forn = 1 to N do | ||
| 03: | , ; | ||
| 04: | from L1 and L2 with Algorithm 4; | ||
| 03: | based on with Algorithm 5; | ||
| 04: | to obtain with Algorithm 2; | ||
| 06: | if then | ||
| 07: | , ; | ||
| 08: | if then | ||
| 09: | , ; | ||
| 10: | end if | ||
| 11: | end if | ||
| 12: | end for | ||
| Output: | |||
3.5. Learner Phase of TLBOCNN
| Algorithm 7: Learner Phase of TLBOCNN | |||
| Input:, , , , , , | |||
| 01: | forn = 1 to N do | ||
| 02: | ; | ||
| 03: | ifthen | ||
| 04: | ; | ||
| 05: | else | ||
| 06: | ; | ||
| 07: | end if | ||
| 08: | from L1 and L2 with Algorithm 4; | ||
| 09: | based on with Algorithm 5; | ||
| 10: | to obtain with Algorithm 2; | ||
| 11: | if then | ||
| 12: | , ; | ||
| 13: | if then | ||
| 14: | , ; | ||
| 15: | end if | ||
| 16: | end if | ||
| 17: | end for | ||
| Output: | |||
3.6. Overall Framework of TLBOCNN
| Algorithm 8: TLBOCNN | ||
| ,, , N, , numOut | ||
| 01: | from the directory; | |
| 02: | with Algorithm 1; | |
| 03: | do | |
| 04: | with Algorithm 6; | |
| 05: | with Algorithm 7; | |
| 06: | end for | |
| 07: | using Algorithm 2; | |
| 08: | ; | |
4. Experimental Design and Results Analysis
4.1. Image Datasets
4.2. Selection of Peer Algorithms and Simulation Settings
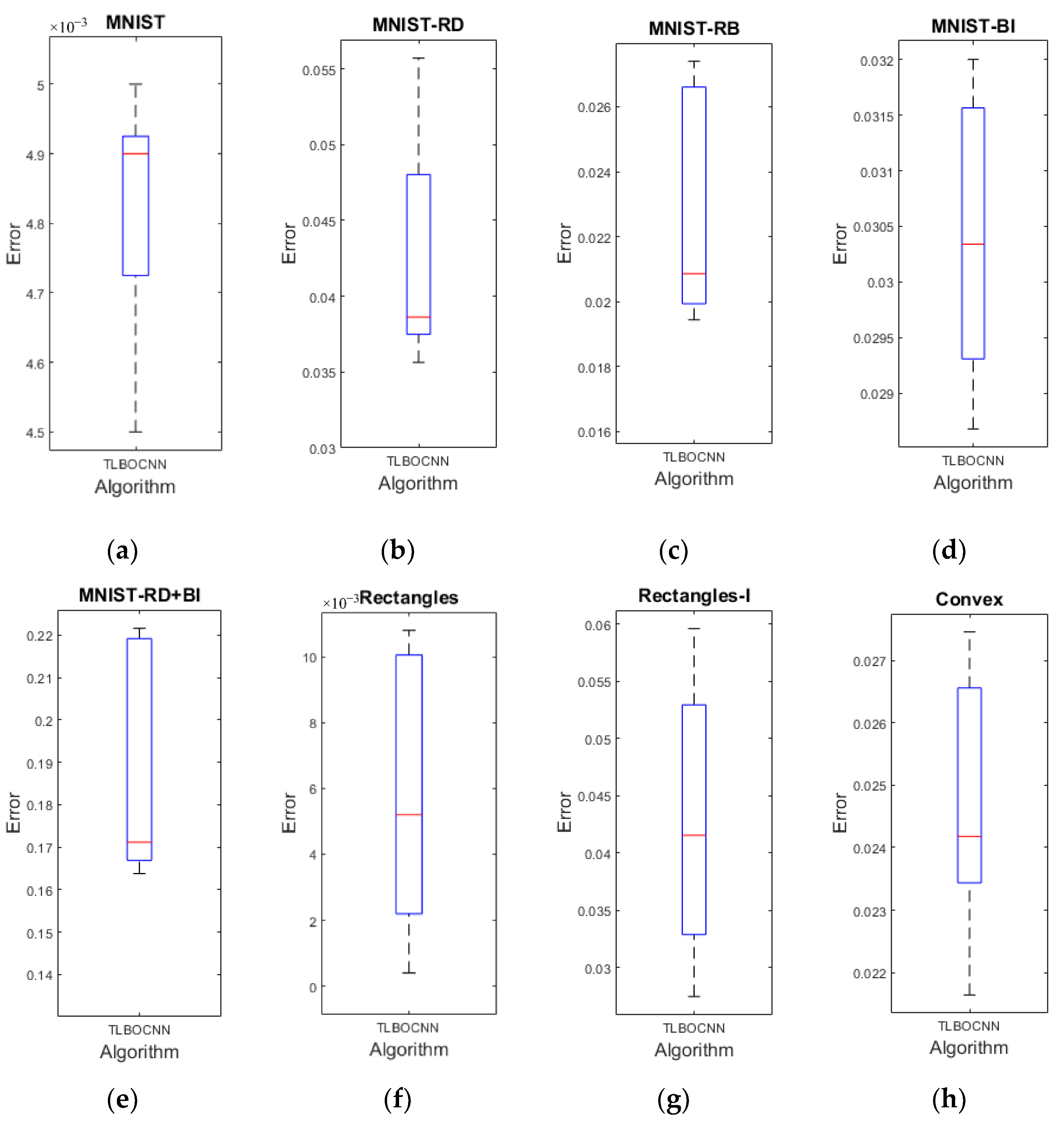
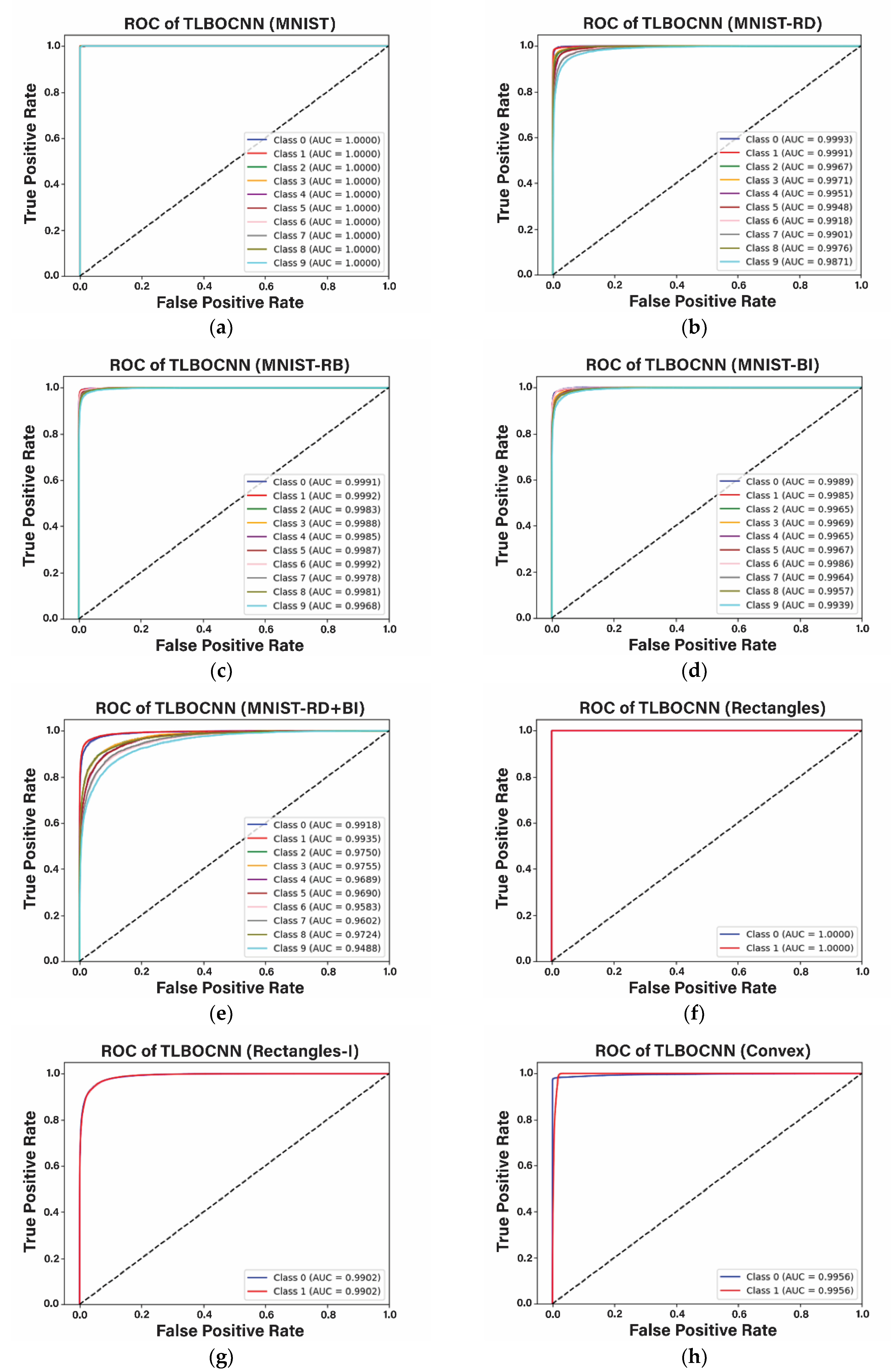
4.3. Simulation Results
4.3.1. Performance Comparisons in Solving Eight Image Datasets
4.3.2. Performance Comparisons in Solving Fashion Dataset
4.3.3. Optimal Network Architecture Designed by TLBOCNN
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carvalho, M.; Ludermir, T.B. Particle swarm optimization of neural network architectures andweights. In Proceedings of the 7th International Conference on Hybrid Intelligent Systems (HIS 2007), Kaiserslautern, Germany, 17–19 September 2007; pp. 336–339. [Google Scholar]
- Sainath, T.N.; Mohamed, A.-R.; Kingsbury, B.; Ramabhadran, B. Deep convolutional neural networks for LVCSR. In Proceedings of the 2013 IEEE international Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8614–8618. [Google Scholar]
- Syulistyo, A.R.; Purnomo, D.M.J.; Rachmadi, M.F.; Wibowo, A. Particle swarm optimization (PSO) for training optimization on convolutional neural network (CNN). J. Ilmu Komput. Dan Inf. 2016, 9, 52–58. [Google Scholar] [CrossRef]
- Rodriguez, P.; Wiles, J.; Elman, J.L. A recurrent neural network that learns to count. Connect. Sci. 1999, 11, 5–40. [Google Scholar] [CrossRef]
- Sumachev, A.E.; Kuzmin, V.A.; Borodin, E.S. River flow forecasting using artificial neural networks. Int. J. Mech. Eng. Technol. 2018, 9, 706–714. [Google Scholar]
- Hu, M.; Wu, Y.; Fan, J.; Jing, B. Joint Semantic Intelligent Detection of Vehicle Color under Rainy Conditions. Mathematics 2022, 10, 3512. [Google Scholar] [CrossRef]
- Alotaibi, M.F.; Omri, M.; Abdel-Khalek, S.; Khalil, E.; Mansour, R.F. Computational Intelligence-Based Harmony Search Algorithm for Real-Time Object Detection and Tracking in Video Surveillance Systems. Mathematics 2022, 10, 733. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; p. 922. [Google Scholar]
- Abdelhamid, A.A.; El-Kenawy, E.-S.M.; Alotaibi, B.; Amer, G.M.; Abdelkader, M.Y.; Ibrahim, A.; Eid, M.M. Robust Speech Emotion Recognition Using CNN+ LSTM Based on Stochastic Fractal Search Optimization Algorithm. IEEE Access 2022, 10, 49265–49284. [Google Scholar] [CrossRef]
- Fan, C.-L.; Chung, Y.-J. Design and Optimization of CNN Architecture to Identify the Types of Damage Imagery. Mathematics 2022, 10, 3483. [Google Scholar] [CrossRef]
- Feng, X.; Gao, X.; Luo, L. A ResNet50-Based Method for Classifying Surface Defects in Hot-Rolled Strip Steel. Mathematics 2021, 9, 2359. [Google Scholar] [CrossRef]
- Khurma, R.A.; Alsawalqah, H.; Aljarah, I.; Elaziz, M.A.; Damaševičius, R. An Enhanced Evolutionary Software Defect Prediction Method Using Island Moth Flame Optimization. Mathematics 2021, 9, 1722. [Google Scholar] [CrossRef]
- Boikov, A.; Payor, V.; Savelev, R.; Kolesnikov, A. Synthetic data generation for steel defect detection and classification using deep learning. Symmetry 2021, 13, 1176. [Google Scholar] [CrossRef]
- Deng, H.; Cheng, Y.; Feng, Y.; Xiang, J. Industrial Laser Welding Defect Detection and Image Defect Recognition Based on Deep Learning Model Developed. Symmetry 2021, 13, 1731. [Google Scholar] [CrossRef]
- El-kenawy, E.-S.M.; Albalawi, F.; Ward, S.A.; Ghoneim, S.S.; Eid, M.M.; Abdelhamid, A.A.; Bailek, N.; Ibrahim, A. Feature selection and classification of transformer faults based on novel meta-heuristic algorithm. Mathematics 2022, 10, 3144. [Google Scholar] [CrossRef]
- Alhussan, A.A.; Khafaga, D.S.; El-Kenawy, E.-S.M.; Ibrahim, A.; Eid, M.M.; Abdelhamid, A.A. Pothole and Plain Road Classification Using Adaptive Mutation Dipper Throated Optimization and Transfer Learning for Self Driving Cars. IEEE Access 2022, 10, 84188–84211. [Google Scholar] [CrossRef]
- Xin, R.; Zhang, J.; Shao, Y. Complex network classification with convolutional neural network. Tsinghua Sci. Technol. 2020, 25, 447–457. [Google Scholar] [CrossRef]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adam, M.; Gertych, A.; San Tan, R. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2017, 89, 389–396. [Google Scholar] [CrossRef]
- Khafaga, D.S.; Alhussan, A.A.; El-Kenawy, E.-S.M.; Ibrahim, A.; Eid, M.M.; Abdelhamid, A.A. Solving Optimization Problems of Metamaterial and Double T-Shape Antennas Using Advanced Meta-Heuristics Algorithms. IEEE Access 2022, 10, 74449–74471. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar] [CrossRef]
- Bäck, T.; Fogel, D.B.; Michalewicz, Z. Handbook of evolutionary computation. Release 1997, 97, B1. [Google Scholar] [CrossRef]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar] [CrossRef]
- Melanie, M. An Introduction to Genetic Algorithms; Massachusetts Institute of Technology: Cambridge, MA, USA, 1996; p. 158. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 1944, pp. 1942–1948. [Google Scholar]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 19. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Behera, M.; Sarangi, A.; Mishra, D.; Mallick, P.K.; Shafi, J.; Srinivasu, P.N.; Ijaz, M.F. Automatic Data Clustering by Hybrid Enhanced Firefly and Particle Swarm Optimization Algorithms. Mathematics 2022, 10, 3532. [Google Scholar] [CrossRef]
- Chen, J.; Chen, M.; Wen, J.; He, L.; Liu, X. A Heuristic Construction Neural Network Method for the Time-Dependent Agile Earth Observation Satellite Scheduling Problem. Mathematics 2022, 10, 3498. [Google Scholar] [CrossRef]
- Qiu, J.; Yin, X.; Pan, Y.; Wang, X.; Zhang, M. Prediction of Uniaxial Compressive Strength in Rocks Based on Extreme Learning Machine Improved with Metaheuristic Algorithm. Mathematics 2022, 10, 3490. [Google Scholar] [CrossRef]
- Kaya, E. A New Neural Network Training Algorithm Based on Artificial Bee Colony Algorithm for Nonlinear System Identification. Mathematics 2022, 10, 3487. [Google Scholar] [CrossRef]
- Ma, Z.; Yuan, X.; Han, S.; Sun, D.; Ma, Y. Improved chaotic particle swarm optimization algorithm with more symmetric distribution for numerical function optimization. Symmetry 2019, 11, 876. [Google Scholar] [CrossRef]
- Zhang, M.; Long, D.; Qin, T.; Yang, J. A chaotic hybrid butterfly optimization algorithm with particle swarm optimization for high-dimensional optimization problems. Symmetry 2020, 12, 1800. [Google Scholar] [CrossRef]
- El-Kenawy, E.-S.M.; Mirjalili, S.; Alassery, F.; Zhang, Y.-D.; Eid, M.M.; El-Mashad, S.Y.; Aloyaydi, B.A.; Ibrahim, A.; Abdelhamid, A.A. Novel Meta-Heuristic Algorithm for Feature Selection, Unconstrained Functions and Engineering Problems. IEEE Access 2022, 10, 40536–40555. [Google Scholar] [CrossRef]
- El-Kenawy, E.-S.M.; Mirjalili, S.; Abdelhamid, A.A.; Ibrahim, A.; Khodadadi, N.; Eid, M.M. Meta-heuristic optimization and keystroke dynamics for authentication of smartphone users. Mathematics 2022, 10, 2912. [Google Scholar] [CrossRef]
- Liu, X.-J.; Yi, H.; Ni, Z.-H. Application of ant colony optimization algorithm in process planning optimization. J. Intell. Manuf. 2013, 24, 1–13. [Google Scholar] [CrossRef]
- Meng, A.-B.; Chen, Y.-C.; Yin, H.; Chen, S.-Z. Crisscross optimization algorithm and its application. Knowl.-Based Syst. 2014, 67, 218–229. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Maleki, I.; Dizaji, Z.A. Chaotic vortex search algorithm: Metaheuristic algorithm for feature selection. Evol. Intell. 2022, 15, 1777–1808. [Google Scholar] [CrossRef]
- Ahmad, M.F.; Isa, N.A.M.; Lim, W.H.; Ang, K.M. Differential evolution: A recent review based on state-of-the-art works. Alex. Eng. J. 2022, 61, 3831–3872. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Schaffer, J.D.; Caruana, R.A.; Eshelman, L.J. Using genetic search to exploit the emergent behavior of neural networks. Phys. D Nonlinear Phenom. 1990, 42, 244–248. [Google Scholar] [CrossRef]
- Kitano, H. Empirical studies on the speed of convergence of neural network training using genetic algorithms. In Proceedings of the AAAI Conference on Artificial Intelligence-1990, Boston, MA, USA, 29 July–3 August 1990; pp. 789–795. [Google Scholar]
- Stanley, K.O.; Miikkulainen, R. Evolving neural networks through augmenting topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef]
- Siebel, N.T.; Sommer, G. Evolutionary reinforcement learning of artificial neural networks. Int. J. Hybrid Intell. Syst. 2007, 4, 171–183. [Google Scholar] [CrossRef]
- Stanley, K.O.; D’Ambrosio, D.B.; Gauci, J. A hypercube-based encoding for evolving large-scale neural networks. Artif. Life 2009, 15, 185–212. [Google Scholar] [CrossRef] [PubMed]
- Verbancsics, P.; Harguess, J. Generative neuroevolution for deep learning. arXiv 2013, arXiv:1312.5355. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Albeahdili, H.M.; Han, T.; Islam, N.E. Hybrid algorithm for the optimization of training convolutional neural network. Int. J. Adv. Comput. Sci. Appl. 2015, 1, 79–85. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009; Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 3 June 2022).
- Sermanet, P.; Chintala, S.; LeCun, Y. Convolutional neural networks applied to house numbers digit classification. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 3288–3291. [Google Scholar]
- Wang, B.; Sun, Y.; Xue, B.; Zhang, M. Evolving deep convolutional neural networks by variable-length particle swarm optimization for image classification. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Junior, F.E.F.; Yen, G.G. Particle swarm optimization of deep neural networks architectures for image classification. Swarm Evol. Comput. 2019, 49, 62–74. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. A particle swarm optimization-based flexible convolutional autoencoder for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 2295–2309. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic Programming; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Oullette, R.; Browne, M.; Hirasawa, K. Genetic algorithm optimization of a convolutional neural network for autonomous crack detection. In Proceedings of the 2004 Congress on Evolutionary Computation (IEEE Cat. No. 04TH8753), Portland, OR, USA, 19–23 June 2004; pp. 516–521. [Google Scholar]
- Ijjina, E.P.; Chalavadi, K.M. Human action recognition using genetic algorithms and convolutional neural networks. Pattern Recognit. 2016, 59, 199–212. [Google Scholar] [CrossRef]
- Reddy, K.K.; Shah, M. Recognizing 50 human action categories of web videos. Mach. Vis. Appl. 2013, 24, 971–981. [Google Scholar] [CrossRef]
- Young, S.R.; Rose, D.C.; Karnowski, T.P.; Lim, S.-H.; Patton, R.M. Optimizing deep learning hyper-parameters through an evolutionary algorithm. In Proceedings of the Workshop on Machine Learning in High-Performance Computing Environments, Austin, TX, USA, 15 November 2015; pp. 1–5. [Google Scholar]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving deep convolutional neural networks for image classification. IEEE Trans. Evol. Comput. 2019, 24, 394–407. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, Y.; Liang, J.; Slowik, A. A self-adaptive mutation neural architecture search algorithm based on blocks. IEEE Comput. Intell. Mag. 2021, 16, 67–78. [Google Scholar] [CrossRef]
- Suganuma, M.; Shirakawa, S.; Nagao, T. A genetic programming approach to designing convolutional neural network architectures. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; pp. 497–504. [Google Scholar]
- Harding, S. Evolution of image filters on graphics processor units using cartesian genetic programming. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1921–1928. [Google Scholar]
- Miller, J.F.; Smith, S.L. Redundancy and computational efficiency in cartesian genetic programming. IEEE Trans. Evol. Comput. 2006, 10, 167–174. [Google Scholar] [CrossRef]
- Miller, J.F.; Harding, S.L. Cartesian genetic programming. In Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers, Montreal, QC, Canada, 8–12 July 2009; pp. 3489–3512. [Google Scholar]
- Wang, B.; Sun, Y.; Xue, B.; Zhang, M. A hybrid differential evolution approach to designing deep convolutional neural networks for image classification. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Wellington, New Zealand, 11–14 December 2018; pp. 237–250. [Google Scholar]
- Dahou, A.; Elaziz, M.A.; Zhou, J.; Xiong, S. Arabic sentiment classification using convolutional neural network and differential evolution algorithm. Comput. Intell. Neurosci. 2019, 2019, 2537689. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Jana, N.D.; Mallik, S.; Zhao, Z. Designing optimal convolutional neural network architecture using differential evolution algorithm. Patterns 2022, 3, 100567. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Larochelle, H.; Erhan, D.; Courville, A.; Bergstra, J.; Bengio, Y. An empirical evaluation of deep architectures on problems with many factors of variation. In Proceedings of the 24th International Conference on Machine Learning, Virtual, 13–15 April 2021; pp. 473–480. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Chan, T.-H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of ICML’11 Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Bruna, J.; Mallat, S. Invariant scattering convolution networks. IEEE Trans. Pattern Anal. Mach. 2013, 35, 1872–1886. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- García, S.; Molina, D.; Lozano, M.; Herrera, F. A study on the use of non-parametric tests for analyzing the evolutionary algorithms’ behaviour: A case study on the CEC’2005 special session on real parameter optimization. J. Heuristics 2009, 15, 617–644. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Functional Block | Hyperparameters | Values |
|---|---|---|
| TLBOCNN learner | 3 | |
| 20 | ||
| Convolutional (CV) | 3 | |
| 256 | ||
| Maximum Pooling (MP) | Pool size (i.e., kernel width kernel height) | |
| Stride size (i.e., stride width stride height) | ||
| Average Pooling (AP) | Pool size (i.e., kernel width kernel height) | |
| Stride size (i.e., stride width stride height) | ||
| Fully Connected (FC) | 1 | |
| 300 |
| Dataset | Input Size | No. of Output Classes | No. of Training Samples | No. of Testing Samples |
|---|---|---|---|---|
| MNIST | 10 | 50,000 | 10,000 | |
| MNIST-RD | 10 | 12,000 | 50,000 | |
| MNIST-RB | 10 | 12,000 | 50,000 | |
| MNIST-BI | 10 | 12,000 | 50,000 | |
| MNIST-RD+BI | 10 | 12,000 | 50,000 | |
| Rectangles | 2 | 1200 | 50,000 | |
| Rectangles-I | 2 | 12,000 | 50,000 | |
| Convex | 2 | 8000 | 50,000 | |
| Fashion | 10 | 60,000 | 10,000 |
| Parameters | Values |
|---|---|
| 10 | |
| Population size, N | 20 |
| 3 | |
| 20 | |
| 3 | |
| 256 | |
| Pool size of pooling layer | |
| Stride size of pooling layer | |
| 1 | |
| 300 | |
| Batch normalization | Yes |
| Dropout rate | 0.5 |
| 1 | |
| 100 |
| Algorithms | MNIST | MNIST-RD | MNIST-RB | MNIST-BI | MNIST-RD+BI |
|---|---|---|---|---|---|
| RandNet-2 | 98.75% (+) | 91.53% (+) | 86.53% (+) | 88.35% (+) | 56.31% (+) |
| LDANet-2 | 98.95% (+) | 92.48% (+) | 93.19% (+) | 87.58% (+) | 61.46% (+) |
| CAE-1 | 98.60% (+) | 95.48% (+) | 93.19% (+) | 87.58% (+) | 61.46% (+) |
| CAE-2 | 97.52% (+) | 90.34% (+) | 89.10% (+) | 84.50% (+) | 54.77% (+) |
| ScatNet-2 | 98.73% (+) | 92.52% (+) | 87.70% (+) | 81.60% (+) | 49.52% (+) |
| SVM+RBF | 96.97% (+) | 88.89% (+) | 85.42% (+) | 77.49% (+) | 44.82% (+) |
| SVM+Poly | 96.31% (+) | 84.58% (+) | 83.38% (+) | 75.99% (+) | 43.59% (+) |
| PCANet-2 | 98.60% (+) | 91.48% (+) | 93.15% (+) | 88.45% (+) | 64.14% (+) |
| NNet | 95.31% (+) | 81.89% (+) | 79.96% (+) | 72.59% (+) | 37.84% (+) |
| SAA-3 | 96.54% (+) | 89.70% (+) | 88.72% (+) | 77.00% (+) | 48.07% (+) |
| DBN-3 | 96.89% (+) | 89.70% (+) | 93.27% (+) | 83.69% (+) | 52.61% (+) |
| EvoCNN | 98.82% (+) | 94.78% (+) | 97.20% (+) | 95.47% (+) | 64.97% (+) |
| psoCNN | 99.51% (+) | 94.56% (+) | 97.61% (+) | 96.87% (+) | 81.05% (+) |
| TLBOCNN (Best) | 99.55% | 96.44% | 98.06% | 97.13% | 83.64% |
| TLBOCNN (Mean) | 99.52% | 95.73% | 97.72% | 96.96% | 81.14% |
| Algorithms | Rectangles | Rectangles-I | Convex | w/t/l | #BCA |
| RandNet-2 | 99.91% (+) | 83.00% (+) | 94.55% (+) | 8/0/0 | 0 |
| LDANet-2 | 99.86% (+) | 83.80% (+) | 92.78% (+) | 8/0/0 | 0 |
| CAE-1 | 99.86% (+) | 83.80% (+) | NA | 7/0/0 | 0 |
| CAE-2 | 98.46% (+) | 78.00% (+) | NA | 7/0/0 | 0 |
| ScatNet-2 | 99.99% (=) | 91.98% (+) | 93.50% (+) | 7/1/0 | 0 |
| SVM+RBF | 97.85% (+) | 75.96% (+) | 80.87% (+) | 8/0/0 | 0 |
| SVM+Poly | 97.85% (+) | 75.95% (+) | 80.18% (+) | 8/0/0 | 0 |
| PCANet-2 | 99.51% (+) | 86.61% (+) | 95.81% (+) | 8/0/0 | 0 |
| NNet | 92.84% (+) | 66.80% (+) | 67.75% (+) | 8/0/0 | 0 |
| SAA-3 | 97.59% (+) | 75.95% (+) | 81.59% (+) | 8/0/0 | 0 |
| DBN-3 | 97.39% (+) | 77.50% (+) | 81.37% (+) | 8/0/0 | 0 |
| EvoCNN | 99.99% (=) | 94.97% (+) | 95.18% (+) | 7/1/0 | 1 |
| psoCNN | 99.93% (+) | 96.03% (+) | 97.74% (+) | 8/0/0 | 0 |
| TLBOCNN (Best) | 99.99% | 97.25% | 97.84% | NA | 8 |
| TLBOCNN (Mean) | 99.94% | 95.72% | 97.53% | NA | NA |
| TLBOCNN (Best) vs. | p-Value | h-Value | ||
|---|---|---|---|---|
| RandNet-2 | 36.0 | 0.0 | 9.58 × 10−3 | + |
| LDANet-2 | 36.0 | 0.0 | 9.58 × 10−3 | + |
| ScatNet-2 | 28.0 | 0.0 | 1.42 × 10−2 | + |
| SVM+RBF | 36.0 | 0.0 | 9.58 × 10−3 | + |
| SVM+Poly | 36.0 | 0.0 | 9.58 × 10−3 | + |
| PCANet-2 | 36.0 | 0.0 | 9.58 × 10−3 | + |
| NNet | 36.0 | 0.0 | 9.58 × 10−3 | + |
| SAA-3 | 36.0 | 0.0 | 9.58 × 10−3 | + |
| DBN-3 | 36.0 | 0.0 | 9.58 × 10−3 | + |
| EvoCNN | 28.0 | 0.0 | 1.23 × 10−2 | + |
| psoCNN | 36.0 | 0.0 | 5.34 × 10−3 | + |
| Algorithms | Ranking | Chi-Square Statistic | p-Value |
|---|---|---|---|
| RandNet-2 | 6.0000 | 76.658654 | 0.00 × 10 |
| LDANet-2 | 5.2500 | ||
| ScatNet-2 | 5.8125 | ||
| SVM+RBF | 9.4375 | ||
| SVM+Poly | 10.5625 | ||
| PCANet-2 | 5.2500 | ||
| NNet | 12.0000 | ||
| SAA-3 | 9.0625 | ||
| DBN-3 | 7.9375 | ||
| EvoCNN | 3.6250 | ||
| psoCNN | 2.5000 | ||
| TLBOCNN (Best) | 1.1250 |
| TLBOCNN (Best) vs. | z | Unadjusted p | Bonferroni-Dunn p | Holm p | Hochberg p |
|---|---|---|---|---|---|
| NNet | 6.03 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 |
| SVM+Poly | 5.23 × 10 | 0.00 × 10 | 2.00 × 10−6 | 2.00 × 10−6 | 2.00 × 10−6 |
| SVM+RBF | 4.61 × 10 | 4.00 × 10−6 | 4.40 × 10−5 | 3.60 × 10−5 | 3.60 × 10−5 |
| SAA-3 | 4.40 × 10 | 1.10 × 10−5 | 1.17 × 10−4 | 8.50 × 10−5 | 8.50 × 10−5 |
| DBN-3 | 3.78 × 10 | 1.58 × 10−4 | 1.73 × 10−3 | 1.10 × 10−3 | 1.10 × 10−3 |
| RandNet-2 | 2.70 × 10 | 6.85 × 10−3 | 7.53 × 10−2 | 4.11 × 10−2 | 4.11 × 10−2 |
| ScatNet-2 | 2.60 × 10 | 9.32 × 10−3 | 1.02 × 10−1 | 4.66 × 10−2 | 4.66 × 10−2 |
| LDANet-2 | 2.29 × 10 | 2.21 × 10−2 | 2.43 × 10−1 | 8.85 × 10−2 | 6.64 × 10−2 |
| PCANet-2 | 2.29 × 10 | 2.21 × 10−2 | 2.43 × 10−1 | 8.85 × 10−2 | 6.64 × 10−2 |
| EvoCNN | 1.07 × 10 | 2.82 × 10−1 | 3.11 × 10 | 5.65 × 10−1 | 4.46 × 10−1 |
| psoCNN | 7.63 × 10−1 | 4.46 × 10−1 | 4.90 × 10 | 5.65 × 10−1 | 4.45 × 10−1 |
| Algorithms | Classification Accuracy | # Parameters |
|---|---|---|
| Human Performance 1 | 83.50% | NA |
| 2C1P2F+Dropout 1 | 91.60% | 3.27 M |
| 2C1P 1 | 92.50% | 100 k |
| 3C2F 1 | 90.70% | NA |
| 3C1P2F+Dropout 1 | 92.60% | 7.14 M |
| GRU+SVM 1 | 88.80% | NA |
| GRU+SVM+Dropout | 89.70% | NA |
| HOG + SVM 1 | 92.60% | NA |
| ResNet-18 [25] | 94.90% | 11 M |
| VGG-16 [23] | 93.50% | 26 M |
| AlexNet [22] | 89.90% | 60 M |
| SqueezeNet-200 [82] | 90.00% | 500 k |
| MLP 256-128-64 1 | 90.00% | 41 k |
| MLP 256-128-100 1 | 88.33% | 3 M |
| EvoCNN [67] | 94.53% | 6.68 M |
| psoCNN [60] | 92.81% | 2.58 M |
| TLBOCNN (Best) | 92.72% | 414 k |
| TLBOCNN (Mean) | 92.54% | 1.56 M |
| Dataset | Layers | Parameters |
|---|---|---|
| MNIST | Convolutional | |
| Convolutional | ||
| Convolutional | ||
| Fully Connected | ||
| MNIST-RD | Convolutional | |
| Convolutional | ||
| Average Pooling | ||
| Convolutional | ||
| Fully Connected | ||
| MNIST-RB | Convolutional | |
| Max Pooling | ||
| Convolutional | ||
| Convolutional | ||
| Fully Connected | ||
| MNIST-BI | Convolutional | |
| Convolutional | ||
| Convolutional | ||
| Convolutional | ||
| Fully Connected | ||
| MNIST-RD+BI | Convolutional | |
| Average Pooling | ||
| Convolutional | ||
| Convolutional | ||
| Fully Connected | ||
| Rectangles | Convolutional | |
| Average Pooling | ||
| Convolutional | ||
| Average Pooling | ||
| Convolutional | ||
| Fully Connected | ||
| Rectangles-I | Convolutional | |
| Max Pooling | ||
| Convolutional | ||
| Convolutional | ||
| Convolutional | ||
| Fully Connected | ||
| Convex | Convolutional | |
| Max Pooling | ||
| Max Pooling | ||
| Convolutional | ||
| Convolutional | ||
| Convolutional | ||
| Fully Connected | ||
| MNIST-Fashion | Convolutional | |
| Max Pooling | ||
| Fully Connected |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ang, K.M.; El-kenawy, E.-S.M.; Abdelhamid, A.A.; Ibrahim, A.; Alharbi, A.H.; Khafaga, D.S.; Tiang, S.S.; Lim, W.H. Optimal Design of Convolutional Neural Network Architectures Using Teaching–Learning-Based Optimization for Image Classification. Symmetry 2022, 14, 2323. https://doi.org/10.3390/sym14112323
Ang KM, El-kenawy E-SM, Abdelhamid AA, Ibrahim A, Alharbi AH, Khafaga DS, Tiang SS, Lim WH. Optimal Design of Convolutional Neural Network Architectures Using Teaching–Learning-Based Optimization for Image Classification. Symmetry. 2022; 14(11):2323. https://doi.org/10.3390/sym14112323
Chicago/Turabian StyleAng, Koon Meng, El-Sayed M. El-kenawy, Abdelaziz A. Abdelhamid, Abdelhameed Ibrahim, Amal H. Alharbi, Doaa Sami Khafaga, Sew Sun Tiang, and Wei Hong Lim. 2022. "Optimal Design of Convolutional Neural Network Architectures Using Teaching–Learning-Based Optimization for Image Classification" Symmetry 14, no. 11: 2323. https://doi.org/10.3390/sym14112323
APA StyleAng, K. M., El-kenawy, E.-S. M., Abdelhamid, A. A., Ibrahim, A., Alharbi, A. H., Khafaga, D. S., Tiang, S. S., & Lim, W. H. (2022). Optimal Design of Convolutional Neural Network Architectures Using Teaching–Learning-Based Optimization for Image Classification. Symmetry, 14(11), 2323. https://doi.org/10.3390/sym14112323