
Analysis of Urban Visual Memes Based on Dictionary Learning: An Example with Urban Image Data

 ,
,  and
and
Abstract
:1. Introduction
- We compute style features based on the deep-level features derived from the ResNet50 network, rather than employing convolutional layer features directly as in traditional methods, to better characterize urban styles.
- We employ dictionary learning methods to extract the visual memes that are the basic components of urban styles in order to interpret the similarities and differences among urban styles at a finer granularity.
- To further understand and quantify how urban styles differ, we define the symmetric memetic similarity and the style similarity based on sparse representations, which measure differences among urban styles from multi-levels.
2. Relation Work
2.1. Urban Style Analysis
2.2. Meme Theory
2.3. Dictionary Learning
3. Data
3.1. Data Resource
3.2. Data Processing
3.3. Data Error Analysis
4. Method
4.1. Research Framework
- 1.
- Data pre-processing: In this paper, some images of flowers and grasses that are not related to buildings are deleted and categorized according to cities. Because of the large sample size, this paper adopts the way of random sampling to select samples, for each city randomly sampled 5000 images each time, resize them to the size of the uniform specifications, and divide the training set and test set according to the ratio of 6:4, this paper sampled a total of five times, and the test set with the highest accuracy as the final result.
- 2.
- Obtaining style features: After dividing the test set and training set, the style features are extracted from the samples and the style vector of each sample is obtained.
- 3.
- Dictionary learning: Using the DPC method [8] to learn the dictionary of the style vectors of the training set, the dictionary and sparse matrix of each city are obtained, and the style vectors of the test set are tested to detect the similarity and difference of style between cities, and then the memetic similarity between cities is calculated by the dictionary to analyze the reasons for the similarity and difference of style between cities.
- 4.
- Urban style analysis: it includes three aspects of style similarity, meme type and sparse representation, respectively, among which style similarity is used to quantify the similarity and difference of style between cities; meme type is to detect the composition of memes; and sparse representation can not only detect the style between cities as a whole but also analyze the linear combination of vs. factors of the style of building images of a city, as well as the difference between two images of buildings from different cities. The sparse representation can not only detect the inter-city style as a whole but also analyze the linear combination of the meme factors of the style of a city’s architectural images and the reasons for the similarity of the style between two architectural images from different cities.
4.2. Style Feature
4.3. Dictionary Learning
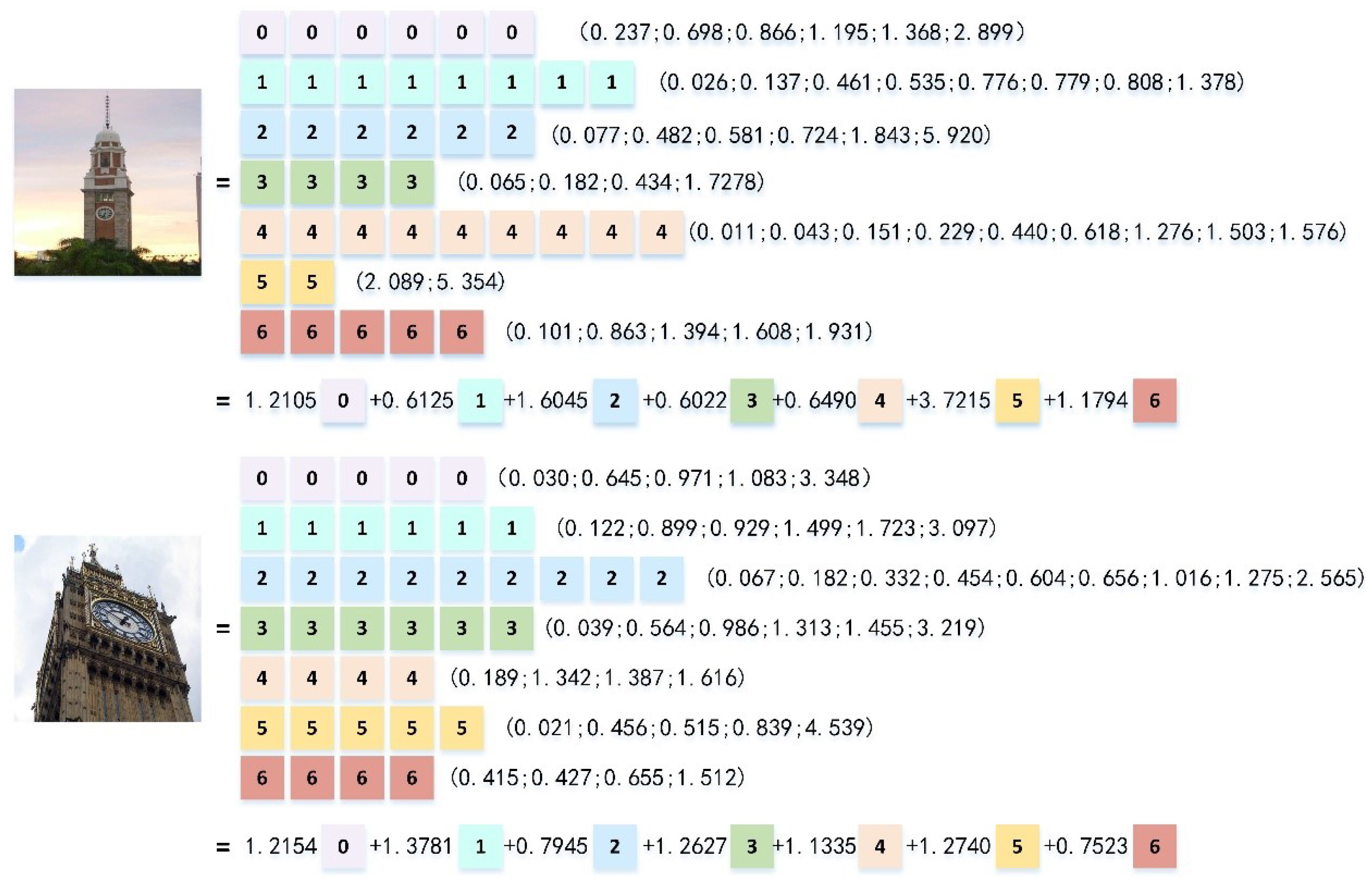
4.4. Sparse Representation
4.5. Memetic Similarity
4.6. Style Similarity
5. Results
5.1. Parameter Settings
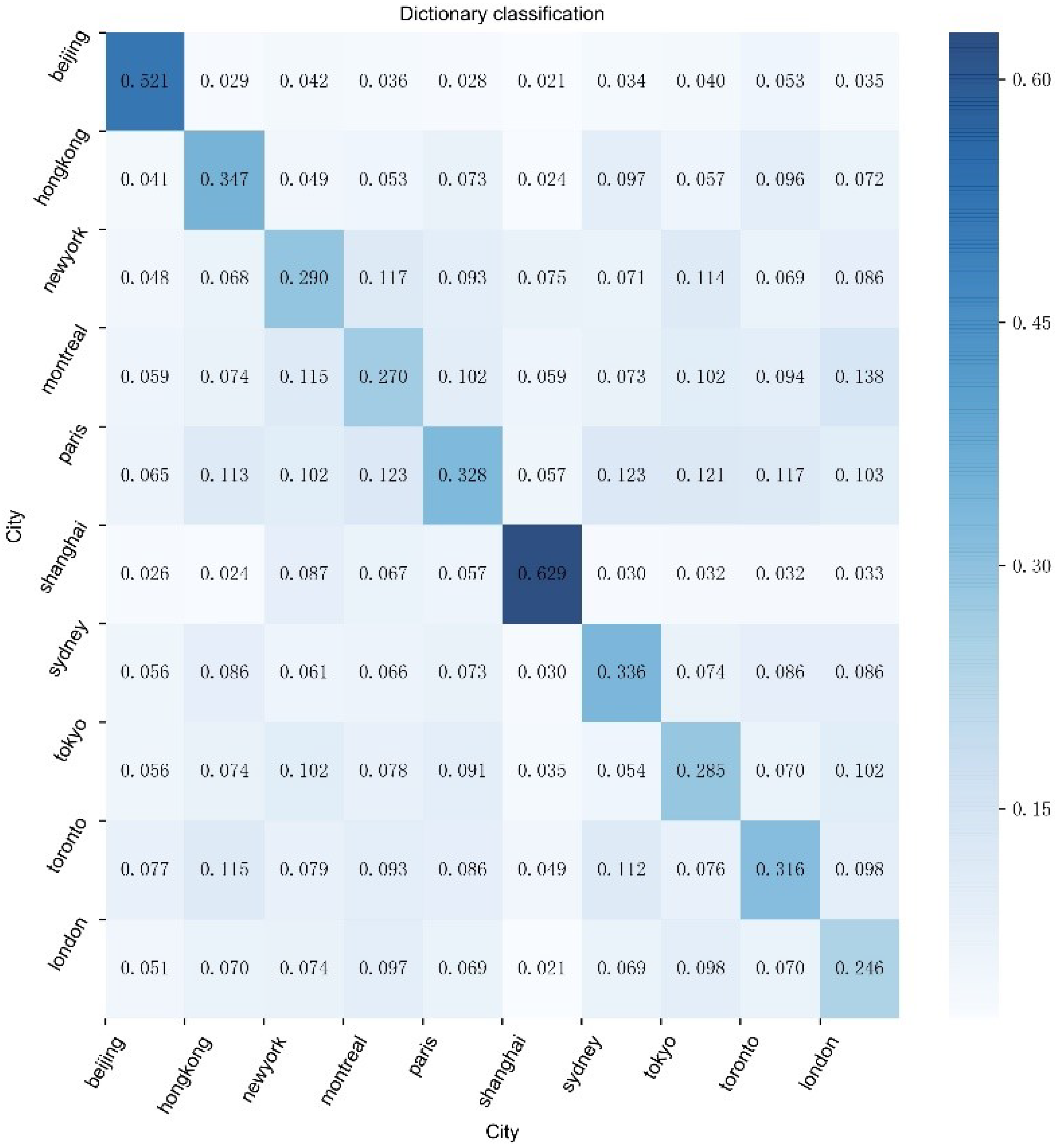
5.2. Dictionary Classification
5.3. Memetic Similarity
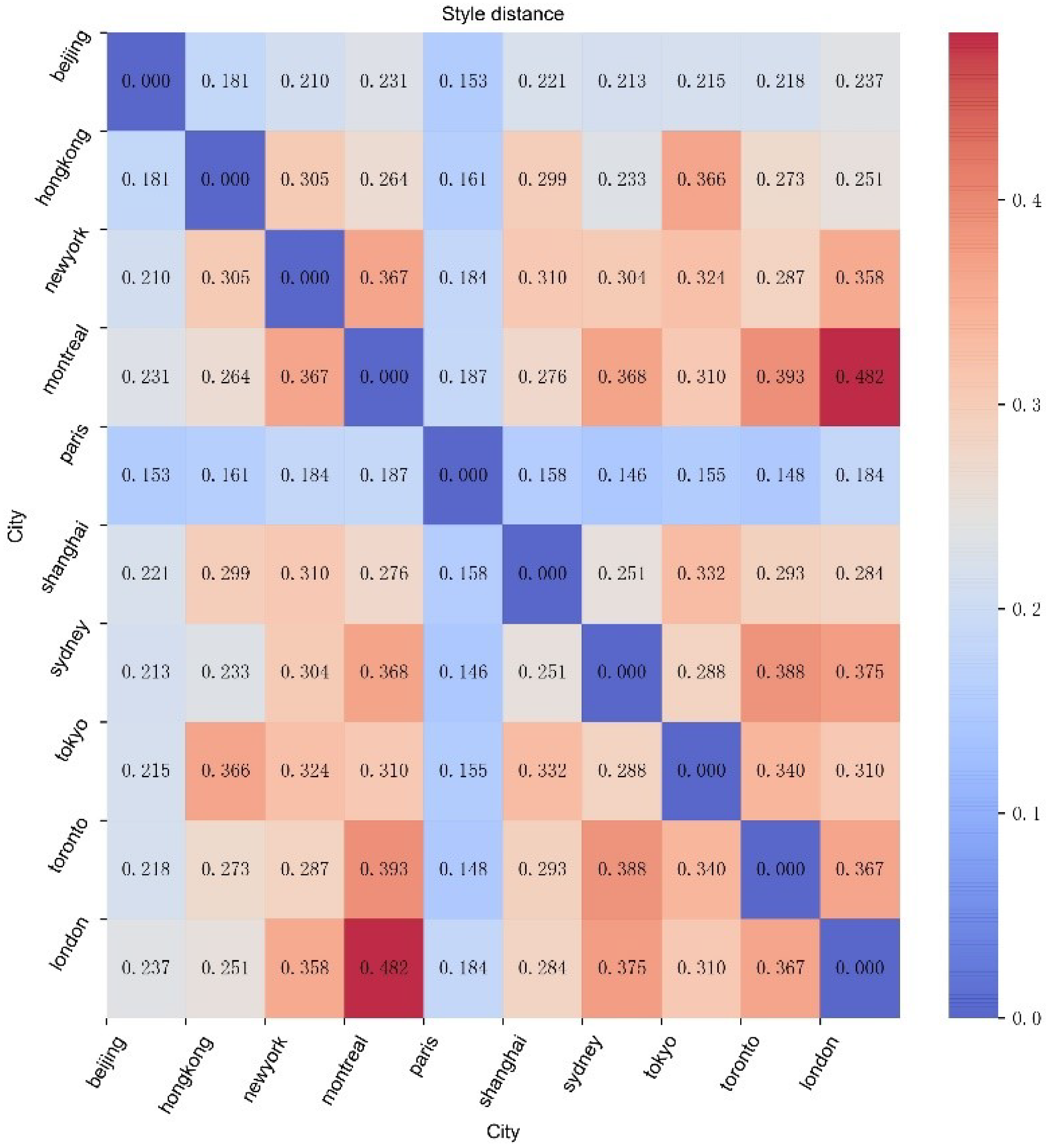
5.4. Style Similarity
5.5. Meme Type and Sparse Representation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Battiston, F.; Nicosia, V.; Latora, V.; San Miguel, M. Layered social influence promotes multiculturality in the Axelrod model. Sci. Rep. 2017, 7, 1809. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paasi, A. Region and place: Regional identity in question. Prog. Hum. Geogr. 2003, 27, 475–485. [Google Scholar] [CrossRef]
- Zhao, J.H.; Zeng, D.L.; Zhou, T.W.; Zhu, Z.C. Data Mining of Urban New Energy Vehicles in an Intelligent Government Subsidy Environment Using Closed-Loop Supply Chain Pricing Model. Comput. Syst. Sci. Eng. 2020, 35, 151–172. [Google Scholar] [CrossRef]
- Romeu, J. On Operations Research and Statistics Techniques: Keys to Quantitative Data Mining. Am. J. Math. Manag. Sci. 2006, 26, 293–328. [Google Scholar] [CrossRef]
- Obeso, A.M.; Vázquez, M.S.G.; Acosta, A.A.R.; Benois-Pineau, J. Connoisseur: Classification of styles of Mexican architectural heritage with deep learning and visual attention prediction. In Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing, Florence, Italy, 19–21 June 2017; pp. 1–7. [Google Scholar]
- Dawkins, R.; Davis, N. The Selfish Gene, 1st ed.; Macat Library: London, UK, 2017. [Google Scholar]
- Reynolds, D.A. Gaussian mixture models. Encycl. Biom. 2009, 741, 659–663. [Google Scholar]
- Ramirez, I.; Sprechmann, P.; Sapiro, G. Classification and clustering via dictionary learning with structured incoherence and shared features. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3501–3508. [Google Scholar]
- Oto-Peralías, D. What do street names tell us? The ‘city-text’as socio-cultural data. J. Econ. Geogr. 2018, 18, 187–211. [Google Scholar] [CrossRef]
- Hollenstein, L.; Purves, R. Exploring place through user-generated content: Using Flickr tags to describe city cores. J. Spat. Inf. Sci. 2010, 2010, 21–48. [Google Scholar]
- Zhou, B.; Liu, L.; Oliva, A.; Torralba, A. Recognizing city identity via attribute analysis of geo-tagged images. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 519–534. [Google Scholar]
- Dubey, A.; Naik, N.; Parikh, D.; Raskar, R.; Hidalgo, C.A. Deep learning the city: Quantifying urban perception at a global scale. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 196–212. [Google Scholar]
- Doersch, C.; Singh, S.; Gupta, A.; Sivic, J.; Efros, A. What makes paris look like paris? Commun. ACM 2015, 58, 103–110. [Google Scholar] [CrossRef]
- Stepaniuk, K. Visualization of expressing culinary experience in social network, memetic approach. Entrep. Sustain. Issues 2018, 5, 693–702. [Google Scholar] [CrossRef]
- Malhotra, N. An Empirical Analysis of “Tort Tales” How Cultural Memes Influence Attitudes on Tort Reform. J. Law Court. 2015, 3, 149–166. [Google Scholar] [CrossRef]
- Shin, S.; Park, J. Evolutionary Dynamics of Cultural Memes and Application to Massive Movie Data. arXiv 2019, arXiv:1903.02197. [Google Scholar]
- Walker, R. Cultural memes, innate proclivities and musical behaviour: A case study of the western traditions. Psychol. Music 2004, 32, 153–190. [Google Scholar] [CrossRef]
- Theisen, W.; Brogan, J.; Thomas, P.B.; Moreira, D.; Phoa, P.; Weninger, T.; Scheirer, W. Automatic discovery of political meme genres with diverse appearances. arXiv 2020, arXiv:2001.06122. [Google Scholar]
- Jia, G. Research on Dictionary Learning Based Ming and Qing Palace Dress Image Multi-Label Annotation for Cultural Gene. Master’s Thesis, Beijing University of Posts and Telecommunications, Beijing, China, 2018. [Google Scholar]
- Gu, B.; Xiong, W.; Bai, Z. Human Action Recognition Based on Supervised Class-Specific Dictionary Learning with Deep Convolutional Neural Network Features. Comput. Mater. Contin. 2020, 63, 243–262. [Google Scholar] [CrossRef]
- Geng, L.; Cui, C.; Guo, Q.; Niu, S.; Zhang, G.; Fu, P.; Geng, L.; Cui, C.; Guo, Q.; Niu, S.; et al. Robust Core Tensor Dictionary Learning with Modified Gaussian Mixture Model for Multispectral Image Restoration. Comput. Mater. Contin. 2020, 65, 913–928. [Google Scholar] [CrossRef]
- Hong, X.; Zheng, X.; Xia, J.; Wei, L.; Xue, W. Cross-Lingual Non-Ferrous Metals Related News Recognition Method Based on CNN with A Limited Bi-Lingual Dictionary. Comput. Mater. Contin. 2019, 58, 379–389. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, S.; Ying, L.; Peng, X.; Zhu, Y.; Liang, D. Adaptive dictionary learning in sparse gradient domain for image recovery. IEEE Trans. Image Process. 2013, 22, 4652–4663. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Moisan, L.; Yu, J.; Zeng, T. A dictionary learning approach for Poisson image deblurring. IEEE Trans. Med. Imaging 2013, 32, 1277–1289. [Google Scholar]
- Du, D.; Pan, Z.; Zhang, P.; Li, Y.; Ku, W. Compressive sensing image recovery using dictionary learning and shape-adaptive DCT thresholding. Magn. Reson. Imaging 2019, 55, 60–71. [Google Scholar] [CrossRef] [PubMed]
- Tartavel, G.; Gousseau, Y.; Peyré, G. Variational texture synthesis with sparsity and spectrum constraints. J. Math. Imaging Vis. 2015, 52, 124–144. [Google Scholar] [CrossRef]
- Quan, Y.; Huang, Y.; Ji, H. Dynamic texture recognition via orthogonal tensor dictionary learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 73–81. [Google Scholar]
- Gangeh, M.J.; Ghodsi, A.; Kamel, M.S. Dictionary learning in texture classification. In Proceedings of the International Conference Image Analysis and Recognition, Burnaby, BC, Canada, 22–24 June 2011; pp. 335–343. [Google Scholar]
- Chen, Y.; Su, J. Sparse embedded dictionary learning on face recognition. Pattern Recognit. 2017, 64, 51–59. [Google Scholar] [CrossRef]
- Ou, W.; You, X.; Tao, D.; Zhang, P.; Tang, Y.; Zhu, Z. Robust face recognition via occlusion dictionary learning. Pattern Recognit. 2014, 47, 1559–1572. [Google Scholar] [CrossRef]
- Luo, X.; Xu, Y.; Yang, J. Multi-resolution dictionary learning for face recognition. Pattern Recognit. 2019, 93, 283–292. [Google Scholar] [CrossRef]
- Lin, G.; Yang, M.; Yang, J.; Shen, L.; Xie, W. Robust, discriminative and comprehensive dictionary learning for face recognition. Pattern Recognit. 2018, 81, 341–356. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Rezende, E.; Ruppert, G.; Carvalho, T.; Ramos, F.; De Geus, P. Malicious software classification using transfer learning of resnet-50 deep neural network. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 1011–1014. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Mateen, M.; Wen, J.; Song, S.; Huang, Z. Fundus image classification using VGG-19 architecture with PCA and SVD. Symmetry 2019, 11, 1. [Google Scholar] [CrossRef] [Green Version]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Yang, J.; Ma, J. Large scale category-structured image retrieval for object identification through supervised learning of CNN and SURF-based matching. IEEE Access 2020, 8, 57796–57809. [Google Scholar] [CrossRef]
- Feng, Y.; Zeng, S.; Yang, Y.; Zhou, Y.; Pan, B. Study on the optimization of CNN based on image identification. In Proceedings of the 2018 17th International Symposium on Distributed Computing and Applications for Business Engineering and Science (DCABES), Wuxi, China, 19–23 October 2018; pp. 123–126. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Karayev, S.; Trentacoste, M.; Han, H.; Agarwala, A.; Darrell, T.; Hertzmann, A.; Winnemoeller, H. Recognizing image style. arXiv 2013, arXiv:1311.3715. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Image Volume | Building Volume | Duplicate Sample Screening |
|---|---|---|---|
| Beijing | 29,604 | 18,288 | 6190 |
| Hong Kong | 37,724 | 17,166 | 7617 |
| London | 121,724 | 74,300 | 22,964 |
| Montreal | 11,148 | 9252 | 6182 |
| New York | 107,967 | 63,887 | 24,066 |
| Paris | 73,487 | 10,865 | 5728 |
| Shanghai | 15,376 | 14,500 | 5655 |
| Sydney | 23,108 | 10,904 | 5262 |
| Tokyo | 86,044 | 33,701 | 13,938 |
| Toronto | 28,585 | 17,716 | 7184 |
| Time of Random Sample | Accuracy |
|---|---|
| 1 | 0.3565 |
| 2 | 0.3552 |
| 3 | 0.3504 |
| 4 | 0.3562 |
| 5 | 0.3567 |
| Average accuracy | 0.351 |
| City | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Beijing | 45 | 27 | 69 | 42 | 41 | 35 | 41 |
| Hong Kong | 37 | 31 | 69 | 55 | 54 | 27 | 27 |
| London | 46 | 27 | 80 | 51 | 33 | 35 | 28 |
| Montreal | 41 | 34 | 77 | 43 | 35 | 38 | 32 |
| New York | 46 | 29 | 80 | 47 | 39 | 32 | 27 |
| Paris | 21 | 60 | 83 | 44 | 40 | 34 | 18 |
| Shanghai | 41 | 26 | 73 | 45 | 41 | 34 | 40 |
| Sydney | 51 | 32 | 77 | 58 | 23 | 35 | 24 |
| Tokyo | 43 | 26 | 76 | 64 | 39 | 26 | 26 |
| Toronto | 43 | 32 | 82 | 61 | 29 | 27 | 26 |
| Total | 414 | 324 | 766 | 510 | 374 | 323 | 289 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Gu, X.; Xiao, J.; Zou, P.; Shi, Z.; He, S.; Li, H.; Li, S. Analysis of Urban Visual Memes Based on Dictionary Learning: An Example with Urban Image Data. Symmetry 2022, 14, 175. https://doi.org/10.3390/sym14010175
Zhang M, Gu X, Xiao J, Zou P, Shi Z, He S, Li H, Li S. Analysis of Urban Visual Memes Based on Dictionary Learning: An Example with Urban Image Data. Symmetry. 2022; 14(1):175. https://doi.org/10.3390/sym14010175
Chicago/Turabian StyleZhang, Ming, Xin Gu, Jun Xiao, Pu Zou, Zuoqin Shi, Silu He, Haifeng Li, and Sumin Li. 2022. "Analysis of Urban Visual Memes Based on Dictionary Learning: An Example with Urban Image Data" Symmetry 14, no. 1: 175. https://doi.org/10.3390/sym14010175
APA StyleZhang, M., Gu, X., Xiao, J., Zou, P., Shi, Z., He, S., Li, H., & Li, S. (2022). Analysis of Urban Visual Memes Based on Dictionary Learning: An Example with Urban Image Data. Symmetry, 14(1), 175. https://doi.org/10.3390/sym14010175