1. Introduction
With the improvement in economic and social development, high-quality electric energy supply provides an important guarantee for the efficient and stable development of the whole country. The accuracy of electricity load forecasting is directly related to the economic efficiency and reliability of each energy supply sector. Many important operational decisions such as generation plans, fuel procurement plans, maintenance plans, and energy trading plans are based on electricity load forecasting [
1,
2,
3,
4].
The intrinsic properties of the electrical load make it fundamentally different from other commodities. This is due to the non-storable nature of the electricity load, which is also influenced by the dynamic balance between supply and demand and the reliability of the intelligent transmission network [
5]. Accurate power load forecasting can effectively optimize the allocation of resources in intelligent distribution networks and power systems. For the supply sector of the power system, accurate load forecasting enables rational control of the capacity of generating units and rational dispatch of generating capacity, thus reducing energy wastage and costs. For the management of the power system, mastering the changes in the power load at any given moment allows them to control the power market information in advance and thus obtain higher economic benefits. In practice, the power sector often does not have access to symmetrical information. This is because inaccurate load forecasts provide the wrong information to the electricity sector, resulting in an asymmetry between the sector and the electricity consumers. The use of asymmetrical load information in production planning not only results in economic losses but also in wasted resources.
In summary, the power sector must ensure a dynamic balance between power demand and supply, while minimizing the waste of resources and economic losses [
6]. Therefore, accurate electricity load forecasting is key to achieving this target.
For the above reasons, a novel combinatorial model for electricity load forecasting is proposed by this paper. The model combines a data pre-processing method (VMD–singular spectrum analysis noise reduction method), two novel combinatorial intelligent optimization algorithms (the CAWOA and EOBL-CSSA algorithm), and three independent and efficient forecasting models (ELMAN neural network, LSSVM model, ELM neural network). Firstly, the original signal is pre-processed by the VMD–singular spectrum analysis data pre-processing method. Secondly, the noise-reduced signals are predicted using the Elman prediction model optimized by the SSA algorithm, the ELM prediction model optimized by the CAWOA-ELM algorithm, and the LSSVM prediction model optimized by the EOBL-CSSA-LSSVM algorithm for electricity load data, respectively. Finally, the weighting coefficients of the three prediction models are calculated using the simulated annealing (SA) algorithm and weighted to obtain the prediction results.
2. Literature Review
Due to the rapid development of smart distribution networks, new grid planning and strategy formulations need the support of high-precision power load forecasting. Many researchers have made unremitting efforts to improve the accuracy of power load forecasting in the environment of smart distribution networks. The different forecasting principles can be divided into traditional forecasting methods based on statistics [
7,
8] and intelligent forecasting methods based on machine learning algorithms [
9,
10]. Traditional methods of forecasting electrical loads have the advantage of low computational effort and high prediction accuracy for simple linear cases. However, such methods are not sufficient to deal with complex nonlinear load time series and are difficult to meet the needs of modern forecasting. With the development of artificial intelligence (AI) technology [
11,
12,
13], machine learning is widely used in the field of power load forecasting due to its powerful non-linear processing capability [
14].
The powerful adaptive and learning capabilities of machine learning algorithms are well suited for processing non-linear time series. However, different machine learning algorithms have their own limitations, which limit their further development. Currently, swarm intelligence optimization algorithms are widely used in neural networks, machine learning, and other intelligent algorithms for structural optimization [
15]. Common swarm intelligence optimization algorithms include: ant colony optimization algorithms (ACO) [
16,
17] and particle swarm optimization algorithms (PSO) [
18,
19]. In addition, such novel swarm intelligence optimization algorithms as the whale optimization algorithm (WOA) [
15,
20] and sparrow search algorithm (SSA) [
21] also show amazing potential in processing structure optimization.
Paper [
22] has shown that using raw data directly for prediction would significantly confound the results. In order to minimize the forecast error of electrical loads, scholars have carried out many studies on combined forecasting models based on data pre-processing and electrical load forecasting models. Typically, these scholars use wavelet transform (WT) [
23], empirical modal decomposition (EMD) [
24], variational modal decomposition (VMD) [
25], and singular spectrum analysis [
26] for noise reduction.
Electricity load is a complex time series with non-linear, highly random fluctuations and time-varying characteristics. The modern requirement for accurate forecasting is difficult to achieve due to the shortcomings of a single forecasting method. Therefore, the idea of combined forecasting is proposed to compensate for the shortcomings of single forecasting methods to improve the overall forecasting accuracy of the model [
27].
Jinliang Zhang and his colleagues [
28] proposed a hybrid forecasting model based on improved empirical modal decomposition (IEMD), autoregressive integrated moving average (ARIMA), and wavelet neural network (WNN) based on fruit fly optimization algorithm (FOA) optimization. Jinliang Zhang used the FOA algorithm to optimize the network parameters in the WNN algorithm. This approach can effectively improve the shortcomings of the WNN algorithm in terms of optimization capability. The optimized model is also combined with traditional prediction methods to improve the overall prediction accuracy. Simulation experiments demonstrate the effectiveness of this approach.
Heng Shi and his colleagues [
29] proposed a method for household load prediction using deep learning and a new deep recurrent neural network based on clustering. The machine learning algorithm batches the load into the input pool to avoid overfitting. Simulation experiments also demonstrate that the model has a higher prediction accuracy than traditional prediction models.
Kun Xie and his colleagues [
30] constructed a hybrid prediction model by optimizing the Elman neural network (ENN) with the PSO algorithm. The PSO algorithm was used to search for the optimal learning rate of the ENN to improve the prediction accuracy of the prediction model. Kun XI also analyzed the effect of neural network parameters on the performance of the network in detail and demonstrated that the optimization of network parameters can effectively improve the performance of the model. Finally, the effectiveness of the method was verified through simulation comparison experiments with the generalized regression neural network (GRNN) and traditional back propagation neural network (BPNN).
Zhihao Shang and his colleagues [
31] used the LSSVM, ELM, and GRNN models to construct a combined prediction model. The weight coefficients of the three models were calculated using the WOA algorithm. The model was compared with the traditional BP and ARIMA models by real data. The experimental results verify that the model has excellent prediction accuracy. This is also good evidence that the use of intelligent algorithms to optimize the weighting coefficients of different models can effectively improve the prediction accuracy of the models.
Lizhen Wu and his colleagues [
32] proposed a GRU-CNN neural network electricity load forecasting model based on gated recurrent units (GRU) and convolutional neural networks (CNN). Lizhen Wu used the GRU module to specifically process the feature vectors of time series data and the CNN module to process other high-dimensional data feature vectors. The effective combination of the two modules was used to improve the model prediction accuracy. Finally, the prediction performance of the model was verified by comparison experiments with BPNN, GRU, and CNN models.
Zuoxun Wang and his colleagues [
33] optimized the ELM neural network with the SSA algorithm improved by firefly perturbation and chaos strategies to construct an electricity load forecasting model. The powerful optimization-seeking capability of the FA-CSSA-ELM algorithm was exploited to optimize two parameters in the ELM algorithm. Finally, a comparison experiment with other competing models was used to verify that the model can improve the prediction accuracy well.
Hairui Zhang and his colleagues [
34] proposed a combined prediction model combining VMD, the Jordan neural network, the echo state network and the LSSVM model in order to overcome the shortcomings of the single prediction model. The PSO algorithm was used to optimize the relevant parameters of the neural network. This combined prediction model can make full use of the advantages of different models. Finally, the weight coefficients of the different models were calculated by the SA algorithm to obtain the final prediction results. The simulation experiments of power load forecasting also demonstrated that this model can improve the prediction accuracy of the forecasting model.
In summary, we found that the prediction performance of the combined prediction model is better than that of the single model. Additionally, we believe that there is still a huge potential for improvement in the selection and improvement of intelligent algorithms and data pre-processing for power load forecasting models, even though several of the above forecasting models have high forecasting accuracy and performance.
3. Materials and Methods
This chapter introduces VMD, singular spectrum analysis, noise reduction methods based on VMD–singular spectrum analysis, Elman neural network model, ELM neural network model, LSSVM model, WOA algorithm, CAWOA algorithm, SSA algorithm, EOBL-CSSA-LSSVM algorithm, and SA algorithm.
3.1. Variational Mode Decomposition
VMD is an adaptive solver and a completely non-recursive method for modal variation and signal processing. VMD can overcome the problems of endpoint effects and modal component confounding that exist in EMD methods. It has been demonstrated in the literature that VMD has a good decomposition effect in dealing with non-linear, non-stationary, and highly complex time series. Additionally, the specific algorithm derivation is shown in the paper [
35].
3.2. Singular Spectrum Analysis
Singular spectrum analysis was first applied to oceanographic research in 1978 [
36]. Nowadays, singular spectrum analysis is a common method for studying non-linear time series. The basic idea of singular spectrum analysis is to calculate its corresponding Hankel trajectory matrix
H from a one-dimensional time series
, as shown in Equation (1).
where
H is the trajectory matrix;
L is the sliding window parameter and 1 <
L <
N;
K is defined as
N −
L + 1; and the eigenvalues and eigenvectors of their corresponding eigenvectors are combined to reconstruct the new time series.
3.3. VMD–Specular Spectral Analysis Noise Reduction Method
In this paper, a noise reduction approach combining VMD and singular spectrum analysis is proposed. First, the original data are adaptively decomposed and reconstructed by introducing kurtosis calculation to make the variational mode decomposition. This ensures that the reconstructed signal is close to the original signal while removing the high-frequency noise present in it. Then, the reconstructed data are second filtered by an adaptive singular spectrum analysis filter to remove the relatively low-frequency residual noise. Additionally, the kurtosis value
is calculated as shown in Equation (2).
where
E is the expectation and
is the mean value of the series
x. The calculated kurtosis value
is then compared with the kurtosis threshold set in this paper to select the IMF components that need to be reconstructed. Finally, the signal to be reconstructed is noise-reduced by singular spectrum analysis.
The detailed steps of the VMD–singular spectrum analysis of noise reduction method can be summarized as follows:
Define the relevant parameters in VMD: the number of modes K and the penalty factor ;
Input time series . The time series is decomposed into K components of IMF by using VMD, and the decomposed components are denoted as ;
The kurtosis values of the K components of IMF obtained from the VMD decomposition are calculated according to Equation (2) and noted as ;
Calculate the kurtosis value for each IMF component and search for IMF components greater than the kurtosis threshold;
The IMF components obtained in step four are linearly reconstructed to obtain the VMD noise-reduced time series ;
For the VMD processed signal , choose a suitable window length parameter L to lag-arrange the original time series to construct the Hankel matrix ;
Singular spectrum analysis method is used to denoise Hankel matrix , and is obtained. U and V represent the associated left and right singular spectral vectors, respectively. Firstly, the covariance matrix of the Hankel matrix H is calculated, and then the covariance matrix S is decomposed into eigenvalues to obtain and the corresponding eigenvector . At this point, and are singular spectra of the original sequence, which can be expressed as , where is the corresponding eigenvector and is a time-empirical orthogonal function that can reflect the evolutionary pattern of the time series;
Divide the L components of the trajectory matrix H into C disjoint subsets representing the different trend components;
Reconstruct the time series. Calculate the projection
of the hysteresis matrix
onto
,
, where
reflects the weight of
at the time of the original series
, and
N is the length of the time series. Finally, the time series is reconstructed by means of the time-empirical orthogonal function
and the weights
. The specific reconstruction process can be defined as Equation (3):
3.4. Elman Neural Network Model
The Elman neural network with great computational power. Each layer of the Elman neural network is independent of each other, which is why it is widely used in the field of power load forecasting [
37].
Additionally, the non-linear state space expression of the Elman network can be defined as:
where
y is the output vector;
x is the unit vector;
u is the input vector;
is the state vector;
is the weight of the output layer and the intermediate layer;
is the weight of the input and intermediate layers;
is the weight of the take-up layer and the intermediate layer;
and
is the transfer function.
3.5. Extreme Learning Machine Neural Network
Elman is a neural network with powerful generalization capabilities. However, the initial weights and thresholds of ELM are randomly assigned [
38,
39].
Suppose there are Q learning samples,
and
. Assume that the number of hidden layer neurons is M. The standard form is shown in Equation (7):
According to the zero-error approximation principle, the existence of
,
,
reduces the normalized form to Equation (8).
where
H is the output matrix,
Y is the desired output matrix, and
a is the output weight matrix found using the solved least squares method. Finally, the solution is continued using
. The specific mathematical model is shown in paper [
38].
3.6. Least Square Support Vector Machine
LSSVM can convert complex quadratic programming problems into linear systems of equations problems and improve the speed of problem solving by replacing inequality constraints with equation constraints in SVM optimization problems [
40,
41].
Let the input and output of the
n training samples be
, where
is the input vector and
is the output vector. The optimal decision function is constructed in the high-dimensional feature space using a non-linear mapping function, as shown in Equation (9):
where
is the weight vector and
b is a constant. The optimization objective can be expressed as Equation (10):
The constraint can be expressed as Equation (11):
where
is the penalty factor and
is the relaxation factor. Because the LSSVM can transform a quadratic programming problem into a problem of solving the above system of linear equations, the prediction model can be summarized as Equation (12).
The specific mathematical derivation is shown in paper [
40].
3.7. Sparrow Search Algorithm
The sparrow search algorithm is a swarm intelligence optimization algorithm proposed by Xue in 2020 [
21]. The algorithm is mainly based on the foraging and anti-predation behavior of sparrows. The SSA has high search accuracy, fast convergence, high stability, and robustness compared to other population intelligence optimization algorithms. Additionally, the SSA has been successfully applied in the field of path planning [
42] and structural optimization of micro-grids [
43].
Sparrows in the SSA algorithm are classified as discoverers, joiners, and vigilantes. The discoverer is responsible for finding food for the entire population and providing foraging directions for the joiners, so the discoverer’s foraging search is larger than that of the joiners. During each iteration, the discoverer iterates according to Equation (13):
where
denotes the current number of iterations,
denotes the maximum number of iterations,
is a random number between
,
is a random number subject to a normal distribution,
is a matrix of
whose elements are all 1,
denotes a guard value, ranging from
, and
is a safe value, ranging from
.
During the foraging process, some joiners will always monitor the finder, and when the finder finds better food, the joiner will compete with it. If successful, it will immediately obtain that finder’s food, otherwise the joiner will update its position according to Equation (14).
where
denotes the worst position in dimension
of the
-th iteration and
denotes the best position. When
, it means that the population is short of food and needs to go elsewhere to forage. When
, it means that the tracker is predating near the optimal position
.
The number of sparrows aware of danger in a sparrow population is 10–20% of the total, and the location of these sparrows is randomly generated and continuously updated according to Equation (15) for the location of the vigilantes.
where
is the step control parameter, a normally distributed random number with a mean of 0 and a variance of 1;
is a random number between
;
is a very small number, just in case the denominator is 0;
is the current fitness;
is the best fitness; and
is the worst fitness.
3.8. The EOBL–CSSA Algorithm
In this paper, the chaotic mapping strategy and the elite opposition-based learning strategy are used to optimize the SSA algorithm. Firstly, the initial population is initialized by Tent chaotic mapping to improve the quality of the initial solution and enhance the global search capability of the algorithm. An elite back-learning mechanism is then introduced on top of the chaotic sparrow algorithm to extend the global search capability of the algorithm. Before extending the neighborhood of the current best individual, reverse learning is performed on it to generate a reverse search population within its search boundary, guiding the algorithm to approach the solution space containing the global optimum, thus improving the algorithm’s balancing and exploration capabilities as well as its ability to jump out of local extremes.
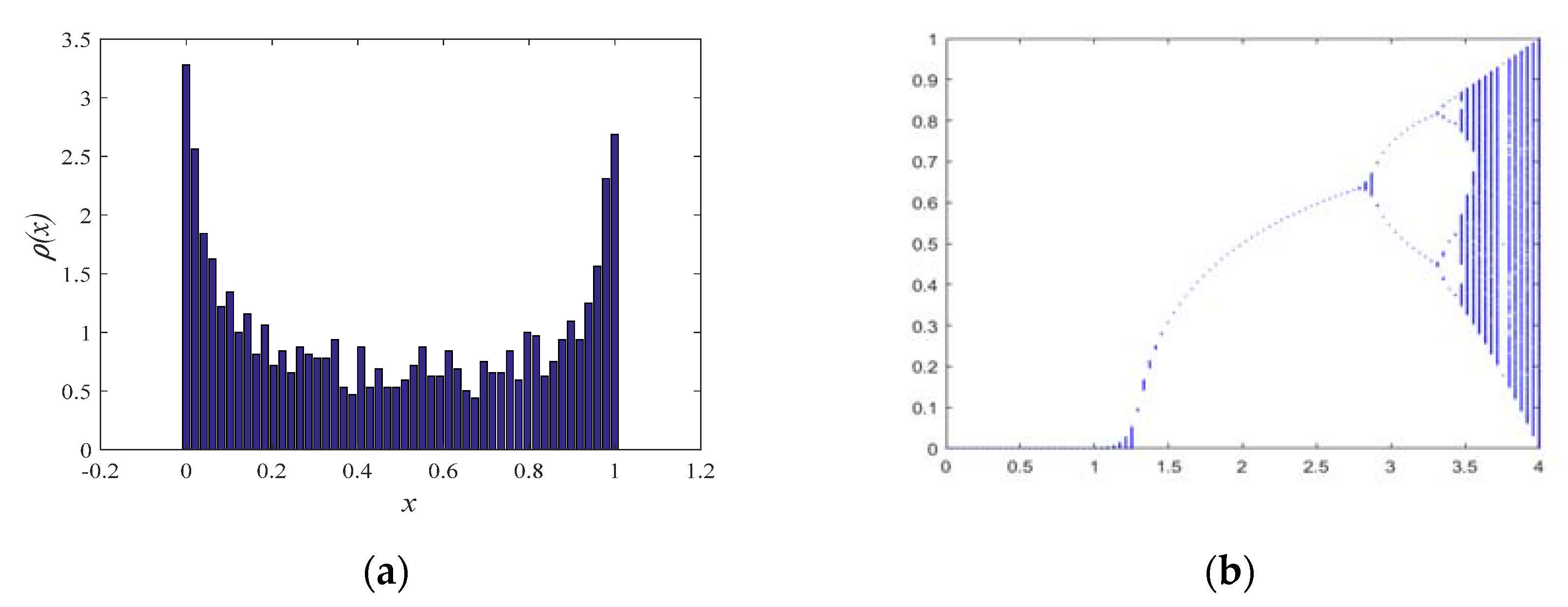
3.8.1. Tent Chaotic Mapping Strategy
The random and ergodic nature of chaos can effectively maintain the diversity of the population, helping the algorithm to jump out of the local optimum and improving the global search capability of the algorithm. It has been documented that the algorithm’s ability to find an optimum is influenced by the ergodicity of the chaotic mapping [
44]. The more uniform the chaotic mapping, the faster the convergence of the algorithm. As shown in
Figure 1, we can observe that the Tent chaotic mapping is well distributed and has even better traversal performance.
Suppose that in a space of dimension D, where
. Additionally, the Tent chaos mapping can be expressed as Equation (16):
3.8.2. Elite Opposition-Based Learning Strategies
Paper [
45] introduces the concept of backward learning for the first time. This method generates a reverse solution individual of the current individual in the fetching region and will select the better of the two into the next generation. It is further shown that the reverse solution has a probability of being closer to the global optimum than the current population by about 50%. The elite inverse strategy has been used in group intelligence optimization algorithms such as PSO [
46], Harris Hawk Optimization (HHO) [
47] and the Dragonfly Algorithm (DA) [
48].
In this paper, the global search capability of the algorithm is extended by introducing an elite opposition-based learning mechanism. The strategy takes the top 10% of individuals in terms of sparrow fitness as the elite solution, while obtaining the dynamic boundaries of the elite sparrows. Before neighborhood expansion is performed on the current best sparrow individual, backward learning is performed on it to generate a reverse search population within its search boundary, guiding the algorithm to approach the solution space containing the global optimum. The sparrow position is updated by comparing the sparrow adaptation values before and after the update. If the comparison result is better, the previous sparrow is replaced. In summary, the elite opposition-based learning strategy can be a good way to improve the algorithm’s balance and exploration capabilities, thus helping the algorithm to jump out of local extremes. The elite opposition-based learning strategy can be illustrated by the following three definitions:
Theorem 1. Reverse solution [49]: Let there exist a real numberon the interval. Then, the reverse solution ofis defined as. Suppose there exists a certain N-dimensional pointon an R-domain and. Then, defineto be the inverse of p, where; k is a generalized coefficient and is a uniform random number belonging within .
Theorem 2. Optimization based on reverse solutions [49]: Let the problem to be optimized be the minimum problem and the fitness function be set to . If there exists some feasible solution, then its reverse feasible solution is. Ifholds, then replacewith.
Theorem 3. Elite Reverse Solution [49]: Letbe the reverse solution of the current group of elite individualsin some N-dimensional space, where;; k is a generalized coefficient and is a uniform random number belonging to the interior of.
The flow of the chaotic sparrow search algorithm based on the elite opposition-based learning strategy can be summarized as follows:
Initialize the population and the number of iterations using the Tent chaos mapping formula . Initialize the initial ratio of predators and joiners;
Calculate fitness values and ranking based on the results;
Update predator location based on ;
Update joiner location based on ;
Update guard positions according to ;
Calculate fitness values and update sparrow positions;
Find the reverse solution of all current solutions according to the defining formula for the reverse solution;
Those individuals whose fitness value of the original solution is greater than the fitness value of the reverse solution are selected according to the elite selection formula and form an elite group;
On the new search space constructed by the elite population, the reverse solution is then found for individuals whose original solution fitness value is less than the reverse solution fitness value according to equation . If the algorithm converges to the global optimal solution, the search interval formed by the elite population must converge to the region where the optimal solution is located. This makes full use of the effective information of the elite population to generate the inverse solution on the dynamically defined interval formed by the elite population, guiding the search closer to the optimal solution;
Calculate the fitness value and update the sparrow individuals and locations. Compare the sparrow individuals and locations before and after the update and compare the results with each other to see if the results are better. If the result is better, replace the previous sparrow;
Determine whether the stop condition is met. If the condition is met, exit and output the result. Otherwise, repeat steps 2–10.
3.9. Whale Optimization Algorithm
The whale optimization algorithm is a new nature-inspired optimization algorithm proposed by Mirjalili in 2016 [
20]. The WOA simulates the social behavior of humpback whales, using random or optimal search agents to model the special hunting behavior of humpback whales, and introduces a bubble attack strategy based on this. The WOA converges quickly around the optimal value and has good global optimization capability. Paper [
20] systematically illustrates the mathematical model of the whale optimization algorithm.
However, the WOA has the disadvantages of uneven initial population distribution, low convergence accuracy, and insufficient global optimization capability when solving complex problems. Therefore, this paper proposes a chaotic adaptive whale algorithm on this basis.
3.10. Chaotic Adaptive Whale Optimization Algorithm
The population is initialized by the chaotic properties of the Sine chaos mapping to ensure a uniform distribution of this whale in the solution space. In addition, studies have shown that larger thresholds facilitate global exploration and smaller thresholds enhance local exploitation. Therefore, this paper introduces adaptive inertia weights to improve the convergence accuracy and global optimization capability of the algorithm. The algorithm is made to have larger inertia weights in the early iterations and smaller inertia weights in the later iterations.
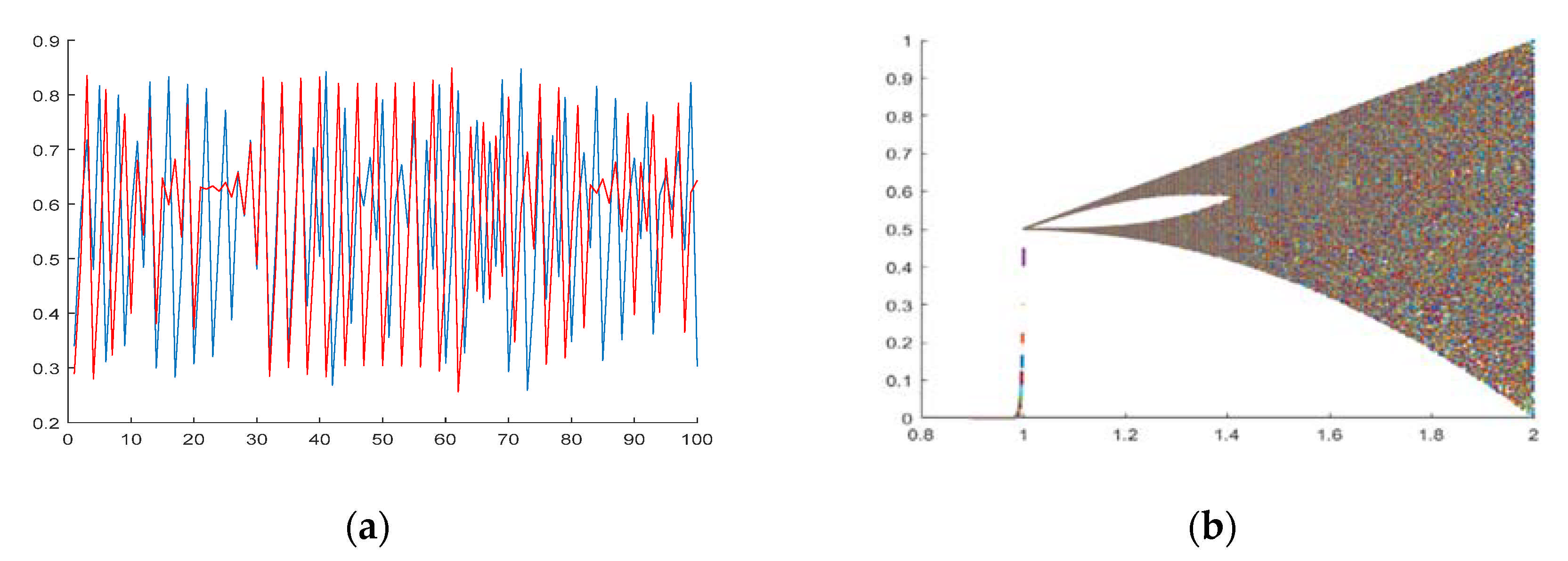
3.10.1. Sine Chaotic Mapping Strategy
The mathematical model of Sine chaotic self-mapping is defined as Equation (17):
Additionally, when
, the algorithm is in a chaotic state. This ensures that the whales are evenly distributed in the solution space after a certain number of iterations. The Sine chaos mapping distribution is shown in
Figure 2.
3.10.2. Adaptive Inertia Weights
The adaptive inertia weight is introduced to balance the global exploration capability and local exploitation capability of the algorithm. This can be a good way to improve the optimization capability of the algorithm. The mathematical model of adaptive inertia weight
is defined as Equation (18):
where
is the fitness value of whale
,
r is the current number of iterations, and
s is the best adaptation value for the whale population in the first iteration of the calculation. Using the dynamic nonlinearities of
to obtain the new whale position, the optimized formula can be expressed as Equations (19) and (22):
where
is the distance between the optimal solution and the current position,
b is the constant of the shape of the logarithmic spiral,
h is the random number between
,
is the current position of the whale,
is the prey position, which is the optimal solution, and
t is the number of iterations.
A and
are coefficient vectors, and
is selection probability.
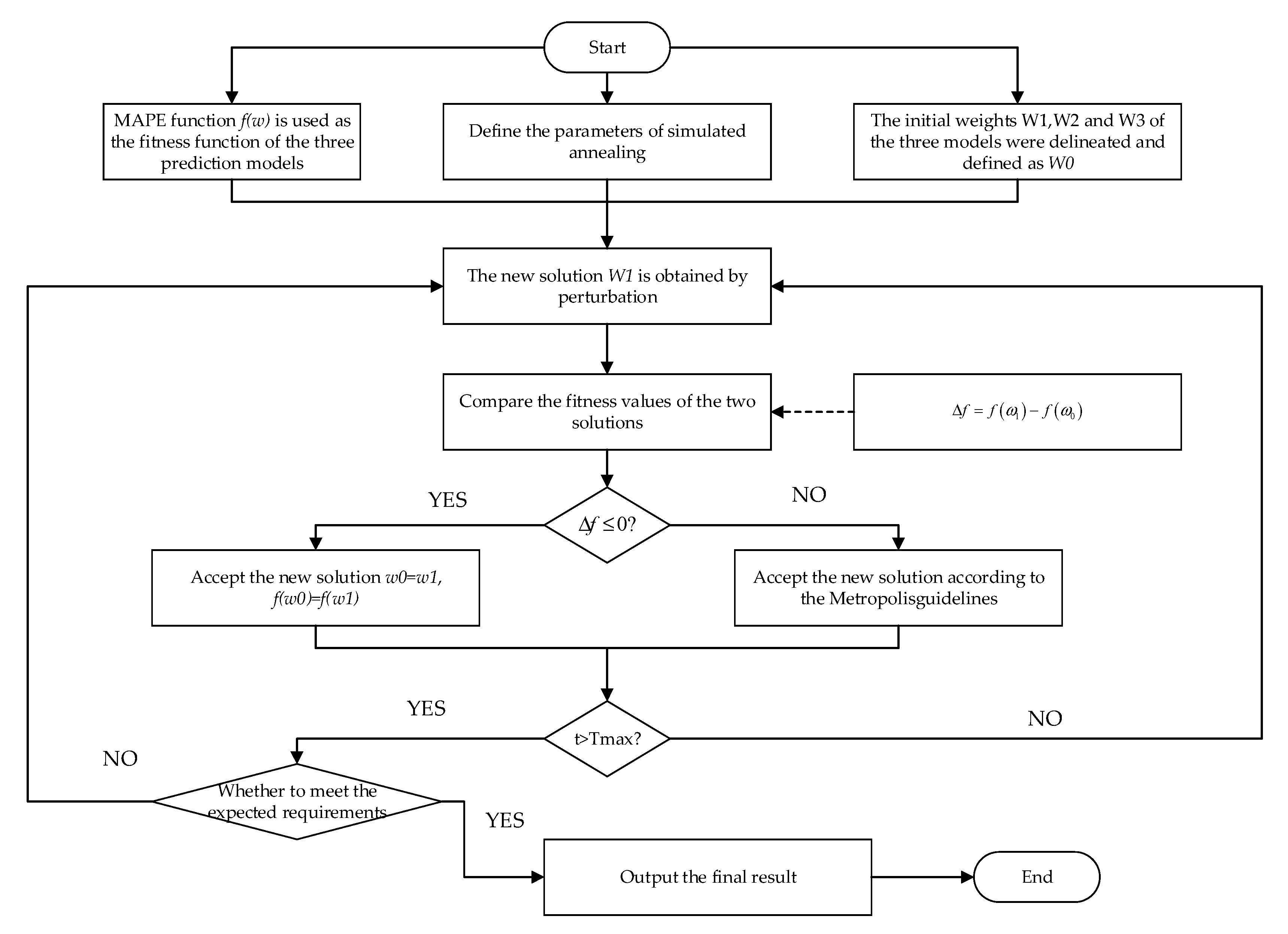
3.11. Simulated Annealing
The SA algorithm can be divided into two parts: the
Metropolis criterion and the annealing process. The specific mathematical model is shown in paper [
50]. In this paper, the SA algorithm is used to determine the proportion of weights for the prediction results of the three models, and the initial weights of all three models are set to 1/3. Finally, the prediction results of each prediction model are used to determine the final prediction results using Equation (23).
where
is the final prediction result;
,
, and
are the Elman prediction model, CAWOA-ELM prediction model, and EOBL-CSSA-LSSVM prediction model, respectively; and
,
, and
are the best weighting coefficients for the above three prediction models, respectively. The size of the weights represents the degree of influence the model has on the overall portfolio forecasting model. The larger the weight, the greater the contribution of the model to the portfolio model. The smaller the weight, the smaller the model’s contribution to the portfolio model. The specific operational flow of the SA algorithm to determine the optimal weighting coefficients for the three prediction models is shown in
Figure 3.
3.12. The Combined Forecasting Models
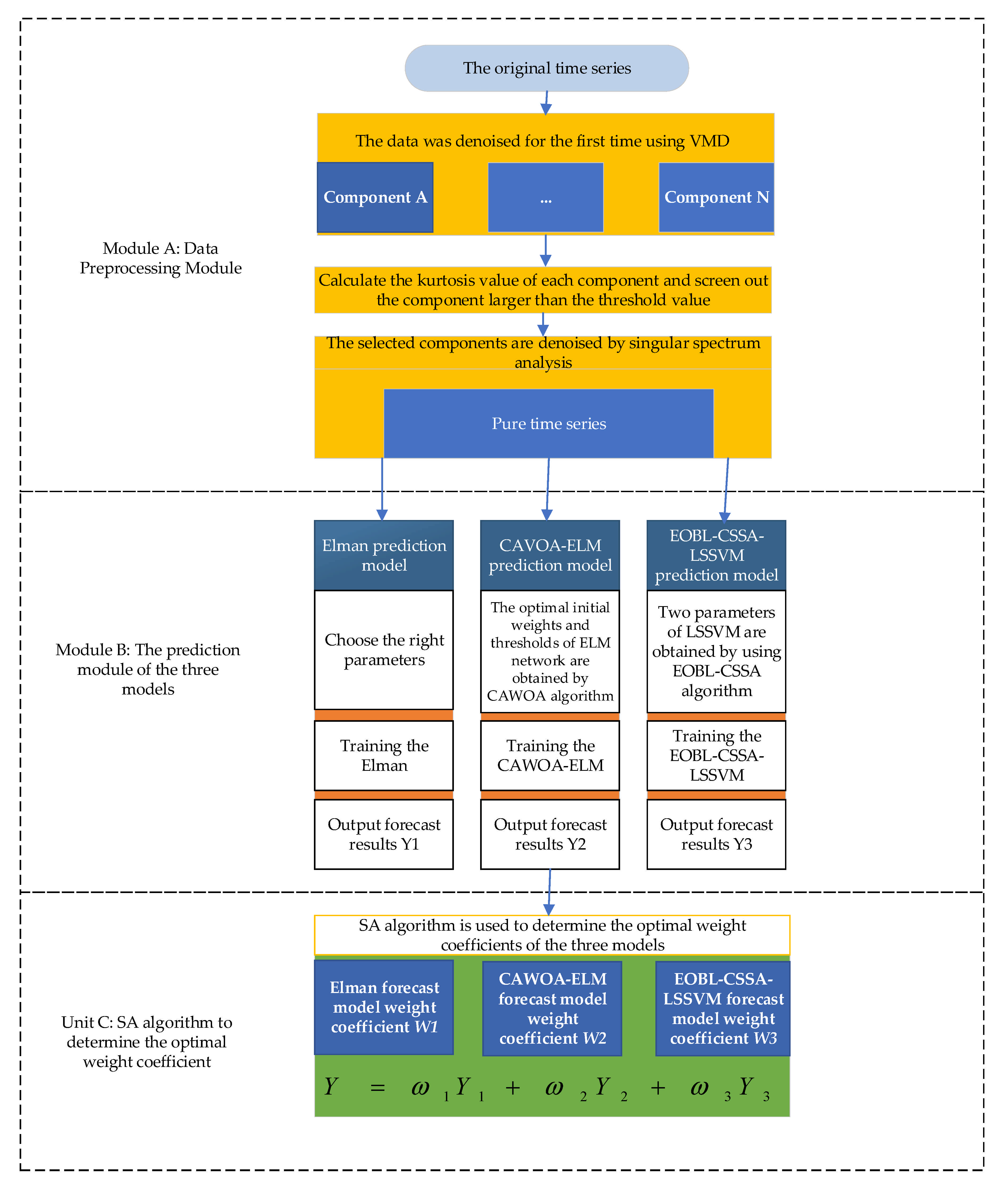
This paper introduces a novel combined prediction model based on machine learning algorithms, swarm intelligence optimization algorithms, and data pre-processing. As shown in
Figure 4, the prediction model can be simplified into three modules: Module A, Module B, and Module C.
Module A represents the data processing module. In real life, raw electrical load data inevitably contain data noise. This data noise can significantly interfere with the learning ability of the model. Therefore, we use VMD–spectral analysis to obtain pure signals.
Module B represents the process of obtaining forecasts using three independent forecasting models. Divide the pure data obtained through module A into the input set and the output set. Firstly, the ELMAN prediction model is trained with the dataset and the optimal number of hidden layers is determined by simulation. The prediction results are then recorded as . Secondly, the CAWOA-ELM model is trained with the dataset to obtain the prediction result . The appropriate initial weights and thresholds for the ELM model are selected by the CAWOA algorithm. Thirdly, the EOBL-CSSA-LSSVM model is trained using the dataset to obtain the prediction result . Then, the EOBL-CSSA algorithm is used to optimize the two parameters in the LSSVM: the penalty factor gam and RBF kernel parameter sig.
Module C represents the process of determining the best weighting coefficients for each set of prediction models by using the SA algorithm. Module C represents the weighting calculation process. The SA algorithm is used to determine the best weighting coefficients for each set of predictions obtained from module B predictions. Additionally, the weight coefficients obtained for each set are multiplied with the prediction results of each of the three prediction models. Finally, the final prediction results are obtained by summing.
3.13. Forecast Feedback System for Electricity Load Forecasting Models
In real life, the way in which the electricity load forecasting model is applied is shown in
Figure 5. The generator converts the voltage to 220 KV through the booster transformer. The electrical load is then transmitted to the primary high-voltage substation via the 220 KV high-voltage transmission line. The voltage is converted from 220 KV to 110 KV at the primary high-voltage substation and then transmitted to the secondary high-voltage substation via the 110 KV high-voltage transmission line. Finally, the secondary high-voltage substation converts the electrical load to the voltage required by the factory or the general user for the daily supply of electricity. Due to the nature of the electrical load, it cannot be stored on a large scale. If too much of the electrical load is transmitted, it can lead to a waste of resources. If too little electrical load is transmitted, it can lead to inadequate power supply and inconvenience to the population.
Based on the above problems, this paper applies the power load forecasting model to the primary high-voltage substation phase. Firstly, historical data of the power load in the area are collected through the relevant power department. The historical data are applied to the combined forecasting model proposed in this paper. The predictive model learns continuously to accurately predict the values and trends of the power loads on the 110 KV high-voltage transmission lines in the coming days. Secondly, the forecast results are fed back to the relevant authorities to provide accurate and reasonable feedback to the power sector. Finally, the power sector obtains symmetric information through the high accuracy of the combined forecasting model proposed in this paper. This symmetric information will not only help the power sector to maintain a dynamic balance between power supply and consumption, but also to reduce the waste of resources.
5. Analysis of Experimental Results of Power Load Simulation
In order to illustrate more effectively the points of the combined prediction model proposed in this paper, we divided the simulation experimental results into several groups of experiments for analysis.
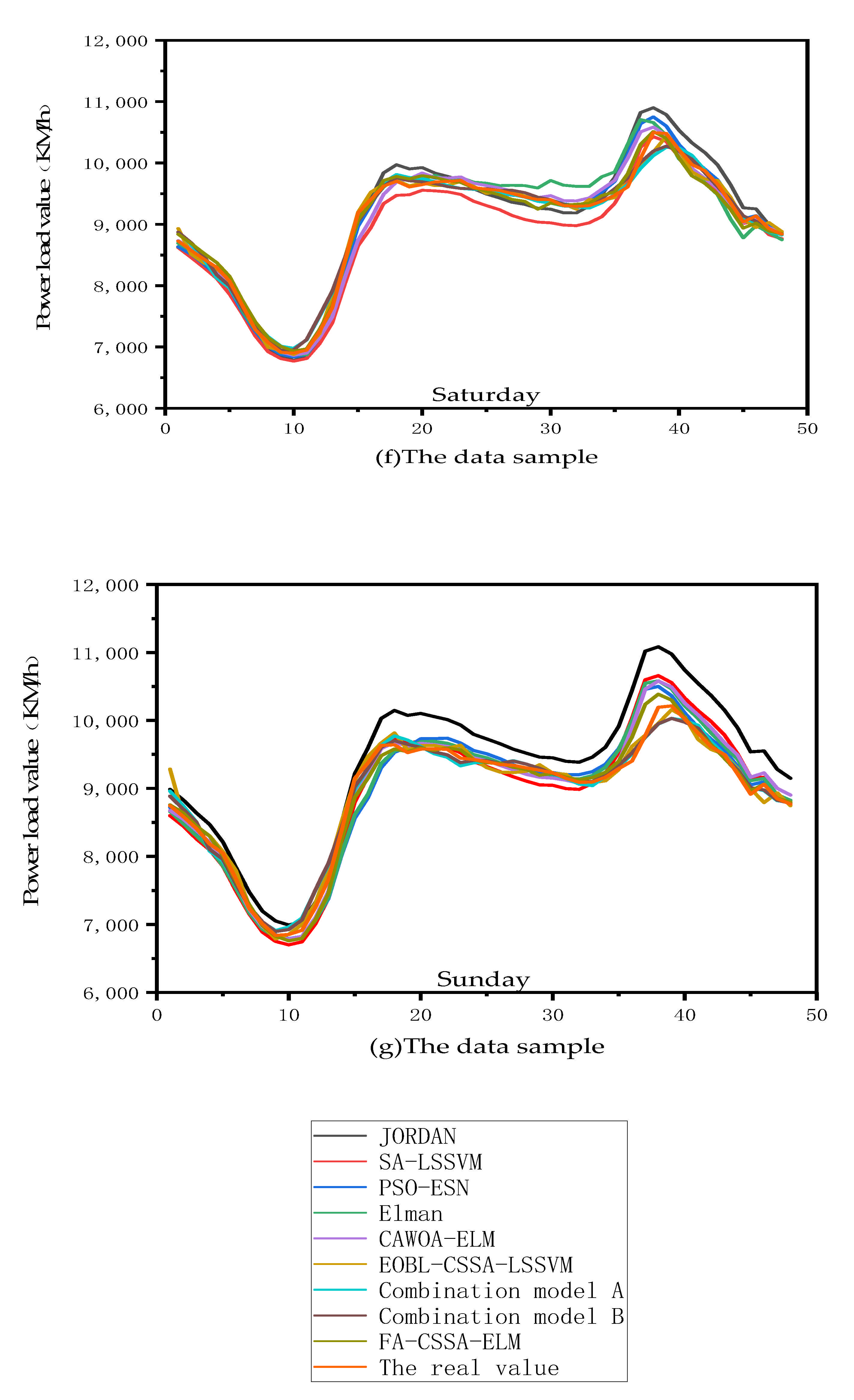
Figure 6 shows the prediction results and prediction trends for the three combined prediction models and the six individual prediction models.
Figure A1 in
Appendix A shows an enlarged view of the prediction results of the competitive model. The three combined forecasting models include the combined forecasting model proposed in this paper, the combined forecasting model proposed in paper [
34], and the FA-CSSA-ELM forecasting model proposed in paper [
33]. The six individual forecasting models include the Jordan model, the Elman model, the PSO-ESN, the SA-LSSVM, the CAWOA-ELM, and the EOBL-CSSA-LSSVM forecasting model. Additionally, the different color curves represent the prediction results of different prediction models.
We conducted a comparative analysis between the combined prediction model proposed in this paper and the six individual prediction models. As shown in
Figure 6, we found that the prediction results of the combined prediction model proposed in this paper are closer to the real historical data. This is followed by the prediction results of the EOBL-CSSA-LSSVM model and the PSO-ESN prediction model. Although the predictive performance of both the EOBL-CSSA-LSSVM model and the PSO-ESN model is excellent, the overall volatility of the PSO-ESN model is higher than that of the EOBL-CSSA-LSSVM model. However, the overall volatility of the PSO-ESN model is higher than that of the EOBL-CSSA-LSSVM model, especially on weekdays. Therefore, we believe that the EOBL-CSSA-LSSVM model has a better predictive performance. In addition, the prediction curves of Jordan’s model and Elman’s model are the furthest away from the real data and have the largest variation. Therefore, we conclude that the prediction performance of the Jordan and Elman models is relatively poor. In summary, the combined prediction model proposed in this paper showed the best prediction accuracy and prediction performance compared to the six individual prediction models.
We also conducted a comparative analysis between the combined prediction model proposed in this paper and the three combined prediction models. As shown in
Figure 6, among the three combined prediction models, the FA-CSSA-ELM prediction model has the lowest prediction accuracy and the prediction curve is the farthest away from the real data. In addition, the prediction curves of both the combined prediction model proposed in paper [
34] and the prediction model proposed in this paper are very close to the distance of the real data. However, on Thursday, the prediction curves of the model proposed in this paper are closer to the real data. Therefore, from an overall perspective, the prediction model proposed in this paper has the best prediction accuracy.
In order to more intuitively verify the predictive performance of the combined models proposed in this paper, we gave the evaluation values of the different prediction models in numerical form in conjunction with the four error evaluation metrics shown in
Table 1, as shown in
Table 9. In particular, the
RMSE,
MSE, and
MAE can reflect the prediction accuracy, while the
MAPE shows a high prediction expressiveness. In addition, we also compared the prediction performance of different prediction models more visually in the form of bar charts, as shown in
Figure 7. From the values of the indicators presented in
Table 9 and
Figure 7, we found that the
RMSE,
MAE,
MAPE, and
MSE values of the combined forecasting model proposed in this paper have the best expressions compared to other competing models. We also found a satisfactory prediction result: the
MAPE values for all data subsets were less than or equal to 1%, even with a minimum value of 0.57%. Although the mean
MAPE value of the prediction model proposed in paper [
34] is very close to 1%, its maximum and minimum
MAPE values are 1.52% and 0.62%, respectively. This also indicates that our proposed new combined forecasting model has the best forecasting accuracy and forecasting performance.
6. Conclusions
Nowadays, accurate electrical loads not only help the power sector to make rational work plans and production decisions, but also to reduce the waste of resources and economic losses. Based on the above problems, this paper proposes a combined power load forecasting model based on machine learning, swarm intelligence optimization algorithms, and data pre-processing. The combined model is based on the Elman model, the ELM model, and the LSSVM model. Additionally, two improved swarm intelligence optimization algorithms (CAWOA-CSSA and EOBL-CSSA algorithms) proposed in this paper are used to optimize the parameters of the ELM and LSSVM models, respectively. Then, the SA algorithm is used to calculate and assign the weighting coefficients of the three models. Finally, the final prediction results are obtained by weighted summation. By combining models, the advantages of machine learning algorithms, swarm intelligence optimization algorithms, and data pre-processing can be combined to reduce the shortcomings of a single model. In addition, through several sets of simulations and analysis of the experimental results, we obtained the following conclusions.
In short, the combined forecasting model proposed in this paper has strong forecasting performance and forecasting accuracy. Additionally, the VMD–singular spectrum analysis method proposed in this paper has an obvious denoising effect. In addition, the EOBL-CSSA algorithm and CAWOA algorithm proposed in this paper can also effectively improve the deficiencies of the machine learning model. Although the predictive performance of our proposed predictive model is excellent, it can provide effective feedback and information for the power sector. However, we have not considered too many practical factors such as weather and holidays. Therefore, we will consider the impact of other factors on power load forecasting in future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}